कोई फर्क नहीं पड़ता कि आप समीकरण के किस पक्ष में हैं, कभी-कभी किसी विशिष्ट कार्य के लिए योग्य व्यक्ति को खोजना कठिन होता है। इस पोस्ट में, हम भर्ती प्रक्रिया के दौरान भर्ती करने वालों और मानव संसाधन विभागों को संगठित रहने में मदद करने के लिए एक डेटा मॉडल को देखते हैं।
हम में से अधिकांश लोग भर्ती प्रक्रिया में शामिल रहे हैं - अक्सर नौकरी आवेदक के रूप में। हालांकि, हम आवेदक के तकनीकी ज्ञान का परीक्षण करके खुद को भर्ती पक्ष में भी शामिल कर सकते हैं। भर्ती प्रक्रिया में एक निश्चित समय लगता है, और जैसे-जैसे हम अंतिम निर्णय के करीब आते जाते हैं, आवेदकों का समूह लगातार छोटा होता जाता है। परिणाम नौकरी के लिए सर्वश्रेष्ठ व्यक्ति का चयन होना चाहिए।
भर्ती अपने आप में बहुत जटिल है, इसलिए हम प्रक्रिया के सभी पहलुओं को कवर करने के लिए एक काफी व्यापक डेटा मॉडल पर चर्चा करेंगे। अपनी कुर्सी पर वापस बैठें और आज के लेख का आनंद लें!
भर्ती प्रक्रिया कैसे काम करती है
भर्ती प्रक्रिया के अधिकांश भाग सामान्य ज्ञान हैं, लेकिन डेटा मॉडल पर आगे बढ़ने से पहले हम ठीक से चर्चा करेंगे कि यह कैसे काम करता है।
-
आवश्यकता का पता लगाना
भर्ती प्रक्रिया में यह एक परम आवश्यक है; यदि प्रबंधन को नए कर्मचारी को नियुक्त करने की आवश्यकता के बारे में जानकारी नहीं है तो कोई प्रक्रिया नहीं होगी। यह आवश्यकता एक नई कंपनी शुरू करने, मौजूदा कंपनी में वृद्धि या किसी मौजूदा कर्मचारी के प्रस्थान का परिणाम हो सकती है।
जब तक किसी कंपनी के पास कड़ाई से परिभाषित पद (जैसे बैंक) न हों, यह निर्धारित करना हमेशा आसान नहीं होता कि किसी नए कर्मचारी को कब नियुक्त किया जाए। कर्मचारियों के साथ बात करना और बहुत अधिक ओवरटाइम देखना एक नया किराया बढ़ा सकता है। आंतरिक या बाहरी विनियमों के लिए यह भी आवश्यक हो सकता है कि कुछ पद केवल एक विशिष्ट कौशल और प्रासंगिक कार्य अनुभव (जैसे आंतरिक पुनरीक्षण) वाले लोगों को दिए जाएं।
-
स्थिति और उसके आवश्यक कौशल को रेखांकित करना
इस कदम का अंदाजा लगाने के लिए, वास्तव में अच्छी तरह से लिखे गए नौकरी के विवरण के बारे में सोचें। इसमें शामिल हैं:
- नौकरी से संबंधित सभी कार्यों की सूची
- न्यूनतम शैक्षणिक और कार्य अनुभव योग्यता
- नौकरी के कार्यों के लिए आवश्यक विशिष्ट कौशल
- अतिरिक्त या पसंदीदा कौशल
- इस बात का सारांश कि नियोक्ता आवेदक से क्या अपेक्षा करता है और आवेदक इस नौकरी से क्या उम्मीद कर सकता है
- एक वेतन सीमा और शायद एक लाभ पैकेज
यह जानकारी नियोक्ताओं और आवेदकों के लिए समान रूप से महत्वपूर्ण है। दस आवेदकों को चयन प्रक्रिया में आमंत्रित करने का कोई मतलब नहीं है यदि उनमें से कोई भी वित्तीय प्रस्ताव से संतुष्ट नहीं होगा। और नौकरी का विवरण जितना विस्तृत होगा, योग्य आवेदकों को आकर्षित करना उतना ही आसान होगा।
-
यह परिभाषित करना कि प्रक्रिया का प्रबंधन कौन करेगा और प्रत्येक कार्य कब होना चाहिए
अगला कदम विशिष्ट तिथियों को परिभाषित करना है जब प्रक्रिया का प्रत्येक भाग होगा। साथ ही, कंपनियां प्रत्येक चरण में कर्मचारियों को असाइन कर सकती हैं। यदि कंपनी के पास मानव संसाधन विभाग है, तो यह संभवतः भर्ती प्रक्रिया के प्रत्येक भाग का प्रबंधन करेगा, हालांकि अन्य कर्मचारी आवश्यकता पड़ने पर अपने विशिष्ट ज्ञान का योगदान दे सकते हैं (उदाहरण के लिए यदि हम एक आईटी विशेषज्ञ को काम पर रख रहे हैं, तो आईटी विभाग के प्रबंधक को उम्मीदवारों का आकलन करना चाहिए। ' तकनीकी कौशल)।
यदि कोई मानव संसाधन विभाग नहीं है, तो हम उम्मीद कर सकते हैं कि प्रबंधन कर्मी प्रक्रिया के प्रभारी होंगे। छोटी और मध्यम आकार की कंपनियों में, इसकी न केवल आवश्यकता है, बल्कि वांछित है।
-
नौकरी पोस्ट करना
अब हम अपनी साइट पर, जॉब बोर्ड या एग्रीगेटर पर, या किसी समाचार पत्र में नौकरी का विवरण पोस्ट करने के लिए तैयार हैं। जॉब पोस्ट में चरण 2 में सूचीबद्ध बुलेट पॉइंट होने चाहिए। इससे संभावित उम्मीदवारों को यह तय करने में मदद मिलेगी कि वे पद के लिए आवेदन करना चाहते हैं या नहीं। कार्य विवरण को सटीक बनाना आवश्यक है; हम सभी ने अपना समय एक ऐसी नौकरी के लिए साक्षात्कार में बर्बाद किया है जो उसके विवरण या हमारी अपेक्षाओं से मेल नहीं खाती।
-
उम्मीदवारों का चयन, परीक्षण और साक्षात्कार
आवेदन की अवधि समाप्त होने के बाद, सबसे प्रासंगिक कौशल और अनुभव वाले आवेदकों को प्रारंभिक मूल्यांकन चरण (आमतौर पर एक साक्षात्कार या परीक्षण) के लिए आमंत्रित किया जाएगा। अन्य आवेदकों को सूचित किया जाएगा कि उन्हें नौकरी के लिए नहीं चुना गया है। एक बड़ी कंपनी को प्रारंभिक मूल्यांकन के लिए पूर्वनिर्धारित न्यूनतम उम्मीदवारों को आमंत्रित करना चाहिए। यह आवेदकों और कंपनी दोनों के लिए समय बचाता है।
छोटी और मध्यम आकार की कंपनियां इस प्रक्रिया को तब तक जारी रखने का निर्णय ले सकती हैं जब तक कि उन्हें सबसे उपयुक्त न मिल जाए। ऐसे मामलों में, आवेदन की अवधि तब तक खुली रहेगी जब तक कि सही उम्मीदवार नहीं मिल जाता और अन्य सभी तिथियों को रास्ते में परिभाषित किया जाएगा।
साक्षात्कार और परीक्षण प्रक्रिया कंपनी के आकार और संगठन के अनुसार अलग-अलग होगी। मानव संसाधन विभागों वाली बड़ी कंपनियों में, आवेदकों के नौकरी कौशल की जांच के लिए परीक्षणों का एक सेट होने की संभावना है। अन्य परीक्षण आवेदक-नौकरी मैच, आवेदक-कंपनी मैच, या यहां तक कि आवेदक की विवेक को निर्धारित करने के लिए मनोवैज्ञानिक और व्यक्तित्व लक्षणों को माप सकते हैं।
इन परीक्षणों को आम तौर पर कई चरणों में विभाजित किया जाएगा, और प्रत्येक चरण में आवेदकों की संख्या कम हो जाएगी।
-
अंतिम साक्षात्कार
यह चरण संभवत:शीर्ष कुछ आवेदकों का साक्षात्कार होगा। यह प्रक्रिया में सबसे महत्वपूर्ण कदम है क्योंकि आवेदक स्वयं के लिए बोल सकते हैं, अपनी क्षमता और व्यक्तित्व का प्रदर्शन कर सकते हैं, और यह निर्धारित कर सकते हैं कि कंपनी और स्थिति उनके लिए उपयुक्त होगी या नहीं। इस चरण के बाद, सर्वश्रेष्ठ आवेदक को एक प्रस्ताव प्राप्त होगा। यदि वे स्वीकार करते हैं, तो उस पद के लिए भर्ती प्रक्रिया समाप्त हो गई है। अगर आवेदक नौकरी के प्रस्ताव को ठुकरा देता है, तो कंपनी उनकी अगली पसंद के लिए एक प्रस्ताव देगी।
-
क्या छोटे, मध्यम और बड़े व्यवसायों की भर्ती प्रक्रिया में अंतर है? हम उन्हें अपने मॉडल में कैसे हल करेंगे?
छोटी, मध्यम और बड़ी कंपनियों की भर्ती प्रक्रियाओं में कुछ अंतर होगा। साथ ही, भर्ती किए जा रहे पदों के अनुसार प्रक्रिया अलग-अलग होगी। सोचें कि एक सामग्री प्रबंधक, एक पक्षी विज्ञानी और एक क्रूज शिप कप्तान के लिए आवश्यक कौशल और अनुभव कितने भिन्न हैं। कुछ नौकरियों में अधिक परीक्षण और साक्षात्कार होंगे, अन्य में कुछ ही हो सकते हैं। लेकिन अंत में, यह सही उत्तर पाने और आवेदकों की रैंकिंग करने के लिए नीचे आता है।
इस मॉडल में, मैं सभी परीक्षणों और साक्षात्कारों को एक समान मानूंगा। हम प्रत्येक आवेदक के उत्तरों को संग्रहीत करेंगे, उन्हें प्रासंगिक प्रश्न से जोड़ेंगे, और प्रक्रिया के प्रत्येक चरण के लिए आवेदक के स्कोर को संग्रहीत करेंगे।
-
इस डेटा मॉडल का उपयोग कौन कर सकता है?
यह मॉडल बहुत विशिष्ट है और इसका उपयोग केवल भर्ती प्रक्रिया के लिए किया जाना चाहिए। लेकिन यह मानव संसाधन विभागों तक सीमित नहीं है; आप इस मॉडल का उपयोग पेशेवर भर्ती सेवा चलाने के लिए भी कर सकते हैं।
-
डेटा मॉडल
डेटा मॉडल में पांच मुख्य विषय क्षेत्र होते हैं:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
मैं प्रत्येक विषय क्षेत्र का अलग से वर्णन करूंगा, उसी क्रम में वे सूचीबद्ध हैं।
अनुभाग 1:नौकरियां
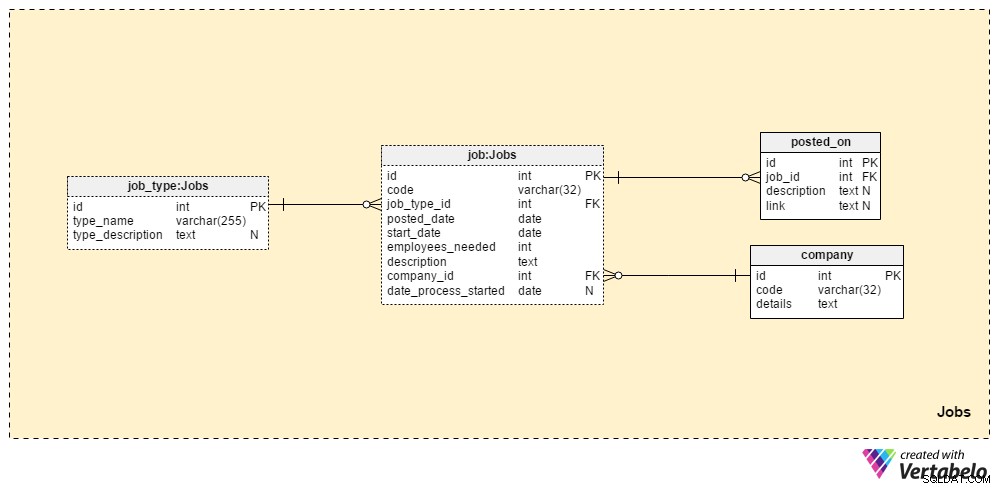
Jobs अनुभाग हमारे द्वारा पोस्ट किए गए सभी पदों के लिए सभी विवरण संग्रहीत करेगा। दो शब्दकोश तालिकाएं, company तालिका और job_type तालिका, प्रारंभिक सेटअप का हिस्सा हैं। शेष दो टेबल, job और posted_on , नौकरी पोस्टिंग से संबंधित "वास्तविक" डेटा शामिल करें।
job_type शब्दकोश में विभिन्न और अद्वितीय कार्य प्रकारों की एक सूची है। हम “वरिष्ठ डेटाबेस व्यवस्थापक” . जैसे मूल्यों की अपेक्षा कर सकते हैं या “आईटी पत्रकार” type_name . में स्टोर करने के लिए गुण। type_description विशेषता नौकरी का अधिक विस्तृत विवरण संग्रहीत कर सकती है।
company डिक्शनरी में उन सभी कंपनियों की सूची है, जिनके साथ हम काम करते हैं। यदि हम केवल अपनी कंपनी के लिए कर्मचारियों को नियुक्त करते हैं, तो इस शब्दकोश में केवल हमारी कंपनी का नाम होगा। अगर हम एक भर्ती एजेंसी हैं, तो यह हर उस कंपनी के नाम रखेगी जिसने हमें काम पर रखा है।
हमारे द्वारा पोस्ट की गई प्रत्येक नौकरी की स्थिति की एक सूची "नौकरी" तालिका में संग्रहीत की जाती है। इस तालिका में विशेषताएँ हैं:
code- हमारी आंतरिक UNIQUE ID किसी कार्य को दर्शाने के लिए प्रयोग की जाती है।job_type_id- संबंधित नौकरी के प्रकार का संदर्भ देता है।posted_date- वह तिथि जब यह नौकरी की स्थिति पोस्ट की गई थी।start_date- उस कार्य के लिए अपेक्षित प्रारंभ तिथि (पहला कार्य दिवस)।employees_needed- इस भर्ती प्रक्रिया के दौरान हम जितने कर्मचारियों को नियुक्त करना चाहते हैं। अधिकतर इसका मान "1" होगा, लेकिन कुछ मामलों में - उदा. एक नई कंपनी शुरू करते समय या एक नया विभाग स्थापित करते समय - हम बड़े मूल्यों की उम्मीद कर सकते हैं।description- उस स्थिति का विस्तृत विवरण। यह वह जगह है जहां हम सभी आवश्यक, पसंदीदा और वांछित नौकरी कौशल सूचीबद्ध करेंगे।company_id- उस कंपनी की आईडी का संदर्भ देता है जिसने हमें काम पर रखा है। यदि हम एक भर्ती एजेंसी हैं, तो यहcompanyटेबल। अन्यथा, यह हमारी अपनी कंपनी की आईडी होगी।date_process_started- भर्ती प्रक्रिया शुरू होने की तिथि। यदि हमें इस कार्य के संबंध में भविष्य के चरणों और कार्यों को परिभाषित करने की आवश्यकता है तो यह NULL हो सकता है।
इस विषय क्षेत्र में अंतिम तालिका posted_on टेबल। प्रत्येक job_id . के लिए , हम एक link स्टोर करेंगे नौकरी की पोस्ट और संबंधित description . के लिए . हम इस डेटा का उपयोग यह जानने के लिए कर सकते हैं कि आवेदकों को हमारे जॉब पोस्ट कहां मिलते हैं।
अनुभाग 2:आवेदक, भर्तीकर्ता और दस्तावेज़
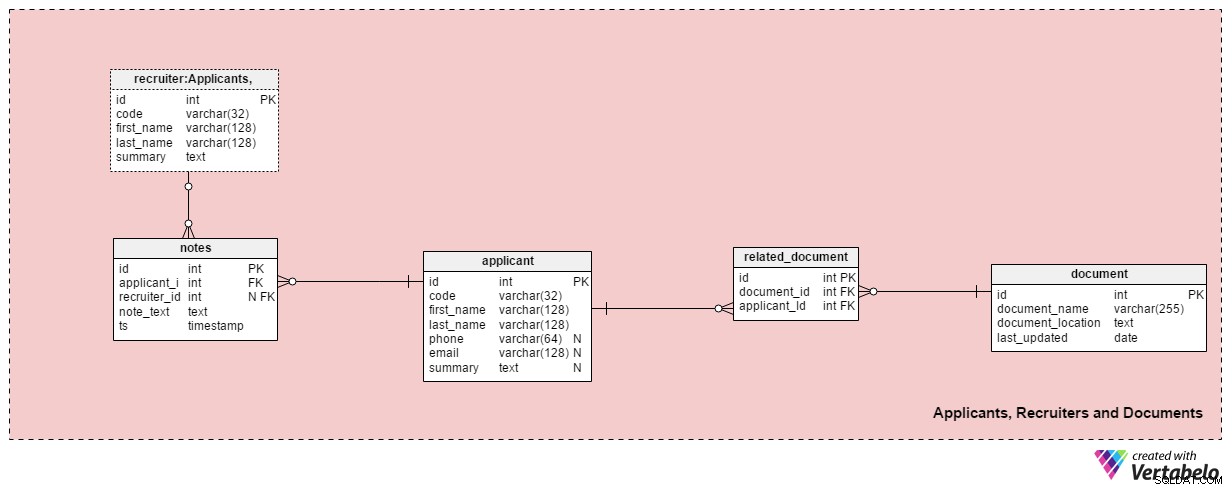
इस विषय क्षेत्र में भर्ती करने वालों, आवेदकों और उनके संबंधित दस्तावेजों के बारे में जानकारी संग्रहीत करने के लिए आवश्यक सभी तालिकाएँ हैं।
applicant तालिका उन सभी आवेदकों को सूचीबद्ध करती है जिनके साथ हमने कभी संपर्क किया है। प्रत्येक आवेदक को हमारे सिस्टम में "कोड" के साथ विशिष्ट रूप से परिभाषित किया गया है। इसके अलावा, हम प्रत्येक आवेदक का पहला और अंतिम नाम, phone . स्टोर करेंगे नंबर, email पता, और उनका summary . इस तालिका को विशिष्ट आवश्यकताओं के लिए समायोजित किया जा सकता है, उदा। अतिरिक्त फ़ोन नंबर, ईमेल या भौतिक पते जोड़ना।
हम उपलब्ध दस्तावेजों के साथ आवेदकों से संबंधित होंगे। document टेबल। प्रत्येक दस्तावेज़ के लिए, हम उसका नाम सिस्टम, उसके स्थान और नवीनतम अपडेट के समय में संग्रहीत करेंगे।
हम related_document टेबल। इसमें केवल दो विदेशी कुंजियाँ होती हैं, जो document_id . बनाती हैं - applicant_id अद्वितीय जोड़ी।
recruiter तालिका उन कर्मचारियों को सूचीबद्ध करती है जिन्हें नौकरी के लिए आवेदन सौंपा जा सकता है या जो आवेदक से संबंधित नोट्स दर्ज करते हैं। प्रत्येक भर्तीकर्ता को उसके या उसके code . द्वारा विशिष्ट रूप से परिभाषित किया जाता है . हम केवल बुनियादी विवरण जैसे first_name . संग्रहित करेंगे , last_name और भर्ती करने वाले का summary ।
इस विषय क्षेत्र में अंतिम तालिका notes टेबल। यह वह जगह है जहां हम एक आवेदक से संबंधित सभी नोटों को संग्रहीत करेंगे। हम “आवेदक से मीटिंग छूट गई” . जैसे नोट्स स्टोर कर सकते हैं या “आवेदक ने पहले साक्षात्कार में बहुत अच्छा किया” . प्रत्येक नोट के लिए, हम उस भर्तीकर्ता की आईडी, जिसने वह नोट बनाया है, संबंधित आवेदक की आईडी, note_text संग्रहीत करेंगे , और टाइमस्टैम्प जब नोट बनाया गया था।
अनुभाग 3:परीक्षण विवरण
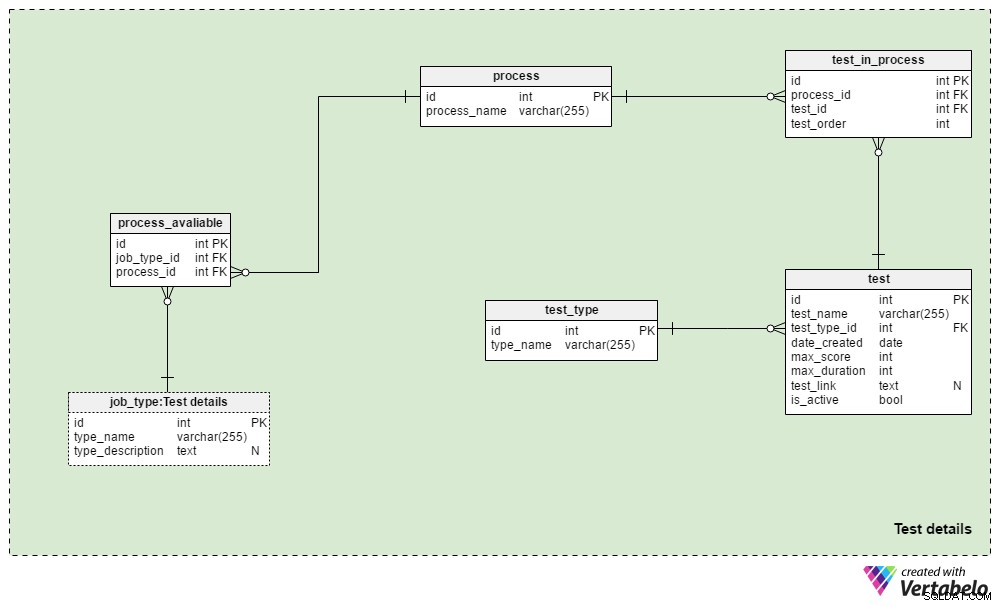
Test details विषय क्षेत्र में भर्ती प्रक्रियाओं और इन प्रक्रियाओं के दौरान उपयोग किए जाने वाले परीक्षणों को परिभाषित करने के लिए उपयोग की जाने वाली तालिकाएँ हैं। हम आम तौर पर समान कार्य प्रकार के लिए समान चयन प्रक्रिया का उपयोग करेंगे:परिवर्तन केवल तभी किए जाते हैं जब वे व्यावसायिक परिस्थितियों के लिए आवश्यक होते हैं। हम प्रत्येक प्रकार के कार्य के लिए कुछ भिन्न प्रक्रियाओं का उपयोग कर सकते हैं, और हम निश्चित रूप से विभिन्न प्रकार के कार्य के लिए समान प्रक्रिया का उपयोग करेंगे।
process तालिका एक साधारण शब्दकोश है जिसमें केवल एक अद्वितीय process_name है गुण। यह उन सभी भर्ती प्रक्रियाओं को सूचीबद्ध करता है जिनका हमने कभी उपयोग किया है और वर्तमान में उपयोग कर रहे हैं।
हम विभिन्न प्रकार के कार्य के साथ प्रक्रियाओं को जोड़ेंगे। हम इन संबंधों को process_available टेबल। इसकी एकमात्र विशेषता UNIQUE जोड़ी है job_type_id - process_id . जब नौकरी के प्रकार के लिए कई प्रक्रियाएं उपलब्ध होती हैं, तो यह भर्तीकर्ता को किसी एक को चुनने की अनुमति देता है।
test_in_process तालिका का उपयोग उस प्रक्रिया के दौरान परीक्षणों के क्रम को परिभाषित करने के लिए किया जाता है। इस तालिका में विशेषताएँ हैं:
process_idऔरtest_id- संबंधित प्रक्रिया और परीक्षण का संदर्भ देता है।test_order- उस परीक्षण की क्रम संख्या या प्रक्रिया में कदम। साथ मेंprocess_id, यह तालिका की UNIQUE कुंजी बनाता है। प्रक्रिया के दौरान हमारे पास एक समय में केवल एक ही चरण हो सकता है।
test तालिका वर्तमान में और भर्ती प्रक्रिया में पहले उपयोग किए गए सभी परीक्षणों को सूचीबद्ध करती है। हम सीवी समीक्षाओं और साक्षात्कारों को भी परीक्षण के रूप में मानेंगे। हालांकि उन्हें परिभाषित प्रश्नों और उत्तरों की आवश्यकता नहीं है, वे एक मूल्यांकन का हिस्सा हैं। प्रत्येक परीक्षण के लिए, हम संग्रहित करेंगे:
test_name- प्रत्येक परीक्षण के लिए एक अद्वितीय पदनाम।test_type_id- संदर्भtest_typeशब्दकोश।date_created- वह तारीख जब हमने अपने सिस्टम में यह परीक्षण बनाया था।max_score- इस परीक्षा के लिए प्राप्त होने वाला अधिकतम अंक। यह मान इस परीक्षा के सभी सही उत्तरों या उच्चतम ग्रेड का योग है जो भर्तीकर्ता सीवी या साक्षात्कार के लिए दे सकते हैं।max_duration- आवेदक को कितनी देर (मिनटों में) परीक्षा पूरी करनी है।test_link- परीक्षण स्थान के लिए एक लिंक शामिल है। जब हम इस प्रक्रिया में किसी परीक्षण का उपयोग नहीं करते हैं तो यह मान NULL हो सकता है।is_active- यह दर्शाता है कि क्या हम वर्तमान में इस परीक्षण का उपयोग करते हैं।
हम पहले ही test_type शब्दकोश। इसमें प्रारूप के अनुसार सभी अद्वितीय परीक्षण नाम शामिल हैं, उदा। “सीवी समीक्षा” , “ऑनलाइन कौशल परीक्षण” , "पेपर स्किल टेस्ट" और “साक्षात्कार” ।
इस मॉडल में परीक्षण प्रश्नों और उत्तरों को संग्रहीत करने के लिए आवश्यक संरचना शामिल नहीं है। बल्कि, यह उन स्थानों के लिए एक लिंक संग्रहीत करता है जिनमें यह जानकारी होती है। Applications . में एक ही डिज़ाइन का उपयोग किया जाएगा विषय क्षेत्र।
अनुभाग 4:अनुप्रयोग
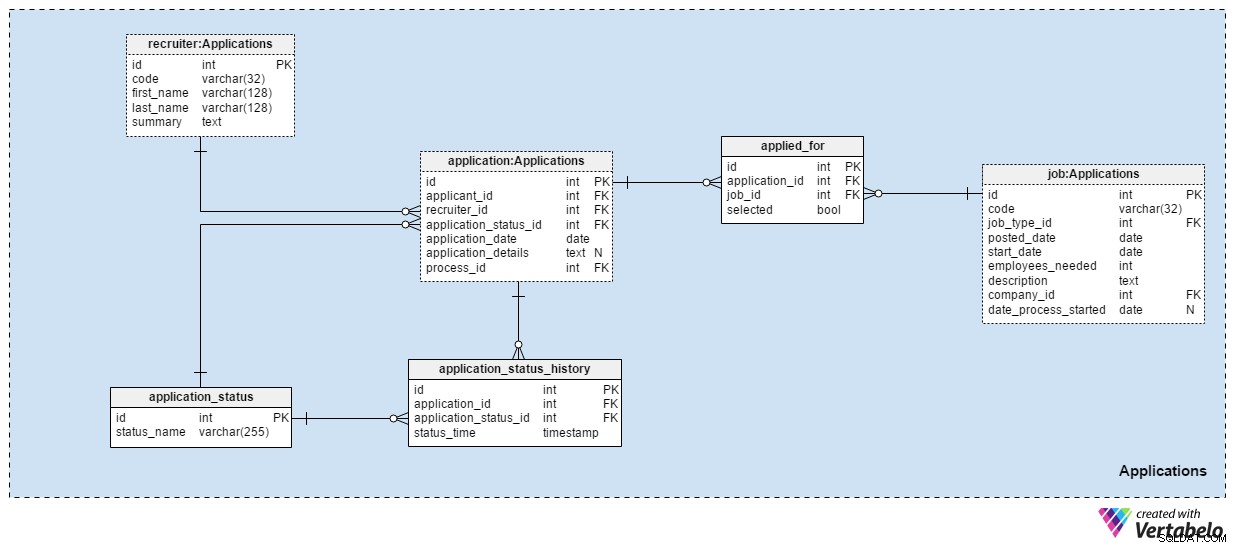
Applications इस डेटा मॉडल में विषय क्षेत्र शायद सबसे महत्वपूर्ण है। अन्य सभी विषय क्षेत्रों में अब तक वर्णित अनुप्रयोगों का उल्लेख किया गया है। यह असली चीजों को स्टोर करता है।
हमें अब तक प्राप्त प्रत्येक आवेदन application टेबल। प्रत्येक आवेदन के लिए, हम संबंधित आवेदकों की आईडी, भर्ती करने वालों की आईडी और उस आवेदन की वर्तमान स्थिति के संदर्भ को संग्रहीत करेंगे। हम इस स्थिति को उसी समय अपडेट करेंगे जब हम application_status_history टेबल। application_date विशेषता का उपयोग प्रासंगिक तिथि को संग्रहीत करने के लिए किया जाता है, जबकि सभी अतिरिक्त विवरण टेक्स्ट प्रारूप में संग्रहीत होते हैं। process_id विशेषता उस एप्लिकेशन के लिए चुनी गई प्रक्रिया का संदर्भ संग्रहीत करती है।
समय के साथ आवेदनों की स्थिति बदलेगी। सभी एप्लिकेशन स्थितियों की एक सूची application_status शब्दकोश। केवल विशेषता status_name . है और यह केवल UNIQUE मान रख सकता है। अपेक्षित मानों में शामिल हैं:"लागू" , "CV की समीक्षा की गई" , "परीक्षण के लिए चुना गया" , "CV समीक्षा के बाद अस्वीकृत" , "परीक्षा उत्तीर्ण की" , "एक साक्षात्कार के लिए आमंत्रित" और "आवेदक द्वारा समाप्त" ।
हम सभी एप्लिकेशन स्थितियों को application_status_history टेबल। इस तालिका में application तालिका और application_status शब्दकोश। हम सटीक status_time . भी स्टोर करेंगे जब यह स्थिति आवेदन को सौंपी गई थी। application_id - status_time जोड़ी इस तालिका की अद्वितीय कुंजी बनाती है।
ज्यादातर मामलों में, एक आवेदक एक आवेदन के साथ केवल एक ही पद के लिए आवेदन करेगा। यह संभव है कि एक आवेदक एक से अधिक पदों के लिए आवेदन करेगा और हम चयन प्रक्रिया के दौरान उनके लिए सबसे उपयुक्त भूमिका का चयन करेंगे। applied_for तालिका में, हम UNIQUE जोड़ी application_id संग्रहित करेंगे - job_id . हम यह भी रिकॉर्ड करेंगे कि उस आवेदन से संबंधित आवेदक selected . था या नहीं उस पद के लिए। हम उम्मीद कर सकते हैं कि सभी selected मान “गलत” . पर सेट हो जाएंगे चयन प्रक्रिया की शुरुआत में और हम प्रत्येक कार्य स्थिति के लिए केवल एक को “True” में अपडेट करेंगे ।
अनुभाग 5:आवेदन परीक्षण
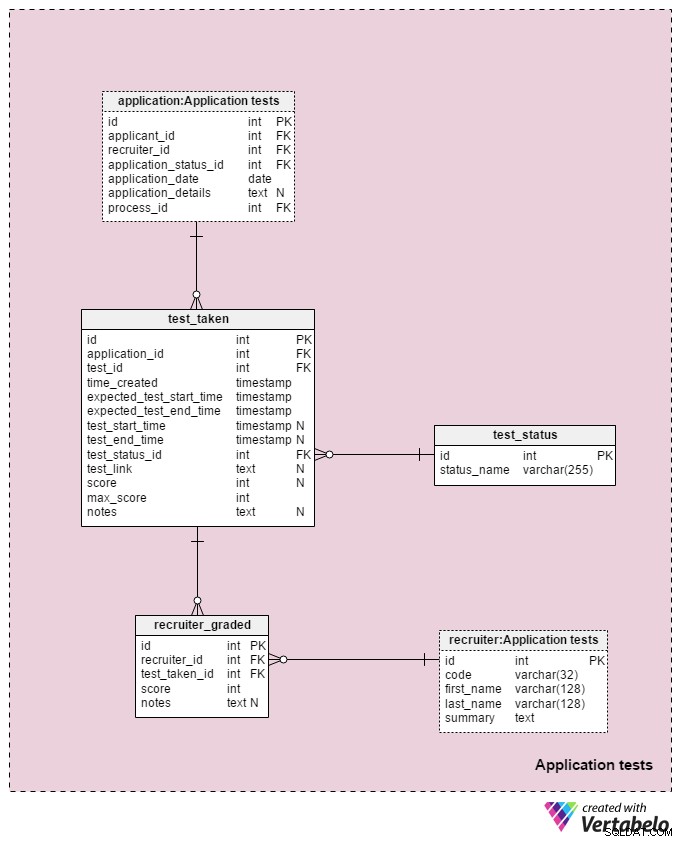
हमारे मॉडल में अंतिम विषय क्षेत्र का उपयोग चयन प्रक्रिया के दौरान लिए गए प्रत्येक परीक्षण के परिणामों को संग्रहीत करने के लिए किया जाएगा। इस विषय क्षेत्र में उपयोग की जाने वाली दो तालिकाएं अन्य विषय क्षेत्रों की प्रतियां हैं:application और recruiter . उनका उपयोग यहां मॉडल को सरल बनाने के लिए किया जाता है।
प्रत्येक परीक्षण से संबंधित सभी विवरण test_taken टेबल। इस तालिका में प्रक्रिया के अन्य सभी चरण भी शामिल हैं जिन्हें सीवी समीक्षा की तरह वर्गीकृत किया जा सकता है। इस तालिका में विशेषताएँ हैं:
application_id- संदर्भapplicationटेबल। यह उस परीक्षार्थी के साथ एक परीक्षण से संबंधित है जिसने वह परीक्षा दी थी।test_id- संदर्भtestसूची हमtest_in_processयहाँ तालिका, जो हमें ली गई परीक्षा के बारे में अधिक जानकारी प्रदान करेगी। मैंने ऐसा नहीं करने का फैसला किया क्योंकि यह संरचना हमें अधिक लचीलापन प्रदान करती है। (उदाहरण के लिए, यदि हम आवेदकों को दो बार या सामान्य समय से बाहर परीक्षा देने की अनुमति देना चाहते हैं)।time_created- वास्तविक समय में हमने इस परीक्षण को अपने सिस्टम में सम्मिलित किया था।expected_test_start_timeऔरexpected_test_end_time- प्रारंभ और समाप्ति समय, जैसा कि आवेदक के साथ चर्चा की गई है। यदि आवेदक या भर्तीकर्ता को परीक्षा स्थगित करने की आवश्यकता हो तो हम इन मूल्यों को बदल सकते हैं।test_start_timeऔरtest_end_time- परीक्षण के लिए वास्तविक प्रारंभ और समाप्ति समय। परीक्षण बनाए जाने पर इनमें NULL मान होंगे; जब आवेदक इस परीक्षण को शुरू करेगा और समाप्त करेगा, तो मूल्यों को अपडेट किया जाएगा।test_status_id- संदर्भtest_statusशब्दकोश।test_link- आवेदक के उत्तरों के साथ परीक्षा के लिंक। आवेदक द्वारा परीक्षा सबमिट करने पर इसे अपडेट कर दिया जाएगा।score- उस परीक्षा में आवेदक का स्कोर। यह या तो एक भर्तीकर्ता द्वारा मैन्युअल रूप से निर्धारित किया जाता है (उदाहरण के लिए सीवी समीक्षा के लिए) या स्वचालित रूप से (सभी परीक्षण आइटम स्कोर का योग)। यह उन परीक्षणों के लिए NULL मान भी रख सकता है जो किसी पूर्वनिर्धारित पैमाने पर स्कोर या ग्रेड नहीं किए गए हैं। साथ ही, एक परीक्षण जो शेड्यूल किया गया है लेकिन अभी तक पूरा नहीं हुआ है, उसका NULL मान हो सकता है।max_score- परीक्षण का अधिकतम प्राप्य स्कोर। यहtest. में स्टोर किए गए मान के समान है ।"max_scoreगुण। मैं उस मान को बनाए रखना चाहता हूं क्योंकि भर्तीकर्ता दिए जाने के दौरान परीक्षण को संशोधित कर सकता है और इसलिए प्राप्त किए जा सकने वाले अधिकतम स्कोर को बदल सकता है।notes- उस विशिष्ट परीक्षा के संबंध में भर्तीकर्ताओं द्वारा दर्ज किया गया कोई भी अतिरिक्त नोट या टिप्पणी।
test_id . का संयोजन - application_id - expected_test_start_time विशेषताएँ इस तालिका की UNIQUE कुंजी बनाती हैं। एक नया परीक्षण सत्र जोड़ने से पहले, हमें अभी भी संबंधित आवेदक और सभी संबंधित भर्तीकर्ताओं के लिए अतिव्यापी परीक्षण अंतरालों की जांच करनी चाहिए।
test_status शब्दकोश में हर UNIQUE status_name . की एक सूची है जिसे एक परीक्षण के लिए सौंपा जा सकता है। कुछ अपेक्षित मानों में शामिल हैं:"शुरू नहीं हुआ" , "प्रगति पर" , "सफलतापूर्वक पूर्ण हुआ" , "असफल पूर्ण" , "स्थगित" , "रद्द किया गया" और "आवेदक रद्द कर दिया गया" ।
हमारे मॉडल में अंतिम तालिका recruiter_graded तालिका, जो सभी ग्रेड भर्तीकर्ताओं को संग्रहीत करती है जो प्रत्येक परीक्षा को ग्रेडिंग करते समय देते हैं। इसलिए, हम recruiter और test_taken टेबल। हम score भी स्टोर करेंगे साथ ही किसी भी notes . को हासिल किया . यह जानकारी बहुत महत्वपूर्ण है, खासकर जब हम मैन्युअल रूप से परीक्षण ग्रेडिंग कर रहे हैं (यानी सीवी समीक्षा और साक्षात्कार के लिए)।
आज हमने एक डेटा मॉडल पर चर्चा की है जो चयन और भर्ती प्रक्रिया में लगभग किसी भी स्थिति को कवर कर सकता है - जिसमें असामान्य अपवाद भी शामिल हैं।
हम में से अधिकांश के पास इस विषय में कुछ विशेषज्ञता है। कृपया अपना अनुभव साझा करें जब आप भर्तीकर्ता की भूमिका में थे या डेस्क के दूसरी तरफ थे। क्या यह मॉडल उन स्थितियों को कवर करता है जिनका आपने सामना किया? यदि नहीं, तो आप क्या परिवर्तन प्रस्तावित करेंगे?