इस लेख में, मैं यह समझाने जा रहा हूं कि प्राथमिक फाइलग्रुप से सेकेंडरी फाइलग्रुप में टेबल को कैसे स्थानांतरित किया जाए। सबसे पहले, आइए समझते हैं कि डेटाफाइल, फाइलग्रुप और फाइलग्रुप के प्रकार क्या हैं।
डेटाबेस फ़ाइलें और फ़ाइल समूह
जब SQL सर्वर किसी भी सर्वर पर स्थापित होता है, तो यह डेटा स्टोर करने के लिए एक प्राथमिक डेटा फ़ाइल और लॉग फ़ाइल बनाता है। प्राथमिक डेटा फ़ाइल डेटा और डेटाबेस ऑब्जेक्ट जैसे टेबल, इंडेक्स, संग्रहीत कार्यविधियाँ आदि संग्रहीत करती है। लॉग फ़ाइलें लेन-देन को पुनर्प्राप्त करने के लिए आवश्यक जानकारी संग्रहीत करती हैं। डेटा फ़ाइलों को फ़ाइल समूहों में एक साथ जोड़ा जा सकता है।
SQL सर्वर में तीन प्रकार की फाइलें होती हैं
- प्राथमिक फ़ाइल :यह तब बनाया जाता है जब SQL सर्वर स्थापित किया जा रहा होता है, और इसमें डेटाबेस मेटाडेटा और जानकारी होती है। उपयोगकर्ता डेटा, वस्तुओं को प्राथमिक डेटा फ़ाइलों पर संग्रहीत किया जा सकता है। प्राथमिक फ़ाइल में .mdf एक्सटेंशन है।
- द्वितीयक फ़ाइल :द्वितीयक फ़ाइलें उपयोगकर्ता-परिभाषित होती हैं। वे उपयोगकर्ता डेटा, उपयोगकर्ता द्वारा बनाई गई वस्तुओं को संग्रहीत करते हैं। उनके पास .ndf एक्सटेंशन है।
- लेन-देन लॉग फ़ाइल s:T-Logs फ़ाइलें डेटाबेस को पुनर्प्राप्त करने के लिए किए गए सभी लेन-देन को लॉग करती हैं। लॉग फ़ाइल एक्सटेंशन .ldf. . में
जैसा कि मैंने ऊपर उल्लेख किया है, डेटा फ़ाइलों को एक फ़ाइल समूह में समूहीकृत किया जा सकता है। जबकि SQL सर्वर स्थापित किया जा रहा है, यह प्राथमिक फ़ाइल समूह बनाता है जिसमें प्राथमिक डेटा फ़ाइल होती है। द्वितीयक फ़ाइल समूह उपयोगकर्ता-परिभाषित हैं। उनके पास द्वितीयक डेटा फ़ाइलें हैं। जब हम एक नया डेटाबेस बनाते हैं, तो हम सेकेंडरी डेटाफाइल्स और फाइलग्रुप्स बना सकते हैं। द्वितीयक डेटा फ़ाइलों को जोड़ने से प्रदर्शन में सुधार करने में मदद मिलती है। इसे विभिन्न डिस्क ड्राइव या अलग डिस्क विभाजन पर बनाया जा सकता है जो IO प्रतीक्षा और पढ़ने-लिखने की विलंबता को कम करता है।
टेबल और इंडेक्स को अलग-अलग फाइलग्रुप में रखने की सिफारिश की जाती है। साथ ही, बड़ी तालिकाओं को अलग फ़ाइलों में रखने से प्रदर्शन में सुधार होता है।
फ़ाइल समूह तीन प्रकार के होते हैं:
- पंक्ति फ़ाइल समूह पंक्ति फ़ाइल समूह, जिसे प्राथमिक फ़ाइल समूह के रूप में भी जाना जाता है, में एक प्राथमिक डेटा फ़ाइल होती है। SQL ऑब्जेक्ट, डेटा, सिस्टम टेबल प्राथमिक फ़ाइल समूह को आवंटित करते हैं।
- स्मृति-अनुकूलित फ़ाइल समूह :मेमोरी-अनुकूलित फ़ाइलग्रुप में मेमोरी अनुकूलित टेबल और डेटा होता है। स्मृति में OLTP सक्षम करने के लिए, हमें स्मृति-अनुकूलित फ़ाइल समूह बनाने की आवश्यकता है।
- फाइलस्ट्रीम :फ़ाइल-स्ट्रीम फ़ाइल समूह में फ़ाइल-स्ट्रीम डेटा जैसे चित्र, दस्तावेज़, निष्पादन योग्य फ़ाइलें आदि शामिल हैं। प्राथमिक फ़ाइल समूह में फ़ाइल-स्ट्रीम डेटा नहीं हो सकता है, हमें एक फ़ाइलस्ट्रीम फ़ाइल समूह बनाने की आवश्यकता है। इसमें फाइलस्ट्रीम डेटा होता है।
डेमो सेटअप
इस डेमो में, मैंने SQL सर्वर 2017 इंस्टेंस पर "डेमोडेटाबेस" बनाया। डेटाबेस पर "रिकॉर्ड" और "रोगी डेटा" टैब बनाए गए थे। "PK_CIDX_Records_ID" प्राथमिक कुंजी "रिकॉर्ड्स" टेबल पर बनाई गई थी और "CIDX_PatientData_ID" क्लस्टर इंडेक्स "PatientData" टेबल पर बनाए गए थे। इस डेमो में, मैं "रिकॉर्ड्स" और "पेशेंटडेटा" टेबल को प्राइमरी फाइलग्रुप से सेकेंडरी फाइलग्रुप में ले जाऊंगा।
इसके लिए हमें निम्न कार्य करने होंगे:
- एक द्वितीयक फ़ाइल समूह बनाएं।
- द्वितीयक फ़ाइल समूह में डेटा फ़ाइलें जोड़ें।
- प्राथमिक कुंजी बाधा के साथ संकुल अनुक्रमणिका को स्थानांतरित करके तालिका को द्वितीयक फ़ाइल समूह में ले जाएं।
- प्राथमिक कुंजी के बिना संकुल अनुक्रमणिका को स्थानांतरित करके तालिकाओं को द्वितीयक फ़ाइल समूह में ले जाएं।
द्वितीयक फ़ाइल समूह बनाएं
T-SQL का उपयोग करके या SQL सर्वर प्रबंधन स्टूडियो से फ़ाइल जोड़ें विज़ार्ड का उपयोग करके एक द्वितीयक फ़ाइल समूह बनाया जा सकता है। SSMS का उपयोग करके एक फ़ाइल समूह जोड़ने के लिए, SSMS खोलें और एक डेटाबेस चुनें जहाँ एक फ़ाइल समूह बनाने की आवश्यकता है। डेटाबेस पर राइट-क्लिक करें “गुण . चुनें ”>> “फ़ाइल समूह . चुनें ” और “फ़ाइल समूह जोड़ें . पर क्लिक करें "जैसा कि निम्न चित्र में दिखाया गया है:
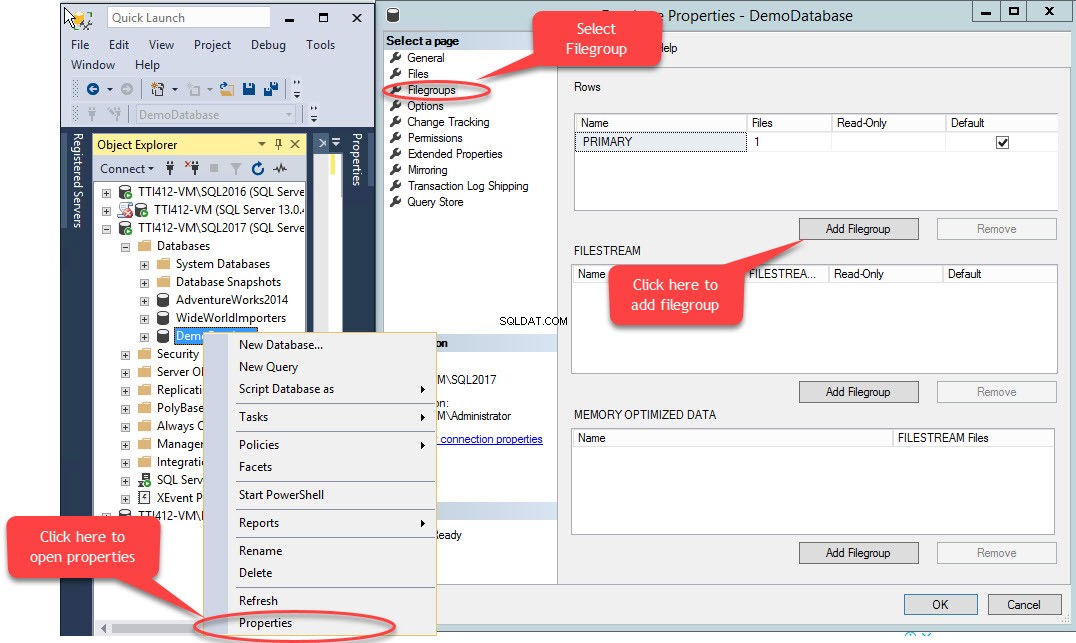
जब हम “फ़ाइल समूह जोड़ें . पर क्लिक करते हैं ” बटन, “पंक्तियों . में एक पंक्ति जोड़ी जाएगी " जाल। “पंक्तियों . में ” ग्रिड, “नाम . में उपयुक्त फ़ाइल समूह नाम प्रदान करें " कॉलम। फ़ाइलग्रुप न तो केवल-पढ़ने के लिए है और न ही डिफ़ॉल्ट; इसलिए, केवल पढ़ने के लिए . रखें और डिफ़ॉल्ट नए फ़ाइल समूह के लिए चेकबॉक्स साफ़ किए गए। निम्न चित्र देखें:
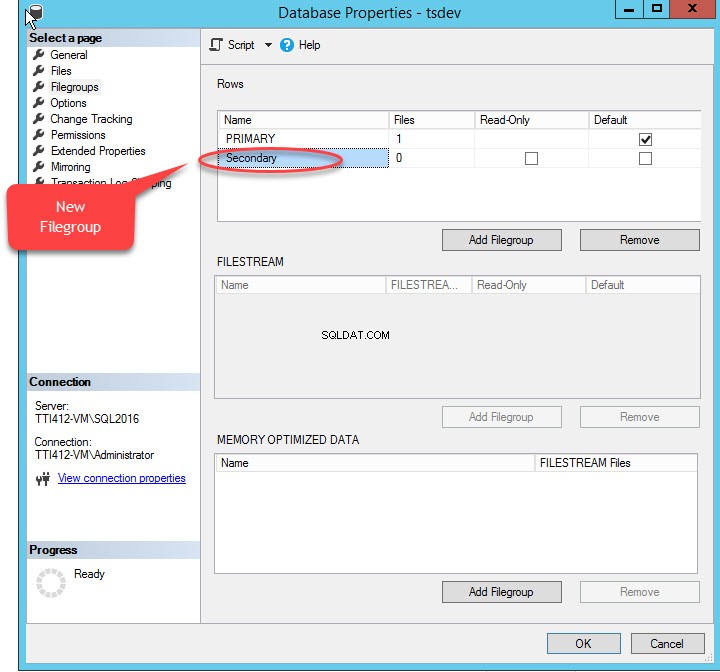
डायलॉग बॉक्स बंद करने के लिए ओके पर क्लिक करें।
T-SQL स्क्रिप्ट का उपयोग करके एक फ़ाइल समूह बनाने के लिए, निम्न स्क्रिप्ट चलाएँ।
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
फ़ाइल समूह में फ़ाइलें जोड़ना
फ़ाइल समूह में फ़ाइलें जोड़ने के लिए, डेटाबेस गुण खोलें, "फ़ाइलें" चुनें और "जोड़ें" पर क्लिक करें। जैसा कि निम्न चित्र में दिखाया गया है:
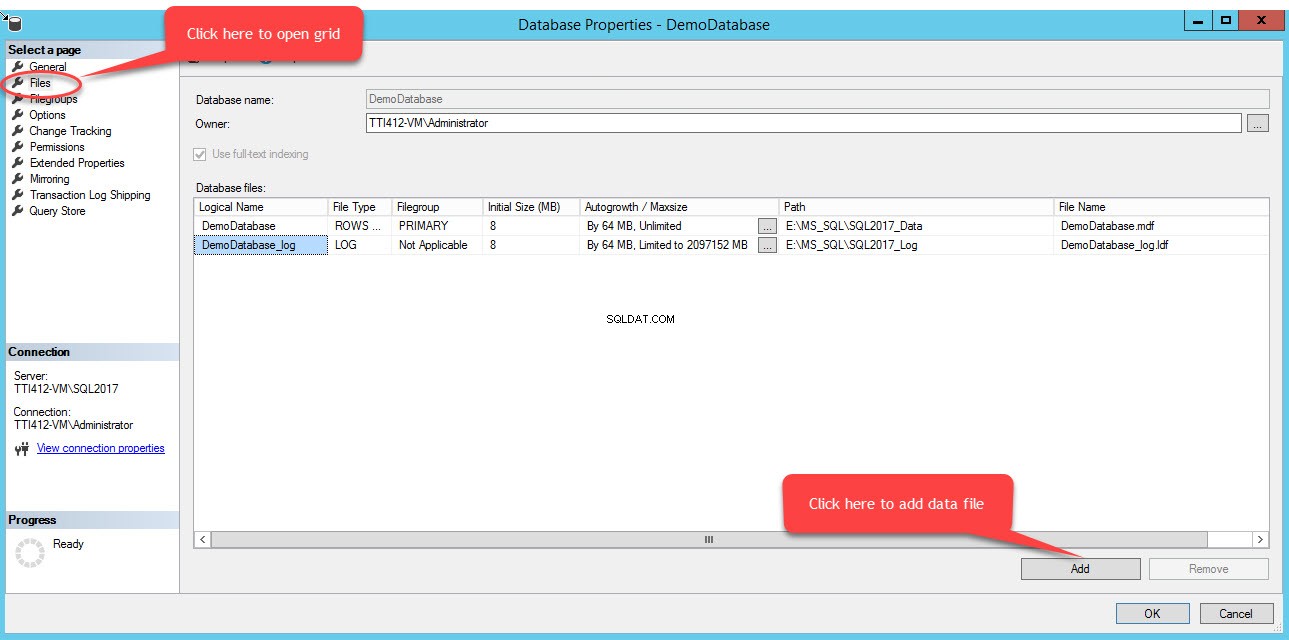
डेटाबेस फ़ाइलें . में एक खाली पंक्ति जोड़ी जाएगी जालक दृश्य। ग्रिड दृश्य में, तार्किक नाम . में उपयुक्त तार्किक नाम प्रदान करें कॉलम में, पंक्तियों का डेटा select चुनें फ़ाइल प्रकार . से ड्रॉप-डाउन बॉक्स में, माध्यमिक select चुनें फ़ाइल समूह . से ड्रॉप-डाउन बॉक्स में, फ़ाइल का आरंभिक आकार प्रारंभिक आकार . में सेट करें कॉलम, ऑटो-ग्रोथ और मैक्स साइज पैरामीटर को ऑटोग्रोथ/मैक्ससाइज . में सेट करें कॉलम, पथ . में द्वितीयक डेटा फ़ाइल का भौतिक स्थान प्रदान करें कॉलम और फ़ाइल नाम . में उपयुक्त फ़ाइल नाम प्रदान करें कॉलम। निम्न चित्र देखें:
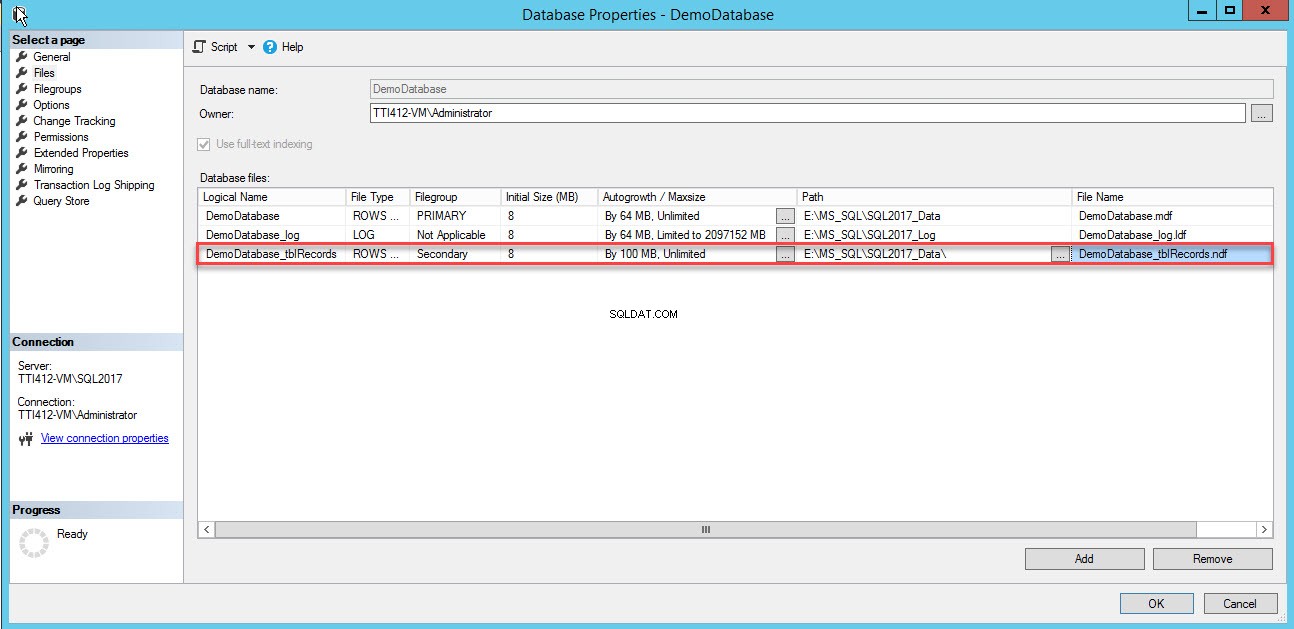
द्वितीयक डेटा फ़ाइल बनाने के लिए निम्न T-SQL स्क्रिप्ट का उपयोग करें।
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
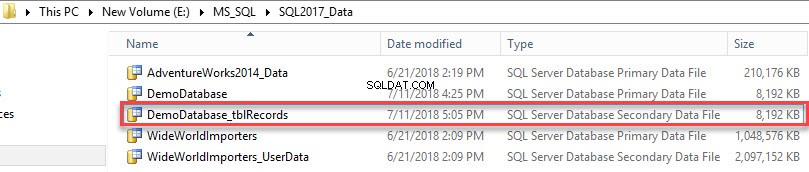
द्वितीयक डेटा फ़ाइल बनाई गई है। निम्न चित्र देखें:
डेटाबेस पर बनाए गए फ़ाइल समूहों की सूची देखने के लिए, निम्न क्वेरी निष्पादित करें।
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
नीचे क्वेरी का आउटपुट दिया गया है।

मौजूदा टेबल को प्राइमरी फाइलग्रुप से सेकेंडरी फाइलग्रुप में ट्रांसफर करना
हम क्लस्टर इंडेक्स को दूसरे फाइलग्रुप में ले जाकर मौजूदा टेबल को दूसरे फाइलग्रुप में ले जा सकते हैं। जैसा कि हम जानते हैं, क्लस्टर्ड इंडेक्स के एक लीफ नोड में वास्तविक डेटा होता है; इसलिए क्लस्टर्ड इंडेक्स को मूव करना पूरी टेबल को दूसरे फाइल ग्रुप में ले जा सकता है। मूविंग इंडेक्स की एक सीमा है:यदि इंडेक्स एक प्राथमिक कुंजी या अद्वितीय बाधा है, तो आप SQL सर्वर प्रबंधन स्टूडियो का उपयोग करके इंडेक्स को स्थानांतरित नहीं कर सकते। उन अनुक्रमणिकाओं को स्थानांतरित करने के लिए, हमें अनुक्रमणिका बनाएं . का उपयोग करने की आवश्यकता है कथन और DROP_Existing=ON . के साथ विकल्प।
प्राथमिक कुंजी बाधा के साथ क्लस्टर किए गए अनुक्रमणिका को स्थानांतरित करना।
प्राथमिक कुंजी अद्वितीय मूल्यों को लागू करती है, इसलिए अद्वितीय क्लस्टर इंडेक्स बनाएं। मुख्य कॉलम पीआरएन है। इसे द्वितीयक फ़ाइल समूह में बनाने के लिए, DROP_EXISTING=ON . सेट करें विकल्प और फ़ाइल समूह माध्यमिक होना चाहिए। निम्न स्क्रिप्ट निष्पादित करें।
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
एक बार कमांड सफलतापूर्वक निष्पादित हो जाने के बाद, सत्यापित करें कि द्वितीयक फ़ाइल समूह में अनुक्रमणिका बनाई गई है। इसके लिए संग्रहण . पर राइट-क्लिक करें अनुक्रमणिका गुण . में विकल्प संवाद बकस। अनुक्रमणिका गुण खोलने के लिए, डेमोडेटाबेस . का विस्तार करें डेटाबेस>> टेबल्स का विस्तार करें>> इंडेक्स का विस्तार करें . PK_CIDX_Records_ID पर राइट-क्लिक करें , जैसा कि निम्न चित्र में दिखाया गया है:
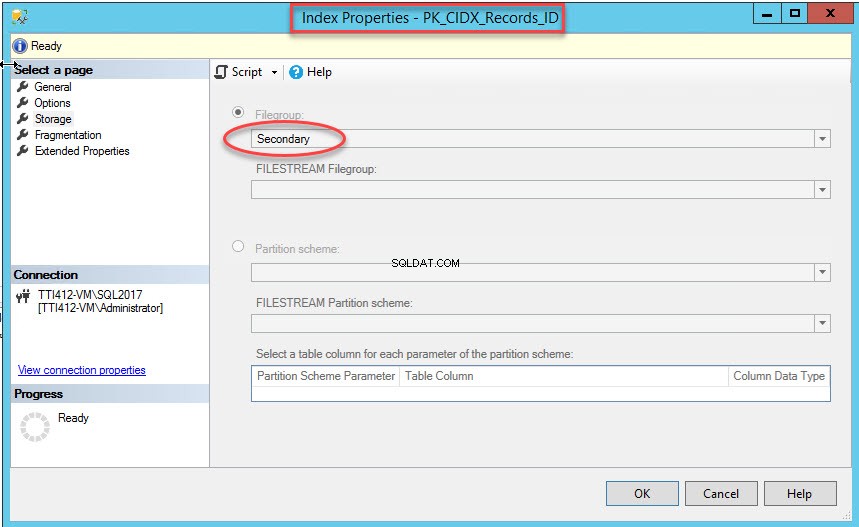
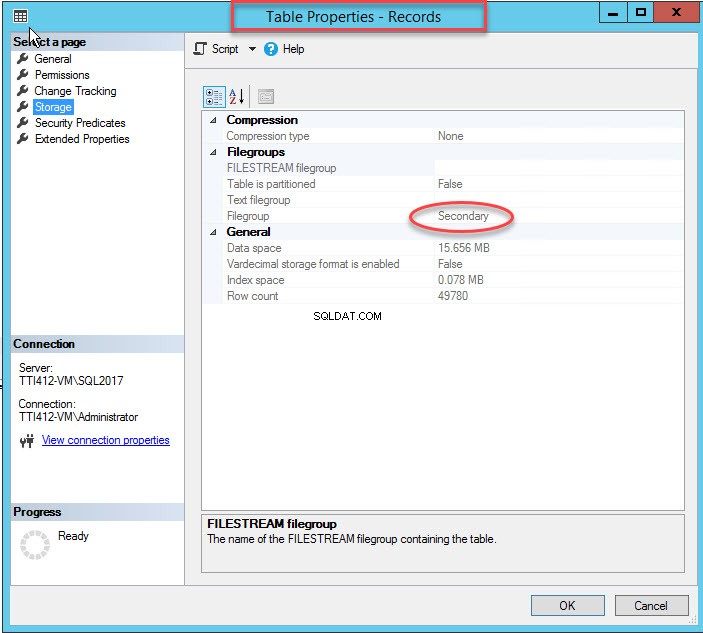
जैसा कि मैंने उल्लेख किया है, एक बार क्लस्टर इंडेक्स एक सेकेंडरी फाइलग्रुप में चला जाता है, टेबल को सेकेंडरी फाइलग्रुप में ले जाया जाएगा। इसे सत्यापित करने के लिए, संग्रहण . पर राइट-क्लिक करें तालिका गुण . में विकल्प संवाद बकस। अनुक्रमणिका गुण खोलने के लिए, डेमोडेटाबेस . का विस्तार करें डेटाबेस>> विस्तृत करें तालिका s>> रिकॉर्ड, पर राइट-क्लिक करें और संग्रहण, . चुनें जैसा कि निम्न चित्र में दिखाया गया है:
प्राथमिक कुंजी के बिना क्लस्टर किए गए अनुक्रमणिका को स्थानांतरित करना
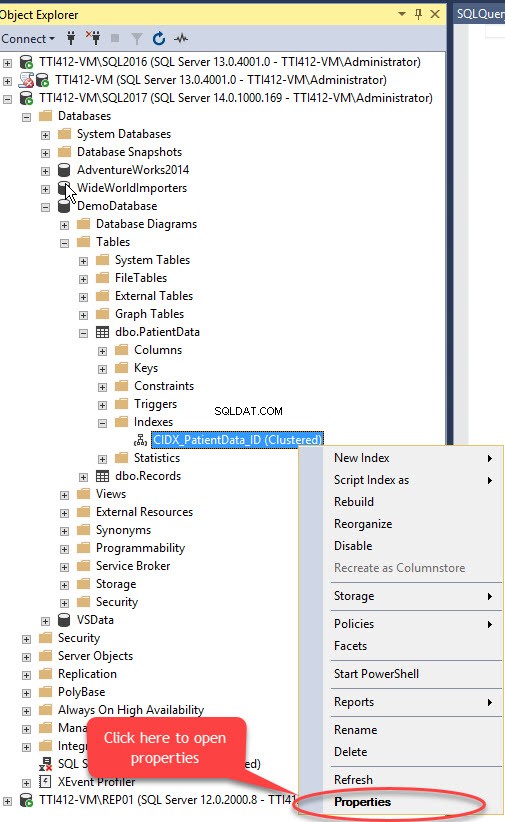
हम SQL सर्वर प्रबंधन स्टूडियो का उपयोग करके प्राथमिक कुंजी के बिना संकुल अनुक्रमणिका को स्थानांतरित कर सकते हैं। ऐसा करने के लिए, डेमोडेटाबेस . का विस्तार करें डेटाबेस>> टेबल्स का विस्तार करें>> इंडेक्स का विस्तार करें s>> CIDX_PatientData_ID . पर राइट-क्लिक करें अनुक्रमणिका करें और गुण, . चुनें जैसा कि निम्न चित्र में दिखाया गया है:
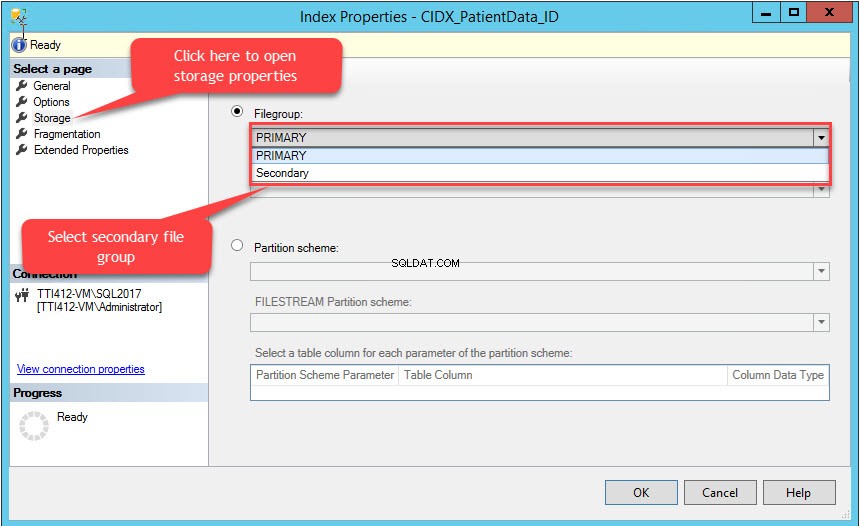
सूचकांक गुण डायलॉग बॉक्स खुलता है। संवाद बॉक्स में, संग्रहण, select चुनें और संग्रहण विंडो में, फ़ाइल समूह . क्लिक करें ड्रॉप-डाउन बॉक्स में, माध्यमिक चुनें फ़ाइल समूह और ठीक, . क्लिक करें जैसा कि निम्न चित्र में दिखाया गया है:
इंडेक्स फाइलग्रुप को बदलने से पूरी इंडेक्स फिर से बन जाएगी। एक बार अनुक्रमणिका बनाने के बाद, तालिका गुण खोलें और एक संग्रहण चुनें।
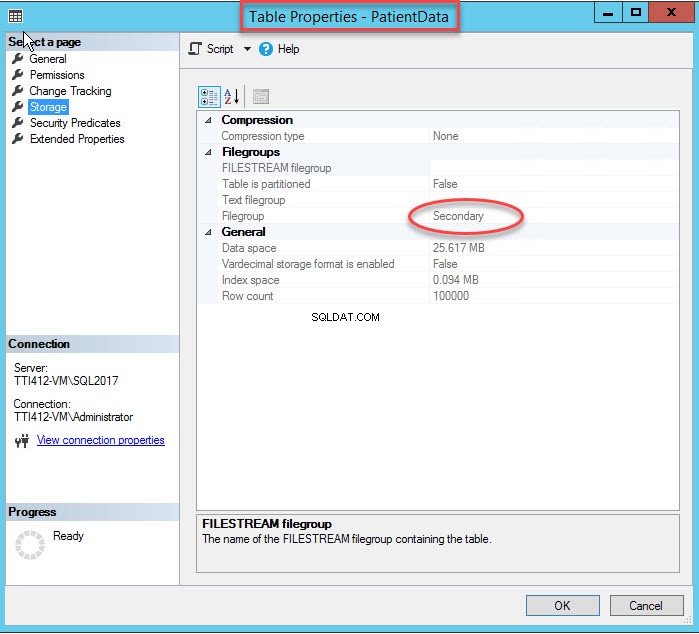
जैसा कि आप ऊपर की छवि में देख सकते हैं, CIDX_PatientData_ID को स्थानांतरित करने के साथ-साथ द्वितीयक फ़ाइल समूह के लिए संकुल अनुक्रमणिका, पेशेंटडेटा तालिका को माध्यमिक . में भी ले जाया जाता है फ़ाइल समूह।
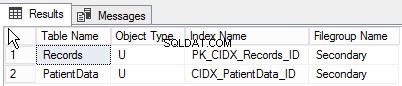
निम्नलिखित क्वेरी को क्रियान्वित करके, आप विभिन्न फ़ाइल समूह के लिए बनाई गई वस्तुओं की सूची पा सकते हैं:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go नीचे क्वेरी का आउटपुट दिया गया है:
सारांश
इस लेख में, मैंने समझाया है
-
- डेटाफ़ाइलों और फ़ाइलसमूहों की मूल बातें।
- सेकेंडरी फाइलग्रुप कैसे बनाएं और उसमें सेकेंडरी डेटाफाइल कैसे जोड़ें।
- स्थानांतरित करके तालिका को द्वितीयक फ़ाइलसमूह में ले जाएँ:
- प्राथमिक कुंजी।
- संकुल अनुक्रमणिका।