अपने पिछले पोस्ट में, मैंने समूहबद्ध संयोजन के लिए कुछ कुशल दृष्टिकोण दिखाए। इस बार, मैं इस समस्या के कुछ अतिरिक्त पहलुओं के बारे में बात करना चाहता था जिन्हें हम FOR XML PATH के साथ आसानी से पूरा कर सकते हैं। दृष्टिकोण:सूची का आदेश देना, और डुप्लिकेट निकालना।
ऐसे कुछ तरीके हैं जिनसे मैंने देखा है कि लोग चाहते हैं कि अल्पविराम से अलग की गई सूची का आदेश दिया जाए। कभी-कभी वे चाहते हैं कि सूची में आइटम को वर्णानुक्रम में क्रमबद्ध किया जाए; मैंने पहले ही अपनी पिछली पोस्ट में दिखाया था। लेकिन कभी-कभी वे चाहते हैं कि इसे किसी अन्य विशेषता द्वारा क्रमबद्ध किया जाए जो वास्तव में आउटपुट में पेश नहीं किया जा रहा है; उदाहरण के लिए, हो सकता है कि मैं सूची को सबसे हाल के आइटम द्वारा पहले ऑर्डर करना चाहता हूं। आइए एक सरल उदाहरण लेते हैं, जहां हमारे पास एक कर्मचारी तालिका और एक कॉफी ऑर्डर तालिका है। आइए एक व्यक्ति के आदेशों को कुछ दिनों के लिए भर दें:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
यदि हम ORDER BY . निर्दिष्ट किए बिना मौजूदा दृष्टिकोण का उपयोग करते हैं , हमें एक मनमाना क्रम मिलता है (इस मामले में, यह सबसे अधिक संभावना है कि आप पंक्तियों को उनके सम्मिलित क्रम में देखेंगे, लेकिन बड़े डेटा सेट, अधिक अनुक्रमणिका आदि के साथ उस पर निर्भर नहीं हैं):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
परिणाम (याद रखें, आप *भिन्न* परिणाम प्राप्त कर सकते हैं जब तक कि आप ORDER BY निर्दिष्ट नहीं करते हैं ):
जैक | लार्ज डबल डबल, मीडियम डबल डबल, लार्ज वनीला लेटे, मीडियम डबल डबल
यदि हम सूची को वर्णानुक्रम में क्रमबद्ध करना चाहते हैं, तो यह सरल है; हम सिर्फ ORDER BY c.OrderDetails . जोड़ते हैं :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
परिणाम:
नाम | आदेशजैक | लार्ज डबल डबल, लार्ज वनीला लेटे, मीडियम डबल डबल, मीडियम डबल डबल
हम एक कॉलम द्वारा भी ऑर्डर कर सकते हैं जो परिणाम सेट में प्रकट नहीं होता है; उदाहरण के लिए, हम सबसे हाल के कॉफी ऑर्डर द्वारा पहले ऑर्डर कर सकते हैं:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
परिणाम:
नाम | आदेशजैक | मीडियम डबल डबल, लार्ज वनीला लेटे, मीडियम डबल डबल, लार्ज डबल डबल
एक और चीज जो हम अक्सर करना चाहते हैं वह है डुप्लीकेट हटाना; आखिरकार, "मध्यम डबल डबल" को दो बार देखने का कोई कारण नहीं है। हम GROUP BY . का उपयोग करके इसे समाप्त कर सकते हैं :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
अब, यह आउटपुट को वर्णानुक्रम में क्रमबद्ध करने के लिए * होता है, लेकिन फिर से आप इस पर भरोसा नहीं कर सकते:
नाम | आदेशजैक | लार्ज डबल डबल, लार्ज वनीला लेटे, मीडियम डबल डबल
अगर आप गारंटी देना चाहते हैं कि इस तरह से ऑर्डर करना, तो आप बस फिर से ORDER BY जोड़ सकते हैं:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
परिणाम समान हैं (लेकिन मैं दोहराता हूं, इस मामले में यह सिर्फ एक संयोग है; यदि आप यह आदेश चाहते हैं, तो हमेशा ऐसा कहें):
नाम | आदेशजैक | लार्ज डबल डबल, लार्ज वनीला लेटे, मीडियम डबल डबल
लेकिन क्या होगा यदि हम डुप्लीकेट *और* सूची को सबसे हाल के कॉफी ऑर्डर के अनुसार पहले खत्म करना चाहते हैं? आपका पहला झुकाव GROUP BY रखने का हो सकता है और बस ORDER BY . बदलें , इस तरह:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
OrderDate . के बाद से यह काम नहीं करेगा क्वेरी के भाग के रूप में समूहीकृत या एकत्रित नहीं किया गया है:
कॉलम "dbo.CoffeeOrders.OrderDate" ORDER BY क्लॉज में अमान्य है क्योंकि यह या तो एग्रीगेट फंक्शन या ग्रुप बाय क्लॉज में शामिल नहीं है।
एक वर्कअराउंड, जो निश्चित रूप से क्वेरी को थोड़ा बदसूरत बनाता है, पहले ऑर्डर को अलग से समूहित करना है, और फिर केवल उस कॉफी ऑर्डर के लिए प्रति कर्मचारी अधिकतम तिथि के साथ पंक्तियों को लेना है:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
परिणाम:
नाम | आदेशजैक | मीडियम डबल डबल, लार्ज वनीला लेटे, लार्ज डबल डबल
यह हमारे दोनों लक्ष्यों को पूरा करता है:हमने डुप्लीकेट को हटा दिया है, और हमने सूची को किसी ऐसी चीज़ से ऑर्डर किया है जो वास्तव में सूची में नहीं है।
प्रदर्शन
आप सोच रहे होंगे कि ये तरीके अधिक मजबूत डेटा सेट के मुकाबले कितना खराब प्रदर्शन करते हैं। मैं अपनी तालिका को 100,000 पंक्तियों के साथ पॉप्युलेट करने जा रहा हूं, देखें कि वे बिना किसी अतिरिक्त अनुक्रमणिका के कैसे करते हैं, और फिर हमारे प्रश्नों का समर्थन करने के लिए थोड़ी सी अनुक्रमणिका ट्यूनिंग के साथ फिर से वही प्रश्न चलाएं। तो सबसे पहले, 10000 कर्मचारियों में फैली 100,000 पंक्तियाँ प्राप्त करना:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; आइए अब अपने प्रत्येक प्रश्न को दो बार चलाएं, और देखें कि दूसरी कोशिश में समय कैसा है (हम यहां विश्वास की छलांग लेंगे, और मान लें कि - एक आदर्श दुनिया में - हम एक प्राइमेड कैश के साथ काम करेंगे ) मैंने इन्हें SQL सेंट्री प्लान एक्सप्लोरर में चलाया, क्योंकि यह सबसे आसान तरीका है जिसे मैं समय के बारे में जानता हूं और व्यक्तिगत प्रश्नों के एक समूह की तुलना करता हूं:
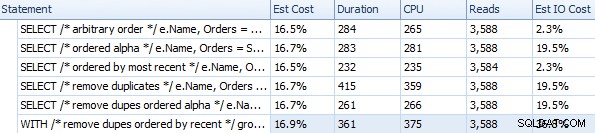 XML PATH दृष्टिकोण के लिए अलग-अलग अवधि और अन्य रनटाइम मेट्रिक्स
XML PATH दृष्टिकोण के लिए अलग-अलग अवधि और अन्य रनटाइम मेट्रिक्स
जब आप सोचते हैं कि वास्तव में यहां क्या किया जा रहा है, तो ये समय (अवधि मिलीसेकंड में है) वास्तव में सभी आईएमएचओ में उतना बुरा नहीं है। सबसे जटिल योजना, कम से कम दृष्टिगत रूप से, वह थी जहां हमने डुप्लीकेट हटा दिए और नवीनतम क्रम के अनुसार क्रमबद्ध किया:
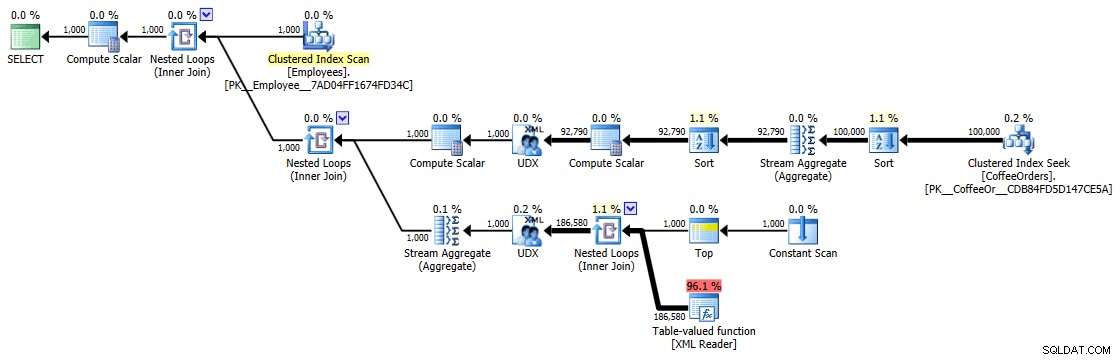 समूहीकृत और क्रमबद्ध क्वेरी के लिए निष्पादन योजना
समूहीकृत और क्रमबद्ध क्वेरी के लिए निष्पादन योजना
लेकिन यहां तक कि सबसे महंगा ऑपरेटर - एक्सएमएल टेबल-वैल्यू फ़ंक्शन - सभी सीपीयू लगता है (भले ही मैं स्वतंत्र रूप से स्वीकार करूंगा कि मुझे यकीन नहीं है कि क्वेरी प्लान विवरण में वास्तविक कार्य कितना उजागर हुआ है):
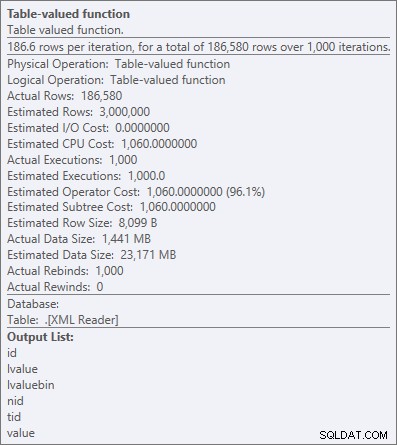 XML तालिका-मूल्यवान फ़ंक्शन के लिए ऑपरेटर गुण
XML तालिका-मूल्यवान फ़ंक्शन के लिए ऑपरेटर गुण
"सभी सीपीयू" आमतौर पर ठीक है, क्योंकि अधिकांश सिस्टम I/O-बाउंड और/या मेमोरी-बाउंड हैं, CPU-बाउंड नहीं हैं। जैसा कि मैं अक्सर कहता हूं, अधिकांश प्रणालियों में मैं सप्ताह के किसी भी दिन मेमोरी या डिस्क के लिए अपने कुछ सीपीयू हेडरूम का व्यापार करूंगा (एक कारण जो मुझे पसंद है OPTION (RECOMPILE) व्यापक पैरामीटर सूँघने के मुद्दों के समाधान के रूप में)।
उस ने कहा, मैं आपको कोडप्लेक्स पर GROUP_CONCAT CLR दृष्टिकोण से प्राप्त समान परिणामों के खिलाफ इन दृष्टिकोणों का परीक्षण करने के लिए दृढ़ता से प्रोत्साहित करता हूं, साथ ही प्रस्तुति स्तर पर एकत्रीकरण और सॉर्टिंग करता हूं (विशेष रूप से यदि आप सामान्यीकृत डेटा को किसी प्रकार में रख रहे हैं कैशिंग परत)।