2013 में वापस, मैंने ऑप्टिमाइज़र में एक बग के बारे में लिखा था जहाँ दूसरा और तीसरा तर्क DATEDIFF() के लिए है अदला-बदली की जा सकती है - जिससे गलत पंक्ति गणना अनुमान हो सकते हैं और बदले में, खराब निष्पादन योजना चयन हो सकता है:
- प्रदर्शन आश्चर्य और अनुमान :DATEDIFF
पिछले सप्ताहांत में, मैंने इसी तरह की स्थिति के बारे में सीखा, और तत्काल धारणा बनाई कि यह वही समस्या थी। आखिरकार, लक्षण लगभग एक जैसे लग रहे थे:
WHERE. में एक दिनांक/समय फ़ंक्शन था खंड।- इस बार यह था
DATEADD()DATEDIFF(). के बजाय ।
- इस बार यह था
- 3 मिलियन से अधिक की वास्तविक पंक्ति गणना की तुलना में 1 का स्पष्ट रूप से गलत पंक्ति गणना अनुमान था।
- यह वास्तव में 0 का अनुमान था, लेकिन SQL सर्वर हमेशा ऐसे अनुमानों को 1 तक बढ़ा देता है।
- कम अनुमान के कारण एक खराब योजना चयन किया गया था (इस मामले में, एक लूप जॉइन चुना गया था)।
आपत्तिजनक पैटर्न इस तरह दिखता था:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
उपयोगकर्ता ने कई रूपों की कोशिश की, लेकिन कुछ भी नहीं बदला; वे अंततः विधेय को इसमें बदलकर समस्या को हल करने में कामयाब रहे:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
इसे एक बेहतर अनुमान मिला (सामान्य रूप से 30% असमानता का अनुमान); तो बिल्कुल सही नहीं है। और जब इसने लूप जॉइन को समाप्त कर दिया, तो इस विधेय के साथ दो प्रमुख समस्याएं हैं:
- यह नहीं है वही प्रश्न, क्योंकि अब यह 365 दिन की सीमाओं को पार करने की तलाश में है, क्योंकि यह 365 दिन पहले एक विशिष्ट बिंदु से अधिक होने के विपरीत है। आंकड़ों की दृष्टि से महत्वपूर्ण? शायद नहीं। लेकिन नीरस, तकनीकी रूप से, वही नहीं।
- कॉलम के सामने फ़ंक्शन को लागू करने से संपूर्ण एक्सप्रेशन गैर-सूक्ष्म हो जाता है - जिससे पूर्ण स्कैन हो जाता है। जब तालिका में केवल एक वर्ष से थोड़ा अधिक डेटा होता है, तो यह कोई बड़ी बात नहीं है, लेकिन जैसे-जैसे तालिका बड़ी होती जाती है, या विधेय संकुचित होता जाता है, यह एक समस्या बन जाएगी।
फिर से, मैं इस निष्कर्ष पर पहुंचा कि DATEADD() ऑपरेशन समस्या थी, और एक दृष्टिकोण की सिफारिश की जो DATEADD() . पर निर्भर नहीं था - एक datetime का निर्माण वर्तमान समय के सभी हिस्सों से, मुझे DATEADD() का उपयोग किए बिना एक वर्ष घटाने की अनुमति देता है :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); भारी होने के अलावा, इसकी अपनी कुछ समस्याएं थीं, अर्थात् लीप वर्षों के लिए तर्क का एक गुच्छा ठीक से जोड़ना होगा। पहला, ताकि यह विफल न हो यदि यह 29 फरवरी को चलता है, और दूसरा, सभी मामलों में ठीक 366 दिनों को शामिल करने के लिए (एक लीप दिवस के बाद वर्ष के दौरान 366 के बजाय)। निश्चित रूप से आसान सुधार, लेकिन वे तर्क को बहुत अधिक कुरूप बनाते हैं - विशेष रूप से क्योंकि क्वेरी को एक दृश्य के अंदर मौजूद होने की आवश्यकता होती है, जहां मध्यवर्ती चर और कई चरण संभव नहीं होते हैं।
इस बीच, ओपी ने 1-पंक्ति अनुमान से निराश होकर एक कनेक्ट आइटम दायर किया:
- कनेक्ट #2567628 :DateAdd() के साथ बाधा अच्छे अनुमान प्रदान नहीं कर रही है
फिर पॉल व्हाइट (@SQL_Kiwi) साथ आए और पहले की तरह कई बार समस्या पर कुछ अतिरिक्त प्रकाश डाला। उन्होंने 2011 में एरलैंड सोमरस्कोग द्वारा दायर एक संबंधित कनेक्ट आइटम साझा किया:
- कनेक्ट #685903 :गलत अनुमान जब sysdatetime dateadd() एक्सप्रेशन में दिखाई देता है
अनिवार्य रूप से, समस्या यह है कि एक खराब अनुमान केवल तब नहीं लगाया जा सकता जब SYSDATETIME() (या SYSUTCDATETIME() ) प्रकट होता है, जैसा कि एरलैंड ने मूल रूप से रिपोर्ट किया था, लेकिन जब कोई datetime2 अभिव्यक्ति विधेय में शामिल है (और शायद केवल जब DATEADD() का भी प्रयोग किया जाता है।) और यह दोनों तरह से हो सकता है - अगर हम >= swap को स्वैप करते हैं <= . के लिए , अनुमान पूरी तालिका बन जाता है, इसलिए ऐसा लगता है कि अनुकूलक SYSDATETIME() को देख रहा है मान एक स्थिरांक के रूप में, और DATEADD() . जैसे किसी भी संचालन को पूरी तरह से अनदेखा कर रहा है जो इसके खिलाफ किया जाता है।
पॉल ने साझा किया कि समाधान केवल datetime . का उपयोग करना है तिथि की गणना करते समय, इसे उचित डेटा प्रकार में परिवर्तित करने से पहले समतुल्य। इस मामले में, हम SYSUTCDATETIME() . को स्वैप कर सकते हैं और इसे GETUTCDATE() में बदलें :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
हां, इसके परिणामस्वरूप सटीकता का एक छोटा सा नुकसान होता है, लेकिन धूल का कण आपकी उंगली को <कीबोर्ड>F5 दबाने के रास्ते में धीमा कर सकता है। चाबी। महत्वपूर्ण बात यह है कि खोज का उपयोग अभी भी किया जा सकता है और अनुमान सही थे - लगभग सही, वास्तव में:

पठन समान हैं क्योंकि तालिका में पिछले वर्ष से लगभग अनन्य रूप से डेटा होता है, इसलिए यहां तक कि एक खोज भी अधिकांश तालिका का रेंज स्कैन बन जाती है। पंक्ति गणना समान नहीं हैं क्योंकि (ए) दूसरी क्वेरी मध्यरात्रि में कट जाती है और (बी) तीसरी क्वेरी में इस वर्ष की शुरुआत में लीप दिवस के कारण डेटा का एक अतिरिक्त दिन शामिल है। किसी भी मामले में, यह अभी भी दर्शाता है कि कैसे हम DATEADD() को हटाकर उचित अनुमानों के करीब पहुंच सकते हैं , लेकिन उचित समाधान प्रत्यक्ष संयोजन . को हटाना है का DATEADD() और datetime2 ।
आगे यह स्पष्ट करने के लिए कि अनुमान कैसे गलत हो रहे हैं, आप देख सकते हैं कि यदि हम मूल प्रश्न और पॉल के पुन:लिखने के लिए अलग-अलग तर्क और निर्देश देते हैं, तो पूर्व के लिए अनुमानित पंक्तियों की संख्या हमेशा वर्तमान समय पर आधारित होती है - वे नहीं करते हैं 'दिनों की संख्या के साथ परिवर्तन न करें (जबकि पॉल हर बार अपेक्षाकृत सटीक होता है):
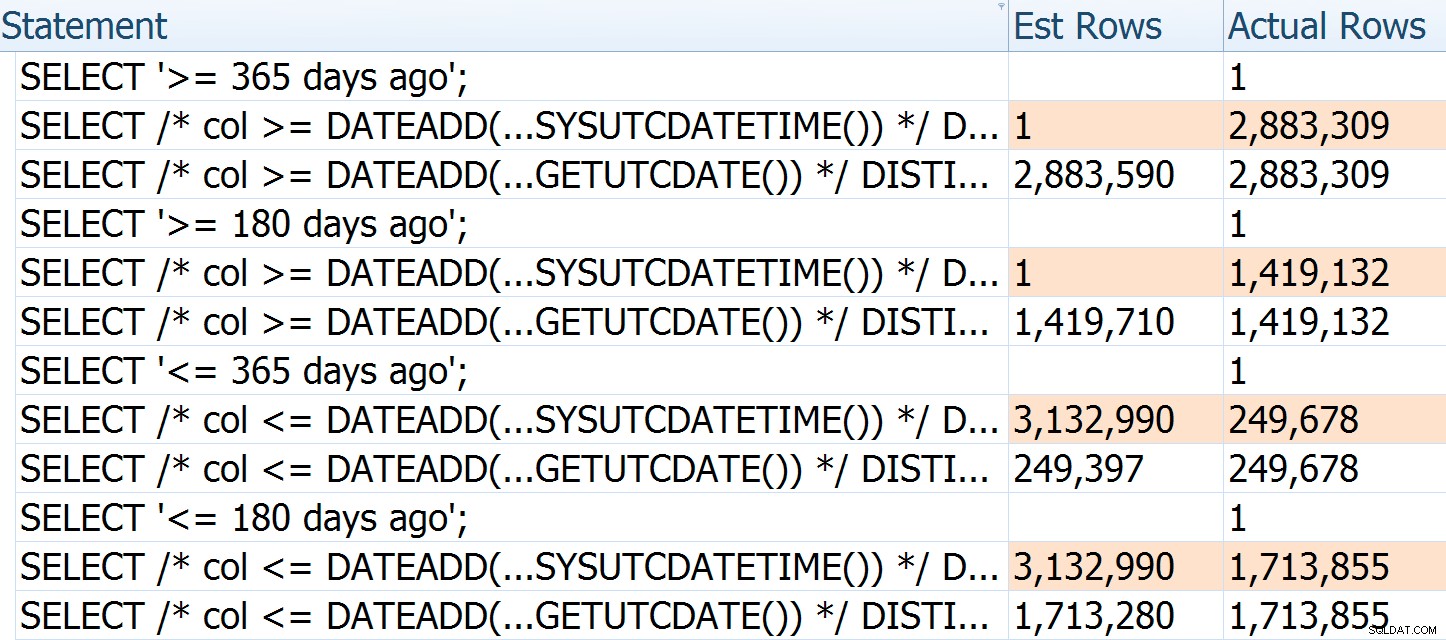 पहली क्वेरी के लिए वास्तविक पंक्तियां थोड़ी कम हैं क्योंकि इसे एक लंबी झपकी के बाद निष्पादित किया गया था
पहली क्वेरी के लिए वास्तविक पंक्तियां थोड़ी कम हैं क्योंकि इसे एक लंबी झपकी के बाद निष्पादित किया गया था
अनुमान हमेशा इतने अच्छे नहीं होंगे; मेरी तालिका में अपेक्षाकृत स्थिर वितरण है। यदि आप इसे स्वयं आज़माना चाहते हैं, तो मैंने इसे निम्नलिखित क्वेरी के साथ भर दिया और फिर फ़ुलस्कैन के साथ अपडेट किए गए आंकड़े:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; मैंने नए कनेक्ट आइटम पर टिप्पणी की, और संभवत:वापस जाकर मेरे स्टैक एक्सचेंज उत्तर को स्पर्श करूंगा।
कहानी की नैतिकता
DATEADD() के संयोजन से बचने का प्रयास करें उन भावों के साथ जो datetime2 yield उत्पन्न करते हैं , विशेष रूप से SQL सर्वर के पुराने संस्करणों पर (यह SQL सर्वर 2012 पर था)। पुराने कार्डिनैलिटी अनुमान मॉडल (कम संगतता स्तर के कारण, या ट्रेस फ्लैग 9481 के स्पष्ट उपयोग के कारण) का उपयोग करते समय SQL सर्वर 2016 पर भी यह एक समस्या हो सकती है। इस तरह की समस्याएं सूक्ष्म होती हैं और हमेशा तुरंत स्पष्ट नहीं होती हैं, इसलिए उम्मीद है कि यह एक अनुस्मारक के रूप में कार्य करता है (शायद अगली बार जब मैं इसी तरह के परिदृश्य में आऊं तो मेरे लिए भी)। जैसा कि मैंने पिछली पोस्ट में सुझाव दिया था, यदि आपके पास इस तरह के क्वेरी पैटर्न हैं, तो जांच लें कि आपको सही अनुमान मिल रहे हैं, और जब भी सिस्टम में कुछ भी बड़ा बदलाव (जैसे अपग्रेड या सर्विस पैक) होता है, तो उन्हें फिर से जांचने के लिए कहीं नोट करें।



