अनुक्रमित दृश्य SQL सर्वर के किसी भी संस्करण में बनाए जा सकते हैं, लेकिन यदि आप उनका अधिकतम लाभ उठाना चाहते हैं, तो इसके बारे में जागरूक होने के लिए कई व्यवहार हैं।
स्वचालित आंकड़ों के लिए NOEXPAND संकेत की आवश्यकता होती है
SQL सर्वर क्वेरी ऑप्टिमाइज़ेशन के दौरान कार्डिनैलिटी अनुमान और लागत-आधारित निर्णय लेने में सहायता के लिए स्वचालित रूप से आँकड़े बना सकता है। यह सुविधा अनुक्रमित दृश्यों के साथ-साथ आधार तालिकाओं के साथ भी काम करती है, लेकिन केवल तभी जब दृश्य को स्पष्ट रूप से क्वेरी और NOEXPAND में नामित किया गया हो संकेत निर्दिष्ट है। (एक दृश्य पर प्रत्येक सूचकांक के साथ हमेशा एक सांख्यिकी वस्तु जुड़ी होती है, यह आंकड़ों का स्वत:निर्माण और रखरखाव है जो उस सूचकांक से जुड़ा नहीं है जिसके बारे में हम यहां बात कर रहे हैं।)
यदि आप SQL सर्वर के गैर-एंटरप्राइज़ संस्करणों के साथ काम करने के अभ्यस्त हैं, तो आपने इस व्यवहार को पहले कभी नहीं देखा होगा। SQL सर्वर के निचले संस्करणों के लिए NOEXPAND . की आवश्यकता होती है एक अनुक्रमित दृश्य तक पहुंचने वाली क्वेरी योजना तैयार करने का संकेत। जब NOEXPAND निर्दिष्ट है, स्वचालित आँकड़े अनुक्रमित दृश्यों पर ठीक वैसे ही बनाए जाते हैं जैसे सामान्य तालिकाओं के साथ होते हैं।
उदाहरण - NOEXPAND के साथ मानक संस्करण
SQL सर्वर 2012 मानक संस्करण और एडवेंचर वर्क्स नमूना डेटाबेस का उपयोग करके, हम पहले एक ऐसा दृश्य बनाते हैं जो दो बिक्री तालिकाओं को जोड़ता है और प्रति ग्राहक और उत्पाद की कुल ऑर्डर मात्रा की गणना करता है:
क्रिएट व्यू dbo.CustomerOrders with SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQty =SUM(SOD.OrderQty), NumRows =COUNT_BIG(*) from Sales.SalesOrderDetail AS SODJOIN Sales.SalesOrder SOD. .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
आँकड़ों का समर्थन करने के लिए इस दृष्टिकोण के लिए, हमें एक अद्वितीय क्लस्टर इंडेक्स जोड़कर इसे अमल में लाना होगा। ग्राहक और उत्पाद आईडी का संयोजन दृश्य में अद्वितीय होने की गारंटी है (परिभाषा के अनुसार) इसलिए हम इसे कुंजी के रूप में उपयोग करेंगे। हम इंडेक्स में दोनों कॉलम को किसी भी तरह से निर्दिष्ट कर सकते हैं, लेकिन यह मानते हुए कि हम उत्पाद द्वारा फ़िल्टर करने के लिए और अधिक प्रश्नों की अपेक्षा करते हैं, हम उत्पाद आईडी को प्रमुख कॉलम बनाते हैं। यह क्रिया उत्पाद आईडी मानों से निर्मित हिस्टोग्राम के साथ अनुक्रमणिका आँकड़े भी बनाती है।
dbo.CustomerOrders (ProductID, CustomerID) पर UNIQUE CLUSTERED INDEX cuq बनाएं;
अब हमें एक प्रश्न लिखने के लिए कहा जाता है जो उत्पादों की एक विशेष श्रेणी के लिए प्रति ग्राहक ऑर्डर की कुल मात्रा दिखाता है। हम उम्मीद करते हैं कि अनुक्रमित दृश्य का उपयोग करने वाली निष्पादन योजना एक प्रभावी रणनीति होगी, क्योंकि यह पहले से आंशिक रूप से एकत्रित डेटा में शामिल होने और संचालित होने से बच जाएगी। चूंकि हम SQL सर्वर मानक संस्करण का उपयोग कर रहे हैं, इसलिए हमें स्पष्ट रूप से दृश्य निर्दिष्ट करना चाहिए और NOEXPAND का उपयोग करना चाहिए अनुक्रमित दृश्य तक पहुंचने वाली क्वेरी योजना तैयार करने का संकेत:
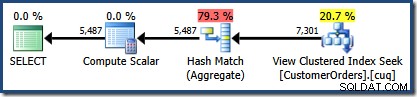
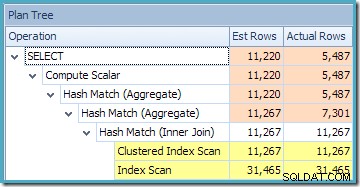
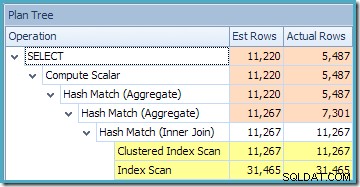
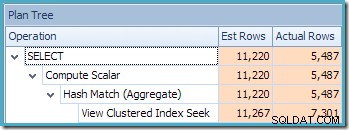
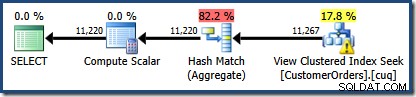
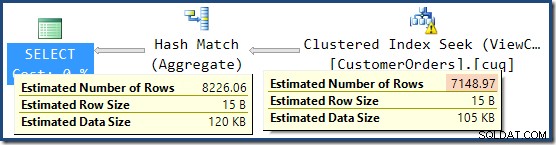
dbo से CO.CustomerID, SUM(CO.OrderQty) चुनें। (NOEXPAND) के साथ CO.उत्पादित निष्पादन योजना ब्याज के उत्पादों के लिए पंक्तियों को खोजने के लिए अनुक्रमित दृश्य पर एक खोज दिखाती है, जिसके बाद प्रति ग्राहक कुल मात्रा की गणना करने के लिए एकत्रीकरण होता है:
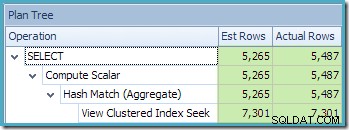
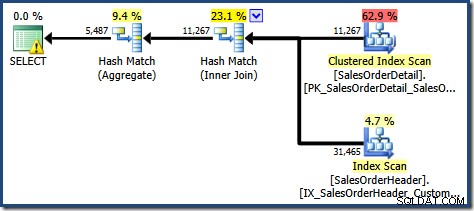
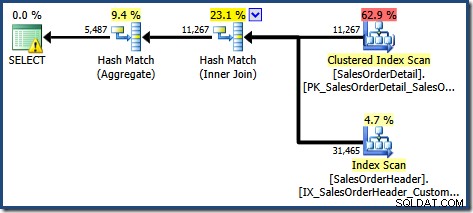
SQL संतरी प्लान एक्सप्लोरर का प्लान ट्री व्यू दिखाता है कि कार्डिनैलिटी का अनुमान अनुक्रमित दृश्य की तलाश के लिए बिल्कुल सही है, और कुल परिणाम के लिए बहुत अच्छा है:
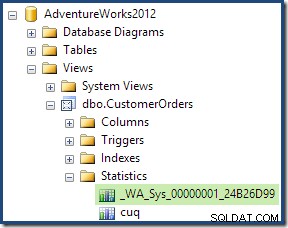
इस क्वेरी के लिए संकलन और अनुकूलन प्रक्रिया के हिस्से के रूप में, SQL सर्वर ने अनुक्रमित दृश्य के ग्राहक आईडी कॉलम पर एक अतिरिक्त सांख्यिकी ऑब्जेक्ट बनाया। यह आँकड़ा इसलिए बनाया गया है क्योंकि ग्राहक आईडी की अपेक्षित संख्या और वितरण महत्वपूर्ण हो सकता है, उदाहरण के लिए एकत्रीकरण रणनीति चुनने में। हम प्रबंधन स्टूडियो ऑब्जेक्ट एक्सप्लोरर का उपयोग करके नया आँकड़ा देख सकते हैं:
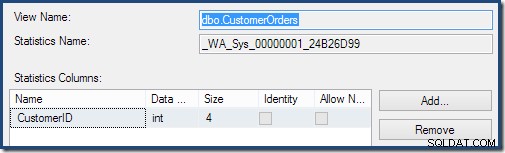
आंकड़े ऑब्जेक्ट पर डबल-क्लिक करने से पुष्टि होती है कि इसे ग्राहक आईडी कॉलम से बनाया गया था (आधार तालिका नहीं):
अनुक्रमित दृश्य कार्डिनैलिटी अनुमान में सुधार कर सकते हैं
अभी भी मानक संस्करण का उपयोग करते हुए, हम अब अनुक्रमित दृश्य को छोड़ देते हैं और फिर से बनाते हैं (जो दृश्य आंकड़े भी छोड़ देता है) और इस बार
NOEXPANDके साथ फिर से क्वेरी निष्पादित करते हैं। संकेत ने टिप्पणी की:CO.CustomerID, SUM(CO.OrderQty) को dbo से चुनें।
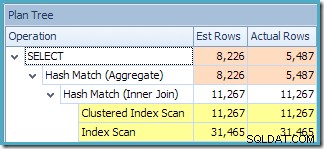
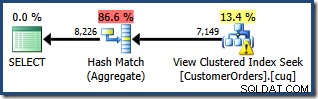
NOEXPAND. के बिना मानक संस्करण का उपयोग करते समय अपेक्षित रूप से , परिणामी क्वेरी योजना सीधे दृश्य के बजाय आधार तालिकाओं पर संचालित होती है:
उपरोक्त योजना में रूट ऑपरेटर पर चेतावनी त्रिकोण हमें बिक्री आदेश विवरण तालिका पर एक संभावित उपयोगी सूचकांक के लिए सचेत कर रहा है, जो हमारे वर्तमान उद्देश्यों के लिए महत्वपूर्ण नहीं है। यह संकलन अनुक्रमित दृश्य पर कोई आँकड़े नहीं बनाता है। क्वेरी संकलन के बाद दृश्य पर एकमात्र आँकड़ा क्लस्टर्ड इंडेक्स से जुड़ा होता है:
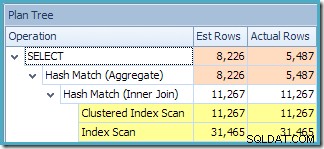
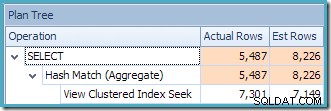
क्वेरी के लिए प्लान ट्री व्यू से पता चलता है कि कार्डिनैलिटी का अनुमान दो टेबल स्कैन और जॉइन के लिए सही है, लेकिन अन्य प्लान ऑपरेटरों के लिए काफी खराब है:
NOEXPAND. के साथ अनुक्रमित दृश्य का उपयोग करना संकेत के परिणामस्वरूप हमारी परीक्षण क्वेरी के लिए अधिक सटीक अनुमान प्राप्त हुए क्योंकि दृश्य के आंकड़ों से बेहतर गुणवत्ता की जानकारी उपलब्ध थी - विशेष रूप से, दृश्य सूचकांक से जुड़े आंकड़े।एक सामान्य नियम के रूप में, सांख्यिकीय जानकारी की सटीकता बहुत तेज़ी से घटती है क्योंकि यह गुजरती है और क्वेरी प्लान ऑपरेटरों द्वारा संशोधित की जाती है। इस संबंध में सरल जोड़ अक्सर बहुत खराब नहीं होते हैं, लेकिन एकत्रीकरण के परिणाम के बारे में जानकारी अक्सर एक शिक्षित अनुमान से बेहतर नहीं होती है। अनुक्रमित दृश्यों पर आँकड़ों का उपयोग करके क्वेरी अनुकूलक को अधिक सटीक जानकारी प्रदान करना योजना की गुणवत्ता और मजबूती को बढ़ाने के लिए एक उपयोगी तकनीक हो सकती है।
NOEXPAND के बिना एक दृश्य एक घटिया योजना बना सकता है
ऊपर दिखाया गया क्वेरी प्लान (मानक संस्करण, बिना
NOEXPAND. के) ) वास्तव में कम इष्टतम है, यदि हमने क्वेरी ऑप्टिमाइज़र को दृश्य का विस्तार करने की अनुमति देने के बजाय, आधार तालिकाओं के विरुद्ध स्वयं क्वेरी लिखी थी। नीचे दी गई क्वेरी उसी तार्किक आवश्यकता को व्यक्त करती है, लेकिन दृश्य को संदर्भित नहीं करती है:Sales से SOH.CustomerID, SUM(OrderQty) चुनें। SOHJOIN Sales के रूप में SalesOrderHeader। SOD पर SOD के रूप में SalesOrderDetail।SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID 711 और SOH.CustomerID द्वारा 718GROUP के बीच;यह क्वेरी निम्नलिखित निष्पादन योजना तैयार करती है:
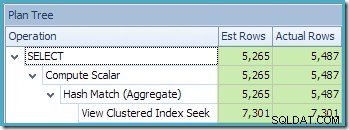
इस योजना में पहले की तुलना में एक कम एकत्रीकरण संचालन है। जब दृश्य विस्तार का उपयोग किया गया था, तो दुर्भाग्य से क्वेरी ऑप्टिमाइज़र एक अनावश्यक एकत्रीकरण ऑपरेशन को हटाने में असमर्थ था, जिसके परिणामस्वरूप एक कम कुशल निष्पादन योजना थी। नई क्वेरी के लिए अंतिम कार्डिनैलिटी अनुमान भी
NOEXPANDके बिना अनुक्रमित दृश्य को संदर्भित किए जाने की तुलना में थोड़ा बेहतर है :
फिर भी, सबसे अच्छे अनुमान अभी भी वे हैं जो अनुक्रमित दृश्य को
NOEXPANDके साथ संदर्भित करते समय उत्पादित किए जाते हैं (सुविधा के लिए नीचे दोहराया गया):
एंटरप्राइज़ संस्करण और मिलान देखें
एंटरप्राइज़ संस्करण इंस्टेंस पर, क्वेरी ऑप्टिमाइज़र अनुक्रमित दृश्य का उपयोग करने में सक्षम हो सकता है, भले ही क्वेरी में स्पष्ट रूप से दृश्य का उल्लेख न हो। यदि ऑप्टिमाइज़र क्वेरी ट्री के हिस्से को अनुक्रमित दृश्य से मिलाने में सक्षम है, तो वह ऐसा करना चुन सकता है, जो दृश्य के उपयोग की लागत के अनुमान के आधार पर है या नहीं। दृश्य-मिलान तर्क यथोचित रूप से चतुर है, लेकिन इसकी सीमाएँ हैं जो व्यवहार में हिट करने में बहुत आसान हैं। यहां तक कि जहां दृश्य मिलान सफल होता है, वहां भी अनुकूलक को गलत लागत अनुमानों से गुमराह किया जा सकता है।
विस्तार दृश्य क्वेरी संकेत
दुर्लभ संभावनाओं के साथ शुरू, ऐसे अवसर हो सकते हैं जहां एक क्वेरी एक अनुक्रमित दृश्य का संदर्भ देती है, लेकिन इसके बजाय बेस टेबल तक पहुंचकर एक बेहतर योजना प्राप्त की जाएगी। इन परिस्थितियों में, क्वेरी संकेत
EXPAND VIEWSइस्तेमाल किया जा सकता है:CO.CustomerID, SUM(CO.OrderQty) को dbo से चुनें।एंटरप्राइज़ संस्करण पर, यह क्वेरी वही योजना तैयार करती है जो मानक संस्करण पर दिखाई देती है जब
NOEXPANDसंकेत छोड़ दिया गया था (अनावश्यक एकत्रीकरण कार्रवाई सहित):
एक तरफ,
EXPAND VIEWSमेरी राय में, संकेत खराब नाम दिया गया है। SQL सर्वर हमेशा एक क्वेरी में दृश्य परिभाषाओं का विस्तार करता है जब तक किNOEXPANDसंकेत निर्दिष्ट है।EXPAND VIEWSसंकेत ऑप्टिमाइज़र में नियमों को अक्षम करता है जो विस्तारित ट्री के कुछ हिस्सों को वापस अनुक्रमित दृश्यों से मिला सकते हैं। किसी भी संकेत के अभाव में, SQL सर्वर पहले किसी दृश्य को उसकी आधार तालिका परिभाषा में विस्तारित करता है, फिर बाद में अनुक्रमित दृश्यों से मिलान करने पर विचार करता है।EXPAND VIEWS. के लिए एक बेहतर नाम संकेत हो सकता हैDISABLE INDEXED VIEW MATCHING, क्योंकि यह वही करता है।
EXPAND VIEWSसंकेत शायद सबसे अधिक बार बेस टेबल के खिलाफ एक क्वेरी को अनुक्रमित दृश्य से मिलान करने से रोकने के लिए उपयोग किया जाता है:Sales से SOH.CustomerID, SUM(OrderQty) चुनें। SOHJOIN Sales के रूप में SalesOrderHeader। SOD पर SOD के रूप में SalesOrderDetail।SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID 711 और SOH द्वारा 718GROUP के बीच;जब हम मानक संस्करण और एक ही बेस-टेबल-ओनली क्वेरी का उपयोग कर रहे थे तब क्वेरी संकेत के परिणाम समान निष्पादन योजना और अनुमानों में दिखाई देते हैं:
एंटरप्राइज़ देखें मिलान और आंकड़े
एंटरप्राइज़ संस्करण में भी, गैर-सूचकांक दृश्य आँकड़े अभी भी केवल तभी बनाए जाते हैं जब
NOEXPANDसंकेत का प्रयोग किया जाता है। इसके बारे में पूरी तरह से स्पष्ट होने के लिए, एंटरप्राइज़-ओनली व्यू-मैचिंग फीचर के परिणामस्वरूप कभी भी दृश्य आँकड़े बनाए या अपडेट नहीं किए जाते हैं। यह अनपेक्षित व्यवहार थोड़ा खोजबीन करने लायक है, क्योंकि इसके आश्चर्यजनक दुष्प्रभाव हो सकते हैं।अब हम एंटरप्राइज़ संस्करण इंस्टेंस पर दृश्य के विरुद्ध अपनी मूल क्वेरी को बिना किसी संकेत के निष्पादित करते हैं:
CO.CustomerID, SUM(CO.OrderQty) को dbo से चुनें।
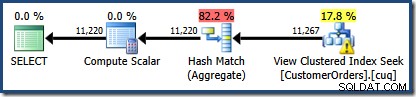
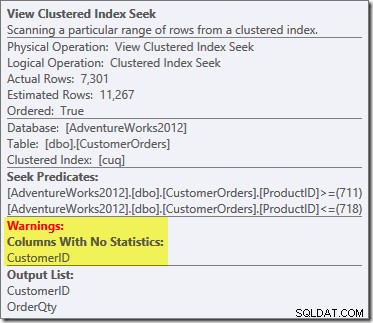
व्यू क्लस्टर्ड इंडेक्स सीक पर एक नई बात चेतावनी त्रिकोण है। टूलटिप विवरण दिखाता है:
हमने
NOEXPAND. का उपयोग नहीं किया संकेत, इसलिए अनुक्रमित दृश्य के ग्राहक आईडी कॉलम पर आंकड़े स्वचालित रूप से नहीं बनाए गए थे। इस सरलीकृत उदाहरण में ग्राहक आईडी के आंकड़े वास्तव में बहुत महत्वपूर्ण नहीं हैं, लेकिन हमेशा ऐसा नहीं होगा।जिज्ञासु कार्डिनैलिटी अनुमान
रुचि की दूसरी बात यह है कि कार्डिनैलिटी अनुमान मानक संस्करण उदाहरणों सहित, अब तक हमारे सामने आए किसी भी मामले से भी बदतर प्रतीत होते हैं।
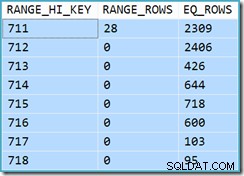
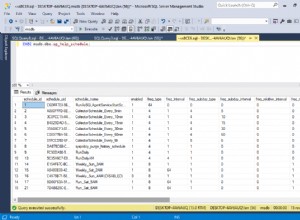
शुरू में यह देखना मुश्किल है कि व्यू क्लस्टर्ड इंडेक्स सीक (11,267) के लिए कार्डिनैलिटी का अनुमान कहां से आया है। हम उम्मीद करते हैं कि यह अनुमान उत्पाद आईडी हिस्टोग्राम जानकारी पर आधारित है, जो व्यू क्लस्टर्ड इंडेक्स से जुड़े आँकड़ों से है। इस हिस्टोग्राम का प्रासंगिक हिस्सा नीचे दिखाया गया है:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') HISTOGRAM के साथ;
यह देखते हुए कि आंकड़े बनाए जाने के बाद से तालिका को संशोधित नहीं किया गया है, हम उम्मीद करेंगे कि अनुमान 711 और 718 के बीच उत्पाद आईडी मानों के लिए RANGE_ROWS और EQ_ROWS का एक साधारण योग होगा (ध्यान दें कि अनुमान में 711 प्रविष्टि के सामने दिखाए गए 28 RANGE_ROWS को शामिल नहीं किया जाना चाहिए। चूंकि वे पंक्तियाँ 711 कुंजी मान से नीचे मौजूद हैं)। दिखाए गए EQ_ROWS का योग 7,301 है। यह वास्तव में दृश्य द्वारा लौटाई गई पंक्तियों की संख्या है - तो 11,267 अनुमान कहां से आया?
उत्तर वर्तमान में दृश्य मिलान के कार्य करने के तरीके में निहित है। हमारी क्वेरी ने
NOEXPAND. निर्दिष्ट नहीं किया संकेत, इसलिए प्रारंभिक कार्डिनैलिटी अनुमान दृश्य-विस्तारित क्वेरी ट्री पर आधारित होते हैं।EXPAND VIEWSके साथ समान क्वेरी के लिए अनुमानित योजना को फिर से देखकर इसे देखना सबसे आसान है निर्दिष्ट:
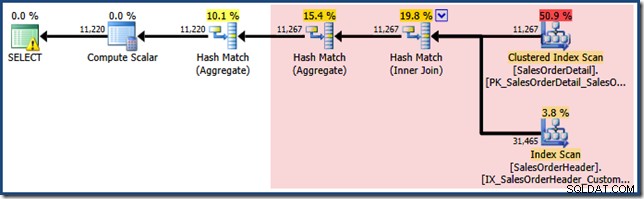
लाल छायांकित क्षेत्र पेड़ के उस हिस्से का प्रतिनिधित्व करता है जिसे दृश्य मिलान गतिविधि द्वारा बदल दिया जाता है। इस क्षेत्र से आउटपुट कार्डिनैलिटी 11,267 है। 11,220 अनुमान के साथ छायांकित भाग दृश्य मिलान से अप्रभावित रहता है। ये ठीक वे अनुमान हैं जिनकी हम व्याख्या करना चाहते थे:
अनुक्रमित दृश्य पर तार्किक रूप से समतुल्य खोज के साथ लाल छायांकित क्षेत्र की जगह मिलान देखें। इसने कार्डिनैलिटी अनुमान की पुनर्गणना करने के लिए सांख्यिकीय जानकारी का उपयोग नहीं किया।
कुछ हद तक, आप शायद इस बात की सराहना कर सकते हैं कि यह इस तरह से क्यों काम कर सकता है:सामान्य तौर पर, यह उम्मीद करने का कोई कारण नहीं है कि सांख्यिकीय जानकारी के एक सेट से गणना की गई अनुमान दूसरे से बेहतर है। एक मामला बनाया जा सकता है कि लाल छायांकित क्षेत्र में पोस्ट-जॉइन व्युत्पन्न आंकड़ों की तुलना में अनुक्रमित दृश्य आंकड़े यहां सटीक होने की अधिक संभावना है, लेकिन इसे सामान्य बनाना मुश्किल हो सकता है, या सही ढंग से यह पता लगाना मुश्किल हो सकता है कि विभिन्न स्रोत कितनी जल्दी हैं सांख्यिकीय जानकारी पुरानी हो सकती है क्योंकि अंतर्निहित डेटा में परिवर्तन होता है।
कोई यह भी तर्क दे सकता है कि यदि हम इतने आश्वस्त होते कि अनुक्रमित दृश्य जानकारी बेहतर होती, तो हम
NOEXPANDका उपयोग करते। संकेत।और भी जिज्ञासु कार्डिनैलिटी अनुमान
एंटरप्राइज़ संस्करण के साथ एक और भी दिलचस्प स्थिति उत्पन्न होती है यदि हम आधार तालिकाओं के विरुद्ध क्वेरी लिखते हैं और स्वचालित दृश्य मिलान पर भरोसा करते हैं:
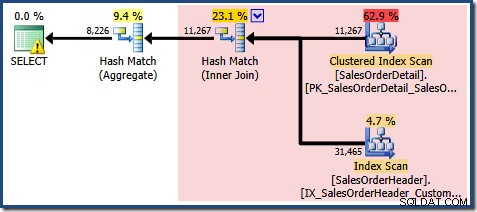
Sales से SOH.CustomerID, SUM(OrderQty) चुनें। SOHJOIN Sales के रूप में SalesOrderHeader। SOD पर SOD के रूप में SalesOrderDetail।SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID 711 और SOH.CustomerID द्वारा 718GROUP के बीच;
लापता सांख्यिकी चेतावनी पहले की तरह ही है, और इसकी व्याख्या एक ही है। अधिक दिलचस्प विशेषता यह है कि अब हमारे पास व्यू क्लस्टर्ड इंडेक्स सीक (7,149) द्वारा उत्पादित पंक्तियों की संख्या के लिए कम अनुमान है और एकत्रीकरण (8,226) से लौटाई गई पंक्तियों की संख्या के लिए एक बढ़ा हुआ अनुमान है।
बिंदु पर जोर देने के लिए, यह क्वेरी योजना इस विचार पर आधारित प्रतीत होती है कि 7,149 स्रोत पंक्तियों को 8,226 पंक्तियों का उत्पादन करने के लिए एकत्रित किया जा सकता है!
स्पष्टीकरण का हिस्सा पहले जैसा ही है।
EXPAND VIEWSलाल क्षेत्र को दर्शाने वाली क्वेरी योजना, जिसे दृश्य मिलान से बदल दिया जाएगा, नीचे दिखाया गया है:
यह बताता है कि 8,226 का अंतिम अनुमान कहां से आता है, लेकिन 7,149 पंक्ति अनुमान के बारे में क्या? पहले देखे गए तर्क के बाद, ऐसा प्रतीत होता है कि दृश्य को 11,267 पंक्तियों का अनुमान दिखाना चाहिए?
इसका उत्तर यह है कि 7,149 अनुमान एक अनुमान है। हाँ सच। अनुक्रमित दृश्य में कुल 79,433 पंक्तियाँ हैं। विधेय के बीच उत्पाद आईडी के लिए जादुई अनुमान प्रतिशत 9% है - 0.09 * 79433 =7148.97 पंक्तियाँ देना। SSMS क्वेरी योजना दर्शाती है कि यह गणना राउंडिंग से पहले ही बिल्कुल सही है:
इस स्थिति में, SQL सर्वर अनुकूलक ने प्रतिस्थापित सबट्री से पोस्ट-जॉइन कार्डिनैलिटी अनुमान पर अनुक्रमित दृश्य कार्डिनैलिटी के आधार पर एक अनुमान को प्राथमिकता दी है। जिज्ञासु।
सारांश
NOEXPAND. का उपयोग करना संकेत गारंटी देता है कि एक अनुक्रमित दृश्य का उपयोग अंतिम क्वेरी योजना में किया जाएगा, और गैर-सूचकांक आँकड़ों को स्वचालित रूप से बनाने, बनाए रखने और क्वेरी अनुकूलक द्वारा उपयोग करने में सक्षम बनाता है।NOEXPANDUsing का उपयोग करना यह भी सुनिश्चित करता है कि प्रारंभिक कार्डिनैलिटी अनुमान बेस टेबल से प्राप्त होने के बजाय अनुक्रमित दृश्य जानकारी पर आधारित हैं।अगर
NOEXPANDनिर्दिष्ट नहीं है, क्वेरी संकलन शुरू होने से पहले (और इसलिए प्रारंभिक कार्डिनैलिटी अनुमान से पहले) दृश्य संदर्भों को हमेशा उनकी आधार तालिका परिभाषाओं से बदल दिया जाता है। केवल एंटरप्राइज़ SKU में, अनुक्रमित दृश्यों को बाद में अनुकूलन प्रक्रिया में क्वेरी ट्री में वापस बदला जा सकता है।
EXPAND VIEWSक्वेरी संकेत ऑप्टिमाइज़र को एंटरप्राइज़ संस्करण अनुक्रमित दृश्य मिलान करने से रोकता है। यह लागू होता है कि क्वेरी मूल रूप से अनुक्रमित दृश्य को संदर्भित करती है या नहीं। जब दृश्य मिलान किया जाता है, तो मौजूदा कार्डिनैलिटी अनुमान को कुछ परिस्थितियों में अनुमान से बदला जा सकता है।अनुक्रमित दृश्य पर अनुपलब्ध के रूप में दिखाए गए आंकड़े मैन्युअल रूप से बनाए जा सकते हैं, लेकिन अनुकूलक आमतौर पर उन प्रश्नों के लिए उनका उपयोग नहीं करेगा जो
NOEXPANDका उपयोग नहीं करते हैं। संकेत।अनुक्रमित दृश्यों का उपयोग करने से कार्डिनैलिटी अनुमान में सुधार हो सकता है, खासकर यदि दृश्य में जोड़ या एकत्रीकरण शामिल हैं। यदि
NOEXPAND. है तो क्वेरीज़ को अधिक सटीक दृश्य आँकड़ों से लाभान्वित होने का सबसे अच्छा मौका मिलता है निर्दिष्ट है।