SQL क्वेरी ऑप्टिमाइज़ेशन के गियर्स के साथ छेड़छाड़ शुरू करना आसान है। आप SQL सर्वर प्रबंधन स्टूडियो (SSMS) खोलते हैं, प्रतीक्षा समय की निगरानी करते हैं, निष्पादन योजना की समीक्षा करते हैं, ऑब्जेक्ट की जानकारी एकत्र करते हैं और SQL को तब तक ऑप्टिमाइज़ करना शुरू करते हैं जब तक कि आप एक अच्छी तरह से ट्यून की गई मशीन नहीं चला रहे हों।
यदि आप इसमें काफी अच्छे हैं, तो आप एक त्वरित जीत हासिल करते हैं और अपने नियमित रूप से निर्धारित अराजकता में वापस आ जाते हैं। लेकिन अगर आप गलत चीज को एडजस्ट करते हैं, या सही चीज को गलत दिशा में एडजस्ट करते हैं, तो आपका बुधवार बीत गया।
SQL क्वेरी अनुकूलन? आपको क्या लगता है कि आपको इसकी आवश्यकता है?
ज्यादातर समय, यह परेशानी वाले टिकटों या उपयोगकर्ता शिकायतों में वृद्धि है। "सिस्टम इतना धीमा क्यों है?" आपके उपयोगकर्ता शिकायत करते हैं। "इस सप्ताह अपनी सामान्य रिपोर्ट चलाने में हमें हमेशा के लिए समय लग रहा है।"
यह एक बहुत ही अस्पष्ट विवरण है, निश्चित रूप से। यह अच्छा होगा यदि वे आपको बता सकें, "चीजें धीमी हैं क्योंकि आपको CurrentOrderQuery5.sql की लाइन 62 में एक अंतर्निहित रूपांतरण मिला है। कॉलम वर्चर है और आप एक पूर्णांक में गुजर रहे हैं।" लेकिन इसकी संभावना नहीं है कि आपके उपयोगकर्ता उस स्तर का विवरण देख सकें।
कम से कम परेशानी वाले टिकट और फोन कॉल एक सक्रिय मीट्रिक बनाते हैं:स्पॉट करने में आसान, मापने में आसान। जब वे रोल करना शुरू करते हैं, तो आप निश्चित रूप से सुनिश्चित हो सकते हैं कि यह SQL ट्यूनिंग का समय है।
लेकिन अन्य, निष्क्रिय मेट्रिक्स हैं जो आवश्यकता को कम स्पष्ट करते हैं। बिक्री में गिरावट जैसी चीजें, जो कई कारकों के कारण हो सकती हैं। क्या ऐसा इसलिए है क्योंकि आपके ऑनलाइन स्टोर में धीमी गति से की जाने वाली क्वेरीज़ आपके ग्राहकों को अपनी शॉपिंग कार्ट छोड़ने पर मजबूर कर रही हैं? क्या ऐसा इसलिए है क्योंकि अर्थव्यवस्था खराब स्थिति में है?
या यह सुस्त SQL सर्वर प्रदर्शन जैसी चीजें हो सकती हैं। क्या ऐसा इसलिए है क्योंकि खराब लिखित क्वेरी छत के माध्यम से तार्किक रीड भेज रही है? क्या ऐसा इसलिए है क्योंकि सर्वर में मेमोरी और स्टोरेज जैसे भौतिक संसाधनों की कमी है?
दोनों ही स्थितियों में, SQL क्वेरी ऑप्टिमाइज़ेशन पहले विकल्प में मदद कर सकता है, लेकिन दूसरे विकल्प में नहीं।
गलत समस्या का सही समाधान क्यों लागू करें?
अनुकूलन के रास्ते पर जाने से पहले, सुनिश्चित करें कि ट्यूनिंग सही समस्या का सही समाधान है।
ट्यूनिंग एसक्यूएल एक तकनीकी प्रक्रिया है, लेकिन हर तकनीकी कदम की जड़ें अच्छे व्यावसायिक अर्थों में होती हैं। आप निष्पादन समय को कुछ मिलीसेकंड से कम करने या तार्किक पढ़ने की संख्या को पांच प्रतिशत कम करने की कोशिश में दिन बिता सकते हैं, लेकिन क्या यह कमी आपके समय के लायक है? यह सच है कि उपयोगकर्ताओं की आवश्यकताओं को पूरा करना महत्वपूर्ण है, लेकिन हर प्रयास अंततः घटते प्रतिफल के बिंदु तक पहुंचता है।
इन SQL क्वेरी प्रदर्शन समस्याओं और उनके आसपास के व्यावसायिक संदर्भ पर विचार करें:
- स्वीकार्य प्रदर्शन - एक क्वेरी को चलने में 10 मिनट लगते हैं और उपयोगकर्ता चाहता है कि वह एक मिनट में चले; यह एक उचित असमानता और अनुकूलन के लिए एक प्राप्त करने योग्य लक्ष्य की तरह लगता है। हालाँकि, यदि क्वेरी में रात भर का समय लगता है और उपयोगकर्ता को लगता है कि इसे एक मिनट में चलाना चाहिए, तो यह एक ट्यूनिंग समस्या से अधिक हो सकता है। एक बात के लिए, आपको उपयोगकर्ता को उस कार्य की मात्रा के बारे में शिक्षित करना पड़ सकता है जो क्वेरी वास्तव में कर रही है। दूसरे के लिए, यह एक समस्या हो सकती है जिस तरह से डेटाबेस को डिज़ाइन किया गया था या जिस तरह से क्लाइंट एप्लिकेशन लिखा गया था।
- उपयोगिता - मान लीजिए कि आप एक निर्माण कंपनी में वित्तीय डेटाबेस के प्रबंधन के लिए जिम्मेदार हैं। हर महीने के अंत में यूजर्स खराब परफॉर्मेंस की शिकायत करते हैं। आप लेखा द्वारा चलाए जा रहे महीने के अंत में रिपोर्ट की एक श्रृंखला के लिए समस्या का पता लगाते हैं, जिसमें प्रत्येक घंटे का समय लगता है और सीधे फाइलिंग कैबिनेट में चला जाता है, जिसकी जांच किसी के द्वारा नहीं की जाती है। ट्यूनिंग के बजाय, आप व्यवसाय प्रबंधकों को समस्या समझाते हैं और रिपोर्ट को हटाने की अनुमति प्राप्त करते हैं।
- समय परिवर्तन - या, मान लीजिए कि वही रिपोर्ट शासन के लिए महत्वपूर्ण हैं लेकिन व्यवसाय के लिए जरूरी नहीं हैं। यदि उन्हें प्रति सप्ताह या प्रति माह एक बार चलाया जाता है, तो उन्हें डेटा सेट को प्री-कैश करके और परिणामों को फ़ाइल में भेजकर ऑफ-पीक घंटों के लिए शेड्यूल किया जा सकता है। यह अन्य व्यावसायिक उपयोगकर्ताओं की अड़चन को दूर करता है और लेखा उपयोगकर्ता को रिपोर्ट के लिए प्रतीक्षा करने से मुक्त करता है।
जब आप अनुकूलित करने के अपने निर्णय में व्यावसायिक संदर्भ को शामिल करते हैं, तो आप प्राथमिकताएं निर्धारित कर सकते हैं और अपने लिए समय खरीद सकते हैं।
जब आप SQL क्वेरी को ऑप्टिमाइज़ करते हैं, तो SQL डायग्रामिंग आज़माएं
SSMS और SQL सर्वर में निर्मित टूल प्रभावी SQL क्वेरी ऑप्टिमाइज़ेशन के लिए आपको आवश्यक अधिकांश चीज़ें प्रदान करते हैं। ई-बुक “एसक्यूएल क्वेरी ऑप्टिमाइज़ेशन के लिए मूलभूत मार्गदर्शिका“: में वर्णित अनुसार, निम्न चरणों के आसपास एक व्यवस्थित दृष्टिकोण के साथ टूल को संयोजित करें।
- प्रतीक्षा समय की निगरानी करें
- निष्पादन योजना की समीक्षा करें
- वस्तु जानकारी एकत्रित करें
- ड्राइविंग टेबल ढूंढें
- प्रदर्शन अवरोधकों की पहचान करें
चरण 4 में, आपका लक्ष्य उस तालिका के साथ क्वेरी चलाना है जो कम से कम डेटा लौटाती है। जब आप जॉइन और प्रेडिकेट का अध्ययन करते हैं, और बाद में की बजाय क्वेरी में पहले फ़िल्टर करते हैं, तो आप तार्किक रीड की संख्या कम कर देते हैं। SQL क्वेरी ऑप्टिमाइज़ेशन में यह एक बड़ा कदम है।
SQL डायग्रामिंग तालिकाओं में डेटा की मात्रा को मैप करने और यह पता लगाने के लिए एक ग्राफिकल तकनीक है कि कौन सा फ़िल्टर सबसे कम रिकॉर्ड लौटाएगा। सबसे पहले, आप यह निर्धारित करते हैं कि कौन-सी तालिकाएँ विस्तृत जानकारी रखती हैं और कौन-सी तालिकाएँ मास्टर या लुकअप तालिकाएँ हैं। विश्वविद्यालय पंजीकरण डेटाबेस के विरुद्ध इस क्वेरी के सरल उदाहरण पर विचार करें:

विवरण तालिका पंजीकरण है। इसमें दो लुकअप टेबल हैं, छात्र और कक्षा। इन तालिकाओं को आरेखित करने के लिए, विवरण तालिका (शीर्ष पर) को तीर (या लिंक) के साथ लुकअप तालिकाओं से जोड़ने वाला एक उल्टा पेड़ बनाएं, जैसे:

अब, शामिल होने के मानदंड के लिए आवश्यक रिकॉर्ड की सापेक्ष संख्या की गणना करें (अर्थात, विवरण तालिका और लुकअप तालिकाओं के बीच संबंधित पंक्तियों का औसत अनुपात)। तीर के प्रत्येक छोर पर संख्याएँ लिखें। इस उदाहरण में, प्रत्येक छात्र के लिए पंजीकरण तालिका में लगभग 5 रिकॉर्ड हैं, और प्रत्येक कक्षा के लिए पंजीकरण में लगभग 30 रिकॉर्ड हैं। इसका मतलब है कि किसी एकल छात्र या किसी एक कक्षा के लिए परिणाम प्राप्त करने के लिए 150 (5×30) से अधिक रिकॉर्ड में शामिल होना कभी भी आवश्यक नहीं होना चाहिए।
यदि आपके शामिल होने वाले कॉलम अनुक्रमित नहीं हैं, या यदि आप सुनिश्चित नहीं हैं कि वे अनुक्रमित हैं, तो यह अभ्यास उपयोगी है।
इसके बाद, क्वेरी को चलाने के लिए किस तालिका को खोजने के लिए फ़िल्टरिंग विधेय को देखें। इस क्वेरी में दो फ़िल्टर थे:एक पंजीकरण रद्द होने पर ='एन' और दूसरा साइनअप_डेट पर दो तिथियों के बीच। यह देखने के लिए कि फ़िल्टर कितना चयनात्मक है, इस क्वेरी को पंजीकरण पर चलाएँ:
पंजीकरण से गिनती (1) चुनें जहां रद्द किया गया ='एन'
और r.signup_date के बीच :beg_date और :beg_date +1
यह पंजीकरण में कुल 79,800 रिकॉर्ड में से 4,344 रिकॉर्ड लौटाता है। यानी उस फिल्टर से 5.43 प्रतिशत रिकॉर्ड पढ़े जाएंगे।
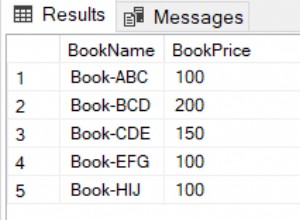
अन्य फ़िल्टर कक्षा में है:
उस वर्ग से गिनती चुनें (1) जहां नाम ='इंग्लिश 101'
यह 1,000 या 0.2 प्रतिशत में से दो रिकॉर्ड लौटाता है, जो कि बहुत अधिक चयनात्मक फ़िल्टर का प्रतिनिधित्व करता है। इस प्रकार, क्लास ड्राइविंग टेबल है, और जिस पर पहले आपकी SQL ट्यूनिंग पर ध्यान केंद्रित करना है।
उपयोगकर्ता की आवाज
यदि आप सुनिश्चित हैं कि आपको SQL ट्यूनिंग की आवश्यकता है, तो "SQL क्वेरी ऑप्टिमाइज़ेशन के लिए मूलभूत मार्गदर्शिका" अधिक जानकारी प्रदान करती है। यह आपको ऊपर वर्णित एक सहित, कॉपी-पेस्ट क्वेरी और केस स्टडी के साथ पांच प्रदर्शन ट्यूनिंग युक्तियों के माध्यम से चलता है।
आप शायद पाएंगे कि सबसे महत्वपूर्ण SQL क्वेरी ऑप्टिमाइज़ेशन टूल उपयोगकर्ता की आवाज़ है। क्यों? क्योंकि वह आवाज आपको बताती है कि कब ऑप्टिमाइज़ करना शुरू करना है और यह आपको बताती है कि आपने कब पर्याप्त रूप से अनुकूलित किया है। यह सुनिश्चित कर सकता है कि जब आपको आवश्यकता हो तो आप गियर के साथ छेड़छाड़ करना शुरू कर दें और आगे बढ़ते हुए रुक जाएं।