SQL सर्वर 2014 SP2 और बाद में रनटाइम ("वास्तविक") निष्पादन योजनाएं तैयार करता है जिसमें बीता हुआ समय शामिल हो सकता है और CPU उपयोग प्रत्येक निष्पादन योजना ऑपरेटर के लिए (KB3170113 और पेड्रो लोप्स द्वारा यह ब्लॉग पोस्ट देखें)।
इन नंबरों की व्याख्या करना हमेशा उतना आसान नहीं होता जितना कोई उम्मीद कर सकता है। पंक्ति मोड . के बीच महत्वपूर्ण अंतर हैं और बैच मोड निष्पादन, साथ ही पंक्ति मोड के साथ मुश्किल मुद्दे समानांतरता . SQL सर्वर कुछ समय समायोजन करता है समानांतर योजनाओं में निरंतरता को बढ़ावा देने के लिए, लेकिन वे पूरी तरह से लागू नहीं होते हैं। इससे ध्वनि प्रदर्शन-ट्यूनिंग निष्कर्ष निकालना मुश्किल हो सकता है।
इस लेख का उद्देश्य आपको यह समझने में मदद करना है कि प्रत्येक मामले में समय कहाँ से आता है, और संदर्भ में उनकी सर्वोत्तम व्याख्या कैसे की जा सकती है।
सेटअप
निम्न उदाहरण सार्वजनिक स्टैक ओवरफ़्लो 2013 का उपयोग करते हैं डेटाबेस (डाउनलोड विवरण), एक एकल अनुक्रमणिका के साथ जोड़ा गया:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
परीक्षण प्रश्न एक स्वीकृत उत्तर के साथ प्रश्नों की संख्या लौटाते हैं, जिन्हें महीने और वर्ष के आधार पर समूहीकृत किया जाता है। वे SQL Server 2019 CU9 . पर चलते हैं , 8 कोर वाले लैपटॉप पर, और SQL सर्वर 2019 इंस्टेंस के लिए आवंटित 16GB मेमोरी। संगतता स्तर 150 विशेष रूप से उपयोग किया जाता है।
बैच मोड सीरियल निष्पादन
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); निष्पादन योजना है (विस्तार करने के लिए क्लिक करें):
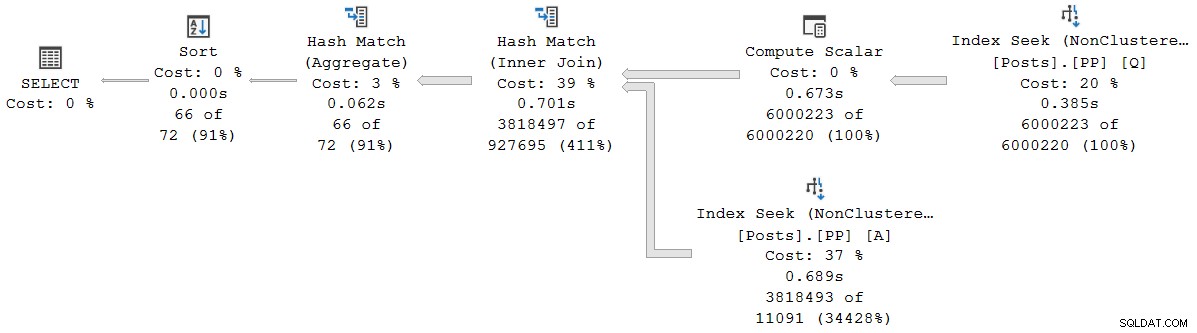
इस योजना में प्रत्येक ऑपरेटर बैच मोड में चलता है, रोस्टोर पर बैच मोड . के लिए धन्यवाद SQL सर्वर 2019 में इंटेलिजेंट क्वेरी प्रोसेसिंग सुविधा (कोई कॉलमस्टोर इंडेक्स की आवश्यकता नहीं है)। क्वेरी 2,523ms . के लिए चलती है 2,522ms CPU समय के साथ, जब आवश्यक सभी डेटा पहले से ही बफर पूल में हो।
जैसा कि पेड्रो लोप्स ने पहले लिंक किए गए ब्लॉग पोस्ट में नोट किया है, बीता हुआ और CPU समय व्यक्तिगत बैच मोड के लिए रिपोर्ट किया गया है ऑपरेटर अकेले उस ऑपरेटर द्वारा उपयोग किए गए समय का प्रतिनिधित्व करते हैं ।
SSMS बीता हुआ समय प्रदर्शित करता है चित्रमय प्रतिनिधित्व में। CPU समय देखने के लिए , एक प्लान ऑपरेटर चुनें, फिर गुणों . में देखें खिड़की। यह विस्तृत दृश्य बीता हुआ और CPU समय, प्रति ऑपरेटर और प्रति थ्रेड दोनों दिखाता है।
शोप्लान समय (एक्सएमएल प्रतिनिधित्व सहित) छोटा गया . है मिलीसेकंड तक। यदि आपको अधिक सटीकता की आवश्यकता है, तो query_thread_profile . का उपयोग करें विस्तारित घटना, जो माइक्रोसेकंड . में रिपोर्ट करती है . ऊपर दिखाए गए निष्पादन योजना के लिए इस घटना से आउटपुट है:
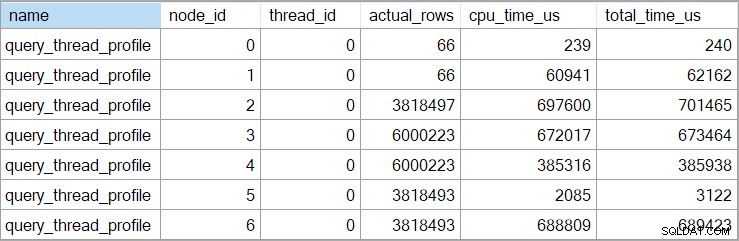
यह शामिल होने के लिए बीता हुआ समय दिखाता है (नोड 2) 701,465μs (शोप्लान में 701ms तक छोटा) है। कुल मिलाकर 62,162µs (62ms) का बीता हुआ समय है। 'प्रश्न' अनुक्रमणिका खोज को 385ms के लिए चलने के रूप में प्रदर्शित किया जाता है, जबकि विस्तारित घटना से पता चलता है कि नोड 4 के लिए वास्तविक आंकड़ा 385,938μs (लगभग 386ms) था।
SQL सर्वर उच्च-परिशुद्धता का उपयोग करता है क्वेरीपरफॉर्मेंस काउंटर समय डेटा पर कब्जा करने के लिए एपीआई। यह हार्डवेयर का उपयोग करता है, आमतौर पर एक क्रिस्टल थरथरानवाला, जो प्रोसेसर की गति, पावर सेटिंग्स, या उस प्रकृति की किसी भी चीज की परवाह किए बिना बहुत उच्च स्थिर दर पर टिक पैदा करता है। नींद के दौरान भी घड़ी उसी गति से चलती रहती है। यदि आप सभी बारीक विवरणों में रुचि रखते हैं, तो लिंक किए गए बहुत विस्तृत लेख को देखें। संक्षिप्त सारांश यह है कि आप सटीक होने के लिए माइक्रोसेकंड संख्याओं पर भरोसा कर सकते हैं।
इस शुद्ध बैच मोड योजना में, कुल निष्पादन समय अलग-अलग ऑपरेटर के बीता हुआ समय के योग के बहुत करीब है। अंतर मुख्य रूप से पोस्ट-स्टेटमेंट कार्य के लिए है जो योजना ऑपरेटरों (जो तब तक सभी बंद हो चुके हैं) से जुड़े नहीं हैं, हालांकि मिलीसेकंड ट्रंकेशन भी एक भूमिका निभाता है।
शुद्ध बैच मोड योजनाओं में, आपको संचयी प्राप्त करने के लिए वर्तमान और चाइल्ड ऑपरेटर समय को मैन्युअल रूप से जोड़ना होगा किसी दिए गए नोड पर बीता हुआ समय।
बैच मोड समानांतर निष्पादन
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); निष्पादन योजना है:
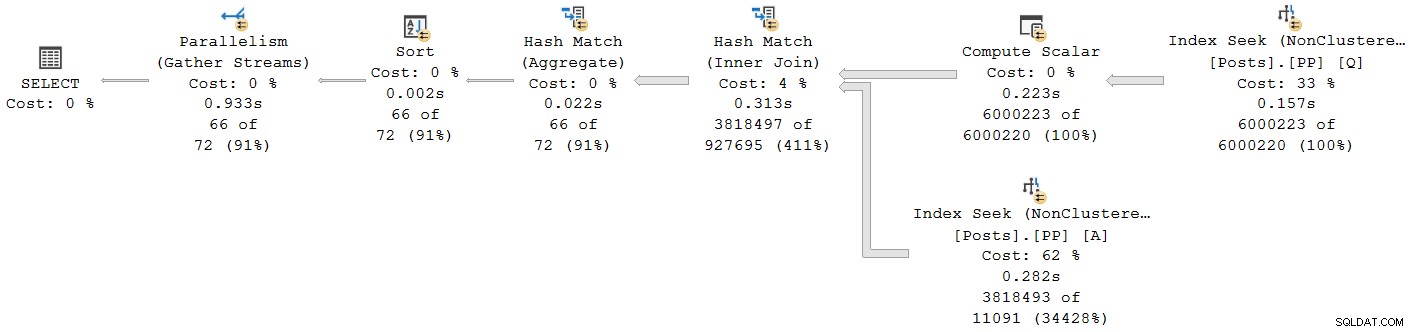
अंतिम एकत्रित स्ट्रीम एक्सचेंज को छोड़कर प्रत्येक ऑपरेटर बैच मोड में चलता है। कुल बीता हुआ समय 933ms है गर्म कैश के साथ 6,673ms CPU समय के साथ।
हैश जॉइन का चयन करना और SSMS में देखना गुण विंडो, हम उस ऑपरेटर के लिए बीता हुआ और CPU समय प्रति थ्रेड देखते हैं:
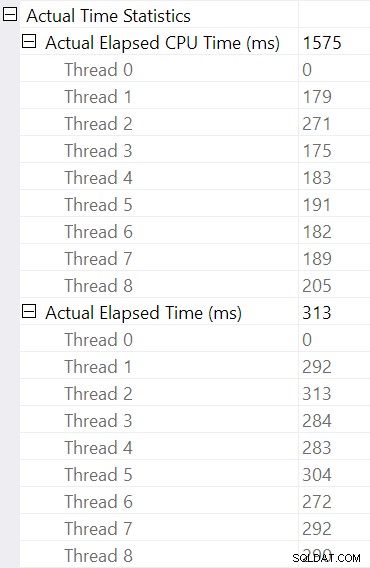
सीपीयू समय ऑपरेटर के लिए रिपोर्ट किया गया योग . है व्यक्तिगत थ्रेड CPU समय की। रिपोर्ट किया गया ऑपरेटर बीता हुआ समय अधिकतम . है प्रति-थ्रेड बीता हुआ समय। दोनों गणनाएं प्रति-थ्रेड काटे गए मिलीसेकंड मानों पर की जाती हैं। पहले की तरह, कुल निष्पादन समय अलग-अलग ऑपरेटर के बीता हुआ समय के योग के बहुत करीब है।
बैच मोड समानांतर योजनाएँ थ्रेड्स के बीच कार्य वितरित करने के लिए एक्सचेंजों का उपयोग नहीं करती हैं। बैच ऑपरेटरों को कार्यान्वित किया जाता है ताकि एकाधिक थ्रेड एक साझा संरचना . पर कुशलता से काम कर सकें (जैसे हैश टेबल)। बैच मोड समानांतर योजनाओं में थ्रेड के बीच कुछ सिंक्रनाइज़ेशन अभी भी आवश्यक है, लेकिन सिंक पॉइंट और अन्य विवरण शोप्लान आउटपुट में दिखाई नहीं दे रहे हैं।
पंक्ति मोड सीरियल निष्पादन
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); निष्पादन योजना नेत्रहीन रूप से बैच मोड सीरियल योजना के समान है, लेकिन प्रत्येक ऑपरेटर अब पंक्ति मोड में चल रहा है:
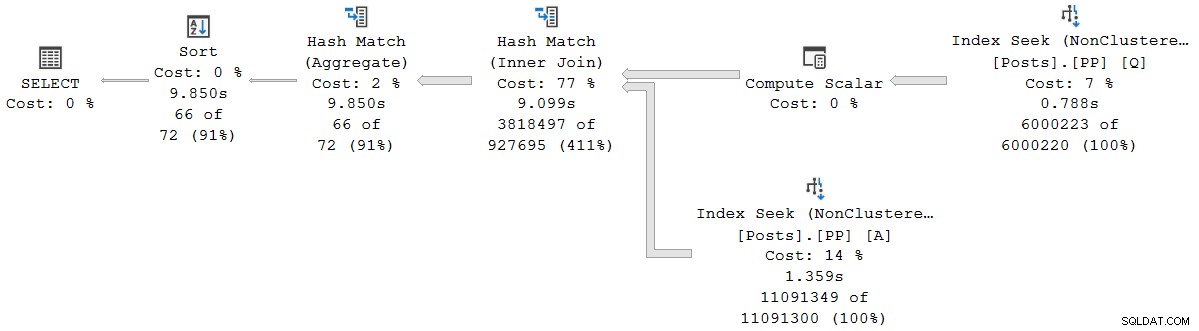
क्वेरी 9,850ms . के लिए चलती है 9,845ms CPU समय के साथ। यह अपेक्षा के अनुरूप सीरियल बैच मोड क्वेरी (2523ms/2522ms) की तुलना में बहुत धीमा है। वर्तमान चर्चा के लिए अधिक महत्वपूर्ण, पंक्ति मोड ऑपरेटर बीत चुका है और CPU समय वर्तमान ऑपरेटर और उसके सभी बच्चों द्वारा उपयोग किए गए समय का प्रतिनिधित्व करता है ।
विस्तारित ईवेंट प्रत्येक नोड पर (माइक्रोसेकंड में) संचयी CPU और बीता हुआ समय भी दिखाता है:
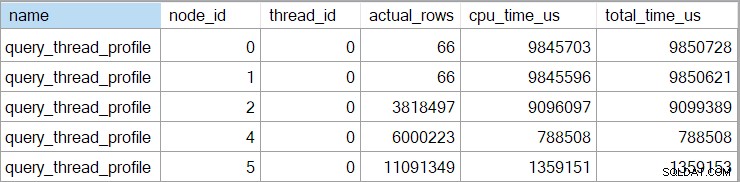
कंप्यूट स्केलर ऑपरेटर (नोड 3) के लिए कोई डेटा नहीं है क्योंकि पंक्ति मोड निष्पादन स्थगित हो सकता है परिणाम का उपभोग करने वाले ऑपरेटर के लिए सबसे अधिक अभिव्यक्ति संगणना। यह वर्तमान में बैच मोड निष्पादन के लिए लागू नहीं किया गया है।
रिपोर्ट की गई संचयी पंक्ति मोड ऑपरेटरों के लिए बीता हुआ समय का अर्थ है कि अंतिम सॉर्ट ऑपरेटर के लिए दिखाया गया समय क्वेरी के लिए कुल निष्पादन समय से निकटता से मेल खाता है (वैसे भी मिलीसेकंड रिज़ॉल्यूशन के लिए)। हैश जॉइन के लिए बीता हुआ समय इसी तरह से दो इंडेक्स के योगदान के साथ-साथ इसके नीचे की तलाश में भी शामिल है। बीता हुआ समय की गणना करने के लिए पंक्ति मोड हैश अकेले जुड़ने के लिए, हमें इसमें से दोनों खोज समय घटाना होगा।
दोनों प्रस्तुतियों के फायदे और नुकसान हैं (पंक्ति मोड के लिए संचयी, केवल बैच मोड के लिए अलग-अलग ऑपरेटर)। जो भी आप पसंद करते हैं, मतभेदों से अवगत होना महत्वपूर्ण है।
मिश्रित निष्पादन मोड योजनाएं
सामान्य तौर पर, आधुनिक निष्पादन योजनाओं में पंक्ति मोड और बैच मोड ऑपरेटरों का कोई भी मिश्रण हो सकता है। बैच मोड ऑपरेटर केवल अपने लिए समय की रिपोर्ट करेंगे। पंक्ति मोड ऑपरेटरों में योजना में उस बिंदु तक का संचयी योग शामिल होगा, जिसमें सभी . शामिल हैं बाल संचालक। इसके बारे में स्पष्ट होने के लिए:एक पंक्ति मोड ऑपरेटर के संचयी समय शामिल हैं कोई भी बैच मोड चाइल्ड ऑपरेटर।
हमने इसे पहले समानांतर बैच मोड योजना में देखा था:अंतिम (पंक्ति मोड) इकट्ठा स्ट्रीम ऑपरेटर के पास 0.933s का एक प्रदर्शित (संचयी) बीता हुआ समय था - जिसमें उसके सभी चाइल्ड बैच मोड ऑपरेटर शामिल थे। अन्य ऑपरेटर सभी बैच मोड थे, और इसलिए अकेले अलग-अलग ऑपरेटर के लिए रिपोर्ट किए गए समय।
यह स्थिति, जहां कुछ प्लान ऑपरेटर एक ही प्लान में संचयी समय है और अन्य नहीं, निस्संदेह भ्रमित करने वाला . माना जाएगा कई लोगों द्वारा।
पंक्ति मोड समानांतर निष्पादन
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); निष्पादन योजना है:

प्रत्येक ऑपरेटर पंक्ति मोड है। क्वेरी 4,677ms . के लिए चलती है 23,311ms CPU समय (सभी थ्रेड्स का योग) के साथ।
एक विशेष रूप से पंक्ति मोड योजना के रूप में, हम हर समय संचयी . होने की अपेक्षा करेंगे . बच्चे से माता-पिता (दाएं से बाएं) की ओर बढ़ते हुए, उस दिशा में समय बढ़ना चाहिए।
आइए योजना के सबसे दाहिने हिस्से को देखें:
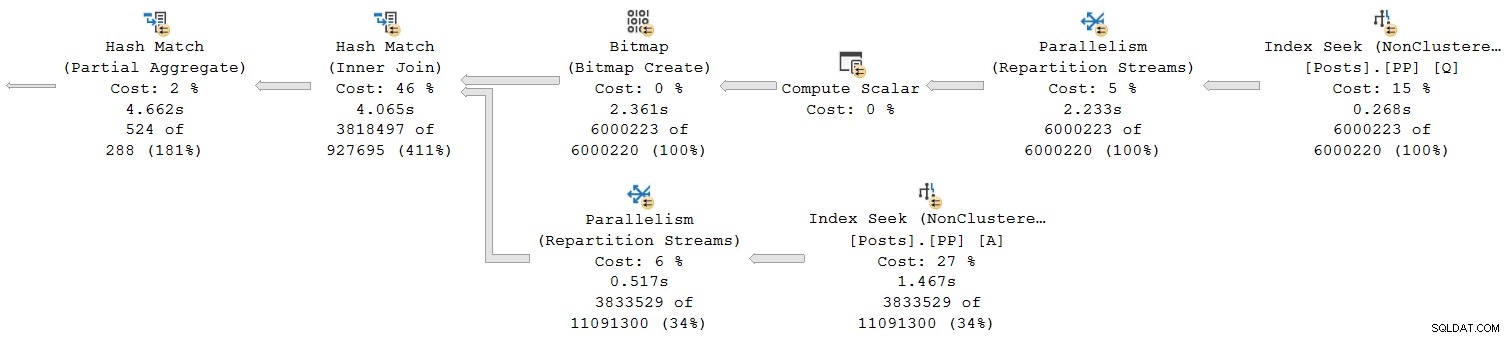
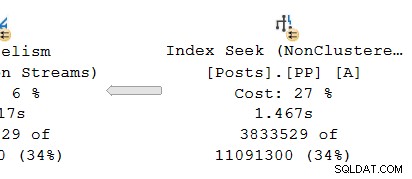
शीर्ष पंक्ति पर दाएं से बाएं कार्य करना, संचयी समय निश्चित रूप से ऐसा प्रतीत होता है। लेकिन एक अपवाद है हैश जॉइन के निचले इनपुट पर:इंडेक्स सीक का 1.467s का बीता हुआ समय है , जबकि इसके अभिभावक पुनर्विभाजन स्ट्रीम का बीता हुआ समय केवल 0.517s है ।
एक माता-पिता . कैसे हो सकता है ऑपरेटर कम समय के लिए चलता है अपने बच्चे . की तुलना में यदि बीता हुआ समय पंक्ति मोड योजनाओं में संचयी है?
असंगत समय
इस पहेली के उत्तर के कई भाग हैं। आइए इसे एक-एक करके लें, क्योंकि यह काफी जटिल है:
सबसे पहले, याद रखें कि एक एक्सचेंज (समानांतरता ऑपरेटर) के दो भाग होते हैं। बायां हाथ (उपभोक्ता ) पक्ष बाईं ओर समानांतर शाखा में चल रहे ऑपरेटरों के थ्रेड्स के एक सेट से जुड़ा है। दाहिना हाथ (निर्माता ) एक्सचेंज का पक्ष दाईं ओर समानांतर शाखा में थ्रेड चलाने वाले ऑपरेटरों के एक अलग सेट से जुड़ा है।
निर्माता की ओर से पंक्तियों को पैकेट . में इकठ्ठा किया जाता है और फिर उपभोक्ता पक्ष में स्थानांतरित कर दिया गया। यह बफ़रिंग . की एक डिग्री प्रदान करता है और प्रवाह नियंत्रण जुड़े हुए धागों के दो सेटों के बीच। (यदि आपको एक्सचेंजों और समानांतर योजना शाखाओं पर एक पुनश्चर्या की आवश्यकता है, तो कृपया मेरा लेख समानांतर निष्पादन योजनाएँ - शाखाएँ और सूत्र देखें।)
संचयी समय का दायरा
निर्माता . पर समानांतर शाखा को देखते हुए एक्सचेंज का पक्ष:
हमेशा की तरह, DOP (समानता की डिग्री) अतिरिक्त वर्कर थ्रेड एक स्वतंत्र धारावाहिक run चलाते हैं इस शाखा में योजना संचालकों की प्रति। तो, डीओपी 8 में, 8 स्वतंत्र सीरियल इंडेक्स हैं जो समग्र (समानांतर) इंडेक्स सीक ऑपरेशन के रेंज-स्कैन भाग को करने के लिए सहयोग करना चाहते हैं। प्रत्येक सिंगल-थ्रेडेड सीक एकल साझा के निर्माता पक्ष पर एक अलग इनपुट (पोर्ट) से जुड़ा है। एक्सचेंज ऑपरेटर।
ऐसी ही स्थिति उपभोक्ता . पर मौजूद है विनिमय की ओर। डीओपी 8 में, इस शाखा की 8 अलग-अलग सिंगल-थ्रेडेड प्रतियां हैं जो सभी स्वतंत्र रूप से चल रही हैं:
इनमें से प्रत्येक सिंगल-थ्रेडेड सबप्लान सामान्य तरीके से चलते हैं, प्रत्येक ऑपरेटर प्रत्येक नोड पर बीता हुआ और CPU समय योग जमा करता है। पंक्ति मोड ऑपरेटर होने के नाते, प्रत्येक कुल वर्तमान नोड और उसके प्रत्येक बच्चे के लिए कुल खर्च किए गए कुल समय का प्रतिनिधित्व करता है।
महत्वपूर्ण बिंदु यह है कि संचयी योग केवल एक ही थ्रेड . पर ऑपरेटरों को शामिल करें और केवल वर्तमान शाखा . के भीतर . उम्मीद है, यह सहज समझ में आता है, क्योंकि प्रत्येक धागे को पता नहीं है कि कहीं और क्या हो रहा है।
पंक्ति मोड मीट्रिक कैसे एकत्रित किए जाते हैं
पहेली का दूसरा भाग पंक्ति मोड योजनाओं में पंक्ति गणना और समय मीट्रिक एकत्र करने के तरीके से संबंधित है। जब रनटाइम ("वास्तविक") योजना की जानकारी की आवश्यकता होती है, तो निष्पादन इंजन एक अदृश्य . जोड़ता है प्रोफाइलिंग ऑपरेटर तत्काल बाईं ओर (पैरेंट) योजना में प्रत्येक ऑपरेटर का जिसे रनटाइम पर निष्पादित किया जाएगा।
यह ऑपरेटर (अन्य बातों के अलावा) उस समय के अंतर को रिकॉर्ड कर सकता है जिस समय उसने अपने चाइल्ड ऑपरेटर को नियंत्रण दिया था, और उस समय जब नियंत्रण वापस किया गया था। यह समय अंतर मॉनिटर किए गए ऑपरेटर और उसके सभी बच्चों . के लिए बीता हुआ समय दर्शाता है , चूंकि बच्चा प्रति पंक्ति अपने बच्चे को बुलाता है और इसी तरह। एक ऑपरेटर को कई बार बुलाया जा सकता है (आरंभ करने के लिए, फिर प्रति पंक्ति एक बार, अंत में बंद करने के लिए) इसलिए प्रोफाइलिंग ऑपरेटर द्वारा एकत्रित समय एक संचय है संभावित रूप से कई प्रति-पंक्ति पुनरावृत्तियों पर।
प्रोफाइलिंग डेटा के बारे में अधिक जानकारी के लिए विभिन्न कैप्चर विधियों का उपयोग करके एकत्र किया गया, क्वेरी प्रोफाइलिंग इन्फ्रास्ट्रक्चर को कवर करने वाले उत्पाद दस्तावेज़ देखें। ऐसी चीजों में रुचि रखने वालों के लिए, मानक बुनियादी ढांचे द्वारा उपयोग किए जाने वाले अदृश्य प्रोफाइलिंग ऑपरेटर का नाम है sqlmin!CQScanProfileNew . सभी रो मोड इटरेटर्स की तरह, इसमें Open है , GetRow , और Close विधियों, दूसरों के बीच में। प्रत्येक विधि में Windows QueryPerformanceCounter . पर कॉल होते हैं वर्तमान उच्च रिज़ॉल्यूशन टाइमर मान एकत्र करने के लिए एपीआई।
चूंकि प्रोफाइलिंग ऑपरेटर बाईं ओर . है लक्ष्य ऑपरेटर का, यह केवल उपभोक्ता . को मापता है विनिमय की ओर। कोई प्रोफाइलिंग ऑपरेटर नहीं है निर्माता . के लिए विनिमय की ओर (दुख की बात है)। अगर वहाँ थे, तो यह इंडेक्स सीक पर दिखाए गए बीता हुआ समय से मेल खाएगा या उससे अधिक होगा, क्योंकि इंडेक्स सीक और प्रोड्यूसर साइड थ्रेड्स का एक ही सेट चला रहे हैं और एक्सचेंज का प्रोड्यूसर साइड इंडेक्स सीक का पैरेंट ऑपरेटर है।
समय पर दोबारा गौर किया गया

इतना सब कहने के बाद भी, आपको अभी भी ऊपर दिखाए गए समय के साथ परेशानी हो सकती है। किसी अनुक्रमणिका की तलाश में 1.467s कैसे लग सकता है? किसी एक्सचेंज के निर्माता पक्ष में पंक्तियों को पास करने के लिए, लेकिन उपभोक्ता पक्ष केवल 0.517s . लेता है उन्हें प्राप्त करने के लिए? अलग-अलग थ्रेड, बफ़रिंग, और क्या नहीं, के बावजूद निश्चित रूप से एक्सचेंज को सीक की तुलना में अधिक समय तक (एंड-टू-एंड) चलना चाहिए?
ठीक है, हाँ यह करता है, लेकिन यह एक अलग माप है बीता हुआ या CPU समय से। हम यहां जो माप रहे हैं, उसके बारे में सटीक जानकारी दें।
पंक्ति मोड के लिए बीता हुआ समय , एक प्रति थ्रेड स्टॉपवॉच . की कल्पना करें प्रत्येक ऑपरेटर पर। स्टॉपवॉच शुरू होता है जब SQL सर्वर किसी ऑपरेटर के लिए उसके पैरेंट से कोड दर्ज करता है, और रोक देता है (लेकिन रीसेट नहीं होता) जब वह कोड ऑपरेटर को माता-पिता (बच्चे को नहीं) पर नियंत्रण वापस करने के लिए छोड़ देता है। बीता हुआ समय शामिल है कोई भी प्रतीक्षा या शेड्यूलिंग विलंब - इनमें से कोई भी घड़ी बंद नहीं करता है।
पंक्ति मोड के लिए CPU समय , समान विशेषताओं वाली समान स्टॉपवॉच की कल्पना करें, सिवाय इसके कि यह प्रतीक्षा और शेड्यूलिंग विलंब के दौरान रुक जाती है। यह केवल उस समय को जमा करता है जब ऑपरेटर या उसका कोई बच्चा शेड्यूलर (CPU) पर सक्रिय रूप से क्रियान्वित हो रहा हो। प्रति-थ्रेड प्रति-ऑपरेटर स्टॉपवॉच पर कुल समय प्रत्येक पंक्ति के लिए एक स्टार्ट-स्टॉप चक्र से बना होता है।
आइए इसे एक्सचेंज के उपभोक्ता पक्ष के साथ मौजूदा स्थिति पर लागू करें और सूचकांक की तलाश करें:
याद रखें, एक्सचेंज और इंडेक्स सीक के उपभोक्ता पक्ष अलग-अलग शाखाओं में हैं, इसलिए वे अलग थ्रेड्स पर चल रहे हैं। . एक ही धागे में उपभोक्ता पक्ष की कोई संतान नहीं है। इंडेक्स सीक में एक्सचेंज का निर्माता पक्ष समान-थ्रेड पैरेंट के रूप में होता है, लेकिन हमारे पास वहां स्टॉपवॉच नहीं है।
प्रत्येक उपभोक्ता धागा अपनी घड़ी तब शुरू करता है जब उसका मूल ऑपरेटर (हैश जॉइन का जांच पक्ष) नियंत्रण पास करता है (उदाहरण के लिए एक पंक्ति लाने के लिए)। जब तक उपभोक्ता वर्तमान एक्सचेंज पैकेट से एक पंक्ति प्राप्त करता है, तब तक घड़ी चलती रहती है। घड़ी रुक जाती है जब नियंत्रण उपभोक्ता को छोड़ देता है और हैश में वापस आ जाता है तो जांच पक्ष में शामिल हो जाता है। अगली पंक्ति लाने के लिए हमारे एक्सचेंज के उपभोक्ता पक्ष पर नियंत्रण लौटने से पहले आगे माता-पिता (आंशिक कुल और उसके मूल विनिमय) भी उस पंक्ति पर काम करेंगे (और प्रतीक्षा कर सकते हैं)। उस समय, हमारे एक्सचेंज का उपभोक्ता पक्ष बीता हुआ और सीपीयू समय फिर से जमा होना शुरू हो जाता है।
इस बीच, उपभोक्ता पक्ष शाखा थ्रेड चाहे जो भी कर रहे हों, स्वतंत्र रूप से सूचकांक खोज थ्रेड इंडेक्स में पंक्तियों का पता लगाने और उन्हें एक्सचेंज में फीड करने के लिए जारी हैं। एक इंडेक्स सीक थ्रेड अपनी स्टॉपवॉच तब शुरू करता है जब एक्सचेंज का निर्माता पक्ष उससे एक पंक्ति मांगता है। जब पंक्ति को एक्सचेंज में पास किया जाता है तो स्टॉपवॉच को रोक दिया जाता है। जब एक्सचेंज अगली पंक्ति के लिए पूछता है, तो इंडेक्स की तलाश स्टॉपवॉच फिर से शुरू हो जाती है।
ध्यान दें कि एक्सचेंज का निर्माता पक्ष CXPACKET . का अनुभव कर सकता है एक्सचेंज बफ़र्स भरने के रूप में प्रतीक्षा करता है, लेकिन यह इंडेक्स की तलाश में दर्ज किए गए बीता हुआ समय में नहीं जुड़ता क्योंकि ऐसा होने पर इसकी स्टॉपवॉच नहीं चल रही है। अगर हमारे पास एक्सचेंज के निर्माता पक्ष के लिए स्टॉपवॉच होती, तो लापता बीता हुआ समय वहां दिखाई देता।
स्थिति के सारांश को दृष्टिगत रूप से अनुमानित करने के लिए, निम्न आरेख दिखाता है कि प्रत्येक ऑपरेटर दो समानांतर शाखाओं में बीता हुआ समय कब जमा करता है:
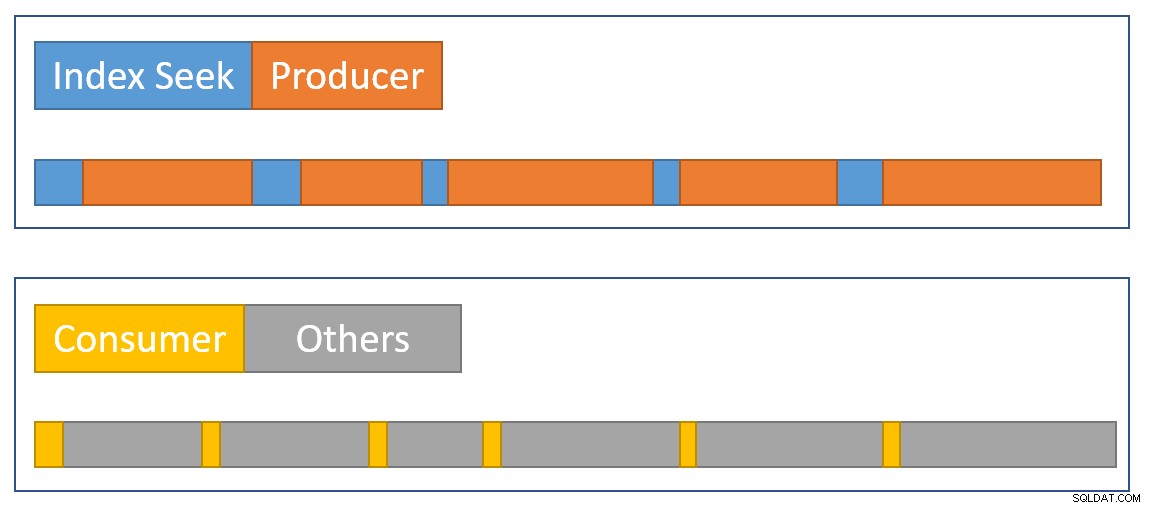
नीला अनुक्रमणिका खोज समय पट्टियाँ कम हैं क्योंकि अनुक्रमणिका से पंक्ति प्राप्त करना तेज़ है। नारंगी CXPACKET . के कारण निर्माता समय लंबा हो सकता है प्रतीक्षा करता है पीला उपभोक्ता समय कम है क्योंकि डेटा उपलब्ध होने पर एक्सचेंज से एक पंक्ति को पुनः प्राप्त करना त्वरित होता है। ग्रे टाइम सेगमेंट एक्सचेंज के उपभोक्ता पक्ष के ऊपर अन्य ऑपरेटरों (हैश जॉइन प्रोब साइड, आंशिक एग्रीगेट, और इसके पैरेंट एक्सचेंज प्रोड्यूसर साइड) द्वारा उपयोग किए गए समय का प्रतिनिधित्व करते हैं।
हम उम्मीद करते हैं कि एक्सचेंज पैकेट जल्दी से भर जाएं अनुक्रमणिका द्वारा खोजा गया, लेकिन धीरे-धीरे खाली किया गया (अपेक्षाकृत बोलते हुए) उपभोक्ता-पक्ष ऑपरेटरों द्वारा क्योंकि उनके पास करने के लिए और अधिक काम है। इसका मतलब है कि एक्सचेंज में पैकेट आमतौर पर फुल या फुल के करीब होंगे। उपभोक्ता जल्दी से एक प्रतीक्षा पंक्ति को पुनः प्राप्त करने में सक्षम होगा, लेकिन निर्माता को पैकेट स्थान के प्रकट होने की प्रतीक्षा करनी पड़ सकती है।
यह शर्म की बात है कि हम एक्सचेंज के निर्माता पक्ष में बीता हुआ समय नहीं देख सकते। मेरा लंबे समय से विचार है कि एक एक्सचेंज का प्रतिनिधित्व दो . द्वारा किया जाना चाहिए निष्पादन योजनाओं में विभिन्न ऑपरेटरों। यह मुश्किल बना देगा CXPACKET /CXCONSUMER प्रतीक्षा विश्लेषण बहुत कम आवश्यक है, और निष्पादन योजनाओं को समझना बहुत आसान है। एक्सचेंज प्रोड्यूसर ऑपरेटर को स्वाभाविक रूप से अपना प्रोफाइलिंग ऑपरेटर मिलेगा।
वैकल्पिक डिज़ाइन
ऐसे कई तरीके हैं जिनसे SQL सर्वर लगातार संचयी प्राप्त कर सकता है समानांतर शाखाओं में बीता हुआ और CPU समय सिद्धांत रूप में . प्रोफाइलिंग ऑपरेटरों के बजाय, प्रत्येक पंक्ति इस बारे में जानकारी ले सकती है कि योजना के माध्यम से अपनी यात्रा में अब तक कितना बीत चुका है और सीपीयू समय कितना अर्जित हुआ है। प्रत्येक पंक्ति के साथ जुड़े इतिहास के साथ, इससे कोई फर्क नहीं पड़ता कि एक्सचेंज कैसे थ्रेड्स के बीच पंक्तियों को पुनर्वितरित करता है और इसी तरह।
ऐसा नहीं है कि उत्पाद को कैसे डिज़ाइन किया गया है, इसलिए हमारे पास ऐसा नहीं है (और यह वैसे भी अक्षम हो सकता है)। निष्पक्ष होने के लिए, मूल पंक्ति मोड डिज़ाइन केवल वास्तविक पंक्ति गणना और प्रत्येक ऑपरेटर पर पुनरावृत्तियों की संख्या एकत्र करने जैसी चीज़ों से संबंधित था। प्रति-ऑपरेटर बीता हुआ समय योजनाओं में जोड़ना एक अत्यधिक अनुरोधित विशेषता . थी , लेकिन मौजूदा ढांचे में शामिल करना आसान नहीं था।
जब बैच मोड प्रोसेसिंग को उत्पाद में जोड़ा गया था, तो एक अलग दृष्टिकोण (केवल वर्तमान ऑपरेटर के लिए समय) को बिना कुछ तोड़े मूल विकास के हिस्से के रूप में लागू किया जा सकता था। फिर से, सिद्धांत रूप में , पंक्ति मोड ऑपरेटरों को बैच मोड ऑपरेटरों के समान काम करने के लिए संशोधित किया जा सकता था, लेकिन इसके लिए प्रत्येक मौजूदा पंक्ति मोड ऑपरेटर को फिर से तैयार करने के लिए बहुत अधिक काम की आवश्यकता होगी। मौजूदा पंक्ति मोड प्रोफाइलिंग ऑपरेटरों में एक नया डेटा बिंदु जोड़ना बहुत आसान था। सीमित इंजीनियरिंग संसाधनों और वांछित उत्पाद सुधारों की एक लंबी सूची को देखते हुए, इस तरह के समझौते अक्सर करने पड़ते हैं।
दूसरी समस्या
वर्तमान योजना में बाईं ओर एक और संचयी समय विसंगति होती है:

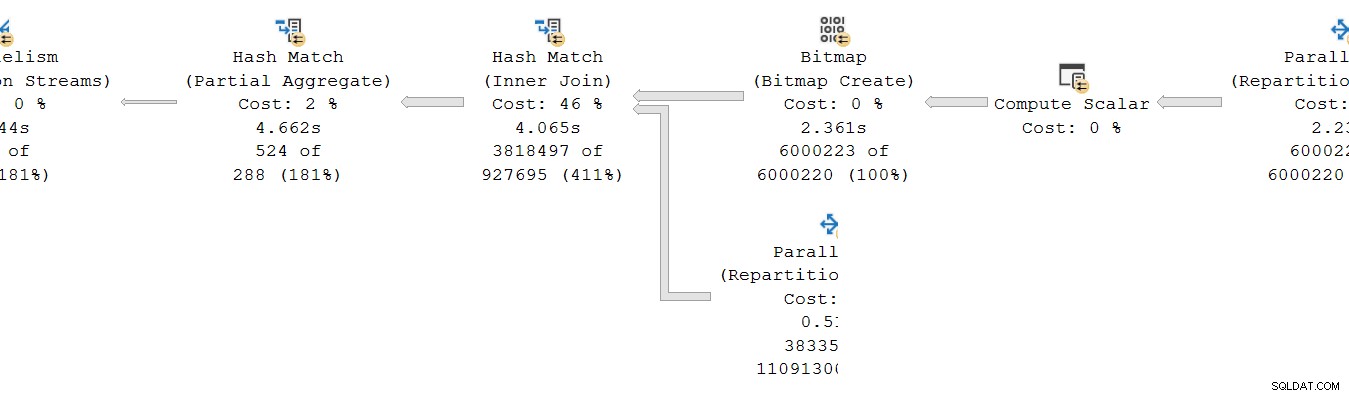
पहली नज़र में, यह एक ही समस्या की तरह लगता है:आंशिक समुच्चय का 4.662s का बीता हुआ समय है , लेकिन इसके ऊपर का एक्सचेंज केवल 2.844s . के लिए चलता है . पहले की तरह ही बुनियादी यांत्रिकी बेशक खेल में हैं, लेकिन एक और महत्वपूर्ण कारक है। स्ट्रीम एग्रीगेट, सॉर्ट और रीपार्टिशनिंग एक्सचेंज के लिए रिपोर्ट किए गए संदिग्ध रूप से समान समय में एक सुराग निहित है।
याद रखें "समय समायोजन" जिसका मैंने परिचय में उल्लेख किया था? यह वह जगह है जहां वे आते हैं। आइए पुनर्विभाजन स्ट्रीम एक्सचेंज के उपभोक्ता पक्ष पर थ्रेड्स के लिए व्यक्तिगत बीता हुआ समय देखें:
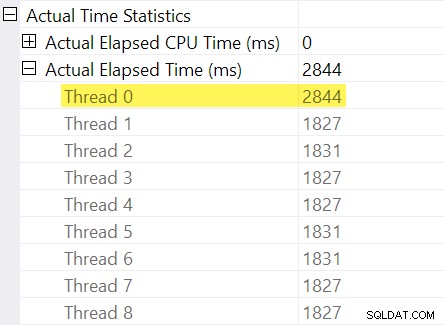
याद रखें कि योजनाएं समानांतर ऑपरेटर के लिए बीते हुए समय को अधिकतम . के रूप में दर्शाती हैं प्रति थ्रेड समय की। सभी 8 थ्रेड्स का समय लगभग 1,830ms था, लेकिन 2,844ms के साथ "थ्रेड 0" के लिए एक अतिरिक्त प्रविष्टि है। दरअसल हर ऑपरेटर इस समानांतर शाखा में (विनिमय उपभोक्ता, सॉर्ट और स्ट्रीम एग्रीगेट) के पास समान . है "थ्रेड 0" से 2,844ms योगदान।
थ्रेड ज़ीरो (उर्फ पैरेंट टास्क या कोऑर्डिनेटर) केवल सीधे ऑपरेटरों को अंतिम इकट्ठा स्ट्रीम ऑपरेटर के बाईं ओर चलाता है। इसे यहाँ समानांतर शाखा में क्यों सौंपा गया है?
स्पष्टीकरण
यह समस्या तब हो सकती है जब समानांतर शाखा में नीचे . ब्लॉक करने वाला ऑपरेटर हो (दाईं ओर) वर्तमान वाला। इस समायोजन के बिना, वर्तमान शाखा के ऑपरेटर बीता हुआ समय कम रिपोर्ट करेंगे चाइल्ड ब्रांच को खोलने के लिए आवश्यक समय के अनुसार (वहाँ हैं जटिल इसके स्थापत्य कारण)।
SQL सर्वर अदृश्य प्रोफाइलिंग ऑपरेटर में एक्सचेंज में चाइल्ड ब्रांच की देरी को रिकॉर्ड करके इसका हिसाब लगाता है। समय मान मूल कार्य . के विरुद्ध दर्ज किया जाता है ("थ्रेड 0") इसके पहले सक्रिय . के बीच के अंतर में और पिछली बार सक्रिय बार। (इस तरह से संख्या को रिकॉर्ड करना अजीब लग सकता है, लेकिन जिस समय संख्या को रिकॉर्ड करने की आवश्यकता होती है, अतिरिक्त समानांतर वर्कर थ्रेड अभी तक नहीं बनाए गए हैं)।
वर्तमान मामले में, 2,844ms समायोजन मुख्य रूप से हैश को अपनी हैश तालिका बनाने में लगने वाले समय के कारण उत्पन्न होता है। (ध्यान दें कि यह समय कुल . से अलग है हैश जॉइन का निष्पादन समय, जिसमें शामिल होने के जांच पक्ष को संसाधित करने में लगने वाला समय शामिल है)।
समायोजन की आवश्यकता उत्पन्न होती है क्योंकि हैश जॉइन इसके निर्माण इनपुट पर अवरुद्ध हो रहा है। (दिलचस्प है, हैश आंशिक समुच्चय योजना में इस संदर्भ में अवरुद्ध नहीं माना जाता है क्योंकि इसे केवल न्यूनतम मात्रा में स्मृति दी जाती है, कभी भी tempdb तक नहीं फैलती है , और अगर यह स्मृति से बाहर हो जाता है (जिससे स्ट्रीमिंग मोड में वापस आ जाता है) तो बस एकत्र करना बंद कर देता है। क्रेग फ़्रीडमैन ने अपनी पोस्ट आंशिक एकत्रीकरण में इसकी व्याख्या की है।
यह देखते हुए कि बीता हुआ समय समायोजन चाइल्ड ब्रांच में आरंभीकरण विलंब का प्रतिनिधित्व करता है, SQL सर्वर चाहिए "थ्रेड 0" मान को ऑफ़सेट . के रूप में मानने के लिए वर्तमान शाखा के भीतर मापा प्रति-धागा बीता हुआ समय संख्या के लिए। अधिकतम . लेना बीता हुआ समय सामान्य रूप से उचित है, क्योंकि धागे एक ही समय में शुरू होते हैं। यह नहीं करता है ऐसा करने के लिए समझ में आता है जब थ्रेड मानों में से एक अन्य सभी मानों के लिए ऑफ़सेट हो!
हम ऑफ़सेट गणना सही कर सकते हैं योजना में उपलब्ध डेटा का मैन्युअल रूप से उपयोग करना। एक्सचेंज के उपभोक्ता पक्ष में हमारे पास है:
अतिरिक्त वर्कर थ्रेड्स के बीच अधिकतम बीता हुआ समय 1,831ms . है ("थ्रेड 0" में संग्रहीत ऑफ़सेट मान को छोड़कर)। ऑफ़सेट . जोड़ना 2,844ms में से कुल 4,675ms . देता है ।
किसी भी योजना में जहां प्रति-थ्रेड समय कम . है ऑफ़सेट की तुलना में, ऑपरेटर गलत तरीके से करेगा ऑफसेट को कुल बीता हुआ समय के रूप में दिखाएं। ऐसा तब हो सकता है जब पहले वाला ब्लॉक करने वाला ऑपरेटर धीमा हो (शायद डेटा के बड़े सेट पर एक सॉर्ट या ग्लोबल एग्रीगेट हो) और बाद के ब्रांच ऑपरेटर कम समय लेने वाले हों।
योजना के इस भाग को फिर से देखना:
हमारे परिकलित 4,675ms के साथ पुनर्विभाजन स्ट्रीम, सॉर्ट, और स्ट्रीम एग्रीगेट ऑपरेटरों को गलती से असाइन किए गए 2,844ms ऑफ़सेट को बदलना value उनके संचयी बीता हुआ समय को बड़े करीने से 4,662ms के बीच आंशिक समुच्चय और 4,676ms के बीच रखता है अंतिम इकट्ठा धाराओं में। (क्रमबद्ध और समुच्चय पंक्तियों की एक छोटी संख्या पर काम करते हैं, इसलिए उनकी बीती हुई समय की गणना क्रम के समान होती है, लेकिन सामान्य तौर पर वे अक्सर भिन्न होती हैं):

उपरोक्त योजना खंड में सभी ऑपरेटरों के पास सभी थ्रेड्स में 0ms बीता हुआ CPU समय है (आंशिक कुल से अलग, जिसमें 14,891ms है)। इसलिए हमारी गणना की गई संख्याओं वाली योजना प्रदर्शित की गई संख्या की तुलना में बहुत अधिक समझ में आती है:
- 4,675ms - 4,662ms =13ms अकेले पुनर्विभाजन धाराओं द्वारा खर्च किए गए समय के लिए बीता हुआ एक अधिक उचित संख्या है . यह ऑपरेटर कोई CPU समय नहीं लेता है, और केवल 524 पंक्तियों को संसाधित करता है।
- 0ms बीता हुआ (मिलीसेकंड रिज़ॉल्यूशन तक) छोटे सॉर्ट और स्ट्रीम एग्रीगेट (फिर से, उनके बच्चों को छोड़कर) के लिए उचित है।
- 4,676ms - 4,675ms =1ms क्लाइंट को वापस करने के लिए पैरेंट टास्क थ्रेड पर 66 पंक्तियों को एकत्रित करने के लिए अंतिम एकत्रित स्ट्रीम के लिए अच्छा लगता है।
आंशिक समुच्चय (4,662ms) और पुनर्विभाजन धाराओं (2,844ms) के बीच दी गई योजना में स्पष्ट असंगति के अलावा, यह सोचना अनुचित है कि 66 पंक्तियों की अंतिम एकत्रित धाराएँ 4,676ms - 2,844ms = के लिए जिम्मेदार हो सकती हैं। 1,832ms बीता हुआ समय का। सही की गई संख्या (1ms) अधिक सटीक है, और क्वेरी ट्यूनर को गुमराह नहीं करेगी।
अब, भले ही यह ऑफ़सेट गणना सही ढंग से की गई हो, समानांतर पंक्ति मोड योजनाएं शायद नहीं पहले चर्चा किए गए कारणों के लिए सभी मामलों में लगातार संचयी समय दिखाएं। प्रमुख वास्तु परिवर्तनों के बिना पूर्ण स्थिरता प्राप्त करना कठिन या असंभव भी हो सकता है।
इस बिंदु पर उत्पन्न होने वाले प्रश्न का अनुमान लगाने के लिए:नहीं, पहले के एक्सचेंज और इंडेक्स सीक विश्लेषण में "थ्रेड 0" ऑफसेट गणना त्रुटि शामिल नहीं थी। उस एक्सचेंज के नीचे कोई ब्लॉकिंग ऑपरेटर नहीं है, इसलिए इनिशियलाइज़ेशन में कोई देरी नहीं होती है।
एक अंतिम उदाहरण
यह अगली उदाहरण क्वेरी पहले की तरह ही डेटाबेस और इंडेक्स का उपयोग करती है। मैं इसे बहुत अधिक विस्तार से नहीं खोजूंगा क्योंकि यह केवल उन बिंदुओं पर विस्तार करने का काम करता है जो मैंने पहले ही बना लिया है, इच्छुक पाठक के लिए।
इस डेमो की विशेषताएं हैं:
- बिना
ORDER GROUPसंकेत, यह दर्शाता है कि कैसे एक आंशिक समुच्चय को एक अवरोधक ऑपरेटर नहीं माना जाता है, इसलिए पुनर्विभाजन स्ट्रीम एक्सचेंज में कोई "थ्रेड 0" समायोजन उत्पन्न नहीं होता है। बीता हुआ समय सुसंगत है। - संकेत के साथ, हैश आंशिक समुच्चय के बजाय अवरुद्ध प्रकार पेश किए जाते हैं। दो अलग "थ्रेड 0" समायोजन दो पुनर्विभाजन एक्सचेंजों में दिखाई देते हैं। बीता हुआ समय दोनों शाखाओं पर अलग-अलग तरीकों से असंगत है।
प्रश्न:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
ORDER GROUP . के बिना निष्पादन योजना (कोई समायोजन नहीं, लगातार समय):

ORDER GROUP . के साथ निष्पादन योजना (दो अलग-अलग समायोजन, असंगत समय):

सारांश और निष्कर्ष
पंक्ति मोड योजना संचालक रिपोर्ट संचयी times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone ।
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ) This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.