जब मैं कुछ हफ़्ते पहले शिकागो में हमारे एक इमर्शन इवेंट के लिए था, तो एक सहभागी के पास एक सांख्यिकी प्रश्न था। मैं इस मुद्दे के सभी विवरणों में नहीं जाऊंगा, लेकिन सहभागी ने उल्लेख किया कि आंकड़े sp_updatestats का उपयोग करके अपडेट किए गए थे . यह आँकड़ों को अद्यतन करने का एक तरीका है जिसकी मैंने कभी अनुशंसा नहीं की है; मैंने हमेशा अनुक्रमणिका पुनर्निर्माण और UPDATE STATISTICS . के संयोजन की अनुशंसा की है आँकड़ों को अद्यतन रखने के लिए। अगर आप sp_updatestats . से परिचित नहीं हैं , यह एक कमांड है जो आँकड़ों को अद्यतन करने के लिए संपूर्ण डेटाबेस के लिए चलाया जाता है। लेकिन जैसा कि किम्बर्ली ने सहभागी को बताया, sp_updatestats एक आँकड़ा तब तक अपडेट करेगा जब तक कि उसमें एक पंक्ति को संशोधित किया गया हो। वाह। मैंने तुरंत पुस्तकें ऑनलाइन खोल दीं, और sp_updatestats . के लिए आप इसे देखेंगे:
अब, मैं मानता हूं, मैंने एक धारणा बनाई है कि "... sys.sysindexes कैटलॉग दृश्य में rowmodctr जानकारी के आधार पर अद्यतन करने की आवश्यकता है ..." का अर्थ है। मैंने यह मान लिया था कि अद्यतन निर्णय उसी तर्क का पालन करेगा जो स्वतः अद्यतन सांख्यिकी विकल्प का अनुसरण करता है, जो है:
- तालिका का आकार 0 से>0 पंक्तियों (परीक्षण 1) हो गया है।
- आँकड़ों को एकत्रित करते समय तालिका में पंक्तियों की संख्या 500 या उससे कम थी, और तब से सांख्यिकी ऑब्जेक्ट के प्रमुख स्तंभ का colmodctr 500 से अधिक बदल गया है (परीक्षण 2)।
- आँकड़ों को इकट्ठा करते समय तालिका में 500 से अधिक पंक्तियाँ थीं, और सांख्यिकी ऑब्जेक्ट के प्रमुख स्तंभ के colmodctr में 500 + 20% से अधिक तालिका में पंक्तियों की संख्या में परिवर्तन हुआ है जब आँकड़े एकत्र किए गए थे ( परीक्षण 3)।
sp_updatestats . के लिए इस तर्क का पालन नहीं किया जाता है . वास्तव में, तर्क इतना अविश्वसनीय रूप से सरल है, यह डरावना है:यदि एक पंक्ति को संशोधित किया जाता है, तो आँकड़ा अद्यतन किया जाता है। एक पंक्ति। एक पंक्ति। मेरी चिंता क्या है? मैं आंकड़ों के एक समूह के लिए आंकड़ों को अद्यतन करने के ऊपरी हिस्से के बारे में चिंतित हूं जिन्हें वास्तव में अद्यतन करने की आवश्यकता नहीं है। आइए sp_updatestats . पर करीब से नज़र डालें ।
हम एडवेंचरवर्क्स2012 डेटाबेस की एक नई प्रति के साथ शुरुआत करेंगे जिसे आप कोडप्लेक्स से डाउनलोड कर सकते हैं। मैं पहले तीन अलग-अलग तालिकाओं में पंक्तियों को अपडेट करने जा रहा हूं:
उपयोग [AdventureWorks2012];GOSET NOCOUNT ON;GO UPDATE [उत्पादन]।[उत्पाद]सेट [नाम] ='बाइक चेन' जहां [ProductID] =952; अद्यतन [व्यक्ति]। [व्यक्ति] सेट [अंतिम नाम] ='कैमरून' जहां [अंतिम नाम] ='डियाज़'; बिक्री में प्रवेश करें। बिक्री कारण (नाम, कारण प्रकार, संशोधित दिनांक) मान ('आंकड़े', 'परीक्षण', GETDATE ( )); 10000 जाओ
हमने Production.Product . में एक पंक्ति को संशोधित किया है , 211 पंक्तियाँ Person.Person . में , और हमने Sales.SalesReason . में 10,000 पंक्तियाँ जोड़ीं . अगर sp_updatestats प्रक्रिया ने अपडेट के लिए ऑटो अपडेट सांख्यिकी विकल्प के समान तर्क का पालन किया, उसके बाद केवल Sales.SalesReason अपडेट होगा क्योंकि इसमें शुरू करने के लिए 10 पंक्तियाँ थीं (जबकि 211 पंक्तियाँ Person.Person में अपडेट की गई थीं) तालिका के लगभग एक प्रतिशत का प्रतिनिधित्व करते हैं)। हालांकि, अगर हम sp_updatestats . में खोदते हैं , हम देख सकते हैं कि प्रयुक्त तर्क भिन्न है। ध्यान दें कि मैं केवल sp_updatestats . के भीतर से स्टेटमेंट निकाल रहा हूं जिनका उपयोग यह निर्धारित करने के लिए किया जाता है कि कौन से आंकड़े अपडेट होते हैं।
एक कर्सर डेटाबेस में सभी उपयोगकर्ता-परिभाषित तालिकाओं और आंतरिक तालिकाओं के माध्यम से पुनरावृति करता है:
घोषित ms_crs_tnames कर्सर स्थानीय fast_forward read_only forselect name, object_id, schema_id, type from sys.objects o.type ='U' or o.type ='IT'open ms_crs_tnamesfetch अगला ms_crs_tnames से @table_name, @table_id में sch_id, @table_type
एक अन्य कर्सर प्रत्येक तालिका के आँकड़ों के माध्यम से लूप करता है, और ढेर और काल्पनिक अनुक्रमणिका और सांख्यिकी को बाहर करता है। ध्यान दें कि sys.sysindexes sp_helpstats . में उपयोग किया जाता है . Sysindexes एक SQL Server 2000 सिस्टम तालिका है और इसे SQL सर्वर के भविष्य के संस्करण में निकालने के लिए शेड्यूल किया गया है। यह दिलचस्प है, क्योंकि अपडेट की गई पंक्तियों को निर्धारित करने की दूसरी विधि है sys.dm_db_stats_properties DMF, जो केवल SQL 2008 R2 SP2 और SQL 2012 SP1 में उपलब्ध है।
थोड़ी तैयारी और अतिरिक्त तर्क के बाद, हमें एक IF . मिलता है बयान जो बताता है कि sp_updatestats उन आँकड़ों को फ़िल्टर करता है जिनकी कोई पंक्ति अपडेट नहीं हुई है… यह पुष्टि करते हुए कि भले ही केवल एक पंक्ति को संशोधित किया गया हो, आंकड़े अपडेट किए जाएंगे। @is_ver_current . के लिए एक चेक भी है , जो एक अंतर्निर्मित, आंतरिक फ़ंक्शन द्वारा निर्धारित किया जाता है।
if ((@ind_rowmodctr <> 0) या ((@is_ver_current शून्य नहीं है) और (@is_ver_current =0)))
नमूनाकरण और संगतता स्तर से संबंधित कुछ और जाँचें, और फिर UPDATE आँकड़ों के लिए कथन निष्पादित करता है। इससे पहले कि हम वास्तव में sp_updatestats चलाएं, हम sys.sysindexes . को क्वेरी कर सकते हैं यह देखने के लिए कि कौन से आंकड़े अपडेट होंगे:
चुनें [ओ]। ]से [sys]।[ऑब्जेक्ट्स] [o] जॉइन [sys]। यू' या [ओ]। [प्रकार] ='आईटी') और [सी]। [इंडिड]> 0 और [सी]। [rowmodctr] <> 0 ऑर्डर बाय [ओ]। [टाइप] डीईएससी, [ओ]। [ नाम];
हमने जिन तीन तालिकाओं को संशोधित किया है, उनके अलावा, उपयोगकर्ता तालिका के लिए एक और आँकड़ा है (dbo.DatabaseLog ) और तीन आंतरिक आंकड़े जो अपडेट किए जाएंगे:
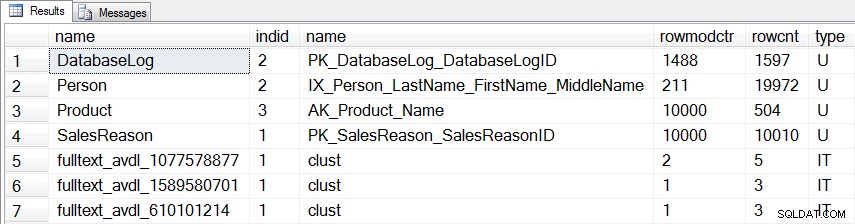
अद्यतन किए जाने वाले आंकड़े
अगर हम sp_updatestats run चलाते हैं एडवेंचरवर्क्स डेटाबेस के लिए, आउटपुट प्रत्येक तालिका और अद्यतन किए गए आंकड़ों को सूचीबद्ध करता है। नीचे दिए गए आउटपुट को केवल अद्यतन आंकड़े दिखाने के लिए संशोधित किया गया है:
[sys] को अपडेट कर रहा है।
…
[dbo] को अपडेट कर रहा है।
…
[sys] को अपडेट कर रहा है।
…
[व्यक्ति] को अपडेट किया जा रहा है। index(es)/statistics को अपडेट कर दिया गया है, 2 को अपडेट की जरूरत नहीं है।
…
[बिक्री] को अपडेट कर रहा है।
…
[उत्पादन] अपडेट किया जा रहा है। AK_Product_rowguid], अपडेट जरूरी नहीं है...
[_WA_Sys_00000013_75A278F5], अपडेट जरूरी नहीं है...
[_WA_Sys_00000014_75A278F5], अपडेट जरूरी नहीं है...
[_WA_Sys_0000000D_75A278F5], अपडेट जरूरी नहीं है...
>[_WA_Sys_0000000C_75A278F5], अपडेट जरूरी नहीं है...
1 इंडेक्स(एस)/आंकड़े अपडेट कर दिए गए हैं, 7 को अपडेट की जरूरत नहीं है।
…
सभी तालिकाओं के आंकड़े अपडेट कर दिए गए हैं।
आउटपुट की अंतिम पंक्ति थोड़ी भ्रामक है - सभी तालिकाओं के आंकड़े अपडेट नहीं किए गए हैं, केवल एक पंक्ति या अधिक संशोधित किए गए आंकड़े अपडेट किए गए हैं। और फिर, इसका दोष यह है कि शायद संसाधनों का उपयोग किया गया था जिनकी आवश्यकता नहीं थी। यदि किसी आंकड़े में केवल एक पंक्ति को संशोधित किया गया है, तो क्या उसे अद्यतन किया जाना चाहिए? नहीं। यदि इसमें 10,000 पंक्तियाँ अद्यतन हैं, तो क्या इसे अद्यतन किया जाना चाहिए? अच्छा, यह निर्भर करता है। यदि तालिका में केवल 5,000 पंक्तियाँ हैं, तो बिल्कुल; यदि तालिका में 1 मिलियन पंक्तियाँ हैं, तो नहीं, क्योंकि तालिका का केवल एक प्रतिशत ही संशोधित किया गया है।
यहाँ मुख्य बात यह है कि यदि आप sp_updatestats . का उपयोग कर रहे हैं अपने आँकड़ों को अद्यतन करने के लिए, आप CPU, I/O, और tempdb सहित संसाधनों को बर्बाद करने की सबसे अधिक संभावना रखते हैं। इसके अलावा, प्रत्येक आंकड़े को अपडेट करने में समय लगता है, और यदि आपके पास एक सख्त रखरखाव विंडो है, तो संभवतः आपके पास अन्य रखरखाव कार्य हैं जो अनावश्यक अपडेट के बजाय उस समय में निष्पादित हो सकते हैं। अंत में, जब बहुत कम पंक्तियाँ बदली हैं तो आप शायद आँकड़े अपडेट करके कोई प्रदर्शन लाभ नहीं दे रहे हैं। वितरण परिवर्तन संभवतः नगण्य है यदि पंक्तियों का केवल एक छोटा प्रतिशत संशोधित किया गया है, इसलिए हिस्टोग्राम और घनत्व मान अंत में इतना परिवर्तन नहीं करते हैं। इसके अलावा, याद रखें कि आंकड़े अपडेट करने से उन आँकड़ों का उपयोग करने वाली क्वेरी योजनाएँ अमान्य हो जाती हैं। जब उन प्रश्नों को निष्पादित किया जाता है, तो योजनाओं को फिर से तैयार किया जाता है, और योजना शायद पहले जैसी ही होगी, क्योंकि हिस्टोग्राम में कोई महत्वपूर्ण परिवर्तन नहीं हुआ था। क्वेरी योजनाओं को फिर से संकलित करने की लागत है - इसे मापना हमेशा आसान नहीं होता है, लेकिन इसे अनदेखा नहीं किया जाना चाहिए।
आँकड़ों को प्रबंधित करने का एक बेहतर तरीका - क्योंकि आपको आँकड़ों को प्रबंधित करने की आवश्यकता है - एक अनुसूचित कार्य को लागू करना है जो संशोधित की गई पंक्तियों के प्रतिशत के आधार पर अद्यतन होता है। आप उपरोक्त क्वेरी का उपयोग कर सकते हैं जो sys.sysindexes . से पूछताछ करती है , या आप नीचे दी गई क्वेरी का उपयोग कर सकते हैं जो SQL Server 2008 R2 SP2 और SQL Server 2012 SP1 में जोड़े गए नए DMF का लाभ उठाती है:
चुनें [sch]। [नाम] + '।' + [तो]। [नाम] एएस [टेबलनाम], [एसएस]। [नाम] एएस [सांख्यिकी], [एसपी]। [last_updated] AS [StatsLastUpdated] , [sp]। [पंक्तियां] AS [RowsInTable] ,[ एसपी]। object_id] =[तो]। [object_id] [sys] में शामिल हों। [स्कीमा] [sch] पर [तो]। [schema_id] =[sch]। [schema_id] बाहरी आवेदन [sys]। [dm_db_stats_properties] ([तो] .[object_id],[ss].[stats_id]) spWHERE [so].[type] ='U'AND [sp].[modification_counter]> 0ORDER BY [sp]।[last_updated] DESC;
समझें कि अलग-अलग तालिकाओं में अलग-अलग थ्रेसहोल्ड हो सकते हैं और आपको अपने डेटाबेस के लिए उपरोक्त क्वेरी को ट्विक करने की आवश्यकता होगी। कुछ तालिकाओं के लिए, 15% या 20% पंक्तियों को संशोधित किए जाने तक प्रतीक्षा करना ठीक हो सकता है। लेकिन दूसरों के लिए, आपको वास्तविक मूल्यों और उनके तिरछेपन के आधार पर 10% या 5% पर भी अपडेट करने की आवश्यकता हो सकती है। कोई चांदी की गोली नहीं है। जितना हम निरपेक्षता से प्यार करते हैं, वे शायद ही कभी SQL सर्वर में मौजूद होते हैं और आँकड़े कोई अपवाद नहीं हैं। आप अभी भी ऑटो अपडेट स्टैटिस्टिक्स को सक्षम छोड़ना चाहते हैं - यह एक सुरक्षा है जो आपकी डेटाबेस फ़ाइलों के लिए ऑटो ग्रोथ की तरह ही कुछ याद आती है। लेकिन आपकी सबसे अच्छी शर्त है कि आप अपने डेटा को जानें, और एक ऐसी कार्यप्रणाली लागू करें जो आपको बदली गई पंक्तियों के प्रतिशत के आधार पर आंकड़े अपडेट करने की अनुमति देती है।