[ भाग 1 | भाग 2 | भाग 3 ]
भाग 1 में, मैंने दिखाया कि कैसे पेज और कॉलमस्टोर संपीड़न दोनों 1TB तालिका के आकार को 80% या उससे अधिक तक कम कर सकते हैं। जबकि मैं प्रभावित था कि मैं 1TB से 50GB तक एक तालिका को छोटा कर सकता हूं, मैं इसमें लगने वाले समय (2 से 14 घंटे तक कहीं भी) से बहुत खुश नहीं था। कुछ सुझावों के साथ जो ओबिश, लोनी नीडेरस्टैड, निको नेउगेबाउर और अन्य जैसे लोगों से कृपापूर्वक उधार लिया गया है, इस पोस्ट में मैं बेहतर लोड प्रदर्शन प्राप्त करने के अपने मूल प्रयास में कुछ बदलाव करने का प्रयास करूंगा। चूंकि नियमित कॉलमस्टोर इंडेक्स इस डेटा सेट पर page पेज कंप्रेशन से बेहतर कंप्रेस नहीं करता था , और वहां पहुंचने में 13 घंटे का समय लगा, मैं केवल COLUMNSTORE_ARCHIVE का उपयोग करके अधिक उन्नत समाधान पर ध्यान केंद्रित करूंगा संपीड़न।
मेरे विचार से कुछ मुद्दों से प्रभावित प्रदर्शन में निम्नलिखित शामिल हैं:
- खराब फ़ाइल लेआउट विकल्प - मैंने एक फाइलग्रुप में 8 फाइलें रखीं, समानांतरता के साथ, लेकिन कोई (या उप-इष्टतम) विभाजन नहीं, कई फाइलों में I/Os का छिड़काव लापरवाह परित्याग के साथ। इसका समाधान करने के लिए, मैं:
- करूंगा
- तालिका को 8 विभाजनों में विभाजित करें (एक प्रति कोर)
- प्रत्येक विभाजन की डेटा फ़ाइल को उसके अपने फ़ाइल समूह पर रखें
- प्रत्येक विभाजन को जोड़ने के लिए 8 अलग-अलग प्रक्रियाओं का उपयोग करें
- संग्रह संपीड़न का उपयोग "सक्रिय" विभाजन को छोड़कर सभी पर करें
- बहुत अधिक छोटे बैच और उप-इष्टतम पंक्तिसमूह जनसंख्या - एक बार में 10 मिलियन पंक्तियों को संसाधित करके, मैं एक अच्छी, 1,048,576 पंक्तियों के साथ नौ पंक्ति समूहों को आबाद कर रहा था, और फिर शेष 562,816 पंक्तियों को एक और छोटे पंक्ति समूह में समाप्त कर दिया जाएगा। और कोई भी असमान वितरण जो शेष <102,400 पंक्तियों को छोड़ देता है, कम कुशल डेल्टा स्टोर संरचना में सम्मिलित करता है। पंक्तियों को अधिक समान रूप से वितरित करने और डेल्टा स्टोर से बचने के लिए, मैं:
- करूंगा
- अधिक से अधिक डेटा को 1,048,576 पंक्तियों के सटीक गुणकों में संसाधित करें
- उन्हें जितना संभव हो उतना समान रूप से 8 विभाजनों में फैलाएं
- 10x -> 100 मिलियन पंक्तियों के करीब बैच आकार का उपयोग करें
- अनुसूचक स्टैकिंग - जबकि मैंने इसके लिए जाँच नहीं की, यह संभव है कि कुछ मंदी एक अनुसूचक के बहुत अधिक काम करने और दूसरे अनुसूचक के पर्याप्त नहीं होने के कारण, अनुसूचक राउंड-रॉबिनिंग के कारण हुई हो। अब जबकि मैं सभी शेड्यूलर को समान रूप से व्यस्त रखने के लिए एक मैक्सडॉप 8 प्रक्रिया के बजाय 8 मैक्सडॉप 1 प्रक्रियाओं के साथ जानबूझकर डेटा लोड कर रहा हूं, मैं करूंगा:
- एक संग्रहीत कार्यविधि का उपयोग करें जो सभी अनुसूचियों में समान रूप से संतुलन बनाने का प्रयास करती है (इस विचार के पीछे प्रेरणा के लिए SQLCAT की मार्गदर्शिका में पृष्ठ 189-191 देखें:संबंधपरक इंजन)
- वैश्विक ट्रेस ध्वज 2467 और 2469 सक्षम करें, जैसा कि दस्तावेज़ीकरण में चेतावनी दी गई है
- पृष्ठभूमि कॉलमस्टोर संपीड़न कार्य - आबादी के दौरान इसे चलाने की अनुमति देना बेकार था, क्योंकि मैंने वैसे भी अंत में पुनर्निर्माण करने की योजना बनाई थी। इस बार मैं करूंगा:
- वैश्विक ट्रेस ध्वज 634 का उपयोग करके इस कार्य को अक्षम करें
मैंने प्रारंभिक विभाजन फ़ंक्शन और योजना को खत्म कर दिया, और डेटा के अधिक समान वितरण के आधार पर एक नया निर्माण किया। मैं चाहता हूं कि 8 विभाजन कोर की संख्या और डेटा फ़ाइलों की संख्या से मेल खाएं, "गरीब आदमी की समानता" को अधिकतम करने के लिए मैं उपयोग करने की योजना बना रहा हूं।
सबसे पहले, हमें फाइलग्रुप का एक नया सेट बनाने की जरूरत है, प्रत्येक की अपनी फाइल के साथ:
डेटाबेस Oप्रतिलिपि जोड़ें FILEGROUP FG_CCI_Part1; डेटाबेस में परिवर्तन फ़ाइल जोड़ें (नाम =N'CCI_Part_1', आकार =250000, फ़ाइल नाम ='K:\Data\o_cci_p_1.mdf') FILEGROUP FG_CCI_Part1 में; -- ... 6 और ... डेटाबेस OCopy ADD FILEGROUP FG_CCI_Part8; डेटाबेस में परिवर्तन फ़ाइल जोड़ें (नाम =N'CCI_Part_8', आकार =250000, फ़ाइल नाम ='K:\Data\o_cci_p_8.mdf') FILEGROUP FG_CCI_Part8;
इसके बाद, मैंने तालिका में पंक्तियों की संख्या देखी:3,754,965,954। उन्हें वितरित करने के लिए बिल्कुल समान रूप से 8 विभाजनों में, जो कि प्रति विभाजन 469,370,744.25 पंक्तियाँ होंगी। इसे अच्छी तरह से काम करने के लिए, आइए विभाजन की सीमाओं को अगले . में समायोजित करें 1,048,576 पंक्तियों में से कई। यह है 1,048,576 x 448 = 469,762,048 - जो कि पहले 7 पार्टिशन में हमारे द्वारा शूट की जाने वाली पंक्तियों की संख्या होगी, अंतिम पार्टिशन में 466,631,618 पंक्तियों को छोड़कर। वास्तविक OID देखने के लिए मान जो प्रत्येक विभाजन में पंक्तियों की इष्टतम संख्या को समाहित करने के लिए सीमाओं के रूप में काम करेंगे, मैंने इस क्वेरी को मूल तालिका के विरुद्ध चलाया (चूंकि इसे चलाने में 25 मिनट लगे, मैंने जल्दी से इन परिणामों को एक अलग तालिका में डंप करना सीख लिया):
;एक्स एएस के साथ (ओआईडी चुनें, आरएन =ROW_NUMBER() ओवर (ओआईडी द्वारा ऑर्डर) डीबीओ से। ) dbo.stage से x जहां rn% (1048576*112) =0;
 यहां अनपैक करने के लिए आपकी अपेक्षा से कहीं अधिक है। CTE सभी भारी भारोत्तोलन करता है, क्योंकि उसे संपूर्ण 1.14TB तालिका को स्कैन करना होता है और एक पंक्ति संख्या हर पंक्ति के लिए निर्दिष्ट करनी होती है। . मैं केवल हर
यहां अनपैक करने के लिए आपकी अपेक्षा से कहीं अधिक है। CTE सभी भारी भारोत्तोलन करता है, क्योंकि उसे संपूर्ण 1.14TB तालिका को स्कैन करना होता है और एक पंक्ति संख्या हर पंक्ति के लिए निर्दिष्ट करनी होती है। . मैं केवल हर (1048576*112)th return को वापस करना चाहता हूं पंक्ति, हालांकि, चूंकि ये मेरी बैच सीमा पंक्तियाँ हैं, इसलिए यह WHERE . है खंड करता है। याद रखें कि मैं एक बार में काम को 100 मिलियन पंक्तियों के करीब बैचों में विभाजित करना चाहता हूं, लेकिन मैं वास्तव में एक शॉट में 469 मिलियन पंक्तियों को संसाधित नहीं करना चाहता। इसलिए डेटा को 8 विभाजनों में विभाजित करने के अलावा, मैं उन सभी विभाजनों को 117,440,512 (1,048,576*112) के चार बैचों में विभाजित करना चाहता हूं। पंक्तियाँ। चार बैचों का प्रत्येक आसन्न सेट एक विभाजन से संबंधित है, इसलिए PartitionID मैं वर्तमान पंक्ति संख्या पूर्णांक . के परिणाम में केवल एक जोड़ता हूं (1,048,576*448) . से विभाजित , जो यह सुनिश्चित करता है कि सीमा हमेशा "बाएं" सेट में हो। फिर हम परिणाम में एक जोड़ते हैं क्योंकि अन्यथा हम विभाजन के 0-आधारित संग्रह की बात कर रहे होते हैं, और कोई भी ऐसा नहीं चाहता है।
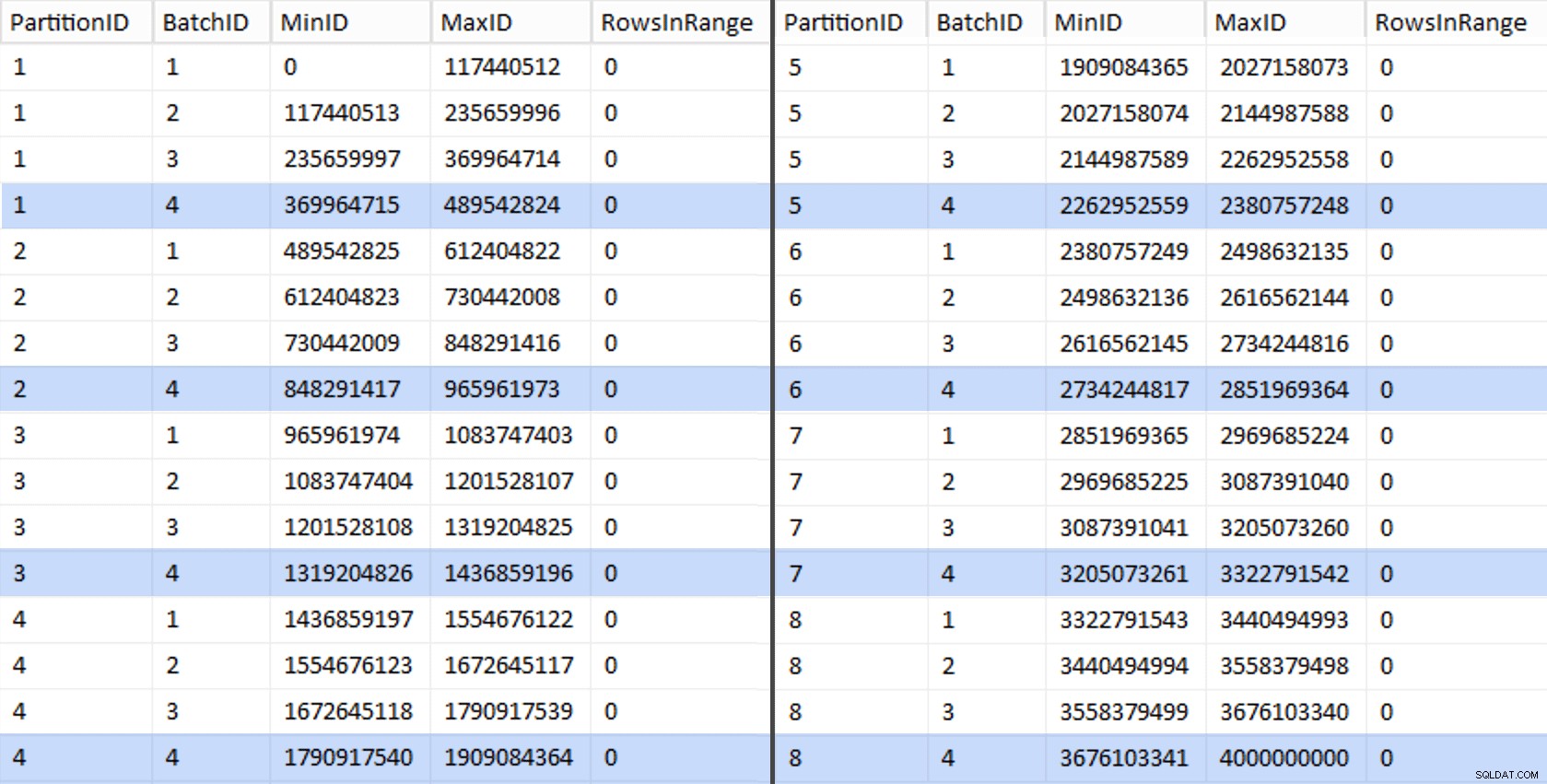
ठीक है, वह बहुत सारे शब्द थे। दाईं ओर stage . की (संक्षिप्त) सामग्री दिखाने वाली एक तस्वीर है तालिका (विभाजन सीमा मानों को हाइलाइट करते हुए, पूरा परिणाम दिखाने के लिए क्लिक करें)।
फिर हम उस स्टेजिंग टेबल से एक और क्वेरी प्राप्त कर सकते हैं जो हमें प्रत्येक विभाजन के अंदर प्रत्येक बैच के लिए न्यूनतम और अधिकतम मान दिखाती है, साथ ही अतिरिक्त बैच का हिसाब नहीं है (मूल तालिका में पंक्तियों के साथ OID उच्चतम सीमा मान से बड़ा):
; x AS के साथ ( OID चुनें, dbo.stage से पार्टीशन आईडी), y AS ( सेलेक्ट पार्टिशन आईडी, मिनिड =COALESCE (LAG (OID, 1) ओवर (OID द्वारा ऑर्डर), -1) +1, MaxID =OID एक्स यूनियन से सभी चयन विभाजन आईडी =8, मिनीआईडी =मैक्स (ओआईडी) +1, मैक्सआईडी =4000000000 - वास्तविक अधिकतम याद रखने से आसान x से) चयन विभाजन आईडी, बैचआईडी =ROW_NUMBER() ओवर (मिनिड द्वारा विभाजन आईडी ऑर्डर द्वारा विभाजन), MinID, MaxID, RowsInRange =CONVERT(int, NULL)INTO dbo.BatchQueueFROM y; -- आइए इसे एक ढेर के रूप में न छोड़ें:Dbo.BatchQueue(PartitionID, BatchID);पर अद्वितीय क्लस्टर इंडेक्स PK_bq बनाएं
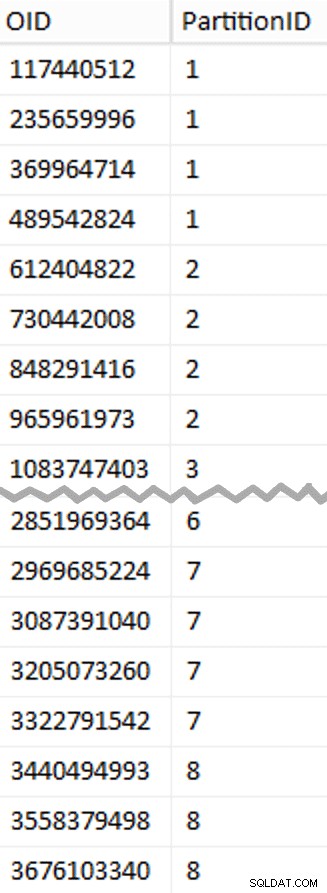
वे मान इस तरह दिखते हैं:
अपने काम का परीक्षण करने के लिए, हम वहां से प्रश्नों का एक सेट प्राप्त कर सकते हैं जो BatchQueue तालिका से वास्तविक पंक्ति गणना के साथ।
घोषणा @sql nvarchar(max) =N''; चयन करें @sql + ='अद्यतन dbo.BatchQueue SET RowsInRange =( dbo.tblOriginal से (NOLOCK) से काउंट (*) चुनें, जहां '+ RTRIM (मिनिड) +' और '+ RTRIM (MaxID) +') के बीच कॉस्टिड है। =' + आरटीआरआईएम (मिनिड) + 'और मैक्सिड =' + आरटीआरआईएम (मैक्सआईडी) + ';' डीबीओ से। बैच क्यू; EXEC sys.sp_executesql @sql;
मेरे सिस्टम पर इसमें लगभग 6 मिनट लगे। फिर आप यह दिखाने के लिए निम्न क्वेरी चला सकते हैं कि अंतिम बैच को छोड़कर प्रत्येक बैच पंक्ति समूहों को पूरी तरह से आबाद करने और संभावित डेल्टा स्टोर उपयोग के लिए कोई शेष नहीं छोड़ने में सक्षम है:
ALTER TABLE dbo.BatchQueue DeltaStore AS जोड़ें (RowsInRange % 1048576);
अब टेबल इस तरह दिखती है:
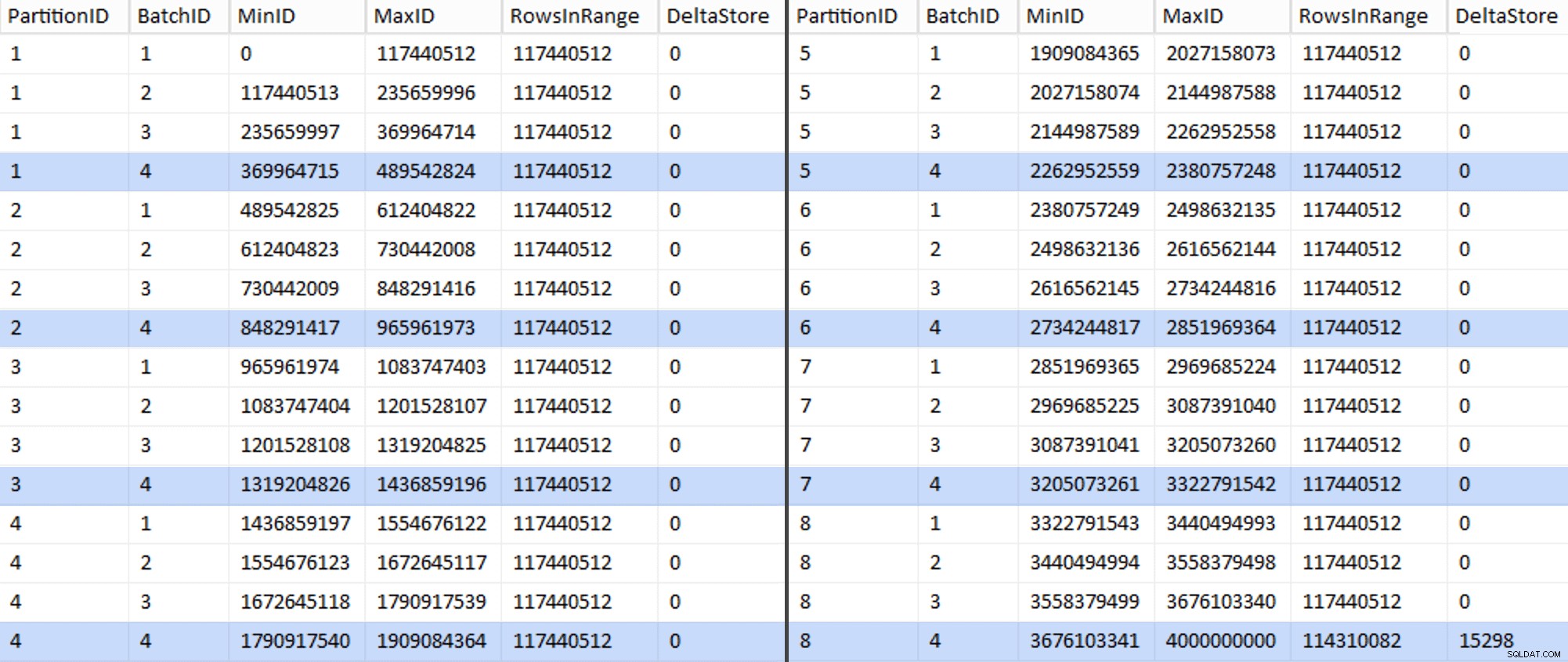
निश्चित रूप से, प्रत्येक बैच में 117,440,512 मिलियन पंक्तियों की गणना की गई है, केवल अंतिम को छोड़कर, जिसमें कम से कम आदर्श रूप से, हमारा एकमात्र असम्पीडित डेल्टा स्टोर होगा। हम शायद इसे भी रोक सकते हैं, बैच आकार को थोड़ा सा बदलकर इस विभाजन के लिए ताकि सभी चार बैच एक ही आकार के साथ चलाए जा सकें, या 102,400 या 1,048,576 के कुछ अन्य गुणकों को समायोजित करने के लिए बैचों की संख्या को बदलकर। चूंकि इसके लिए नया OID प्राप्त करने की आवश्यकता होगी बेस टेबल से मूल्यों को जोड़ते हुए, हमारे माइग्रेशन प्रयास में एक और 25 मिनट और जोड़ते हुए, मैं इसे एक अपूर्ण विभाजन को स्लाइड करने जा रहा हूं - खासकर जब से हमें इससे पूर्ण अभिलेखीय संपीड़न लाभ नहीं मिल रहा है।
BatchQueue तालिका हमारे बैच को संसाधित करने के लिए उपयोगी होने के संकेत दिखाना शुरू कर रही है ताकि डेटा को हमारी नई, विभाजित, क्लस्टर्ड कॉलमस्टोर तालिका में माइग्रेट किया जा सके। जिसे हमें बनाने की जरूरत है, अब जबकि हम सीमाओं को जानते हैं। केवल 7 सीमाएँ हैं, इसलिए आप निश्चित रूप से इसे मैन्युअल रूप से कर सकते हैं, लेकिन मैं गतिशील SQL को मेरे लिए अपना काम करना पसंद करता हूँ:
घोषणा @sql nvarchar(max) =N''; चयन करें @sql =N'CREATE PARTITION FUNCTION PF_OID([bigint]) as RANGE LEFT FOR VALUES ('+ STRING_AGG(MaxID,', ') +');' dbo.BatchQueue से जहां PartitionID <8 और BatchID =4; प्रिंट @sql;-- EXEC sys.sp_executesql @sql; परिणाम:
CREATE PARTITION FUNCTION PF_OID([bigint]) VALUES के लिए बाएं रेंज के रूप में (489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542);
एक बार यह बन जाने के बाद, हम अपनी विभाजन योजना बना सकते हैं और प्रत्येक क्रमिक विभाजन को उसकी समर्पित फ़ाइल में असाइन कर सकते हैं:
विभाजन योजना बनाएं PS_OID को PF_OID के रूप में (CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8);
अब हम टेबल बना सकते हैं और इसे माइग्रेशन के लिए तैयार कर सकते हैं:
टेबल dbo.tblPartitionedCCI(OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar( 128) नॉट न्यूल, वीसी4 वर्कर(128) न्यूल, एनएम1 न्यूमेरिक (24,12) न्यूल, एनएम 2 न्यूमेरिक (24,12) न्यूल, एनएम 3 न्यूमेरिक (24,12) न्यूल, बीआई 2 बिगिंट न्यूल, आईएन 4 इंट न्यूल, बीआई 3 बिगिंट न्यूल , NM4 न्यूमेरिक (24,12) NULL, IN5 int NULL, NM5 न्यूमेरिक (24,12) NULL, DT1 डेट न्यूल, VC5 वर्कर (128) NULL, BI4 बिगिंट न्यूल, BI5 बिगिंट न्यूल, BI6 बिगिंट न्यूल, BT1 बिट नॉट न्यूल , NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, - विभाजन योजना पर एक PK बाधा बनाने की जरूरत है... CONSTRAINT PK_CCI_Part प्राथमिक कुंजी क्लस्टर (OID) पीएस_ओआईडी (ओआईडी) पर); -- ... केवल इसे तुरंत छोड़ने के लिए... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;GO --... ताकि हम इसे CCI से बदल सकें:CRIATE COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID) );जाओ -- अब अपनी इच्छित संपीड़न के साथ पुनर्निर्माण करें:ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION =ALL WITH ( DATA_COMPRESSION =COLUMNSTORE_ARCHIVE ON PARTITIONS (1 से 7)), DATA_COMPRESSION =COLUMNSTORE ON PARTITIONS (8));भाग 3 में, मैं
BatchQueue. को और अधिक कॉन्फ़िगर करूँगा तालिका, डेटा को नई संरचना में धकेलने और परिणामों का विश्लेषण करने के लिए प्रक्रियाओं के लिए एक प्रक्रिया बनाएं।[ भाग 1 | भाग 2 | भाग 3 ]