SQL सर्वर 2012 में कई निष्पादन योजना सुधारों में से एक समानांतर निष्पादन योजनाओं के लिए थ्रेड आरक्षण और उपयोग की जानकारी को जोड़ना था। यह पोस्ट वास्तव में इन नंबरों का अर्थ देखती है, और समानांतर निष्पादन को समझने में अतिरिक्त अंतर्दृष्टि प्रदान करती है।
निम्नलिखित क्वेरी पर विचार करें जो एडवेंचरवर्क्स डेटाबेस के बढ़े हुए संस्करण के विरुद्ध चलती है:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; क्वेरी अनुकूलक समानांतर निष्पादन योजना चुनता है:
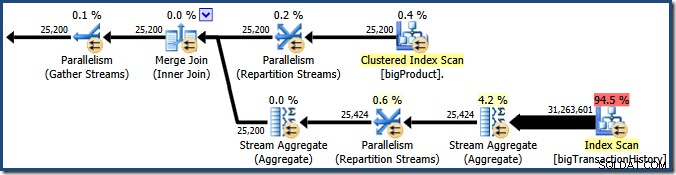
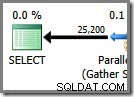
प्लान एक्सप्लोरर रूट नोड टूलटिप में समानांतर थ्रेड उपयोग विवरण दिखाता है। SSMS में समान जानकारी देखने के लिए, योजना रूट नोड पर क्लिक करें, गुण विंडो खोलें, और ThreadStat का विस्तार करें। नोड. उपयोग करने के लिए SQL सर्वर के लिए उपलब्ध आठ तार्किक प्रोसेसर वाली मशीन का उपयोग करते हुए, इस क्वेरी के एक विशिष्ट रन से थ्रेड उपयोग की जानकारी नीचे दिखाई गई है, बाईं ओर प्लान एक्सप्लोरर, दाईं ओर SSMS दृश्य:
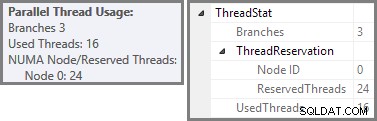
स्क्रीनशॉट से पता चलता है कि निष्पादन इंजन ने इस क्वेरी के लिए 24 थ्रेड आरक्षित किए, और उनमें से 16 का उपयोग करके घाव किया। यह यह भी दर्शाता है कि क्वेरी योजना में तीन शाखाएँ हैं , हालांकि यह बिल्कुल नहीं बताता कि एक शाखा क्या है। यदि आपने समानांतर क्वेरी निष्पादन पर मेरा सिंपल टॉक लेख पढ़ा है, तो आप जानेंगे कि शाखाएं एक समानांतर क्वेरी योजना के खंड हैं जो एक्सचेंज ऑपरेटरों द्वारा सीमित हैं। नीचे दिया गया आरेख सीमाओं को खींचता है, और शाखाओं की संख्या (विस्तार करने के लिए क्लिक करें):

शाखा दो (नारंगी)
आइए पहले शाखा दो को थोड़ा और विस्तार से देखें:
आठ के समानांतरवाद (डीओपी) की डिग्री पर, क्वेरी योजना की इस शाखा को चलाने वाले आठ सूत्र हैं। यह समझना महत्वपूर्ण है कि यह संपूर्ण निष्पादन योजना है जहां तक इन आठ धागों का संबंध है - उन्हें व्यापक योजना का कोई ज्ञान नहीं है।
एक सीरियल निष्पादन योजना में, एक एकल थ्रेड डेटा स्रोत से डेटा पढ़ता है, कई योजना ऑपरेटरों के माध्यम से पंक्तियों को संसाधित करता है, और गंतव्य पर परिणाम लौटाता है (उदाहरण के लिए, एसएसएमएस क्वेरी परिणाम विंडो या डेटाबेस तालिका हो सकती है)।
एक शाखा . में समानांतर निष्पादन योजना में, स्थिति बहुत समान है:प्रत्येक थ्रेड एक स्रोत से डेटा पढ़ता है, कई योजना ऑपरेटरों के माध्यम से पंक्तियों को संसाधित करता है, और परिणाम को गंतव्य पर लौटाता है। अंतर यह है कि गंतव्य एक एक्सचेंज (समानांतरता) ऑपरेटर है, और डेटा स्रोत एक एक्सचेंज भी हो सकता है।
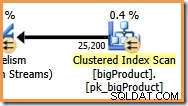
नारंगी शाखा में, डेटा स्रोत एक क्लस्टर इंडेक्स स्कैन है, और गंतव्य एक पुनर्विभाजन स्ट्रीम एक्सचेंज का दाहिना हाथ है। एक्सचेंज के दाहिने हाथ को निर्माता पक्ष . के रूप में जाना जाता है , क्योंकि यह उस शाखा से जुड़ता है जो एक्सचेंज में डेटा जोड़ती है।
नारंगी शाखा में आठ धागे तालिका को स्कैन करने और एक्सचेंज में पंक्तियों को जोड़ने के लिए सहयोग करते हैं। एक्सचेंज पंक्तियों को पेज के आकार के पैकेट में असेंबल करता है। एक बार एक पैकेट भर जाने के बाद इसे एक्सचेंज में दूसरी तरफ धकेल दिया जाता है। यदि एक्सचेंज में भरने के लिए एक और खाली पैकेट उपलब्ध है, तो प्रक्रिया तब तक जारी रहती है जब तक कि सभी डेटा स्रोत पंक्तियों को संसाधित नहीं किया जाता (या एक्सचेंज खाली पैकेट से बाहर हो जाता है)।
हम प्लान एक्सप्लोरर में प्लान ट्री व्यू का उपयोग करके प्रत्येक थ्रेड पर संसाधित पंक्तियों की संख्या देख सकते हैं:
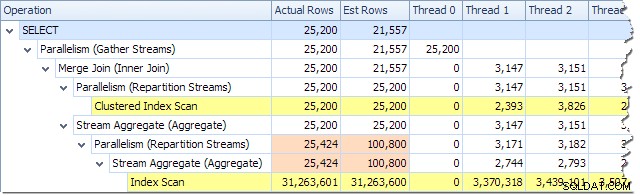
Plan Explorer यह देखना आसान बनाता है कि सभी . के लिए पंक्तियों को थ्रेड में कैसे वितरित किया जाता है योजना में भौतिक संचालन। SSMS में, आप एकल प्लान ऑपरेटर के लिए पंक्ति वितरण देखने तक सीमित हैं। ऐसा करने के लिए, एक ऑपरेटर आइकन पर क्लिक करें, गुण विंडो खोलें, और फिर पंक्तियों की वास्तविक संख्या नोड का विस्तार करें। नीचे दिया गया ग्राफ़िक नारंगी और बैंगनी शाखाओं के बीच की सीमा पर पुनर्विभाजन स्ट्रीम नोड के लिए SSMS जानकारी दिखाता है:
शाखा तीन (हरा)
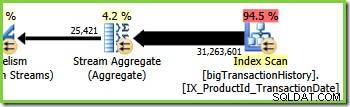
शाखा तीन शाखा दो के समान है, लेकिन इसमें एक अतिरिक्त स्ट्रीम एग्रीगेट ऑपरेटर होता है। हरी शाखा में भी आठ धागे होते हैं, जिससे अब तक कुल सोलह देखे जा सकते हैं। आठ हरे-शाखा धागे एक गैर-संकुल सूचकांक स्कैन से डेटा पढ़ते हैं, किसी प्रकार का एकत्रीकरण करते हैं, और परिणामों को दूसरे रिपार्टिशन स्ट्रीम एक्सचेंज के निर्माता पक्ष को पास करते हैं।
स्ट्रीम एग्रीगेट के लिए प्लान एक्सप्लोरर टूलटिप से पता चलता है कि यह उत्पाद आईडी के आधार पर समूह बना रहा है और partialagg1005 लेबल वाले एक्सप्रेशन की गणना कर रहा है। :
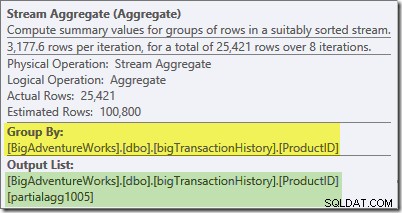
एक्सप्रेशन टैब दिखाता है कि व्यंजक प्रत्येक समूह में पंक्तियों की गिनती का परिणाम है:

स्ट्रीम एग्रीगेट एक आंशिक की गणना कर रहा है ('स्थानीय' के रूप में भी जाना जाता है) समुच्चय। आंशिक (या स्थानीय) क्वालीफायर का सीधा सा मतलब है कि प्रत्येक धागा उन पंक्तियों पर कुल की गणना करता है जो वह देखता है। इंडेक्स स्कैन से पंक्तियों को मांग-आधारित योजना का उपयोग करके थ्रेड्स के बीच वितरित किया जाता है:समय से पहले पंक्तियों का कोई निश्चित वितरण नहीं होता है; धागे स्कैन से पंक्तियों की एक श्रृंखला प्राप्त करते हैं क्योंकि वे उनके लिए पूछते हैं। कौन सी पंक्तियाँ समाप्त होती हैं, कौन से धागे अनिवार्य रूप से यादृच्छिक होते हैं क्योंकि यह समय के मुद्दों और अन्य कारकों पर निर्भर करता है।
हर थ्रेड में अलग-अलग पंक्तियां दिखाई देती हैं स्कैन से, लेकिन पंक्तियों के साथ समान उत्पाद आईडी एक से अधिक धागे द्वारा देखा जा सकता है। कुल 'आंशिक' है क्योंकि किसी विशेष उत्पाद आईडी समूह के लिए उप-योग एक से अधिक थ्रेड पर प्रदर्शित हो सकते हैं; यह 'स्थानीय' है क्योंकि प्रत्येक थ्रेड केवल प्राप्त होने वाली पंक्तियों के आधार पर अपने परिणाम की गणना करता है। उदाहरण के लिए, मान लें कि तालिका में उत्पाद आईडी #1 के लिए 1,000 पंक्तियां हैं। उनमें से 432 पंक्तियों को देखने के लिए एक थ्रेड हो सकता है, जबकि दूसरा 568 देख सकता है। दोनों थ्रेड्स में आंशिक होगा उत्पाद आईडी #1 के लिए पंक्तियों की संख्या (एक थ्रेड में 432, दूसरे में 568)।
आंशिक एकत्रीकरण एक प्रदर्शन अनुकूलन है क्योंकि यह अन्यथा संभव होने की तुलना में पहले की पंक्तियों की संख्या को कम करता है। हरी शाखा में, जल्दी एकत्रीकरण के परिणामस्वरूप कम पंक्तियों को पैकेट में इकट्ठा किया जाता है और रिपार्टिशन स्ट्रीम एक्सचेंज में धकेल दिया जाता है।
शाखा 1 (बैंगनी)

बैंगनी शाखा में आठ और धागे हैं, जो अब तक चौबीस बना रहे हैं। इस शाखा में प्रत्येक थ्रेड दो रिपार्टिशन स्ट्रीम एक्सचेंजों से पंक्तियों को पढ़ता है, और एक गैदर स्ट्रीम एक्सचेंज को पंक्तियाँ लिखता है। यह शाखा जटिल और अपरिचित लग सकती है, लेकिन यह केवल डेटा स्रोत से पंक्तियों को पढ़ रही है और किसी अन्य क्वेरी योजना की तरह परिणाम को गंतव्य पर भेज रही है।
योजना के दाहिने हाथ की ओर नारंगी और हरे रंग की शाखाओं में देखे गए दो रिपार्टिशन स्ट्रीम एक्सचेंजों के दूसरी तरफ से पढ़े जा रहे डेटा को दर्शाता है। एक्सचेंज के इस (बाएं हाथ) पक्ष को उपभोक्ता . के रूप में जाना जाता है पक्ष, क्योंकि यहां संलग्न धागे पंक्तियों को पढ़ रहे हैं (खपत) कर रहे हैं। आठ बैंगनी शाखा धागे उपभोक्ता . हैं दो पुनर्विभाजन स्ट्रीम एक्सचेंजों पर डेटा का।
बैंगनी रंग की शाखा के बाईं ओर निर्माता . को लिखी जा रही पंक्तियों को दर्शाता है एक इकट्ठा स्ट्रीम एक्सचेंज के पक्ष में। वही आठ सूत्र (जो पुनर्विभाजन स्ट्रीम एक्सचेंज में उपभोक्ता हैं) एक निर्माता . का प्रदर्शन कर रहे हैं यहाँ भूमिका।
बैंगनी शाखा में प्रत्येक धागा शाखा में प्रत्येक ऑपरेटर को चलाता है, जैसे एक एकल धागा एक सीरियल निष्पादन योजना में प्रत्येक ऑपरेशन को निष्पादित करता है। मुख्य अंतर यह है कि आठ धागे एक साथ चल रहे हैं, प्रत्येक एक अलग पंक्ति पर किसी भी समय अलग-अलग इंस्टेंस का उपयोग करते हुए काम कर रहे हैं। क्वेरी प्लान ऑपरेटरों की।
इस शाखा में स्ट्रीम एग्रीगेट एक वैश्विक है सकल। यह हरे रंग की शाखा में गणना किए गए आंशिक (स्थानीय) समुच्चय को जोड़ती है (एक थ्रेड में 432 गिनती और दूसरे में 568 का उदाहरण याद रखें) प्रत्येक उत्पाद आईडी के लिए संयुक्त कुल का उत्पादन करने के लिए। प्लान एक्सप्लोरर टूलटिप वैश्विक परिणाम अभिव्यक्ति दिखाता है, जिसे Expr1004 लेबल किया गया है:
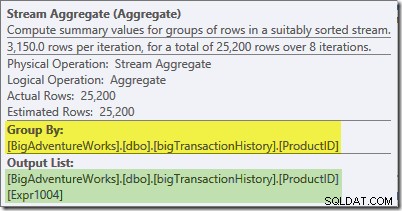
प्रति उत्पाद आईडी सही वैश्विक परिणाम की गणना आंशिक योगों को जोड़कर की जाती है, जैसा कि एक्सप्रेशन टैब दिखाता है:
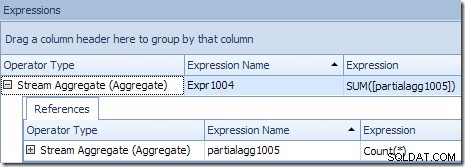
हमारे (काल्पनिक) उदाहरण को जारी रखने के लिए, उत्पाद आईडी #1 के लिए 1,000 पंक्तियों का सही परिणाम 432 और 568 के दो उप-योगों को जोड़कर प्राप्त किया जाता है।
आठ बैंगनी शाखा थ्रेड्स में से प्रत्येक दो गैदर स्ट्रीम एक्सचेंजों के उपभोक्ता पक्ष से डेटा पढ़ता है, वैश्विक समुच्चय की गणना करता है, उत्पाद आईडी पर मर्ज जॉइन करता है, और बैंगनी शाखा के बाईं ओर गैदर स्ट्रीम एक्सचेंज में पंक्तियों को जोड़ता है। मूल प्रक्रिया सामान्य धारावाहिक योजना से बहुत अलग नहीं है; अंतर यह है कि पंक्तियों को कहाँ से पढ़ा जाता है, उन्हें कहाँ भेजा जाता है, और पंक्तियों के बीच पंक्तियों को कैसे वितरित किया जाता है…
विनिमय पंक्ति वितरण
सतर्क पाठक इस बिंदु पर कुछ विवरणों के बारे में सोच रहा होगा। बैंगनी शाखा प्रति उत्पाद आईडी . के सही परिणामों की गणना करने का प्रबंधन कैसे करती है लेकिन हरी शाखा नहीं कर सका (उसी उत्पाद आईडी के परिणाम कई धागे में फैले हुए थे)? साथ ही, यदि आठ अलग-अलग मर्ज जॉइन हैं (एक प्रति थ्रेड) SQL सर्वर कैसे गारंटी देता है कि पंक्तियाँ जो एक ही इंस्टेंस पर अंत में शामिल होंगी शामिल होने का?
इन दोनों प्रश्नों का उत्तर यह देखकर दिया जा सकता है कि जिस तरह से दो पुनर्विभाजन धाराएँ उत्पादक पक्ष (हरे और नारंगी शाखाओं में) से उपभोक्ता पक्ष (बैंगनी शाखा में) की पंक्तियों का आदान-प्रदान करती हैं। हम सबसे पहले नारंगी और बैंगनी शाखाओं की सीमा पर स्थित पुनर्विभाजन स्ट्रीम एक्सचेंज को देखेंगे:
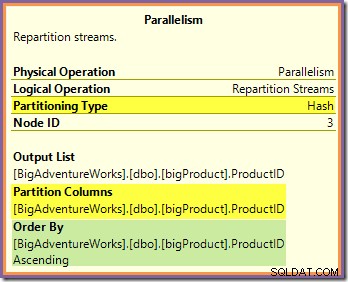
यह एक्सचेंज उत्पाद आईडी कॉलम पर लागू हैश फ़ंक्शन का उपयोग करके आने वाली पंक्तियों (नारंगी शाखा से) को रूट करता है। इसका प्रभाव यह है कि किसी विशेष उत्पाद आईडी के लिए सभी पंक्तियां गारंटीकृत . हैं उसी बैंगनी-शाखा के धागे में भेजा जाना। नारंगी और बैंगनी धागे इस मार्ग के बारे में कुछ नहीं जानते; यह सब आंतरिक रूप से एक्सचेंज द्वारा नियंत्रित किया जाता है।
सभी नारंगी धागे जानते हैं कि वे मूल पुनरावर्तक को पंक्तियों को वापस कर रहे हैं जिन्होंने उनसे (एक्सचेंज के निर्माता पक्ष) के लिए कहा था। समान रूप से, सभी बैंगनी धागे 'जानते हैं' कि वे डेटा स्रोत से पंक्तियों को पढ़ रहे हैं। एक्सचेंज निर्धारित करता है कि आने वाली ऑरेंज-थ्रेड पंक्ति किस पैकेट में जाएगी, और यह आठ उम्मीदवार पैकेटों में से कोई एक हो सकता है। इसी तरह, एक्सचेंज यह निर्धारित करता है कि बैंगनी धागे से पढ़ने के अनुरोध को पूरा करने के लिए किस पैकेट से एक पंक्ति को पढ़ना है।
सावधान रहें कि किसी विशेष नारंगी (उत्पादक) धागे की मानसिक छवि को सीधे किसी विशेष बैंगनी (उपभोक्ता) धागे से न जोड़ा जाए। ऐसा नहीं है कि यह क्वेरी योजना कैसे काम करती है। संतरा उत्पादक हो सकता है अंत में सभी बैंगनी उपभोक्ताओं को पंक्तियाँ भेजना - रूटिंग पूरी तरह से उत्पाद आईडी कॉलम के मूल्य पर निर्भर करती है, प्रत्येक पंक्ति में यह संसाधित होती है।
यह भी ध्यान दें कि एक्सचेंज में पंक्तियों का एक पैकेट केवल तभी स्थानांतरित होता है जब वह भर जाता है (या जब निर्माता पक्ष डेटा से बाहर हो जाता है)। कल्पना कीजिए कि एक्सचेंज पैकेट को एक समय में एक पंक्ति में भरता है, जहां किसी विशेष पैकेट के लिए पंक्तियाँ किसी भी निर्माता-पक्ष (नारंगी) धागे से आ सकती हैं। एक बार एक पैकेट भर जाने के बाद, इसे उपभोक्ता पक्ष में भेज दिया जाता है, जहां एक विशेष उपभोक्ता (बैंगनी) धागा इससे पढ़ना शुरू कर सकता है।
हरे और बैंगनी रंग की शाखाओं की सीमा पर स्थित पुनर्विभाजन स्ट्रीम एक्सचेंज बहुत समान तरीके से काम करता है:
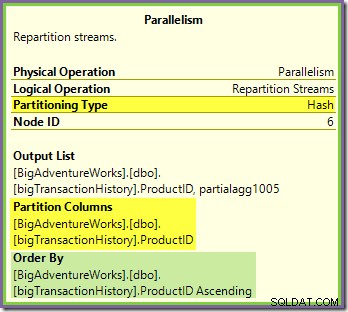
समान हैश फ़ंक्शन . का उपयोग करके इस एक्सचेंज में पंक्तियों को पैकेट में भेजा जाता है समान विभाजन स्तंभ . पर नारंगी-बैंगनी विनिमय के लिए जैसा कि पहले देखा गया था। इसका मतलब है कि दोनों पुनर्विभाजन धाराएं समान उत्पाद आईडी वाली रूट पंक्तियों को समान बैंगनी-शाखा थ्रेड में एक्सचेंज करती हैं।
यह बताता है कि कैसे बैंगनी शाखा में स्ट्रीम एग्रीगेट वैश्विक समुच्चय की गणना करने में सक्षम है - यदि किसी विशेष उत्पाद आईडी वाली एक पंक्ति को किसी विशेष बैंगनी-शाखा थ्रेड पर देखा जाता है, तो उस थ्रेड को उस उत्पाद आईडी के लिए सभी पंक्तियों को देखने की गारंटी है (और नहीं अन्य धागा होगा)।
मर्ज जॉइन के लिए कॉमन एक्सचेंज पार्टीशनिंग कॉलम भी जॉइन की है, इसलिए सभी पंक्तियां जो संभवत:शामिल हो सकती हैं, उसी (बैंगनी) थ्रेड द्वारा संसाधित होने की गारंटी है।
ध्यान देने वाली एक अंतिम बात यह है कि दोनों एक्सचेंज आदेश-संरक्षण . हैं (a.k.a 'विलय') एक्सचेंज, जैसा कि टूलटिप्स में ऑर्डर बाय एट्रिब्यूट में दिखाया गया है। यह मर्ज जॉइन की आवश्यकता को पूरा करता है कि इनपुट पंक्तियों को जॉइन कीज़ पर सॉर्ट किया जाए। ध्यान दें कि एक्सचेंज कभी भी पंक्तियों को स्वयं क्रमबद्ध नहीं करते हैं, उन्हें केवल संरक्षित . के लिए कॉन्फ़िगर किया जा सकता है मौजूदा आदेश।
जीरो धागा
निष्पादन योजना का अंतिम भाग गैदर स्ट्रीम एक्सचेंज के बाईं ओर स्थित है। यह हमेशा एक ही धागे पर चलता है - वही जो पूरे नियमित धारावाहिक योजना को चलाता था। निष्पादन योजनाओं में इस धागे को हमेशा 'थ्रेड 0' लेबल किया जाता है और इसे कभी-कभी 'समन्वयक' थ्रेड कहा जाता है (एक पदनाम जो मुझे विशेष रूप से उपयोगी नहीं लगता)।
थ्रेड जीरो गैदर स्ट्रीम एक्सचेंज के उपभोक्ता (बाएं) की ओर से पंक्तियों को पढ़ता है और उन्हें क्लाइंट को लौटाता है। इस उदाहरण में एक्सचेंज के अलावा कोई थ्रेड ज़ीरो इटरेटर नहीं हैं, लेकिन अगर वहाँ थे, तो वे सभी एक ही थ्रेड पर चलेंगे। नोट द गैदर स्ट्रीम्स भी एक मर्जिंग एक्सचेंज है (इसमें ऑर्डर बाय एट्रिब्यूट है):

अधिक जटिल समानांतर योजनाओं में अंतिम गैदर स्ट्रीम एक्सचेंज के बाईं ओर एक के अलावा सीरियल निष्पादन क्षेत्र शामिल हो सकते हैं। ये सीरियल ज़ोन थ्रेड ज़ीरो में नहीं चलाए जाते हैं, लेकिन यह एक और बार एक्सप्लोर करने के लिए एक विवरण है।
आरक्षित और उपयोग किए गए थ्रेड पर दोबारा गौर किया गया
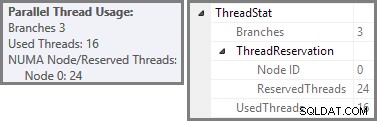
हमने देखा है कि इस समानांतर योजना में तीन शाखाएँ हैं। यह बताता है कि क्यों SQL सर्वर आरक्षित 24 धागे (डीओपी 8 पर तीन शाखाएं)। सवाल यह है कि ऊपर के स्क्रीनशॉट में केवल 16 थ्रेड्स को 'यूज्ड' के रूप में क्यों रिपोर्ट किया गया है।
उत्तर के दो भाग हैं। पहला भाग इस योजना पर लागू नहीं होता है, लेकिन फिर भी इसके बारे में जानना जरूरी है। रिपोर्ट की गई शाखाओं की संख्या अधिकतम संख्या है जो समवर्ती रूप से निष्पादित की जा सकती है ।
जैसा कि आप जानते हैं, कुछ योजना संचालक 'अवरुद्ध' कर रहे हैं - जिसका अर्थ है कि उन्हें पहली आउटपुट पंक्ति उत्पन्न करने से पहले अपनी सभी इनपुट पंक्तियों का उपभोग करना होगा। ब्लॉकिंग (जिसे स्टॉप-एंड-गो के रूप में भी जाना जाता है) ऑपरेटर का सबसे स्पष्ट उदाहरण सॉर्ट है। प्रत्येक इनपुट पंक्ति को देखने से पहले एक सॉर्ट पहली पंक्ति को क्रमबद्ध क्रम में वापस नहीं कर सकता क्योंकि अंतिम इनपुट पंक्ति पहले क्रमबद्ध हो सकती है।
कई इनपुट वाले ऑपरेटर (उदाहरण के लिए जॉइन और यूनियन) एक इनपुट के संबंध में अवरुद्ध हो सकते हैं, लेकिन दूसरे के संबंध में गैर-अवरुद्ध ('पाइपलाइन')। इसका एक उदाहरण हैश जॉइन है - बिल्ड इनपुट ब्लॉक हो रहा है, लेकिन जांच इनपुट पाइपलाइन में है। बिल्ड इनपुट अवरुद्ध हो रहा है क्योंकि यह हैश तालिका बनाता है जिसके विरुद्ध जांच पंक्तियों का परीक्षण किया जाता है।
ब्लॉक करने वाले ऑपरेटरों की मौजूदगी का मतलब है कि एक या एक से ज़्यादा समानांतर शाखाएं हो सकती हैं दूसरों को शुरू करने से पहले पूरा करने की गारंटी दी जा सकती है। जहां ऐसा होता है, SQL सर्वर पुन:उपयोग कर सकता है अनुक्रम में बाद की शाखा के लिए एक पूर्ण शाखा को संसाधित करने के लिए प्रयुक्त धागे। SQL सर्वर थ्रेड आरक्षण के बारे में बहुत रूढ़िवादी है, इसलिए केवल वे शाखाएँ जो गारंटीकृत . हैं एक और शुरुआत से पहले पूरा करने के लिए इस थ्रेड-आरक्षण अनुकूलन का उपयोग करें। हमारी क्वेरी योजना में कोई अवरोधक ऑपरेटर शामिल नहीं है, इसलिए रिपोर्ट की गई शाखाओं की संख्या केवल शाखाओं की कुल संख्या है।
उत्तर का दूसरा भाग यह है कि यदि धागे होते हैं . तब भी उनका पुन:उपयोग किया जा सकता है किसी अन्य शाखा में एक धागा शुरू होने से पहले पूरा करने के लिए। इस मामले में थ्रेड्स की पूरी संख्या अभी भी आरक्षित है, लेकिन वास्तविक उपयोग कम हो सकता है। समानांतर योजना वास्तव में कितने धागे का उपयोग करती है यह अन्य बातों के अलावा समय के मुद्दों पर निर्भर करता है, और निष्पादन के बीच भिन्न हो सकता है।
समानांतर धागे सभी एक ही समय में निष्पादित करना शुरू नहीं करते हैं, लेकिन फिर से इसके विवरण के लिए एक और अवसर की प्रतीक्षा करनी होगी। ब्लॉकिंग ऑपरेटरों की कमी के बावजूद, थ्रेड्स का पुन:उपयोग कैसे किया जा सकता है, यह देखने के लिए क्वेरी योजना को फिर से देखें:
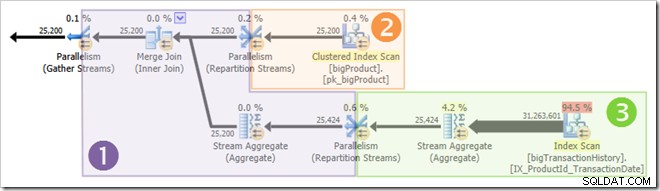
यह स्पष्ट है कि शाखा में धागे दो या तीन शाखाओं में धागे से पहले पूरा नहीं हो सकता है, इसलिए वहां धागे के पुन:उपयोग की कोई संभावना नहीं है। शाखा तीन भी संभावना नहीं . है शाखा एक या दो शाखा शुरू होने से पहले पूरा करने के लिए क्योंकि इसमें बहुत काम है (कुल मिलाकर लगभग 32 मिलियन पंक्तियाँ)।
शाखा दो एक अलग मामला है। उत्पाद तालिका के अपेक्षाकृत छोटे आकार का मतलब है कि इस बात की अच्छी संभावना है कि शाखा अपना काम पहले पूरा कर सकती है। शाखा तीन शुरू होती है। यदि उत्पाद तालिका को पढ़ने से कोई भौतिक I/O नहीं मिलता है, तो आठ थ्रेड्स को 25,200 पंक्तियों को पढ़ने और उन्हें नारंगी-बैंगनी सीमा रिपार्टिशन स्ट्रीम एक्सचेंज में सबमिट करने में बहुत समय नहीं लगेगा।
इस पोस्ट में अब तक देखे गए स्क्रीनशॉट के लिए उपयोग किए गए टेस्ट रन में ठीक यही हुआ:आठ नारंगी शाखा के धागे इतनी जल्दी पूरे हो गए कि उन्हें हरी शाखा के लिए पुन:उपयोग किया जा सके। कुल मिलाकर, सोलह अद्वितीय धागों का उपयोग किया गया था, इसलिए निष्पादन योजना यही रिपोर्ट करती है।
यदि क्वेरी को कोल्ड कैश के साथ फिर से चलाया जाता है, तो भौतिक I/O द्वारा शुरू की गई देरी यह सुनिश्चित करने के लिए पर्याप्त है कि किसी भी नारंगी शाखा थ्रेड के पूरा होने से पहले हरी शाखा थ्रेड शुरू हो जाए। किसी भी धागे का पुन:उपयोग नहीं किया जाता है, इसलिए निष्पादन योजना रिपोर्ट करती है कि सभी 24 आरक्षित धागे वास्तव में उपयोग किए गए थे:
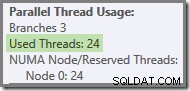
आम तौर पर, दो चरम सीमाओं (इस क्वेरी योजना के लिए 16 और 24) के बीच 'प्रयुक्त धागे' की कोई भी संख्या संभव है:
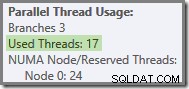
अंत में, ध्यान दें कि अंतिम गैदर स्ट्रीम के बाईं ओर योजना के सीरियल भाग को चलाने वाला थ्रेड गिना नहीं जाता है समानांतर धागे के योग में। यह समानांतर निष्पादन को समायोजित करने के लिए जोड़ा गया एक अतिरिक्त धागा नहीं है।
अंतिम विचार
समानांतर निष्पादन को लागू करने के लिए SQL सर्वर द्वारा उपयोग किए जाने वाले एक्सचेंज मॉडल की सुंदरता यह है कि थ्रेड्स के बीच बफरिंग और मूविंग पंक्तियों की सभी जटिलता एक्सचेंज (समानांतर) ऑपरेटरों के अंदर छिपी हुई है। शेष योजना एक्सचेंजों से घिरी साफ-सुथरी 'शाखाओं' में विभाजित है। एक शाखा के भीतर, प्रत्येक ऑपरेटर वैसा ही व्यवहार करता है जैसा वह एक सीरियल प्लान में करता है - लगभग सभी मामलों में, शाखा संचालकों को इस बात का कोई ज्ञान नहीं होता है कि व्यापक योजना समानांतर निष्पादन का उपयोग करती है।
समानांतर निष्पादन को समझने की कुंजी (मानसिक रूप से) एक्सचेंज की सीमाओं पर समानांतर योजना को तोड़ना है, और प्रत्येक शाखा को डीओपी अलग धारावाहिक के रूप में चित्रित करना है योजनाओं, पंक्तियों के एक अलग सबसेट पर सभी निष्पादन संगामिति। विशेष रूप से याद रखें कि ऐसी प्रत्येक सीरियल योजना उस शाखा के सभी ऑपरेटरों को चलाती है - SQL सर्वर नहीं . करता है प्रत्येक ऑपरेटर को उसके अपने थ्रेड पर चलाएँ!
सबसे विस्तृत व्यवहार को समझने के लिए थोड़ा विचार करने की आवश्यकता होती है, विशेष रूप से कि कैसे एक्सचेंजों के भीतर पंक्तियों को रूट किया जाता है, और कैसे इंजन सही परिणामों की गारंटी देता है, लेकिन फिर जानने योग्य अधिकांश चीजों पर थोड़ा विचार करने की आवश्यकता होती है, है ना?