यह लेख सिमेंटिक सर्च की बुनियादी बातों से संबंधित है, जिसमें सिमेंटिक सर्च का पूरा वॉकथ्रू शामिल है:स्क्रैच से शुरू होकर रेडी-टू-यूज़ फीचर के साथ फिनिशिंग।
इसके अतिरिक्त, पाठक SQL सर्वर में उपलब्ध कुछ बहुत उपयोगी लेकिन आम तौर पर ज्ञात नहीं खोज सुविधाओं के बारे में जानने जा रहे हैं, जैसे सिमेंटिक सर्च, जिसे हम कुछ बुनियादी उदाहरणों के साथ प्रदर्शित करेंगे।
यह लेख विश्लेषण के एक विशिष्ट रूप के लिए अर्थपूर्ण खोज के महत्व पर भी जोर देता है जिसे सामान्य खोज के साथ नहीं किया जा सकता है।
सिमेंटिक सर्च क्या है
आइए पहले देखें कि सिमेंटिक सर्च वास्तव में क्या है और यह फुल-टेक्स्ट सर्च से कैसे अलग है।
माइक्रोसॉफ्ट परिभाषा
Microsoft दस्तावेज़ के अनुसार, सिमेंटिक सर्च असंरचित दस्तावेज़ों में गहरी अंतर्दृष्टि प्रदान करता है।
वैकल्पिक परिभाषा
सिमेंटिक सर्च एक विशेष खोज तकनीक या विशेषता है जिसका उपयोग व्यापक खोज या तुलनात्मक विश्लेषण करने के लिए मुख्य रूप से असंरचित डेटा या दस्तावेज़ों में किया जाता है, जैसे कि एमएस वर्ड दस्तावेज़, बशर्ते कि असंरचित डेटा SQL सर्वर डेटाबेस के अंदर संग्रहीत हो।
संगतता
सिमेंटिक सर्च केवल SQL Server 2012 और बाद के संस्करणों के साथ संगत है।
कृपया याद रखें कि सिमेंटिक सर्च Azure SQL डेटाबेस या Azure डेटा वेयरहाउस क्लाउड समाधानों के साथ संगत नहीं है।
इसका मतलब है कि आपको या तो Azure पर VM के साथ काम करना होगा या इस शक्तिशाली सुविधा का उपयोग करने के लिए ऑन-प्रिमाइसेस SQL सर्वर इंस्टेंस पर काम करना होगा।
अर्थपूर्ण खोज बनाम पूर्ण-पाठ खोज
Microsoft दस्तावेज़ीकरण के अनुसार, पूर्ण-पाठ खोज आपको किसी दस्तावेज़ में शब्दों को क्वेरी करने देता है; सिमेंटिक खोज आपको दस्तावेज़ के अर्थ को क्वेरी करने देती है।
पूर्ण-पाठ खोज के साथ सिमेंटिक खोज Microsoft SQL सर्वर द्वारा प्रस्तुत एक संयुक्त सुविधा का प्रतिनिधित्व करता है, और आप या तो अपने SQL सर्वर इंस्टेंस की स्थापना के दौरान या बाद में अपने मौजूदा SQL इंस्टेंस में नई सुविधाएँ जोड़कर उन्हें स्थापित करने के लिए चुन सकते हैं।
आवश्यकताएं
आइए इस लेख में पूर्वाभ्यास का पालन करने के लिए आवश्यक कुछ चीजों के साथ-साथ सिमेंटिक सर्च के सामान्य उपयोग के लिए पूर्वापेक्षाएँ देखें।
पूर्ण-पाठ खोज स्थापित
यह जानना अनिवार्य है कि पूर्ण-पाठ खोज को कैसे सेट किया जाए क्योंकि पूर्ण-पाठ खोज और सिमेंटिक खोज दोनों को एक संयुक्त विशेषता के रूप में पेश किया जाता है।
कृपया लेख देखें पूर्ण-पाठ खोज को स्थापित करने के लिए SQL सर्वर 2016 में पूर्ण-पाठ खोज लागू करना, जो SQL सर्वर में सिमेंटिक खोज स्थापित करने के लिए एक पूर्वापेक्षा है।
यह आलेख अपेक्षा करता है कि आपने अपने SQL सर्वर इंस्टेंस पर पूर्ण-पाठ खोज स्थापित किया है।
SQL सर्वर के लिए dbForge स्टूडियो
सिमेंटिक सर्च (इस आलेख के पूर्वाभ्यास में) के उपयोग के लिए असंरचित डेटा को SQL सर्वर डेटाबेस में संग्रहीत करने की आवश्यकता होती है, और इस लेख में, हमने SQL सर्वर में सीधे असंरचित डेटा को सहेजने के बजाय SQL सर्वर के लिए dbForge Studio का उपयोग करके ऐसा किया है।
एसक्यूएल सर्वर 2016
हम इस लेख में SQL सर्वर 2016 का उपयोग कर रहे हैं, लेकिन किसी भी अन्य संगत संस्करण के लिए चरण लगभग समान होने चाहिए।
अर्थपूर्ण खोज सेट करें
सिमेंटिक सर्च या स्टैटिस्टिकल सिमेंटिक सर्च का उपयोग करने के लिए, आप इसे फुल-टेक्स्ट सर्च की स्थापना के दौरान या बाद में फुल-टेक्स्ट सर्च और सिमेंटिक सर्च को एक नई सुविधा के रूप में जोड़कर इंस्टॉल कर सकते हैं।
पूर्ण-पाठ खोज जांच
कृपया मास्टर डेटाबेस के विरुद्ध निम्न स्क्रिप्ट चलाकर पूर्ण-पाठ खोज और सिमेंटिक खोज स्थापना स्थिति की जाँच करें:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO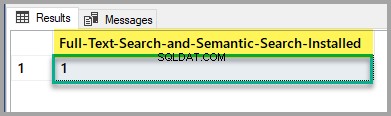
यदि आउटपुट 1 है, तो आप जाने के लिए अच्छे हैं, लेकिन यदि यह 0 है, तो कृपया SQL सर्वर सेटअप का उपयोग करके पूर्ण-पाठ खोज और सिमेंटिक खोज सुविधा स्थापित करने के लिए ऊपर वर्णित लेख देखें।
अर्थपूर्ण भाषा सांख्यिकी डेटाबेस स्थापित करें
या तो Microsoft® SQL Server® 2016 सिमेंटिक भाषा सांख्यिकी खोज कर सिमेंटिक लैंग्वेज स्टैटिस्टिक्स डेटाबेस इंस्टॉल करें इंटरनेट पर या निम्न लिंक पर क्लिक करके।
अपने Windows संस्करण के आधार पर डाउनलोड का चयन करना:
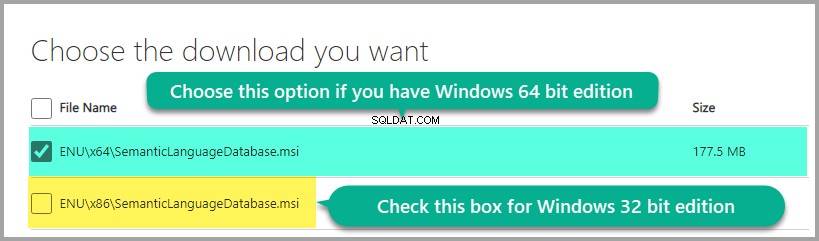
भाषा डेटाबेस स्थापित करें:
अगला क्लिक करें यदि आप लाइसेंस समझौते की शर्तों के साथ ठीक हैं तो आगे बढ़ने के लिए:
डिफ़ॉल्ट विकल्पों को वैसे ही रहने दें जैसे वे हैं, लेकिन डिस्क लागत की जाँच करने की अनुशंसा की जाती है जैसा कि नीचे दिखाया गया है:
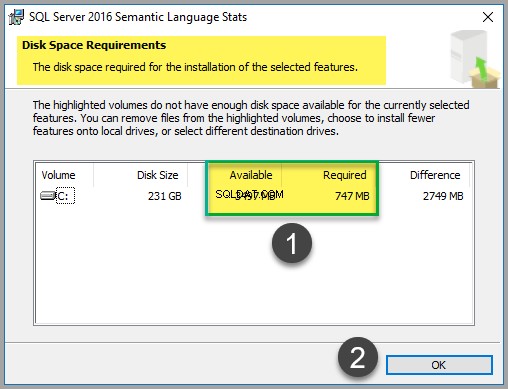
हालाँकि फ़ाइल केवल 747 एमबी स्थान लेती है (इस लेख को लिखते समय), यह सुनिश्चित करने के लिए कि आपके पास पर्याप्त स्थान उपलब्ध है, डिस्क लागत की जाँच करें:
एक बार जब आप डिस्क की लागत की जांच कर लें, तो ठीक . पर क्लिक करें और फिर अगला . क्लिक करें ।
आपको फ़ाइल स्थापित करने के लिए कहा जाएगा, कृपया इंस्टॉल करें . क्लिक करें (यदि ऐसा करने में दिलचस्पी है):
समाप्त करें क्लिक करें एक बार इंस्टॉलेशन सफलतापूर्वक हो जाने के बाद, जो नीचे दिए गए स्क्रीनशॉट की तरह दिखना चाहिए:
उस फ़ोल्डर का पता लगाएँ जहाँ सिमेंटिक लैंग्वेज डेटाबेस डिफ़ॉल्ट रूप से स्थापित किया गया था (C:\Program Files\Microsoft Semantic Language Database):
सब कुछ अच्छा लग रहा है, इसलिए डेटा और लॉग फ़ाइल को अपने SQL इंस्टेंस डेटा फ़ोल्डर में कॉपी करें जैसा कि नीचे दिखाया गया है:
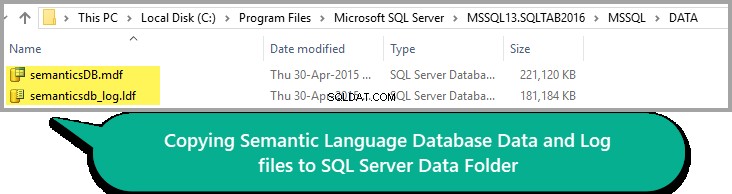
कृपया याद रखें कि आपके SQL सर्वर संस्करण के आधार पर डेटा फ़ोल्डर का पथ भिन्न हो सकता है।
सिमेंटिक लैंग्वेज डेटाबेस को SQL इंस्टेंस से अटैच करें
डेटाबेस पर राइट क्लिक करें SSMS (SQL सर्वर प्रबंधन स्टूडियो) में ऑब्जेक्ट एक्सप्लोरर के अंतर्गत नोड और संलग्न करें . क्लिक करें :
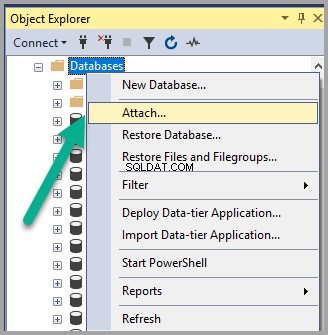
जोड़ें Semanticsdb.mdf और ठीक . क्लिक करें :
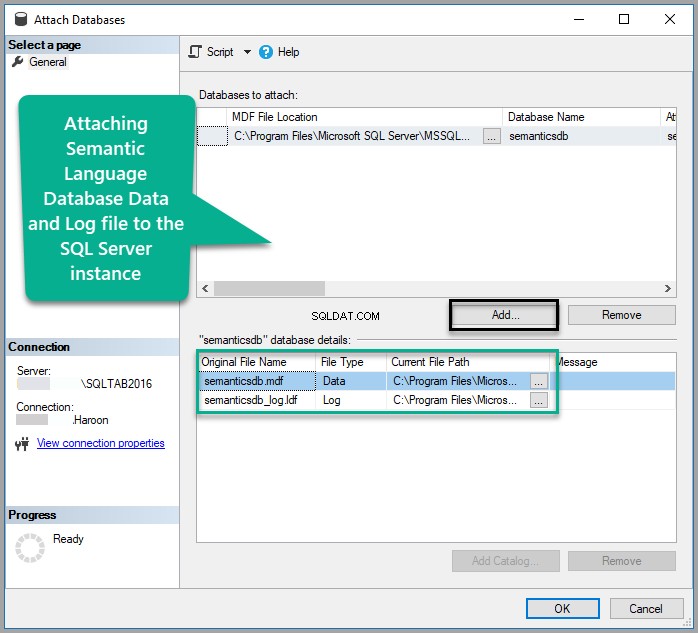
डेटाबेस देखें:
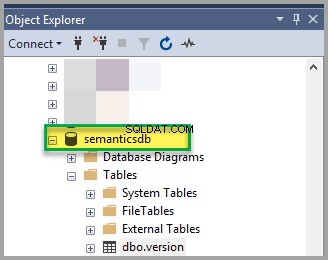
अर्थपूर्ण डेटाबेस पंजीकृत करें
सिमेंटिक लैंग्वेज स्टैटिस्टिक्स डेटाबेस को रजिस्टर करने के लिए मास्टर डेटाबेस के सामने निम्न स्क्रिप्ट टाइप करें:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOअर्थपूर्ण डेटाबेस स्थिति जांचें
मास्टर डेटाबेस के विरुद्ध निम्न स्क्रिप्ट चलाकर सिमेंटिक लैंग्वेज स्टैटिस्टिक्स डेटाबेस स्थिति की जाँच करें:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GOआउटपुट खाली नहीं होना चाहिए और इस प्रकार होगा:

कृपया याद रखें कि उपरोक्त मान आपकी मशीन पर भिन्न हो सकते हैं, जो सामान्य है जब तक आप एक पंक्ति देखते हैं, तो इसका मतलब है कि सिमेंटिक भाषा सांख्यिकी डेटाबेस आपके SQL इंस्टेंस पर सफलतापूर्वक स्थापित किया गया है।
अर्थपूर्ण खोज का उपयोग करना
एक बार सिमेंटिक सर्च पूरी तरह से सेट हो जाने के बाद, हम इसे SQL सर्वर में उपयोग करने के लिए तैयार हैं।
अर्थपूर्ण खोज परिदृश्य
हम कर्मचारियों के दस्तावेज़ (नमूने) को SQL सर्वर डेटाबेस में रिच टेक्स्ट प्रारूप में संग्रहीत करने जा रहे हैं, जिन्हें बाद में सिमेंटिक सर्च का उपयोग करके खोजा और तुलना की जाएगी।
एक कर्मचारी नमूना डेटाबेस सेट करें
मास्टर डेटाबेस के विरुद्ध टी-एसक्यूएल स्क्रिप्ट को निम्नानुसार चलाकर एकल तालिका के साथ एक नमूना डेटाबेस बनाएं:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOनमूना डेटाबेस जांचें
केवल नमूना डेटाबेस तालिका की जाँच करने के लिए निम्न स्क्रिप्ट चलाएँ:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssआउटपुट इस प्रकार है:
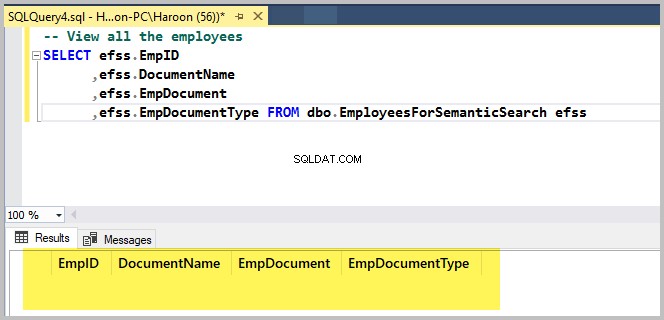
SQL सर्वर के लिए dbForge Studio का उपयोग करके पहली रिच टेक्स्ट फ़ाइल जोड़ें
हम टेबल में बाइनरी डेटा जोड़ने जा रहे हैं, जो कि SQL सर्वर के लिए dbForge Studio का उपयोग करके रिच टेक्स्ट फ़ाइलों द्वारा दर्शाया जाता है। ।
नमूना डेटाबेस खोलें कर्मचारियों का नमूना SQL सर्वर के लिए dbForge Studio में।
कर्मचारियों के लिए अर्थपूर्ण खोज . पर राइट क्लिक करें तालिका और क्लिक करें डेटा पुनर्प्राप्त करें:
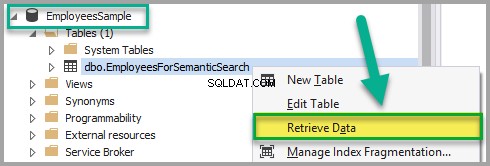
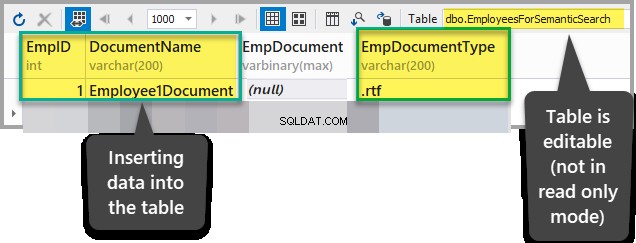
कर्मचारियों के लिए अर्थपूर्ण खोज में निम्न डेटा जोड़ें EmpDocument . को छोड़कर तालिका यह सुनिश्चित करने के बाद कि तालिका केवल-पढ़ने के लिए मोड में नहीं है:
एम्पआईडी:1
दस्तावेज़ का नाम:कर्मचारी1दस्तावेज़
EmpDocument:(null)
EmpDocumentType:.rtf
EmpDocument . में रिच टेक्स्ट फ़ॉर्मेट दस्तावेज़ डालें तालिका में निम्नलिखित पाठ जोड़कर कॉलम (दीर्घवृत्त पर क्लिक करके और डेटा जोड़कर):
This is a research based article and it is a new research which is in process but this is superb in the field of research.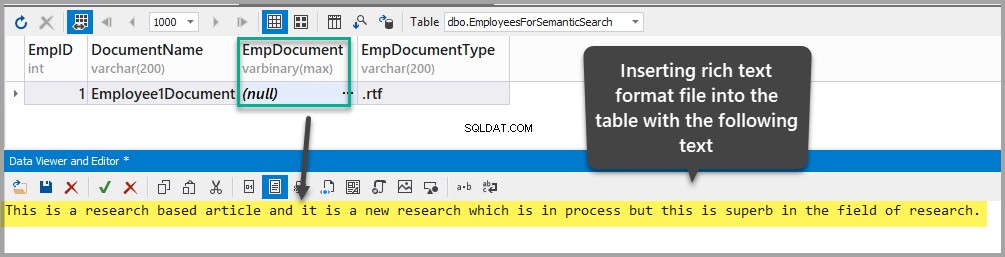
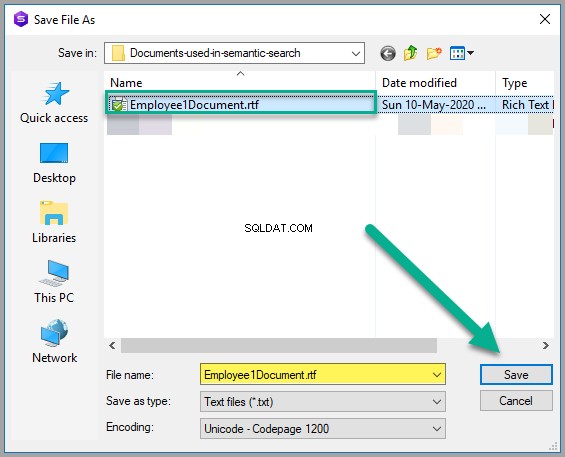
दस्तावेज़ को कर्मचारी1Document.rtf . के रूप में सहेजें किसी भी उपयुक्त विंडोज़ फ़ोल्डर में:
कृपया यह देखने के लिए परिवर्तन लागू करें कि आपने तालिका में रिच टेक्स्ट फ़ाइल को सफलतापूर्वक संग्रहीत कर लिया है:
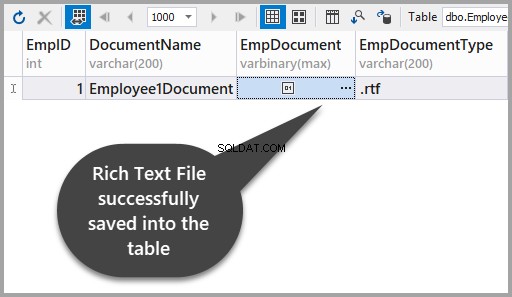
SQL सर्वर के लिए dbForge Studio का उपयोग करके दूसरी रिच टेक्स्ट फ़ाइल जोड़ें
इसके बाद, EmployeesForSemanticSearch . में एक और रिच टेक्स्ट फ़ाइल जोड़ें नीचे दी गई जानकारी का उपयोग करके उसी तरह तालिका बनाएं:
एम्पिड:2
दस्तावेज़ का नाम:Employee2दस्तावेज़
EmpDocument:(null)
EmpDocumentType:.rtf
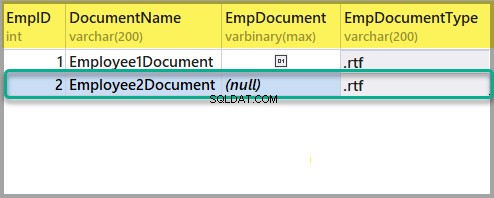
निम्नलिखित टेक्स्ट के साथ एक और रिच टेक्स्ट फ़ाइल जोड़ें:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.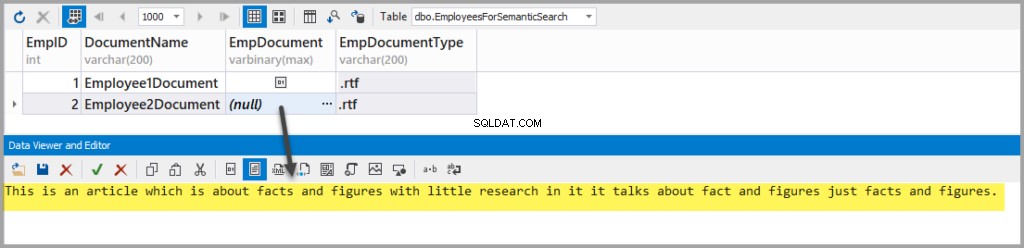
दस्तावेज़ को उसी फ़ोल्डर में इस प्रकार सहेजें:
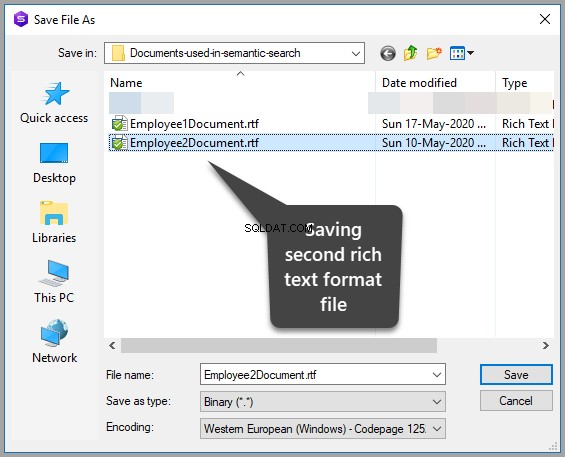
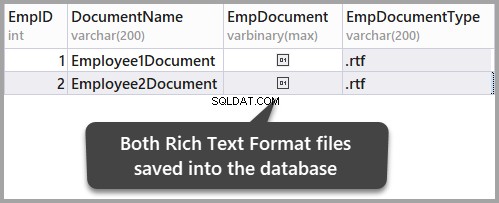
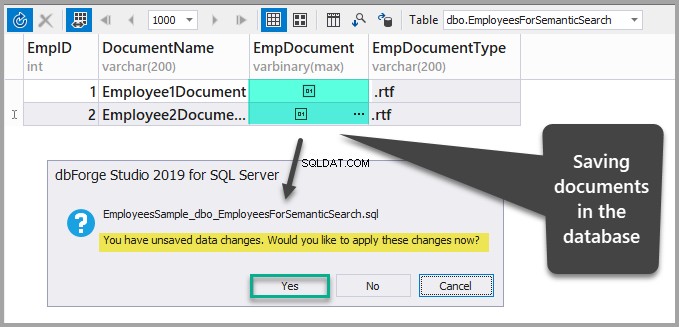
तालिका को रीफ़्रेश करके डेटा सहेजें और फिर हाँ क्लिक करके आपके द्वारा अभी-अभी किए गए परिवर्तनों की पुष्टि करें:
विज़ार्ड का उपयोग करके एक अद्वितीय अनुक्रमणिका, पूर्ण-पाठ अनुक्रमणिका और सिमेंटिक अनुक्रमणिका बनाएं
SSMS (SQL सर्वर प्रबंधन स्टूडियो) में वापस, तालिका पर राइट-क्लिक करें और पूर्ण-पाठ अनुक्रमणिका क्लिक करें और फिर क्लिक करें पूर्ण-पाठ अनुक्रमणिका परिभाषित करें… जैसा कि नीचे दिखाया गया है:
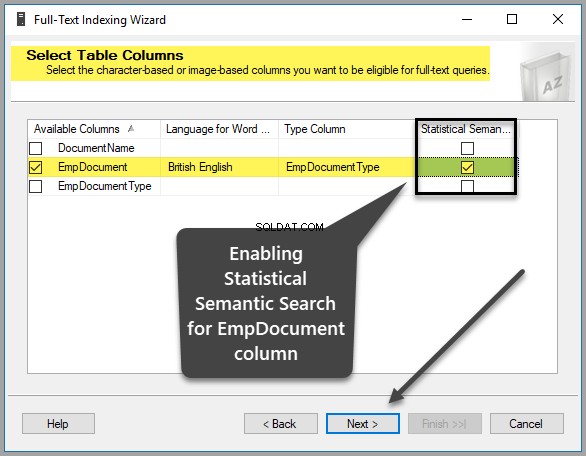
इसके बाद, आपको एक अद्वितीय अनुक्रमणिका का चयन करना होगा, जो वास्तव में डिफ़ॉल्ट रूप से चयनित है, जैसा कि हमने EmpID बनाया है प्राथमिक कुंजी कॉलम पहले जैसा कि नीचे दिखाया गया है, इसलिए अगला . पर क्लिक करें जारी रखने के लिए:
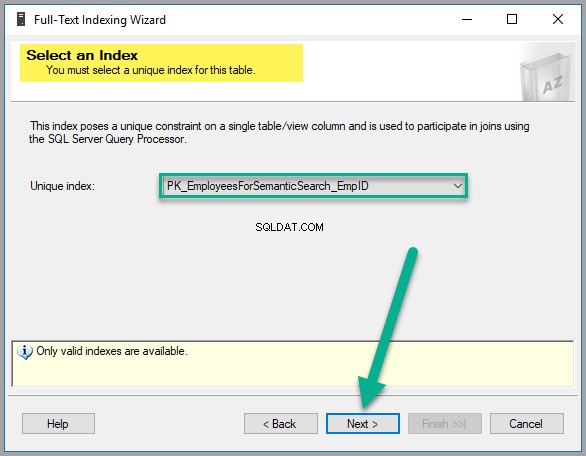
कृपया EmpDocument . चुनें उपलब्ध कॉलम . से , ब्रिटिश अंग्रेज़ी वर्ड ब्रेकर के लिए भाषा . के रूप में , EmpDocumentType टाइप कॉलम . के रूप में और सांख्यिकीय अर्थपूर्ण खोज की जांच करें एक ही पंक्ति में बॉक्स इस प्रकार है:
जब तक आपके पास इन सेटिंग्स को बदलने का कोई ठोस कारण न हो, तब तक परिवर्तन ट्रैकिंग विकल्प को डिफ़ॉल्ट सेटिंग्स के रूप में छोड़ कर चुनें:
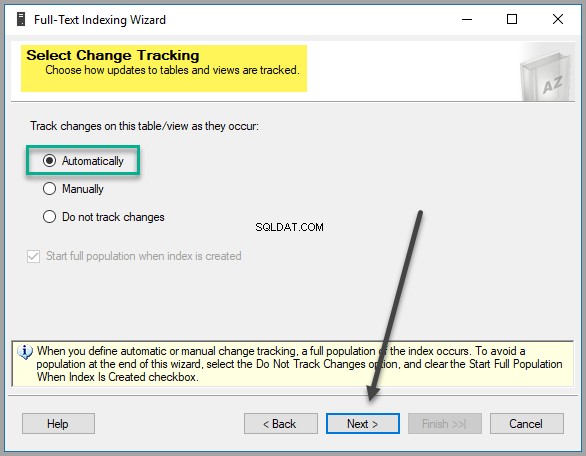
कर्मचारी कैटलॉग . के रूप में एक नया कैटलॉग बनाएं :
अगला क्लिक करें फिर से:
अंत में, कुछ और क्लिक के बाद (अगलाClick क्लिक करें) ), आवश्यक तालिका सिमेंटिक सर्च द्वारा पूछे जाने के लिए तैयार है:
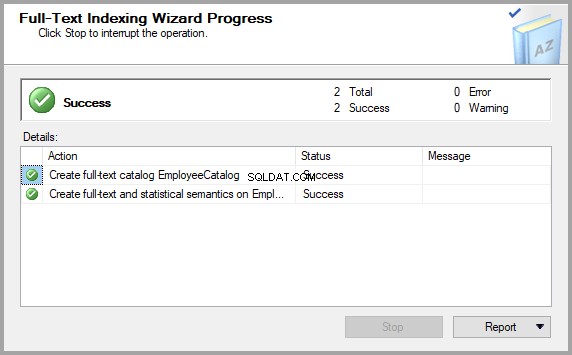
जांचें कि तालिका के लिए अर्थपूर्ण खोज सक्षम है या नहीं
नमूना डेटाबेस के विरुद्ध निम्न स्क्रिप्ट चलाकर कृपया जाँचें कि क्या शब्दार्थ खोज रुचि की तालिका के लिए बरकरार है:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOआउटपुट को इंगित करना चाहिए कि इसे तीसरे कॉलम के लिए सक्षम किया गया है क्योंकि हमने इसे वॉकथ्रू की शुरुआत में सेट किया था:
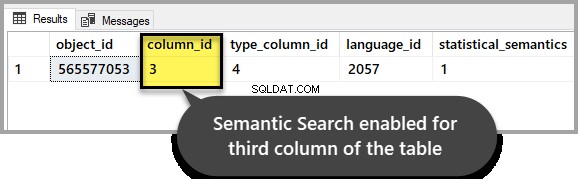
उदाहरण 1:प्रासंगिक दस्तावेज़ खोजने के लिए सिमेंटिक सर्च स्कोर का उपयोग करना
रुचि के कीवर्ड और उसके सापेक्ष स्कोर को खोजने के लिए अब हम दो दस्तावेज़ों की तुलना करने के लिए सिमेंटिक सर्च का उपयोग कर सकते हैं, जो हमें अधिक प्रासंगिक दस्तावेज़ों की ओर इंगित करने में मदद करता है।
यदि हम उस दस्तावेज़ को देखने में रुचि रखते हैं जहाँ शब्द “शोध “अन्य दस्तावेज़ की तुलना में अधिक बार उल्लेख किया गया है, तब हमें निम्नलिखित टी-एसक्यूएल स्क्रिप्ट चलाते समय प्रत्येक दस्तावेज़ के स्कोर पर नज़र रखनी होगी:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;उपरोक्त क्वेरी का परिणाम इस प्रकार है:
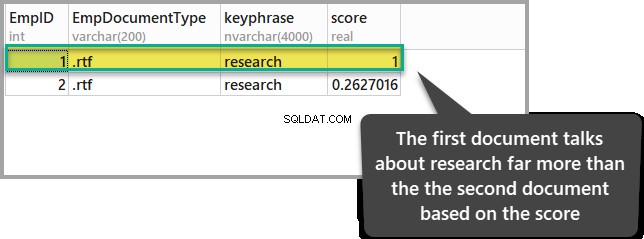
उच्चतम स्कोर वाला दस्तावेज़ दिखाता है कि जहां तक हमारी रुचि (शोध) का संबंध है, अन्य दस्तावेज़ की तुलना में इसकी अधिक प्रासंगिकता है।
उदाहरण 2:प्रासंगिक दस्तावेज़ खोजने के लिए सिमेंटिक सर्च स्कोर का उपयोग करना
हम उस दस्तावेज़ को भी ढूंढ सकते हैं जहां "तथ्य" शब्द किसी अन्य दस्तावेज़ के मुकाबले नीचे दी गई स्क्रिप्ट को चलाकर हावी है:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;परिणाम इस प्रकार हैं:
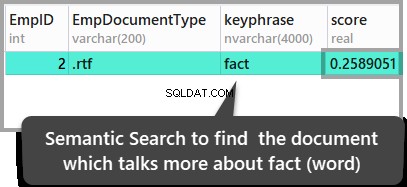
उपरोक्त परिणाम इस निष्कर्ष की ओर ले जाते हैं कि दूसरा संग्रहीत दस्तावेज़ ही एकमात्र ऐसा दस्तावेज़ है जहाँ शब्द तथ्य . है उल्लेख किया गया है, लेकिन यदि आप इन परिणामों की जांच करना चाहते हैं, तो संग्रहीत दस्तावेज़ों को देखने के लिए उन्हें खोलें।
बधाई हो! आपने SQL सर्वर में न केवल सिमेंटिक सर्च सेट करना सफलतापूर्वक सीखा है, बल्कि सिमेंटिक सर्च का उपयोग करने का कुछ व्यावहारिक अनुभव भी प्राप्त किया है।
करने के लिए चीज़ें
अब जब आप कुछ बुनियादी अर्थपूर्ण खोज क्वेरी सेट अप कर सकते हैं और लिख सकते हैं, तो अपने कौशल को और बेहतर बनाने के लिए निम्न प्रयास करें:
- कोई अन्य दस्तावेज़ जोड़ने का प्रयास करें जो अनुसंधान . के बारे में बताता हो और फिर उनके स्कोर की तुलना करके यह देखने के लिए कि कौन सा दस्तावेज़ सबसे प्रासंगिक दस्तावेज़ है, पहले उदाहरण में स्क्रिप्ट चलाएँ।
- इस लेख को ध्यान में रखते हुए, एक और दस्तावेज़ जोड़ें जिसमें तथ्य . शब्द हो दो बार उल्लेख किया गया है और फिर इस आलेख के उदाहरण 2 में टी-एसक्यूएल चलाएं ताकि यह देखने के लिए कि परिणाम वही रहते हैं या बदलते हैं।
- मौजूदा और नए दोनों दस्तावेज़ों में अधिक दस्तावेज़ और अधिक टेक्स्ट जोड़कर और फिर अपनी रुचि के शब्दों से मेल खाने वाले दस्तावेज़ ढूंढ़कर सिमेंटिक खोज का उपयोग करने का प्रयास करें।
- सीमेंटिक सर्च केस सेंसिटिव है या केस असंवेदनशील (संकेत:आप उदाहरणों को थोड़ा संशोधित कर सकते हैं) यह पता लगाने के लिए आगे उदाहरणों का अन्वेषण करें।