यह लेख अपडेट क्वेरी से संबंधित कुछ गहन आंतरिक का पता लगाने के लिए एक साधारण क्वेरी का उपयोग करता है।
नमूना डेटा और कॉन्फ़िगरेशन
नीचे दी गई नमूना डेटा निर्माण स्क्रिप्ट के लिए संख्याओं की तालिका की आवश्यकता है। यदि आपके पास इनमें से कोई भी पहले से नहीं है, तो नीचे दी गई स्क्रिप्ट का उपयोग कुशलतापूर्वक एक बनाने के लिए किया जा सकता है। परिणामी संख्या तालिका में एक से दस लाख तक की संख्याओं वाला एक पूर्णांक स्तंभ होगा:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); नीचे दी गई स्क्रिप्ट 10,000 आईडी के साथ एक क्लस्टर नमूना डेटा तालिका बनाती है, जिसमें प्रति आईडी लगभग 100 अलग-अलग प्रारंभ तिथियां होती हैं। समाप्ति तिथि कॉलम शुरू में निश्चित मान '99991231' पर सेट किया गया है।
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); जबकि इस आलेख में दिए गए बिंदु सामान्य रूप से SQL सर्वर के सभी मौजूदा संस्करणों पर लागू होते हैं, नीचे दी गई कॉन्फ़िगरेशन जानकारी का उपयोग यह सुनिश्चित करने के लिए किया जा सकता है कि आप समान निष्पादन योजना और प्रदर्शन प्रभाव देखें:
- SQL Server 2012 सर्विस पैक 3 x64 डेवलपर संस्करण
- अधिकतम सर्वर मेमोरी 2048 एमबी पर सेट है
- उदाहरण के लिए उपलब्ध चार तार्किक प्रोसेसर
- कोई ट्रेस फ़्लैग सक्षम नहीं
- डिफ़ॉल्ट पढ़ने के लिए प्रतिबद्ध अलगाव स्तर
- RCSI और SI डेटाबेस विकल्प अक्षम
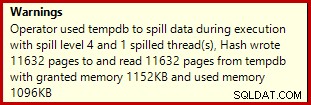
हैश एग्रीगेट स्पिल्स
यदि आप वास्तविक निष्पादन योजनाओं के साथ ऊपर डेटा निर्माण स्क्रिप्ट चलाते हैं, तो हैश एग्रीगेट एक चेतावनी आइकन उत्पन्न करते हुए tempdb पर फैल सकता है:

SQL सर्वर 2012 सर्विस पैक 3 पर निष्पादित होने पर, स्पिल के बारे में अतिरिक्त जानकारी टूलटिप में दिखाई जाती है:
यह स्पिल आश्चर्यजनक हो सकता है, यह देखते हुए कि हैश मैच के लिए इनपुट पंक्ति अनुमान बिल्कुल सही हैं:
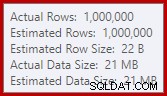
हम इनपुट . पर अनुमानों की तुलना करने के आदी हैं प्रकार और हैश जॉइन के लिए (केवल इनपुट बनाएं), लेकिन उत्सुक हैश समुच्चय अलग हैं। एक हैश समुच्चय हैश तालिका में समूहीकृत परिणाम पंक्तियों को जमा करके काम करता है, इसलिए यह आउटपुट की संख्या है पंक्तियाँ जो महत्वपूर्ण हैं:
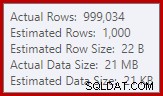
SQL सर्वर 2012 में कार्डिनैलिटी अनुमानक अपेक्षित अलग-अलग मानों की संख्या पर एक खराब अनुमान लगाता है (1,000 बनाम 999,034 वास्तविक); हैश कुल परिणाम के रूप में रनटाइम पर स्तर 4 पर पुनरावर्ती रूप से फैलता है। SQL सर्वर 2014 में उपलब्ध 'नया' कार्डिनैलिटी अनुमानक इस क्वेरी में हैश आउटपुट के लिए अधिक सटीक अनुमान उत्पन्न करने के लिए होता है, इसलिए आपको उस स्थिति में हैश स्पिल नहीं दिखाई देगा:

स्क्रिप्ट में छद्म-यादृच्छिक संख्या जनरेटर के उपयोग को देखते हुए, वास्तविक पंक्तियों की संख्या आपके लिए थोड़ी भिन्न हो सकती है। महत्वपूर्ण बिंदु यह है कि हैश एग्रीगेट स्पिल अद्वितीय मान आउटपुट की संख्या पर निर्भर करता है, इनपुट आकार पर नहीं।
अपडेट विशिष्टता
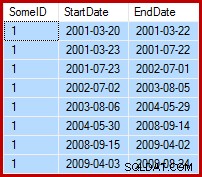
हाथ में कार्य उदाहरण डेटा को अपडेट करना है जैसे कि समाप्ति तिथियां निम्नलिखित प्रारंभ तिथि (प्रति SomeID) से एक दिन पहले सेट की जाती हैं। उदाहरण के लिए, नमूना डेटा की पहली कुछ पंक्तियां अपडेट से पहले इस तरह दिख सकती हैं (सभी समाप्ति तिथियां 9999-12-31 पर सेट हैं):

फिर अपडेट के बाद इस तरह करें:
1. बेसलाइन अपडेट क्वेरी
टी-एसक्यूएल में आवश्यक अपडेट को व्यक्त करने का एक स्वाभाविक तरीका इस प्रकार है:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); निष्पादन के बाद (वास्तविक) निष्पादन योजना है:
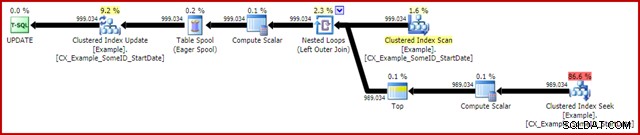
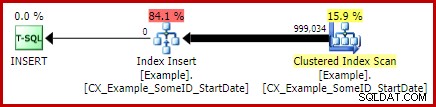
सबसे उल्लेखनीय विशेषता हैलोवीन सुरक्षा प्रदान करने के लिए एक उत्सुक टेबल स्पूल का उपयोग है। अद्यतन लक्ष्य तालिका के स्वयं-जुड़ने के कारण यहां सही संचालन के लिए यह आवश्यक है। प्रभाव यह है कि स्पूल के दाईं ओर सब कुछ पूरा होने के लिए चलाया जाता है, एक tempdb कार्य तालिका में परिवर्तन करने के लिए आवश्यक सभी जानकारी संग्रहीत करता है। एक बार रीडिंग ऑपरेशन पूरा हो जाने के बाद, क्लस्टर इंडेक्स अपडेट इटरेटर में परिवर्तन लागू करने के लिए कार्य तालिका की सामग्री को फिर से चलाया जाता है।
प्रदर्शन
इस निष्पादन योजना की अधिकतम प्रदर्शन क्षमता पर ध्यान केंद्रित करने के लिए, हम एक ही अद्यतन क्वेरी को कई बार चला सकते हैं। स्पष्ट रूप से, केवल पहले रन के परिणामस्वरूप डेटा में कोई परिवर्तन होगा, लेकिन यह एक मामूली विचार है। यदि यह आपको परेशान करता है, तो निम्न कोड का उपयोग करके प्रत्येक रन से पहले समाप्ति तिथि कॉलम को रीसेट करने के लिए स्वतंत्र महसूस करें। मैं जो व्यापक बिंदु बना रहा हूं वह वास्तव में किए गए डेटा परिवर्तनों की संख्या पर निर्भर नहीं करता है।
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
निष्पादन योजना संग्रह अक्षम होने, बफर पूल में सभी आवश्यक पृष्ठ, और रनों के बीच समाप्ति तिथि मानों को रीसेट नहीं करने के साथ, यह क्वेरी आमतौर पर लगभग 5700ms में निष्पादित होती है मेरे लैपटाप पर। आँकड़े IO आउटपुट इस प्रकार है:(आगे पढ़ें और LOB काउंटर शून्य थे, और अंतरिक्ष कारणों से छोड़े गए हैं)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
स्कैन गिनती यह दर्शाती है कि कितनी बार स्कैनिंग ऑपरेशन शुरू किया गया था। उदाहरण तालिका के लिए, यह क्लस्टर इंडेक्स स्कैन के लिए 1 है, और 999,034 हर बार सहसंबद्ध क्लस्टर इंडेक्स सीक रिबाउंड होने पर। ईगर स्पूल द्वारा उपयोग की जाने वाली कार्य तालिका में स्कैनिंग ऑपरेशन केवल एक बार शुरू हुआ है।
तार्किक पढ़ता है
आईओ आउटपुट में अधिक रोचक जानकारी तार्किक पढ़ने की संख्या है:6 मिलियन से अधिक उदाहरण तालिका के लिए, और लगभग 3 मिलियन कार्य तालिका के लिए।
उदाहरण तालिका तार्किक पठन ज्यादातर सीक और अपडेट के साथ जुड़ा हुआ है। सीक प्रत्येक पुनरावृत्ति के लिए 3 तार्किक पढ़ता है:सूचकांक के रूट, इंटरमीडिएट और लीफ स्तरों के लिए प्रत्येक 1। इसी तरह हर बार पंक्ति . पर अपडेट की लागत 3 बार पढ़ी जाती है अद्यतन किया जाता है, क्योंकि इंजन लक्ष्य पंक्ति का पता लगाने के लिए बी-ट्री के नीचे नेविगेट करता है। क्लस्टर्ड इंडेक्स स्कैन केवल कुछ हज़ार रीड्स के लिए ज़िम्मेदार है, प्रति पेज पढ़ें।
स्पूल वर्क टेबल को आंतरिक रूप से बी-ट्री के रूप में भी संरचित किया जाता है, और कई रीड्स की गणना करता है क्योंकि स्पूल अपने इनपुट का उपभोग करते समय इन्सर्ट स्थिति का पता लगाता है। शायद काउंटर-सहज रूप से, स्पूल कोई तार्किक पठन नहीं गिनाता है जबकि इसे क्लस्टर्ड इंडेक्स अपडेट को चलाने के लिए पढ़ा जा रहा है। यह केवल कार्यान्वयन का एक परिणाम है:जब भी कोड BPool::Get को निष्पादित करता है तो एक तार्किक पठन की गणना की जाती है तरीका। स्पूल को लिखना सूचकांक के प्रत्येक स्तर पर इस पद्धति को कॉल करता है; स्पूल से पढ़ना एक अलग कोड पथ का अनुसरण करता है जो BPool::Get . को कॉल नहीं करता है बिल्कुल।
यह भी ध्यान दें कि आँकड़ा IO आउटपुट उदाहरण तालिका के लिए एकल कुल रिपोर्ट करता है, इस तथ्य के बावजूद कि इसे निष्पादन योजना (स्कैन, सीक और अपडेट) में तीन अलग-अलग पुनरावृत्तियों द्वारा एक्सेस किया जाता है। यह बाद वाला तथ्य तार्किक पठन को पुनरावृत्त करने के लिए कठिन बनाता है जो उन्हें पैदा करता है। मुझे उम्मीद है कि इस सीमा को उत्पाद के भविष्य के संस्करण में संबोधित किया जाएगा।
2. पंक्ति संख्याओं का उपयोग करके अपडेट करें
अद्यतन क्वेरी को व्यक्त करने का एक अन्य तरीका प्रति आईडी पंक्तियों को क्रमांकित करना और शामिल होना शामिल है:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); निष्पादन के बाद की योजना इस प्रकार है:
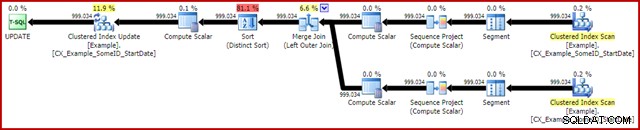
यह क्वेरी आमतौर पर 2950ms . में चलती है मेरे लैपटॉप पर, जो मूल अद्यतन विवरण के लिए देखे गए 5700ms (उसी परिस्थितियों में) के साथ अनुकूल रूप से तुलना करता है। आँकड़े IO आउटपुट है:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
यह उदाहरण तालिका के लिए शुरू किए गए दो स्कैन दिखाता है (प्रत्येक क्लस्टर इंडेक्स स्कैन इटरेटर के लिए एक)। तार्किक पठन फिर से उन सभी पुनरावृत्तियों पर एक समग्र है जो इस तालिका को क्वेरी योजना में एक्सेस करते हैं। पहले की तरह, ब्रेकडाउन की कमी से यह निर्धारित करना असंभव हो जाता है कि कौन सा इटरेटर (दो स्कैन और अपडेट में से) 3 मिलियन रीड्स के लिए जिम्मेदार था।
फिर भी, मैं आपको बता सकता हूं कि क्लस्टर्ड इंडेक्स स्कैन में से प्रत्येक में केवल कुछ हज़ार तार्किक रीड होते हैं। तार्किक पठन का विशाल बहुमत क्लस्टर्ड इंडेक्स अपडेट के कारण होता है, जो प्रत्येक पंक्ति के लिए अद्यतन स्थिति खोजने के लिए इंडेक्स बी-ट्री को नीचे नेविगेट करता है। इसके लिए आपको फिलहाल मेरी बात माननी होगी; अधिक स्पष्टीकरण शीघ्र ही आने वाला है।
नकारात्मक पक्ष
क्वेरी के इस रूप के लिए यह अच्छी खबर का अंत है। यह मूल की तुलना में बहुत बेहतर प्रदर्शन करता है, लेकिन कई अन्य कारणों से यह बहुत कम संतोषजनक है। मुख्य समस्या एक अनुकूलक सीमा के कारण होती है, जिसका अर्थ यह है कि यह नहीं पहचानता है कि पंक्ति क्रमांकन ऑपरेशन प्रत्येक पंक्ति के लिए कुछ आईडी विभाजन के भीतर एक अद्वितीय संख्या उत्पन्न करता है।
यह सरल तथ्य कई अवांछनीय परिणामों की ओर ले जाता है। एक बात के लिए, मर्ज जॉइन को कई-से-अनेक जॉइन मोड में चलाने के लिए कॉन्फ़िगर किया गया है। यही कारण है कि आँकड़ों में (अप्रयुक्त) कार्य तालिका IO (कई-से-कई मर्ज के लिए डुप्लिकेट जॉइन की रिवाइंड के लिए कार्य तालिका की आवश्यकता होती है)। कई-से-अनेक जॉइन की अपेक्षा करने का अर्थ यह भी है कि जॉइन आउटपुट के लिए कार्डिनैलिटी अनुमान निराशाजनक रूप से गलत है:
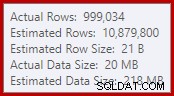
इसके परिणामस्वरूप, सॉर्ट बहुत अधिक मेमोरी ग्रांट का अनुरोध करता है। रूट नोड गुण दिखाते हैं कि सॉर्ट को 812,752 केबी मेमोरी पसंद आई होगी, हालांकि इसे प्रतिबंधित अधिकतम सर्वर मेमोरी सेटिंग (2048 एमबी) के कारण केवल 379,440 केबी दिया गया था। वास्तव में इस प्रकार ने रनटाइम पर अधिकतम 58,968 KB का उपयोग किया:
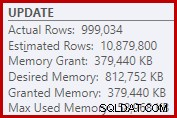
अत्यधिक स्मृति अनुदान स्मृति को अन्य उत्पादक उपयोगों से दूर कर देता है, और स्मृति उपलब्ध होने तक प्रतीक्षा करने वाले प्रश्नों को जन्म दे सकता है। कई मायनों में, अत्यधिक स्मृति अनुदान कम करके आंका जाने से अधिक एक समस्या हो सकती है।
ऑप्टिमाइज़र सीमा यह भी बताती है कि सर्वश्रेष्ठ प्रदर्शन के लिए क्वेरी पर मर्ज जॉइन संकेत क्यों आवश्यक था। इस संकेत के बिना, ऑप्टिमाइज़र गलत तरीके से आकलन करता है कि हैश जॉइन कई-से-अनेक मर्ज जॉइन की तुलना में सस्ता होगा। हैश जॉइन प्लान औसतन 3350ms में चलता है।
अंतिम नकारात्मक परिणाम के रूप में, ध्यान दें कि योजना में क्रमबद्ध एक विशिष्ट प्रकार है। अब उस सॉर्ट के कुछ कारण हैं (कम से कम इसलिए नहीं कि यह आवश्यक हैलोवीन सुरक्षा प्रदान कर सकता है) लेकिन यह केवल एक विशिष्ट है क्रमबद्ध करें क्योंकि अनुकूलक विशिष्टता की जानकारी को याद करता है। कुल मिलाकर, प्रदर्शन से परे इस निष्पादन योजना के बारे में बहुत कुछ पसंद करना मुश्किल है।
3. LEAD विश्लेषणात्मक फ़ंक्शन का उपयोग करके अपडेट करें
चूंकि यह आलेख मुख्य रूप से SQL सर्वर 2012 और बाद में लक्षित करता है, हम LEAD विश्लेषणात्मक फ़ंक्शन का उपयोग करके अद्यतन क्वेरी को स्वाभाविक रूप से व्यक्त कर सकते हैं। एक आदर्श दुनिया में, हम एक बहुत ही कॉम्पैक्ट सिंटैक्स का उपयोग कर सकते हैं जैसे:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); दुर्भाग्य से, यह कानूनी नहीं है। इसका परिणाम त्रुटि संदेश 4108 में होता है, "विंडो वाले फ़ंक्शन केवल SELECT या ORDER BY क्लॉज में दिखाई दे सकते हैं"। यह थोड़ा निराशाजनक है क्योंकि हम एक निष्पादन योजना की उम्मीद कर रहे थे जो एक स्व-जुड़ने (और संबंधित अद्यतन हैलोवीन सुरक्षा) से बच सके।
अच्छी खबर यह है कि हम अभी भी सामान्य तालिका अभिव्यक्ति या व्युत्पन्न तालिका का उपयोग करके स्वयं-जुड़ने से बच सकते हैं। वाक्य-विन्यास थोड़ा अधिक क्रियात्मक है, लेकिन विचार काफी हद तक समान है:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); निष्पादन के बाद की योजना है:

यह आमतौर पर लगभग 3400ms . में चलता है मेरे लैपटॉप पर, जो पंक्ति संख्या समाधान (2950ms) से धीमा है, लेकिन मूल (5700ms) की तुलना में अभी भी बहुत तेज़ है। एक चीज जो निष्पादन योजना से अलग है वह है सॉर्ट स्पिल (फिर से, अतिरिक्त स्पिल जानकारी SP3 में सुधार के सौजन्य से):
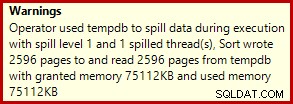
यह काफी छोटा स्पिल है, लेकिन यह अभी भी कुछ हद तक प्रदर्शन को प्रभावित कर सकता है। इसके बारे में अजीब बात यह है कि सॉर्ट करने के लिए इनपुट अनुमान बिल्कुल सही है:
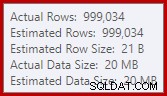
सौभाग्य से, SQL Server 2012 SP2 CU8 (और अन्य रिलीज़ - विवरण के लिए KB आलेख देखें) में इस विशिष्ट स्थिति के लिए एक "फिक्स" है। फिक्स और आवश्यक ट्रेस फ्लैग 7470 सक्षम के साथ क्वेरी चलाने का मतलब है कि सॉर्ट पर्याप्त मेमोरी का अनुरोध करता है ताकि यह सुनिश्चित हो सके कि अनुमानित इनपुट सॉर्ट आकार से अधिक नहीं होने पर यह डिस्क पर कभी नहीं फैलेगा।
बिना सॉर्ट स्पिल के लीड अपडेट क्वेरी
विविधता के लिए, नीचे दी गई फिक्स-सक्षम क्वेरी CTE के बजाय व्युत्पन्न तालिका सिंटैक्स का उपयोग करती है:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); निष्पादन के बाद की नई योजना है:

छोटे स्पिल को हटाने से प्रदर्शन में सुधार होता है 3400ms से 3250ms . आँकड़े IO आउटपुट है:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
यदि आप पंक्ति क्रमांकित क्वेरी के लिए तार्किक रीड्स से इसकी तुलना करते हैं, तो आप देखेंगे कि तार्किक रीड्स 3,001,808 से घटकर 2,999,455 हो गए हैं - 2,353 रीड्स का अंतर। यह एक क्लस्टर इंडेक्स स्कैन (प्रति पृष्ठ एक पढ़ा गया) को हटाने के बिल्कुल समान है।
आपको याद होगा कि मैंने उल्लेख किया था कि इन अद्यतन प्रश्नों के लिए तार्किक पढ़ने का विशाल बहुमत क्लस्टर्ड इंडेक्स अपडेट से जुड़ा हुआ है, और स्कैन "केवल कुछ हजार रीड्स" से जुड़े थे। उदाहरण तालिका के विरुद्ध एक साधारण पंक्ति-गणना क्वेरी चलाकर अब हम इसे थोड़ा और सीधे देख सकते हैं:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
IO आउटपुट पंक्ति संख्या और लीड अपडेट के बीच ठीक 2,353 तार्किक पठन अंतर दिखाता है:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
आगे सुधार?
स्पिल-फिक्स्ड लीड क्वेरी (3250ms) अभी भी डबल रो नंबरेड क्वेरी (2950ms) की तुलना में काफी धीमी है, जो थोड़ा आश्चर्यजनक हो सकता है। सहज रूप से, कोई एक स्कैन और विश्लेषणात्मक फ़ंक्शन (विंडो स्पूल और स्ट्रीम एग्रीगेट) के दो स्कैन, पंक्ति क्रमांकन के दो सेट और एक जॉइन की तुलना में तेज़ होने की उम्मीद कर सकता है।
भले ही, लीड क्वेरी निष्पादन योजना से बाहर निकलने वाली चीज सॉर्ट है। यह पंक्ति-क्रमांकित क्वेरी में भी मौजूद था, जहां इसने हैलोवीन प्रोटेक्शन के साथ-साथ क्लस्टर इंडेक्स अपडेट (जिसमें DMLRequestSort प्रॉपर्टी सेट है) के लिए एक अनुकूलित सॉर्ट ऑर्डर का योगदान दिया था।
बात यह है कि लीड क्वेरी प्लान में यह सॉर्ट पूरी तरह से अनावश्यक है। हैलोवीन प्रोटेक्शन के लिए इसकी जरूरत नहीं है क्योंकि सेल्फ-जॉइन चला गया है। ऑप्टिमाइज़्ड इंसर्ट सॉर्ट ऑर्डर के लिए इसकी आवश्यकता नहीं है:पंक्तियों को क्लस्टर्ड की ऑर्डर में पढ़ा जा रहा है, और उस ऑर्डर को डिस्टर्ब करने की योजना में कुछ भी नहीं है। वास्तविक समस्या को क्रमबद्ध गुणों को देखकर देखा जा सकता है:

वहां अनुभाग द्वारा आदेश पर ध्यान दें। सॉर्ट कुछ आईडी और स्टार्टडेट (क्लस्टर इंडेक्स कुंजी) द्वारा ऑर्डर कर रहा है, लेकिन [यूनिक 1002] द्वारा भी, जो कि यूनीकिफायर है। यह क्लस्टर्ड इंडेक्स को अद्वितीय घोषित नहीं करने का परिणाम है, भले ही हमने डेटा जनसंख्या क्वेरी में कदम उठाए ताकि यह सुनिश्चित किया जा सके कि कुछ आईडी और स्टार्टडेट का संयोजन वास्तव में अद्वितीय होगा। (यह जानबूझकर किया गया था, इसलिए मैं इस बारे में बात कर सकता था।)
फिर भी, यह एक सीमा है। क्लस्टर्ड इंडेक्स से पंक्तियों को क्रम में पढ़ा जाता है, और आवश्यक आंतरिक गारंटी मौजूद होती है ताकि ऑप्टिमाइज़र सुरक्षित रूप से इस सॉर्ट से बच सके। यह केवल एक निरीक्षण है कि अनुकूलक यह नहीं पहचानता है कि आने वाली धारा को यूनीकिफायर के साथ-साथ कुछ आईडी और स्टार्टडेट द्वारा क्रमबद्ध किया गया है। यह मानता है कि (कुछ आईडी, स्टार्टडेट) ऑर्डर संरक्षित किया जा सकता है, लेकिन नहीं (कुछ आईडी, स्टार्टडेट, यूनीकिफायर)। फिर से, मुझे आशा है कि इसे भविष्य के संस्करण में संबोधित किया जाएगा।
इसके आसपास काम करने के लिए, हम वह कर सकते हैं जो हमें पहले करना चाहिए था:क्लस्टर्ड इंडेक्स को अद्वितीय के रूप में बनाएं:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
मैं इसे पाठक के लिए यह दिखाने के लिए एक अभ्यास के रूप में छोड़ दूंगा कि पहले दो (गैर-लीड) प्रश्न इस अनुक्रमण परिवर्तन से लाभान्वित नहीं होते हैं (विशुद्ध रूप से अंतरिक्ष कारणों से छोड़े गए - कवर करने के लिए बहुत कुछ है)।
लीड अपडेट क्वेरी का अंतिम रूप
अद्वितीय . के साथ क्लस्टर इंडेक्स जगह पर है, ठीक वही LEAD क्वेरी (CTE या व्युत्पन्न तालिका जैसा कि आप कृपया) अनुमानित (पूर्व-निष्पादन) योजना तैयार करते हैं जिसकी हम अपेक्षा करते हैं:

यह काफी इष्टतम लगता है। बीच में कम से कम ऑपरेटरों के साथ एक सिंगल रीड एंड राइट ऑपरेशन। निश्चित रूप से, यह अनावश्यक सॉर्ट के साथ पिछले संस्करण की तुलना में काफी बेहतर लगता है, जिसे एक बार परिहार्य स्पिल हटा दिए जाने के बाद 3250ms में निष्पादित किया गया था (स्मृति अनुदान को थोड़ा बढ़ाने की कीमत पर)।
निष्पादन के बाद (वास्तविक) योजना लगभग पूर्व-निष्पादन योजना के समान ही है:

विंडो स्पूल के आउटपुट को छोड़कर, जो 2 पंक्तियों से बंद है, सभी अनुमान बिल्कुल सही हैं। आंकड़े IO की जानकारी ठीक वैसी ही है जैसी कि सॉर्ट को हटाए जाने से पहले थी, जैसा कि आप उम्मीद करेंगे:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
संक्षेप में संक्षेप में, इस नई योजना और तत्काल पिछली योजना के बीच एकमात्र स्पष्ट अंतर यह है कि सॉर्ट (लगभग 80% की अनुमानित लागत योगदान के साथ) को हटा दिया गया है।
तब यह जानकर आश्चर्य हो सकता है कि नई क्वेरी - बिना सॉर्ट के - 5000ms में निष्पादित होती है . यह सॉर्ट के साथ 3250ms से बहुत खराब है, और लगभग 5700ms मूल लूप क्वेरी में शामिल होने तक। डबल रो नंबरिंग सॉल्यूशन अभी भी 2950ms पर बहुत आगे है।
स्पष्टीकरण
स्पष्टीकरण कुछ गूढ़ है और नवीनतम क्वेरी के लिए कुंडी को संभालने के तरीके से संबंधित है। हम इस प्रभाव को कई तरीकों से दिखा सकते हैं, लेकिन सबसे आसान तरीका शायद डीएमवी का उपयोग करके प्रतीक्षा और कुंडी के आंकड़ों को देखना है:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; जब संकुल अनुक्रमणिका अद्वितीय नहीं है, और योजना में एक क्रमबद्ध है, तो कोई महत्वपूर्ण प्रतीक्षा नहीं है, बस कुछ PAGEIOLATCH_UP प्रतीक्षारत हैं और अपेक्षित SOS_SCHEDULER_YIELDs हैं।
जब क्लस्टर्ड इंडेक्स अद्वितीय होता है, और सॉर्ट को हटा दिया जाता है, तो प्रतीक्षा होती है:
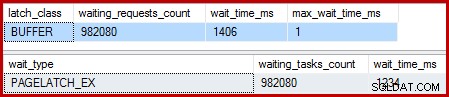
वहाँ 982,080 अनन्य पृष्ठ कुंडी हैं, एक प्रतीक्षा समय के साथ जो अतिरिक्त निष्पादन समय के बारे में बहुत कुछ बताता है। जोर देने के लिए, यह प्रति पंक्ति लगभग एक कुंडी प्रतीक्षा अद्यतन है! हम कुंडी प्रति पंक्ति परिवर्तन की अपेक्षा कर सकते हैं, लेकिन कुंडी नहीं प्रतीक्षा करें , खासकर जब परीक्षण क्वेरी उदाहरण पर एकमात्र गतिविधि है। कुंडी प्रतीक्षा कम है, लेकिन उनमें से बहुत सारे हैं।
आलसी कुंडी
डिबगर और विश्लेषक संलग्न के साथ क्वेरी निष्पादन के बाद, स्पष्टीकरण इस प्रकार है।
क्लस्टर्ड इंडेक्स स्कैन आलसी कुंडी . का उपयोग करता है - एक अनुकूलन जिसका अर्थ है कि लैच केवल तभी जारी किए जाते हैं जब किसी अन्य थ्रेड को पृष्ठ तक पहुंच की आवश्यकता होती है। आम तौर पर, कुंडी पढ़ने या लिखने के तुरंत बाद छोड़ दी जाती है। आलसी कुंडी उस मामले को अनुकूलित करती है जहां एक पूरे पृष्ठ को स्कैन करने से अन्यथा प्रत्येक पंक्ति के लिए एक ही पृष्ठ कुंडी प्राप्त हो जाती है और जारी हो जाती है। जब बिना किसी विवाद के आलसी लैचिंग का उपयोग किया जाता है, तो पूरे पृष्ठ के लिए केवल एक ही कुंडी ली जाती है।
समस्या यह है कि निष्पादन योजना की पाइपलाइन प्रकृति (कोई अवरुद्ध ऑपरेटर नहीं) का अर्थ है कि लिखने के साथ ओवरलैप पढ़ता है। जब क्लस्टर्ड इंडेक्स अपडेट एक पंक्ति को संशोधित करने के लिए EX लैच प्राप्त करने का प्रयास करता है, तो यह लगभग हमेशा पाता है कि पेज पहले से ही SH (क्लस्टर इंडेक्स स्कैन द्वारा लिया गया आलसी लैच) है। इस स्थिति के परिणामस्वरूप कुंडी प्रतीक्षा होती है।
शेड्यूलर पर अगले रन करने योग्य आइटम पर प्रतीक्षा करने और स्विच करने की तैयारी के हिस्से के रूप में, कोड किसी भी आलसी कुंडी को छोड़ने के लिए सावधान है। आलसी कुंडी को छोड़ना पहले योग्य वेटर का संकेत देता है, जो स्वयं होता है। तो, हमारे पास अजीब स्थिति है जहां एक धागा खुद को अवरुद्ध करता है, अपनी आलसी कुंडी को छोड़ता है, फिर खुद को संकेत देता है कि यह फिर से चलने योग्य है। धागा फिर से उठाता है, और जारी रहता है, लेकिन सब कुछ बर्बाद होने के बाद ही निलंबित और स्विच, सिग्नल और फिर से शुरू करने का काम किया गया है। जैसा कि मैंने पहले कहा, प्रतीक्षा कम है, लेकिन बहुत हैं।
सभी के लिए मुझे पता है, घटनाओं का यह अजीब क्रम डिजाइन द्वारा और अच्छे आंतरिक कारणों से है। फिर भी, इस तथ्य से दूर नहीं है कि यहां प्रदर्शन पर इसका काफी नाटकीय प्रभाव पड़ा है। मैं इस बारे में कुछ पूछताछ करूंगा और अगर कोई सार्वजनिक बयान देना है तो मैं लेख को अपडेट करूंगा। इस बीच, पाइपलाइन की अद्यतन क्वेरी के साथ अत्यधिक सेल्फ़-लैच प्रतीक्षा कुछ देखने लायक हो सकती है, हालांकि यह स्पष्ट नहीं है कि क्वेरी लेखक के दृष्टिकोण से इसके बारे में क्या किया जाना चाहिए।
क्या इसका मतलब यह है कि डबल रो-नंबरिंग दृष्टिकोण इस क्वेरी के लिए सबसे अच्छा है जो हम कर सकते हैं? बिलकुल नहीं।
4. मैन्युअल हेलोवीन सुरक्षा
यह आखिरी विकल्प लग सकता है और थोड़ा पागल लग सकता है। व्यापक विचार यह है कि तालिका चर में परिवर्तन करने के लिए आवश्यक सभी जानकारी लिखें, फिर अद्यतन को एक अलग चरण के रूप में निष्पादित करें।
बेहतर विवरण की कमी के लिए, मैं इसे "मैनुअल एचपी" दृष्टिकोण कहता हूं क्योंकि यह अवधारणात्मक रूप से उस स्पूल से अपडेट चलाने से पहले सभी परिवर्तन जानकारी को ईगर टेबल स्पूल (जैसा कि पहली क्वेरी में देखा गया है) में लिखने के समान है।
वैसे भी, कोड इस प्रकार है:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); वह कोड जानबूझकर एक तालिका चर . का उपयोग करता है एक अस्थायी तालिका का उपयोग करने वाले स्वतः निर्मित आँकड़ों की लागत से बचने के लिए। यह यहां ठीक है क्योंकि मुझे अपनी इच्छित योजना का आकार पता है, और यह लागत अनुमानों या सांख्यिकीय जानकारी पर निर्भर नहीं करता है।
तालिका चर (एक ट्रेस ध्वज के बिना) का एकमात्र नकारात्मक पक्ष यह है कि अनुकूलक आमतौर पर एक पंक्ति का अनुमान लगाएगा और अद्यतन के लिए नेस्टेड लूप का चयन करेगा। इसे रोकने के लिए, मैंने मर्ज जॉइन संकेत का उपयोग किया है। फिर से, यह वास्तव में प्राप्त की जाने वाली योजना के आकार को जानने से प्रेरित है।
टेबल वैरिएबल इंसर्ट के लिए पोस्ट-निष्पादन योजना बिल्कुल वैसी ही दिखती है, जिस क्वेरी में लैच वेटिंग की समस्या थी:

इस योजना का लाभ यह है कि यह उसी तालिका को नहीं बदल रहा है जिससे वह पढ़ रहा है। कोई हेलोवीन सुरक्षा की आवश्यकता नहीं है, और कुंडी के हस्तक्षेप की कोई संभावना नहीं है। इसके अलावा, tempdb ऑब्जेक्ट्स (लॉकिंग और लॉगिंग) के लिए महत्वपूर्ण आंतरिक अनुकूलन हैं और अन्य सामान्य बल्क लोडिंग ऑप्टिमाइज़ेशन भी लागू होते हैं। याद रखें कि बल्क ऑप्टिमाइज़ेशन केवल इंसर्ट के लिए उपलब्ध हैं, अपडेट या डिलीट के लिए नहीं।
अद्यतन विवरण के लिए निष्पादन के बाद की योजना है:
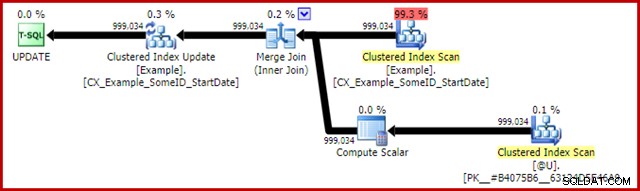
यहां मर्ज जॉइन कुशल वन-टू-मैनी प्रकार है। खास बात यह है कि यह योजना एक विशेष अनुकूलन के लिए योग्य है जिसका अर्थ है कि क्लस्टर्ड इंडेक्स स्कैन और क्लस्टर्ड इंडेक्स अपडेट एक ही रोसेट साझा करते हैं। महत्वपूर्ण परिणाम यह है कि अद्यतन को अब अद्यतन करने के लिए पंक्ति का पता लगाने की आवश्यकता नहीं है - यह पहले से ही रीड द्वारा सही ढंग से स्थित है। यह अद्यतन पर बहुत सारे तार्किक पठन (और अन्य गतिविधि) को बचाता है।
सामान्य निष्पादन योजनाओं में यह दिखाने के लिए कुछ भी नहीं है कि यह साझा रोसेट ऑप्टिमाइज़ेशन कहाँ लागू किया गया है, लेकिन अनिर्दिष्ट ट्रेस फ़्लैग 8666 को सक्षम करने से अद्यतन और स्कैन पर अतिरिक्त गुण प्रदर्शित होते हैं जो दिखाते हैं कि रोसेट साझाकरण उपयोग में है, और यह सुनिश्चित करने के लिए कदम उठाए जाते हैं कि अद्यतन सुरक्षित है हैलोवीन समस्या से।
दो प्रश्नों के लिए IO आउटपुट के आँकड़े इस प्रकार हैं:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
उदाहरण तालिका के दोनों पठन में एक स्कैन और प्रति पृष्ठ एक तार्किक पठन शामिल है (पहले सरल पंक्ति गणना क्वेरी देखें)। #B9C034B8 तालिका तालिका चर का समर्थन करने वाले आंतरिक tempdb ऑब्जेक्ट का नाम है। दोनों प्रश्नों के लिए कुल तार्किक पठन 3 * 2353 =7,059 है। कार्य तालिका विंडो स्पूल द्वारा उपयोग की जाने वाली इन-मेमोरी आंतरिक संग्रहण है।
इस क्वेरी के लिए सामान्य निष्पादन समय 2300ms . है . अंत में, हमारे पास कुछ ऐसा है जो डबल रो-नंबरिंग क्वेरी (2950ms) को पीछे छोड़ देता है, जितना कि यह असंभव लग सकता है।
अंतिम विचार
इस अद्यतन को लिखने के और भी बेहतर तरीके हो सकते हैं जो ऊपर दिए गए "मैनुअल एचपी" समाधान से भी बेहतर प्रदर्शन करते हैं। आपके हार्डवेयर और SQL सर्वर कॉन्फ़िगरेशन पर प्रदर्शन परिणाम भिन्न भी हो सकते हैं, लेकिन इनमें से कोई भी इस आलेख का मुख्य बिंदु नहीं है। इसका मतलब यह नहीं है कि मुझे बेहतर क्वेरी या प्रदर्शन तुलना देखने में कोई दिलचस्पी नहीं है - मैं हूं।
मुद्दा यह है कि निष्पादन योजनाओं में उजागर होने की तुलना में SQL सर्वर के अंदर बहुत अधिक चल रहा है। उम्मीद है कि इस लंबे लेख में चर्चा की गई कुछ जानकारी कुछ लोगों के लिए दिलचस्प या उपयोगी भी होगी।
प्रदर्शन की अपेक्षाएं रखना और यह जानना अच्छा है कि कौन से योजना आकार और गुण आम तौर पर फायदेमंद होते हैं। उस तरह का अनुभव और ज्ञान आपको 99% या अधिक प्रश्नों के लिए अच्छी तरह से सेवा देगा जो आपको कभी भी ट्यून करने के लिए कहा जाएगा। कभी-कभी, हालांकि, यह देखने के लिए कि क्या होता है, और उन अपेक्षाओं को मान्य करने के लिए थोड़ा अजीब या असामान्य कुछ करने की कोशिश करना अच्छा है।