मेरी पिछली पोस्ट में, हमने देखा कि कैसे एक स्केलर एग्रीगेट की विशेषता वाली क्वेरी को ऑप्टिमाइज़र द्वारा अधिक कुशल रूप में बदला जा सकता है। एक अनुस्मारक के रूप में, यह फिर से स्कीमा है:
तालिका dbo.T1 बनाएं (pk पूर्णांक प्राथमिक कुंजी, c1 पूर्णांक शून्य नहीं); तालिका dbo.T2 बनाएं (pk पूर्णांक प्राथमिक कुंजी, c1 पूर्णांक शून्य नहीं); तालिका बनाएं dbo.T3 (पीके पूर्णांक प्राथमिक कुंजी, c1 पूर्णांक बनाएं) NOT NULL);GOINSERT dbo.T1 (pk, c1) सेलेक्ट n, nFROM dbo.Numbers as NWHERE n के बीच 1 और 50000; GO INSERT dbo.T2 (pk, c1) सेलेक्ट pk, c1 से dbo.T1;GOINSERT dbo। T3 (pk, c1) dbo.T1 से pk, c1 चुनें; dbo.T1 (c1) पर GOCREATE INDEX nc1; dbo.T2 (c1) पर INDEX nc1 बनाएं; dbo.T3 (c1) पर INDEX nc1 बनाएं;GOCREATE देखें dbo.V1AS dbo से c1 चुनें।योजना विकल्प
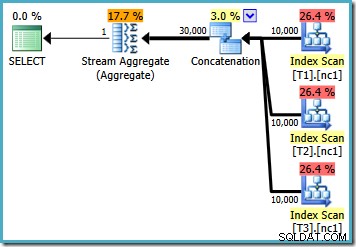
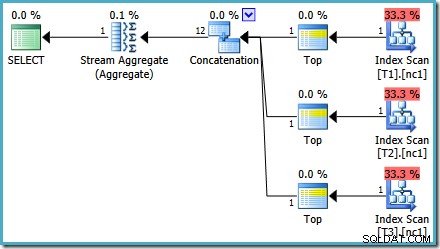
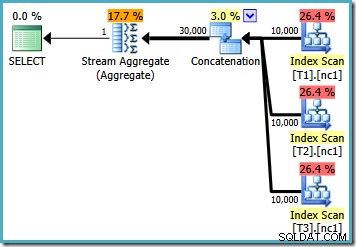
प्रत्येक बेस टेबल में 10,000 पंक्तियों के साथ, ऑप्टिमाइज़र एक साधारण योजना के साथ आता है जो सभी 30,000 पंक्तियों को एक समग्र में पढ़कर अधिकतम की गणना करता है:
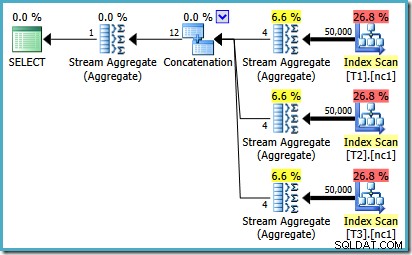
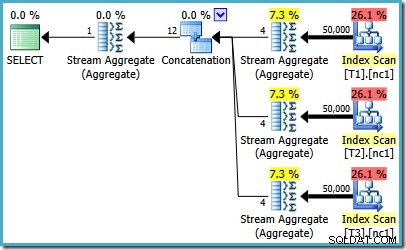
प्रत्येक तालिका में 50,000 पंक्तियों के साथ, अनुकूलक समस्या पर थोड़ा अधिक समय व्यतीत करता है और एक बेहतर योजना ढूंढता है। यह प्रत्येक अनुक्रमणिका से केवल शीर्ष पंक्ति (अवरोही क्रम में) पढ़ता है और फिर केवल उन 3 पंक्तियों से अधिकतम की गणना करता है:
एक अनुकूलक बग
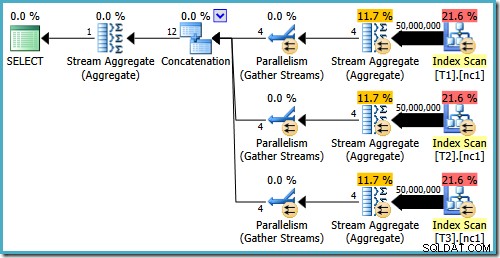
आपको उस अनुमानित . के बारे में कुछ अजीब लग सकता है योजना। Concatenation ऑपरेटर तीन तालिकाओं से एक पंक्ति पढ़ता है और किसी तरह बारह पंक्तियों का उत्पादन करता है! यह एक त्रुटि कार्डिनैलिटी अनुमान में एक बग के कारण है जिसे मैंने मई 2011 में रिपोर्ट किया था। यह अभी भी SQL सर्वर 2014 CTP 1 के रूप में तय नहीं है (भले ही नए कार्डिनैलिटी अनुमानक का उपयोग किया गया हो) लेकिन मुझे आशा है कि इसे संबोधित किया जाएगा अंतिम रिलीज।
यह देखने के लिए कि त्रुटि कैसे उत्पन्न होती है, याद रखें कि 50,000 पंक्ति मामले के लिए अनुकूलक द्वारा विचार किए गए योजना विकल्पों में से एक में Concatenation ऑपरेटर के नीचे आंशिक समुच्चय है:
यह इन आंशिक
MAX. के लिए कार्डिनैलिटी अनुमान है समुच्चय जिसमें दोष है। वे चार पंक्तियों का अनुमान लगाते हैं जहां परिणाम एक पंक्ति होने की गारंटी है। आप चार के अलावा एक नंबर देख सकते हैं - यह इस बात पर निर्भर करता है कि योजना के संकलन के समय कितने तार्किक प्रोसेसर ऑप्टिमाइज़र के लिए उपलब्ध हैं (अधिक विवरण के लिए ऊपर बग लिंक देखें)।ऑप्टिमाइज़र बाद में आंशिक समुच्चय को शीर्ष (1) ऑपरेटरों से बदल देता है, जो कार्डिनैलिटी अनुमान को सही ढंग से पुनर्गणना करता है। अफसोस की बात है कि कॉन्सटेनेशन ऑपरेटर अभी भी बदले हुए आंशिक समुच्चय (3 * 4 =12) के अनुमानों को दर्शाता है। नतीजतन, हम एक संयोजन के साथ समाप्त होते हैं जो 3 पंक्तियों को पढ़ता है और 12 उत्पन्न करता है।
MAX के बजाय TOP का उपयोग करना
50,000 पंक्ति योजना को फिर से देखने पर, ऐसा लगता है कि अनुकूलक द्वारा पाया गया सबसे बड़ा सुधार सभी पंक्तियों को पढ़ने और पाशविक बल का उपयोग करके अधिकतम मूल्य की गणना करने के बजाय शीर्ष (1) ऑपरेटरों का उपयोग करना है। क्या होता है अगर हम कुछ इसी तरह की कोशिश करते हैं और टॉप का उपयोग करके स्पष्ट रूप से क्वेरी को फिर से लिखते हैं?
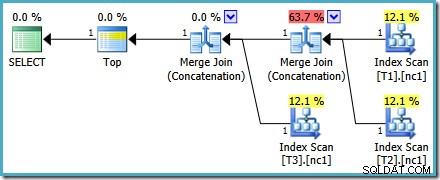
शीर्ष चुनें (1) c1dbo.V1ORDER BY c1 DESC;नई क्वेरी के लिए निष्पादन योजना है:
यह योजना अनुकूलक द्वारा
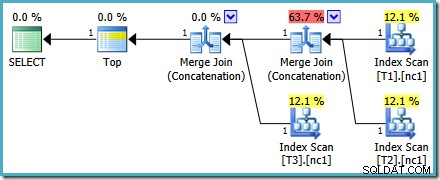
MAX. के लिए चुनी गई योजना से काफी भिन्न है सवाल। इसमें तीन ऑर्डर किए गए इंडेक्स स्कैन, दो मर्ज जॉइन कॉनटेनेशन मोड में चल रहे हैं, और एक सिंगल टॉप ऑपरेटर है। इस नई क्वेरी योजना में कुछ दिलचस्प विशेषताएं हैं जो थोड़ी विस्तार से जांच करने योग्य हैं।योजना विश्लेषण
पहली पंक्ति (अवरोही अनुक्रमणिका क्रम में) प्रत्येक तालिका के गैर-संकुल सूचकांक से पढ़ी जाती है, और एक मर्ज जॉइन ऑपरेटिंग मोड में संचालन का उपयोग किया जाता है। हालांकि मर्ज जॉइन ऑपरेटर सामान्य अर्थों में जॉइन नहीं कर रहा है, इस ऑपरेटर के प्रोसेसिंग एल्गोरिदम को जॉइन मानदंड लागू करने के बजाय इसके इनपुट को संयोजित करने के लिए आसानी से अनुकूलित किया जाता है।
नई योजना में इस ऑपरेटर का उपयोग करने का लाभ यह है कि मर्ज कॉन्सटेनेशन अपने इनपुट में सॉर्ट ऑर्डर को बरकरार रखता है। इसके विपरीत, एक नियमित Concatenation ऑपरेटर अपने इनपुट से क्रम में पढ़ता है। नीचे दिया गया चित्र अंतर दिखाता है (विस्तार करने के लिए क्लिक करें):
मर्ज कॉन्सटेनेशन के आदेश-संरक्षण व्यवहार का अर्थ है कि नई योजना में सबसे बाईं ओर मर्ज ऑपरेटर द्वारा निर्मित पहली पंक्ति को सभी तीन तालिकाओं में कॉलम c1 में उच्चतम मान वाली पंक्ति होने की गारंटी है। अधिक विशेष रूप से, योजना निम्नानुसार संचालित होती है:
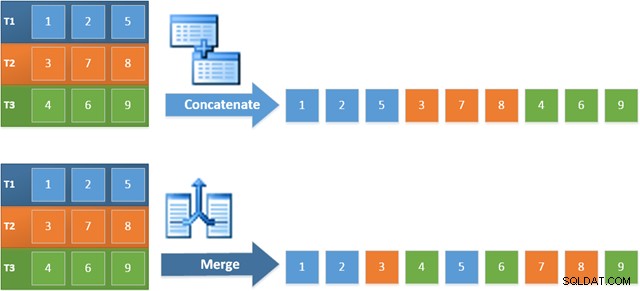
- एक पंक्ति प्रत्येक तालिका से पढ़ा जाता है (सूचकांक अवरोही क्रम में); और
- प्रत्येक मर्ज एक परीक्षण करता है यह देखने के लिए कि इसकी किस इनपुट पंक्ति का मान अधिक है
यह एक बहुत ही कुशल रणनीति लगती है, इसलिए यह अजीब लग सकता है कि अनुकूलक का MAX योजना की अनुमानित लागत नई योजना के आधे से भी कम है। काफी हद तक, इसका कारण यह है कि ऑर्डर-संरक्षित मर्ज कॉन्सटेनेशन को एक साधारण कॉन्सटेनेशन की तुलना में अधिक महंगा माना जाता है। ऑप्टिमाइज़र को यह एहसास नहीं होता है कि प्रत्येक मर्ज कभी भी अधिकतम एक पंक्ति देख सकता है, और परिणामस्वरूप इसकी लागत का अधिक अनुमान लगाता है।
अधिक लागत संबंधी मुद्दे
कड़ाई से बोलते हुए हम यहां सेब के साथ सेब की तुलना नहीं कर रहे हैं, क्योंकि दोनों योजनाएं अलग-अलग प्रश्नों के लिए हैं। इस तरह की लागतों की तुलना करना आम तौर पर एक वैध बात नहीं है, हालांकि एसएसएमएस एक बैच में विभिन्न विवरणों के लिए लागत प्रतिशत प्रदर्शित करके ठीक यही करता है। लेकिन, मैं पछताता हूं।
अगर आप SQL सेंट्री प्लान एक्सप्लोरर के बजाय SSMS में नए प्लान को देखेंगे तो आपको कुछ इस तरह दिखाई देगा:
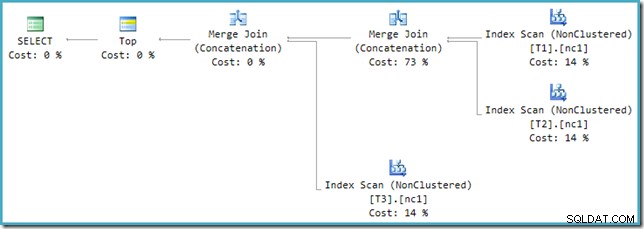
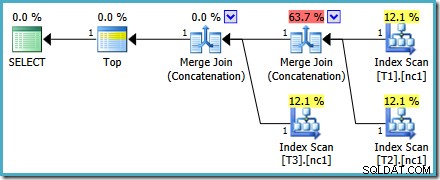
मर्ज जॉइन कॉन्सटेनेशन ऑपरेटरों में से एक की अनुमानित लागत 73% है, जबकि दूसरी (बिल्कुल समान पंक्तियों पर काम करने वाली) को लागत के रूप में बिल्कुल भी नहीं दिखाया गया है। एक और संकेत है कि यहां कुछ गलत है कि इस योजना में ऑपरेटर लागत प्रतिशत 100% नहीं है।
ऑप्टिमाइज़र बनाम एक्ज़ीक्यूशन इंजन
समस्या अनुकूलक और निष्पादन इंजन के बीच असंगति में है। ऑप्टिमाइज़र में, Union और Union All में 2 या अधिक इनपुट हो सकते हैं। निष्पादन इंजन में, केवल Concatenation ऑपरेटर 2 या अधिक को स्वीकार करने में सक्षम है इनपुट; मर्ज जॉइन की आवश्यकता है बिल्कुल दो इनपुट, तब भी जब एक जुड़ने के बजाय एक संयोजन करने के लिए कॉन्फ़िगर किया गया हो।
इस असंगति को हल करने के लिए, ऑप्टिमाइज़र के आउटपुट ट्री को एक ऐसे रूप में अनुवाद करने के लिए पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन लागू किया जाता है जिसे निष्पादन इंजन संभाल सकता है। जहां एक संघ या संघ सभी दो से अधिक इनपुट के साथ मर्ज का उपयोग करके कार्यान्वित किया जाता है, ऑपरेटरों की एक श्रृंखला की आवश्यकता होती है। संघ को तीन इनपुट के साथ सभी वर्तमान मामले में, दो मर्ज यूनियनों की आवश्यकता है:
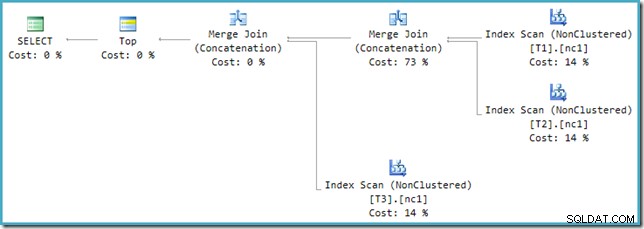
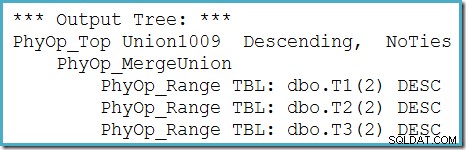
हम ट्रेस फ़्लैग 8607 का उपयोग करके ऑप्टिमाइज़र के आउटपुट ट्री (भौतिक मर्ज यूनियन में तीन इनपुट के साथ) देख सकते हैं:
एक अधूरा सुधार
दुर्भाग्य से, पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन पूरी तरह से लागू नहीं किया गया है। यह लागत संख्या में थोड़ा गड़बड़ करता है। मुद्दों को अलग करते हुए, योजना की लागत 114% तक बढ़ जाती है और अतिरिक्त 14% इनपुट से अतिरिक्त मर्ज जॉइन कॉन्सटेनेशन में पुनर्लेखन द्वारा उत्पन्न होता है:
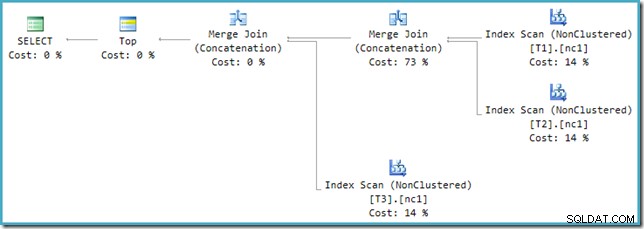
इस योजना में सबसे दाहिना मर्ज ऑप्टिमाइज़र के आउटपुट ट्री में मूल ऑपरेटर है। इसे यूनियन ऑल ऑपरेशन की पूरी लागत सौंपी गई है। अन्य मर्ज को पुनर्लेखन द्वारा जोड़ा जाता है और एक शून्य लागत प्राप्त करता है।
जिस तरह से हम इसे देखने के लिए चुनते हैं (और ऐसे विभिन्न मुद्दे हैं जो नियमित संयोजन को प्रभावित करते हैं) संख्याएं विषम दिखती हैं। प्लान एक्सप्लोरर कम से कम 100% तक संख्या जोड़ने को सुनिश्चित करके एक्सएमएल योजना में टूटी हुई जानकारी के आसपास काम करने की पूरी कोशिश करता है:
यह विशेष लागत समस्या SQL Server 2014 CTP 1 में ठीक की गई है:
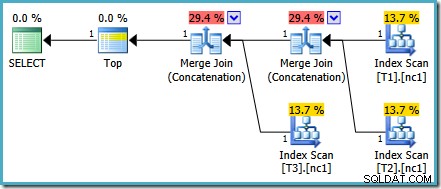
मर्ज कॉन्सटेनेशन की लागत अब दो ऑपरेटरों के बीच समान रूप से विभाजित है, और प्रतिशत 100% तक जुड़ जाता है। चूंकि अंतर्निहित XML को ठीक कर दिया गया है, SSMS भी वही नंबर दिखाने का प्रबंधन करता है।
कौन सी योजना बेहतर है?
अगर हम MAX . का उपयोग करके क्वेरी लिखते हैं , हमें एक कुशल योजना खोजने के लिए आवश्यक अतिरिक्त कार्य करने के लिए अनुकूलक पर निर्भर रहना होगा। यदि अनुकूलक को एक स्पष्ट रूप से पर्याप्त योजना जल्दी मिल जाती है, तो यह अपेक्षाकृत अक्षम योजना तैयार कर सकता है जो प्रत्येक आधार तालिका से प्रत्येक पंक्ति को पढ़ता है:
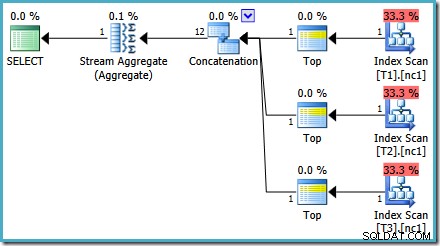
यदि आप SQL Server 2008 या SQL Server 2008 R2 चला रहे हैं, तो आधार तालिका में पंक्तियों की संख्या की परवाह किए बिना ऑप्टिमाइज़र अभी भी एक अक्षम योजना का चयन करेगा। निम्न योजना SQL Server 2008 R2 पर 50,000 पंक्तियों के साथ तैयार की गई थी:
यहां तक कि प्रत्येक तालिका में 50 मिलियन पंक्तियों के साथ, 2008 और 2008 R2 अनुकूलक केवल समानता जोड़ता है, यह शीर्ष ऑपरेटरों का परिचय नहीं देता है:
जैसा कि मेरी पिछली पोस्ट में बताया गया है, शीर्ष ऑपरेटरों के साथ योजना तैयार करने के लिए SQL Server 2008 और 2008 R2 प्राप्त करने के लिए ट्रेस फ्लैग 4199 की आवश्यकता है। SQL सर्वर 2005 और 2012 के बाद ट्रेस फ़्लैग की आवश्यकता नहीं है:
आदेश के साथ शीर्ष
एक बार जब हम समझ जाते हैं कि पिछली निष्पादन योजनाओं में क्या चल रहा है, तो हम ORDER BY के साथ एक स्पष्ट TOP का उपयोग करके क्वेरी को फिर से लिखने के लिए एक सचेत (और सूचित) विकल्प बना सकते हैं:
शीर्ष चुनें (1) c1dbo.V1ORDER BY c1 DESC;
परिणामी निष्पादन योजना में लागत प्रतिशत हो सकते हैं जो SQL सर्वर के कुछ संस्करणों में अजीब लगते हैं, लेकिन अंतर्निहित योजना ध्वनि है। पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन, जिसके कारण संख्याएँ विषम दिखती हैं, क्वेरी ऑप्टिमाइज़ेशन पूर्ण होने के बाद लागू की जाती हैं, इसलिए हम यह सुनिश्चित कर सकते हैं कि ऑप्टिमाइज़र का योजना चयन इस समस्या से प्रभावित नहीं हुआ था।
आधार तालिका में पंक्तियों की संख्या के आधार पर यह योजना नहीं बदलती है, और उत्पन्न करने के लिए किसी ट्रेस फ़्लैग की आवश्यकता नहीं होती है। एक छोटा अतिरिक्त लाभ यह है कि यह योजना अनुकूलक द्वारा लागत-आधारित अनुकूलन के पहले चरण के दौरान पाई जाती है (खोज 0):
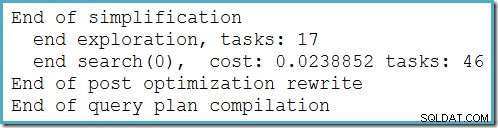
अनुकूलक द्वारा MAX . के लिए चुनी गई सर्वोत्तम योजना लागत-आधारित अनुकूलन के दो चरणों को चलाने के लिए आवश्यक क्वेरी (खोज 0 और खोज 1).
TOP . के बीच एक छोटा सा अर्थ अंतर है क्वेरी और मूल MAX जिस रूप का मुझे उल्लेख करना चाहिए। यदि किसी भी तालिका में कोई पंक्ति नहीं है, तो मूल क्वेरी एक एकल NULL produce उत्पन्न करेगी नतीजा। प्रतिस्थापन TOP (1) query समान परिस्थितियों में बिल्कुल भी आउटपुट नहीं देता है। वास्तविक दुनिया के प्रश्नों में यह अंतर अक्सर महत्वपूर्ण नहीं होता है, लेकिन इसके बारे में पता होना चाहिए। हम TOP . के व्यवहार को दोहरा सकते हैं MAX . का उपयोग करके SQL सर्वर 2008 में एक खाली सेट GROUP BY जोड़कर आगे की ओर :
dbo.V1GROUP BY () से MAX(c1)चुनें;
यह परिवर्तन MAX . के लिए जेनरेट की गई निष्पादन योजनाओं को प्रभावित नहीं करता है इस तरह से क्वेरी करें जो अंतिम उपयोगकर्ताओं के लिए दृश्यमान हो।
मर्ज संयोजन के साथ MAX
TOP (1) . में मर्ज जॉइन कॉन्सटेनेशन की सफलता को देखते हुए निष्पादन योजना, यह आश्चर्य होना स्वाभाविक है कि मूल MAX . के लिए वही इष्टतम योजना तैयार की जा सकती है या नहीं क्वेरी अगर हम ऑप्टिमाइज़र को UNION ALL के लिए रेगुलर कॉन्सटेनेशन के बजाय मर्ज कॉन्सटेनेशन का उपयोग करने के लिए बाध्य करते हैं ऑपरेशन।
इस उद्देश्य के लिए एक प्रश्न संकेत है - MERGE UNION - लेकिन दुख की बात है कि यह केवल SQL Server 2012 के बाद ही सही ढंग से काम करता है। पिछले संस्करणों में, UNION संकेत केवल UNION को प्रभावित करता है प्रश्न, न कि UNION ALL . SQL सर्वर 2012 में आगे, हम यह कोशिश कर सकते हैं:
dbo.V1OPTION (मर्ज यूनियन) से MAX(c1) चुनें
हमें एक ऐसी योजना से पुरस्कृत किया गया है जिसमें मर्ज कॉन्सटेनेशन की सुविधा है। दुर्भाग्य से, यह वह सब कुछ नहीं है जिसकी हम उम्मीद कर सकते हैं:
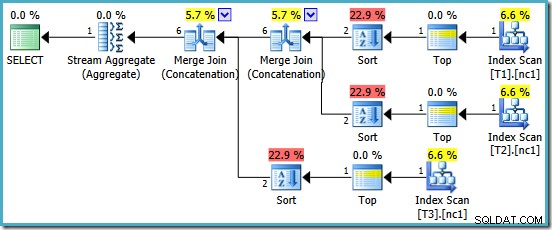
इस योजना में दिलचस्प ऑपरेटर इस प्रकार हैं। 1 पंक्ति इनपुट कार्डिनैलिटी अनुमान, और आउटपुट पर 4 पंक्ति अनुमान पर ध्यान दें। कारण अब तक आप से परिचित होना चाहिए:यह वही आंशिक समग्र कार्डिनैलिटी अनुमान त्रुटि है जिसकी हमने पहले चर्चा की थी।
प्रकार की उपस्थिति आंशिक समुच्चय के साथ एक और समस्या का खुलासा करती है। न केवल वे एक गलत कार्डिनैलिटी अनुमान का उत्पादन करते हैं, वे इंडेक्स ऑर्डरिंग को संरक्षित करने में भी विफल होते हैं जो अनावश्यक सॉर्टिंग कर देगा (मर्ज कॉन्सटेनेशन को सॉर्ट किए गए इनपुट की आवश्यकता होती है)। आंशिक समुच्चय अदिश हैं MAX समुच्चय, एक पंक्ति का उत्पादन करने की गारंटी है, इसलिए आदेश देने का मुद्दा वैसे भी विवादास्पद होना चाहिए (एक पंक्ति को क्रमबद्ध करने का केवल एक ही तरीका है!)
यह शर्म की बात है, क्योंकि इस तरह के बिना यह एक अच्छी निष्पादन योजना होगी। यदि आंशिक समुच्चय ठीक से लागू किए गए थे, और MAX GROUP BY () . के साथ लिखा गया है क्लॉज, हम यह भी उम्मीद कर सकते हैं कि ऑप्टिमाइज़र यह देख सकता है कि तीन टॉप्स और फाइनल स्ट्रीम एग्रीगेट को एक फाइनल टॉप ऑपरेटर द्वारा प्रतिस्थापित किया जा सकता है, जो बिल्कुल स्पष्ट TOP (1) जैसी ही योजना देता है। सवाल। ऑप्टिमाइज़र में आज वह परिवर्तन शामिल नहीं है, और मुझे नहीं लगता कि यह भविष्य में इसके समावेश को सार्थक बनाने के लिए पर्याप्त रूप से उपयोगी होगा।
अंतिम शब्द
TOP का उपयोग करना हमेशा MIN . से बेहतर नहीं होगा या MAX . कुछ मामलों में यह काफी कम इष्टतम योजना तैयार करेगा। इस पोस्ट की बात यह है कि ऑप्टिमाइज़र द्वारा लागू किए गए परिवर्तनों को समझने से मूल क्वेरी को फिर से लिखने के तरीके सुझाए जा सकते हैं जो मददगार साबित हो सकते हैं।