जब उपयोगकर्ता किसी सिस्टम से डेटा का अनुरोध करते हैं, तो वे आमतौर पर इसे एक विशिष्ट क्रम में देखना पसंद करते हैं... भले ही वे हजारों पंक्तियों को वापस कर रहे हों। जैसा कि कई डीबीए और डेवलपर्स जानते हैं, ऑर्डर बाय एक क्वेरी प्लान में कहर बरपा सकता है, क्योंकि इसके लिए डेटा को सॉर्ट करने की आवश्यकता होती है। इसे कभी-कभी क्वेरी निष्पादन के हिस्से के रूप में SORT ऑपरेटर की आवश्यकता हो सकती है, जो एक महंगा ऑपरेशन हो सकता है, खासकर अगर अनुमान बंद हो और यह डिस्क पर फैल जाए। एक आदर्श दुनिया में, डेटा पहले से ही एक सूचकांक के लिए धन्यवाद दिया जाता है (सूचकांक और प्रकार बहुत पूरक हैं)। हम अक्सर एक प्रश्न को संतुष्ट करने के लिए एक कवरिंग इंडेक्स बनाने के बारे में बात करते हैं - ताकि ऑप्टिमाइज़र को अतिरिक्त कॉलम प्राप्त करने के लिए बेस टेबल या क्लस्टर इंडेक्स पर वापस न जाना पड़े। और आपने लोगों को यह कहते सुना होगा कि इंडेक्स में कॉलम का क्रम मायने रखता है। क्या आपने कभी सोचा है कि यह आपके SORT संचालन को कैसे प्रभावित करता है?
आदेश के आधार पर जांच करना और क्रमबद्ध करना
हम SQL Server 2014 इंस्टेंस (संस्करण 12.0.2000) पर AdventureWorks2014 डेटाबेस की एक नई प्रति के साथ शुरुआत करेंगे। यदि हम Sales.SalesOrderHeader के विरुद्ध कोई ORDER BY के साथ एक साधारण SELECT क्वेरी चलाते हैं, तो हम एक सादा पुराना क्लस्टर्ड इंडेक्स स्कैन (SQL संतरी प्लान एक्सप्लोरर का उपयोग करके) देखते हैं:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 बिना ORDER BY, क्लस्टर इंडेक्स स्कैन के साथ क्वेरी
बिना ORDER BY, क्लस्टर इंडेक्स स्कैन के साथ क्वेरी
आइए अब यह देखने के लिए ORDER BY जोड़ें कि योजना कैसे बदलती है:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
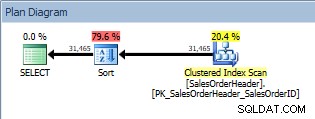 एक ORDER BY, संकुल अनुक्रमणिका स्कैन और एक प्रकार के साथ क्वेरी
एक ORDER BY, संकुल अनुक्रमणिका स्कैन और एक प्रकार के साथ क्वेरी
क्लस्टर्ड इंडेक्स स्कैन के अलावा, अब हमारे पास ऑप्टिमाइज़र द्वारा पेश किया गया एक सॉर्ट है, और इसकी अनुमानित लागत स्कैन की तुलना में काफी अधिक है। अब, अनुमानित लागत का अनुमान लगाया गया है, और हम यहां बिल्कुल निश्चितता के साथ नहीं कह सकते हैं कि सॉर्ट ने क्वेरी की लागत का 79.6% लिया। वास्तव में यह समझने के लिए कि सॉर्ट करना कितना महंगा है, हमें IO आँकड़ों को भी देखना होगा, जो आज के लक्ष्य से परे है।
अब यदि यह एक ऐसा प्रश्न था जिसे आपके परिवेश में बार-बार निष्पादित किया गया था, तो आप शायद इसका समर्थन करने के लिए एक अनुक्रमणिका जोड़ने पर विचार करेंगे। इस मामले में, कोई WHERE क्लॉज नहीं है, हम केवल चार कॉलम प्राप्त कर रहे हैं, और उनमें से एक द्वारा ऑर्डर कर रहे हैं। किसी अनुक्रमणिका पर एक तार्किक पहला प्रयास होगा:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
हम इंडेक्स को जोड़ने के बाद अपनी क्वेरी को फिर से चलाएंगे जिसमें हमारे सभी कॉलम हैं, और याद रखें कि इंडेक्स ने डेटा को सॉर्ट करने का काम किया है। अब हम अपने नए गैर-संकुल अनुक्रमणिका के विरुद्ध एक अनुक्रमणिका स्कैन देखते हैं:
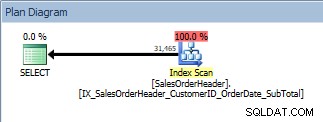 एक ORDER BY के साथ क्वेरी, नई, गैर-संकुल अनुक्रमणिका स्कैन की जाती है
एक ORDER BY के साथ क्वेरी, नई, गैर-संकुल अनुक्रमणिका स्कैन की जाती है
यह अच्छी खबर है। लेकिन क्या होता है अगर कोई उस क्वेरी को बदल देता है - या तो क्योंकि उपयोगकर्ता निर्दिष्ट कर सकते हैं कि वे कौन से कॉलम ऑर्डर करना चाहते हैं, या क्योंकि किसी डेवलपर से बदलाव का अनुरोध किया गया था? उदाहरण के लिए, शायद उपयोगकर्ता CustomerIDs और SalesOrderIDs को अवरोही क्रम में देखना चाहते हैं:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
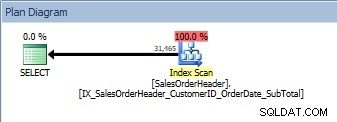 ORDER BY में दो कॉलम वाली क्वेरी, नया, गैर-क्लस्टर इंडेक्स स्कैन किया गया है
ORDER BY में दो कॉलम वाली क्वेरी, नया, गैर-क्लस्टर इंडेक्स स्कैन किया गया है
हमारी एक ही योजना है; कोई सॉर्ट ऑपरेटर नहीं जोड़ा गया था। यदि हम किम्बर्ली ट्रिप के sp_helpindex (स्थान बचाने के लिए कुछ कॉलम ढह गए) का उपयोग करके सूचकांक को देखते हैं, तो हम देख सकते हैं कि योजना क्यों नहीं बदली:
 sp_helpindex का आउटपुट
sp_helpindex का आउटपुट
अनुक्रमणिका के लिए मुख्य स्तंभ CustomerID है, लेकिन चूंकि SalesOrderID संकुल अनुक्रमणिका का मुख्य स्तंभ है, यह अनुक्रमणिका कुंजी का भी हिस्सा है, इस प्रकार डेटा को CustomerID, फिर SalesOrderID द्वारा क्रमबद्ध किया जाता है। क्वेरी ने उन दो स्तंभों द्वारा अवरोही क्रम में सॉर्ट किए गए डेटा का अनुरोध किया। सूचकांक दोनों स्तंभों के आरोही के साथ बनाया गया था, लेकिन क्योंकि यह एक डबल-लिंक्ड सूची है, इसलिए इंडेक्स को पीछे की ओर पढ़ा जा सकता है। आप इसे गैर-संकुल अनुक्रमणिका स्कैन ऑपरेटर के लिए प्रबंधन स्टूडियो में गुण फलक में देख सकते हैं:
 गैर-क्लस्टर किए गए इंडेक्स स्कैन का गुण फलक, यह दर्शाता है कि यह पीछे की ओर था
गैर-क्लस्टर किए गए इंडेक्स स्कैन का गुण फलक, यह दर्शाता है कि यह पीछे की ओर था
बढ़िया, उस प्रश्न के साथ कोई समस्या नहीं...लेकिन इसके बारे में क्या:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
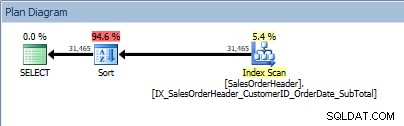 ORDER BY में दो कॉलम वाली क्वेरी, और एक सॉर्ट जोड़ा जाता है
ORDER BY में दो कॉलम वाली क्वेरी, और एक सॉर्ट जोड़ा जाता है
हमारा SORT ऑपरेटर फिर से प्रकट होता है, क्योंकि इंडेक्स से आने वाला डेटा अनुरोधित क्रम में सॉर्ट नहीं किया जाता है। यदि हम शामिल किए गए कॉलम में से किसी एक को सॉर्ट करते हैं तो हमें वही व्यवहार दिखाई देगा:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
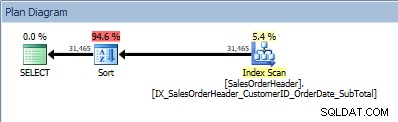 ORDER BY में दो कॉलम वाली क्वेरी, और एक सॉर्ट जोड़ा जाता है
ORDER BY में दो कॉलम वाली क्वेरी, और एक सॉर्ट जोड़ा जाता है
क्या होता है यदि हम (आखिरकार) एक विधेय जोड़ते हैं, और हमारे ORDER BY को थोड़ा बदल देते हैं?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
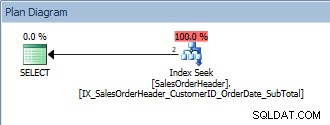 एक विधेय के साथ क्वेरी और एक ORDER BY
एक विधेय के साथ क्वेरी और एक ORDER BY
यह क्वेरी ठीक है क्योंकि फिर से, SalesOrderID अनुक्रमणिका कुंजी का भाग है। इस एक CustomerID के लिए, डेटा पहले से SalesOrderID द्वारा ऑर्डर किया गया है। क्या होगा यदि हम SalesOrderIDs द्वारा क्रमबद्ध CustomerIDs की एक श्रृंखला के लिए क्वेरी करते हैं?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
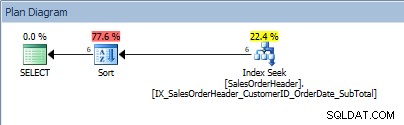 विधेय में मानों की श्रेणी के साथ क्वेरी और इसके द्वारा ऑर्डर करें
विधेय में मानों की श्रेणी के साथ क्वेरी और इसके द्वारा ऑर्डर करें
चूहों, हमारा SORT वापस आ गया है। तथ्य यह है कि ग्राहक आईडी द्वारा डेटा का आदेश दिया जाता है, केवल मूल्यों की उस श्रेणी को खोजने के लिए सूचकांक की तलाश में मदद करता है; ORDER BY SalesOrderID के लिए, ऑप्टिमाइज़र को डेटा को अनुरोधित क्रम में रखने के लिए सॉर्ट को इंटरसेप्ट करना होगा।
अब इस बिंदु पर, आप सोच रहे होंगे कि मुझे क्वेरी योजनाओं में प्रदर्शित होने वाले सॉर्ट ऑपरेटर पर क्यों फिक्स किया गया है। ऐसा इसलिए है क्योंकि यह महंगा है। यह संसाधनों (मेमोरी, आईओ) और/या अवधि के मामले में महंगा हो सकता है।
क्वेरी अवधि सॉर्ट द्वारा प्रभावित हो सकती है क्योंकि यह एक स्टॉप-एंड-गो ऑपरेशन है। योजना में अगला ऑपरेशन होने से पहले डेटा के पूरे सेट को सॉर्ट करना होगा। यदि डेटा की केवल कुछ पंक्तियों का आदेश दिया जाना है, तो यह इतनी बड़ी बात नहीं है। यदि यह हजारों या लाखों पंक्तियाँ हैं? अब हम इंतजार कर रहे हैं।
समग्र क्वेरी अवधि के अलावा, हमें संसाधन उपयोग के बारे में भी सोचना होगा। आइए उन 31,465 पंक्तियों को लें जिनके साथ हम काम कर रहे हैं और उन्हें एक तालिका चर में धकेलते हैं, फिर उस प्रारंभिक क्वेरी को ORDER BY ग्राहक आईडी पर चलाएँ:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
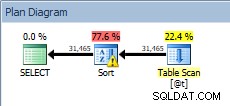 सॉर्ट के साथ टेबल वेरिएबल के खिलाफ क्वेरी
सॉर्ट के साथ टेबल वेरिएबल के खिलाफ क्वेरी
हमारा SORT वापस आ गया है, और इस बार इसमें एक चेतावनी है (विस्मयादिबोधक चिह्न के साथ पीले त्रिकोण पर ध्यान दें)। चेतावनियाँ अच्छी नहीं हैं। यदि हम इस प्रकार के गुणों को देखते हैं, तो हम चेतावनी देख सकते हैं, "ऑपरेटर ने स्पिल स्तर 1 के साथ निष्पादन के दौरान डेटा को फैलाने के लिए tempdb का उपयोग किया":
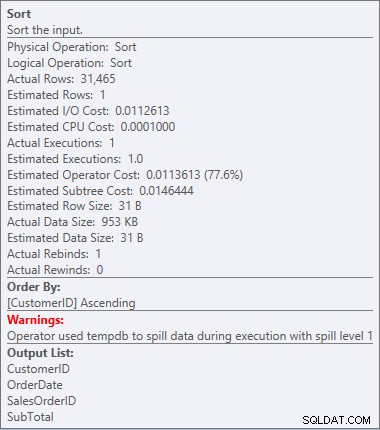 चेतावनी क्रमित करें
चेतावनी क्रमित करें
यह ऐसा कुछ नहीं है जिसे मैं किसी योजना में देखना चाहता हूं। ऑप्टिमाइज़र ने अनुमान लगाया कि डेटा को सॉर्ट करने के लिए मेमोरी में कितनी जगह की आवश्यकता होगी, और उसने उस मेमोरी का अनुरोध किया। लेकिन जब उसके पास वास्तव में सभी डेटा था और उसे सॉर्ट करने के लिए चला गया, तो इंजन को एहसास हुआ कि पर्याप्त मेमोरी नहीं थी (ऑप्टिमाइज़र ने बहुत कम मांगा!), इसलिए सॉर्ट ऑपरेशन फैल गया। कुछ मामलों में, यह डिस्क पर फैल सकता है, जिसका अर्थ है कि पढ़ना और लिखना - जो धीमा है। हम न केवल डेटा को क्रम में लाने के लिए प्रतीक्षा कर रहे हैं, यह और भी धीमा है क्योंकि हम यह सब स्मृति में नहीं कर सकते हैं। अनुकूलक ने पर्याप्त स्मृति क्यों नहीं मांगी? सॉर्ट करने के लिए आवश्यक डेटा के बारे में इसका खराब अनुमान था:
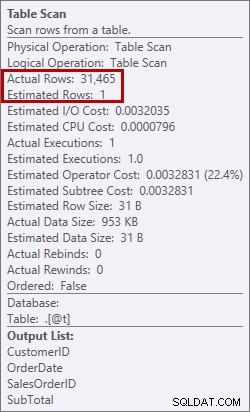 31,465 पंक्तियों के वास्तविक बनाम 1 पंक्ति का अनुमान
31,465 पंक्तियों के वास्तविक बनाम 1 पंक्ति का अनुमान
इस मामले में मैंने टेबल वैरिएबल का उपयोग करके खराब अनुमान लगाया। आंकड़ों के अनुमान और तालिका चर के साथ ज्ञात समस्याएं हैं (हारून बर्ट्रेंड के पास इसे हल करने के लिए विकल्पों पर एक बढ़िया पोस्ट है), और यहां, अनुकूलक का मानना था कि तालिका स्कैन से केवल 1 पंक्ति वापस आने वाली थी, न कि 31,465।
विकल्प
तो आप, DBA या डेवलपर के रूप में, अपनी क्वेरी योजनाओं में SORTs से बचने के लिए क्या कर सकते हैं? इसका त्वरित उत्तर है, "अपना डेटा ऑर्डर न करें।" लेकिन यह हमेशा यथार्थवादी नहीं होता है। कुछ मामलों में, आप उस सॉर्टिंग को क्लाइंट, या किसी एप्लिकेशन लेयर पर ऑफ़लोड कर सकते हैं - लेकिन उपयोगकर्ताओं को अभी भी उस पर डेटा सॉर्ट करने के लिए प्रतीक्षा करनी होगी परत। उन स्थितियों में जहां आप एप्लिकेशन के काम करने के तरीके में बदलाव नहीं कर सकते हैं, आप अपने इंडेक्स को देखकर शुरू कर सकते हैं।
यदि आप किसी ऐसे एप्लिकेशन का समर्थन करते हैं जो उपयोगकर्ताओं को तदर्थ प्रश्नों को चलाने की अनुमति देता है, या क्रम को बदलने की अनुमति देता है ताकि वे डेटा को देख सकें कि वे कैसे चाहते हैं ... आपके पास सबसे कठिन समय होगा (लेकिन यह एक खोया हुआ कारण नहीं है इसलिए अभी तक पढ़ना बंद मत करो!) आप हर विकल्प के लिए इंडेक्स नहीं कर सकते। यह अक्षम है और आप हल करने की तुलना में अधिक समस्याएं पैदा करेंगे। यहां आपका सबसे अच्छा दांव उपयोगकर्ताओं से बात करना है (मुझे पता है, कभी-कभी जंगल के अपने कोने को छोड़ना डरावना होता है, लेकिन इसे आज़माएं)। उन प्रश्नों के लिए जो उपयोगकर्ता सबसे अधिक बार चलाते हैं, पता करें कि वे आमतौर पर डेटा को कैसे देखना पसंद करते हैं। हां, आप इसे प्लान कैश से भी प्राप्त कर सकते हैं - आप प्रश्नों और योजनाओं को तब तक प्राप्त कर सकते हैं जब तक कि आपके दिल की सामग्री यह देखने के लिए न हो कि वे क्या कर रहे हैं। लेकिन उपयोगकर्ताओं से बात करना तेज़ है। अतिरिक्त लाभ यह है कि आप समझा सकते हैं कि आप क्यों पूछ रहे हैं, और यह विचार "सभी कॉलमों को क्रमबद्ध करने के लिए क्योंकि मैं कर सकता हूं" इतना अच्छा क्यों नहीं है। जानना केवल आधी लड़ाई है। यदि आप अपने बिजली उपयोगकर्ताओं और नए लोगों को प्रशिक्षित करने वाले उपयोगकर्ताओं को शिक्षित करने में कुछ समय व्यतीत कर सकते हैं, तो आप कुछ अच्छा करने में सक्षम हो सकते हैं।
यदि आप सीमित ORDER BY विकल्पों के साथ किसी एप्लिकेशन का समर्थन करते हैं, तो आप कुछ वास्तविक विश्लेषण कर सकते हैं। समीक्षा करें कि ORDER BY विविधताएं क्या मौजूद हैं, यह निर्धारित करें कि कौन से संयोजन सबसे अधिक बार निष्पादित किए जाते हैं, और उन प्रश्नों का समर्थन करने के लिए अनुक्रमणिका। आप शायद हर एक को नहीं मारेंगे, लेकिन फिर भी आप प्रभाव डाल सकते हैं। आप अपने डेवलपर से बात करके और समस्या के बारे में उन्हें शिक्षित करके और इसका समाधान कैसे करें, इसे एक कदम आगे ले जा सकते हैं।
अंत में, जब आप SORT संचालन के साथ क्वेरी प्लान देख रहे हों, तो केवल सॉर्ट को हटाने पर ध्यान केंद्रित न करें। देखें कहां योजना में क्रमबद्ध होता है। यदि यह योजना के बाईं ओर होता है, और आमतौर पर . होता है कुछ पंक्तियों में, बड़े सुधार कारक वाले अन्य क्षेत्र भी हो सकते हैं जिन पर ध्यान केंद्रित करना है। बाईं ओर का सॉर्ट वह पैटर्न है जिस पर हमने आज ध्यान केंद्रित किया है, लेकिन ORDER BY के कारण हमेशा सॉर्ट नहीं होता है। अगर आपको योजना के सबसे दूर दाईं ओर एक सॉर्ट दिखाई देता है, और योजना के उस हिस्से में बहुत सी पंक्तियाँ चलती हैं, तो आप जानते हैं कि आपको ट्यूनिंग शुरू करने के लिए एक अच्छी जगह मिल गई है।