समूहीकरण एक महत्वपूर्ण विशेषता है जो डेटा को व्यवस्थित और व्यवस्थित करने में मदद करती है। इसे करने के कई तरीके हैं, और सबसे प्रभावी तरीकों में से एक है SQL GROUP BY क्लॉज।
परिणामों में पंक्तियों को एग्रीगेट फ़ंक्शन वाले समूहों में विभाजित करने के लिए आप SQL GROUP BY का उपयोग कर सकते हैं . इसके साथ रिकॉर्ड को जोड़ना, औसत करना या गिनना आसान लगता है।
लेकिन क्या आप इसे सही कर रहे हैं?
"राइट" व्यक्तिपरक हो सकता है। जब यह सही आउटपुट के साथ महत्वपूर्ण त्रुटियों के बिना चलता है, तो इसे ठीक माना जाता है। हालांकि, इसे भी जल्दी करने की जरूरत है।
इस लेख में गति पर भी विचार किया जाएगा। आप सभी बिंदुओं पर तार्किक पठन और निष्पादन योजनाओं का उपयोग करते हुए बहुत अधिक क्वेरी विश्लेषण देखेंगे।
आइए शुरू करते हैं।
1. जल्दी फ़िल्टर करें
यदि आप इस उलझन में हैं कि WHERE और HAVING का उपयोग कब करें, तो यह आपके लिए है। क्योंकि आपके द्वारा प्रदान की जाने वाली शर्त के आधार पर, दोनों एक ही परिणाम दे सकते हैं।
लेकिन वे अलग हैं।
SQL ग्रुप बाय क्लॉज में कॉलम का उपयोग करके समूहों को फ़िल्टर करना। जहां समूहीकरण और एकत्रीकरण होने से पहले पंक्तियों को फ़िल्टर किया जाता है। इसलिए, यदि आप HAVING क्लॉज का उपयोग करके फ़िल्टर करते हैं, तो सभी . के लिए समूहीकरण होता है पंक्तियाँ वापस आ गईं।
और यह बुरा है।
क्यों? संक्षिप्त उत्तर है:यह धीमा है। आइए इसे 2 प्रश्नों के साथ साबित करें। नीचे दिए गए कोड की जाँच करें। SQL सर्वर प्रबंधन स्टूडियो में इसे चलाने से पहले, पहले Ctrl-M दबाएं।
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
विश्लेषण
ऊपर दिए गए 2 सेलेक्ट स्टेटमेंट समान पंक्तियों को वापस कर देंगे। वर्ष 2012 में महीने के हिसाब से उत्पाद ऑर्डर वापस करने में दोनों सही हैं। लेकिन पहले SELECT में 136ms लगे। मेरे लैपटॉप पर चलने के लिए, जबकि दूसरे ने 764ms लिया।!
क्यों?
आइए पहले चित्र 1 में तार्किक पठन की जाँच करें। सांख्यिकी IO ने इन परिणामों को वापस कर दिया। फिर, मैंने स्वरूपित आउटपुट के लिए इसेStatisticsParser.com में चिपकाया।
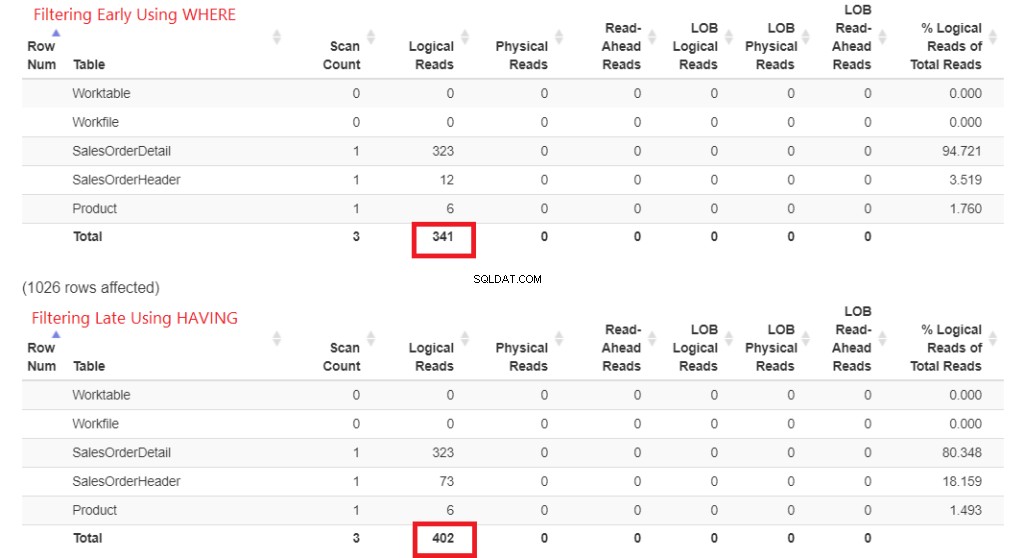
चित्र 1 . WHERE का उपयोग करके जल्दी फ़िल्टर करने के तार्किक पठन बनाम HAVING का उपयोग करके देर से फ़िल्टर करना।
प्रत्येक के कुल तार्किक पठन को देखें। इन नंबरों को समझने के लिए, इसे जितना अधिक तार्किक रूप से पढ़ा जाएगा, क्वेरी उतनी ही धीमी होगी। इसलिए, यह साबित करता है कि HAVING का उपयोग करना धीमा है, और WHERE के साथ जल्दी फ़िल्टर करना तेज़ है।
बेशक, इसका मतलब यह नहीं है कि होना बेकार है। एक अपवाद तब होता है जब HAVING का उपयोग HAVING SUM(sod.Linetotal)> 100000 जैसे समुच्चय के साथ किया जाता है . आप एक क्वेरी में WHERE क्लॉज़ और HAVING क्लॉज़ को जोड़ सकते हैं।
चित्र 2 में निष्पादन योजना देखें।
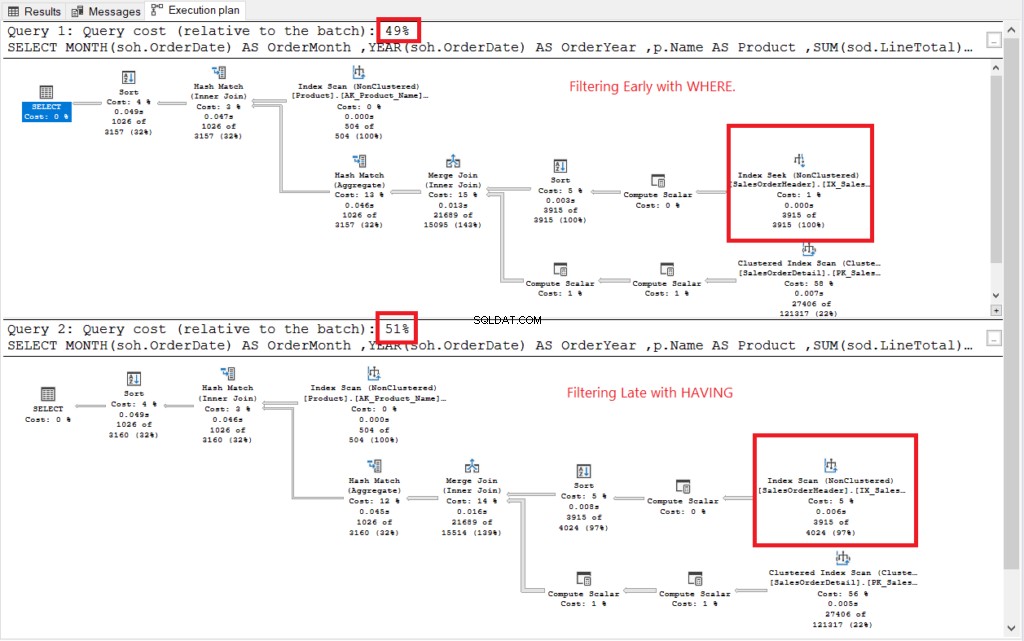
चित्र 2 . जल्दी फ़िल्टर करने बनाम देर से फ़िल्टर करने की निष्पादन योजनाएँ।
लाल रंग में बॉक्स किए गए लोगों को छोड़कर दोनों निष्पादन योजनाएं समान दिखती थीं। फ़िल्टरिंग ने पहले इंडेक्स सीक ऑपरेटर का इस्तेमाल किया जबकि दूसरे ने इंडेक्स स्कैन का इस्तेमाल किया। खोज बड़ी तालिकाओं में स्कैन की तुलना में तेज़ हैं।
नहीं ते: देर से छानने की तुलना में जल्दी छानने की लागत कम होती है। इसलिए, निचली पंक्ति पंक्तियों को जल्दी फ़िल्टर कर रही है जिससे प्रदर्शन में सुधार हो सकता है।
2. समूह पहले, बाद में जुड़ें
आपको बाद में आवश्यक कुछ तालिकाओं में शामिल होने से भी प्रदर्शन में सुधार हो सकता है।
मान लीजिए कि आप मासिक उत्पाद बिक्री करना चाहते हैं। आपको एक ही क्वेरी में उत्पाद का नाम, संख्या और उपश्रेणी प्राप्त करने की भी आवश्यकता है। ये कॉलम दूसरी टेबल में हैं। और सफल निष्पादन के लिए उन सभी को ग्रुप बाय क्लॉज में जोड़ा जाना चाहिए। यह रहा कोड।
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
यह ठीक चलेगा। लेकिन एक बेहतर, तेज़ तरीका है। इसके लिए आपको ग्रुप बाय क्लॉज में उत्पाद के नाम, संख्या और उपश्रेणी के लिए 3 कॉलम जोड़ने की आवश्यकता नहीं होगी। हालांकि, इसके लिए कुछ अधिक कीस्ट्रोक्स की आवश्यकता होगी। यह रहा।
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
विश्लेषण
यह तेज़ क्यों है? उत्पाद . से जुड़ता है और उत्पाद उपश्रेणी बाद में किया जाता है। दोनों ग्रुप बाय क्लॉज में शामिल नहीं हैं। आइए इसे STATISTICS IO में संख्याओं द्वारा सिद्ध करें। चित्र 4 देखें।
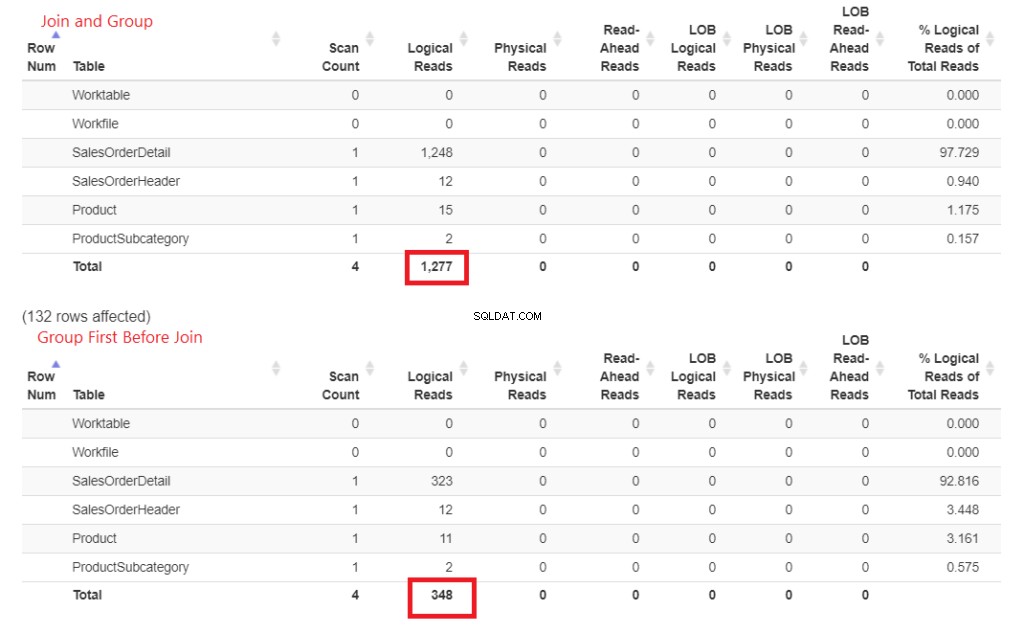
चित्र 3 . जल्दी शामिल होने के बाद समूह में शामिल होने से बाद में जुड़ने की तुलना में अधिक तार्किक पढ़ने की खपत होती है।
उन लॉजिकल रीड्स को देखें? अंतर बहुत दूर है, और विजेता स्पष्ट है।
आइए उपरोक्त संख्याओं के पीछे के कारण को देखने के लिए 2 प्रश्नों की निष्पादन योजना की तुलना करें। सबसे पहले, क्वेरी के निष्पादन योजना के लिए चित्र 4 देखें, जिसमें समूहबद्ध होने पर सभी तालिकाओं को शामिल किया गया हो।
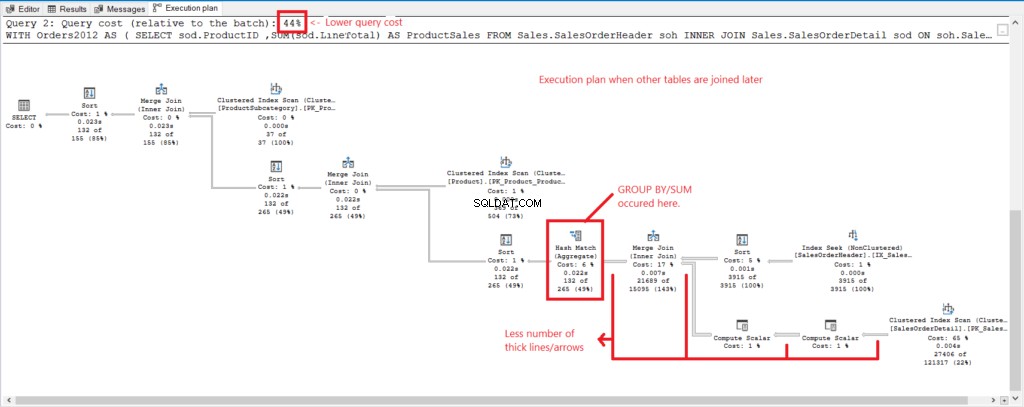
चित्र 4 . निष्पादन योजना जब सभी तालिकाएं जुड़ जाती हैं।
और हमारे पास निम्नलिखित अवलोकन हैं:
- GROUP BY और SUM सभी तालिकाओं में शामिल होने के बाद प्रक्रिया में देर से किए गए।
- काफी मोटी रेखाएं और तीर - यह 1,277 तार्किक पठन की व्याख्या करता है।
- दो प्रश्न संयुक्त रूप से क्वेरी लागत का 100% बनाते हैं। लेकिन इस क्वेरी की योजना की क्वेरी लागत (56%) अधिक है।
अब, जब हम पहले समूह बनाते हैं, और उत्पाद . में शामिल होते हैं, तो यह एक निष्पादन योजना है और उत्पाद उपश्रेणी बाद में टेबल। चित्र 5 देखें।
चित्र 5 . निष्पादन योजना जब समूह पहले, बाद में शामिल हो जाता है।
और हमारे पास चित्र 5 में निम्नलिखित अवलोकन हैं।
- ग्रुप बाय और एसयूएम जल्दी समाप्त हो गए।
- मोटी रेखाओं और तीरों की कम संख्या - यह केवल 348 तार्किक पठन की व्याख्या करता है।
- कम क्वेरी लागत (44%)।
3. अनुक्रमित कॉलम समूहित करें
जब भी किसी कॉलम पर SQL GROUP BY किया जाता है, तो उस कॉलम में एक इंडेक्स होना चाहिए। एक बार जब आप कॉलम को इंडेक्स के साथ समूहित करते हैं तो आप निष्पादन की गति बढ़ा देंगे। आइए पिछली क्वेरी को संशोधित करें और ऑर्डर की तारीख के बजाय जहाज की तारीख का उपयोग करें। शिप दिनांक कॉलम में SalesOrderHeader . में कोई अनुक्रमणिका नहीं है ।
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Ctrl-M दबाएं, फिर ऊपर SSMS में क्वेरी चलाएँ। फिर, शिपडेट . पर एक गैर-संकुल अनुक्रमणिका बनाएं कॉलम। तार्किक पढ़ने और निष्पादन योजना पर ध्यान दें। अंत में, उपरोक्त क्वेरी को किसी अन्य क्वेरी टैब में फिर से चलाएँ। तार्किक पठन और निष्पादन योजनाओं में अंतर पर ध्यान दें।
यहाँ चित्र 6 में तार्किक पठन की तुलना है।
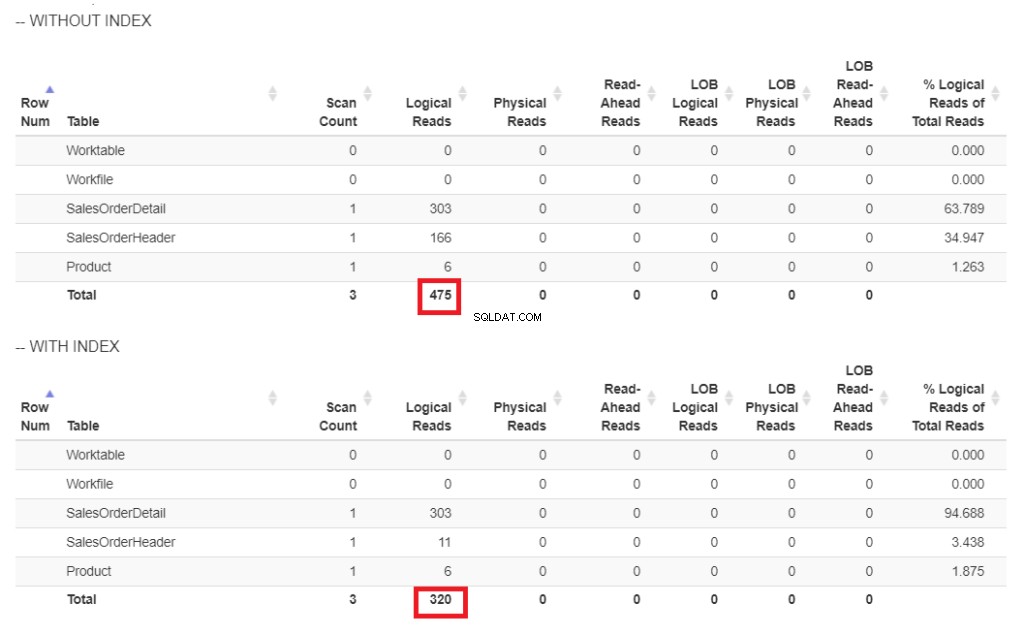
चित्र 6 . शिपडेट पर इंडेक्स के साथ और बिना हमारे क्वेरी उदाहरण को तार्किक रूप से पढ़ता है।
चित्र 6 में, ShipDate पर अनुक्रमणिका के बिना क्वेरी के उच्च तार्किक पठन हैं ।
अब निष्पादन योजना है जब शिपडेट . पर कोई अनुक्रमणिका नहीं है चित्र 7 में मौजूद है।
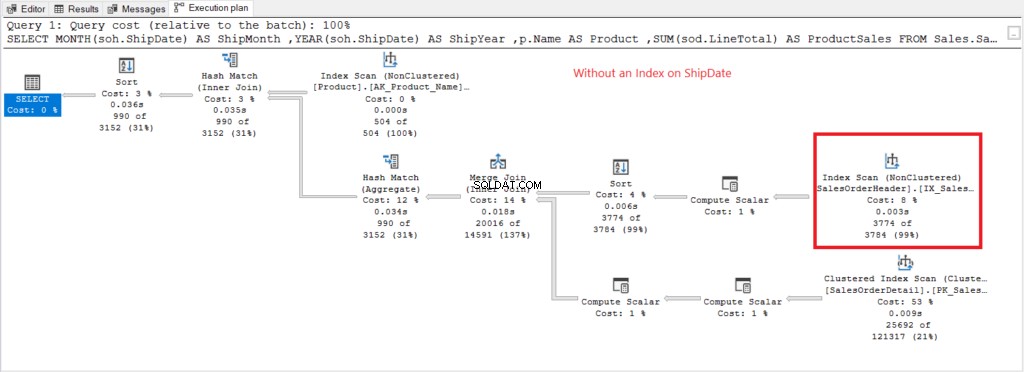
चित्र 7 . शिपडेट पर GROUP BY का उपयोग करते समय निष्पादन योजना अनइंडेक्स्ड।
इंडेक्स स्कैन चित्र 7 में योजना में प्रयुक्त ऑपरेटर उच्च तार्किक पठन (475) की व्याख्या करता है। यहां शिपडेट . को अनुक्रमित करने के बाद एक निष्पादन योजना है कॉलम।
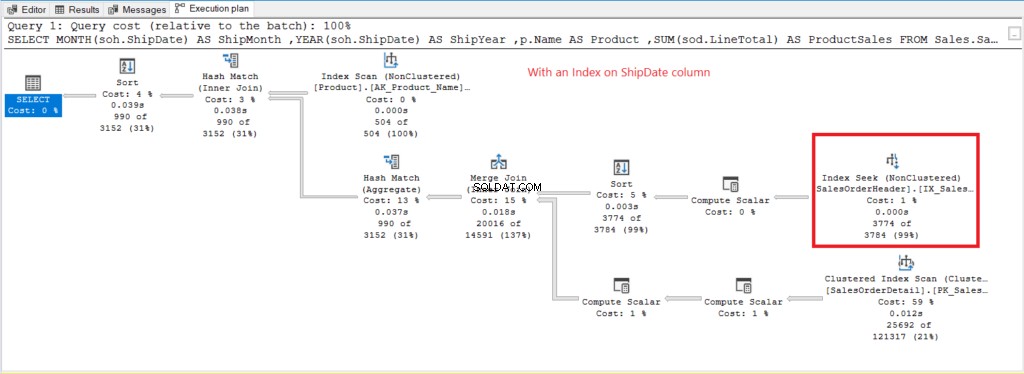
आकृति 8 . शिपडेट पर GROUP BY का उपयोग करते समय निष्पादन योजना को अनुक्रमित किया गया।
इंडेक्स स्कैन के बजाय, इंडेक्स सीक का उपयोग शिपडेट . को इंडेक्स करने के बाद किया जाता है कॉलम। यह चित्र 6 में निम्न तार्किक पठन की व्याख्या करता है।
इसलिए, GROUP BY का उपयोग करते समय प्रदर्शन को बेहतर बनाने के लिए, उन स्तंभों को अनुक्रमित करने पर विचार करें जिनका उपयोग आपने समूहीकरण के लिए किया था।
एसक्यूएल ग्रुप बाय का उपयोग करने में महत्वपूर्ण बातें
SQL GROUP BY का उपयोग करना आसान है। लेकिन रिपोर्ट के लिए डेटा को सारांशित करने से आगे जाने के लिए आपको अगला कदम उठाने की आवश्यकता है। ये रहे बिंदु फिर से:
- जल्दी फ़िल्टर करें . HAVING क्लॉज़ के बजाय WHERE क्लॉज़ का उपयोग करके उन पंक्तियों को हटा दें जिन्हें आपको सारांशित करने की आवश्यकता नहीं है।
- पहले समूह बनाएं, बाद में शामिल हों . कभी-कभी, आपके द्वारा समूहीकृत किए जा रहे स्तंभों से अलग कॉलम जोड़ने की आवश्यकता होगी। उन्हें GROUP BY क्लॉज में शामिल करने के बजाय, क्वेरी को CTE से विभाजित करें, और बाद में अन्य तालिकाओं में शामिल हों।
- अनुक्रमित स्तंभों के साथ GROUP BY का उपयोग करें . यह बुनियादी बात तब काम आ सकती है जब डेटाबेस घोंघे की तरह तेज़ हो।
आशा है कि इससे आपको परिणामों को समूहीकृत करने में अपने खेल का स्तर बढ़ाने में मदद मिलेगी।
अगर आपको यह पोस्ट पसंद आए तो कृपया इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर शेयर करें।