पेजिनेशन हर जगह क्लाइंट और वेब एप्लिकेशन में एक सामान्य उपयोग का मामला है। Google आपको एक बार में 10 परिणाम दिखाता है, आपका ऑनलाइन बैंक प्रति पृष्ठ 20 बिल दिखा सकता है, और बग ट्रैकिंग और स्रोत नियंत्रण सॉफ़्टवेयर स्क्रीन पर 50 आइटम प्रदर्शित कर सकता है।
मैं SQL सर्वर 2012 पर सामान्य पेजिनेशन दृष्टिकोण को देखना चाहता था - OFFSET / FETCH (MySQL के प्राथमिक LIMIT क्लॉज के बराबर एक मानक) - और एक भिन्नता का सुझाव देता है जो केवल इष्टतम होने के बजाय पूरे सेट में अधिक रैखिक पेजिंग प्रदर्शन को जन्म देगा। शुरू में। जो, दुख की बात है कि बहुत सारी दुकानों का परीक्षण होगा।
SQL सर्वर में पेजिनेशन क्या है?
तालिका के अनुक्रमण के आधार पर, आवश्यक कॉलम, और चुनी गई सॉर्ट विधि, पेजिनेशन अपेक्षाकृत दर्द रहित हो सकता है। यदि आप "पहले" 20 ग्राहकों की तलाश में हैं और क्लस्टर इंडेक्स उस सॉर्टिंग का समर्थन करता है (कहें, पहचान कॉलम या डेटक्रेटेड कॉलम पर क्लस्टर इंडेक्स), तो क्वेरी अपेक्षाकृत कुशल होगी। यदि आपको सॉर्टिंग का समर्थन करने की आवश्यकता है जिसके लिए गैर-क्लस्टर इंडेक्स की आवश्यकता होती है, और विशेष रूप से यदि आपके पास आउटपुट के लिए आवश्यक कॉलम हैं जो इंडेक्स द्वारा कवर नहीं किए जाते हैं (कोई बात नहीं अगर कोई सपोर्टिंग इंडेक्स नहीं है), तो प्रश्न अधिक महंगे हो सकते हैं। और यहां तक कि एक ही क्वेरी (एक अलग @PageNumber पैरामीटर के साथ) बहुत अधिक महंगी हो सकती है क्योंकि @PageNumber अधिक हो जाता है - क्योंकि डेटा के उस "स्लाइस" को प्राप्त करने के लिए और अधिक पढ़ने की आवश्यकता हो सकती है।
कुछ लोग कहेंगे कि सेट के अंत की ओर बढ़ना कुछ ऐसा है जिसे आप समस्या पर अधिक मेमोरी फेंक कर हल कर सकते हैं (ताकि आप किसी भी भौतिक I/O को समाप्त कर दें) और/या एप्लिकेशन-स्तरीय कैशिंग का उपयोग करें (इसलिए आप नहीं जा रहे हैं डेटाबेस बिल्कुल)। आइए इस पोस्ट के प्रयोजनों के लिए मान लें कि अधिक मेमोरी हमेशा संभव नहीं होती है, क्योंकि प्रत्येक ग्राहक ऐसे सर्वर में रैम नहीं जोड़ सकता है जो मेमोरी स्लॉट से बाहर है या उनके नियंत्रण में नहीं है, या बस अपनी उंगलियों को स्नैप करें और नए, बड़े सर्वर तैयार करें चल देना। विशेष रूप से चूंकि कुछ ग्राहक मानक संस्करण पर हैं, इसलिए 64GB (एसक्यूएल सर्वर 2012) या 128 जीबी (एसक्यूएल सर्वर 2014) पर छाया हुआ है, या एक्सप्रेस (1 जीबी) या कई क्लाउड पेशकशों में से एक जैसे अधिक सीमित संस्करणों का उपयोग कर रहे हैं।
इसलिए मैं SQL सर्वर 2012 - OFFSET / FETCH - पर सामान्य पेजिंग दृष्टिकोण को देखना चाहता था और एक भिन्नता का सुझाव देना चाहता था जो शुरुआत में केवल इष्टतम होने के बजाय पूरे सेट में अधिक रैखिक पेजिंग प्रदर्शन की ओर ले जाएगा। जो, दुख की बात है कि बहुत सारी दुकानों का परीक्षण होगा।
पेजिनेशन डेटा सेटअप / उदाहरण
मैं एक और पोस्ट से उधार लेने जा रहा हूं, बुरी आदतें:कुंजी चुनते समय केवल डिस्क स्थान पर ध्यान केंद्रित करना, जहां मैंने निम्न तालिका को यादृच्छिक-ईश (लेकिन पूरी तरह यथार्थवादी नहीं) ग्राहक डेटा की 1,000,000 पंक्तियों के साथ पॉप्युलेट किया:
टेबल बनाएं [डीबीओ]। न्यूल, [ईमेल] [नवरचर] (320) न्यूल नहीं, [सक्रिय] [बिट] न्यूल डिफॉल्ट नहीं ((1)), [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट (sysdatetime ()), [अपडेट किया गया] [डेटाटाइम] NULL, CONSTRAINT [C_PK_Customers_I] प्राथमिक कुंजी क्लस्टर ([CustomerID] ASC)); गैर-अनुक्रमित सूचकांक [C_Active_Customers_I] को [dbo] पर बनाएं। सक्रिय] =1);अद्वितीय गैर-अनुक्रमित सूचकांक [C_Email_Customers_I] को [dbo] पर बनाएं। ] एएससी) शामिल करें ([ईमेल]);जाओ
चूंकि मुझे पता था कि मैं यहां I/O का परीक्षण कर रहा हूं, और गर्म और ठंडे कैश दोनों से परीक्षण करूंगा, इसलिए मैंने विखंडन को कम करने के लिए सभी इंडेक्स को पुनर्निर्माण करके परीक्षण को कम से कम थोड़ा और निष्पक्ष बना दिया (जैसा कि कम किया जाएगा) विघटनकारी, लेकिन नियमित रूप से, अधिकांश व्यस्त प्रणालियों पर जो किसी भी प्रकार के अनुक्रमणिका रखरखाव कर रहे हैं):
ALTER INDEX ALL ON dbo.Customers_I रीबिल्ड विद (ऑनलाइन =ऑन);
पुनर्निर्माण के बाद, सभी इंडेक्स (इंडेक्स लेवल =0) के लिए फ़्रेग्मेंटेशन अब 0.05% - 0.17% पर आता है, पेज 99% से अधिक भरे हुए हैं, और इंडेक्स के लिए पंक्ति गणना / पृष्ठ गणना इस प्रकार है:
| सूचकांक | पृष्ठ गणना | पंक्ति गणना |
|---|---|---|
| C_PK_Customers_I (संकुल अनुक्रमणिका) | 19,210 | 1,000,000 |
| C_Email_Customers_I | 7,344 | 1,000,000 |
| C_Active_Customers_I (फ़िल्टर की गई अनुक्रमणिका) | 13,648 | 815,235 |
| C_Name_Customers_I | 16,824 | 1,000,000 |
इंडेक्स, पेज काउंट, रो काउंट्स
यह स्पष्ट रूप से एक सुपर-वाइड टेबल नहीं है, और मैंने इस बार तस्वीर से संपीड़न छोड़ दिया है। शायद मैं भविष्य के परीक्षण में और अधिक कॉन्फ़िगरेशन का पता लगाऊंगा।
SQL क्वेरी को प्रभावी ढंग से कैसे पेजेट करें
पेजिनेशन की अवधारणा - उपयोगकर्ता को एक समय में केवल पंक्तियों को दिखाना - व्याख्या करने की तुलना में कल्पना करना आसान है। एक भौतिक पुस्तक के सूचकांक के बारे में सोचें, जिसमें पुस्तक के भीतर बिंदुओं के संदर्भ के कई पृष्ठ हो सकते हैं, लेकिन वर्णानुक्रम में व्यवस्थित हो सकते हैं। सरलता के लिए, मान लें कि सूचकांक के प्रत्येक पृष्ठ पर दस आइटम फिट होते हैं। यह ऐसा दिखाई दे सकता है:
अब, अगर मैंने पहले ही इंडेक्स के पेज 1 और 2 को पढ़ लिया है, तो मुझे पता है कि पेज 3 पर जाने के लिए, मुझे 2 पेज को छोड़ना होगा। लेकिन चूंकि मुझे पता है कि प्रत्येक पृष्ठ पर 10 आइटम हैं, इसलिए मैं इसे 2 x 10 आइटम छोड़ने और 21वें आइटम से शुरू करने के बारे में भी सोच सकता हूं। या, इसे दूसरे तरीके से रखने के लिए, मुझे पहले (10*(3-1)) आइटम को छोड़ना होगा। इसे और अधिक सामान्य बनाने के लिए, मैं कह सकता हूं कि पेज n पर शुरू करने के लिए, मुझे पहले (10 * (n-1)) आइटम को छोड़ना होगा। पहले पृष्ठ पर जाने के लिए, मैं आइटम 1 पर समाप्त करने के लिए 10*(1-1) आइटम छोड़ता हूं। दूसरे पृष्ठ पर जाने के लिए, मैं आइटम 11 पर समाप्त होने के लिए 10*(2-1) आइटम छोड़ता हूं। और इसलिए चालू।
उस जानकारी के साथ, उपयोगकर्ता इस तरह एक पेजिंग क्वेरी तैयार करेंगे, यह देखते हुए कि SQL Server 2012 में जोड़े गए OFFSET / FETCH क्लॉज विशेष रूप से कई पंक्तियों को छोड़ने के लिए डिज़ाइन किए गए थे:
चुनें [a_bunch_of_columns] dbo से।जैसा कि मैंने ऊपर उल्लेख किया है, यह ठीक काम करता है यदि कोई अनुक्रमणिका है जो ORDER BY का समर्थन करती है और जो SELECT क्लॉज में सभी कॉलम को कवर करती है (और, अधिक जटिल प्रश्नों के लिए, WHERE और JOIN क्लॉज)। हालांकि, बिना किसी सपोर्टिंग इंडेक्स के सॉर्ट की लागत भारी हो सकती है, और यदि आउटपुट कॉलम कवर नहीं किए गए हैं, तो आप या तो कुंजी लुकअप के पूरे समूह के साथ समाप्त हो जाएंगे, या आपको कुछ परिदृश्यों में टेबल स्कैन भी मिल सकता है।
एसक्यूएल पेजिनेशन सर्वोत्तम प्रथाओं को क्रमबद्ध करना
ऊपर दी गई तालिका और अनुक्रमणिका को देखते हुए, मैं इन परिदृश्यों का परीक्षण करना चाहता था, जहाँ हम प्रति पृष्ठ 100 पंक्तियाँ दिखाना चाहते हैं, और तालिका के सभी स्तंभों को आउटपुट करना चाहते हैं:
- डिफ़ॉल्ट -
ORDER BY CustomerID(संकुल सूचकांक)। यह डेटाबेस के लोगों के लिए सबसे सुविधाजनक ऑर्डरिंग है, क्योंकि इसके लिए किसी अतिरिक्त सॉर्टिंग की आवश्यकता नहीं है, और इस तालिका के सभी डेटा जो संभवतः प्रदर्शन के लिए आवश्यक हो सकते हैं, शामिल हैं। दूसरी ओर, यदि आप तालिका का सबसेट प्रदर्शित कर रहे हैं तो यह उपयोग करने के लिए सबसे कुशल अनुक्रमणिका नहीं हो सकता है। यह आदेश अंतिम उपयोगकर्ताओं के लिए भी मायने नहीं रखता है, खासकर यदि CustomerID एक सरोगेट पहचानकर्ता है जिसका कोई बाहरी अर्थ नहीं है।- फ़ोन बुक -
ORDER BY LastName, FirstName(गैर-संकुल सूचकांक का समर्थन)। यह उपयोगकर्ताओं के लिए सबसे सहज क्रम है, लेकिन छँटाई और कवरेज दोनों का समर्थन करने के लिए एक गैर-संकुल सूचकांक की आवश्यकता होगी। सपोर्टिंग इंडेक्स के बिना, पूरी टेबल को स्कैन करना होगा।- उपयोगकर्ता द्वारा परिभाषित -
ORDER BY FirstName DESC, EMail(कोई सहायक सूचकांक नहीं)। यह उपयोगकर्ता के लिए किसी भी सॉर्टिंग ऑर्डर को चुनने की क्षमता का प्रतिनिधित्व करता है, एक पैटर्न माइकल जे। स्वार्ट ने "यूआई डिज़ाइन पैटर्न जो स्केल नहीं करते" में चेतावनी दी है।मैं इन विधियों का परीक्षण करना चाहता था और योजनाओं और मेट्रिक्स की तुलना करना चाहता था - जब - गर्म कैश और कोल्ड कैश परिदृश्य दोनों के तहत - पृष्ठ 1, पृष्ठ 500, पृष्ठ 5,000 और पृष्ठ 9,999 को देखते हुए। मैंने इन प्रक्रियाओं को बनाया है (केवल ORDER BY क्लॉज द्वारा भिन्न):
CREATE PROCEDURE dbo.Pagination_Test_1 -- CustomerID द्वारा ऑर्डर @PageNumber INT =1, @PageSize INT =100ASBEGIN SET NOCOUNT ON; ग्राहक आईडी, प्रथम नाम, अंतिम नाम, ईमेल, सक्रिय, बनाया गया, डीबीओ से अपडेट किया गया। - अंतिम नाम द्वारा आदेश, प्रथम नामप्रक्रिया बनाएं dbo.Pagination_Test_3 -- प्रथम नाम DESC, ईमेल द्वारा आदेशवास्तव में, आपके पास शायद केवल एक प्रक्रिया होगी जो या तो डायनेमिक SQL (जैसे मेरे "किचन सिंक" उदाहरण में) का उपयोग करती है या ऑर्डर को निर्देशित करने के लिए CASE एक्सप्रेशन का उपयोग करती है।
किसी भी मामले में, आप उन योजनाओं के पुन:उपयोग से बचने के लिए क्वेरी पर विकल्प (RECOMPILE) का उपयोग करके सर्वोत्तम परिणाम देख सकते हैं जो एक सॉर्टिंग विकल्प के लिए इष्टतम हैं लेकिन सभी नहीं। मैंने उन चरों को दूर करने के लिए यहां अलग प्रक्रियाएं बनाईं; मैंने पूरे प्लान कैश को बार-बार फ्लश किए बिना पैरामीटर सूँघने और अन्य अनुकूलन मुद्दों से दूर रहने के लिए इन परीक्षणों के लिए OPTION (RECOMPILE) जोड़ा।
बेहतर प्रदर्शन के लिए SQL सर्वर पेजिनेशन के लिए एक वैकल्पिक दृष्टिकोण
थोड़ा अलग दृष्टिकोण, जिसे मैं अक्सर लागू नहीं देखता, वह है "पृष्ठ" का पता लगाना, जिस पर हम केवल क्लस्टरिंग कुंजी का उपयोग कर रहे हैं, और फिर उसमें शामिल हों:
;पीजी एएस के साथ (चुनें [key_column] dbo से। [some_table] [some_column_or_columns] द्वारा ऑर्डर करें। [some_table] एएस टी इनर जॉइन पीजी ऑन टी। [की_कॉलम] =पीजी।यह निश्चित रूप से अधिक वर्बोज़ कोड है, लेकिन उम्मीद है कि यह स्पष्ट है कि SQL सर्वर को क्या करने के लिए मजबूर किया जा सकता है:एक स्कैन से बचना, या कम से कम लुकअप को तब तक टालना जब तक कि बहुत छोटे परिणाम को कम न कर दिया जाए। पॉल व्हाइट (@SQL_Kiwi) ने 2010 में इसी तरह के दृष्टिकोण की जांच की, इससे पहले कि OFFSET/FETCH को प्रारंभिक SQL Server 2012 बीटा में पेश किया गया था (मैंने उस वर्ष बाद में इसके बारे में पहली बार ब्लॉग किया था)।
ऊपर दिए गए परिदृश्यों को देखते हुए, मैंने तीन और प्रक्रियाएं बनाईं, ORDER BY क्लॉज में निर्दिष्ट कॉलम के बीच एकमात्र अंतर के साथ (अब हमें दो की जरूरत है, एक पेज के लिए, और एक परिणाम ऑर्डर करने के लिए):
CREATE PROCEDURE dbo.Alternate_Test_1 -- CustomerID द्वारा ऑर्डर @PageNumber INT =1, @PageSize INT =100ASBEGIN SET NOCOUNT ON;;पीजी एएस के साथ (dbo.Customers_I से ग्राहक आईडी का चयन करें। .सक्रिय, c.बनाया गया, c. dbo से अपडेट किया गया। Customers_I जहां मौजूद है (जहां pg से 1 चुनें। अंतिम नाम द्वारा आदेश, प्रथम नामप्रक्रिया बनाएं dbo.Alternate_Test_3 -- प्रथम नाम DESC, ईमेल द्वारा आदेशध्यान दें:यदि आपकी प्राथमिक कुंजी को क्लस्टर नहीं किया गया है तो यह इतनी अच्छी तरह से काम नहीं कर सकता है - चाल का एक हिस्सा जो इस काम को बेहतर बनाता है, जब एक सहायक सूचकांक का उपयोग किया जा सकता है, यह है कि क्लस्टरिंग कुंजी पहले से ही इंडेक्स में है, इसलिए ए देखने से अक्सर बचा जाता है।
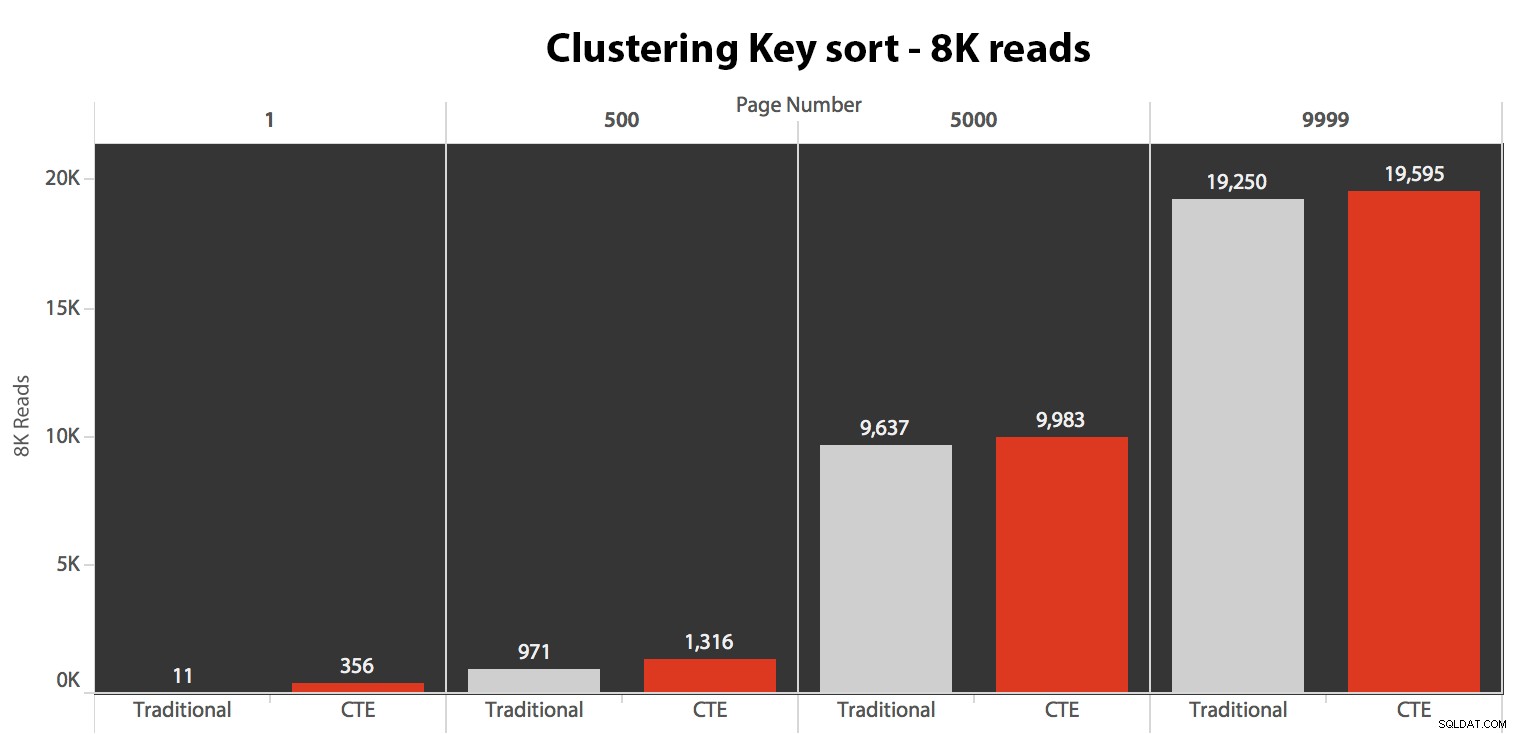
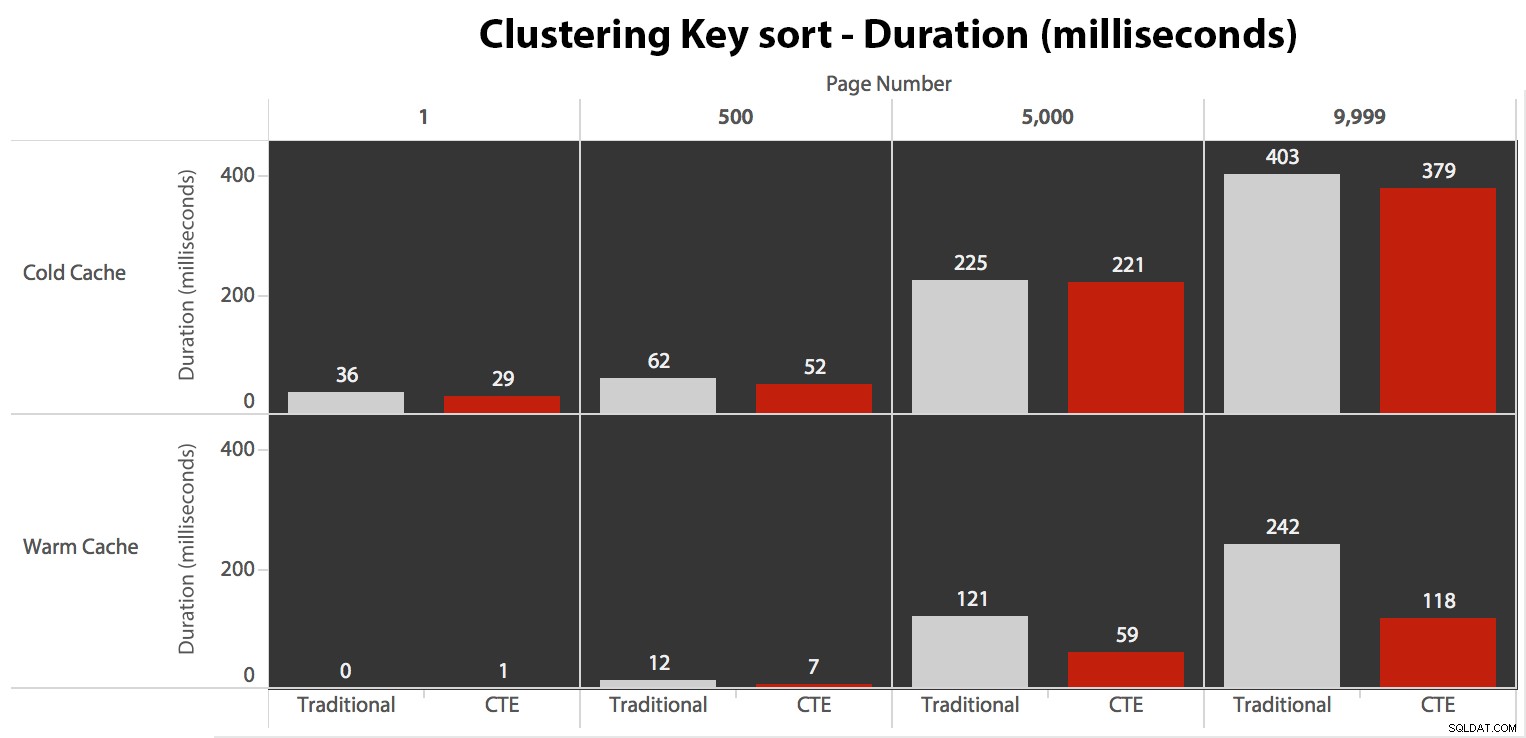
क्लस्टरिंग कुंजी सॉर्ट का परीक्षण करना
पहले मैंने उस मामले का परीक्षण किया जहां मुझे दो विधियों के बीच बहुत अधिक भिन्नता की उम्मीद नहीं थी - क्लस्टरिंग कुंजी द्वारा क्रमबद्ध करना। मैंने इन कथनों को SQL संतरी योजना एक्सप्लोरर में एक बैच में चलाया और यह सुनिश्चित करते हुए कि प्रत्येक क्वेरी पूरी तरह से ठंडे कैश से शुरू हो रही थी, अवधि, रीडिंग और ग्राफिकल योजनाओं का अवलोकन किया:
सेट नोकाउंट ऑन;-- डिफॉल्ट मेथडDBCC DROPCLEANBUFFERS;EXEC dbo.Pagination_Test_1 @PageNumber =1;DBCC DROPCLEANBUFFERS;EXEC dbo.Pagination_Test_1 @PageNumber =500;DBCC DROPCLEANBUFFERS; dbo.Pagination_Test_1 @PageNumber =9999; -- वैकल्पिक विधिDBCC DROPCLEANBUFFERS;EXEC dbo.Alternate_Test_1 @PageNumber =1;DBCC DROPCLEANBUFFERS;EXEC dbo.Alternate_Test_1 @PageNumber =500;DBCC DROPCLEANBUFFERS;EXEC dbo.Alternate_Test_1 @PageNumber =1;;यहां परिणाम आश्चर्यजनक नहीं थे। क्लस्टरिंग कुंजी के आधार पर क्रमबद्ध करते समय, 5 से अधिक निष्पादनों की औसत संख्या यहां दिखाई गई है, जो सभी पृष्ठ संख्याओं में दो प्रश्नों के बीच नगण्य अंतर दिखाती है:
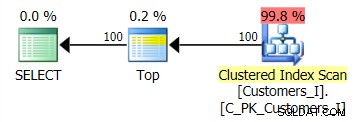
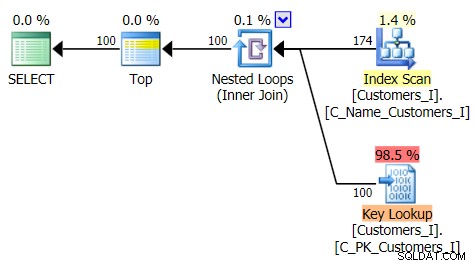
सभी मामलों में डिफ़ॉल्ट विधि की योजना (जैसा कि प्लान एक्सप्लोरर में दिखाया गया है) इस प्रकार थी:
जबकि सीटीई-आधारित पद्धति की योजना इस तरह दिखती थी:
अब, जबकि I/O कैशिंग की परवाह किए बिना समान था (कोल्ड कैश परिदृश्य में बस बहुत अधिक रीड-फ़ॉरवर्ड पढ़ता है), मैंने अवधि को कोल्ड कैश के साथ और गर्म कैश के साथ भी मापा (जहां मैंने DROPCLEANBUFFERS कमांड पर टिप्पणी की) और मापने से पहले प्रश्नों को कई बार चलाया)। ये अवधियाँ इस तरह दिखती थीं:
जब आप एक पैटर्न देख सकते हैं जो पृष्ठ संख्या के बढ़ने के साथ-साथ अवधि को बढ़ाता हुआ दिखाता है, तो पैमाने को ध्यान में रखें:999,801 -> 999,900 पंक्तियों को हिट करने के लिए, हम सबसे खराब स्थिति में आधा सेकंड और सबसे अच्छे मामले में 118 मिलीसेकंड की बात कर रहे हैं। सीटीई दृष्टिकोण जीतता है, लेकिन पूरी तरह से नहीं।
फ़ोन बुक सॉर्ट का परीक्षण करना
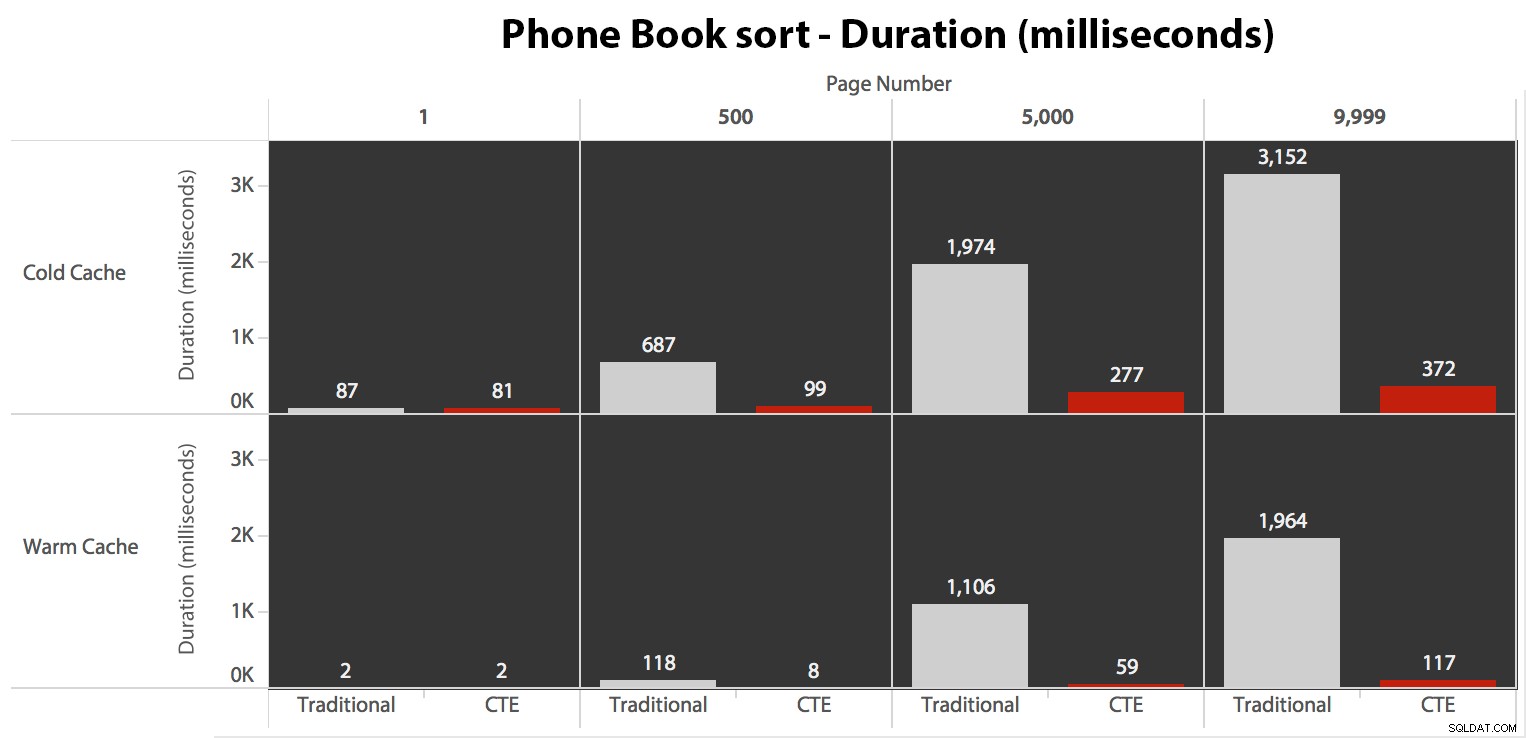
इसके बाद, मैंने दूसरे मामले का परीक्षण किया, जहां सॉर्टिंग को LastName, FirstName पर एक गैर-कवरिंग इंडेक्स द्वारा समर्थित किया गया था। ऊपर दी गई क्वेरी ने
Test_1. के सभी उदाहरणों को बदल दिया है करने के लिएTest_2. यहाँ एक कोल्ड कैश का उपयोग करके पढ़ा गया था:
(वार्म कैश के तहत रीडिंग एक ही पैटर्न का अनुसरण करती है - वास्तविक संख्या थोड़ी भिन्न होती है, लेकिन एक अलग चार्ट को सही ठहराने के लिए पर्याप्त नहीं है।)
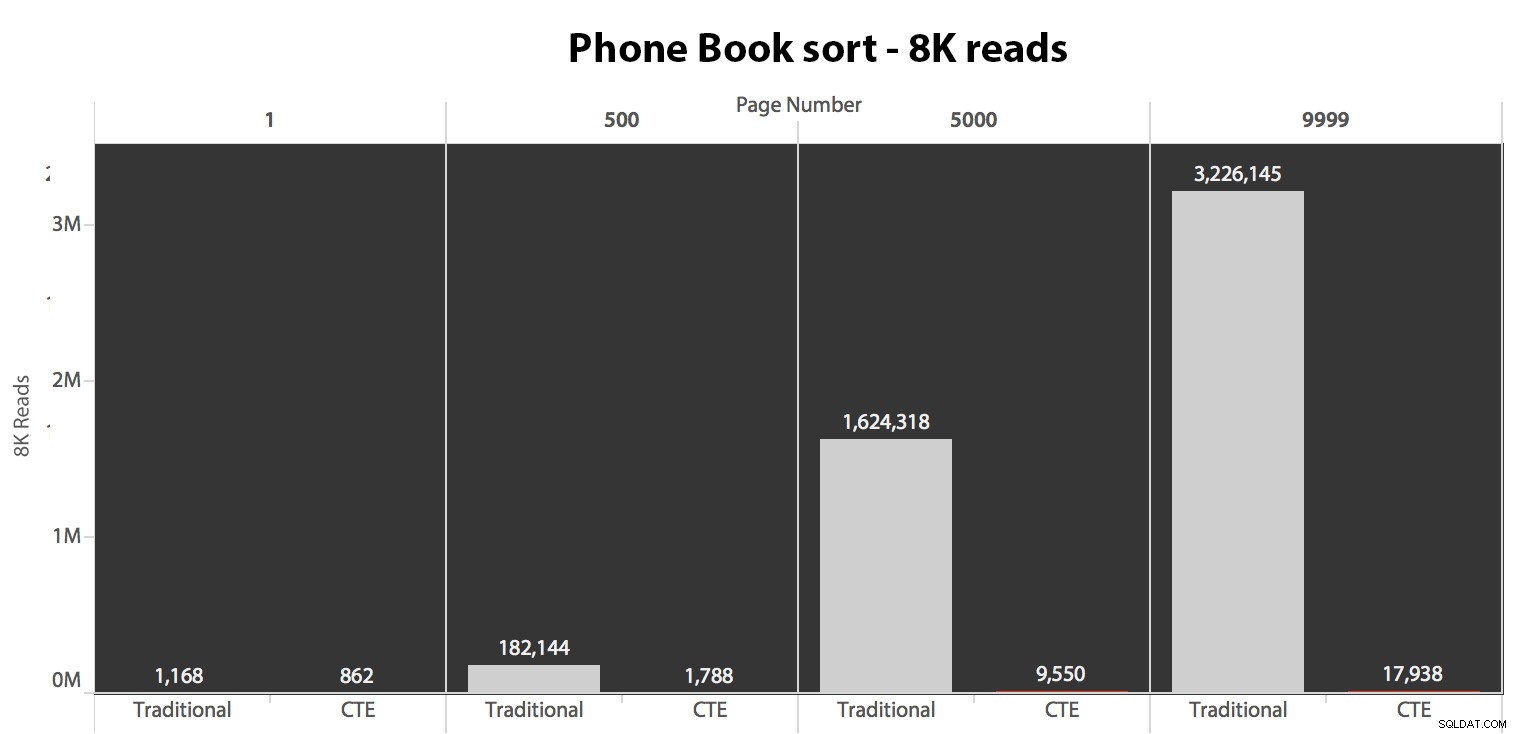
जब हम सॉर्ट करने के लिए क्लस्टर्ड इंडेक्स का उपयोग नहीं कर रहे हैं, तो यह स्पष्ट है कि OFFSET/FETCH की पारंपरिक पद्धति में शामिल I/O लागत CTE में पहले कुंजियों की पहचान करने और बाकी कॉलमों को खींचने की तुलना में कहीं अधिक खराब है। सिर्फ उस सबसेट के लिए।
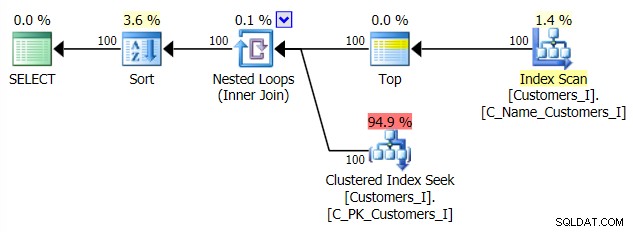
यहाँ पारंपरिक क्वेरी दृष्टिकोण की योजना है:
और मेरे वैकल्पिक, सीटीई दृष्टिकोण की योजना:
अंत में, अवधि:
जब आप पेजिनेशन के अंत की ओर बढ़ते हैं तो पारंपरिक दृष्टिकोण अवधि में एक बहुत ही स्पष्ट उतार-चढ़ाव दिखाता है। सीटीई दृष्टिकोण एक गैर-रेखीय पैटर्न भी दिखाता है, लेकिन यह बहुत कम स्पष्ट है और प्रत्येक पृष्ठ संख्या पर बेहतर समय देता है। हम दूसरे से अंतिम पृष्ठ के लिए 117 मिलीसेकंड देखते हैं, जबकि पारंपरिक दृष्टिकोण लगभग दो सेकंड में आता है।
उपयोगकर्ता द्वारा परिभाषित सॉर्ट का परीक्षण करना
अंत में, मैंने
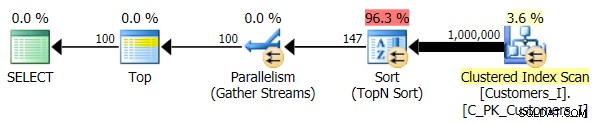
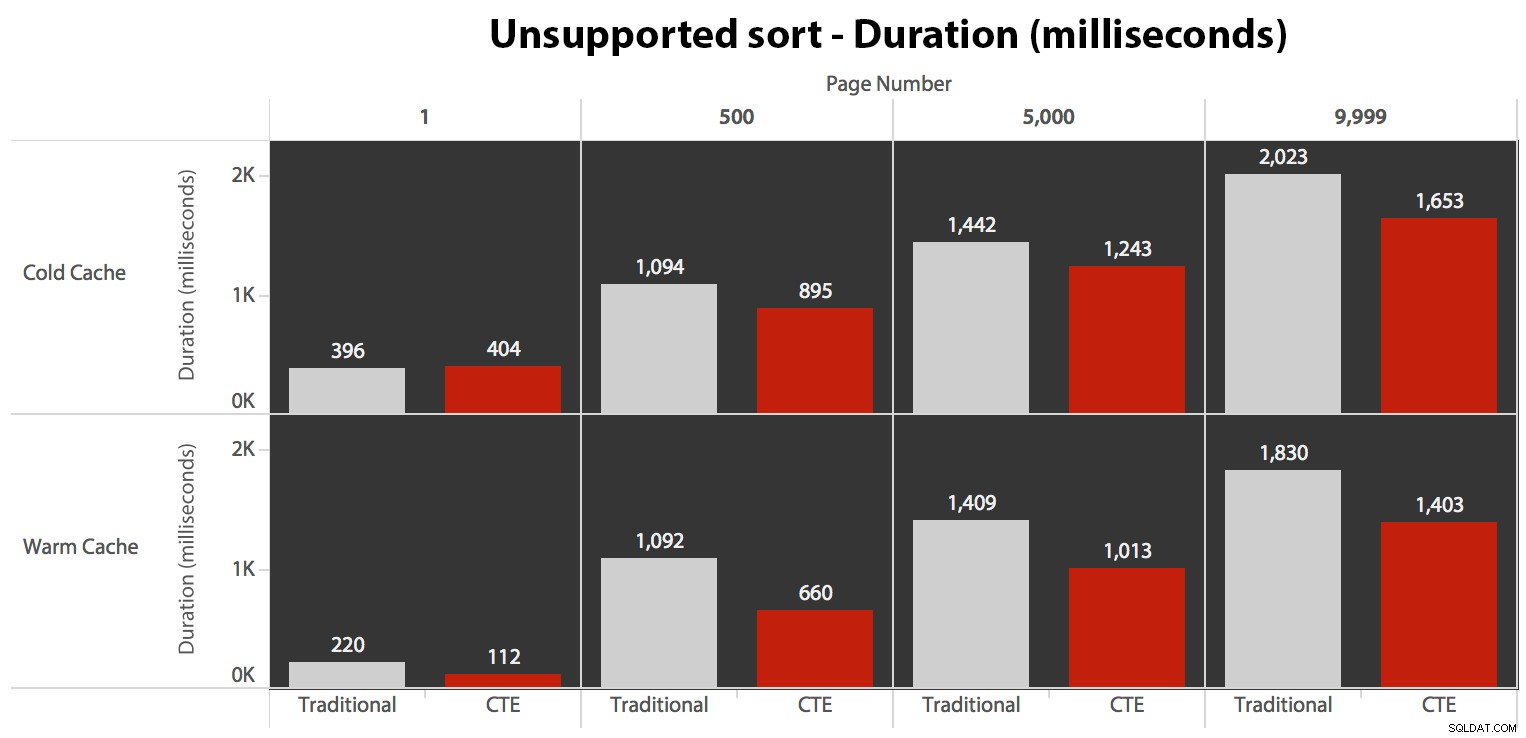
Test_3. का उपयोग करने के लिए क्वेरी को बदल दिया संग्रहीत कार्यविधियाँ, उस मामले का परीक्षण करना जहाँ उपयोगकर्ता द्वारा सॉर्ट को परिभाषित किया गया था और उसके पास एक सहायक सूचकांक नहीं था। परीक्षण के प्रत्येक सेट में I/O सुसंगत था; ग्राफ़ इतना दिलचस्प नहीं है, मैं बस उससे लिंक करने जा रहा हूँ। लंबी कहानी छोटी:सभी परीक्षणों में 19,000 से अधिक पढ़े गए थे। इसका कारण यह है कि आदेश का समर्थन करने के लिए एक सूचकांक की कमी के कारण हर एक भिन्नता को पूर्ण स्कैन करना पड़ा। यहाँ पारंपरिक दृष्टिकोण की योजना है:
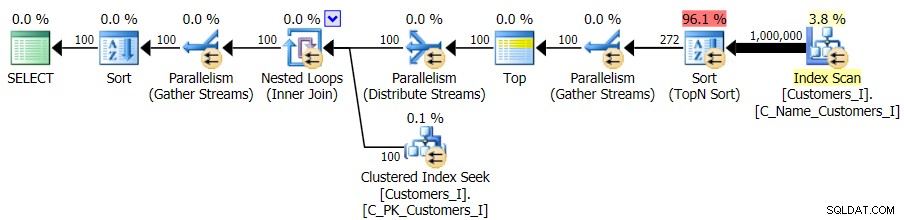
और जबकि क्वेरी के CTE संस्करण की योजना खतरनाक रूप से अधिक जटिल दिखती है…
...यह एक मामले को छोड़कर सभी में कम अवधि की ओर जाता है। ये अवधियां हैं:
आप देख सकते हैं कि हम यहां किसी भी विधि का उपयोग करके रैखिक प्रदर्शन नहीं प्राप्त कर सकते हैं, लेकिन सीटीई पहले के खिलाफ कोल्ड कैश क्वेरी को छोड़कर हर एक मामले में एक अच्छे मार्जिन (कहीं भी 16% से 65% बेहतर) से शीर्ष पर आता है। पृष्ठ (जहां यह 8 मिलीसेकंड तक खो गया)। यह भी ध्यान रखना दिलचस्प है कि पारंपरिक विधि "मध्य" (पृष्ठ 500 और 5000) में गर्म कैश द्वारा बिल्कुल भी मदद नहीं करती है; केवल सेट के अंत की ओर ध्यान देने योग्य कोई दक्षता है।
अधिक मात्रा
कुछ निष्पादन और औसत लेने के व्यक्तिगत परीक्षण के बाद, मैंने सोचा कि लेनदेन की उच्च मात्रा का परीक्षण करना भी समझ में आता है जो कुछ हद तक व्यस्त सिस्टम पर वास्तविक यातायात का अनुकरण करेगा। इसलिए मैंने ऊपर दिए गए चार पेज नंबरों को हिट करने के 100-चरण अनुक्रम के साथ, क्वेरी विधि (पारंपरिक पेजिंग बनाम सीटीई) और सॉर्ट प्रकार (क्लस्टरिंग कुंजी, फोन बुक, और असमर्थित) के प्रत्येक संयोजन के लिए 6 चरणों के साथ एक नौकरी बनाई। , 10 गुना प्रत्येक, और 60 अन्य पृष्ठ संख्या यादृच्छिक रूप से चुनी गई (लेकिन प्रत्येक चरण के लिए समान)। यहां बताया गया है कि मैंने जॉब क्रिएशन स्क्रिप्ट कैसे तैयार की:
सेट पर NOCOUNT ON;DECLARE @sql NVARCHAR(MAX), @job SYSNAME =N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);; t10 AS के साथ (मास्टर.dbo.spt_values से टॉप (10) नंबर चुनें), f AS (सेलेक्ट f से (VALUES(1),(500),(5000),(9999)) AS f(f)) सेलेक्ट करें @sql =STUFF ((चुनें CHAR(13) + CHAR(10) + N'EXEC dbo.$p$_Test_$v$ @PageNumber ='+ RTRIM(f) +';' से ( से चुनें ( f.f चुनें) t10 क्रॉस जॉइन f यूनियन से सभी चुनें टॉप (60) f =ABS (CHECKSUM (NEWID ())) % 10000 sys.all_objects से) AS x) AS y ऑर्डर बाय NEWID() फॉर एक्सएमएल पाथ (''), टाइप) .value(N'.[1]','nvarchar(max)'),1,0,''); अगर मौजूद है (msdb.dbo.sysjobs से चुनें जहां नाम =@job)BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@job;END EXEC msdb.dbo.sp_add_job @job_name =@job, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobserver @job_name =@job, @server_name =N'(local)'; DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT स्टेप =p.p + '_' + v.v, कमांड =REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v) FROM (से चुनें) VALUES('1'),('2'),('3')) AS v(v)) AS v CROSS JOIN (सेलेक्ट p फ्रॉम (VALUES('Alternate'),('Pagination')) AS p( पी)) पीपी, वी.वी द्वारा आदेश के अनुसार; खुला सी; FETCH c INTO @step, @command; जबकि @@FETCH_STATUS <> -1BEGIN EXEC msdb.dbo.sp_add_jobstep @job_name =@job, @step_name =@step, @command =@command, @database_name =N'IDs', @on_success_action =3; FETCH c INTO @step, @command;END EXEC msdb.dbo.sp_update_jobstep @job_name =@job, @step_id =6, @on_success_action =1; -- सफलता के साथ छोड़ें प्रिंट N'EXEC msdb.dbo.sp_start_job @job_name =''' + @job + ''';';यहां परिणामी कार्य चरण सूची और चरण के गुणों में से एक है:
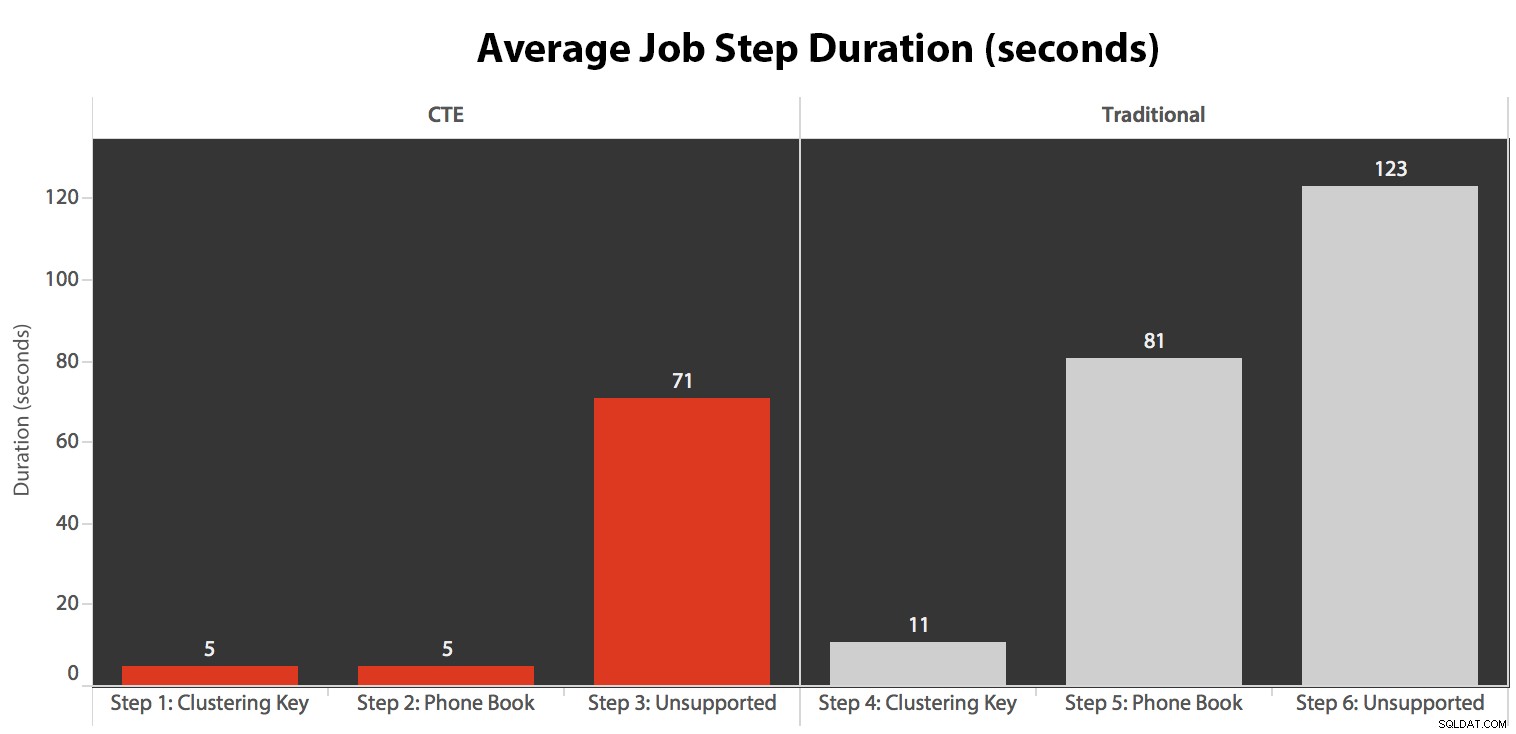
मैंने पांच बार काम चलाया, फिर नौकरी के इतिहास की समीक्षा की, और यहां प्रत्येक चरण के औसत रनटाइम थे:
मैंने SQL संतरी इवेंट मैनेजर कैलेंडर पर निष्पादनों में से एक को भी सहसंबद्ध किया…
... SQL संतरी डैशबोर्ड के साथ, और मैन्युअल रूप से मोटे तौर पर चिह्नित किया गया जहां छह चरणों में से प्रत्येक चलता था। यहाँ डैशबोर्ड के विंडोज़ साइड से CPU उपयोग चार्ट दिया गया है:
और डैशबोर्ड के SQL सर्वर की ओर से, दिलचस्प मीट्रिक कुंजी लुकअप और प्रतीक्षा ग्राफ़ में थे:
विशुद्ध रूप से दृश्य दृष्टिकोण से सबसे दिलचस्प अवलोकन:
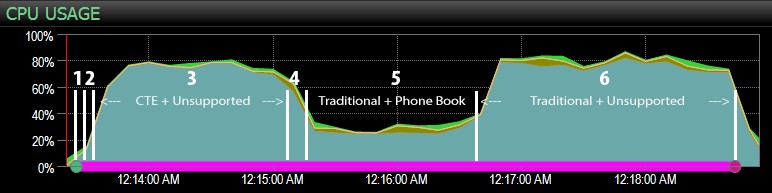
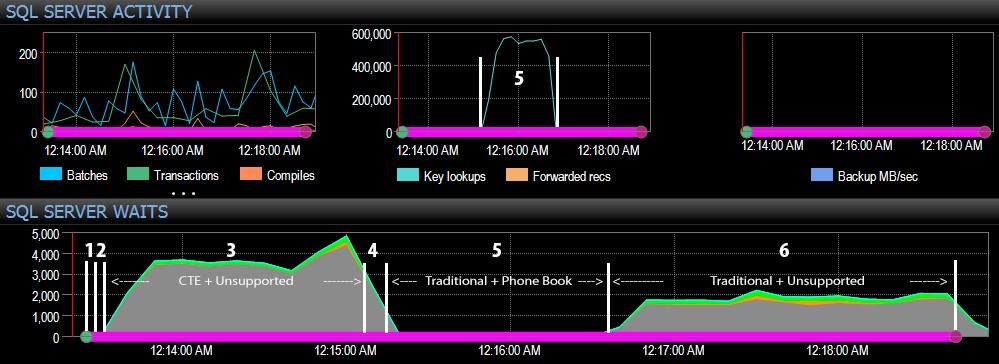
- चरण 3 (CTE + नो सपोर्टिंग इंडेक्स) और स्टेप 6 (पारंपरिक + नो सपोर्टिंग इंडेक्स) के दौरान लगभग 80% पर CPU बहुत गर्म होता है;
- सीएक्सपैकेट प्रतीक्षा चरण 3 के दौरान अपेक्षाकृत अधिक है और चरण 6 के दौरान कुछ हद तक;
- आप लगभग एक मिनट के अंतराल में मुख्य लुकअप में लगभग 600,000 तक की भारी छलांग देख सकते हैं (चरण 5 से संबंधित - फोन बुक-स्टाइल इंडेक्स के साथ पारंपरिक दृष्टिकोण)।
भविष्य के परीक्षण में - जैसा कि GUID पर मेरी पिछली पोस्ट के साथ है - मैं इसे ऐसे सिस्टम पर परीक्षण करना चाहता हूं जहां डेटा मेमोरी (अनुकरण करने में आसान) में फिट नहीं होता है और जहां डिस्क धीमी होती है (अनुकरण करना इतना आसान नहीं है) , चूंकि इनमें से कुछ परिणाम शायद उन चीजों से लाभान्वित होते हैं जो हर उत्पादन प्रणाली में नहीं होती हैं - तेज डिस्क और पर्याप्त रैम। मुझे अधिक विविधताओं को शामिल करने के लिए परीक्षणों का विस्तार करना चाहिए (पतला और चौड़ा कॉलम, पतला और चौड़ा इंडेक्स का उपयोग करके, एक फोन बुक इंडेक्स जो वास्तव में सभी आउटपुट कॉलम को कवर करता है, और दोनों दिशाओं में सॉर्टिंग करता है)। स्कोप क्रीप ने निश्चित रूप से परीक्षणों के इस पहले सेट के लिए मेरे परीक्षण की सीमा को सीमित कर दिया।
SQL सर्वर पेजिनेशन को कैसे सुधारें
पृष्ठ पर अंक लगाना हमेशा दर्दनाक नहीं होता है; SQL सर्वर 2012 निश्चित रूप से सिंटैक्स को आसान बनाता है, लेकिन यदि आप केवल मूल सिंटैक्स को प्लग इन करते हैं, तो आपको हमेशा एक बड़ा लाभ नहीं दिखाई दे सकता है। यहां मैंने दिखाया है कि सीटीई का उपयोग करके थोड़ा अधिक वर्बोज़ सिंटैक्स सर्वोत्तम मामले में बेहतर प्रदर्शन कर सकता है, और सबसे खराब स्थिति में तर्कसंगत रूप से नगण्य प्रदर्शन अंतर हो सकता है। डेटा पुनर्प्राप्ति से डेटा स्थान को दो अलग-अलग चरणों में अलग करके, हम कुछ परिदृश्यों में एक जबरदस्त लाभ देख सकते हैं, उच्च CXPACKET के बाहर एक मामले में प्रतीक्षा करता है (और फिर भी, समानांतर प्रश्न अन्य प्रश्नों की तुलना में तेजी से समाप्त होते हैं जो बहुत कम या कोई प्रतीक्षा नहीं दिखाते हैं, इसलिए उनके "खराब" CXPACKET होने की संभावना नहीं थी, हर कोई आपको इसके बारे में चेतावनी देता है)।
फिर भी, जब कोई सहायक सूचकांक नहीं होता है, तब भी तेज़ तरीका धीमा होता है। जबकि आप प्रत्येक संभावित सॉर्टिंग एल्गोरिदम के लिए एक इंडेक्स को लागू करने के लिए प्रेरित हो सकते हैं जो उपयोगकर्ता चुन सकता है, आप कम विकल्प प्रदान करने पर विचार करना चाहेंगे (क्योंकि हम सभी जानते हैं कि इंडेक्स मुक्त नहीं हैं)। उदाहरण के लिए, क्या आपके एप्लिकेशन को LastName आरोही *और* LastName अवरोही द्वारा सॉर्टिंग का समर्थन करने की बिल्कुल आवश्यकता है? यदि वे सीधे उन ग्राहकों के पास जाना चाहते हैं जिनके अंतिम नाम Z से शुरू होते हैं, तो क्या वे *अंतिम* पृष्ठ पर जाकर पीछे की ओर काम नहीं कर सकते? यह एक तकनीकी निर्णय से अधिक एक व्यवसाय और उपयोगिता निर्णय है, सबसे अस्पष्ट सॉर्टिंग विकल्पों के लिए भी सर्वश्रेष्ठ प्रदर्शन प्राप्त करने के लिए, दोनों दिशाओं में प्रत्येक प्रकार के कॉलम पर इंडेक्स को थप्पड़ मारने से पहले इसे एक विकल्प के रूप में रखें।