SQL सर्वर में बनाए गए किसी भी नए डेटाबेस के लिए, स्वत:अद्यतन सांख्यिकी विकल्प के लिए डिफ़ॉल्ट मान सक्षम है . मुझे संदेह है कि अधिकांश डीबीए सक्षम विकल्प छोड़ देते हैं, क्योंकि यह अनुकूलक को अमान्य होने पर स्वचालित रूप से आंकड़ों को अपडेट करने की अनुमति देता है, और आमतौर पर इसे सक्षम छोड़ने की अनुशंसा की जाती है। जब इंडेक्स को फिर से बनाया जाता है तो आंकड़े भी अपडेट किए जाते हैं, और हालांकि ऑटो अपडेट स्टैटिस्टिक्स ऑप्शन और इंडेक्स रीबिल्ड के माध्यम से आंकड़ों को अच्छी तरह से प्रबंधित करना असामान्य नहीं है, समय-समय पर एक डीबीए को अपडेट करने के लिए एक नियमित नौकरी स्थापित करना आवश्यक हो सकता है। आँकड़ा, या आँकड़ों का समूह।
आंकड़ों के कस्टम प्रबंधन में अक्सर अद्यतन सांख्यिकी कमांड शामिल होता है, जो काफी सौम्य लगता है। इसे किसी तालिका या अनुक्रमित दृश्य के सभी आँकड़ों के लिए या किसी विशिष्ट आँकड़ों के लिए चलाया जा सकता है। डिफ़ॉल्ट नमूने का उपयोग किया जा सकता है, एक विशिष्ट नमूना दर या नमूने के लिए पंक्तियों की संख्या निर्दिष्ट की जा सकती है, या आप उसी नमूना मान का उपयोग कर सकते हैं जो पहले उपयोग किया गया था। यदि किसी तालिका या अनुक्रमित दृश्य के लिए आँकड़े अद्यतन किए जाते हैं, तो आप सभी आँकड़े, केवल अनुक्रमणिका आँकड़े, या केवल स्तंभ आँकड़े अद्यतन करना चुन सकते हैं। और अंत में, आप किसी आंकड़े के लिए स्वत:अद्यतन आंकड़े विकल्प को अक्षम कर सकते हैं।
अधिकांश डीबीए के लिए, सबसे बड़ा विचार कब . हो सकता है अद्यतन सांख्यिकी विवरण चलाने के लिए। लेकिन डीबीए यह भी तय करते हैं, होशपूर्वक या नहीं, अद्यतन के लिए नमूना आकार। चयनित नमूना आकार वास्तविक अद्यतन के प्रदर्शन के साथ-साथ प्रश्नों के प्रदर्शन को भी प्रभावित कर सकता है।
नमूना आकार के प्रभावों को समझना
अद्यतन सांख्यिकी के लिए डिफ़ॉल्ट नमूना आकार एक गैर-रेखीय एल्गोरिथ्म से आता है, और नमूना आकार कम हो जाता है क्योंकि तालिका का आकार बड़ा हो जाता है, जैसा कि जो सैक ने अपनी पोस्ट, ऑटो-अपडेट आँकड़े डिफ़ॉल्ट नमूना परीक्षण में दिखाया था। कुछ मामलों में, नमूना का आकार इतना बड़ा नहीं हो सकता है कि पर्याप्त रोचक जानकारी प्राप्त कर सके, या दाएं सूचना, सांख्यिकी हिस्टोग्राम के लिए, जैसा कि कॉनर कनिंघम ने अपने सांख्यिकी नमूना दर पोस्ट में उल्लेख किया है। यदि डिफ़ॉल्ट नमूना एक अच्छा हिस्टोग्राम नहीं बनाता है, तो डीबीए फुलस्कैन (तालिका या अनुक्रमित दृश्य में सभी पंक्तियों को स्कैन करना) तक उच्च नमूना दर के साथ आंकड़ों को अपडेट करना चुन सकता है। लेकिन जैसा कि कॉनर ने अपनी पोस्ट में उल्लेख किया है, अधिक पंक्तियों को स्कैन करना एक लागत पर आता है, और डीबीए को यह तय करने के लिए चुनौती दी जाती है कि क्या "सर्वश्रेष्ठ" हिस्टोग्राम को संभव बनाने और बनाने के लिए फुलस्कैन चलाया जाए, या प्रदर्शन प्रभाव को कम करने के लिए एक छोटे प्रतिशत का नमूना लिया जाए। अद्यतन।
यह समझने और समझने के लिए कि किस बिंदु पर एक नमूना फुलस्कैन से अधिक समय लेता है, मैंने निम्नलिखित कथनों को SalesOrderDetail तालिका की प्रतियों के विरुद्ध चलाया, जिन्हें जोनाथन केहैयस की स्क्रिप्ट का उपयोग करके बड़ा किया गया था:
| विवरण आईडी | अद्यतन सांख्यिकी विवरण |
|---|---|
| 1 | अद्यतन आंकड़े [बिक्री]। [SalesOrderDetailEnlarged] फुलस्कैन के साथ; |
| 2 | अद्यतन आंकड़े [बिक्री]।[SalesOrderDetailEnlarged]; |
| 3 | अद्यतन आंकड़े [बिक्री]। [SalesOrderDetailEnlarged] नमूना 10 प्रतिशत के साथ; |
| 4 | अद्यतन आंकड़े [बिक्री]। [SalesOrderDetailEnlarged] नमूना 25 प्रतिशत के साथ; |
| 5 | अद्यतन आंकड़े [बिक्री]। [SalesOrderDetailEnlarged] नमूना 50 प्रतिशत के साथ; |
| 6 | अद्यतन आंकड़े [बिक्री]। [SalesOrderDetailEnlarged] नमूना 75 प्रतिशत के साथ; |
मेरे पास निम्नलिखित विशेषताओं के साथ SalesOrderDetailबढ़ी हुई तालिका की तीन प्रतियां थीं*:
| पंक्ति गणना | पेज की संख्या | MAXDOP | अधिकतम मेमोरी <वें valign="top" चौड़ाई="106">संग्रहण | मशीन | |
|---|---|---|---|---|---|
| 23,899,449 | 363,284 | 4 | 8GB | SSD_1 | लैपटॉप |
| 607,312,902 | 7,757,200 | 16 | 54GB | SSD_2 | टेस्ट सर्वर |
| 607,312,902 | 7,757,200 | 16 | 54GB | 15K | टेस्ट सर्वर |
*हार्डवेयर के बारे में अतिरिक्त विवरण इस पोस्ट के अंत में हैं।
तालिका की सभी प्रतियों में निम्नलिखित आँकड़े थे, और तीन सूचकांक आँकड़ों में से किसी में भी कॉलम शामिल नहीं थे:
| सांख्यिकीय <थ चौड़ाई="68">प्रकार | कुंजी में कॉलम | |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | सूचकांक | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | सूचकांक | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | सूचकांक | ProductId |
| user_CarrierTrackingNumber | कॉलम | CarrierTrackingNumber |
मैंने उपरोक्त अद्यतन सांख्यिकी विवरण को अपने लैपटॉप पर SalesOrderDetailEnlarged तालिका के विरुद्ध चार बार और TestServer पर SalesOrderDetailEnlarged तालिकाओं के विरुद्ध दो बार चलाया। स्टेटमेंट हर बार रैंडम क्रम में चलाए जाते थे, और प्रत्येक अपडेट स्टेटमेंट से पहले प्रोसेस कैश और बफर कैशे को क्लियर कर दिया जाता था। बयानों के प्रत्येक सेट (औसत) के लिए अवधि और tempdb उपयोग नीचे दिए गए ग्राफ़ में हैं:
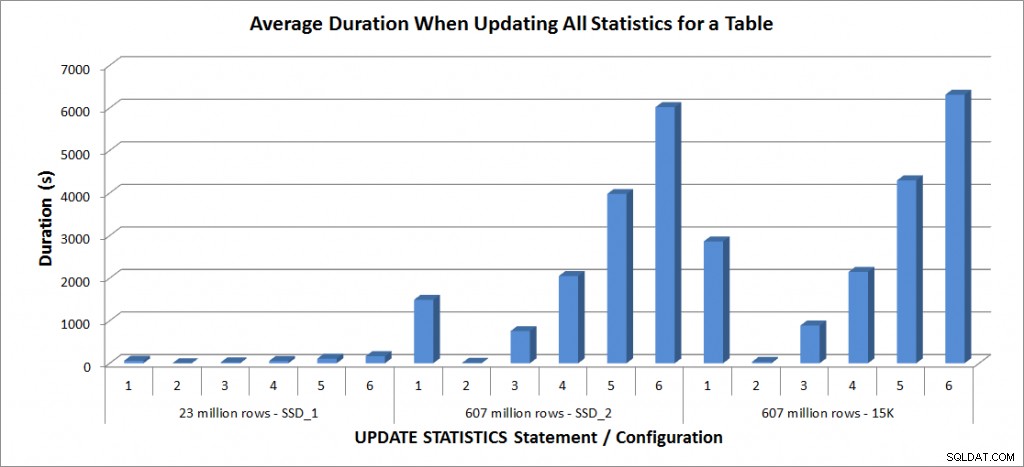
औसत अवधि - SalesOrderDetailEnlarged के सभी आंकड़े अपडेट करें
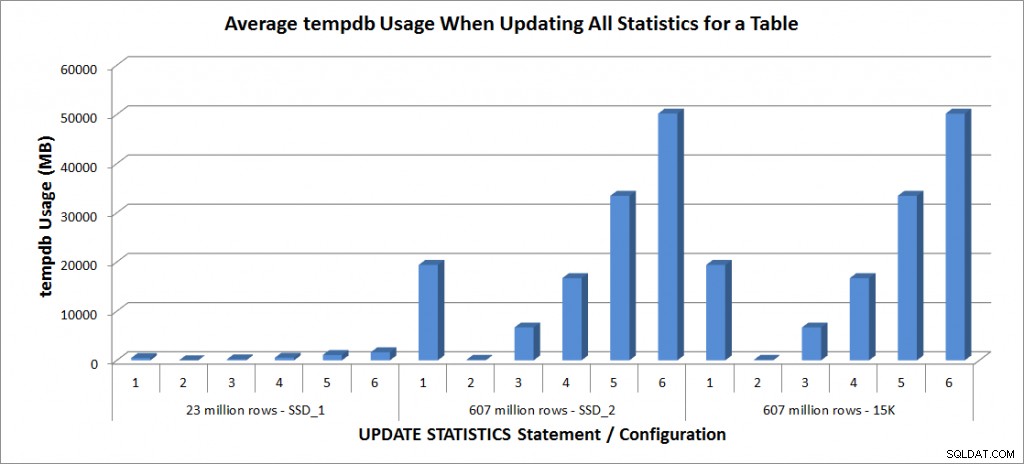
tempdb उपयोग - SalesOrderDetailEnlarged के सभी आंकड़े अपडेट करें
23 मिलियन पंक्ति तालिका के लिए अवधि सभी तीन मिनट से कम थी, और अगले भाग में अधिक विस्तार से वर्णित हैं। SSD_2 डिस्क पर तालिका के लिए, FULLSCAN स्टेटमेंट में 1492 सेकंड (लगभग 25 मिनट) लगे और 25% सैंपल वाले अपडेट में 2051 सेकंड (34 मिनट से अधिक) लगे। इसके विपरीत, 15K डिस्क पर, FULLSCAN स्टेटमेंट में 2864 सेकंड (47 मिनट से अधिक) लगे और 25% सैंपल के साथ अपडेट में 2147 सेकंड (लगभग 36 मिनट) लगे - FULLSCAN के समय से भी कम। हालांकि, 50% नमूने के साथ अपडेट में 4296 सेकंड (71 मिनट से अधिक) लगे।
Tempdb का उपयोग बहुत अधिक सुसंगत है, नमूना आकार बढ़ने के साथ-साथ एक स्थिर वृद्धि दिखा रहा है, और 25% और 50% के बीच कहीं फुलस्कैन की तुलना में अधिक tempdb स्थान का उपयोग कर रहा है। यहाँ जो उल्लेखनीय है वह यह है कि अद्यतन आँकड़े करता है उपयोग करें tempdb, जो याद रखना महत्वपूर्ण है जब आप SQL सर्वर वातावरण के लिए tempdb का आकार बदल रहे हैं। अद्यतन सांख्यिकी BOL प्रविष्टि में Tempdb उपयोग का उल्लेख किया गया है:
<ब्लॉककोट>अद्यतन आँकड़े, आंकड़ों के निर्माण के लिए पंक्तियों के नमूने को क्रमबद्ध करने के लिए tempdb का उपयोग कर सकते हैं। ”
और प्रभाव को लिंची शी की पोस्ट, प्रदर्शन प्रभाव:tempdb और अद्यतन आँकड़े में प्रलेखित किया गया है। हालाँकि, यह ऐसा कुछ नहीं है जिसका उल्लेख हमेशा टेम्पर्ड साइज़िंग चर्चाओं के दौरान किया जाता है। यदि आपके पास बड़े टेबल हैं और फुलस्कैन या उच्च नमूना मानों के साथ अद्यतन करते हैं, तो tempdb उपयोग के बारे में जागरूक रहें।
चुनिंदा अपडेट का प्रदर्शन
मैंने अगली बार तालिका पर अन्य आँकड़ों के लिए अद्यतन सांख्यिकी विवरण का परीक्षण करने का निर्णय लिया, लेकिन अपने परीक्षणों को 23 मिलियन पंक्तियों वाली तालिका की प्रतिलिपि तक सीमित कर दिया। अद्यतन सांख्यिकी विवरण के उपरोक्त छह रूपांतरों को निम्नलिखित व्यक्तिगत आंकड़ों के लिए चार बार दोहराया गया और फिर संपूर्ण तालिका के लिए अद्यतन के साथ तुलना की गई:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
मेरे लैपटॉप पर उपरोक्त कॉन्फ़िगरेशन के साथ सभी परीक्षण चलाए गए थे, और परिणाम नीचे दिए गए ग्राफ़ में हैं:
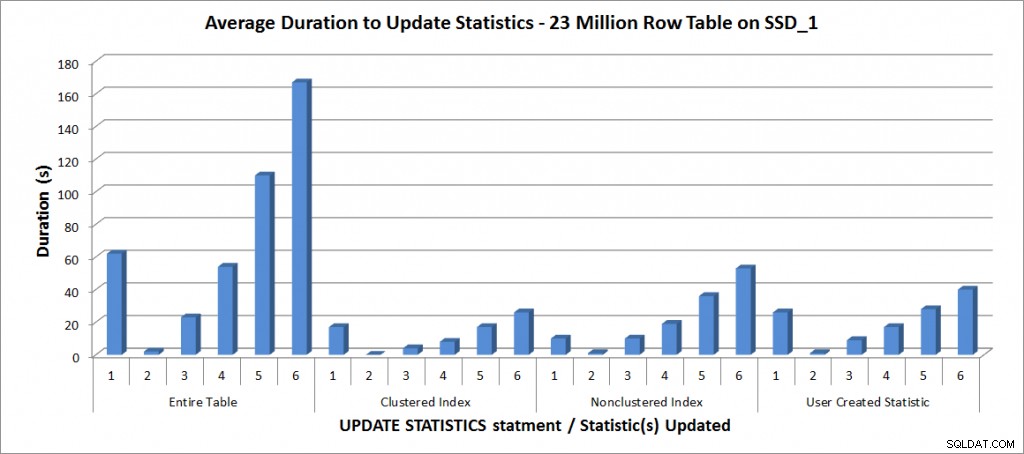
अद्यतन आंकड़ों की औसत अवधि - सभी आंकड़े बनाम चयनित
जैसा कि अपेक्षित था, तालिका के सभी आंकड़ों को अपडेट करने की तुलना में किसी एक आंकड़े के अपडेट में कम समय लगा। जिस मान पर नमूना अपडेट किया गया था, उसमें FULLSCAN की भिन्नता से अधिक समय लगा:
| अद्यतन विवरण <थ चौड़ाई="213">फुलस्कैन अवधि (अवधि) <थ चौड़ाई="213">पहला अद्यतन जिसमें अधिक समय लगा | ||
|---|---|---|
| संपूर्ण तालिका | 62 | 50% - 110 सेकंड |
| संकुल अनुक्रमणिका | 17 | 75% - 26 सेकंड |
| गैर-संकुल सूचकांक | 10 | 25% - 19 सेकंड |
| उपयोगकर्ता द्वारा बनाए गए आंकड़े | 26 | 50% - 28 सेकंड |
निष्कर्ष
इस डेटा और 607 मिलियन पंक्ति तालिकाओं से FULLSCAN डेटा के आधार पर, कोई विशिष्ट नहीं है टिपिंग बिंदु जहां एक नमूना अद्यतन FULLSCAN से अधिक समय लेता है; वह बिंदु तालिका के आकार और उपलब्ध संसाधनों पर निर्भर है। लेकिन डेटा अभी भी सार्थक है क्योंकि यह दर्शाता है कि है एक बिंदु जहां एक नमूना मूल्य को फुलस्कैन की तुलना में पकड़ने में अधिक समय लग सकता है। यह फिर से आपके डेटा को जानने के लिए नीचे आता है। यह न केवल यह समझने के लिए महत्वपूर्ण है कि क्या किसी तालिका को आंकड़ों के कस्टम प्रबंधन की आवश्यकता है, बल्कि एक उपयोगी हिस्टोग्राम बनाने और संसाधन उपयोग को अनुकूलित करने के लिए आदर्श नमूना आकार को भी समझना है।
विनिर्देश
लैपटॉप विनिर्देश:डेल M6500, 1 Intel i7 (2.13GHz 4 कोर और HT सक्षम है इसलिए 8 तार्किक कोर), 32 GB मेमोरी, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), 265GB सैमसंग SSD पर संग्रहीत डेटाबेस फ़ाइलें PM810टेस्ट सर्वर विनिर्देश:डेल R720, 2 इंटेल E5-2670 (2.6GHz 8 कोर और HT सक्षम है इसलिए 16 लॉजिकल कोर प्रति सॉकेट), 64 जीबी मेमोरी, विंडोज 2012, SQL सर्वर 2012 SP1 (11.0.3339.0 x64), के लिए डेटाबेस फाइलें एक तालिका दो 640GB फ़्यूज़न-आईओ डुओ एमएलसी कार्ड पर स्थित है, दूसरी तालिका के लिए डेटाबेस फ़ाइलें RAID5 सरणी में नौ 15K RPM डिस्क पर हैं