Books Online में उल्लिखित फ़िल्टर किए गए अनुक्रमणिका उपयोग मामलों में से एक कॉलम से संबंधित है जिसमें अधिकतर NULL . होता है मूल्य। एक फ़िल्टर इंडेक्स बनाने का विचार है जिसमें NULLs . शामिल न हो , जिसके परिणामस्वरूप एक छोटा गैर-संकुल सूचकांक होता है जिसके लिए समकक्ष अनफ़िल्टर्ड इंडेक्स की तुलना में कम रखरखाव की आवश्यकता होती है। फ़िल्टर किए गए अनुक्रमणिका का एक अन्य लोकप्रिय उपयोग NULLs को फ़िल्टर करना है एक अद्वितीय . से सूचकांक, अन्य डेटाबेस इंजनों के व्यवहार उपयोगकर्ताओं को एक डिफ़ॉल्ट UNIQUE . से उम्मीद कर सकता है अनुक्रमणिका या बाधा:विशिष्टता केवल गैर-NULL . के लिए लागू की जा रही है मान।
दुर्भाग्य से, क्वेरी ऑप्टिमाइज़र की सीमाएँ हैं जहाँ फ़िल्टर्ड इंडेक्स का संबंध है। यह पोस्ट कुछ कम प्रसिद्ध उदाहरणों को देखता है।
नमूना तालिकाएं
हम दो तालिकाओं (A &B) का उपयोग करेंगे जिनकी संरचना समान होगी:एक सरोगेट क्लस्टर प्राथमिक कुंजी, एक अधिकतर-NULL स्तंभ जो अद्वितीय है (NULLs . की परवाह किए बिना ), और एक पैडिंग कॉलम जो वास्तविक तालिका में मौजूद अन्य स्तंभों का प्रतिनिधित्व करता है।
रुचि का कॉलम अधिकतर होता है-NULL एक, जिसे मैंने SPARSE . घोषित किया है . विरल विकल्प की आवश्यकता नहीं है, मैं इसे सिर्फ इसलिए शामिल करता हूं क्योंकि मुझे इसका उपयोग करने का अधिक मौका नहीं मिलता है। किसी भी स्थिति में, SPARSE शायद कई परिदृश्यों में समझ में आता है जहां कॉलम डेटा अधिकतर NULL होने की उम्मीद है . अगर आप चाहें तो बेझिझक उदाहरणों से विरल विशेषता को हटा दें।
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
प्रत्येक तालिका में अतिरिक्त 40,000 पंक्तियों के साथ डेटा कॉलम में 1 से 2,000 तक की संख्याएं होती हैं जहां डेटा कॉलम NULL होता है :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
दोनों तालिकाओं को एक UNIQUE मिलता है 2,000 गैर-NULL . के लिए फ़िल्टर की गई अनुक्रमणिका डेटा मान:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
DBCC SHOW_STATISTICS का आउटपुट स्थिति को सारांशित करता है:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

नमूना क्वेरी
नीचे दी गई क्वेरी दो तालिकाओं का एक सरल जुड़ाव करती है - कल्पना करें कि तालिकाएँ किसी प्रकार के माता-पिता-बच्चे के संबंध में हैं और कई विदेशी कुंजियाँ NULL हैं। वैसे भी उन पंक्तियों के साथ कुछ।
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; डिफ़ॉल्ट निष्पादन योजना
एसक्यूएल सर्वर के डिफ़ॉल्ट कॉन्फ़िगरेशन के साथ, ऑप्टिमाइज़र समानांतर नेस्टेड लूप जॉइन की विशेषता वाली एक निष्पादन योजना चुनता है:
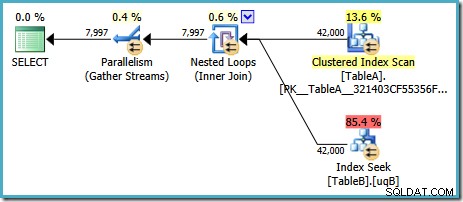
इस योजना की अनुमानित लागत 7.7768 है मैजिक ऑप्टिमाइज़र यूनिट™.
हालांकि इस योजना के बारे में कुछ अजीब बातें हैं। इंडेक्स सीक टेबल बी पर हमारे फ़िल्टर्ड इंडेक्स का उपयोग करता है, लेकिन क्वेरी टेबल ए के क्लस्टर्ड इंडेक्स स्कैन द्वारा संचालित होती है। जॉइन विधेय डेटा कॉलम पर एक समानता परीक्षण है, जो अस्वीकार एनयूएलएल (चाहे ANSI_NULLS . की परवाह किए बिना सेटिंग)। हमें उम्मीद थी कि अनुकूलक उस अवलोकन के आधार पर कुछ उन्नत तर्क करेगा, लेकिन नहीं। यह योजना तालिका A से प्रत्येक पंक्ति को पढ़ती है (40,000 NULLs सहित) ), प्रत्येक के लिए तालिका B पर फ़िल्टर किए गए अनुक्रमणिका की तलाश करता है, इस तथ्य पर निर्भर करता है कि NULL NULL से मेल नहीं खाएगा उस तलाश में। यह प्रयास की जबरदस्त बर्बादी है।
अजीब बात यह है कि ऑप्टिमाइज़र ने महसूस किया होगा कि जॉइन रिजेक्ट NULLs तालिका B की तलाश के लिए फ़िल्टर किए गए अनुक्रमणिका को चुनने के लिए, लेकिन उसने NULLs को फ़िल्टर करने के बारे में नहीं सोचा तालिका ए से पहले - या बेहतर अभी भी, बस NULL . को स्कैन करने के लिए टेबल ए पर -फ्री फ़िल्टर्ड इंडेक्स। आपको आश्चर्य हो सकता है कि क्या यह लागत-आधारित निर्णय है, शायद आंकड़े बहुत अच्छे नहीं हैं? शायद हमें संकेत के साथ फ़िल्टर्ड इंडेक्स के उपयोग को मजबूर करना चाहिए? तालिका A पर फ़िल्टर किए गए अनुक्रमणिका को इंगित करने से वही योजना बनती है जिसमें भूमिकाएँ उलट जाती हैं - तालिका B को स्कैन करना और तालिका A में खोज करना। दोनों तालिकाओं के लिए फ़िल्टर किए गए अनुक्रमणिका को मजबूर करने से त्रुटि 8622 उत्पन्न होती है। :क्वेरी प्रोसेसर एक क्वेरी योजना नहीं बना सका।
एक NOT NULL विधेय जोड़ना
अंतर्निहित NULL के साथ कुछ होने के कारण पर संदेह करना -जॉइन विधेय की अस्वीकृति, हम एक स्पष्ट NOT NULL add जोड़ते हैं चालू . के लिए विधेय खंड (या कहां क्लॉज यदि आप चाहें, तो यहां भी यही बात आती है):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
हमने NOT NULL added जोड़ा है तालिका ए कॉलम की जांच करें क्योंकि मूल योजना ने हमारे फ़िल्टर किए गए इंडेक्स का उपयोग करने के बजाय उस तालिका के क्लस्टर इंडेक्स को स्कैन किया था (तालिका बी में तलाश ठीक थी - यह फ़िल्टर किए गए इंडेक्स का उपयोग करती थी)। नई क्वेरी शब्दार्थ रूप से पिछले वाले के समान ही है, लेकिन निष्पादन योजना अलग है:
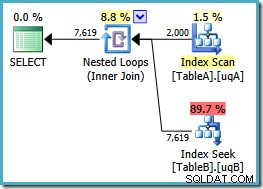
अब हमारे पास टेबल A पर फ़िल्टर किए गए इंडेक्स का अपेक्षित स्कैन है, जो 2,000 गैर-NULL उत्पन्न करता है। नेस्टेड लूप को चलाने के लिए पंक्तियाँ तालिका B में खोजती हैं। दोनों तालिकाएँ हमारे फ़िल्टर किए गए अनुक्रमणिका का उपयोग स्पष्ट रूप से अब बेहतर तरीके से कर रही हैं:नई योजना की लागत केवल 0.362835 है इकाइयों (7.7768 से नीचे)। हालांकि, हम बेहतर कर सकते हैं।
दो NOT NULL विधेय जोड़ना
अनावश्यक शून्य नहीं तालिका ए के लिए विधेय अद्भुत काम किया; यदि हम तालिका B के लिए भी एक जोड़ दें तो क्या होगा?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; यह क्वेरी अभी भी तार्किक रूप से पिछले दो प्रयासों के समान है, लेकिन निष्पादन योजना फिर से अलग है:
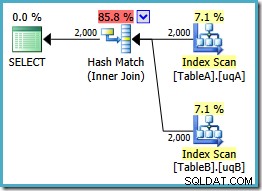
यह योजना तालिका A से 2,000 पंक्तियों के लिए एक हैश तालिका बनाती है, फिर तालिका B से 2,000 पंक्तियों का उपयोग करके मिलानों की जांच करती है। लौटाई गई पंक्तियों की अनुमानित संख्या पिछली पंक्तियों की तुलना में बहुत बेहतर है। पिछली योजना (क्या आपने वहां 7,619 अनुमान देखा था?) और अनुमानित निष्पादन लागत 0.362835 से गिरकर 0.0772056 हो गई है। .
आप मूल या एकल पर एक संकेत का उपयोग करके हैश में शामिल होने के लिए मजबूर करने का प्रयास कर सकते हैं-शून्य नहीं प्रश्न, लेकिन आपको ऊपर दिखाया गया कम लागत वाला प्लान नहीं मिलेगा। ऑप्टिमाइज़र के पास NULL . के बारे में पूरी तरह से तर्क करने की क्षमता नहीं है -शामिल होने के व्यवहार को अस्वीकार करना क्योंकि यह दोनों निरर्थक विधेय के बिना हमारे फ़िल्टर किए गए अनुक्रमणिका पर लागू होता है।
आपको इससे आश्चर्यचकित होने की अनुमति है - भले ही यह केवल यह विचार हो कि एक निरर्थक विधेय पर्याप्त नहीं था (निश्चित रूप से यदि ta.data शून्य नहीं है और ta.data =tb.data , यह इस प्रकार है कि tb.data शून्य नहीं भी है , है ना?)
अभी भी सही नहीं है
हैश को इसमें शामिल होते देखना थोड़ा आश्चर्य की बात है। यदि आप तीन भौतिक जुड़ने वाले ऑपरेटरों के बीच मुख्य अंतर से परिचित हैं, तो आप शायद जानते हैं कि हैश जॉइन एक शीर्ष उम्मीदवार है जहां:
- पूर्व-क्रमबद्ध इनपुट उपलब्ध नहीं है
- हैश बिल्ड इनपुट जांच इनपुट से छोटा है
- जांच इनपुट काफी बड़ा है
यहां इनमें से कोई भी बात सच नहीं है। हमारी अपेक्षा यह होगी कि इस क्वेरी और डेटा सेट के लिए सबसे अच्छी योजना मर्ज जॉइन होगी, जो हमारे दो फ़िल्टर किए गए इंडेक्स से उपलब्ध ऑर्डर किए गए इनपुट का शोषण करेगी। हम दो अतिरिक्त चालू . को बनाए रखते हुए, एक मर्ज जॉइन का संकेत देने का प्रयास कर सकते हैं क्लॉज विधेय:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); योजना का आकार वैसा ही है जैसा हमें उम्मीद थी:
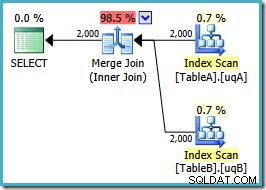
फ़िल्टर किए गए इंडेक्स दोनों का एक ऑर्डर किया गया स्कैन, बढ़िया कार्डिनैलिटी अनुमान, शानदार। बस एक छोटी सी समस्या:यह निष्पादन योजना बहुत खराब है; अनुमानित लागत 0.0772056 से बढ़कर 0.741527 . हो गई है . मर्ज जॉइन ऑपरेटर की संपत्तियों की जांच से अनुमानित लागत में उछाल का कारण पता चलता है:
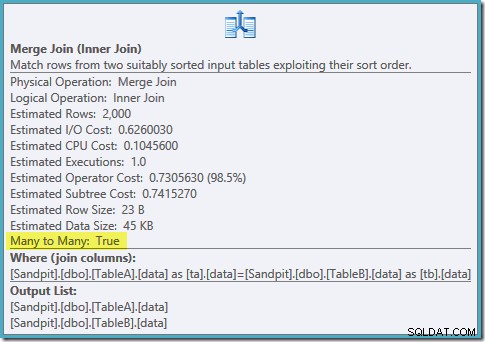
यह एक महंगा कई-से-अनेक जॉइन है, जहां निष्पादन इंजन को वर्कटेबल में बाहरी इनपुट से डुप्लिकेट का ट्रैक रखना चाहिए, और आवश्यकतानुसार रिवाइंड करना चाहिए। डुप्लीकेट? हम एक अद्वितीय अनुक्रमणिका स्कैन कर रहे हैं! यह पता चला है कि ऑप्टिमाइज़र को यह नहीं पता है कि फ़िल्टर की गई अद्वितीय अनुक्रमणिका अद्वितीय मान उत्पन्न करती है (यहां आइटम कनेक्ट करें)। वास्तव में यह एक-से-एक जॉइन है, लेकिन ऑप्टिमाइज़र इसकी लागत ऐसे लेता है जैसे कि यह कई-से-अनेक थे, यह बताते हुए कि यह हैश जॉइन प्लान को क्यों पसंद करता है।
एक वैकल्पिक रणनीति
ऐसा लगता है कि हम यहां फ़िल्टर किए गए इंडेक्स का उपयोग करते समय ऑप्टिमाइज़र सीमाओं के खिलाफ आते रहते हैं (यह बुक्स ऑनलाइन में हाइलाइट किए गए उपयोग के मामले के बावजूद)। यदि हम इसके बजाय दृश्यों का उपयोग करने का प्रयास करते हैं तो क्या होगा?
दृश्यों का उपयोग करना
निम्न दो दृश्य केवल उन पंक्तियों को दिखाने के लिए आधार तालिकाओं को फ़िल्टर करते हैं जहां डेटा स्तंभ है शून्य नहीं :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; विचारों का उपयोग करने के लिए मूल क्वेरी को फिर से लिखना तुच्छ है:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; याद रखें कि इस क्वेरी ने मूल रूप से एक समानांतर नेस्टेड लूप योजना तैयार की थी जिसकी कीमत 7.7768 थी इकाइयां दृश्य संदर्भों के साथ, हमें यह निष्पादन योजना मिलती है:
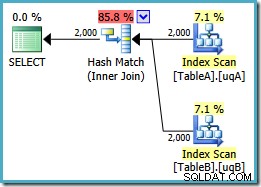
यह बिल्कुल वैसी ही हैश जॉइन योजना है जिसमें हमें अनावश्यक जोड़ना था NOT NULL फ़िल्टर किए गए इंडेक्स के साथ आने की भविष्यवाणी करता है (लागत 0.0772056 . है पहले की तरह इकाइयां)। यह अपेक्षित है, क्योंकि हमने यहां अनिवार्य रूप से जो कुछ किया है वह अतिरिक्त NOT NULL . को आगे बढ़ाने के लिए है क्वेरी से एक दृश्य की भविष्यवाणी करता है।
दृश्यों को अनुक्रमित करना
हम pk कॉलम पर एक अद्वितीय क्लस्टर इंडेक्स बनाकर विचारों को मूर्त रूप देने का भी प्रयास कर सकते हैं:
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
अब हम अनुक्रमित दृश्य में फ़िल्टर किए गए डेटा कॉलम पर अद्वितीय गैर-संकुल अनुक्रमणिका जोड़ सकते हैं:
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
ध्यान दें कि फ़िल्टरिंग दृश्य में की जाती है, ये गैर-संकुल अनुक्रमणिका स्वयं फ़िल्टर नहीं की जाती हैं।
उत्तम योजना
अब हम NOEXPAND का उपयोग करके, दृश्य के विरुद्ध अपनी क्वेरी चलाने के लिए तैयार हैं तालिका संकेत:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; निष्पादन योजना है:
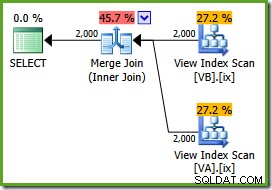
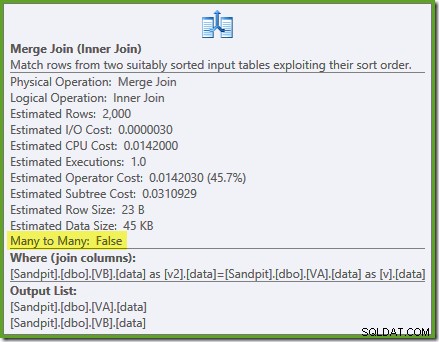
अनुकूलक अनफ़िल्टर्ड देख सकता है गैर-संकुल दृश्य अनुक्रमणिका अद्वितीय हैं, इसलिए कई-से-अनेक मर्ज में शामिल होने की आवश्यकता नहीं है। इस अंतिम निष्पादन योजना की अनुमानित लागत 0.0310929 . है इकाइयाँ - हैश जॉइन प्लान (0.0772056 यूनिट) से भी कम। यह हमारी अपेक्षा की पुष्टि करता है कि मर्ज जॉइन की इस क्वेरी और नमूना डेटा सेट के लिए न्यूनतम अनुमानित लागत होनी चाहिए।
NOEXPAND एंटरप्राइज़ संस्करण में भी संकेतों की आवश्यकता होती है ताकि यह सुनिश्चित किया जा सके कि व्यू इंडेक्स द्वारा प्रदान की गई विशिष्टता गारंटी ऑप्टिमाइज़र द्वारा उपयोग की जाती है।
सारांश
यह पोस्ट फ़िल्टर्ड इंडेक्स के साथ दो महत्वपूर्ण ऑप्टिमाइज़र सीमाओं पर प्रकाश डालता है:
- फ़िल्टर किए गए अनुक्रमणिका से मिलान करने के लिए अनावश्यक शामिल विधेय आवश्यक हो सकते हैं
- फ़िल्टर की गई अद्वितीय अनुक्रमणिका अनुकूलक को विशिष्ट जानकारी प्रदान नहीं करती हैं
कुछ मामलों में प्रत्येक क्वेरी में केवल निरर्थक विधेय जोड़ना व्यावहारिक हो सकता है। वैकल्पिक रूप से वांछित निहित विधेय को एक अनइंडेक्स्ड दृश्य में एनकैप्सुलेट करना है। इस पोस्ट में हैश मैच योजना डिफ़ॉल्ट योजना से काफी बेहतर थी, भले ही अनुकूलक को थोड़ा बेहतर मर्ज जॉइन योजना खोजने में सक्षम होना चाहिए। कभी-कभी, आपको दृश्य को अनुक्रमित करने और NOEXPAND . का उपयोग करने की आवश्यकता हो सकती है संकेत (मानक संस्करण उदाहरणों के लिए वैसे भी आवश्यक)। अभी भी अन्य परिस्थितियों में, इनमें से कोई भी दृष्टिकोण उपयुक्त नहीं होगा। इसके लिए खेद है :)