एक आदर्श दुनिया में, इससे कोई फर्क नहीं पड़ता कि हमने किसी प्रश्न को व्यक्त करने के लिए कौन सा विशेष टी-एसक्यूएल सिंटैक्स चुना है। कोई भी शब्दार्थिक रूप से समान निर्माण बिल्कुल समान प्रदर्शन विशेषताओं के साथ, ठीक उसी भौतिक निष्पादन योजना की ओर ले जाएगा।
इसे प्राप्त करने के लिए, SQL सर्वर क्वेरी ऑप्टिमाइज़र को हर संभव तार्किक तुल्यता को जानने की आवश्यकता होगी (यह मानते हुए कि हम उन सभी को कभी भी जान सकते हैं), और सभी विकल्पों का पता लगाने के लिए समय और संसाधन दिए जाएं। संभावित तरीकों की विशाल संख्या को देखते हुए हम T-SQL में समान आवश्यकता को व्यक्त कर सकते हैं, और संभावित परिवर्तनों की बड़ी संख्या को देखते हुए, संयोजन बहुत ही सरल मामलों को छोड़कर सभी के लिए जल्दी से अप्रबंधनीय हो जाते हैं।
पूर्ण सिंटैक्स-स्वतंत्रता के साथ एक "संपूर्ण दुनिया" उन उपयोगकर्ताओं के लिए बिल्कुल सही नहीं लग सकती है जिन्हें संकलित करने के लिए मामूली-जटिल क्वेरी के लिए दिन, सप्ताह या यहां तक कि वर्षों तक इंतजार करना पड़ता है। तो क्वेरी ऑप्टिमाइज़र समझौता करता है:यह कुछ सामान्य समकक्षों की खोज करता है और निष्पादन समय में बचत की तुलना में संकलन और अनुकूलन पर अधिक समय खर्च करने से बचने के लिए कड़ी मेहनत करता है। उचित संसाधनों का उपभोग करते हुए, उचित समय में एक उचित निष्पादन योजना खोजने की कोशिश के रूप में इसके लक्ष्य को संक्षेप में प्रस्तुत किया जा सकता है।
इन सबका एक परिणाम यह है कि निष्पादन योजनाएँ अक्सर क्वेरी के लिखित रूप के प्रति संवेदनशील होती हैं। ऑप्टिमाइज़र के पास कुछ व्यापक रूप से उपयोग किए जाने वाले समकक्ष निर्माणों को एक सामान्य रूप में बदलने के लिए कुछ तर्क हैं, लेकिन इन क्षमताओं को न तो अच्छी तरह से प्रलेखित किया गया है और न ही (कहीं भी) व्यापक है।
हम निश्चित रूप से सरल प्रश्न लिखकर, उपयोगी अनुक्रमणिका प्रदान करके, अच्छे आंकड़े बनाए रखने और अधिक संबंधपरक अवधारणाओं (जैसे कर्सर, स्पष्ट लूप और गैर-इनलाइन फ़ंक्शंस से बचकर) को सीमित करके एक अच्छी निष्पादन योजना प्राप्त करने की हमारी संभावनाओं को अधिकतम कर सकते हैं, लेकिन यह है पूर्ण समाधान नहीं। यह भी कहना संभव नहीं है कि एक टी-एसक्यूएल निर्माण हमेशा हमेशा होगा एक बेहतर निष्पादन योजना तैयार करें जो एक शब्दार्थ-समान विकल्प हो।
मेरी सामान्य सलाह है कि आप जो भी टी-एसक्यूएल सिंटैक्स आपको बेहतर लगे, उसका उपयोग करके आपकी आवश्यकताओं को पूरा करने वाले सबसे सरल रिलेशनल क्वेरी फॉर्म से शुरू करें। यदि भौतिक अनुकूलन (जैसे अनुक्रमण) के बाद क्वेरी आवश्यकताओं को पूरा नहीं करती है, तो मूल शब्दार्थ को बनाए रखते हुए क्वेरी को थोड़ा अलग तरीके से व्यक्त करने का प्रयास करना उचित हो सकता है। यह मुश्किल हिस्सा है। आपको क्वेरी के किस भाग को फिर से लिखने का प्रयास करना चाहिए? आपको किस पुनर्लेखन का प्रयास करना चाहिए? इन सवालों का कोई आसान एक-आकार-फिट-सभी जवाब नहीं है। इसमें से कुछ अनुभव के लिए नीचे आता है, हालांकि क्वेरी ऑप्टिमाइज़ेशन और निष्पादन इंजन इंटर्नल के बारे में कुछ जानना भी एक उपयोगी मार्गदर्शिका हो सकता है।
उदाहरण
यह उदाहरण AdventureWorks TransactionHistory तालिका का उपयोग करता है। नीचे दी गई स्क्रिप्ट तालिका की एक प्रति बनाती है और एक संकुल और गैर-संकुल सूचकांक बनाती है। हम डेटा को बिल्कुल भी संशोधित नहीं करेंगे; यह चरण केवल अनुक्रमण को स्पष्ट करने के लिए है (और तालिका को छोटा नाम देने के लिए):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
कार्य छह विशेष उत्पादों के लिए उत्पाद और इतिहास आईडी की सूची तैयार करना है। प्रश्न को व्यक्त करने का एक तरीका यह है:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
यह क्वेरी निम्नलिखित निष्पादन योजना (SentryOne Plan Explorer में दिखाई गई) का उपयोग करके 764 पंक्तियाँ लौटाती है:

यह सरल प्रश्न TRIVIAL योजना संकलन के लिए योग्य है। निष्पादन योजना में छह अलग-अलग इंडेक्स सीक ऑपरेशंस को एक में शामिल किया गया है:
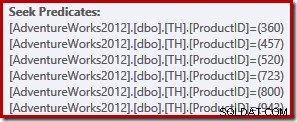
ईगल-आइड पाठकों ने देखा होगा कि छह खोज आरोही . में सूचीबद्ध हैं उत्पाद आईडी क्रम, मूल क्वेरी की IN सूची में निर्दिष्ट (मनमाने ढंग से) क्रम में नहीं। वास्तव में, यदि आप स्वयं क्वेरी चलाते हैं, तो आपको आरोही उत्पाद आईडी क्रम में लौटाए जाने वाले परिणाम देखने की काफी संभावना है। क्वेरी गारंटीकृत नहीं है निश्चित रूप से उस क्रम में परिणाम वापस करने के लिए, क्योंकि हमने क्लॉज द्वारा शीर्ष-स्तरीय ऑर्डर निर्दिष्ट नहीं किया था। हालांकि हम इस मामले में उत्पादित निष्पादन योजना को बदले बिना इस तरह के एक आदेश द्वारा खंड जोड़ सकते हैं:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
मैं निष्पादन योजना ग्राफिक को नहीं दोहराऊंगा, क्योंकि यह बिल्कुल वैसा ही है:क्वेरी अभी भी एक तुच्छ योजना के लिए योग्य है, मांग के संचालन बिल्कुल समान हैं, और दोनों योजनाओं की अनुमानित लागत बिल्कुल समान है। ORDER BY क्लॉज जोड़ने से हमें कुछ भी खर्च नहीं करना पड़ा, लेकिन हमें परिणाम सेट ऑर्डरिंग की गारंटी मिली।
अब हमारे पास गारंटी है कि परिणाम उत्पाद आईडी क्रम में लौटाए जाएंगे, लेकिन हमारी क्वेरी वर्तमान में निर्दिष्ट नहीं करती है कि समान के साथ पंक्तियाँ कैसी हैं उत्पाद आईडी का आदेश दिया जाएगा। परिणामों को देखते हुए, आप देख सकते हैं कि एक ही उत्पाद आईडी के लिए पंक्तियों को लेन-देन आईडी, आरोही द्वारा क्रमित किया गया प्रतीत होता है।
स्पष्ट ORDER BY के बिना, यह सिर्फ एक और अवलोकन है (यानी हम इस आदेश पर भरोसा नहीं कर सकते हैं), लेकिन हम यह सुनिश्चित करने के लिए क्वेरी को संशोधित कर सकते हैं कि प्रत्येक उत्पाद आईडी के भीतर लेनदेन आईडी द्वारा पंक्तियों का आदेश दिया गया है:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
फिर से, इस क्वेरी के लिए निष्पादन योजना बिल्कुल पहले की तरह ही है; एक ही अनुमानित लागत के साथ एक ही तुच्छ योजना का उत्पादन किया जाता है। अंतर यह है कि परिणाम अब गारंटीकृत . हैं पहले उत्पाद आईडी और फिर लेनदेन आईडी द्वारा ऑर्डर किया जाना है।
कुछ लोगों को यह निष्कर्ष निकालने के लिए लुभाया जा सकता है कि पिछले दो प्रश्न भी हमेशा इस क्रम में पंक्तियाँ लौटाएंगे, क्योंकि निष्पादन योजनाएँ समान हैं। यह एक सुरक्षित निहितार्थ नहीं है, क्योंकि निष्पादन योजनाओं (यहां तक कि एक्सएमएल फॉर्म में) में सभी निष्पादन इंजन विवरण उजागर नहीं होते हैं। खंड द्वारा स्पष्ट आदेश के बिना, SQL सर्वर किसी भी क्रम में पंक्तियों को वापस करने के लिए स्वतंत्र है, भले ही योजना हमें समान दिखती हो (उदाहरण के लिए, यह क्वेरी पाठ में निर्दिष्ट क्रम में खोज कर सकती है)। मुद्दा यह है कि क्वेरी ऑप्टिमाइज़र इंजन के भीतर कुछ ऐसे व्यवहारों के बारे में जानता है और लागू कर सकता है जो उपयोगकर्ताओं को दिखाई नहीं देते हैं।
यदि आप सोच रहे हैं कि उत्पाद आईडी पर हमारा गैर-अद्वितीय गैर-संकुल सूचकांक उत्पाद और में पंक्तियों को कैसे लौटा सकता है लेन-देन आईडी क्रम, उत्तर यह है कि गैर-संकुल सूचकांक कुंजी में लेनदेन आईडी (अद्वितीय क्लस्टर सूचकांक कुंजी) शामिल है। वास्तव में, भौतिक हमारे गैर-संकुलित अनुक्रमणिका की संरचना बिल्कुल है समान, सभी स्तरों पर, मानो हमने निम्नलिखित परिभाषा के साथ सूचकांक बनाया हो:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
हम क्वेरी को स्पष्ट DISTINCT या GROUP BY के साथ भी लिख सकते हैं और फिर भी ठीक उसी निष्पादन योजना को प्राप्त कर सकते हैं:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
स्पष्ट होने के लिए, इसके लिए मूल गैर-संकुल सूचकांक को किसी भी तरह से बदलने की आवश्यकता नहीं है। अंतिम उदाहरण के रूप में, ध्यान दें कि हम अवरोही क्रम में भी परिणामों का अनुरोध कर सकते हैं:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
निष्पादन योजना गुण अब दिखाते हैं कि सूचकांक पीछे की ओर स्कैन किया गया है:

इसके अलावा, योजना वही है - इसे तुच्छ योजना अनुकूलन चरण में तैयार किया गया था, और अभी भी वही अनुमानित लागत है।
क्वेरी को फिर से लिखना
पिछली क्वेरी या निष्पादन योजना में कुछ भी गलत नहीं है, लेकिन हो सकता है कि हमने क्वेरी को अलग तरीके से व्यक्त करना चुना हो:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
स्पष्ट रूप से यह फॉर्म मूल के समान ही परिणाम निर्दिष्ट करता है, और वास्तव में नई क्वेरी एक ही निष्पादन योजना (तुच्छ योजना, एक में एकाधिक खोज, समान अनुमानित लागत) उत्पन्न करती है। OR फ़ॉर्म शायद यह थोड़ा स्पष्ट करता है कि परिणाम छह अलग-अलग उत्पाद आईडी के परिणामों का एक संयोजन है, जो हमें एक और भिन्नता का प्रयास करने के लिए प्रेरित कर सकता है जो इस विचार को और भी स्पष्ट करता है:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
UNION ALL क्वेरी के लिए निष्पादन योजना काफी अलग है:
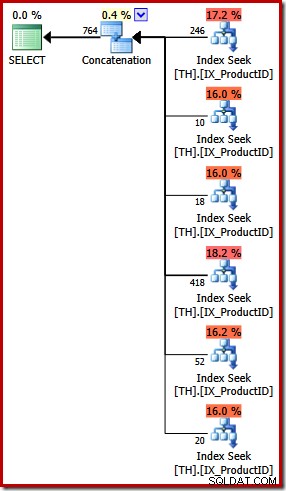
स्पष्ट दृश्य अंतरों के अलावा, इस योजना के लिए लागत-आधारित (पूर्ण) अनुकूलन की आवश्यकता थी (यह एक तुच्छ योजना के लिए योग्य नहीं थी), और अनुमानित लागत (अपेक्षाकृत बोल) काफी अधिक है, लगभग 0.02 इकाइयाँ बनाम लगभग 0.005 इकाइयों से पहले।
यह मेरी शुरुआती टिप्पणियों पर वापस जाता है:क्वेरी ऑप्टिमाइज़र हर तार्किक तुल्यता के बारे में नहीं जानता है, और हमेशा वैकल्पिक प्रश्नों को समान परिणामों को निर्दिष्ट करने के रूप में नहीं पहचान सकता है। इस स्तर पर मैं जो बात कह रहा हूं, वह यह है कि IN के बजाय UNION ALL का उपयोग करके इस विशेष प्रश्न को व्यक्त करने से कम इष्टतम निष्पादन योजना प्राप्त हुई।
दूसरा उदाहरण
यह उदाहरण छह उत्पाद आईडी का एक अलग सेट चुनता है और लेनदेन आईडी क्रम में परिणाम का अनुरोध करता है:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
हमारा गैर-संकुल सूचकांक अनुरोधित क्रम में पंक्तियाँ प्रदान नहीं कर सकता है, इसलिए क्वेरी ऑप्टिमाइज़र के पास गैर-संकुलित अनुक्रमणिका पर खोज करने और छँटाई करने, या क्लस्टर किए गए अनुक्रमणिका को स्कैन करने (जो कि केवल लेन-देन आईडी पर कुंजीबद्ध है) और उत्पाद आईडी को लागू करने के बीच चयन करने का विकल्प है। एक अवशिष्ट। सूचीबद्ध उत्पाद आईडी में पिछले सेट की तुलना में कम चयनात्मकता होती है, इसलिए ऑप्टिमाइज़र इस मामले में एक क्लस्टर इंडेक्स स्कैन चुनता है:
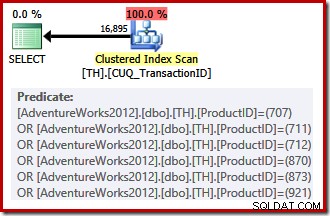
क्योंकि लागत-आधारित विकल्प बनाने के लिए, यह निष्पादन योजना एक तुच्छ योजना के लिए योग्य नहीं थी। अंतिम योजना की अनुमानित लागत लगभग 0.714 . है इकाइयां संकुल अनुक्रमणिका को स्कैन करने के लिए 797 requires की आवश्यकता होती है निष्पादन समय पर तार्किक पढ़ता है।
शायद आश्चर्य हो रहा है कि क्वेरी ने उत्पाद अनुक्रमणिका का उपयोग नहीं किया है, हम अनुक्रमणिका संकेत का उपयोग करके या FORCESEEK निर्दिष्ट करके गैर-संकुल अनुक्रमणिका की तलाश के लिए बाध्य करने का प्रयास कर सकते हैं:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
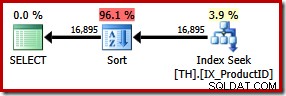
इसका परिणाम लेन-देन आईडी द्वारा एक स्पष्ट क्रम में होता है। नए प्रकार के 96% होने का अनुमान है नई योजना की 1.15 इकाई लागत। यह उच्च अनुमानित लागत बताती है कि क्यों अनुकूलक ने अपने उपकरणों पर छोड़े जाने पर स्पष्ट रूप से सस्ता क्लस्टर इंडेक्स स्कैन चुना। नई क्वेरी की I/O लागत कम है, हालांकि:निष्पादित होने पर, अनुक्रमणिका खोज केवल 49 की खपत करती है तार्किक पढ़ता है (797 से नीचे)।
हो सकता है कि हमने इस प्रश्न को व्यक्त करने के लिए (पहले असफल) UNION ALL विचार का उपयोग करना चुना हो:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
निम्नलिखित निष्पादन योजना तैयार करता है (नई विंडो में विस्तार करने के लिए छवि पर क्लिक करें):

यह योजना अधिक जटिल लग सकती है, लेकिन इसकी अनुमानित लागत केवल 0.099 . है इकाइयाँ, जो क्लस्टर्ड इंडेक्स स्कैन से बहुत कम है (0.714 इकाइयाँ) या प्लस सॉर्ट (1.15 . की तलाश करें) इकाइयां)। इसके अलावा, नई योजना केवल 49 . की खपत करती है निष्पादन समय पर तार्किक पढ़ता है - सीक + सॉर्ट योजना के समान, और क्लस्टर इंडेक्स स्कैन के लिए आवश्यक 797 से बहुत कम।
इस बार, UNION ALL का उपयोग करके क्वेरी को व्यक्त करते हुए, अनुमानित लागत और तार्किक रीड दोनों के संदर्भ में एक बेहतर योजना तैयार की। क्वेरी अवधि या CPU उपयोग के बीच वास्तव में सार्थक तुलना करने के लिए स्रोत डेटा सेट थोड़ा बहुत छोटा है, लेकिन क्लस्टर इंडेक्स स्कैन मेरे सिस्टम पर अन्य दो की तुलना में दोगुना लंबा (26ms) लेता है।
संकेतित योजना में अतिरिक्त छँटाई शायद इस सरल उदाहरण में हानिरहित है क्योंकि यह डिस्क पर फैलने की संभावना नहीं है, लेकिन बहुत से लोग वैसे भी UNION ALL योजना को पसंद करेंगे क्योंकि यह गैर-अवरुद्ध है, स्मृति अनुदान से बचा जाता है, और इसकी आवश्यकता नहीं है क्वेरी संकेत।
निष्कर्ष
हमने देखा है कि क्वेरी सिंटैक्स ऑप्टिमाइज़र द्वारा चुनी गई निष्पादन योजना को प्रभावित कर सकता है, भले ही क्वेरी तार्किक रूप से समान परिणाम सेट को निर्दिष्ट करती है। वही पुनर्लेखन (उदा. UNION ALL) के परिणामस्वरूप कभी-कभी सुधार होता है, और कभी-कभी एक बदतर योजना का चयन किया जाता है।
प्रश्नों को फिर से लिखना और वैकल्पिक सिंटैक्स का प्रयास करना एक मान्य ट्यूनिंग तकनीक है, लेकिन कुछ देखभाल की आवश्यकता है। एक जोखिम यह है कि उत्पाद में भविष्य में बदलाव के कारण अलग-अलग क्वेरी फॉर्म अचानक बेहतर योजना का निर्माण बंद कर सकते हैं, लेकिन कोई यह तर्क दे सकता है कि यह हमेशा एक जोखिम होता है, और पूर्व-अपग्रेड परीक्षण या योजना गाइड के उपयोग से कम हो जाता है।
इस तकनीक से दूर होने का जोखिम भी है:बेहतर प्रदर्शन करने वाली योजना प्राप्त करने के लिए 'अजीब' या 'असामान्य' क्वेरी निर्माण का उपयोग करना अक्सर एक संकेत है कि एक रेखा पार कर दी गई है। ठीक वहीं जहां वैध वैकल्पिक वाक्यविन्यास और 'असामान्य/अजीब' के बीच भेद शायद काफी व्यक्तिपरक है; मेरा अपना निजी मार्गदर्शक है समकक्ष संबंधपरक क्वेरी फ़ॉर्म के साथ काम करना, और चीजों को यथासंभव सरल रखना।