इस ब्लॉग के पहले भाग में, हमने एक अच्छे PostgreSQL प्रतिकृति वातावरण से संबंधित कुछ महत्वपूर्ण अवधारणाओं का उल्लेख किया है। अब, आइए देखें कि ClusterControl का उपयोग करके इन सभी चीजों को एक साथ एक आसान तरीके से कैसे संयोजित किया जाए। इसके लिए, हम मानेंगे कि आपके पास ClusterControl स्थापित है, लेकिन यदि नहीं, तो आप आधिकारिक साइट पर जा सकते हैं, या इसे स्थापित करने के लिए आधिकारिक दस्तावेज़ देखें।
PostgreSQL स्ट्रीमिंग प्रतिकृति परिनियोजित करना
ClusterControl से PostgreSQL क्लस्टर का परिनियोजन करने के लिए, डिप्लॉय विकल्प चुनें और आने वाले निर्देशों का पालन करें।
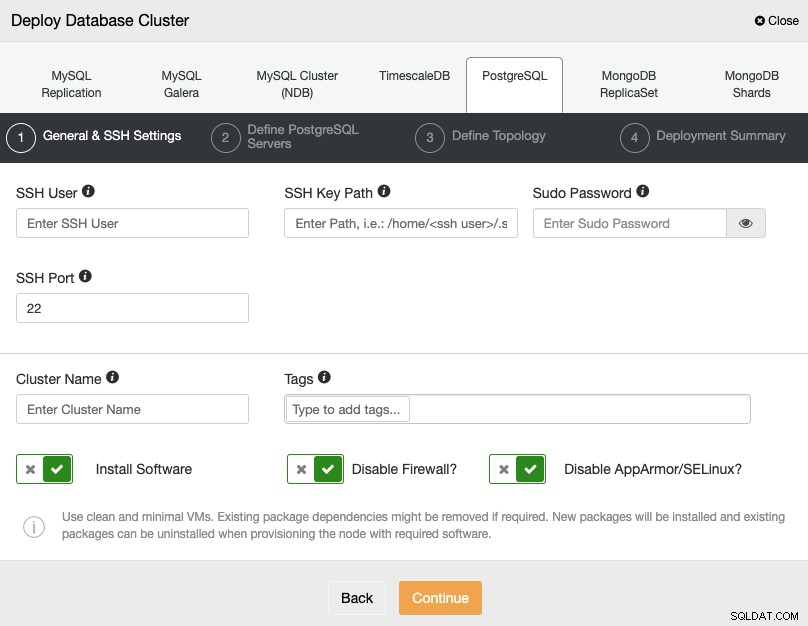
PostgreSQL का चयन करते समय, आपको उपयोगकर्ता, कुंजी या पासवर्ड निर्दिष्ट करना होगा, और SSH द्वारा आपके सर्वर से कनेक्ट करने के लिए पोर्ट। आप अपने नए क्लस्टर के लिए एक नाम भी जोड़ सकते हैं और निर्दिष्ट कर सकते हैं कि क्या आप चाहते हैं कि ClusterControl आपके लिए संबंधित सॉफ़्टवेयर और कॉन्फ़िगरेशन स्थापित करे।
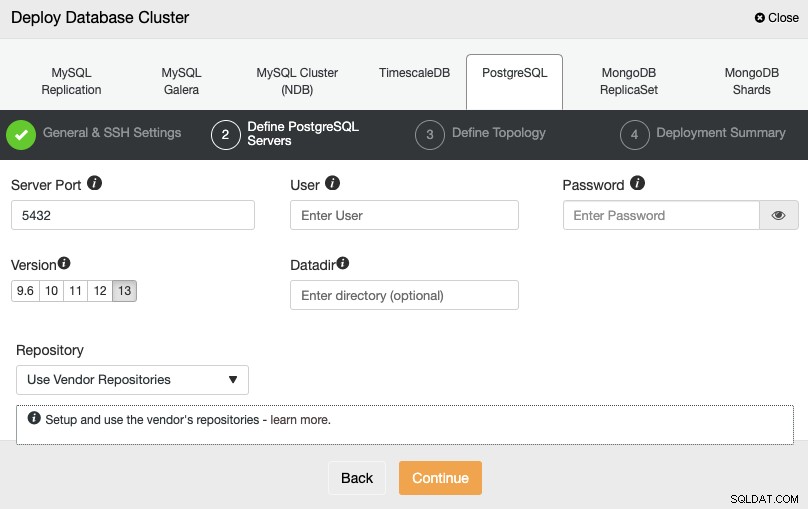
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस क्रेडेंशियल्स को परिभाषित करने की आवश्यकता है , संस्करण, और डेटादिर (वैकल्पिक)। आप यह भी निर्दिष्ट कर सकते हैं कि किस भंडार का उपयोग करना है।
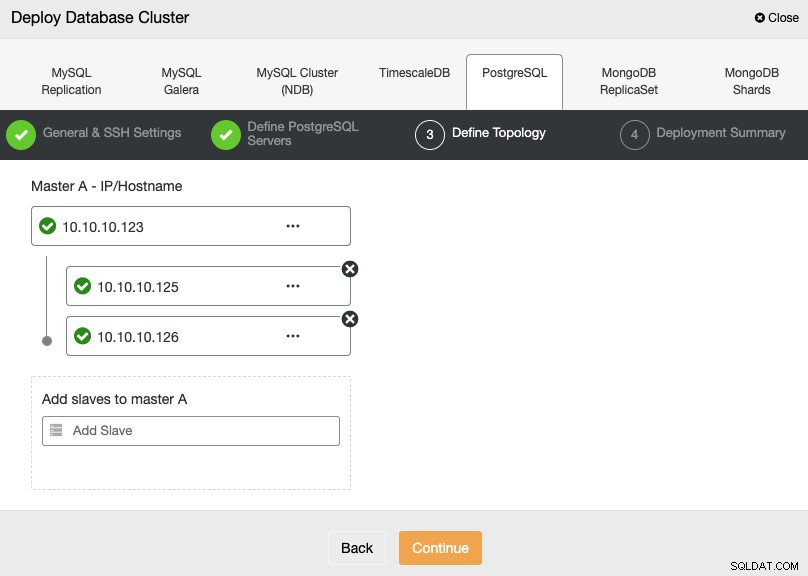
अगले चरण में, आपको अपने सर्वर को उस क्लस्टर में जोड़ना होगा जिसे आप आईपी एड्रेस या होस्टनाम का उपयोग करके बनाने जा रहे हैं।
आखिरी चरण में, आप चुन सकते हैं कि आपकी प्रतिकृति सिंक्रोनस होगी या नहीं एसिंक्रोनस, और फिर डिप्लॉय पर प्रेस करें।
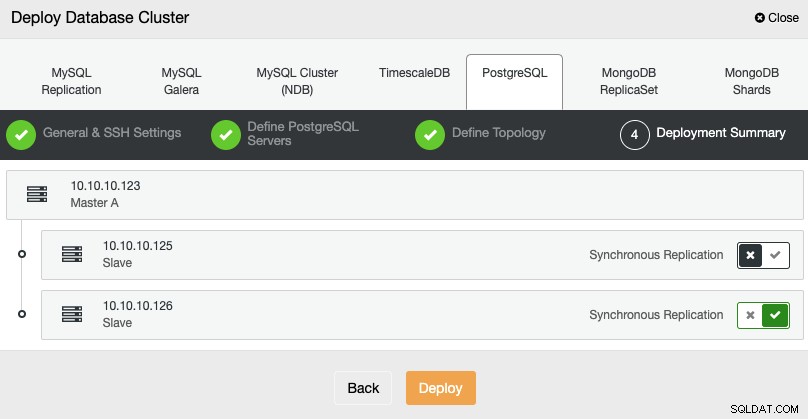
कार्य समाप्त होने के बाद, आप अपना नया PostgreSQL क्लस्टर देख सकते हैं मुख्य क्लस्टर नियंत्रण स्क्रीन।

अब आपने अपना क्लस्टर बना लिया है, आप उस पर कई कार्य कर सकते हैं, जैसे लोड बैलेंसर (HAProxy), कनेक्शन पूलर (PgBouncer), या एक नया सिंक्रोनस या एसिंक्रोनस प्रतिकृति दास जोड़ना।
तुल्यकालिक और अतुल्यकालिक प्रतिकृति दास जोड़ना
ClusterControl पर जाएँ -> क्लस्टर क्रियाएँ -> प्रतिकृति स्लेव जोड़ें।
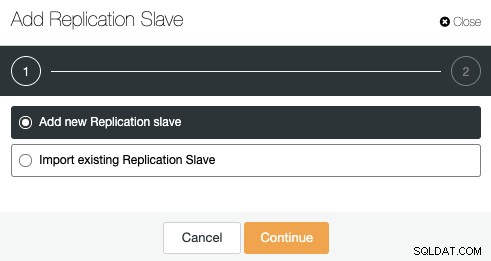
आप एक नया प्रतिकृति दास जोड़ सकते हैं, या यहां तक कि एक मौजूदा आयात भी कर सकते हैं। आइए पहला विकल्प चुनें और जारी रखें।
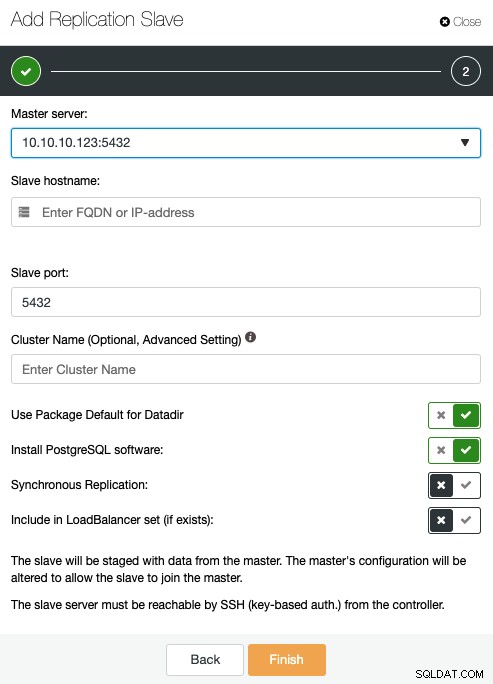
यहां, आपको इसका मास्टर सर्वर, आईपी पता या होस्टनाम निर्दिष्ट करने की आवश्यकता है नया प्रतिकृति दास, पोर्ट, और यदि आप चाहते हैं कि ClusterControl सॉफ़्टवेयर स्थापित करें, या इस नोड को मौजूदा लोड बैलेंसर में शामिल करें। आप प्रतिकृति को सिंक्रोनस या एसिंक्रोनस होने के लिए भी कॉन्फ़िगर कर सकते हैं।
अब आपके पास संबंधित प्रतिकृतियों के साथ अपना PostgreSQL क्लस्टर है, आइए देखें कि कनेक्शन पूलर जोड़कर प्रदर्शन को कैसे बेहतर बनाया जाए।
PgBouncer परिनियोजन
ClusterControl पर जाएं -> PostgreSQL क्लस्टर चुनें -> क्लस्टर क्रियाएं -> लोड बैलेंसर जोड़ें -> PgBouncer। यहां, आप एक नया PgBouncer नोड तैनात कर सकते हैं जिसे चयनित डेटाबेस नोड में तैनात किया जाएगा, या यहां तक कि एक मौजूदा PgBouncer आयात भी कर सकते हैं।
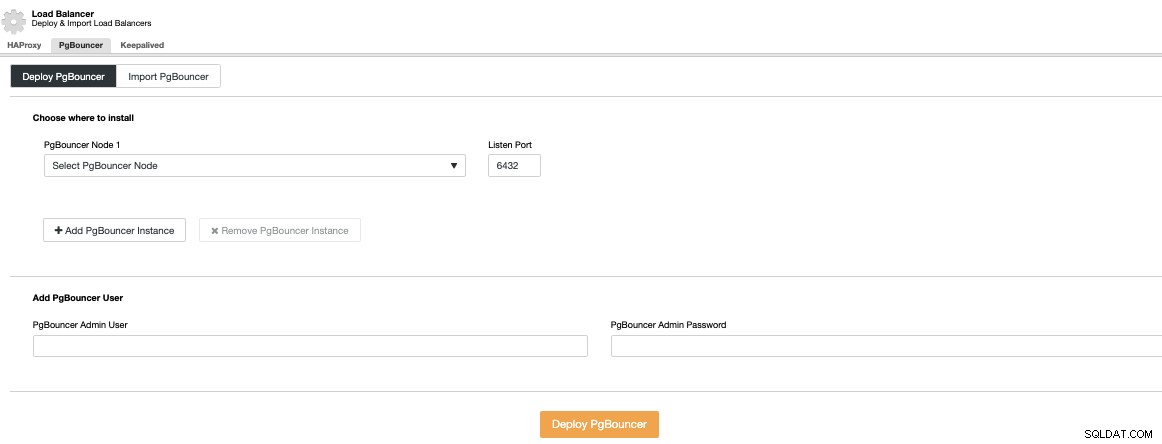
आपको IP पता या होस्टनाम, लिसन पोर्ट और PgBouncer क्रेडेंशियल। जब आप Deploy PgBouncer दबाते हैं, तो ClusterControl नोड को एक्सेस करेगा, बिना किसी मैन्युअल हस्तक्षेप के सब कुछ इंस्टॉल और कॉन्फ़िगर करेगा।
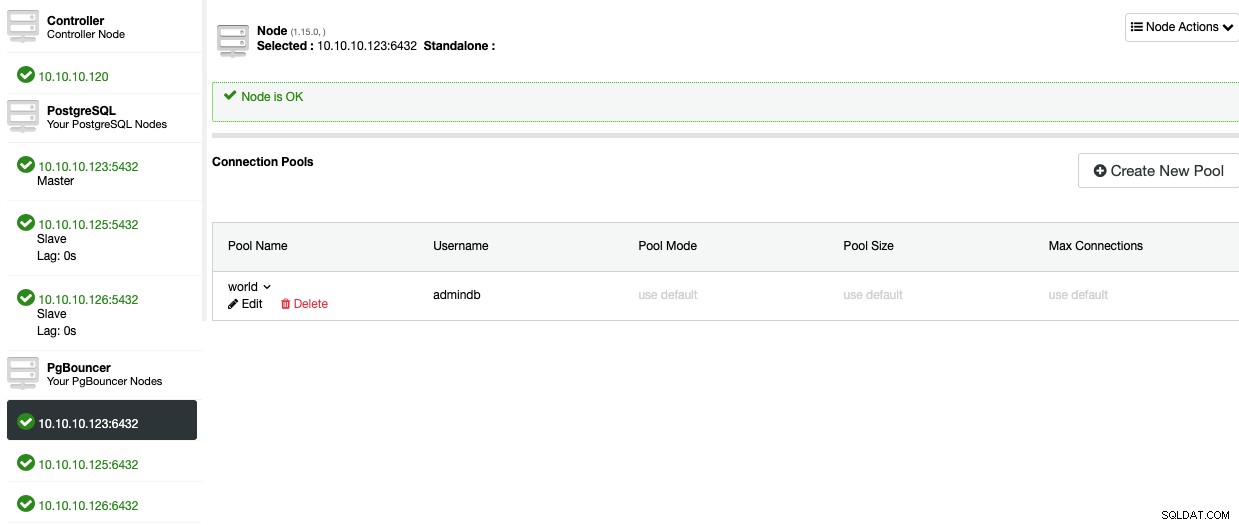
आप ClusterControl गतिविधि अनुभाग में प्रगति की निगरानी कर सकते हैं। जब यह समाप्त हो जाए, तो आपको नया पूल बनाना होगा। इसके लिए, ClusterControl पर जाएँ -> PostgreSQL क्लस्टर चुनें -> Nodes -> PgBouncer नोड।
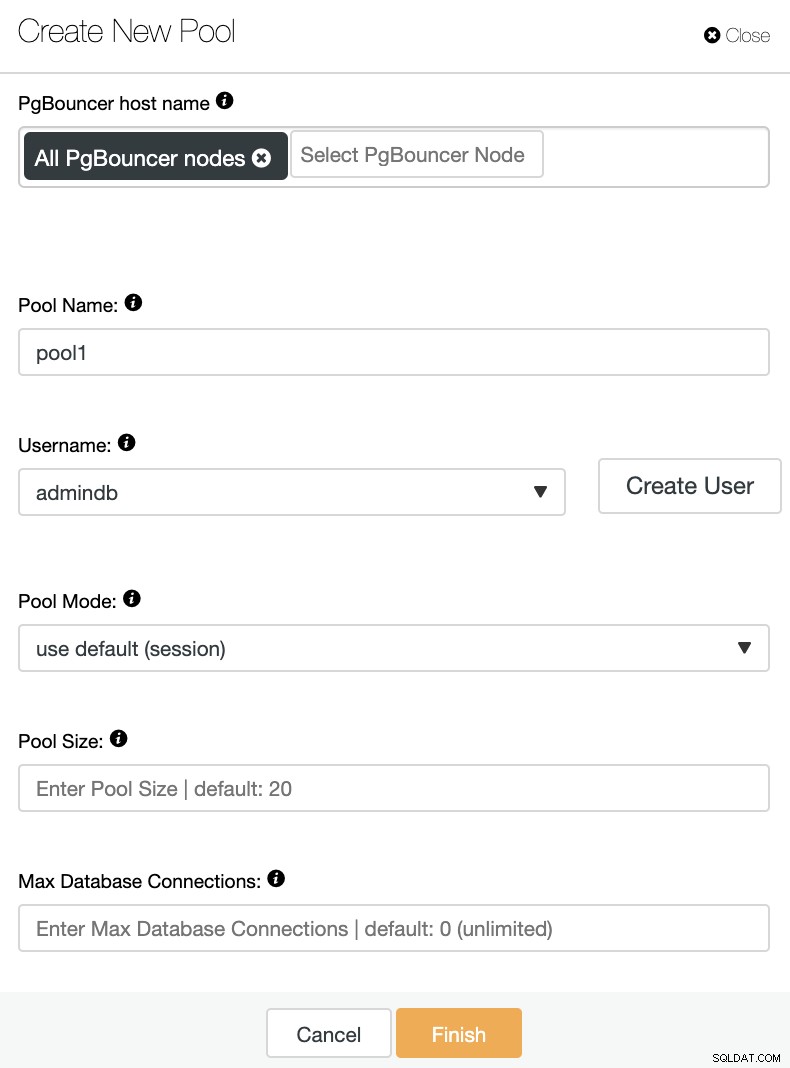
आपको निम्नलिखित जानकारी जोड़नी होगी:
-
PgBouncer hostname:कनेक्शन पूल बनाने के लिए नोड होस्ट का चयन करें।
-
पूल का नाम:पूल और डेटाबेस के नाम समान होने चाहिए।
-
उपयोगकर्ता नाम: PostgreSQL प्राथमिक नोड से एक उपयोगकर्ता चुनें या एक नया बनाएं।
-
पूल मोड:यह हो सकता है:सत्र (डिफ़ॉल्ट), लेन-देन, या स्टेटमेंट पूलिंग।
-
पूल आकार:इस डेटाबेस के लिए पूल का अधिकतम आकार। डिफ़ॉल्ट मान 20 है।
-
अधिकतम डेटाबेस कनेक्शन:एक डेटाबेस-व्यापी अधिकतम कॉन्फ़िगर करें। डिफ़ॉल्ट मान 0 है, जिसका अर्थ है असीमित।
अब, आप पूल को नोड सेक्शन में देख पाएंगे।
अपने PostgreSQL डेटाबेस में उच्च उपलब्धता जोड़ने के लिए, आइए देखें कि एक को कैसे परिनियोजित किया जाए लोड बैलेंसर।
बैलेंसर परिनियोजन लोड करें
लोड बैलेंसर परिनियोजन करने के लिए, क्लस्टर क्रियाएँ मेनू में लोड बैलेंसर जोड़ें विकल्प चुनें और पूछी गई जानकारी को पूरा करें।
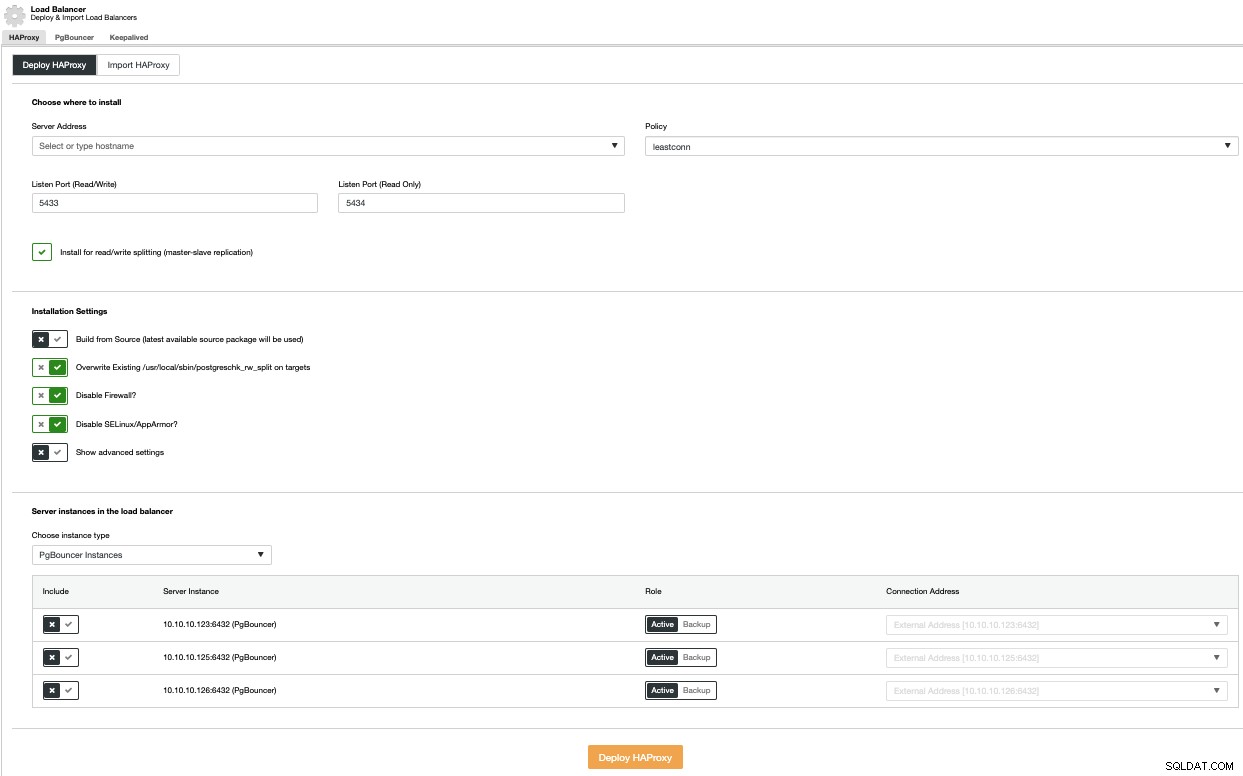
आपको IP या होस्टनाम, पोर्ट, नीति और नोड्स जोड़ने की आवश्यकता है आप उपयोग करने जा रहे हैं। यदि आप PgBouncer का उपयोग कर रहे हैं, तो आप इसे इंस्टेंस टाइप कॉम्बो बॉक्स में चुन सकते हैं।
विफलता के एक बिंदु से बचने के लिए, आपको कम से कम दो HAProxy नोड्स को तैनात करना चाहिए, और Keepalived का उपयोग करना चाहिए जो आपको अपने एप्लिकेशन में एक वर्चुअल आईपी पते का उपयोग करने की अनुमति देता है जो सक्रिय HAProxy नोड को सौंपा गया है। अगर यह नोड विफल हो जाता है, तो वर्चुअल आईपी पता सेकेंडरी लोड बैलेंसर में माइग्रेट कर दिया जाएगा, ताकि आपका एप्लिकेशन अभी भी हमेशा की तरह काम कर सके।
परिनियोजन बनाए रखा
एक Keepalived परिनियोजन करने के लिए, क्लस्टर क्रियाएँ मेनू में विकल्प लोड बैलेंसर जोड़ें का चयन करें और फिर, Keepalived Tab पर जाएँ।
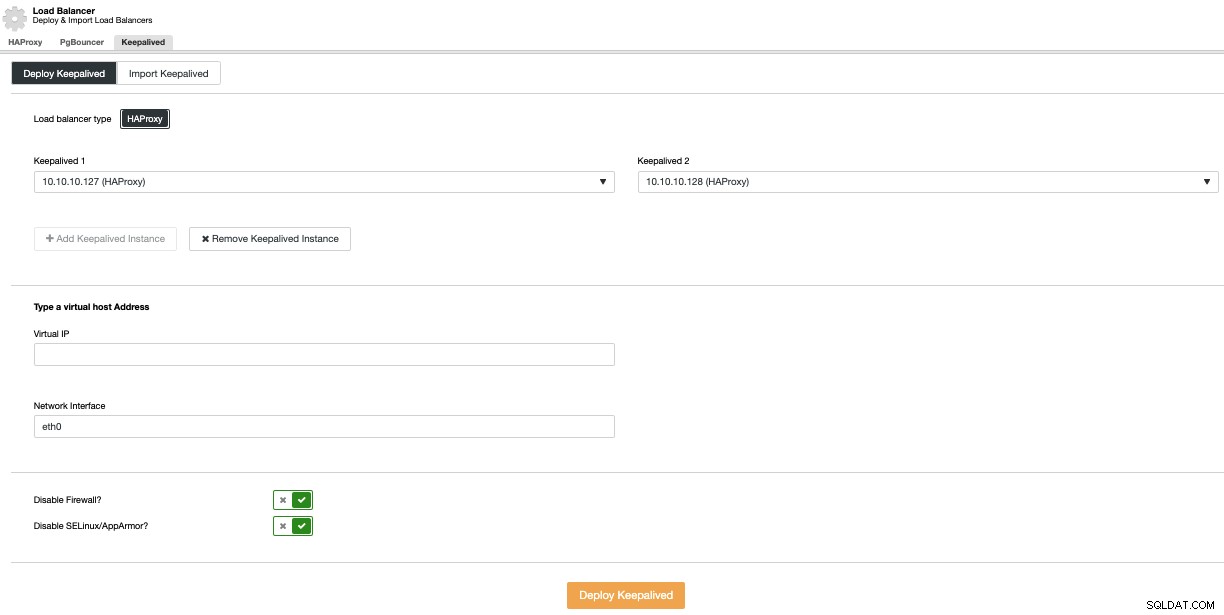
यहां, HAProxy नोड्स चुनें, और वर्चुअल आईपी एड्रेस निर्दिष्ट करें जो डेटाबेस (या कनेक्शन पूलर) तक पहुँचने के लिए इस्तेमाल किया जा सकता है।
इस समय, आपके पास निम्न टोपोलॉजी होनी चाहिए:
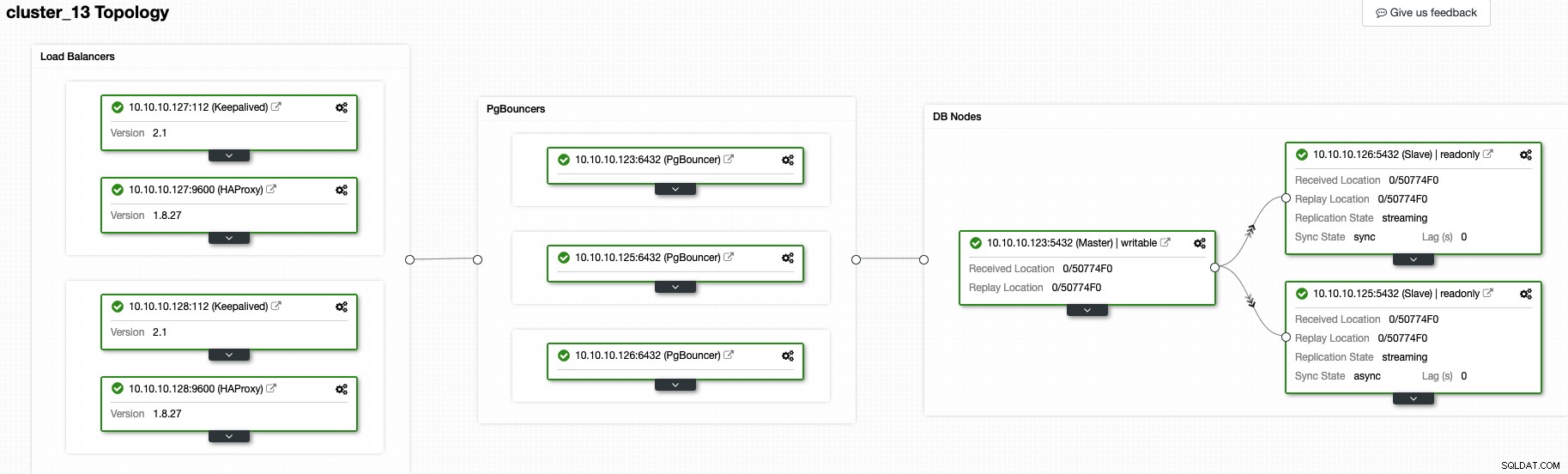
और इसका अर्थ है:HAProxy + Keepalived -> PgBouncer -> PostgreSQL डेटाबेस नोड्स , यह आपके PostgreSQL क्लस्टर के लिए एक अच्छा टोपोलॉजी है।
ClusterControl स्वतः पुनर्प्राप्ति सुविधा
विफल होने की स्थिति में, ClusterControl सबसे उन्नत स्टैंडबाय नोड को प्राथमिक में बढ़ावा देगा और साथ ही आपको समस्या के बारे में सूचित करेगा। यह नए प्राथमिक सर्वर से दोहराने के लिए शेष स्टैंडबाय नोड पर भी विफल रहता है।
डिफ़ॉल्ट रूप से, HAProxy दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है:रीड-राइट और रीड-ओनली। रीड-राइट पोर्ट में, आपके पास अपना प्राथमिक डेटाबेस (या PgBouncer) नोड ऑनलाइन है और बाकी नोड्स ऑफ़लाइन हैं, और रीड-ओनली पोर्ट में, आपके पास प्राथमिक और स्टैंडबाय दोनों नोड ऑनलाइन हैं।
जब HAProxy को पता चलता है कि आपका एक नोड पहुंच योग्य नहीं है, तो यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित कर देता है और इसे ट्रैफ़िक भेजने के लिए ध्यान में नहीं रखता है। जांच स्वास्थ्य जांच स्क्रिप्ट द्वारा की जाती है जिसे परिनियोजन के समय क्लस्टरकंट्रोल द्वारा कॉन्फ़िगर किया जाता है। ये जाँचते हैं कि क्या इंस्टेंस ऊपर हैं, क्या वे ठीक हो रहे हैं, या केवल-पढ़ने के लिए हैं।
जब ClusterControl एक स्टैंडबाय नोड को बढ़ावा देता है, HAProxy पुराने प्राथमिक को दोनों पोर्ट के लिए ऑफ़लाइन के रूप में चिह्नित करता है और प्रचारित नोड को रीड-राइट पोर्ट में ऑनलाइन रखता है।
यदि आपका सक्रिय HAProxy, जिसे एक वर्चुअल IP पता सौंपा गया है, जिससे आपका सिस्टम कनेक्ट होता है, विफल हो जाता है, Keepalived इस IP पते को आपके निष्क्रिय HAProxy में स्वचालित रूप से माइग्रेट कर देता है। इसका मतलब है कि आपका सिस्टम तब सामान्य रूप से कार्य करना जारी रखने में सक्षम है।
निष्कर्ष
जैसा कि आप देख सकते हैं, एक अच्छा PostgreSQL टोपोलॉजी होना आसान है यदि आप ClusterControl का उपयोग करते हैं और यदि आप PostgreSQL प्रतिकृति के लिए बुनियादी सर्वोत्तम अभ्यास अवधारणाओं का पालन कर रहे हैं। बेशक, सबसे अच्छा वातावरण कार्यभार, हार्डवेयर, एप्लिकेशन आदि पर निर्भर करता है, लेकिन आप इसे एक उदाहरण के रूप में उपयोग कर सकते हैं और टुकड़ों को अपनी आवश्यकता के अनुसार स्थानांतरित कर सकते हैं।