[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]
पिछले कुछ वर्षों में SELECT . को समझने और अनुकूलित करने के बारे में बहुत कुछ लिखा गया है प्रश्न, बल्कि डेटा संशोधन के बारे में कम। पोस्ट की यह श्रृंखला एक ऐसे मुद्दे को देखती है जो INSERT . के लिए विशिष्ट है , UPDATE , DELETE और MERGE प्रश्न - हैलोवीन समस्या।
वाक्यांश "हैलोवीन समस्या" मूल रूप से एक SQL UPDATE . के संदर्भ में गढ़ा गया था वह प्रश्न जो $25,000 से कम कमाने वाले प्रत्येक कर्मचारी को 10% वृद्धि देने वाला था। समस्या यह थी कि सभी . तक क्वेरी 10% वृद्धि देती रही कम से कम 25,000 डॉलर कमाए। हम इस श्रृंखला में बाद में देखेंगे कि अंतर्निहित मुद्दा INSERT . पर भी लागू होता है , DELETE और MERGE प्रश्न, लेकिन इस पहली प्रविष्टि के लिए, UPDATE . की जांच करना सहायक होगा थोड़ा विस्तार से समस्या।
पृष्ठभूमि
SQL भाषा उपयोगकर्ताओं को UPDATE . का उपयोग करके डेटाबेस परिवर्तन निर्दिष्ट करने का एक तरीका प्रदान करती है कथन, लेकिन वाक्य-विन्यास कैसे . के बारे में कुछ नहीं कहता है डेटाबेस इंजन को परिवर्तन करना चाहिए। दूसरी ओर, SQL मानक यह निर्दिष्ट करता है कि UPDATE . का परिणाम चाहिए ऐसा ही होना चाहिए जैसे कि इसे तीन अलग-अलग और गैर-अतिव्यापी चरणों में निष्पादित किया गया हो:
- केवल-पढ़ने के लिए खोज, बदले जाने वाले रिकॉर्ड और नए कॉलम के मान निर्धारित करती है
- प्रभावित रिकॉर्ड पर परिवर्तन लागू होते हैं
- डेटाबेस संगतता बाधाओं को सत्यापित किया गया है
डेटाबेस इंजन में इन तीन चरणों को शाब्दिक रूप से लागू करने से सही परिणाम प्राप्त होंगे, लेकिन प्रदर्शन बहुत अच्छा नहीं हो सकता है। प्रत्येक चरण में मध्यवर्ती परिणामों के लिए सिस्टम मेमोरी की आवश्यकता होगी, जिससे सिस्टम द्वारा समवर्ती रूप से निष्पादित प्रश्नों की संख्या कम हो जाएगी। आवश्यक स्मृति उस से भी अधिक हो सकती है जो उपलब्ध है, जिसके लिए अद्यतन सेट के कम से कम भाग को डिस्क संग्रहण में लिखने और बाद में फिर से पढ़ने की आवश्यकता होती है। अंतिम लेकिन कम से कम, इस निष्पादन मॉडल के तहत तालिका की प्रत्येक पंक्ति को कई बार स्पर्श करने की आवश्यकता है।
एक वैकल्पिक रणनीति UPDATE को संसाधित करना है एक समय में एक पंक्ति। यह केवल प्रत्येक पंक्ति को एक बार छूने का लाभ है, और आम तौर पर भंडारण के लिए स्मृति की आवश्यकता नहीं होती है (हालांकि कुछ संचालन, जैसे पूर्ण प्रकार, आउटपुट की पहली पंक्ति बनाने से पहले पूर्ण इनपुट सेट को संसाधित करना चाहिए)। यह पुनरावृत्त मॉडल SQL सर्वर क्वेरी निष्पादन इंजन द्वारा उपयोग किया जाने वाला मॉडल है।
क्वेरी ऑप्टिमाइज़र के लिए चुनौती एक पुनरावृत्त (पंक्ति दर पंक्ति) निष्पादन योजना खोजना है जो UPDATE को संतुष्ट करती है पाइपलाइन निष्पादन के प्रदर्शन और समवर्ती लाभों को बनाए रखते हुए, SQL मानक द्वारा आवश्यक शब्दार्थ।
अपडेट प्रोसेसिंग
मूल मुद्दे को स्पष्ट करने के लिए, हम Employees का उपयोग करके $25,000 से कम आय वाले प्रत्येक कर्मचारी पर 10% की वृद्धि लागू करेंगे। नीचे दी गई तालिका:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; तीन चरणों में अपडेट करने की रणनीति
केवल-पढ़ने के लिए पहला चरण WHERE . के अनुरूप सभी रिकॉर्ड ढूंढता है खंड भविष्यवाणी करता है, और दूसरे चरण के लिए अपना काम करने के लिए पर्याप्त जानकारी बचाता है। व्यवहार में, इसका अर्थ है प्रत्येक क्वालीफाइंग पंक्ति (क्लस्टर इंडेक्स कीज़ या हीप रो आइडेंटिफ़ायर) और नए वेतन मूल्य के लिए एक विशिष्ट पहचानकर्ता को रिकॉर्ड करना। एक बार चरण एक पूरा हो जाने पर, अद्यतन जानकारी का पूरा सेट दूसरे चरण में भेज दिया जाता है, जो अद्वितीय पहचानकर्ता का उपयोग करके अद्यतन किए जाने वाले प्रत्येक रिकॉर्ड का पता लगाता है, और वेतन को नए मान में बदल देता है। तीसरा चरण तब जाँचता है कि तालिका की अंतिम स्थिति से कोई डेटाबेस अखंडता बाधाओं का उल्लंघन नहीं हुआ है।
पुनरावर्ती रणनीति
यह दृष्टिकोण स्रोत तालिका से एक समय में एक पंक्ति पढ़ता है। यदि पंक्ति WHERE . को संतुष्ट करती है खंड विधेय, वेतन वृद्धि लागू होती है। यह प्रक्रिया तब तक दोहराई जाती है जब तक कि सभी पंक्तियों को स्रोत से संसाधित नहीं कर दिया जाता। इस मॉडल का उपयोग करते हुए एक नमूना निष्पादन योजना नीचे दिखाई गई है:

SQL सर्वर की मांग-संचालित पाइपलाइन के लिए हमेशा की तरह, निष्पादन सबसे बाईं ओर के ऑपरेटर से शुरू होता है - UPDATE इस मामले में। यह टेबल अपडेट से एक पंक्ति का अनुरोध करता है, जो कंप्यूट स्केलर से एक पंक्ति मांगता है, और श्रृंखला को टेबल स्कैन के लिए नीचे मांगता है:
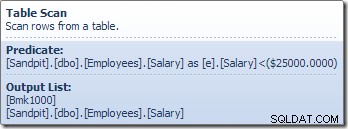
टेबल स्कैन ऑपरेटर स्टोरेज इंजन से एक-एक करके पंक्तियों को तब तक पढ़ता है, जब तक कि उसे कोई ऐसा न मिल जाए जो वेतन विधेय को संतुष्ट करता हो। उपरोक्त ग्राफ़िक में आउटपुट सूची तालिका स्कैन ऑपरेटर को एक पंक्ति पहचानकर्ता और इस पंक्ति के लिए वेतन कॉलम का वर्तमान मान लौटाती है। सूचना के इन दो टुकड़ों के संदर्भ वाली एक पंक्ति को कंप्यूट स्केलर तक भेजा जाता है:
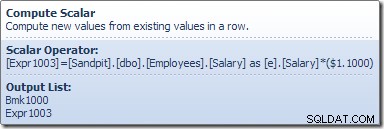
कंप्यूट स्केलर एक अभिव्यक्ति को परिभाषित करता है जो वेतन वृद्धि को वर्तमान पंक्ति पर लागू करता है। यह एक पंक्ति देता है जिसमें पंक्ति पहचानकर्ता के संदर्भ और तालिका अद्यतन में संशोधित वेतन होता है, जो डेटा संशोधन करने के लिए स्टोरेज इंजन को आमंत्रित करता है। यह पुनरावृति प्रक्रिया तब तक जारी रहती है जब तक कि टेबल स्कैन पंक्तियों से बाहर नहीं हो जाता। यदि तालिका में एक संकुल अनुक्रमणिका है तो उसी मूल प्रक्रिया का पालन किया जाता है:
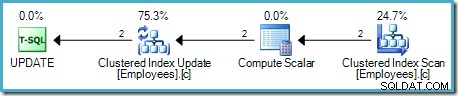
मुख्य अंतर यह है कि संकुल अनुक्रमणिका कुंजी (कुंजी) और uniquifier (यदि मौजूद है) का उपयोग ढेर RID के बजाय पंक्ति पहचानकर्ता के रूप में किया जाता है।
समस्या
SQL मानक में परिभाषित तार्किक तीन-चरण संचालन से भौतिक पुनरावृत्ति निष्पादन मॉडल में परिवर्तन ने कई सूक्ष्म परिवर्तन पेश किए हैं, जिनमें से केवल एक को हम आज देखने जा रहे हैं। हमारे चल रहे उदाहरण में एक समस्या हो सकती है यदि वेतन कॉलम पर एक गैर-संकुल सूचकांक है, जिसे क्वेरी ऑप्टिमाइज़र योग्य पंक्तियों को खोजने के लिए उपयोग करने का निर्णय लेता है (वेतन <$ 25,000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
पंक्ति-दर-पंक्ति निष्पादन मॉडल अब गलत परिणाम दे सकता है, या अनंत लूप में भी प्रवेश कर सकता है। एक (काल्पनिक) पुनरावृत्ति निष्पादन योजना पर विचार करें जो वेतन सूचकांक की तलाश करती है, एक समय में एक पंक्ति को कंप्यूट स्केलर पर लौटाती है, और अंततः अपडेट ऑपरेटर को:

इस योजना में कुछ अतिरिक्त कंप्यूट स्केलर हैं, जो एक अनुकूलन के कारण गैर-संकुल सूचकांक रखरखाव को छोड़ देता है यदि वेतन मूल्य नहीं बदला है (इस मामले में केवल शून्य वेतन के लिए संभव है)।
इसे नज़रअंदाज़ करते हुए, इस योजना की महत्वपूर्ण विशेषता यह है कि अब हमारे पास एक आदेशित आंशिक अनुक्रमणिका स्कैन है जो एक ऑपरेटर को एक बार में एक पंक्ति पास करता है जो समान अनुक्रमणिका को संशोधित करता है (उपरोक्त SQL संतरी योजना एक्सप्लोरर ग्राफ़िक में हरा हाइलाइट क्लस्टर को स्पष्ट करता है इंडेक्स अपडेट ऑपरेटर बेस टेबल और गैर-क्लस्टर इंडेक्स दोनों को बनाए रखता है।
वैसे भी, समस्या यह है कि एक समय में एक पंक्ति को संसाधित करके, अद्यतन वर्तमान पंक्ति को स्कैन स्थिति से आगे ले जा सकता है जिसका उपयोग इंडेक्स सीक द्वारा बदलने के लिए पंक्तियों का पता लगाने के लिए किया जाता है। उदाहरण के माध्यम से कार्य करना उस कथन को थोड़ा स्पष्ट करना चाहिए:
गैर-संकुलित सूचकांक को वेतन मूल्य पर कुंजीबद्ध और आरोही क्रमित किया जाता है। इंडेक्स में बेस टेबल में पैरेंट रो के लिए एक पॉइंटर भी होता है (या तो एक हीप आरआईडी या क्लस्टर्ड इंडेक्स कुंजियाँ और यदि आवश्यक हो तो यूनीक्विफ़ायर)। उदाहरण का अनुसरण करना आसान बनाने के लिए, मान लें कि आधार तालिका में अब नाम स्तंभ पर एक अद्वितीय संकुल अनुक्रमणिका है, इसलिए अद्यतन प्रसंस्करण की शुरुआत में गैर-संकुल अनुक्रमणिका सामग्री हैं:
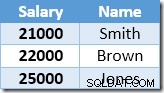
इंडेक्स सीक द्वारा लौटाई गई पहली पंक्ति स्मिथ के लिए $ 21,000 का वेतन है। यह मान आधार तालिका में $23,100 और क्लस्टर इंडेक्स ऑपरेटर द्वारा गैर-संकुल अनुक्रमणिका में अद्यतन किया जाता है। गैर-संकुल अनुक्रमणिका में अब शामिल हैं:
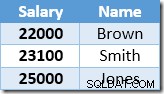
इंडेक्स सीक द्वारा लौटाई गई अगली पंक्ति ब्राउन के लिए $22,000 प्रविष्टि होगी जिसे $24,200 में अपडेट किया गया है:
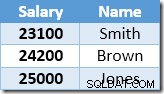
अब इंडेक्स सीक स्मिथ के लिए $23,100 का मूल्य ढूंढता है, जिसे फिर से अपडेट किया जाता है , $25,410 करने के लिए। यह प्रक्रिया तब तक जारी रहती है जब तक कि सभी कर्मचारियों का वेतन कम से कम $25,000 न हो - जो कि दिए गए UPDATE के लिए सही परिणाम नहीं है। सवाल। अन्य परिस्थितियों में एक ही प्रभाव एक भगोड़ा अद्यतन का कारण बन सकता है जो केवल तभी समाप्त होता है जब सर्वर लॉग स्थान से बाहर हो जाता है या एक अतिप्रवाह त्रुटि होती है (यह इस मामले में हो सकता है यदि किसी के पास शून्य वेतन था)। यह हैलोवीन समस्या है क्योंकि यह अपडेट पर लागू होती है।
अपडेट के लिए हैलोवीन समस्या से बचना
ईगल-आइड पाठकों ने देखा होगा कि काल्पनिक इंडेक्स सीक प्लान में अनुमानित लागत प्रतिशत 100% तक नहीं जोड़ा गया था। प्लान एक्सप्लोरर के साथ यह कोई समस्या नहीं है - मैंने जानबूझकर एक प्रमुख ऑपरेटर को योजना से हटा दिया है:

क्वेरी ऑप्टिमाइज़र यह मानता है कि यह पाइपलाइन अद्यतन योजना हैलोवीन समस्या के लिए असुरक्षित है, और इसे होने से रोकने के लिए एक उत्सुक टेबल स्पूल पेश करता है। इस निष्पादन योजना में स्पूल को शामिल करने से रोकने के लिए कोई संकेत या ट्रेस फ़्लैग नहीं है क्योंकि यह शुद्धता के लिए आवश्यक है।
जैसा कि इसके नाम से पता चलता है, स्पूल अपने मूल कंप्यूट स्केलर को एक पंक्ति वापस करने से पहले अपने चाइल्ड ऑपरेटर (इंडेक्स सीक) से सभी पंक्तियों का उत्सुकता से उपभोग करता है। इसका प्रभाव पूर्ण चरण पृथक्करण . का परिचय देना है - किसी भी अपडेट के प्रदर्शन से पहले सभी योग्य पंक्तियों को पढ़ा जाता है और अस्थायी भंडारण में सहेजा जाता है।
यह हमें SQL मानक के तीन-चरण तार्किक अर्थ के करीब लाता है, हालांकि कृपया ध्यान दें कि योजना निष्पादन अभी भी मौलिक रूप से पुनरावृत्त है, ऑपरेटरों के साथ स्पूल के दाईं ओर कर्सर पढ़ें बनाते हैं , और बाईं ओर के ऑपरेटर राइट कर्सर . बनाते हैं . स्पूल की सामग्री अभी भी पंक्ति दर पंक्ति पढ़ी और संसाधित की जाती है (इसे एन मस्से पास नहीं किया जाता है क्योंकि SQL मानक के साथ तुलना अन्यथा आपको विश्वास करने के लिए प्रेरित कर सकती है)।
चरण पृथक्करण की कमियां वही हैं जो पहले बताई गई हैं। टेबल स्पूल खपत करता है tempdb अंतरिक्ष (बफर पूल में पृष्ठ) और स्मृति दबाव में डिस्क पर भौतिक पढ़ने और लिखने की आवश्यकता हो सकती है। क्वेरी ऑप्टिमाइज़र स्पूल को एक अनुमानित लागत प्रदान करता है (अनुमानों के बारे में सभी सामान्य चेतावनियों के अधीन) और उन योजनाओं के बीच चयन करेगा जिनके लिए हैलोवीन समस्या के खिलाफ सुरक्षा की आवश्यकता होती है, जो सामान्य रूप से अनुमानित लागत के आधार पर नहीं होती हैं। स्वाभाविक रूप से, अनुकूलक किसी भी सामान्य कारणों से विकल्पों में से गलत तरीके से चयन कर सकता है।
इस मामले में, हैलोवीन समस्या से बचने के लिए आवश्यक स्पूल की अनुमानित लागत के मुकाबले सीधे योग्यता रिकॉर्ड (वेतन के साथ <$ 25,000) की मांग करके दक्षता वृद्धि के बीच व्यापार बंद है। एक वैकल्पिक योजना (इस विशिष्ट मामले में) संकुल सूचकांक (या ढेर) का एक पूर्ण स्कैन है। इस रणनीति के लिए समान हेलोवीन सुरक्षा की आवश्यकता नहीं है क्योंकि कुंजी संकुल अनुक्रमणिका को संशोधित नहीं किया गया है:

क्योंकि सूचकांक कुंजियाँ स्थिर हैं, पंक्तियाँ पुनरावृत्तियों के बीच सूचकांक में स्थिति को स्थानांतरित नहीं कर सकती हैं, वर्तमान मामले में हैलोवीन समस्या से बचते हुए। पहले देखे गए इंडेक्स सीक प्लस ईगर टेबल स्पूल संयोजन की तुलना में क्लस्टर्ड इंडेक्स स्कैन की रनटाइम लागत के आधार पर, एक योजना दूसरे की तुलना में तेजी से निष्पादित हो सकती है। एक और विचार यह है कि हैलोवीन प्रोटेक्शन वाली योजना पूरी तरह से पाइपलाइन की गई योजना की तुलना में अधिक ताले प्राप्त करेगी, और ताले लंबे समय तक रहेंगे।
अंतिम विचार
हैलोवीन समस्या और डेटा संशोधन क्वेरी योजनाओं पर इसके प्रभावों को समझने से आपको डेटा-परिवर्तन निष्पादन योजनाओं का विश्लेषण करने में मदद मिलेगी, और जहां एक विकल्प उपलब्ध है, अनावश्यक सुरक्षा की लागत और दुष्प्रभावों से बचने के अवसर प्रदान कर सकते हैं।
हैलोवीन समस्या के कई रूप हैं, जिनमें से सभी एक सामान्य सूचकांक की कुंजियों को पढ़ने और लिखने के कारण नहीं होते हैं। हैलोवीन समस्या भी UPDATE तक सीमित नहीं है प्रश्न। हैलोवीन समस्या से बचने के लिए उत्सुक टेबल स्पूल का उपयोग करके ब्रूट-फोर्स फेज सेपरेशन के अलावा क्वेरी ऑप्टिमाइज़र के पास अपनी आस्तीन में अधिक तरकीबें हैं। इस श्रृंखला की अगली किश्तों में इन बिंदुओं (और अधिक) की खोज की जाएगी।
[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]



