[ भाग 1 | भाग 2 | भाग 3 ]
हाल ही में काम पर किसी ने तेजी से बढ़ती मेज को समायोजित करने के लिए और जगह मांगी। उस समय इसकी 3.75 बिलियन पंक्तियाँ थीं, जो 143 मिलियन पृष्ठों पर प्रस्तुत की गई थीं, और ~ 1.14TB पर कब्जा कर रही थीं। बेशक हम हमेशा एक टेबल पर अधिक डिस्क फेंक सकते हैं, लेकिन मैं यह देखना चाहता था कि क्या हम वर्तमान रैखिक प्रवृत्ति की तुलना में इसे अधिक कुशलता से माप सकते हैं। संपीड़न के लिए एक महान नौकरी की तरह लगता है, है ना? लेकिन मैं कुछ अन्य समाधानों को भी आज़माना चाहता था, जिसमें कॉलमस्टोर भी शामिल है - जिसे लोग आश्चर्यजनक रूप से आज़माने से हिचकते हैं। मैं निको नहीं हूं, लेकिन मैं यह देखने का प्रयास करना चाहता था कि यह हमारे लिए यहां क्या कर सकता है।
ध्यान दें कि मैं इस समय कार्यभार या अन्य पठन क्वेरी प्रदर्शन की रिपोर्ट करने पर ध्यान केंद्रित नहीं कर रहा हूं - मैं केवल यह देखना चाहता हूं कि इस डेटा के भंडारण (और मेमोरी) पदचिह्न पर मेरा क्या प्रभाव हो सकता है।
यहाँ मूल तालिका है। निर्दोषों की सुरक्षा के लिए मैंने टेबल और कॉलम के नाम बदल दिए हैं, लेकिन बाकी सब अपेक्षाकृत सटीक है।
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
वहां कुछ अन्य छोटी चीजें हैं जो उनकी तुलना में व्यापक हैं और/या वह पंक्ति संपीड़न साफ हो सकता है, जैसे numeric(24,12) और bigint कॉलम जो समय से पहले बड़े हो सकते हैं, लेकिन मैं एप्लिकेशन टीम में वापस नहीं जा रहा हूं और पता लगा रहा हूं कि क्या वहां कम क्षमताएं हैं, और मैं इस अभ्यास के लिए पंक्ति संपीड़न को छोड़ दूंगा और पेज और कॉलमस्टोर संपीड़न पर ध्यान केंद्रित करूंगा।
यह एक निष्क्रिय सर्वर (8 कोर, 64 जीबी रैम) पर डेटा की एक प्रति है, जिसमें बहुत सारे डिस्क स्थान (6TB से अधिक) हैं। तो सबसे पहले, आइए कुछ फ़ाइल समूह जोड़ें, एक मानक क्लस्टर्ड कॉलमस्टोर के लिए, और एक तालिका के विभाजित संस्करण के लिए (जहां सबसे हाल के विभाजन को छोड़कर सभी को COLUMNSTORE_ARCHIVE के साथ संपीड़ित किया जाएगा। , चूंकि वह सारा पुराना डेटा अब "केवल और कभी-कभी पढ़ने वाला" है:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
और फिर इन फ़ाइल समूहों के लिए कुछ फ़ाइलें (एक फ़ाइल प्रति कोर, अच्छी और समान रूप से 256GB पर आकार):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
इस विशेष हार्डवेयर (YMMV!) पर, इसमें प्रति फ़ाइल लगभग 10 सेकंड का समय लगा, और निम्नलिखित प्राप्त हुए:
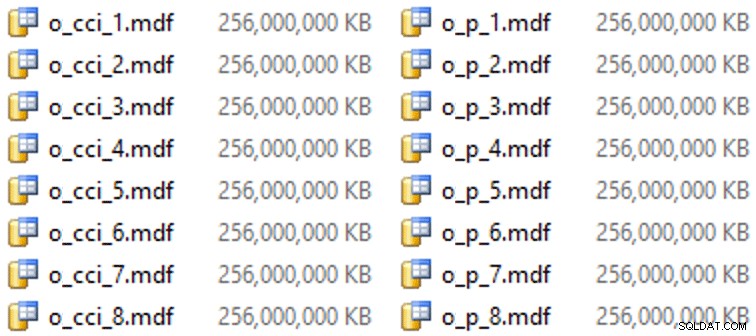
विभाजन उत्पन्न करने के लिए, मैंने भोलेपन से डेटा को "समान रूप से" विभाजित किया - या तो मैंने सोचा। मैंने अभी 3.75 बिलियन पंक्तियों को लिया और कुछ में विभाजित किया जो मुझे लगा कि प्रबंधनीय होगा:पहले 37 विभाजनों में 100 मिलियन पंक्तियों के साथ 38 विभाजन, और शेष पिछले एक में। (याद रखें, यह सिर्फ भाग 1 है! स्रोत तालिका में मूल्यों के वितरण के बारे में यहां एक अंतर्निहित धारणा है, और गंतव्य तालिका में पंक्ति समूह आबादी के लिए इष्टतम क्या है।) इसके लिए विभाजन स्कीमा और फ़ंक्शन बनाना इस प्रकार है इस प्रकार है:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
मैं RANGE LEFT का उपयोग करता हूं क्योंकि, जैसा कि कैथरीन विल्हेल्म्सन ने मुझे याद दिलाने में मदद करना जारी रखा है, इसका मतलब है कि सीमा मूल्य इसके बाईं ओर के विभाजन का एक हिस्सा है। दूसरे शब्दों में, मैं जो मान निर्दिष्ट कर रहा हूं, वे प्रत्येक विभाजन में अधिकतम मान हैं (तारीखों के साथ, आप आमतौर पर RANGE RIGHT चाहते हैं। )।
मैंने तब तालिका की दो प्रतियां बनाईं, प्रत्येक फ़ाइल समूह पर एक। पहले वाले में एक मानक क्लस्टर्ड कॉलमस्टोर इंडेक्स था, केवल अंतर OID . था कॉलम एक IDENTITY नहीं है और परिकलित कॉलम सिर्फ एक varbinary(8000) है :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
दूसरा एक विभाजन योजना पर बनाया गया था, इसलिए पहले एक नामित पीके की आवश्यकता थी, जिसे बाद में क्लस्टर्ड कॉलमस्टोर इंडेक्स द्वारा प्रतिस्थापित किया जाना था (हालांकि ब्रेंट ओज़र इस संक्षिप्त पोस्ट में दिखाता है कि कुछ अनजान वाक्यविन्यास है जो इसे कम चरणों में पूरा करेगा ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
फिर, पिछले विभाजन को छोड़कर सभी पर संग्रह संपीड़न डालने के लिए, मैंने निम्नलिखित को चलाया:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); अब, मैं इन तालिकाओं को डेटा के साथ भरने, लिए गए समय और परिणामी आकार को मापने और तुलना करने के लिए तैयार था। मैंने एंडी मॉलन से एक सहायक बैचिंग स्क्रिप्ट को संशोधित किया, और पंक्तियों को क्रमिक रूप से दोनों तालिकाओं में सम्मिलित किया, जिसमें 10 मिलियन पंक्तियों का बैच आकार था। वास्तविक लिपि में इसके अलावा और भी बहुत कुछ है (प्रगति के साथ एक कतार तालिका को अद्यतन करने सहित), लेकिन मूल रूप से:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END मूल (असंपीड़ित) स्रोत से दोनों कॉलमस्टोर टेबल को पॉप्युलेट करने के बाद, मैंने किसी भी पंक्ति समूह और शब्दकोश गड़बड़ी को साफ करने के लिए उन विभाजनों को फिर से बनाया। अंत में, मैंने स्रोत तालिका में पृष्ठ संपीड़न लागू किया। यहां प्रत्येक प्रकार के समय और संपीड़न परिणाम दिए गए थे:
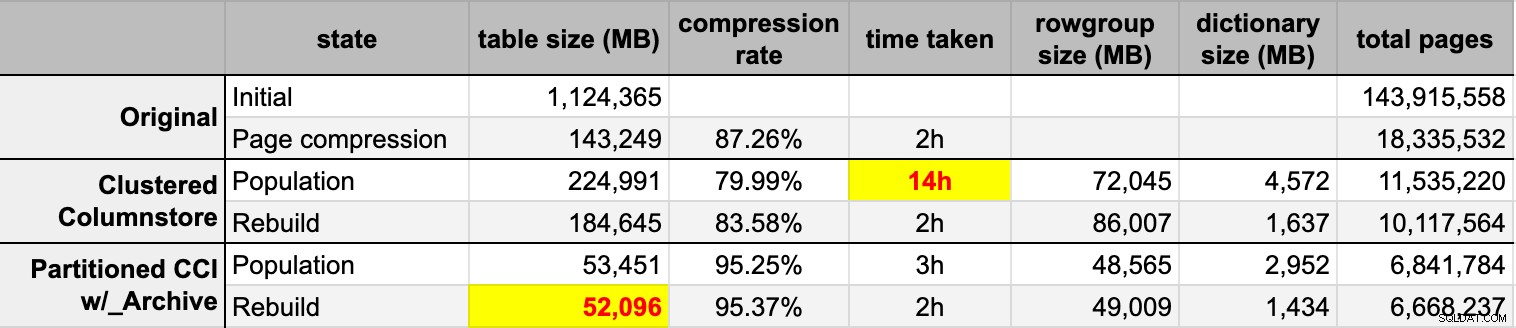
मैं प्रभावित और निराश दोनों हूं। प्रभावित हुआ क्योंकि यह डेटा वास्तव में अच्छी तरह से संकुचित होता है - स्टोरेज फुटप्रिंट को मूल 1TB के 5% तक कम करना आश्चर्यजनक है। निराश क्योंकि:
- मैंने उन डेटा फ़ाइलों को रास्ता बनाया है बहुत बड़ा।
- मुझे समझ नहीं आया कि 14 घंटे के प्रारंभिक कॉलमस्टोर कम्प्रेशन के साथ क्या हुआ:
- मैंने कोई मेमोरी या लॉग प्रेशर नहीं देखा।
- कोई फ़ाइल वृद्धि ईवेंट नहीं थे।
- दुर्भाग्य से, मैंने प्रतीक्षा को ट्रैक करने के बारे में नहीं सोचा। नहीं, मैं इसे दोबारा कोशिश नहीं करने जा रहा हूं। :-)
- पेज कम्प्रेशन ने नियमित कॉलमस्टोर कम्प्रेशन से बेहतर प्रदर्शन किया - शायद डेटा के कारण।
- कॉलमस्टोर संग्रह विभाजन के पुनर्निर्माण ने लगभग शून्य लाभ के लिए बहुत अधिक CPU समय का उपयोग किया।
आगामी पोस्टों में, और पास शिखर सम्मेलन में जो ओबिश द्वारा एक अद्भुत कॉलमस्टोर प्रस्तुति से मेरे नोट्स की समीक्षा करने के बाद (जिसे मैं सीधे लिंक करूंगा, अगर केवल पास यूआई को जानता था), मैं उन परिवर्तनों के बारे में कुछ बात करूंगा जो मैं करूंगा सर्वर कॉन्फ़िगरेशन और मेरी जनसंख्या स्क्रिप्ट में यह देखने के लिए कि क्या मैं कॉलमस्टोर आबादी से बेहतर प्रदर्शन प्राप्त कर सकता हूं।
[ भाग 1 | भाग 2 | भाग 3 ]