किसी भी रिलेशनल डेटाबेस इंजन में, एक सर्वोत्तम संभव योजना तैयार करना आवश्यक है जो कम से कम समय और संसाधनों के साथ क्वेरी के निष्पादन के अनुरूप हो। आम तौर पर, सभी डेटाबेस ट्री स्ट्रक्चर फॉर्मेट में प्लान जेनरेट करते हैं, जहां प्रत्येक प्लान ट्री के लीफ नोड को टेबल स्कैन नोड कहा जाता है। योजना का यह विशेष नोड बेस टेबल से डेटा लाने के लिए उपयोग किए जाने वाले एल्गोरिदम से मेल खाता है।
उदाहरण के लिए, एक साधारण क्वेरी उदाहरण पर विचार करें जैसे SELECT * FROM TBL1, TBL2 जहां TBL2.ID>1000; और मान लीजिए कि तैयार की गई योजना इस प्रकार है:
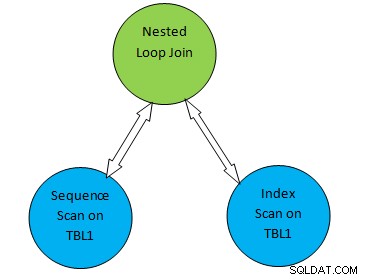
तो उपरोक्त प्लान ट्री में, "TBL1 पर अनुक्रमिक स्कैन" और " TBL2 पर इंडेक्स स्कैन क्रमशः टेबल TBL1 और TBL2 पर टेबल स्कैन विधि से मेल खाता है। इसलिए इस योजना के अनुसार, TBL1 को संबंधित पृष्ठों से क्रमिक रूप से प्राप्त किया जाएगा और TBL2 को INDEX स्कैन का उपयोग करके एक्सेस किया जा सकता है।
योजना के हिस्से के रूप में सही स्कैन पद्धति का चयन करना समग्र क्वेरी प्रदर्शन के संदर्भ में बहुत महत्वपूर्ण है।
पोस्टग्रेएसक्यूएल द्वारा समर्थित सभी प्रकार की स्कैन विधियों में शामिल होने से पहले, आइए कुछ प्रमुख प्रमुख बिंदुओं को संशोधित करें जिनका उपयोग हम ब्लॉग के माध्यम से करते समय अक्सर करेंगे।
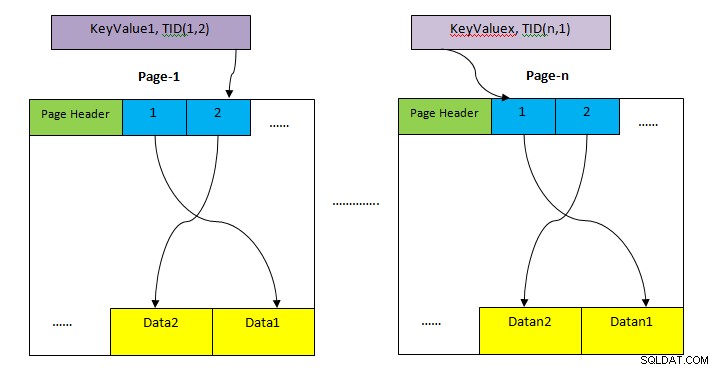
- ढेर: टेबल की पूरी पंक्ति को स्टोर करने के लिए स्टोरेज एरिया। यह कई पृष्ठों में विभाजित है (जैसा कि ऊपर चित्र में दिखाया गया है) और प्रत्येक पृष्ठ का आकार डिफ़ॉल्ट रूप से 8KB है। प्रत्येक पृष्ठ के भीतर, प्रत्येक आइटम सूचक (उदा. 1, 2,….) पृष्ठ के भीतर डेटा को इंगित करता है।
- सूचकांक संग्रहण: यह संग्रहण केवल प्रमुख मानों को संग्रहीत करता है अर्थात अनुक्रमणिका द्वारा निहित स्तंभ मान। यह भी कई पृष्ठों में विभाजित है और प्रत्येक पृष्ठ का आकार डिफ़ॉल्ट रूप से 8KB है।
- टुपल पहचानकर्ता (TID): TID 6 बाइट्स की संख्या है जिसमें दो भाग होते हैं। पहला भाग 4-बाइट पेज नंबर और शेष 2 बाइट्स टपल इंडेक्स पेज के अंदर है। इन दो संख्याओं का संयोजन विशिष्ट रूप से किसी विशेष टपल के संग्रहण स्थान की ओर इशारा करता है।
वर्तमान में, PostgreSQL नीचे स्कैन विधियों का समर्थन करता है जिसके द्वारा सभी आवश्यक डेटा तालिका से पढ़ा जा सकता है:
- अनुक्रमिक स्कैन
- इंडेक्स स्कैन
- केवल अनुक्रमणिका स्कैन
- बिटमैप स्कैन
- टीआईडी स्कैन
इन स्कैन विधियों में से प्रत्येक क्वेरी और अन्य मापदंडों के आधार पर समान रूप से उपयोगी हैं उदा। टेबल कार्डिनैलिटी, टेबल चयनात्मकता, डिस्क I/O लागत, यादृच्छिक I/O लागत, अनुक्रम I/O लागत, आदि। आइए कुछ पूर्व-सेटअप तालिका बनाएं और कुछ डेटा के साथ पॉप्युलेट करें, जिसका उपयोग इन स्कैन विधियों को बेहतर ढंग से समझाने के लिए अक्सर किया जाएगा। ।
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEतो इस उदाहरण में, दस लाख रिकॉर्ड डाले जाते हैं और फिर तालिका का विश्लेषण किया जाता है ताकि सभी आंकड़े अद्यतित हों।
अनुक्रमिक स्कैन
जैसा कि नाम से पता चलता है, एक तालिका का अनुक्रमिक स्कैन संबंधित तालिकाओं के सभी पृष्ठों के सभी आइटम पॉइंटर्स को क्रमिक रूप से स्कैन करके किया जाता है। इसलिए यदि किसी विशेष तालिका के लिए 100 पृष्ठ हैं और फिर प्रत्येक पृष्ठ में 1000 रिकॉर्ड हैं, तो अनुक्रमिक स्कैन के हिस्से के रूप में यह 100 * 1000 रिकॉर्ड प्राप्त करेगा और जांच करेगा कि क्या यह अलगाव स्तर के अनुसार और विधेय खंड के अनुसार मेल खाता है। इसलिए भले ही पूरे टेबल स्कैन के हिस्से के रूप में केवल 1 रिकॉर्ड का चयन किया गया हो, शर्त के अनुसार एक योग्य रिकॉर्ड खोजने के लिए उसे 100K रिकॉर्ड स्कैन करना होगा।
उपरोक्त तालिका और डेटा के अनुसार, निम्न क्वेरी के परिणामस्वरूप अनुक्रमिक स्कैन होगा क्योंकि अधिकांश डेटा चयनित हो रहे हैं।
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)नोट
हालांकि योजना लागत की गणना और तुलना किए बिना, यह बताना लगभग असंभव है कि किस प्रकार के स्कैन का उपयोग किया जाएगा। लेकिन अनुक्रमिक स्कैन का उपयोग करने के लिए कम से कम नीचे दिए गए मानदंडों का मिलान होना चाहिए:
- कुंजी पर कोई अनुक्रमणिका उपलब्ध नहीं है, जो विधेय का हिस्सा है।
- अधिकांश पंक्तियाँ SQL क्वेरी के भाग के रूप में प्राप्त की जा रही हैं।
टिप्स
यदि केवल बहुत कम% पंक्तियाँ प्राप्त की जा रही हैं और विधेय एक (या अधिक) कॉलम पर है, तो इंडेक्स के साथ या बिना प्रदर्शन का मूल्यांकन करने का प्रयास करें।
इंडेक्स स्कैन
अनुक्रमिक स्कैन के विपरीत, अनुक्रमणिका स्कैन सभी रिकॉर्ड क्रमिक रूप से प्राप्त नहीं करता है। बल्कि यह क्वेरी में शामिल सूचकांक के अनुरूप विभिन्न डेटा संरचना (सूचकांक के प्रकार के आधार पर) का उपयोग करता है और बहुत कम स्कैन के साथ आवश्यक डेटा (विधेय के अनुसार) खंड का पता लगाता है। फिर इंडेक्स स्कैन का उपयोग करके मिली प्रविष्टि सीधे हीप क्षेत्र में डेटा की ओर इशारा करती है (जैसा कि ऊपर की आकृति में दिखाया गया है), जिसे तब अलगाव स्तर के अनुसार दृश्यता की जांच करने के लिए प्राप्त किया जाता है। तो अनुक्रमणिका स्कैन के लिए दो चरण हैं:
- सूचकांक संबंधित डेटा संरचना से डेटा प्राप्त करें। यह ढेर में संबंधित डेटा का TID लौटाता है।
- फिर संपूर्ण डेटा प्राप्त करने के लिए संबंधित हीप पेज को सीधे एक्सेस किया जाता है। यह अतिरिक्त कदम निम्नलिखित कारणों से आवश्यक है:
- हो सकता है कि क्वेरी ने संबंधित इंडेक्स में उपलब्ध कॉलम से अधिक कॉलम लाने का अनुरोध किया हो।
- सूचकांक डेटा के साथ दृश्यता जानकारी का रखरखाव नहीं किया जाता है। इसलिए आइसोलेशन स्तर के अनुसार डेटा की दृश्यता की जांच करने के लिए, इसे हीप डेटा तक पहुंचने की आवश्यकता है।
अब हम सोच सकते हैं कि क्यों न हमेशा इंडेक्स स्कैन का उपयोग किया जाए यदि यह इतना कुशल है। तो जैसा कि हम जानते हैं कि सब कुछ कुछ लागत के साथ आता है। यहां शामिल लागत हमारे द्वारा किए जा रहे I/O के प्रकार से संबंधित है। इंडेक्स स्कैन के मामले में, इंडेक्स स्टोरेज में पाए जाने वाले प्रत्येक रिकॉर्ड के लिए रैंडम I/O शामिल होता है, इसे HEAP स्टोरेज से संबंधित डेटा प्राप्त करना होता है जबकि अनुक्रमिक स्कैन के मामले में, अनुक्रम I/O शामिल होता है जो लगभग 25% लेता है यादृच्छिक I/O समय की।
इसलिए इंडेक्स स्कैन को तभी चुना जाना चाहिए जब समग्र लाभ रैंडम I/O लागत के कारण किए गए ओवरहेड से बेहतर प्रदर्शन करता है।
उपरोक्त तालिका और डेटा के अनुसार, निम्न क्वेरी के परिणामस्वरूप एक इंडेक्स स्कैन होगा क्योंकि केवल एक रिकॉर्ड का चयन किया जा रहा है। इसलिए रैंडम I/O कम होता है और साथ ही संबंधित रिकॉर्ड की खोज जल्दी होती है।
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)केवल अनुक्रमणिका स्कैन
इंडेक्स ओनली स्कैन दूसरे चरण को छोड़कर इंडेक्स स्कैन के समान है, जैसा कि नाम से ही स्पष्ट है कि यह केवल इंडेक्स डेटा संरचना को स्कैन करता है। इंडेक्स स्कैन की तुलना में केवल इंडेक्स स्कैन चुनने के लिए दो अतिरिक्त पूर्व-शर्तें हैं:
- क्वेरी में केवल प्रमुख कॉलम होने चाहिए जो इंडेक्स का हिस्सा हैं।
- चयनित हीप पेज पर सभी टुपल्स (रिकॉर्ड) दिखाई देने चाहिए। जैसा कि पिछले खंड में चर्चा की गई है कि इंडेक्स डेटा संरचना दृश्यता जानकारी को बनाए नहीं रखती है, इसलिए केवल इंडेक्स से डेटा का चयन करने के लिए हमें दृश्यता की जांच से बचना चाहिए और ऐसा तब हो सकता है जब उस पृष्ठ के सभी डेटा को दृश्यमान माना जाता है।
निम्न क्वेरी के परिणामस्वरूप केवल एक अनुक्रमणिका स्कैन होगी। भले ही यह क्वेरी रिकॉर्ड की संख्या चुनने के मामले में लगभग समान है, लेकिन केवल कुंजी फ़ील्ड (यानी "संख्या") का चयन किया जा रहा है, यह केवल इंडेक्स स्कैन का चयन करेगा।
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)बिटमैप स्कैन
बिटमैप स्कैन इंडेक्स स्कैन और अनुक्रमिक स्कैन का मिश्रण है। यह इंडेक्स स्कैन के नुकसान को हल करने की कोशिश करता है लेकिन फिर भी इसका पूरा फायदा उठाता है। जैसा कि ऊपर चर्चा की गई है, इंडेक्स डेटा संरचना में पाए गए प्रत्येक डेटा के लिए, इसे हीप पेज में संबंधित डेटा खोजने की आवश्यकता है। तो वैकल्पिक रूप से इसे एक बार इंडेक्स पेज लाने की जरूरत है और फिर ढेर पेज के बाद, जो बहुत सारे यादृच्छिक I/O का कारण बनता है। तो बिटमैप स्कैन विधि यादृच्छिक I/O के बिना इंडेक्स स्कैन के लाभ का लाभ उठाती है। यह नीचे दो स्तरों में काम करता है:
- बिटमैप इंडेक्स स्कैन:सबसे पहले यह इंडेक्स डेटा संरचना से सभी इंडेक्स डेटा प्राप्त करता है और सभी टीआईडी का एक बिट मैप बनाता है। सरल समझ के लिए, आप मान सकते हैं कि इस बिटमैप में सभी पृष्ठों का हैश (पृष्ठ संख्या के आधार पर हैश) है और प्रत्येक पृष्ठ प्रविष्टि में उस पृष्ठ के भीतर सभी ऑफ़सेट की एक सरणी होती है।
- बिटमैप हीप स्कैन:जैसा कि नाम से ही स्पष्ट है, यह पृष्ठों के बिटमैप के माध्यम से पढ़ता है और फिर संग्रहीत पृष्ठ और ऑफसेट के अनुरूप हीप से डेटा को स्कैन करता है। अंत में, यह दृश्यता और विधेय आदि के लिए जाँच करता है और इन सभी जाँचों के परिणाम के आधार पर टपल लौटाता है।
नीचे की क्वेरी के परिणामस्वरूप बिटमैप स्कैन होगा क्योंकि यह बहुत कम रिकॉर्ड (यानी इंडेक्स स्कैन के लिए बहुत अधिक) का चयन नहीं कर रहा है और साथ ही साथ बड़ी संख्या में रिकॉर्ड का चयन नहीं कर रहा है (यानी अनुक्रमिक के लिए बहुत कम है) स्कैन)।
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)अब नीचे दी गई क्वेरी पर विचार करें, जो समान संख्या में रिकॉर्ड का चयन करती है लेकिन केवल प्रमुख फ़ील्ड (यानी केवल इंडेक्स कॉलम)। चूंकि यह केवल कुंजी का चयन करता है, इसलिए इसे डेटा के अन्य भागों के लिए हीप पृष्ठों को संदर्भित करने की आवश्यकता नहीं है और इसलिए इसमें कोई यादृच्छिक I/O शामिल नहीं है। तो यह क्वेरी बिटमैप स्कैन के बजाय इंडेक्स ओनली स्कैन को चुनेगी।
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID स्कैन
TID, जैसा कि ऊपर उल्लेख किया गया है, 6 बाइट्स संख्या है जिसमें 4-बाइट पृष्ठ संख्या होती है और पृष्ठ के अंदर शेष 2 बाइट्स टपल अनुक्रमणिका होती है। TID स्कैन PostgreSQL में एक बहुत ही विशिष्ट प्रकार का स्कैन है और केवल तभी चुना जाता है जब क्वेरी विधेय में TID हो। TID स्कैन को प्रदर्शित करने वाली निम्न क्वेरी पर विचार करें:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)तो यहां विधेय में, शर्त के रूप में कॉलम का सटीक मान देने के बजाय, TID प्रदान किया जाता है। यह Oracle में ROWID आधारित खोज के समान है।
बोनस
सभी स्कैन विधियां व्यापक रूप से उपयोग की जाती हैं और प्रसिद्ध हैं। साथ ही, ये स्कैन विधियाँ लगभग सभी रिलेशनल डेटाबेस में उपलब्ध हैं। लेकिन हाल ही में PostgreSQL समुदाय में चर्चा में एक और स्कैन विधि है और साथ ही हाल ही में अन्य रिलेशनल डेटाबेस में जोड़ा गया है। इसे MySQL में "लूज़ इंडेक्सस्कैन", Oracle में "इंडेक्स स्किप स्कैन" और DB2 में "जंप स्कैन" कहा जाता है।
इस स्कैन पद्धति का उपयोग एक विशिष्ट परिदृश्य के लिए किया जाता है जहां बी-ट्री इंडेक्स के प्रमुख कुंजी कॉलम के विशिष्ट मूल्य का चयन किया जाता है। इस स्कैन के हिस्से के रूप में, यह सभी समान कुंजी कॉलम मान को पार करने से बचता है, बल्कि केवल पहले अद्वितीय मान को पार करता है और फिर अगले बड़े मान पर कूद जाता है।
यह कार्य अभी भी PostgreSQL में "इंडेक्स स्किप स्कैन" के रूप में अस्थायी नाम के साथ प्रगति पर है और हम इसे भविष्य के रिलीज में देखने की उम्मीद कर सकते हैं।