मेरे सहकर्मी स्टीव राइट (ब्लॉग | @SQL_Steve) ने मुझे हाल ही में एक अजीब परिणाम पर एक प्रश्न के साथ देखा जो वह देख रहा था। हमारे नवीनतम टूल, एसक्यूएल सेंट्री प्लान एक्सप्लोरर प्रो में कुछ कार्यक्षमता का परीक्षण करने के लिए, उन्होंने एक विस्तृत और बड़ी तालिका का निर्माण किया था, और इसके खिलाफ कई तरह के प्रश्न चला रहे थे। एक मामले में वह बहुत सारा डेटा लौटा रहा था, लेकिन सांख्यिकी IO दिखा रहा था कि बहुत कम पढ़े जा रहे थे। मैंने कुछ लोगों को #sqlhelp पर पिंग किया और, चूंकि ऐसा लग रहा था कि किसी ने भी इस मुद्दे को नहीं देखा है, मैंने सोचा कि मैं इसके बारे में ब्लॉग करूंगा।
TL;DR संस्करण
संक्षेप में, इस बात से अवगत रहें कि कुछ ऐसे परिदृश्य हैं जहां आप सांख्यिकी IO पर भरोसा नहीं कर सकते हैं सच बताऊं तो। कुछ मामलों में (इसमें TOP . शामिल है) और समानांतरवाद), यह तार्किक रूप से बहुत कम रिपोर्ट करेगा। इससे आपको विश्वास हो सकता है कि जब आप नहीं करते हैं तो आपके पास एक बहुत ही I/O-अनुकूल क्वेरी है। अन्य अधिक स्पष्ट मामले हैं - जैसे कि जब आपके पास स्केलर उपयोगकर्ता-परिभाषित कार्यों के उपयोग से छिपे हुए I/O का एक गुच्छा होता है। हमें लगता है कि प्लान एक्सप्लोरर उन मामलों को और स्पष्ट करता है; हालांकि, यह थोड़ा पेचीदा है।
समस्या क्वेरी
तालिका में 37 मिलियन पंक्तियाँ हैं, प्रति पंक्ति 250 बाइट्स तक, लगभग 1 मिलियन पृष्ठ, और बहुत कम विखंडन (स्तर 0 पर 0.42%, स्तर 1 पर 15% और उससे आगे 0)। प्रमुख INT पर संकुल प्राथमिक कुंजी को छोड़कर कोई गणना कॉलम नहीं है, कोई UDF नहीं चल रहा है, और कोई अनुक्रमणिका नहीं है कॉलम। TOP . का उपयोग करके 500,000 पंक्तियों, सभी स्तंभों को लौटाने वाली एक साधारण क्वेरी और चुनें* :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(और हां, मुझे एहसास है कि मैं अपने नियमों का उल्लंघन कर रहा हूं और SELECT * . का उपयोग कर रहा हूं और टॉप बिना ऑर्डर बाय , लेकिन सादगी के लिए मैं अनुकूलक पर अपने प्रभाव को कम करने की पूरी कोशिश कर रहा हूं।)
परिणाम:
(500000 पंक्ति(पंक्तियाँ) प्रभावित)तालिका 'आदेश इतिहास'। स्कैन काउंट 1, लॉजिकल रीड्स 23, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0।
हम 500,000 पंक्तियों को वापस कर रहे हैं, और इसमें लगभग 10 सेकंड लगते हैं। मुझे तुरंत पता चल जाता है कि तार्किक पठन संख्या में कुछ गड़बड़ है। यहां तक कि अगर मुझे पहले से ही अंतर्निहित डेटा के बारे में पता नहीं था, तो मैं प्रबंधन स्टूडियो में ग्रिड परिणामों से बता सकता हूं कि यह डेटा के 23 से अधिक पृष्ठों को खींच रहा है, चाहे वे मेमोरी से हों या कैशे, और यह कहीं न कहीं दिखाई देना चाहिए। कोड>सांख्यिकी आईओ . योजना को देख रहे हैं…
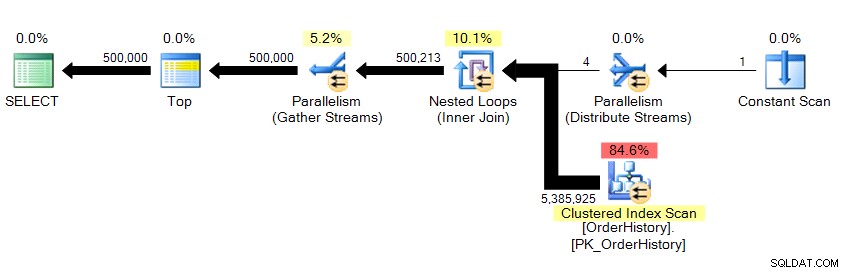
...हम देखते हैं कि समानता मौजूद है, और हमने पूरी तालिका को स्कैन कर लिया है। तो यह कैसे संभव है कि केवल 23 तार्किक पठन हों?
एक और "समान" क्वेरी
स्टीव से मेरे पहले प्रश्नों में से एक था:"यदि आप समानता को खत्म कर देते हैं तो क्या होगा?" इसलिए मैंने इसे आजमाया। मैंने मूल सबक्वेरी संस्करण लिया और MAXDOP 1 . जोड़ा :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
परिणाम और योजना:
(500000 पंक्ति(पंक्तियाँ) प्रभावित)तालिका 'आदेश इतिहास'। स्कैन काउंट 1, लॉजिकल रीड्स 149589, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0।
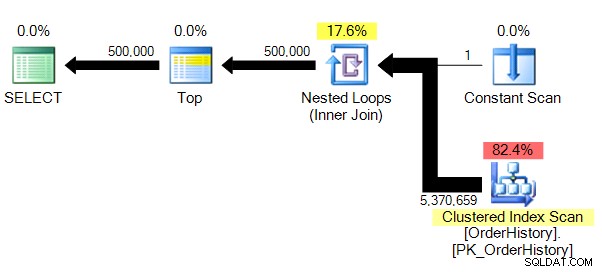
हमारे पास थोड़ी कम जटिल योजना है, और समानता के बिना (स्पष्ट कारणों से), सांख्यिकी IO तार्किक पढ़ने की संख्या के लिए हमें और अधिक विश्वसनीय संख्या दिखा रहा है।
सच्चाई क्या है?
यह देखना कठिन नहीं है कि इनमें से एक प्रश्न पूरी सच्चाई नहीं बता रहा है। जबकि सांख्यिकी आईओ हो सकता है हमें पूरी कहानी न बताएं, शायद ट्रेस करेंगे। यदि हम प्लान एक्सप्लोरर में एक वास्तविक निष्पादन योजना बनाकर रनटाइम मेट्रिक्स को पुनः प्राप्त करते हैं, तो हम देखते हैं कि जादुई कम-पढ़ने वाली क्वेरी वास्तव में मेमोरी या डिस्क से डेटा खींच रही है, न कि मैजिक पिक्सी डस्ट के बादल से। वास्तव में यह अन्य संस्करण की तुलना में *अधिक* पढ़ता है:

तो यह स्पष्ट है कि रीड हो रहे हैं, वे सांख्यिकी IO में ठीक से दिखाई नहीं दे रहे हैं आउटपुट।
समस्या क्या है?
खैर, मैं काफी ईमानदार रहूंगा:मुझे नहीं पता, इस तथ्य के अलावा कि समांतरता निश्चित रूप से एक भूमिका निभा रही है, और ऐसा लगता है कि यह किसी प्रकार की दौड़ की स्थिति है। सांख्यिकी आईओ (और, चूंकि हमें डेटा मिलता है, इसलिए हमारी तालिका I/O टैब) बहुत ही भ्रामक संख्या को पढ़ता है। यह स्पष्ट है कि क्वेरी हमारे द्वारा खोजे जा रहे सभी डेटा को लौटाती है, और ट्रेस परिणामों से यह स्पष्ट है कि ऐसा करने के लिए यह रीड्स का उपयोग करता है न कि ऑस्मोसिस का। मैंने इसके बारे में पॉल व्हाइट (ब्लॉग | @SQL_Kiwi) से पूछा और उन्होंने सुझाव दिया कि केवल कुछ पूर्व-थ्रेड I/O गणनाओं को कुल में शामिल किया जा रहा है (और सहमत हैं कि यह एक बग है)।
यदि आप इसे घर पर आज़माना चाहते हैं, तो आपको केवल एडवेंचरवर्क्स की आवश्यकता है (इसे 2008, 2008 R2 और 2012 संस्करणों के विरुद्ध पुन:प्रस्तुत करना चाहिए), और निम्नलिखित क्वेरी:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(ध्यान दें कि SETCPUWEIGHT केवल समानता को समेटने के लिए उपयोग किया जाता है। अधिक जानकारी के लिए, योजना लागत पर पॉल व्हाइट का ब्लॉग पोस्ट देखें।)
परिणाम:
तालिका 'बिक्री ऑर्डर हैडर'। स्कैन काउंट 1, लॉजिकल रीड्स 4, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0।टेबल 'सेल्सऑर्डरहेडर'। स्कैन काउंट 1, लॉजिकल रीड्स 333, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0।
पॉल ने और भी सरल रेप्रो की ओर इशारा किया:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
परिणाम:
तालिका 'लेनदेन इतिहास'। स्कैन काउंट 1, लॉजिकल रीड्स 5, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।टेबल 'ट्रांजेक्शनहिस्ट्री'। स्कैन काउंट 1, लॉजिकल रीड्स 110, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0।
तो ऐसा लगता है कि हम इसे आसानी से TOP . के साथ अपनी इच्छानुसार पुन:उत्पन्न कर सकते हैं ऑपरेटर और कम पर्याप्त डीओपी। मैंने एक बग दर्ज किया है:
- सांख्यिकी आईओ समानांतर योजनाओं के लिए तार्किक पठन को कम रिपोर्ट करता है
और पॉल ने दो अन्य कुछ हद तक संबंधित बग दायर किए हैं जिनमें समानताएं शामिल हैं, पहला हमारी बातचीत के परिणामस्वरूप:
- एक लुकअप पर पुश विधेय के साथ कार्डिनैलिटी अनुमान त्रुटि [संबंधित ब्लॉग पोस्ट]
- समानांतरता के साथ खराब प्रदर्शन और शीर्ष [संबंधित ब्लॉग पोस्ट]
(उदासीन लोगों के लिए, यहां छह अन्य समांतरता बग हैं जिन्हें मैंने कुछ साल पहले बताया था।)
सबक क्या है?
किसी एक स्रोत पर भरोसा करने में सावधानी बरतें। यदि आप केवल सांख्यिकी IO को देखते हैं इस तरह की एक क्वेरी को बदलने के बाद, आप अवधि में वृद्धि के बजाय चमत्कारी गिरावट पर ध्यान केंद्रित करने के लिए ललचा सकते हैं। किस बिंदु पर आप अपनी पीठ थपथपा सकते हैं, जल्दी काम छोड़ सकते हैं और अपने सप्ताहांत का आनंद ले सकते हैं, यह सोचकर कि आपने अपनी क्वेरी पर जबरदस्त प्रदर्शन प्रभाव डाला है। जब सच से आगे कुछ भी नहीं हो सकता है।