पिछले महीने में मैंने ऐसे कई ग्राहकों के साथ काम किया है जिनके OLTP वर्कलोड से जुड़े कॉलम-साइड अंतर्निहित रूपांतरण समस्याएं थीं। दो मौकों पर, कॉलम-साइड निहित रूपांतरणों का संचित प्रभाव SQL सर्वर की समीक्षा के लिए समग्र प्रदर्शन समस्या का अंतर्निहित कारण था, और दुर्भाग्य से कोई जादुई सेटिंग या कॉन्फ़िगरेशन विकल्प नहीं है जिसे हम स्थिति को सुधारने के लिए बदल सकते हैं जब यह मामला है। जबकि हम अन्य, कम लटकने वाले फलों को ठीक करने के लिए सुझाव दे सकते हैं जो समग्र रूप से प्रदर्शन को प्रभावित कर सकते हैं, कॉलम-साइड निहित रूपांतरणों का प्रभाव कुछ ऐसा है जिसे ठीक करने के लिए या तो एक स्कीमा डिज़ाइन परिवर्तन की आवश्यकता होती है, या कॉलम को रोकने के लिए एक कोड परिवर्तन की आवश्यकता होती है- वर्तमान डेटाबेस स्कीमा के विरुद्ध होने वाली साइड रूपांतरण पूरी तरह से।
क्वेरी निष्पादन के दौरान अलग-अलग डेटा प्रकारों के मूल्यों की तुलना करने वाले डेटाबेस इंजन का परिणाम अंतर्निहित रूपांतरण हैं। संभावित निहित रूपांतरणों की एक सूची जो डेटाबेस इंजन के अंदर हो सकती है, पुस्तकें ऑनलाइन विषय डेटा प्रकार रूपांतरण (डेटाबेस इंजन) में पाई जा सकती हैं। ऑपरेशन के दौरान तुलना की जा रही डेटा प्रकारों के लिए डेटा प्रकार प्राथमिकता के आधार पर निहित रूपांतरण हमेशा होते हैं। डेटा प्रकार वरीयता क्रम पुस्तकें ऑनलाइन विषय डेटा प्रकार वरीयता (Transact-SQL) में पाया जा सकता है। मैंने हाल ही में अंतर्निहित रूपांतरणों के बारे में ब्लॉग किया है जिसके परिणामस्वरूप एक इंडेक्स स्कैन होता है, और चार्ट प्रदान किए जाते हैं जिनका उपयोग सबसे अधिक समस्याग्रस्त निहित रूपांतरणों को निर्धारित करने के लिए भी किया जा सकता है।
टेस्ट सेट करना
कॉलम-साइड निहित रूपांतरणों से जुड़े प्रदर्शन ओवरहेड को प्रदर्शित करने के लिए, जिसके परिणामस्वरूप एक इंडेक्स स्कैन होता है, मैंने टेस्ट टेबल और डेटा सेट बनाने के लिए Sales.SalesOrderDetail टेबल का उपयोग करके AdventureWorks2012 डेटाबेस के खिलाफ विभिन्न परीक्षणों की एक श्रृंखला चलाई है। सबसे आम कॉलम-साइड निहित रूपांतरण जिसे मैं सलाहकार के रूप में देखता हूं, तब होता है जब कॉलम प्रकार चार या वर्कर होता है, और एप्लिकेशन कोड एक पैरामीटर पास करता है जो nchar या nvarchar है और चार या वर्कर कॉलम पर फ़िल्टर करता है। इस प्रकार के परिदृश्य का अनुकरण करने के लिए, मैंने SalesOrderDetail तालिका (SalesOrderDetail_ASCII नाम से) की एक प्रति बनाई और कैरियरट्रैकिंगनंबर कॉलम को nvarchar से varchar में बदल दिया। इसके अतिरिक्त, मैंने कैरियरट्रैकिंगनंबर कॉलम पर मूल SalesOrderDetail तालिका के साथ-साथ नई SalesOrderDetail_ASCII तालिका में एक गैर-संकुल अनुक्रमणिका जोड़ी।
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO बनाएं नई SalesOrderDetail_ASCII तालिका में 121,317 पंक्तियाँ हैं और इसका आकार 17.5MB है, और इसका उपयोग एक छोटी तालिका के ऊपरी भाग का मूल्यांकन करने के लिए किया जाएगा। मैंने अपने ब्लॉग से एनलार्जिंग द एडवेंचरवर्क्स नमूना डेटाबेस स्क्रिप्ट के एक संशोधित संस्करण का उपयोग करके दस गुना बड़ी एक तालिका भी बनाई है, जिसमें 1,334,487 पंक्तियां हैं और आकार में 190 एमबी है। इसके लिए परीक्षण सर्वर 4GB RAM के साथ वही 4 vCPU VM है, जो सर्विस पैक 1 और संचयी अद्यतन 3 के साथ Windows Server 2008 R2 और SQL Server 2012 चला रहा है, जिसका मैंने पिछले लेखों में उपयोग किया है, इसलिए तालिकाएँ पूरी तरह से मेमोरी में फिट होंगी , चल रहे परीक्षणों को प्रभावित करने से डिस्क I/O ओवरहेड को समाप्त करना।
परीक्षण कार्यभार पावरशेल स्क्रिप्ट की एक श्रृंखला का उपयोग करके उत्पन्न किया गया था जो एक ArrayList बनाने वाली SalesOrderDetail तालिका से कैरियरट्रैकिंग नंबर की सूची का चयन करता है, और फिर एक varchar पैरामीटर और फिर एक nvarchar पैरामीटर का उपयोग करके SalesOrderDetail_ASCII तालिका को क्वेरी करने के लिए ArrayList से एक कैरियरट्रैकिंग नंबर का यादृच्छिक रूप से चयन करता है, और फिर nvarchar पैरामीटर का उपयोग करके SalesOrderDetail तालिका को क्वेरी करने के लिए जहां कॉलम और पैरामीटर दोनों nvarchar हैं, इसकी तुलना प्रदान करने के लिए। प्रत्येक व्यक्तिगत परीक्षण निरंतर कार्यभार पर प्रदर्शन ओवरहेड को मापने की अनुमति देने के लिए 10,000 बार कथन चलाता है।
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now परीक्षणों का एक दूसरा सेट SalesOrderDetailEnlarged_ASCII और SalesOrderDetailEnlarged तालिकाओं के विरुद्ध चलाए गए थे, जो परीक्षणों के पहले सेट के रूप में परीक्षण के पहले सेट के रूप में परीक्षण के पहले सेट के रूप में तालिका में संग्रहीत डेटा का आकार समय के साथ बढ़ता है। परीक्षण का एक अंतिम सेट भी उत्पाद आईडी कॉलम का उपयोग करके int, bigint के पैरामीटर प्रकार के साथ फ़िल्टर कॉलम के रूप में SalesOrderDetail तालिका के विरुद्ध चलाया गया था, और उसके बाद अंतर्निहित रूपांतरणों के ऊपरी भाग की तुलना प्रदान करने के लिए छोटा होता है जिसके परिणामस्वरूप अनुक्रमणिका स्कैन नहीं होता है तुलना के लिए।
नोट:आगे के मूल्यांकन और तुलना के लिए निहित रूपांतरण परीक्षणों के पुनरुत्पादन की अनुमति देने के लिए सभी स्क्रिप्ट इस आलेख से जुड़ी हुई हैं।
परीक्षा परिणाम
प्रत्येक परीक्षण निष्पादन के दौरान, प्रदर्शन मॉनिटर को एक डेटा कलेक्टर सेट चलाने के लिए कॉन्फ़िगर किया गया था जिसमें प्रोसेसर\% प्रोसेसर समय और SQL सर्वर शामिल था:प्रत्येक परीक्षण के लिए प्रदर्शन ओवरहेड को ट्रैक करने के लिए SQLStatisitics\Batch Requests/sec काउंटर। इसके अतिरिक्त, प्रत्येक परीक्षण के लिए औसत अवधि, cpu_time, और तार्किक पठन को ट्रैक करने की अनुमति देने के लिए rpc_completed ईवेंट को ट्रैक करने के लिए विस्तारित ईवेंट को कॉन्फ़िगर किया गया है।
स्माल टेबल कैरियरट्रैकिंगनंबर परिणाम
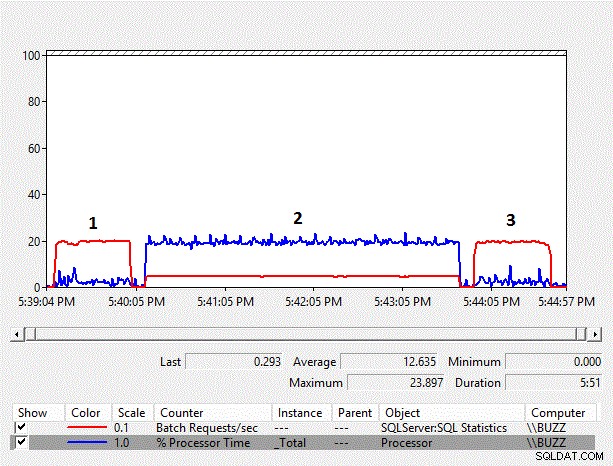
चित्र 1 - काउंटरों का प्रदर्शन मॉनिटर चार्ट
| टेस्ट आईडी | कॉलम डेटा प्रकार | पैरामीटर डेटा प्रकार | औसत % प्रोसेसर समय | औसत बैच अनुरोध/सेकंड | अवधि h:mm:ss |
|---|---|---|---|---|---|
| 1 | वर्चर | वर्चर | 2.5 | 192.3 | 0:00:51 |
| 2 | वर्चर | नवरचर | 19.4 | 46.7 | 0:03:33 |
| 3 | नवरचर | नवरचर | 2.6 | 192.3 | 0:00:51 |
तालिका 2 - प्रदर्शन मॉनिटर डेटा औसत
परिणामों से, हम देख सकते हैं कि कॉलम-साइड वर्चर से nvarchar में निहित रूपांतरण और परिणामी इंडेक्स स्कैन का कार्यभार के प्रदर्शन पर महत्वपूर्ण प्रभाव पड़ता है। कॉलम-साइड इंपैक्ट कन्वर्जन टेस्ट (टेस्टआईडी =2) के लिए औसत% प्रोसेसर समय अन्य परीक्षणों की तुलना में लगभग दस गुना अधिक है, जहां कॉलम-साइड निहित रूपांतरण, जिसके परिणामस्वरूप एक इंडेक्स स्कैन नहीं हुआ था। इसके अतिरिक्त, कॉलम-साइड निहित रूपांतरण परीक्षण के लिए औसत बैच अनुरोध/सेकंड अन्य परीक्षणों के केवल 25% से कम था। परीक्षणों की अवधि जहां निहित रूपांतरण नहीं हुआ, दोनों में 51 सेकंड लगे, भले ही डेटा को nvarchar डेटा प्रकार का उपयोग करके परीक्षण संख्या 3 में nvarchar के रूप में संग्रहीत किया गया था, जिसमें दो बार संग्रहण स्थान की आवश्यकता होती है। यह अपेक्षित है क्योंकि तालिका अभी भी बफ़र पूल से छोटी है।
| टेस्ट आईडी | औसत cpu_time (µs) | औसत अवधि (µs) | औसत तार्किक_पढ़ें |
|---|---|---|---|
| 1 | 40.7 | 154.9 | 51.6 |
| 2 | 15,640.8 | 15,760.0 | 385.6 |
| 3 | 45.3 | 169.7 | 52.7 |
तालिका 3 – विस्तारित ईवेंट औसत
विस्तारित ईवेंट में rpc_completed ईवेंट द्वारा एकत्र किए गए डेटा से पता चलता है कि औसत cpu_time, अवधि, और लॉजिकल रीड्स उन क्वेरी से जुड़े हैं जो कॉलम-साइड इंपैक्ट रूपांतरण नहीं करते हैं, मोटे तौर पर समतुल्य हैं, जहां कॉलम-साइड इंप्लिट रूपांतरण एक महत्वपूर्ण CPU लेता है ओवरहेड, साथ ही लंबी औसत अवधि के साथ काफी अधिक तार्किक रीडिंग।
विस्तारित टेबल कैरियरट्रैकिंगनंबर परिणाम
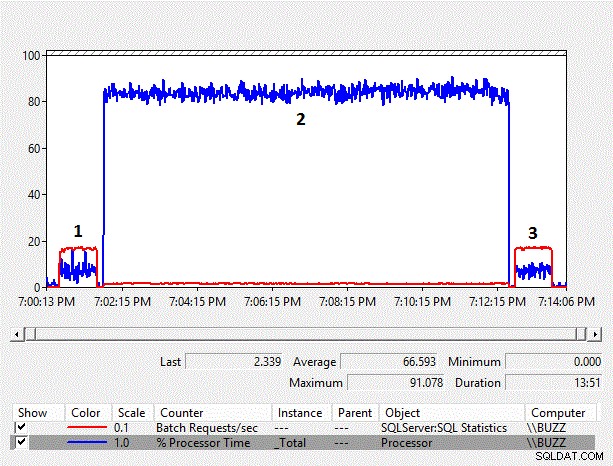
चित्र 4 - काउंटरों का प्रदर्शन मॉनिटर चार्ट
| टेस्ट आईडी | कॉलम डेटा प्रकार | पैरामीटर डेटा प्रकार | औसत % प्रोसेसर समय | औसत बैच अनुरोध/सेकंड | अवधि h:mm:ss |
|---|---|---|---|---|---|
| 1 | वर्चर | वर्चर | 7.2 | 164.0 | 0:01:00 |
| 2 | वर्चर | नवरचर | 83.8 | 15.4 | 0:10:49 |
| 3 | नवरचर | नवरचर | 7.0 | 166.7 | 0:01:00 |
तालिका 5 - प्रदर्शन मॉनिटर डेटा औसत
जैसे-जैसे डेटा का आकार बढ़ता है, कॉलम-साइड निहित रूपांतरण का प्रदर्शन ओवरहेड भी बढ़ता है। कॉलम-साइड निहित रूपांतरण परीक्षण (टेस्टआईडी =2) के लिए औसत% प्रोसेसर समय, फिर से, अन्य परीक्षणों से लगभग दस गुना अधिक है, जहां कॉलम-साइड निहित रूपांतरण के परिणामस्वरूप इंडेक्स स्कैन नहीं हुआ था। इसके अतिरिक्त, कॉलम-साइड निहित रूपांतरण परीक्षण के लिए औसत बैच अनुरोध/सेकंड अन्य परीक्षणों के केवल 10% से कम था। उन परीक्षणों की अवधि जहां निहित रूपांतरण नहीं हुए, दोनों में एक मिनट का समय लगा, जबकि कॉलम-साइड निहित रूपांतरण परीक्षण को निष्पादित करने के लिए लगभग ग्यारह मिनट की आवश्यकता थी।
| टेस्ट आईडी | औसत cpu_time (µs) | औसत अवधि (µs) | औसत तार्किक_पढ़ें |
|---|---|---|---|
| 1 | 728.5 | 1,036.5 | 569.6 |
| 2 | 214,174.6 | 59,519.1 | 4,358.2 |
| 3 | 821.5 | 1,032.4 | 553.5 |
तालिका 6 – विस्तारित ईवेंट औसत
विस्तारित ईवेंट परिणाम वास्तव में कार्यभार के लिए कॉलम-साइड निहित रूपांतरणों के कारण प्रदर्शन ओवरहेड दिखाना शुरू करते हैं। प्रति निष्पादन औसत cpu_time 214ms से अधिक हो जाता है और उन कथनों के लिए cpu_time से 200 गुना अधिक है जिनमें कॉलम-साइड निहित रूपांतरण नहीं हैं। यह अवधि उन बयानों से भी लगभग 60 गुना अधिक है जिनमें कॉलम-साइड निहित रूपांतरण नहीं हैं।
सारांश
जैसे-जैसे डेटा का आकार बढ़ता जा रहा है, कॉलम-साइड निहित रूपांतरणों से जुड़ा ओवरहेड भी बढ़ता रहेगा, जिसके परिणामस्वरूप वर्कलोड के लिए एक इंडेक्स स्कैन होता है, और याद रखने वाली महत्वपूर्ण बात यह है कि किसी बिंदु पर हार्डवेयर की कोई मात्रा नहीं होती है। प्रदर्शन ओवरहेड का सामना करने में सक्षम होंगे। जब एक अच्छा डेटाबेस स्कीमा डिज़ाइन मौजूद होता है, और डेवलपर्स अच्छी एप्लिकेशन कोडिंग तकनीकों का पालन करते हैं, तो निहित रूपांतरण एक आसान चीज़ है। उन स्थितियों में जहां एप्लिकेशन कोडिंग प्रथाओं के परिणामस्वरूप पैरामीटराइजेशन होता है जो nvarchar पैरामीटराइजेशन का लाभ उठाता है, डेटाबेस स्कीमा डिज़ाइन को क्वेरी पैरामीटराइज़ेशन से मिलान करना डेटाबेस डिज़ाइन में varchar कॉलम का उपयोग करने और कॉलम-साइड निहित रूपांतरण से प्रदर्शन ओवरहेड लगाने से बेहतर है।
डेमो स्क्रिप्ट डाउनलोड करें:Implicit_Conversion_Tests.zip (5 KB)