जेपीए (जावा पर्सिस्टेंस एनोटेशन ) ऑब्जेक्ट-ओरिएंटेड डोमेन मॉडल और रिलेशनल डेटाबेस सिस्टम के बीच की खाई को पाटने के लिए जावा का मानक समाधान है। विचार यह है कि जावा कक्षाओं को संबंधपरक तालिकाओं और उन वर्गों के गुणों को तालिका में पंक्तियों में मैप करना है। यह एक ही प्रोग्रामिंग प्रतिमान के भीतर दो अलग-अलग तकनीकों को मूल रूप से सहयोग करके जावा कोडिंग के समग्र अनुभव के शब्दार्थ को बदल देता है। यह आलेख जावा में एक सिंहावलोकन और इसके सहायक कार्यान्वयन प्रदान करता है।
एक सिंहावलोकन
रिलेशनल डेटाबेस शायद कंप्यूटिंग में उपलब्ध सभी दृढ़ता तकनीकों में सबसे अधिक स्थिर हैं, न कि इससे जुड़ी सभी जटिलताओं के। ऐसा इसलिए है क्योंकि आज, तथाकथित "बड़े डेटा" के युग में भी, "नोएसक्यूएल" रिलेशनल डेटाबेस लगातार मांग और संपन्न हैं। रिलेशनल डेटाबेस केवल शब्दों से नहीं बल्कि वर्षों से अपने अस्तित्व से स्थिर तकनीक हैं। NoSQL उद्यम में बड़ी मात्रा में संरचित डेटा से निपटने के लिए अच्छा हो सकता है, लेकिन कई लेन-देन संबंधी कार्यभार को रिलेशनल डेटाबेस के माध्यम से बेहतर ढंग से नियंत्रित किया जाता है। साथ ही, रिलेशनल डेटाबेस से जुड़े कुछ बेहतरीन विश्लेषणात्मक उपकरण हैं।
रिलेशनल डेटाबेस के साथ संवाद करने के लिए, ANSI ने SQL . नामक एक भाषा का मानकीकरण किया है (संरचित क्वेरी भाषा ) इस भाषा में लिखे गए कथन का उपयोग डेटा को परिभाषित करने और उसमें हेर-फेर करने, दोनों के लिए किया जा सकता है। लेकिन, जावा से निपटने में एसक्यूएल की समस्या यह है कि उनके पास एक बेमेल वाक्य रचनात्मक संरचना है और मूल में बहुत अलग है, जिसका अर्थ है कि एसक्यूएल प्रक्रियात्मक है जबकि जावा ऑब्जेक्ट ओरिएंटेड है। इसलिए, एक कार्यशील समाधान की तलाश की जाती है ताकि जावा ऑब्जेक्ट ओरिएंटेड-वे में बोल सके और रिलेशनल डेटा बेस अभी भी एक दूसरे को समझने में सक्षम हो। जेपीए उस कॉल का उत्तर है और दोनों के बीच एक कार्यशील समाधान स्थापित करने के लिए तंत्र प्रदान करता है।
ऑब्जेक्ट मैपिंग से संबंधित
जावा प्रोग्राम JDBC . का उपयोग करके रिलेशनल डेटाबेस के साथ इंटरैक्ट करते हैं (जावा डेटाबेस कनेक्टिविटी ) एपीआई। एक JDBC ड्राइवर कनेक्टिविटी की कुंजी है और जावा प्रोग्राम को JDBC API का उपयोग करके उस डेटाबेस में हेरफेर करने की अनुमति देता है। एक बार कनेक्शन स्थापित हो जाने के बाद, जावा प्रोग्राम स्ट्रिंग . के रूप में SQL क्वेरी को सक्रिय करता है s बनाने, डालने, अपडेट करने और संचालन को हटाने के लिए संवाद करने के लिए। यह सभी व्यावहारिक उद्देश्यों के लिए पर्याप्त है, लेकिन जावा प्रोग्रामर के दृष्टिकोण से असुविधाजनक है। क्या होगा यदि रिलेशनल टेबल की संरचना को शुद्ध जावा कक्षाओं में फिर से तैयार किया जा सकता है और फिर आप उनसे सामान्य वस्तु-उन्मुख तरीके से निपट सकते हैं? एक संबंधपरक तालिका की संरचना एक सारणीबद्ध रूप में डेटा का तार्किक प्रतिनिधित्व है। तालिकाएँ इकाई विशेषताओं का वर्णन करने वाले स्तंभों से बनी होती हैं और पंक्तियाँ संस्थाओं का संग्रह होती हैं। उदाहरण के लिए, एक कर्मचारी तालिका में उनकी विशेषताओं के साथ निम्नलिखित निकाय हो सकते हैं।
| Emp_number | नाम | dept_no | वेतन | स्थान |
| 112233 | पीटर | 123 | 1200 | LA |
| 112244 | रे | 234 | 1300 | NY |
| 112255 | संदीप | 123 | 1400 | NJ |
| 112266 | कल्पना | 234 | 1100 | LA |
तालिका के भीतर प्राथमिक कुंजी (emp_number) द्वारा पंक्तियाँ अद्वितीय होती हैं; यह एक त्वरित खोज को सक्षम बनाता है। एक तालिका किसी कुंजी द्वारा एक या अधिक तालिकाओं से संबंधित हो सकती है, जैसे कि एक विदेशी कुंजी (dept_no), जो किसी अन्य तालिका में समकक्ष पंक्ति से संबंधित होती है।
जावा पर्सिस्टेंस 2.1 विनिर्देश के अनुसार, जेपीए स्कीमा पीढ़ी के लिए समर्थन जोड़ता है, रूपांतरण विधियों को टाइप करता है, प्रश्नों में इकाई ग्राफ का उपयोग करता है और ऑपरेशन, अनसिंक्रनाइज़्ड दृढ़ता संदर्भ, संग्रहीत प्रक्रिया आमंत्रण, और इकाई श्रोता वर्गों में इंजेक्शन लगाता है। इसमें जावा पर्सिस्टेंस क्वेरी लैंग्वेज, क्राइटेरिया एपीआई, और नेटिव क्वेश्चन की मैपिंग में एन्हांसमेंट भी शामिल हैं।
संक्षेप में, यह भ्रम प्रदान करने के लिए सब कुछ करता है कि संबंधपरक डेटाबेस से निपटने में कोई प्रक्रियात्मक हिस्सा नहीं है और सब कुछ वस्तु उन्मुख है।
जेपीए कार्यान्वयन
JPA जावा एप्लिकेशन में रिलेशनल डेटा मैनेजमेंट का वर्णन करता है। यह एक विनिर्देश है और इसके कई कार्यान्वयन हैं। कुछ लोकप्रिय कार्यान्वयन हाइबरनेट, एक्लिप्सलिंक, और अपाचे ओपनजेपीए हैं। जेपीए जावा कक्षाओं में एनोटेशन के माध्यम से या एक्सएमएल कॉन्फ़िगरेशन फ़ाइलों के माध्यम से मेटाडेटा को परिभाषित करता है। हालाँकि, हम मेटाडेटा का वर्णन करने के लिए XML और एनोटेशन दोनों का उपयोग कर सकते हैं। ऐसी स्थिति में, XML कॉन्फ़िगरेशन एनोटेशन को ओवरराइड कर देता है। यह उचित है क्योंकि एनोटेशन जावा कोड के साथ लिखे गए हैं, जबकि एक्सएमएल कॉन्फ़िगरेशन फ़ाइलें जावा कोड के बाहर हैं। इसलिए, बाद में, यदि कोई हो, मेटाडेटा में परिवर्तन करने की आवश्यकता है; एनोटेशन-आधारित कॉन्फ़िगरेशन के मामले में, इसे सीधे जावा कोड एक्सेस की आवश्यकता होती है। यह हमेशा संभव नहीं हो सकता है। ऐसे मामले में, हम मूल कोड में बदलाव के किसी भी संकेत के बिना XML फ़ाइल में नया या परिवर्तित मेटाडेटा कॉन्फ़िगरेशन लिख सकते हैं और अभी भी वांछित प्रभाव डाल सकते हैं। XML कॉन्फ़िगरेशन का उपयोग करने का यह लाभ है। हालांकि, एनोटेशन-आधारित कॉन्फ़िगरेशन उपयोग करने के लिए अधिक सुविधाजनक है और प्रोग्रामर के बीच लोकप्रिय विकल्प है।
- हाइबरनेट Red Hat के कारण सभी JPA कार्यान्वयनों में सबसे लोकप्रिय और सबसे उन्नत है। यह अपने स्वयं के ट्विक्स और अतिरिक्त सुविधाओं का उपयोग करता है जिनका उपयोग इसके जेपीए कार्यान्वयन के अतिरिक्त किया जा सकता है। इसमें उपयोगकर्ताओं का एक बड़ा समुदाय है और यह अच्छी तरह से प्रलेखित है। कुछ अतिरिक्त मालिकाना विशेषताएं बहु-किरायेदारी के लिए समर्थन हैं, प्रश्नों में असंबद्ध संस्थाओं में शामिल होना, टाइमस्टैम्प प्रबंधन, आदि।
- ग्रहण लिंक टॉपलिंक पर आधारित है और जेपीए संस्करणों का एक संदर्भ कार्यान्वयन है। यह कुछ दिलचस्प मालिकाना सुविधाओं के अलावा मानक जेपीए कार्यात्मकता प्रदान करता है, जैसे बहु-किरायेदारी से समर्थन, डेटाबेस परिवर्तन ईवेंट हैंडलिंग, और इसी तरह।
Java SE प्रोग्राम में JPA का उपयोग करना
जावा प्रोग्राम में जेपीए का उपयोग करने के लिए, आपको एक जेपीए प्रदाता जैसे हाइबरनेट या एक्लिप्सलिंक, या किसी अन्य पुस्तकालय की आवश्यकता होती है। साथ ही, आपको एक JDBC ड्राइवर की आवश्यकता है जो विशिष्ट रिलेशनल डेटाबेस से कनेक्ट हो। उदाहरण के लिए, निम्नलिखित कोड में, हमने निम्नलिखित पुस्तकालयों का उपयोग किया है:
- प्रदाता: एक्लिप्सलिंक
- JDBC ड्राइवर: MySQL (कनेक्टर/जे) के लिए JDBC ड्राइवर
हम दो तालिकाओं-कर्मचारी और विभाग के बीच एक-से-एक और एक-से-अनेक के बीच संबंध स्थापित करेंगे, जैसा कि निम्नलिखित ईईआर आरेख में दर्शाया गया है (चित्र 1 देखें)।
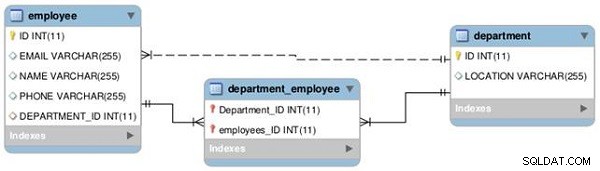
चित्र 1: टेबल संबंध
कर्मचारी तालिका को निम्नानुसार एनोटेशन का उपयोग करके एक इकाई वर्ग में मैप किया जाता है:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
और, विभाग तालिका को एक इकाई वर्ग में निम्नानुसार मैप किया जाता है:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
कॉन्फ़िगरेशन फ़ाइल, persistence.xml , META-INF . में बनाया गया है निर्देशिका। इस फ़ाइल में कनेक्शन कॉन्फ़िगरेशन, जैसे JDBC ड्राइवर का उपयोग, डेटाबेस एक्सेस के लिए उपयोगकर्ता नाम और पासवर्ड, और डेटाबेस कनेक्शन स्थापित करने के लिए JPA प्रदाता द्वारा आवश्यक अन्य प्रासंगिक जानकारी शामिल है।
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
संस्थाएं खुद को कायम नहीं रखती हैं। संस्थाओं को उनके निरंतर जीवन चक्र को प्रबंधित करने के लिए हेरफेर करने के लिए तर्क को लागू किया जाना चाहिए। इकाई प्रबंधक जेपीए द्वारा प्रदान किया गया इंटरफ़ेस एप्लिकेशन को रिलेशनल डेटाबेस में संस्थाओं को प्रबंधित करने और खोजने देता है। हम EntityManager . की मदद से एक क्वेरी ऑब्जेक्ट बनाते हैं डेटाबेस के साथ संवाद करने के लिए। EntityManager प्राप्त करने के लिए किसी दिए गए डेटाबेस के लिए, हम उस ऑब्जेक्ट का उपयोग करेंगे जो एक EntityManagerFactory . को लागू करता है इंटरफेस। एक स्थिर है विधि, जिसे createEntityManagerFactory . कहा जाता है , दृढ़ता . में वह वर्ग जो EntityManagerFactory returns लौटाता है स्ट्रिंग . के रूप में निर्दिष्ट दृढ़ता इकाई के लिए बहस। निम्नलिखित अल्पविकसित कार्यान्वयन में, हमने तर्क को लागू किया है।
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
अब, हम जाने और एप्लिकेशन का मुख्य इंटरफ़ेस बनाने के लिए तैयार हैं। यहां, हमने सरलता और स्थान की कमी के लिए केवल सम्मिलन ऑपरेशन लागू किया है।
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| नोट: पिछले कोड में प्रयुक्त एपीआई पर विस्तृत जानकारी के लिए कृपया उपयुक्त जावा एपीआई दस्तावेज देखें। |
निष्कर्ष
जैसा कि स्पष्ट होना चाहिए, जेपीए और दृढ़ता संदर्भ की मूल शब्दावली यहां दी गई झलक से अधिक विशाल है, लेकिन एक त्वरित अवलोकन के साथ शुरुआत करना लंबे जटिल गंदे कोड और उनके वैचारिक विवरण से बेहतर है। यदि आपके पास कोर JDBC में प्रोग्रामिंग का थोड़ा सा अनुभव है, तो आप निस्संदेह सराहना करेंगे कि कैसे JPA आपके जीवन को सरल बना सकता है। जैसे-जैसे हम आगामी लेखों में आगे बढ़ेंगे, हम धीरे-धीरे जेपीए में गहराई से उतरेंगे।