SQL सर्वर क्वेरी निष्पादन इंजन के पास तार्किक 'यूनियन ऑल' ऑपरेशन को लागू करने के दो तरीके हैं, Concatenation और Merge Join Concatenation भौतिक ऑपरेटरों का उपयोग करते हुए। जबकि तार्किक संचालन समान है, दो भौतिक ऑपरेटरों के बीच महत्वपूर्ण अंतर हैं जो आपकी निष्पादन योजनाओं की दक्षता में जबरदस्त अंतर ला सकते हैं।
क्वेरी ऑप्टिमाइज़र कई मामलों में दो विकल्पों के बीच चयन करने का एक उचित काम करता है, लेकिन यह इस क्षेत्र में परिपूर्ण होने का एक लंबा रास्ता तय करता है। यह आलेख मर्ज जॉइन कॉन्सटेनेशन द्वारा प्रस्तुत क्वेरी ट्यूनिंग अवसरों का वर्णन करता है, और आंतरिक व्यवहारों और विचारों का विवरण देता है जिन्हें आपको इसका अधिकतम लाभ उठाने के लिए जागरूक होना चाहिए।
संयोजन

Concatenation ऑपरेटर अपेक्षाकृत सरल है:इसका आउटपुट अनुक्रम में इसके प्रत्येक इनपुट से पूरी तरह से पढ़ने का परिणाम है। Concatenation ऑपरेटर एक n-ary है भौतिक ऑपरेटर, जिसका अर्थ है कि इसमें '2…n' इनपुट हो सकते हैं। उदाहरण के लिए, आइए अपने पिछले लेख, "प्रदर्शन में सुधार के लिए प्रश्नों को फिर से लिखना" से एडवेंचरवर्क्स-आधारित उदाहरण पर फिर से विचार करें:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
निम्नलिखित क्वेरी छह विशेष उत्पादों के लिए उत्पाद और लेनदेन आईडी सूचीबद्ध करती है:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
यह एक निष्पादन योजना तैयार करता है जिसमें छह इनपुट के साथ एक संयोजन ऑपरेटर होता है, जैसा कि SQL संतरी योजना एक्सप्लोरर में देखा गया है:
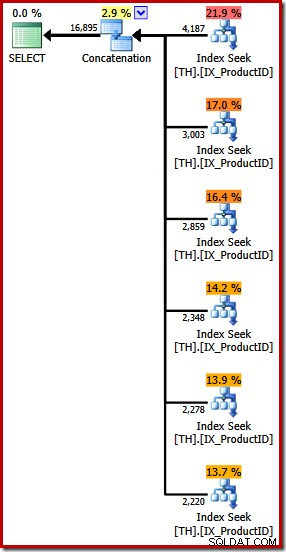
उपरोक्त योजना में प्रत्येक सूचीबद्ध उत्पाद आईडी के लिए एक अलग इंडेक्स सीक की सुविधा है, उसी क्रम में जैसा कि क्वेरी में निर्दिष्ट है (ऊपर नीचे पढ़ना)। शीर्षतम इंडेक्स सीक उत्पाद 870 के लिए है, अगला नीचे उत्पाद 873 के लिए है, फिर 921 और इसी तरह। इनमें से कोई भी निश्चित रूप से गारंटीकृत व्यवहार नहीं है, यह केवल देखने के लिए कुछ दिलचस्प है।
मैंने पहले उल्लेख किया है कि Concatenation ऑपरेटर अनुक्रम में अपने इनपुट से पढ़कर अपना आउटपुट बनाता है। जब इस योजना को क्रियान्वित किया जाता है, तो एक अच्छा मौका है कि परिणाम सेट पहले उत्पाद 870, फिर 873, 921, 712, 707, और अंत में उत्पाद 711 के लिए पंक्तियां दिखाएगा। फिर से, इसकी गारंटी नहीं है क्योंकि हमने ऑर्डर निर्दिष्ट नहीं किया है BY खंड, लेकिन यह दिखाता है कि Concatenation आंतरिक रूप से कैसे संचालित होता है।
एक SSIS "निष्पादन योजना"
उन कारणों के लिए जो एक पल में समझ में आ जाएंगे, विचार करें कि हम समान कार्य करने के लिए SSIS पैकेज कैसे डिज़ाइन कर सकते हैं। हम निश्चित रूप से एसएसआईएस में एक टी-एसक्यूएल स्टेटमेंट के रूप में पूरी चीज लिख सकते हैं, लेकिन अधिक दिलचस्प विकल्प प्रत्येक उत्पाद के लिए एक अलग डेटा स्रोत बनाना है, और एसक्यूएल सर्वर कॉन्सटेनेशन के स्थान पर एसएसआईएस "यूनियन ऑल" घटक का उपयोग करना है। ऑपरेटर:
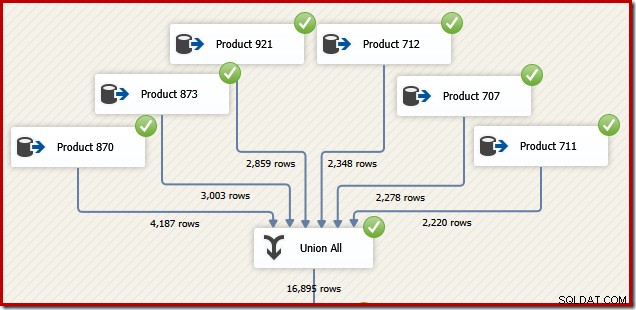
अब कल्पना करें कि हमें ट्रांजेक्शन आईडी क्रम में उस डेटा प्रवाह से अंतिम आउटपुट की आवश्यकता है। यूनियन ऑल के बाद एक स्पष्ट सॉर्ट घटक जोड़ना एक विकल्प होगा:
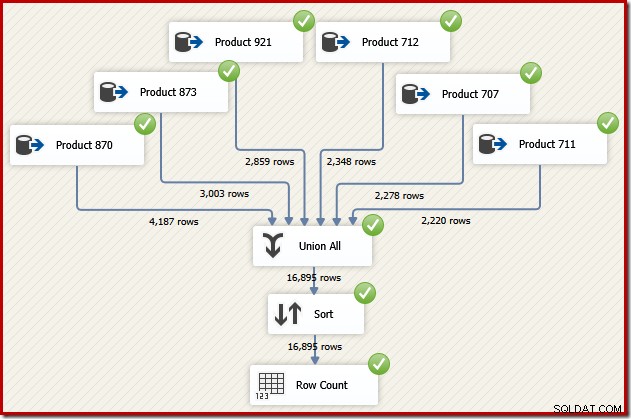
यह निश्चित रूप से काम करेगा, लेकिन एक कुशल और अनुभवी एसएसआईएस डिजाइनर को एहसास होगा कि एक बेहतर विकल्प है:लेनदेन आईडी क्रम में प्रत्येक उत्पाद के लिए स्रोत डेटा पढ़ें (सूचकांक का उपयोग करके), फिर सेट को संयोजित करने के लिए ऑर्डर-संरक्षण ऑपरेशन का उपयोग करें ।
SSIS में, दो सॉर्ट किए गए डेटा प्रवाह से पंक्तियों को एक एकल सॉर्ट किए गए डेटा प्रवाह में संयोजित करने वाले घटक को "मर्ज" कहा जाता है। लेन-देन आईडी क्रम में वांछित पंक्तियों को वापस करने के लिए मर्ज का उपयोग करने वाला एक पुन:डिज़ाइन किया गया SSIS डेटा प्रवाह निम्नानुसार है:
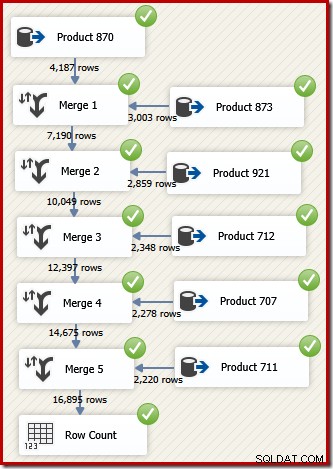
ध्यान दें कि हमें पांच अलग-अलग मर्ज घटकों की आवश्यकता है क्योंकि मर्ज एक बाइनरी घटक है, एसएसआईएस "यूनियन ऑल" घटक के विपरीत, जो कि n-ary था। . नया मर्ज प्रवाह एक महंगे (और अवरुद्ध) सॉर्ट घटक की आवश्यकता के बिना, लेनदेन आईडी क्रम में परिणाम उत्पन्न करता है। वास्तव में, अगर हम अंतिम मर्ज के बाद ट्रांजेक्शन आईडी पर एक सॉर्ट जोड़ने का प्रयास करते हैं, तो एसएसआईएस हमें यह बताने के लिए एक चेतावनी दिखाता है कि स्ट्रीम पहले से ही वांछित फैशन में क्रमबद्ध है:
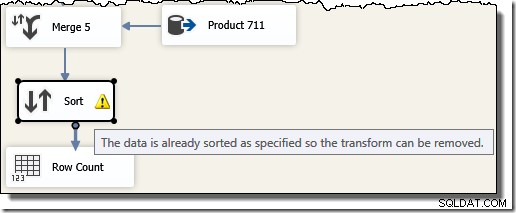
एसएसआईएस उदाहरण की बात अब सामने आ सकती है। SQL सर्वर क्वेरी ऑप्टिमाइज़र द्वारा चुनी गई निष्पादन योजना को देखें, जब हम इसे मूल T-SQL क्वेरी परिणामों को ट्रांज़ैक्शन आईडी क्रम में वापस करने के लिए कहते हैं (एक ORDER BY क्लॉज जोड़कर):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
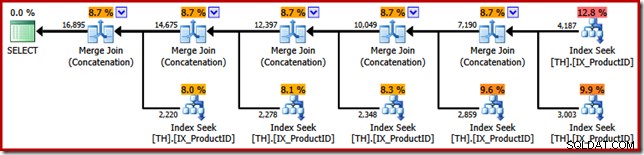
एसएसआईएस मर्ज पैकेज की समानताएं हड़ताली हैं; यहां तक कि पांच बाइनरी "मर्ज" ऑपरेटरों की आवश्यकता के लिए भी। एक महत्वपूर्ण अंतर यह है कि एसएसआईएस में "मर्ज जॉइन" और "मर्ज" के लिए अलग-अलग घटक हैं जबकि SQL सर्वर दोनों के लिए एक ही कोर ऑपरेटर का उपयोग करता है।
स्पष्ट होने के लिए, SQL सर्वर निष्पादन योजना में मर्ज जॉइन (Concatenation) ऑपरेटर नहीं हैं शामिल होने का प्रदर्शन; आदेश-संरक्षण संघ को लागू करने के लिए इंजन केवल उसी भौतिक ऑपरेटर का पुन:उपयोग करता है।
एसक्यूएल सर्वर में निष्पादन योजनाएं लिखना
SSIS के पास डेटा प्रवाह विनिर्देश भाषा नहीं है, और न ही ऐसे विनिर्देशन को निष्पादन योग्य डेटा प्रवाह कार्य में बदलने के लिए कोई अनुकूलक नहीं है। यह SSIS पैकेज डिज़ाइनर पर निर्भर है कि वह यह महसूस करे कि ऑर्डर-संरक्षण मर्ज संभव है, घटक गुण (जैसे सॉर्ट कुंजियाँ) को उचित रूप से सेट करें, फिर प्रदर्शन की तुलना करें। इसके लिए डिज़ाइनर की ओर से अधिक प्रयास (और कौशल) की आवश्यकता होती है, लेकिन यह नियंत्रण की एक बहुत अच्छी डिग्री प्रदान करता है।
SQL सर्वर में स्थिति विपरीत है:हम एक क्वेरी लिखते हैं विनिर्देश टी-एसक्यूएल भाषा का उपयोग करते हुए, फिर कार्यान्वयन विकल्पों का पता लगाने और एक कुशल चुनने के लिए क्वेरी ऑप्टिमाइज़र पर निर्भर रहें। हमारे पास सीधे निष्पादन योजना बनाने का विकल्प नहीं है। अधिकांश समय, यह अत्यधिक वांछनीय है:SQL सर्वर निस्संदेह कम लोकप्रिय होगा यदि प्रत्येक क्वेरी के लिए हमें SSIS-शैली पैकेज लिखने की आवश्यकता होती है।
फिर भी (जैसा कि मेरी पिछली पोस्ट में बताया गया है), अनुकूलक द्वारा चुनी गई योजना वांछित परिणामों का वर्णन करने के लिए उपयोग किए जाने वाले टी-एसक्यूएल के प्रति संवेदनशील हो सकती है। उस लेख के उदाहरण को दोहराते हुए, हम वैकल्पिक सिंटैक्स का उपयोग करके मूल T-SQL क्वेरी लिख सकते थे:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
यह क्वेरी पहले जैसा ही परिणाम सेट निर्दिष्ट करती है, लेकिन ऑप्टिमाइज़र ऑर्डर-संरक्षण (मर्ज कॉन्सटेनेशन) योजना पर विचार नहीं करता है, इसके बजाय क्लस्टर इंडेक्स को स्कैन करना चुनता है (एक बहुत कम कुशल विकल्प):
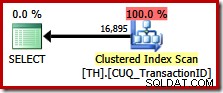
एसक्यूएल सर्वर में ऑर्डर प्रिजर्वेशन का लाभ उठाना
चाहे हम SSIS या SQL सर्वर के बारे में बात कर रहे हों, अनावश्यक छँटाई से बचने से महत्वपूर्ण दक्षता हासिल हो सकती है। SQL सर्वर में इस लक्ष्य को प्राप्त करना अधिक जटिल और कठिन हो सकता है क्योंकि हमारे पास निष्पादन योजना पर इतना अच्छा नियंत्रण नहीं है, लेकिन अभी भी कुछ चीजें हैं जो हम कर सकते हैं।
विशेष रूप से, यह समझना कि SQL सर्वर मर्ज जॉइन कॉन्सटेनेशन ऑपरेटर आंतरिक रूप से कैसे काम करता है, हमें स्पष्ट, रिलेशनल T-SQL लिखना जारी रखने में मदद कर सकता है, जबकि क्वेरी ऑप्टिमाइज़र को जहां उपयुक्त हो, ऑर्डर-प्रिजर्विंग (विलय) प्रोसेसिंग विकल्पों पर विचार करने के लिए प्रोत्साहित करता है।
कनटेनेशन वर्क्स को कैसे मर्ज करें

एक नियमित मर्ज जॉइन के लिए जॉइन कीज़ पर दोनों इनपुट्स को सॉर्ट करने की आवश्यकता होती है। दूसरी ओर, मर्ज जॉइन कॉन्सटेनेशन, बस पहले से ऑर्डर की गई दो स्ट्रीम को एक ही ऑर्डर की गई स्ट्रीम में मर्ज कर देता है - कोई जॉइन नहीं है, जैसे कि।
यह प्रश्न पूछता है:वास्तव में वह 'आदेश' क्या है जो संरक्षित है?
एसएसआईएस में, हमें ऑर्डरिंग को परिभाषित करने के लिए मर्ज इनपुट पर सॉर्ट कुंजी गुण सेट करना होगा। SQL सर्वर के पास इसके बराबर नहीं है। ऊपर दिए गए प्रश्न का उत्तर थोड़ा जटिल है, इसलिए हम इसे चरण दर चरण आगे बढ़ाएंगे।
निम्नलिखित उदाहरण पर विचार करें, जो दो अनइंडेक्स्ड हीप टेबल (सबसे सरल मामला) के मर्ज संयोजन का अनुरोध करता है:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
इन दो तालिकाओं में कोई अनुक्रमणिका नहीं है, और कोई ORDER BY खंड नहीं है। विलय 'संरक्षित' में शामिल होने का आदेश क्या होगा? आपको इसके बारे में सोचने के लिए एक क्षण देने के लिए, आइए पहले SQL सर्वर संस्करणों में उपरोक्त क्वेरी के लिए तैयार निष्पादन योजना को देखें पहले 2012:
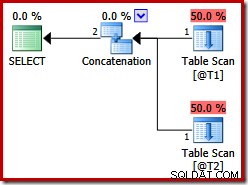
क्वेरी संकेत के बावजूद कोई मर्ज जॉइन कॉन्सटेनेशन नहीं है:SQL सर्वर 2012 से पहले, यह संकेत केवल यूनियन के साथ काम करता है, यूनियन ऑल नहीं। वांछित मर्ज ऑपरेटर के साथ एक योजना प्राप्त करने के लिए, हमें Concatenation (CON) भौतिक ऑपरेटर का उपयोग करके एक तार्किक UNION ALL (UNIA) के कार्यान्वयन को अक्षम करना होगा। कृपया ध्यान दें कि निम्नलिखित अनिर्दिष्ट है और उत्पादन के उपयोग के लिए समर्थित नहीं है:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
वह क्वेरी SQL Server 2012 और 2014 जैसी ही योजना तैयार करती है जो अकेले MERGE UNION क्वेरी संकेत के साथ होती है:
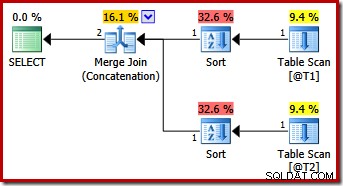
शायद अप्रत्याशित रूप से, निष्पादन योजना में विलय के लिए दोनों इनपुट पर स्पष्ट प्रकार हैं। सॉर्ट गुण हैं:
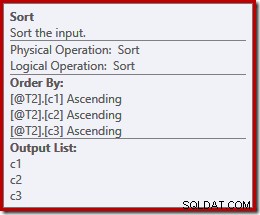
यह समझ में आता है कि ऑर्डर-संरक्षित विलय के लिए लगातार इनपुट ऑर्डरिंग की आवश्यकता होती है, लेकिन उसने (सी 1, सी 2, सी 3) को (सी 3, सी 1, सी 2) या (सी 2, सी 3, सी 1) के बजाय क्यों चुना? प्रारंभिक बिंदु के रूप में, आउटपुट प्रोजेक्शन सूची पर मर्ज कॉन्सटेनेशन इनपुट को सॉर्ट किया जाता है। क्वेरी में सेलेक्ट-स्टार का विस्तार (c1, c2, c3) तक होता है, इसलिए यह चुना गया क्रम है।
मर्ज आउटपुट प्रोजेक्शन सूची के अनुसार क्रमित करें
इस बिंदु को और स्पष्ट करने के लिए, जब हम उस पर होते हैं, तो हम एक अलग क्रम (c3, c2, c1) का चयन करके स्वयं चयन-स्टार का विस्तार कर सकते हैं (जैसा कि हमें करना चाहिए!):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
प्रकार अब मिलान में बदल जाते हैं (c3, c2, c1):
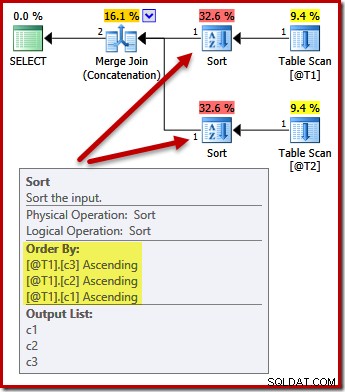
फिर से, क्वेरी आउटपुट आदेश (यह मानते हुए कि हम तालिकाओं में कुछ डेटा जोड़ने वाले थे) को दिखाए गए अनुसार क्रमबद्ध करने की गारंटी नहीं है, क्योंकि हमारे पास कोई ORDER BY खंड नहीं है। इन उदाहरणों का उद्देश्य केवल यह दिखाना है कि सॉर्ट करने के लिए किसी अन्य कारण के अभाव में ऑप्टिमाइज़र एक प्रारंभिक इनपुट सॉर्ट क्रम का चयन कैसे करता है।
परस्पर विरोधी क्रमबद्ध आदेश
अब विचार करें कि क्या होगा यदि हम प्रक्षेपण सूची को (c3, c2, c1) के रूप में छोड़ दें और क्वेरी परिणामों को (c1, c2, c3) द्वारा क्रमित करने के लिए एक आवश्यकता जोड़ें। ORDER BY को संतुष्ट करने के लिए क्या मर्ज के इनपुट अभी भी (c3, c2, c1) पोस्ट-मर्ज सॉर्ट ऑन (c1, c2, c3) के साथ सॉर्ट करेंगे?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
नहीं। अनुकूलक इतना स्मार्ट है कि दो बार छँटाई से बचा जा सकता है:
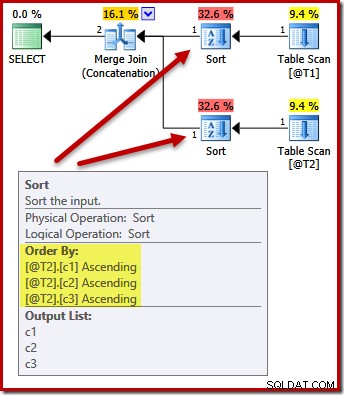
दोनों इनपुट को (c1, c2, c3) पर सॉर्ट करना मर्ज कॉन्सटेनेशन के लिए पूरी तरह से स्वीकार्य है, इसलिए किसी डबल सॉर्ट की आवश्यकता नहीं है।
ध्यान दें कि यह योजना करती है गारंटी है कि परिणामों का क्रम होगा (c1, c2, c3)। यह योजना ORDER BY के बिना पिछली योजनाओं जैसी ही दिखती है, लेकिन सभी आंतरिक विवरण उपयोगकर्ता-दृश्यमान निष्पादन योजनाओं में प्रस्तुत नहीं किए जाते हैं।
विशिष्टता का प्रभाव
मर्ज इनपुट के लिए सॉर्ट ऑर्डर चुनते समय, ऑप्टिमाइज़र किसी भी विशिष्टता की गारंटी से भी प्रभावित होता है जो मौजूद है। निम्नलिखित उदाहरण पर विचार करें, पांच कॉलम के साथ, लेकिन यूनियन ऑल ऑपरेशन में अलग-अलग कॉलम ऑर्डर नोट करें:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
निष्पादन योजना में तालिका @T1 के लिए (c5, c1, c2, c4, c3) प्रकार और तालिका @ T2 के लिए (c5, c4, c3, c2, c1) शामिल हैं:
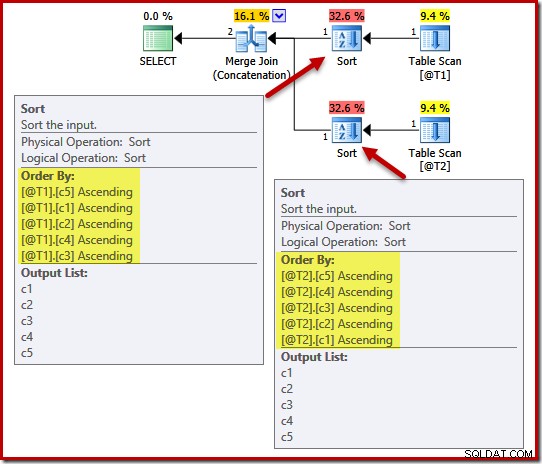
इन प्रकारों पर विशिष्टता के प्रभाव को प्रदर्शित करने के लिए, हम तालिका T1 में स्तंभ c1 और तालिका T2 में स्तंभ c4 में एक UNIQUE बाधा जोड़ेंगे:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
विशिष्टता के बारे में बात यह है कि ऑप्टिमाइज़र जानता है कि जैसे ही यह एक कॉलम का सामना करता है, जो अद्वितीय होने की गारंटी है, यह सॉर्ट करना बंद कर सकता है। एक अद्वितीय कुंजी मिलने के बाद अतिरिक्त स्तंभों के आधार पर छाँटने से परिभाषा के अनुसार अंतिम क्रमबद्ध क्रम प्रभावित नहीं होगा।
जगह में अद्वितीय बाधाओं के साथ, ऑप्टिमाइज़र T1 से (c5, c1) के लिए (c5, c1, c2, c4, c3) सॉर्ट सूची को सरल बना सकता है क्योंकि c1 अद्वितीय है। इसी तरह, T2 के लिए (c5, c4, c3, c2, c1) सॉर्ट सूची को (c5, c4) के लिए सरल बनाया गया है क्योंकि c4 एक कुंजी है:
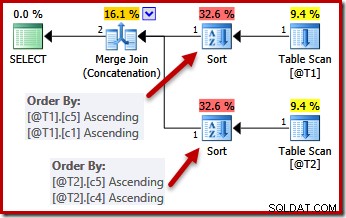
समानांतरता
एक अद्वितीय कुंजी के कारण सरलीकरण पूरी तरह से लागू नहीं होता है। समानांतर योजना में, धाराओं को विभाजित किया जाता है ताकि मर्ज के समान उदाहरण के लिए सभी पंक्तियाँ एक ही थ्रेड पर समाप्त हो जाएँ। यह डेटा सेट विभाजन मर्ज कॉलम पर आधारित है, और कुंजी की उपस्थिति से सरल नहीं है।
पिछली क्वेरी के लिए समानांतर योजना बनाने के लिए निम्न स्क्रिप्ट असमर्थित ट्रेस फ़्लैग 8649 का उपयोग करती है (जो अन्यथा अपरिवर्तित रहती है):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
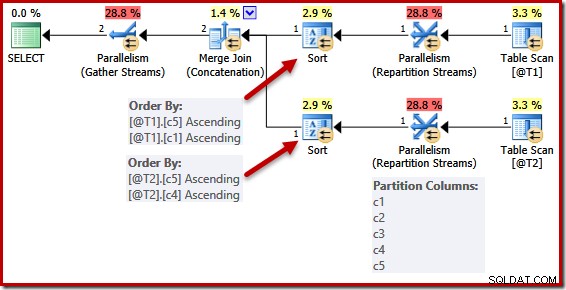
सॉर्ट सूचियों को पहले की तरह सरल बनाया गया है, लेकिन पुनर्विभाजन स्ट्रीम ऑपरेटर अभी भी सभी स्तंभों पर विभाजन करते हैं। यदि यह सरलीकरण लगातार लागू किया जाता है, तो पुनर्विभाजन ऑपरेटर भी अकेले (c5, c1) और (c5, c4) पर ही काम करेंगे।
गैर-अद्वितीय अनुक्रमणिका के साथ समस्याएं
मर्ज कॉन्सटेनेशन के लिए सॉर्टिंग आवश्यकताओं के बारे में ऑप्टिमाइज़र जिस तरह से तर्क करता है, उसके परिणामस्वरूप अनावश्यक सॉर्ट समस्याएं हो सकती हैं, जैसा कि अगले उदाहरण से पता चलता है:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
क्वेरी और उपलब्ध इंडेक्स को देखते हुए, हम एक निष्पादन योजना की अपेक्षा करेंगे जो किसी भी सॉर्टिंग की आवश्यकता से बचने के लिए मर्ज जॉइन कॉन्सटेनेशन का उपयोग करके क्लस्टर इंडेक्स का ऑर्डर स्कैन करता है। यह अपेक्षा पूरी तरह से उचित है, क्योंकि संकुल अनुक्रमणिका ORDER BY खंड में निर्दिष्ट क्रम प्रदान करती है। दुर्भाग्य से, हमें वास्तव में जो योजना मिलती है, उसमें दो प्रकार शामिल होते हैं:
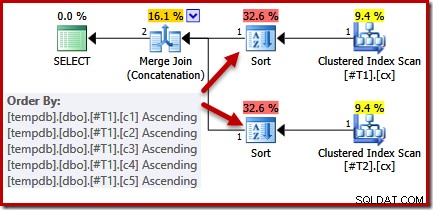
इस प्रकार के लिए कोई अच्छा कारण नहीं है, वे केवल इसलिए प्रकट होते हैं क्योंकि क्वेरी ऑप्टिमाइज़र का तर्क अपूर्ण है। मर्ज आउटपुट कॉलम सूची (c1, c2, c3, c4, c5) ORDER BY का सुपरसेट है, लेकिन कोई अद्वितीय नहीं है उस सूची को सरल बनाने की कुंजी। ऑप्टिमाइज़र के तर्क में इस अंतर के परिणामस्वरूप, यह निष्कर्ष निकालता है कि मर्ज को इसके इनपुट को क्रमबद्ध करने की आवश्यकता है (c1, c2, c3, c4, c5)।
हम किसी एक संकुल अनुक्रमणिका को विशिष्ट बनाने के लिए स्क्रिप्ट को संशोधित करके इस विश्लेषण को सत्यापित कर सकते हैं:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
निष्पादन योजना में अब केवल गैर-अद्वितीय अनुक्रमणिका वाली तालिका के ऊपर एक प्रकार है:
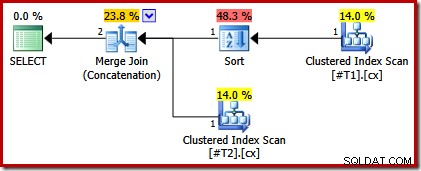
अगर हम अब दोनों . बनाते हैं संकुल अनुक्रमणिका अद्वितीय, किसी प्रकार का प्रकट नहीं होता:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
दोनों इंडेक्स अद्वितीय हैं, प्रारंभिक मर्ज इनपुट सॉर्ट सूचियों को अकेले कॉलम c1 में सरल बनाया जा सकता है। सरलीकृत सूची तब ORDER BY खंड से बिल्कुल मेल खाती है, इसलिए अंतिम योजना में किसी प्रकार की आवश्यकता नहीं है:
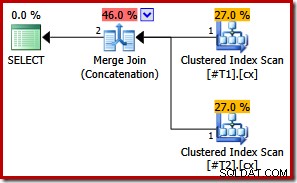
ध्यान दें कि इष्टतम निष्पादन योजना प्राप्त करने के लिए हमें इस अंतिम उदाहरण में क्वेरी संकेत की भी आवश्यकता नहीं है।
अंतिम विचार
निष्पादन योजना में प्रकार को खत्म करना मुश्किल हो सकता है। कुछ मामलों में, आवश्यक क्रम में पंक्तियों को वितरित करने के लिए मौजूदा अनुक्रमणिका को संशोधित करना (या एक नया प्रदान करना) जितना आसान हो सकता है। उपयुक्त इंडेक्स उपलब्ध होने पर क्वेरी ऑप्टिमाइज़र समग्र रूप से उचित कार्य करता है।
हालांकि (कई) अन्य मामलों में, प्रकार से बचने के लिए निष्पादन इंजन, क्वेरी ऑप्टिमाइज़र और स्वयं योजना ऑपरेटरों की बहुत गहरी समझ की आवश्यकता हो सकती है। प्रकार से बचना निस्संदेह एक उन्नत क्वेरी ट्यूनिंग विषय है, लेकिन जब सब कुछ सही हो जाता है तो यह अविश्वसनीय रूप से पुरस्कृत भी होता है।



