पहले के एक ट्यूटोरियल में, "डेटा फ़ाइलों को स्टेटिस्टिका के साथ मर्ज करना, भाग 1," हमने स्प्रेडशीट को मर्ज करने के लिए स्टेटिस्टिका का उपयोग करके पेश किया। हमने कॉन्सटेनेशन मर्ज मोड पर चर्चा की। इस ट्यूटोरियल में, हम दो अन्य तरीकों पर चर्चा करेंगे:केस नेम और वेरिएबल नेम का उपयोग करना। इस ट्यूटोरियल में निम्नलिखित भाग हैं:
- डेटा फ़ाइलों को मर्ज करने के लिए केस नामों का उपयोग करना
- डेटा फ़ाइलों को मर्ज करने के लिए चर नामों का उपयोग करना
- निष्कर्ष
डेटा फ़ाइलों को मर्ज करने के लिए केस नामों का उपयोग करना
इसके बाद, हम पंक्तियों का मिलान करके डेटा फ़ाइलों (स्प्रेडशीट्स) को मर्ज करेंगे (जिन्हें केस भी कहा जाता है) ) यदि पंक्तियों में समान केस नाम हैं, तो दो डेटा फ़ाइलों की पंक्तियों में डेटा मर्ज हो जाता है। पिछले आलेख में हमने जिन उदाहरण डेटा फ़ाइलों का उपयोग किया था उनमें केस का नाम शामिल नहीं है। केस का नाम 1 कॉलम, डेटा कॉलम से पहले कॉलम में निर्दिष्ट किया गया है। डेटा फ़ाइलों को जोड़ने के समान डेटा का उपयोग करते हुए, केस के नाम जोड़ें (log1 करने के लिए लॉग6 ) wlslog1.sta . में पंक्तियों में स्प्रेडशीट, जैसा कि चित्र 1 में दिखाया गया है।
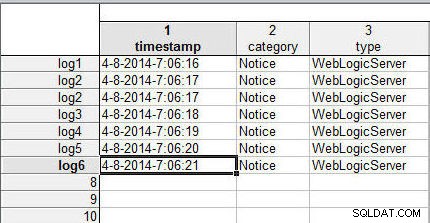
चित्र 1: स्प्रेडशीट wlslog1
इसी तरह, केस के नाम जोड़ें (log1 करने के लिए लॉग6 ) wlslog2.sta . में प्रत्येक पंक्ति में , जैसा कि चित्र 2 में दिखाया गया है।
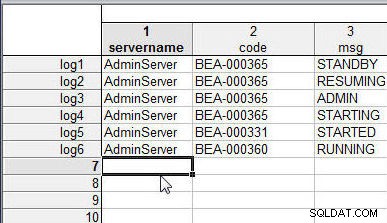
चित्र 2: स्प्रेडशीट wlslog2
डेटा>मर्ज करें Select चुनें और, मर्ज विकल्प . में , मोड . चुनें केसनामों का मिलान करें . के रूप में , जैसा चित्र 3 में दिखाया गया है। ठीक . क्लिक करें ।
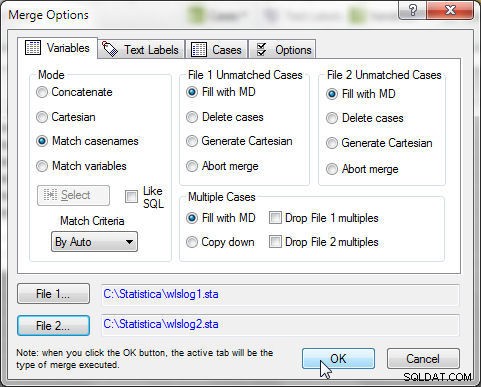
चित्र 3: Wlslog1 और wlslog2 को मर्ज करना
wlslog1.sta . में डेटा स्प्रैडशीट wlslog2.sta . में डेटा के साथ मर्ज हो जाती है स्प्रैडशीट, जैसा कि चित्र 4 में परिणामी स्प्रैडशीट में दिखाया गया है।
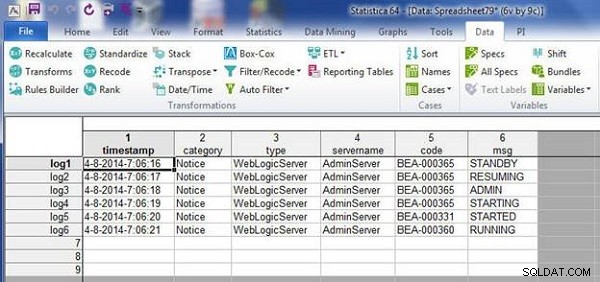
चित्र 4: मर्ज की गई फ़ाइल
केसनामों का मिलान करके विलय करते समय, मर्ज की जाने वाली प्रत्येक डेटा फ़ाइल में केस नाम शामिल होने चाहिए, या चित्र 5 में दिखाई गई त्रुटि प्रदर्शित हो जाती है।
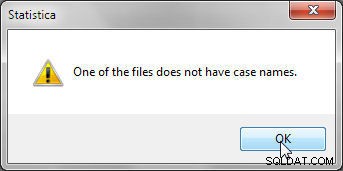
चित्र 5: केसनामों का मिलान करते हुए विलय करते समय केस नामों की आवश्यकता होती है
एक स्प्रेडशीट में दूसरे की तुलना में अधिक मामले (या पंक्तियाँ) हो सकते हैं। उदाहरण के तौर पर, wlslog1.sta . में एक 7 पंक्ति जोड़ें (चित्र 6 देखें)। मर्ज करें Click क्लिक करें स्प्रेडशीट मर्ज करने के लिए।
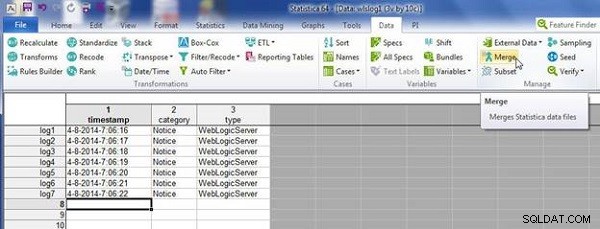
चित्र 6: wlslog1.sta में 7वीं पंक्ति के साथ मर्ज करें
केसनामों को wlslog2.sta . के साथ मिलान करके मर्ज करें , जो 6 मामलों (पंक्तियों) के साथ पहले जैसा ही है, जैसा कि चित्र 28 में दिखाया गया है। मर्ज की जाने वाली स्प्रेडशीट में बेजोड़ मामले हैं (एक स्प्रेडशीट में दूसरे की तुलना में अधिक मामले हैं)। बेजोड़ मामलों को डिफ़ॉल्ट रूप से लापता डेटा भरकर मर्ज कर दिया जाता है, जिसका अर्थ है कि डेटा मान खाली हैं। परिणामी स्प्रैडशीट में बेजोड़ मामलों के लिए खाली अनुपलब्ध डेटा है, जैसा कि चित्र 7 में दिखाया गया है।
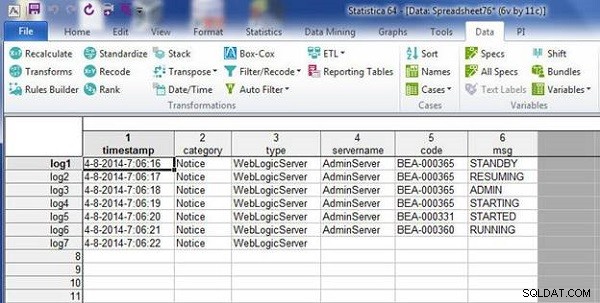
चित्र 7: परिणामी स्प्रैडशीट में खाली डेटा मौजूद नहीं है
मर्ज विकल्प बेजोड़ मामलों के लिए कुछ विकल्प प्रदान करता है लापता डेटा भरने के अलावा। प्रदर्शित करने के लिए, एक स्प्रेडशीट का उपयोग करें, wlslog1.sta , एक अतिरिक्त पंक्ति और एक डुप्लीकेट केस नाम के साथ (log2 ), जैसा कि चित्र 8 में दिखाया गया है।
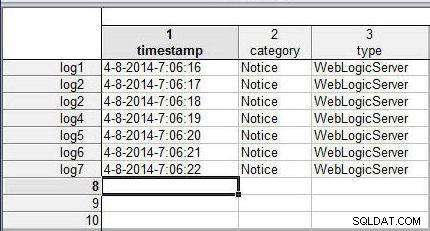
चित्र 8: डुप्लीकेट केस नाम वाली स्प्रेडशीट
फ़ाइल 1 बेजोड़ मामले . में मामलों को हटाएँ का चयन करके बेजोड़ मामलों को हटाया जा सकता है , जैसा कि चित्र 9 में दिखाया गया है। "फ़ाइल 1 गुणक छोड़ें" का चयन करके एकाधिक मामले तय किए जाते हैं। मर्ज मोड . के साथ केसनामों का मिलान करें . के रूप में , ठीक . क्लिक करें ।
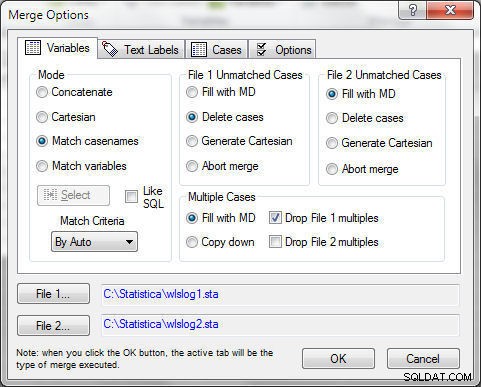
चित्र 9: फ़ाइल 1 बेजोड़ मामले>मामले हटाएं
परिणामी स्प्रैडशीट में दोनों समस्याएँ ठीक हो गई हैं। बेजोड़ केस को हटा दिया जाता है और डुप्लिकेट केस को हटा दिया जाता है, जैसा कि चित्र 10 में दिखाया गया है।
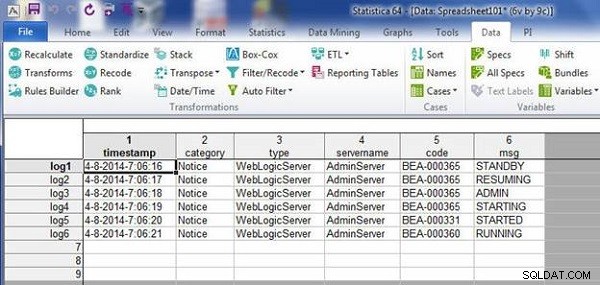
चित्र 10: बेजोड़ केस वाली परिणामी स्प्रैडशीट को हटा दिया गया और डुप्लीकेट केस को हटा दिया गया
डेटा फ़ाइलों को मर्ज करने के लिए चर नामों का उपयोग करना
इसके बाद, हम वेरिएबल नामों का मिलान करके स्प्रैडशीट्स को मर्ज करेंगे। दो स्प्रैडशीट से प्रारंभ करें, wlslog1.sta और wlslog2.sta , प्रत्येक स्तंभ नाम चित्र 11 में दिखाए गए हैं।
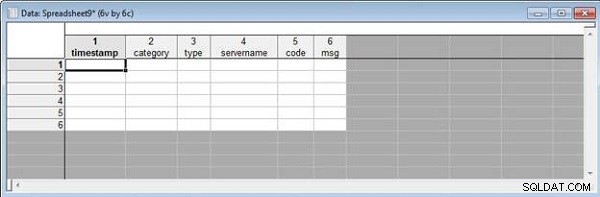
चित्र 11: wlslog1 और wlslog2 में कॉलम के नाम
निम्न डेटा को wlslog1.sta . में जोड़ें ।
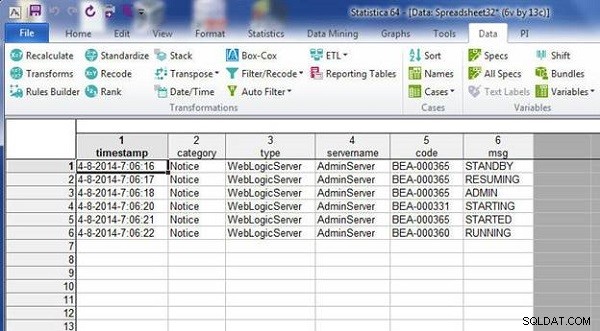
4-8-2014-7:06:16,Notice,WebLogicServer,AdminServer,BEA-000365, STANDBY 4-8-2014-7:06:17,Notice,WebLogicServer,AdminServer,BEA-000365, RESUMING 4-8-2014-7:06:18,Notice,WebLogicServer,AdminServer,BEA-000365, ADMIN
wlslog1.sta स्प्रैडशीट चित्र 12 में दिखाया गया है।
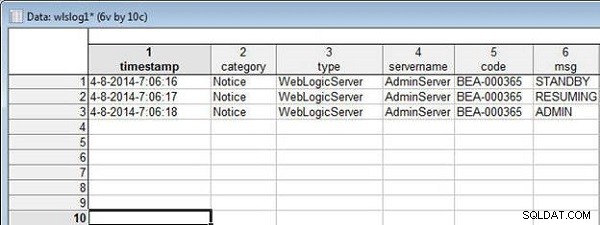
चित्र 12: स्प्रेडशीट wlslog1.sta
निम्न डेटा को wlslog2.sta . में जोड़ें ।
4-8-2014-7:06:20,Notice,WebLogicServer,AdminServer,BEA-000331, STARTING 4-8-2014-7:06:21,Notice,WebLogicServer,AdminServer,BEA-000365, STARTED 4-8-2014-7:06:22,Notice,WebLogicServer,AdminServer,BEA-000360, RUNNING
wlslog2.sta चित्र 13 में दिखाया गया है। डेटा>मर्ज करें Select चुनें पहले की तरह।
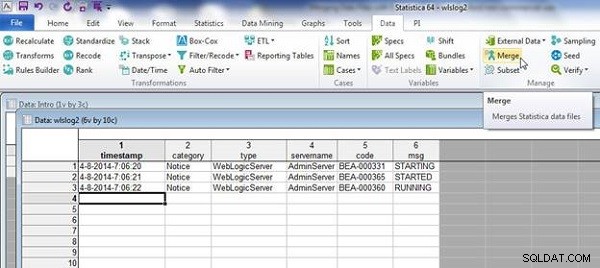
चित्र 13: स्प्रेडशीट wlslog2.sta
मर्ज विकल्प . में , मोड . चुनें मिलान चर . के रूप में , जैसा कि चित्र 14 में दिखाया गया है। फ़ाइल 1 . चुनें wlslog1.sta . के रूप में और फ़ाइल 2 wlslog2.sta . के रूप में . आदेश महत्वपूर्ण है क्योंकि दूसरे के निचले भाग में जोड़ी जाने वाली स्प्रैडशीट फ़ाइल 2 . होनी चाहिए . मिलान मानदंड रखें स्वतः . के रूप में , जो स्वचालित रूप से सबसे उपयुक्त मर्ज मानदंड चुनता है। मैच मानदंड के अन्य विकल्प पाठ द्वारा . हैं , जो टेक्स्ट की तुलना करके डेटा की तुलना करता है; और संख्यात्मक द्वारा , जो संख्यात्मक मानों की तुलना करके डेटा की तुलना करता है। इसके बाद, चुनें . क्लिक करें मिलान करने के लिए चर का चयन करने के लिए।
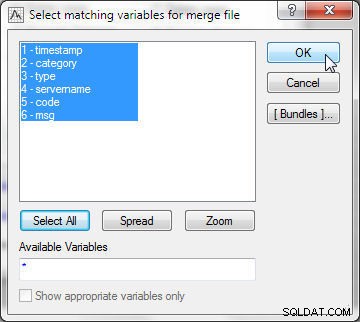
चित्र 14: मिलान चर के रूप में मर्ज मोड
सबसे पहले, वर्तमान फ़ाइल के लिए मिलान करने वाले चर चुनें (फ़ाइल 1)। सभी का चयन करें Click क्लिक करें और ठीक क्लिक करें, जैसा कि चित्र 15 में दिखाया गया है।
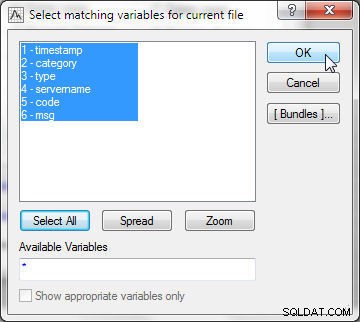
चित्र 15: वर्तमान फ़ाइल में वेरिएबल का चयन करना
इसी तरह, मर्ज फ़ाइल (फ़ाइल 2) के लिए सभी चरों का चयन करें और ठीक क्लिक करें (चित्र 16 देखें)।
चित्र 16: मर्ज फ़ाइल में वेरिएबल का चयन करना
मर्ज विकल्प में ठीक क्लिक करें, जैसा कि चित्र 17 में दिखाया गया है।
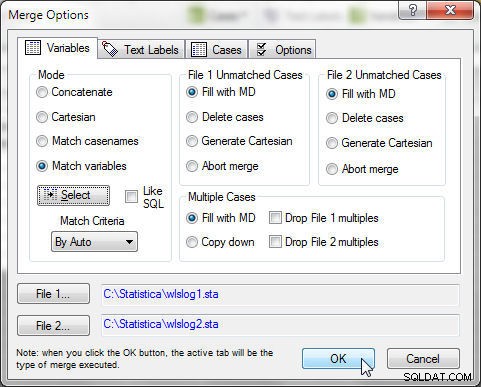
चित्र 17: मिलान चर के रूप में मोड के साथ विलय
जैसा कि चित्र 18 में दिखाया गया है, दो स्प्रैडशीट चर नामों के मिलान से मर्ज हो जाते हैं।
चित्र 18: वेरिएबल नामों का मिलान करके विलय से परिणामी स्प्रैडशीट
चर नामों का मिलान करके स्प्रैडशीट्स को मर्ज करते समय, डेटा मानों को संख्यात्मक और पाठ्य रूप से क्रमबद्ध किया जाता है। उदाहरण के तौर पर, चित्र 19 में दिखाए गए 1 स्प्रेडशीट के साथ दो स्प्रेडशीट मर्ज करें।
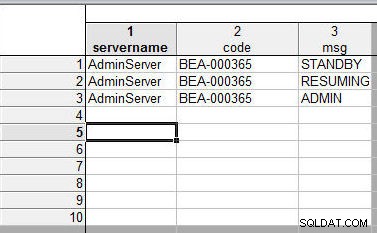
चित्र 19: मर्ज करने के लिए पहली स्प्रैडशीट
दूसरी स्प्रेडशीट चित्र 20 में दिखाई गई है। एक संशोधन जोड़ा गया है कि चर नाम को फ़ाइल 1 में थोड़ा संशोधित किया गया है:"सर्वरनाम" के बजाय "सर्वर टाइप", "कोड" के बजाय "मैसेजकोड", और "संदेश" के बजाय "संदेश"। संदेश"।
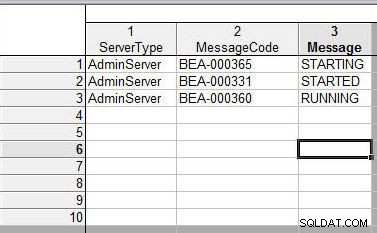
चित्र 20: मर्ज करने के लिए दूसरी स्प्रैडशीट
मिलान के लिए उपयोग किए जाने वाले चरों का चयन करने के लिए चयन करें पर क्लिक करें। फ़ाइल 1 में, सभी चर चुनें (चित्र 21 देखें)।
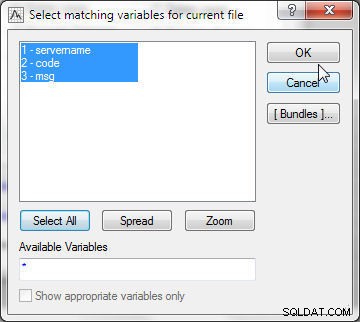
चित्र 21: वर्तमान फ़ाइल के लिए मिलान करने वाले चर का चयन करना
फ़ाइल 2 में, सभी चर भी चुनें, जैसा कि चित्र 22 में दिखाया गया है।
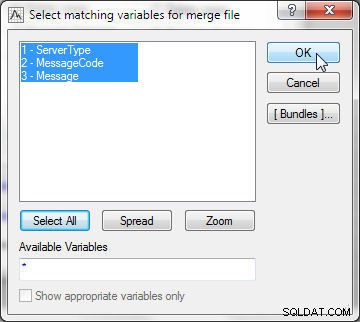
चित्र 22: मर्ज फ़ाइल के लिए मिलान करने वाले चर का चयन करना
दो स्प्रैडशीट्स को पहले की तरह मर्ज करें। "सर्वरनाम" या "सर्वर टाइप" सभी पंक्तियों के लिए समान है और परिणामी स्प्रेडशीट में डेटा की छंटाई में योगदान नहीं करता है। "कोड" या "मैसेजकोड" कॉलम डेटा मानों को टेक्स्ट केस असंवेदनशील के रूप में क्रमबद्ध किया जाता है; BEA-000331 को BEA-000360 से पहले सॉर्ट किया जाता है, जिसे BEA-000365 से पहले सॉर्ट किया जाता है। कोड BEA-000365 के समान मान के लिए, "msg" या "Message" कॉलम डेटा को टेक्स्ट द्वारा भी सॉर्ट किया जाता है—ADMIN->RESUMING->STANDBY>STARTING—जैसा कि चित्र 23 में दिखाया गया है।
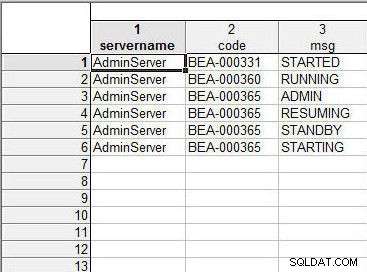
चित्र 23: परिणामी स्प्रैडशीट
चर का चयन करते समय कुछ शर्तों को लागू किया जाना चाहिए। मिलान के लिए कम से कम एक चर का चयन किया जाना चाहिए, या चित्र 24 में दिखाई गई त्रुटि उत्पन्न हो जाती है।
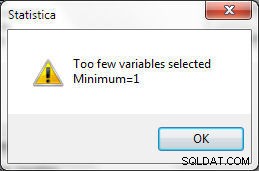
चित्र 24: कम से कम 1 वेरिएबल का चयन किया जाना चाहिए
फ़ाइल 1 और फ़ाइल 2 में चयनित चरों की संख्या समान होनी चाहिए, या चित्र 25 में दिखाई गई त्रुटि उत्पन्न हो जाती है।
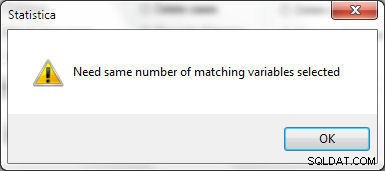
चित्र 25: स्प्रैडशीट में मर्ज करने के लिए समान संख्या में वैरिएबल का चयन किया जाना चाहिए
चयनित चरों का डेटा प्रकार चयनित चरों के लिए समान होना चाहिए। उदाहरण के तौर पर, फ़ाइल 1 और फ़ाइल 2 में क्रमशः "सर्वरनाम" और "सर्वर टाइप" चर का डेटा प्रकार समान होना चाहिए, या चित्र 26 में दिखाई गई त्रुटि उत्पन्न हो जाती है।
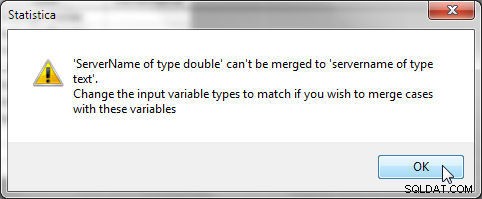
चित्र 26: वेरिएबल का मिलान करते समय वेरिएबल प्रकार समान होने चाहिए
निष्कर्ष
इस ट्यूटोरियल में, हमने स्टेटिस्टिका प्लेटफ़ॉर्म में मोड का उपयोग करके डेटा फ़ाइलों (जिसे स्प्रेडशीट भी कहा जाता है) को मर्ज करने पर चर्चा की:मैच केसनाम और मैच वेरिएबल।