एक निष्पादन योजना की गुणवत्ता प्रत्येक योजना ऑपरेटर द्वारा आउटपुट की अनुमानित संख्या की सटीकता पर अत्यधिक निर्भर है। यदि पंक्तियों की अनुमानित संख्या पंक्तियों की वास्तविक संख्या से महत्वपूर्ण रूप से विषम है, तो यह क्वेरी की निष्पादन योजना की गुणवत्ता पर महत्वपूर्ण प्रभाव डाल सकती है। खराब योजना गुणवत्ता अत्यधिक I/O, फुलाए हुए CPU, स्मृति दबाव, घटी हुई थ्रूपुट और समग्र संगामिति को कम करने के लिए जिम्मेदार हो सकती है।
"प्लान क्वालिटी" द्वारा - मैं SQL सर्वर द्वारा एक निष्पादन योजना तैयार करने के बारे में बात कर रहा हूं जिसके परिणामस्वरूप भौतिक ऑपरेटर विकल्प हैं जो डेटा की वर्तमान स्थिति को दर्शाते हैं। सटीक डेटा के आधार पर ऐसे निर्णय लेने से, इस बात की बेहतर संभावना है कि क्वेरी ठीक से प्रदर्शन करेगी। कार्डिनैलिटी अनुमान मूल्यों का उपयोग ऑपरेटर लागत के लिए इनपुट के रूप में किया जाता है, और जब मूल्य वास्तविकता से बहुत दूर होते हैं, तो निष्पादन योजना पर नकारात्मक प्रभाव स्पष्ट किया जा सकता है। इन अनुमानों को क्वेरी से जुड़े विभिन्न लागत मॉडल को खिलाया जाता है, और खराब पंक्ति अनुमान इंडेक्स चयन, तलाश बनाम स्कैन संचालन, समानांतर बनाम सीरियल निष्पादन, एल्गोरिदम चयन में शामिल होने, आंतरिक बनाम बाहरी भौतिक जुड़ाव सहित विभिन्न निर्णयों को प्रभावित कर सकते हैं। चयन (जैसे बिल्ड बनाम प्रोब), स्पूल जनरेशन, बुकमार्क लुकअप बनाम फुल क्लस्टर्ड या हीप टेबल एक्सेस, स्ट्रीम या हैश एग्रीगेट चयन, और डेटा संशोधन एक विस्तृत या संकीर्ण योजना का उपयोग करता है या नहीं।
उदाहरण के तौर पर, मान लें कि आपके पास निम्न SELECT है क्वेरी (क्रेडिट डेटाबेस का उपयोग करके):
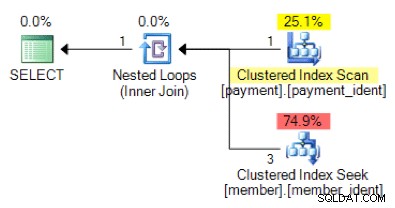
चुनेंक्वेरी लॉजिक के आधार पर, निम्न योजना आकार क्या आप देखने की उम्मीद करेंगे?
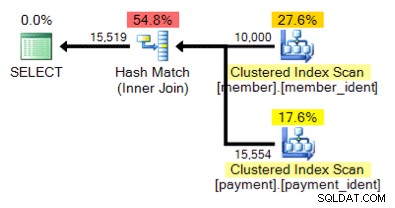
और इस वैकल्पिक योजना के बारे में क्या, जहां नेस्टेड लूप के बजाय हमारे पास हैश मैच है?
"सही" उत्तर कुछ अन्य कारकों पर निर्भर है - लेकिन एक प्रमुख कारक प्रत्येक तालिका में पंक्तियों की संख्या है। कुछ मामलों में, एक फिजिकल जॉइन एल्गोरिथम दूसरे की तुलना में अधिक उपयुक्त होता है - और यदि प्रारंभिक कार्डिनैलिटी अनुमान अनुमान सही नहीं हैं, तो हो सकता है कि आपकी क्वेरी गैर-इष्टतम दृष्टिकोण का उपयोग कर रही हो।
पहचान करना कार्डिनैलिटी अनुमान के मुद्दे अपेक्षाकृत सरल हैं। यदि आपके पास वास्तविक निष्पादन योजना है, तो आप ऑपरेटरों के लिए अनुमानित बनाम वास्तविक पंक्ति गणना मानों की तुलना कर सकते हैं और स्क्यू की तलाश कर सकते हैं। SQL सेंट्री प्लान एक्सप्लोरर आपको एक ही प्लान ट्री टैब में सभी ऑपरेटरों के लिए वास्तविक बनाम अनुमानित पंक्तियों को देखने की अनुमति देकर इस कार्य को सरल बनाता है बनाम ग्राफिकल प्लान में अलग-अलग ऑपरेटरों पर होवर करने के लिए:
अब, स्क्यूज़ का परिणाम हमेशा खराब गुणवत्ता वाली योजनाओं में नहीं होता है, लेकिन यदि आपको किसी क्वेरी के साथ प्रदर्शन संबंधी समस्याएँ आ रही हैं और आपको योजना में ऐसी विषमताएँ दिखाई देती हैं, तो यह एक ऐसा क्षेत्र है जो आगे की जाँच के योग्य है।
कार्डिनैलिटी अनुमान के मुद्दों की पहचान अपेक्षाकृत सरल है, लेकिन समाधान अक्सर नहीं होता है। कार्डिनैलिटी अनुमान के मुद्दे क्यों हो सकते हैं, इसके कई मूल कारण हैं, और मैं इस पोस्ट में दस अधिक सामान्य कारणों को शामिल करूंगा।
अनुपलब्ध या पुराने आंकड़े
कार्डिनैलिटी अनुमान के मुद्दों के सभी कारणों में से, यह वही है जिसकी आपको उम्मीद . है देखने के लिए, क्योंकि इसे संबोधित करना अक्सर आसान होता है। इस परिदृश्य में, आपके आँकड़े या तो अनुपलब्ध हैं या पुराने हैं। आपके पास स्वचालित आंकड़े निर्माण और अपडेट अक्षम करने के लिए डेटाबेस विकल्प हो सकते हैं, विशिष्ट आंकड़ों के लिए "कोई पुनर्गणना नहीं" सक्षम है, या आपके पास इतनी बड़ी तालिकाएं हैं कि आपके स्वचालित आंकड़े अपडेट अक्सर पर्याप्त नहीं हो रहे हैं।
नमूना संबंधी समस्याएं
यह हो सकता है कि आँकड़ों के हिस्टोग्राम की सटीकता अपर्याप्त हो - उदाहरण के लिए, यदि आपके पास महत्वपूर्ण और/या लगातार डेटा स्क्यू के साथ एक बहुत बड़ी तालिका है। आपको अपना नमूना डिफ़ॉल्ट से बदलने की आवश्यकता हो सकती है या यदि वह भी मदद नहीं करता है - अलग-अलग तालिकाओं, फ़िल्टर किए गए आंकड़ों या फ़िल्टर किए गए अनुक्रमणिका का उपयोग करके जांच करें।
छिपे हुए कॉलम सहसंबंध
क्वेरी ऑप्टिमाइज़र मानता है कि एक ही तालिका में कॉलम स्वतंत्र हैं। उदाहरण के लिए, यदि आपके पास एक शहर और राज्य का कॉलम है, तो हम सहज रूप से जान सकते हैं कि ये दो कॉलम सहसंबद्ध हैं, लेकिन SQL सर्वर इसे तब तक नहीं समझता है जब तक कि हम इसे संबद्ध मल्टी-कॉलम इंडेक्स या मैन्युअल रूप से बनाए गए मल्टी-कॉलम के साथ मदद नहीं करते हैं। स्तंभ आँकड़े। अनुकूलक को सहसंबंध के साथ मदद किए बिना, आपके विधेय की चयनात्मकता अतिरंजित हो सकती है।
नीचे दो सहसंबद्ध विधेय का उदाहरण दिया गया है:
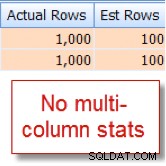
अंतिम नाम चुनें, पहला नाम dbo.member से जहां शहर ='मिनियापोलिस' और State_prov - 'MN';मुझे पता चला है कि हमारी 10,000 पंक्ति का 10%
memberतालिका इस संयोजन के लिए योग्य है, लेकिन क्वेरी अनुकूलक अनुमान लगा रहा है कि यह 10,000 पंक्तियों में से 1% है:
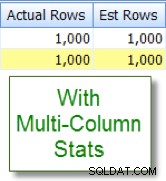
अब इसकी तुलना उस उपयुक्त अनुमान से करें जो मुझे बहु-स्तंभ आँकड़े जोड़ने के बाद दिखाई देता है:
इंट्रा-टेबल कॉलम तुलना
समान तालिका में स्तंभों की तुलना करते समय कार्डिनैलिटी अनुमान संबंधी समस्याएँ उत्पन्न हो सकती हैं। यह एक जाना - माना मुद्दा है। यदि आपको ऐसा करना है, तो आप इसके बजाय गणना किए गए कॉलम का उपयोग करके या स्वयं-जुड़ने या सामान्य तालिका अभिव्यक्तियों का उपयोग करने के लिए क्वेरी को फिर से लिखकर कॉलम तुलनाओं के कार्डिनैलिटी अनुमानों में सुधार कर सकते हैं।
टेबल वेरिएबल उपयोग
तालिका चर का अधिक उपयोग करना? तालिका चर "1" का कार्डिनैलिटी अनुमान दिखाते हैं - जो कि केवल कुछ पंक्तियों के लिए कोई समस्या नहीं हो सकती है, लेकिन बड़े या अस्थिर परिणाम सेट क्वेरी योजना की गुणवत्ता को महत्वपूर्ण रूप से प्रभावित कर सकते हैं। नीचे एक ऑपरेटर के
@chargeसे वास्तविक 1,600,000 पंक्तियों की तुलना में 1 पंक्ति के अनुमान का स्क्रीनशॉट है तालिका चर:
यदि यह आपका मूल कारण है, तो आपको अस्थायी टेबल और जहां संभव हो वहां स्थायी स्टेजिंग टेबल जैसे विकल्पों का पता लगाने की सलाह दी जाएगी।
स्केलर और MSTV UDFs
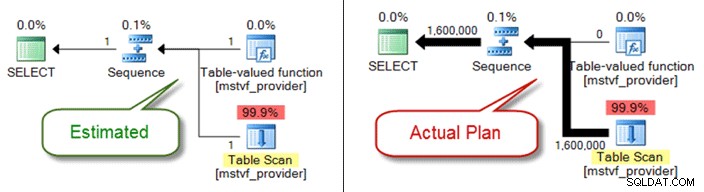
तालिका चर के समान, बहु-कथन तालिका-मूल्यवान और अदिश कार्य कार्डिनैलिटी अनुमान के दृष्टिकोण से एक ब्लैक-बॉक्स हैं। यदि आप उनके कारण योजना गुणवत्ता के मुद्दों का सामना कर रहे हैं, तो एक विकल्प के रूप में इनलाइन तालिका कार्यों पर विचार करें - या यहां तक कि फ़ंक्शन संदर्भ को पूरी तरह से बाहर निकालना और सीधे वस्तुओं को संदर्भित करना।
नीचे एक बहु-कथन तालिका-मूल्यवान फ़ंक्शन का उपयोग करते समय एक अनुमानित बनाम वास्तविक योजना दिखाई गई है:
डेटा प्रकार की समस्याएं
खोज और शामिल होने की स्थितियों के संयोजन में निहित डेटा प्रकार की समस्याएं कार्डिनैलिटी अनुमान संबंधी समस्याओं का कारण बन सकती हैं। वे सर्वर-स्तरीय संसाधनों (सीपीयू, आई/ओ, मेमोरी) को भी गुप्त रूप से खा सकते हैं, इसलिए जब भी संभव हो उन्हें संबोधित करना महत्वपूर्ण है।
जटिल विधेय
आपने शायद इस पैटर्न को पहले देखा होगा - एक क्वेरी जिसमें
WHERE. है खंड जिसमें प्रत्येक तालिका स्तंभ संदर्भ विभिन्न कार्यों, संयोजन संचालन, गणितीय संचालन और बहुत कुछ में लिपटा हुआ है। और जबकि सभी फ़ंक्शन रैपिंग उचित कार्डिनैलिटी अनुमानों को नहीं छोड़ते हैं (जैसेLOWERके लिए) ,UPPERऔरGETDATE) आपके विधेय को इस हद तक दफनाने के कई तरीके हैं कि क्वेरी अनुकूलक अब सटीक अनुमान नहीं लगा सकता है।क्वेरी जटिलता
दफन विधेय के समान, क्या आपके प्रश्न असाधारण रूप से जटिल हैं? मुझे एहसास है कि "जटिल" एक व्यक्तिपरक शब्द है, और आपका मूल्यांकन भिन्न हो सकता है, लेकिन अधिकांश सहमत हो सकते हैं कि विचारों के भीतर विचारों के भीतर घोंसले के विचार जो संदर्भ अतिव्यापी तालिकाओं के गैर-इष्टतम होने की संभावना है - खासकर जब 10+ तालिका के साथ मिलकर, फ़ंक्शन संदर्भ और दफन भविष्यवाणी। जबकि क्वेरी ऑप्टिमाइज़र एक सराहनीय काम करता है, यह जादू नहीं है, और यदि आपके पास महत्वपूर्ण विषमताएं हैं, तो क्वेरी जटिलता (स्विस-सेना चाकू क्वेरी) निश्चित रूप से ऑपरेटरों के लिए सटीक पंक्ति अनुमान प्राप्त करना असंभव बना सकती है।
वितरित क्वेरी
क्या आप लिंक किए गए सर्वर के साथ वितरित क्वेरी का उपयोग कर रहे हैं और आपको महत्वपूर्ण कार्डिनैलिटी अनुमान समस्याएं दिखाई दे रही हैं? यदि ऐसा है, तो डेटा तक पहुँचने के लिए उपयोग किए जा रहे लिंक किए गए सर्वर प्रिंसिपल से जुड़ी अनुमतियों की जाँच करना सुनिश्चित करें। बिना न्यूनतम
db_ddladminलिंक किए गए सर्वर खाते के लिए निश्चित डेटाबेस भूमिका, अपर्याप्त अनुमतियों के कारण दूरस्थ आँकड़ों की दृश्यता की कमी आपके कार्डिनैलिटी अनुमान के मुद्दों का स्रोत हो सकती है।और भी हैं...
कार्डिनैलिटी अनुमानों के विषम होने के और भी कारण हैं, लेकिन मेरा मानना है कि मैंने सबसे आम लोगों को कवर किया है। मुख्य बिंदु ज्ञात, खराब प्रदर्शन करने वाले प्रश्नों के संबंध में विषमताओं पर ध्यान देना है। यह न मानें कि सटीक पंक्ति गणना शर्तों के आधार पर योजना तैयार की गई थी। यदि ये संख्याएँ विषम हैं, तो आपको पहले इसका निवारण करने का प्रयास करने की आवश्यकता है।