परिचय
डेवलपर्स को अक्सर तथाकथित तदर्थ प्रश्नों से बचने के लिए संग्रहीत कार्यविधियों का उपयोग करने के लिए कहा जाता है जिसके परिणामस्वरूप योजना कैश की अनावश्यक सूजन हो सकती है। आप देखते हैं, जब आवर्तक SQL कोड असंगत रूप से लिखा जाता है या जब कोई कोड होता है जो मक्खी पर गतिशील SQL उत्पन्न करता है, तो SQL सर्वर में प्रत्येक व्यक्तिगत निष्पादन के लिए एक निष्पादन योजना बनाने की प्रवृत्ति होती है। इससे समग्र प्रदर्शन कम हो सकता है:
हर कोड निष्पादन के लिए एक संकलन चरण की मांग करना।
बहुत सारे प्लान हैंडल के साथ प्लान कैश को फुला देना जिनका पुन:उपयोग नहीं किया जा सकता है।
तदर्थ कार्यभार के लिए अनुकूलित करें
अतीत में इस समस्या से निपटने का एक तरीका एड हॉक वर्कलोड के लिए इंस्टेंस को ऑप्टिमाइज़ करना है। ऐसा करना तभी मददगार हो सकता है जब अधिकांश डेटाबेस या उदाहरण पर सबसे महत्वपूर्ण डेटाबेस मुख्य रूप से एड हॉक एसक्यूएल को क्रियान्वित कर रहे हों।
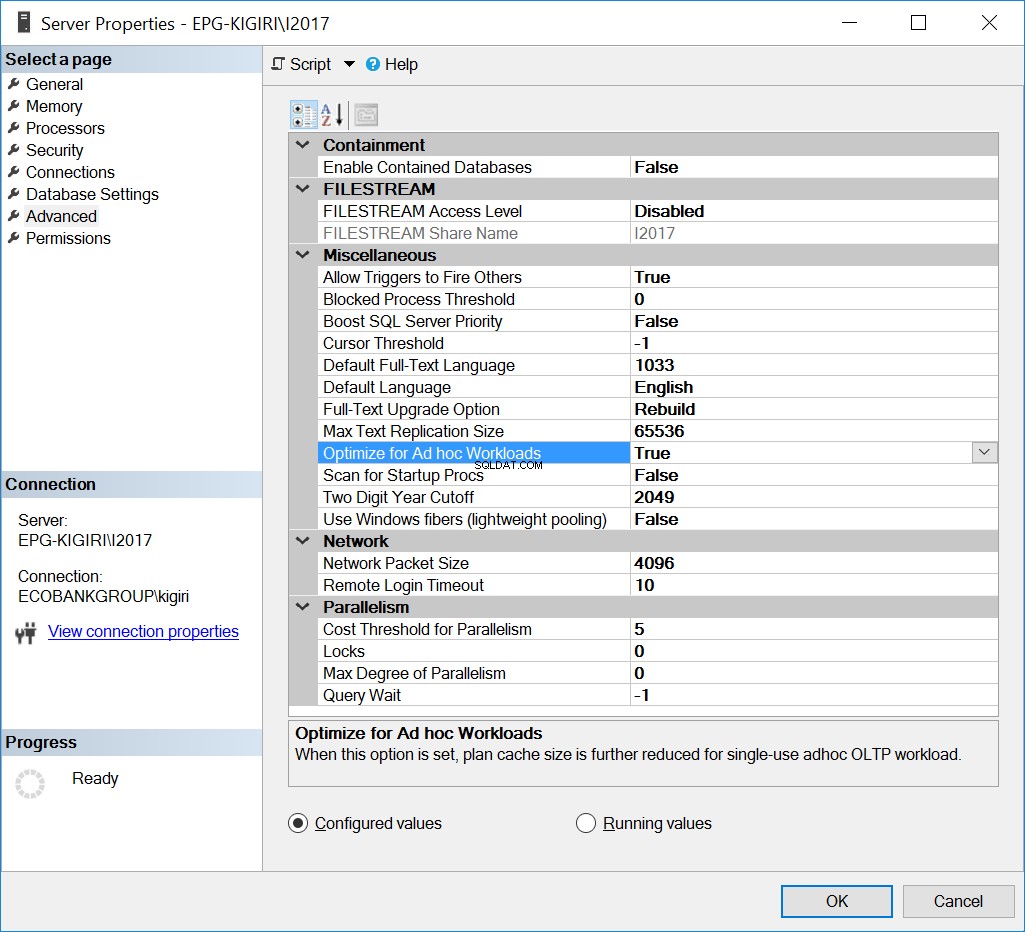
अंजीर। 1 तदर्थ कार्यभार के लिए अनुकूलित करें
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
अनिवार्य रूप से, यह विकल्प SQL सर्वर को संकलित योजना स्टब के रूप में ज्ञात योजना के आंशिक संस्करण को सहेजने के लिए कहता है। ठूंठ पूरी योजना की तुलना में बहुत कम जगह घेरता है।
इस पद्धति के विकल्प के रूप में, कुछ लोग इस मुद्दे पर बेरहमी से संपर्क करते हैं और समय-समय पर योजना कैश को फ्लश करते हैं। या, अधिक सावधानीपूर्वक तरीके से, DBCC FREESYSTEMCACHE का उपयोग करके "एकल-उपयोग योजनाओं" को फ्लश करें। जैसा कि आप पहले से ही जानते होंगे, पूरे प्लान कैश को फ्लश करने के अपने नुकसान हैं।
संग्रहीत कार्यविधियों और पैरामीटरों का उपयोग करना
संग्रहीत कार्यविधियों का उपयोग करके, एड हॉक एसक्यूएल के कारण होने वाली समस्या को वस्तुतः समाप्त किया जा सकता है। एक संग्रहीत कार्यविधि केवल एक बार संकलित की जाती है और उसी योजना को समान या समान SQL क्वेरी के बाद के निष्पादन के लिए पुन:उपयोग किया जाता है। जब व्यावसायिक तर्क को लागू करने के लिए संग्रहीत कार्यविधियों का उपयोग किया जाता है, तो SQL सर्वर द्वारा अंतिम रूप से निष्पादित की जाने वाली SQL क्वेरी में महत्वपूर्ण अंतर निष्पादन समय पर पारित मापदंडों में निहित है। चूंकि योजना पहले से ही मौजूद है और उपयोग के लिए तैयार है, SQL सर्वर उसी योजना का उपयोग करेगा चाहे कोई भी पैरामीटर पारित किया गया हो।
तिरछा डेटा
कुछ परिदृश्यों में, हम जिस डेटा से निपट रहे हैं वह समान रूप से वितरित नहीं है। हम इसे प्रदर्शित कर सकते हैं - सबसे पहले, हमें एक टेबल बनाने की आवश्यकता होगी:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); हमारी तालिका में विभिन्न देशों के क्लब सदस्यों का डेटा है। बड़ी संख्या में क्लब के सदस्य घाना से हैं, जबकि दो अन्य देशों में क्रमशः दस और दो सदस्य हैं। एजेंडा पर ध्यान केंद्रित रखने के लिए और सादगी के लिए, मैंने केवल तीन देशों का इस्तेमाल किया और एक ही देश से आने वाले सदस्यों के लिए एक ही नाम का इस्तेमाल किया। साथ ही, मैंने आईडी कॉलम में एक क्लस्टर इंडेक्स और कंट्रीकोड कॉलम में एक गैर-क्लस्टर इंडेक्स जोड़ा है ताकि विभिन्न मूल्यों के लिए अलग-अलग निष्पादन योजनाओं के प्रभाव को प्रदर्शित किया जा सके।
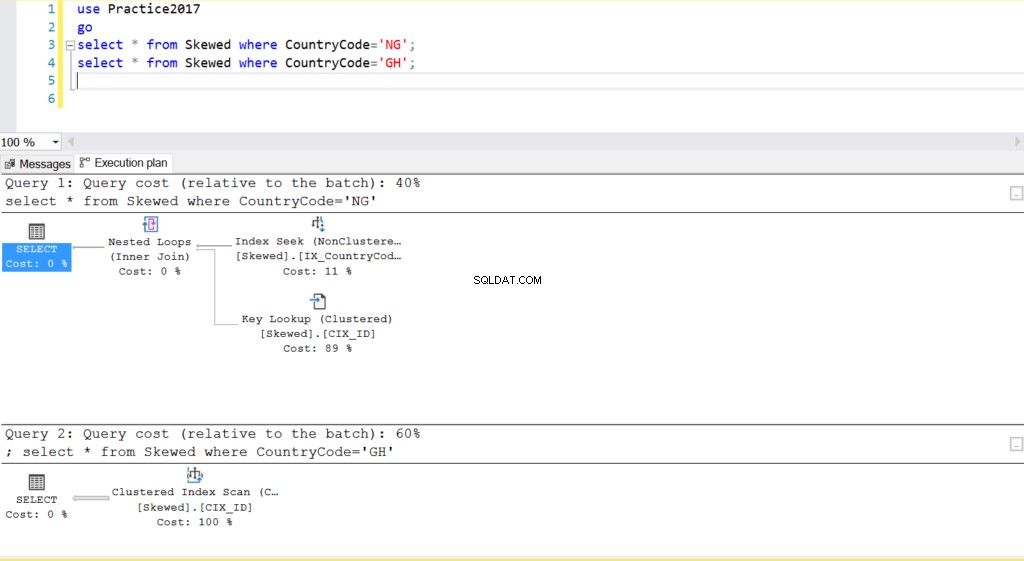
अंजीर। 2 दो प्रश्नों के लिए निष्पादन योजना
जब हम उन रिकॉर्ड्स के लिए तालिका को क्वेरी करते हैं जहां कंट्रीकोड NG और GH है, तो हम पाते हैं कि SQL सर्वर इन मामलों में दो अलग-अलग निष्पादन योजनाओं का उपयोग करता है। ऐसा इसलिए होता है क्योंकि कंट्रीकोड ='एनजी' के लिए पंक्तियों की अपेक्षित संख्या 10 है, जबकि कंट्रीकोड ='जीएच' के लिए 10000 है। SQL सर्वर तालिका के आंकड़ों के आधार पर बेहतर निष्पादन योजना निर्धारित करता है। यदि तालिका में पंक्तियों की कुल संख्या की तुलना में पंक्तियों की अपेक्षित संख्या अधिक है, तो SQL सर्वर निर्णय लेता है कि किसी अनुक्रमणिका को संदर्भित करने के बजाय केवल एक पूर्ण तालिका स्कैन करना बेहतर है। पंक्तियों की बहुत कम अनुमानित संख्या के साथ, अनुक्रमणिका उपयोगी हो जाती है।
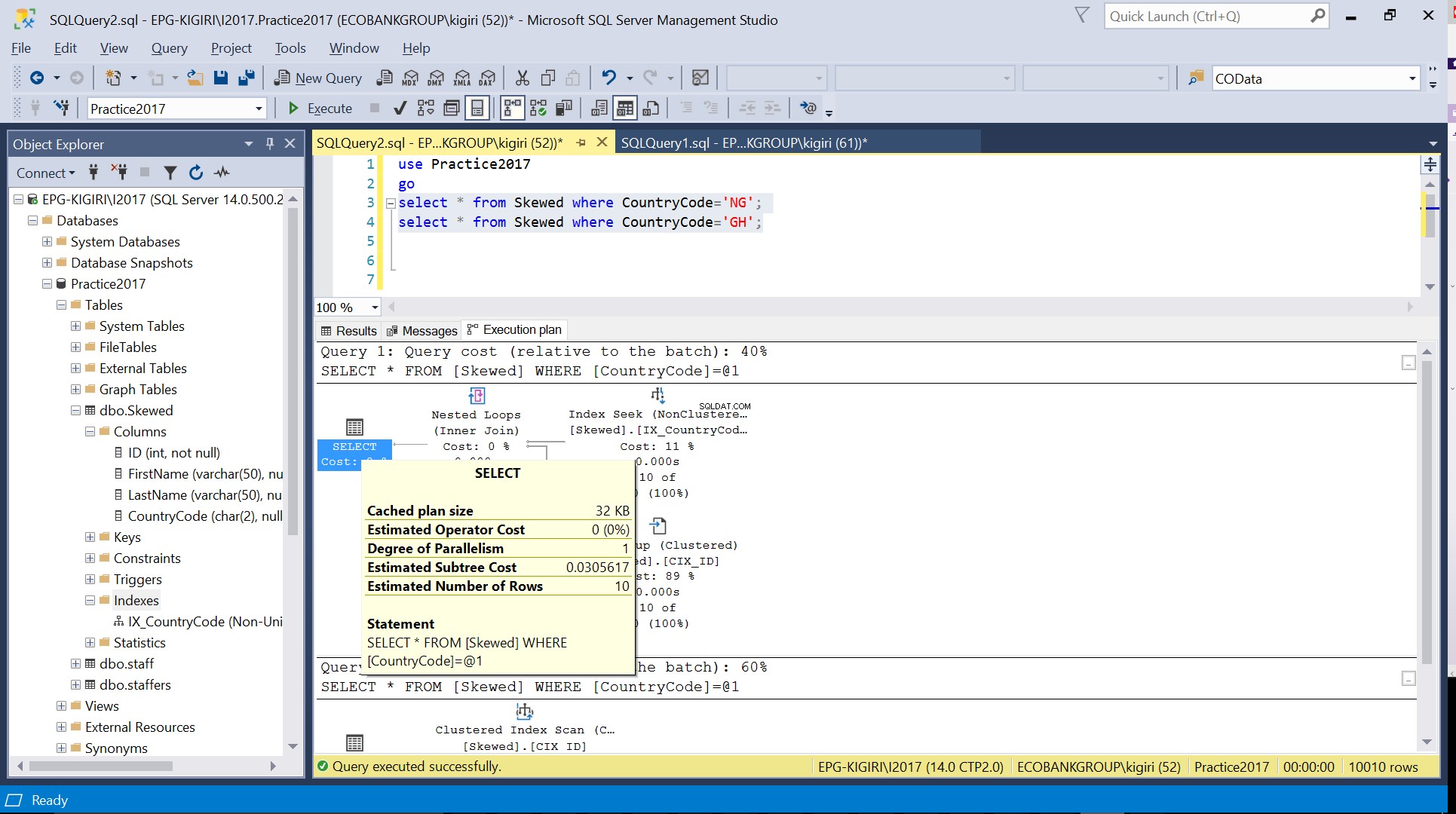
अंजीर। 3 CountryCode='NG' के लिए पंक्तियों की अनुमानित संख्या
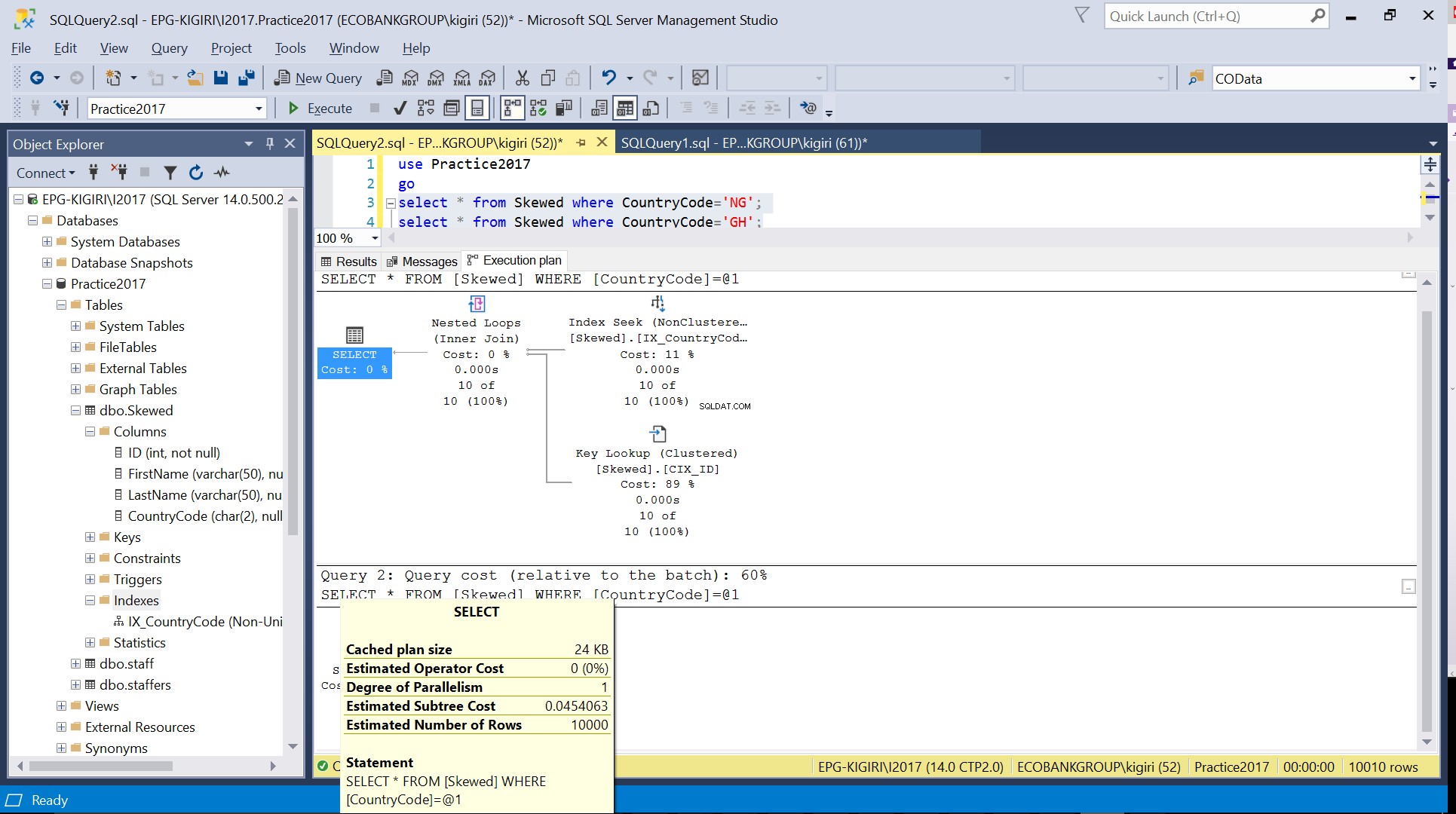
अंजीर। 4 CountryCode='GH'
. के लिए पंक्तियों की अनुमानित संख्यासंग्रहीत कार्यविधियां दर्ज करें
हम उसी क्वेरी का उपयोग करके अपने इच्छित रिकॉर्ड प्राप्त करने के लिए एक संग्रहीत कार्यविधि बना सकते हैं। इस बार फर्क सिर्फ इतना है कि हम कंट्रीकोड को एक पैरामीटर के रूप में पास करते हैं (लिस्टिंग 3 देखें)। ऐसा करते समय, हमें पता चलता है कि निष्पादन योजना वही है, चाहे हम किसी भी पैरामीटर से गुजरें। निष्पादन योजना जिसका उपयोग किया जाएगा, वह निष्पादन योजना द्वारा निर्धारित किया जाता है जो पहली बार संग्रहीत कार्यविधि लागू होने पर लौटाया जाता है। उदाहरण के लिए, यदि हम पहले कंट्रीकोड ='जीएच' के साथ प्रक्रिया चलाते हैं, तो यह उस बिंदु से एक पूर्ण टेबल स्कैन का उपयोग करेगा। अगर हम प्रक्रिया कैश को साफ़ करते हैं और पहले देश कोड ='एनजी' के साथ प्रक्रिया चलाते हैं, तो यह भविष्य में इंडेक्स-आधारित स्कैन का उपयोग करेगा।
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
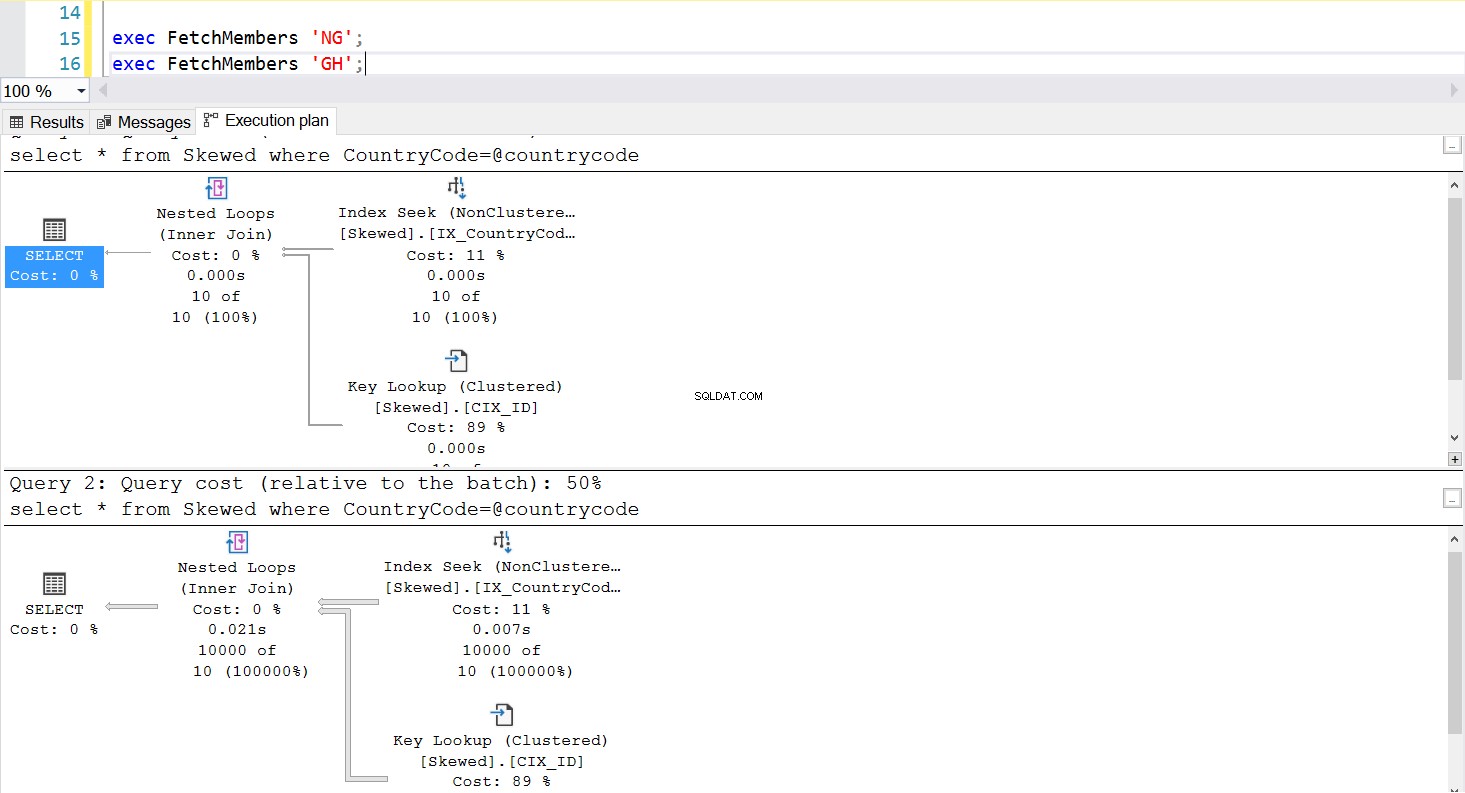
अंजीर। 5 जब 'एनजी' पहले इस्तेमाल किया जाता है तो इंडेक्स निष्पादन योजना चाहता है
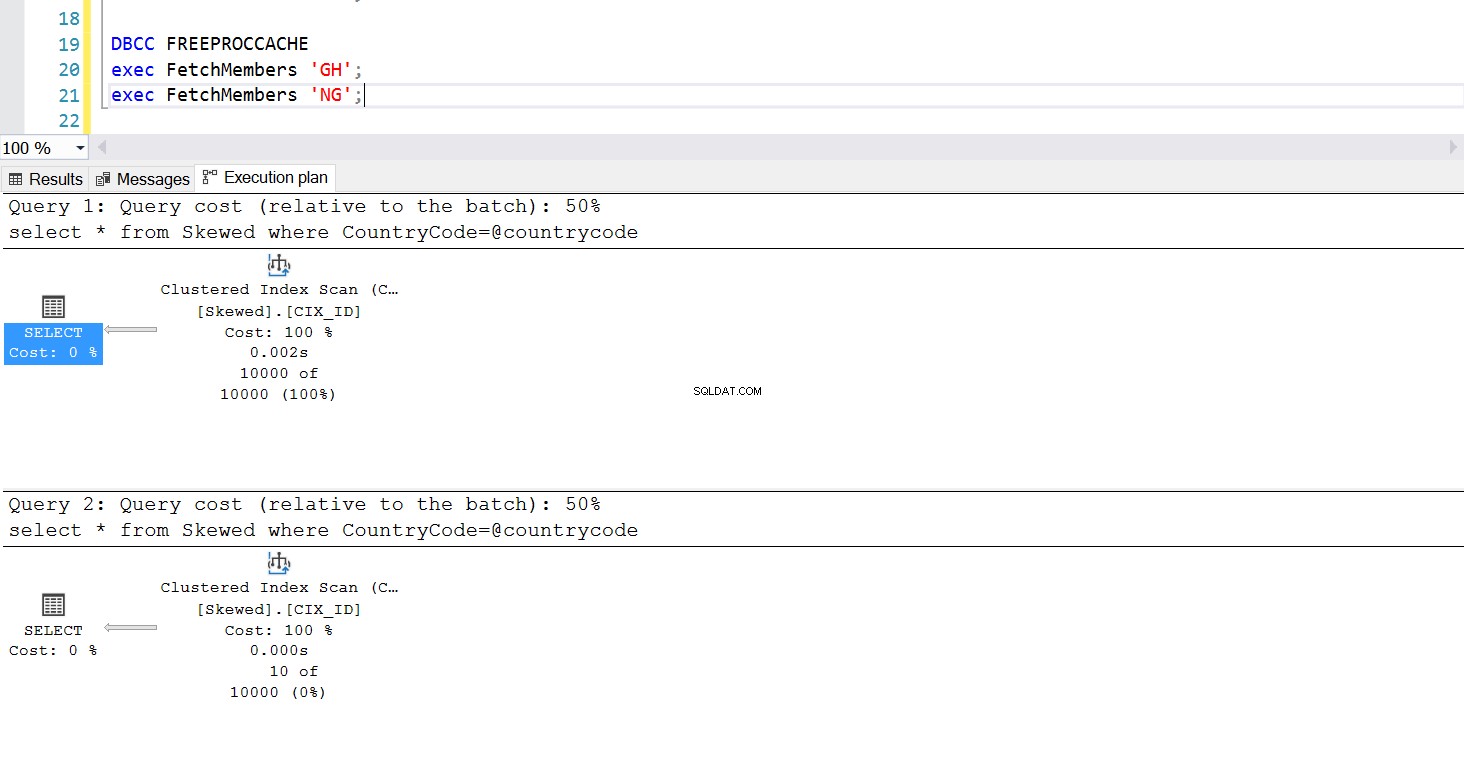
अंजीर। 6 क्लस्टर इंडेक्स स्कैन निष्पादन योजना जब पहले 'जीएच' का उपयोग किया जाता है
संग्रहीत कार्यविधि का निष्पादन डिजाइन के अनुसार व्यवहार कर रहा है - आवश्यक निष्पादन योजना का लगातार उपयोग किया जाता है। हालाँकि, यह एक समस्या हो सकती है क्योंकि डेटा विषम होने पर एक निष्पादन योजना सभी प्रश्नों के लिए उपयुक्त नहीं है। लगभग पूरी तालिका जितनी बड़ी पंक्तियों के संग्रह को पुनः प्राप्त करने के लिए एक अनुक्रमणिका का उपयोग करना कुशल नहीं है - न ही केवल कुछ पंक्तियों को पुनः प्राप्त करने के लिए पूर्ण स्कैन का उपयोग करना है। यह पैरामीटर सूँघने की समस्या है।
संभावित समाधान
पैरामीटर सूँघने की समस्या को प्रबंधित करने का एक सामान्य तरीका यह है कि जब भी संग्रहीत कार्यविधि निष्पादित की जाती है, तो जानबूझकर पुनर्संकलन का आह्वान किया जाता है। यह प्लान कैश को फ्लश करने से कहीं बेहतर है - सिवाय इसके कि आप इस विशिष्ट SQL क्वेरी के कैश को फ्लश करना चाहते हैं, जो पूरी तरह से संभव है। संग्रहीत कार्यविधि के अद्यतन संस्करण पर एक नज़र डालें। इस बार, यह समस्या के प्रबंधन के लिए OPTION (RECOMPILE) का उपयोग करता है। Fig.6 हमें दिखाता है कि, जब भी नई संग्रहीत प्रक्रिया निष्पादित की जाती है, तो यह उस पैरामीटर के लिए उपयुक्त योजना का उपयोग करती है जिसे हम पास कर रहे हैं।
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
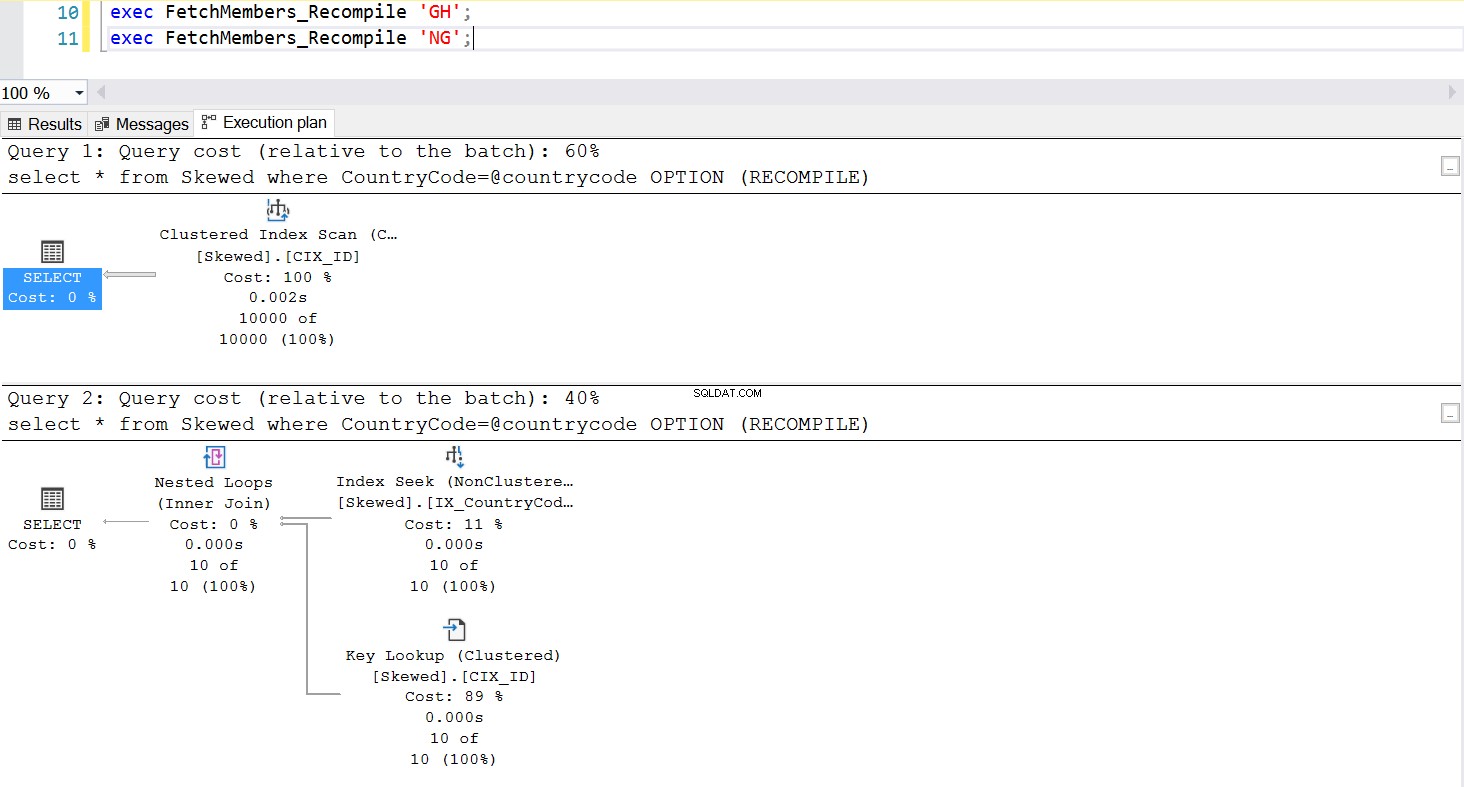
अंजीर। 7 विकल्प (RECOMPILE) के साथ संग्रहीत कार्यविधि का व्यवहार
निष्कर्ष
इस लेख में, हमने देखा है कि जब हम जिस डेटा के साथ काम कर रहे हैं वह विषम है, तो संग्रहीत प्रक्रियाओं के लिए लगातार निष्पादन योजना कैसे एक समस्या बन सकती है। हमने इसे व्यवहार में भी प्रदर्शित किया है और समस्या के एक सामान्य समाधान के बारे में सीखा है। मैं यह कहने की हिम्मत करता हूं कि यह ज्ञान उन डेवलपर्स के लिए अमूल्य है जो SQL सर्वर का उपयोग करते हैं। इस समस्या के कई अन्य समाधान हैं - ब्रेंट ओज़र ने इस विषय में गहराई से जाना और SQLDay पोलैंड 2017 में कुछ और गहन विवरण और समाधानों पर प्रकाश डाला। मैंने संदर्भ अनुभाग में संबंधित लिंक को सूचीबद्ध किया है।
संदर्भ
तदर्थ कार्यभार के लिए संचय और अनुकूलन की योजना बनाएं
पैरामीटर सूँघने की समस्याओं की पहचान करना और उन्हें ठीक करना