कुछ हफ़्ते पहले SQLskills टीम हमारे परफॉरमेंस ट्यूनिंग इमर्शन इवेंट (IE2) के लिए टैम्पा में थी और मैं बेसलाइन को कवर कर रहा था। बेसलाइन एक ऐसा विषय है जो मेरे दिल के करीब और प्रिय है, क्योंकि वे कई कारणों से बहुत मूल्यवान हैं। उन दो कारणों में से, जो मैं हमेशा बताता हूं कि क्या शिक्षण या ग्राहकों के साथ काम करना, प्रदर्शन के समस्या निवारण के लिए आधार रेखा का उपयोग कर रहा है, और फिर ट्रेंडिंग उपयोग और क्षमता नियोजन अनुमान प्रदान करना। लेकिन जब आप प्रदर्शन ट्यूनिंग या परीक्षण कर रहे हों तो वे भी आवश्यक होते हैं - चाहे आप अपने मौजूदा प्रदर्शन मीट्रिक को आधार रेखा मानते हों या नहीं।
मॉड्यूल के दौरान, मैंने प्रदर्शन मॉनिटर, डीएमवी, और ट्रेस या एक्सई डेटा जैसे डेटा के लिए विभिन्न स्रोतों की समीक्षा की, और डेटा लोड से संबंधित एक प्रश्न सामने आया। विशेष रूप से, सवाल यह था कि क्या डेटा को बिना किसी अनुक्रमणिका के तालिका में लोड करना बेहतर है, और फिर समाप्त होने पर उन्हें बनाना, बनाम डेटा लोड के दौरान अनुक्रमणिका रखना। मेरी प्रतिक्रिया थी, "आम तौर पर, हाँ"। मेरा व्यक्तिगत अनुभव यह रहा है कि यह हमेशा मामला होता है, लेकिन आप कभी नहीं जानते कि कोई व्यक्ति किस चेतावनी या एकतरफा परिदृश्य में भाग सकता है जहां प्रदर्शन परिवर्तन अपेक्षित नहीं था, और जैसा कि इसके साथ है सभी प्रदर्शन प्रश्न, आप निश्चित रूप से तब तक नहीं जानते जब तक आप इसका परीक्षण नहीं करते। जब तक आप एक विधि के लिए आधार रेखा स्थापित नहीं करते हैं और फिर देखते हैं कि उस आधार रेखा पर दूसरी विधि में सुधार होता है, तो आप केवल अनुमान लगा रहे हैं। मैंने सोचा कि परीक्षण करना मजेदार होगा। यह परिदृश्य, न केवल यह साबित करने के लिए कि मैं क्या सच होने की उम्मीद करता हूं, बल्कि यह भी दिखाने के लिए कि मैं किन मीट्रिक की जांच करूंगा, क्यों, और उन्हें कैसे कैप्चर करूंगा। यदि आपने पहले प्रदर्शन परीक्षण किया है, तो यह शायद पुरानी टोपी है। लेकिन उनके लिए आप अभ्यास के लिए नए हैं, मैं आपको आरंभ करने में मदद करने के लिए अपनाई जाने वाली प्रक्रिया के माध्यम से कदम उठाऊंगा। यह महसूस करें कि "कौन सी विधि बेहतर है?" का उत्तर प्राप्त करने के कई तरीके हैं। मुझे उम्मीद है कि आप इस प्रक्रिया को अपनाएंगे, इसमें बदलाव करेंगे और समय के साथ इसे अपना बना लेंगे।
आप क्या साबित करने की कोशिश कर रहे हैं?
पहला कदम यह तय करना है कि आप वास्तव में क्या परीक्षण कर रहे हैं। हमारे मामले में यह सीधा है:क्या डेटा को खाली तालिका में लोड करना तेज़ है, फिर इंडेक्स जोड़ें, या डेटा लोड के दौरान टेबल पर इंडेक्स रखना तेज़ है? लेकिन, अगर हम चाहें तो यहां कुछ बदलाव जोड़ सकते हैं। डेटा को एक हीप में लोड करने में लगने वाले समय पर विचार करें, और फिर क्लस्टर्ड और नॉनक्लस्टर इंडेक्स बनाएं, बनाम क्लस्टर इंडेक्स में डेटा लोड करने में लगने वाला समय, और फिर नॉनक्लस्टर इंडेक्स बनाएं। क्या प्रदर्शन में कोई अंतर है? क्या क्लस्टरिंग कुंजी एक कारक होगी? मुझे उम्मीद है कि डेटा लोड मौजूदा गैर-अनुक्रमित अनुक्रमणिका को खंडित कर देगा, इसलिए शायद मैं देखना चाहता हूं कि लोड के बाद कुल अवधि पर अनुक्रमणिका के पुनर्निर्माण पर क्या प्रभाव पड़ता है। जितना संभव हो सके इस चरण का दायरा महत्वपूर्ण है, और आप जो मापना चाहते हैं उसके बारे में बहुत विशिष्ट होना चाहिए, क्योंकि यह निर्धारित करेगा कि आप कौन सा डेटा कैप्चर करते हैं। हमारे उदाहरण के लिए, हमारे चार परीक्षण होंगे:
टेस्ट 1: डेटा को ढेर में लोड करें, क्लस्टर इंडेक्स बनाएं, गैर-क्लस्टर इंडेक्स बनाएं
टेस्ट 2: क्लस्टर इंडेक्स में डेटा लोड करें, गैर-क्लस्टर इंडेक्स बनाएं
टेस्ट 3: क्लस्टर इंडेक्स और गैर-क्लस्टर इंडेक्स बनाएं, डेटा लोड करें
टेस्ट 4: क्लस्टर्ड इंडेक्स और नॉनक्लस्टर इंडेक्स बनाएं, डेटा लोड करें, नॉनक्लस्टर इंडेक्स को फिर से बनाएं
आपको क्या जानना चाहिए?
हमारे परिदृश्य में, हमारा प्राथमिक प्रश्न है "कौन सी विधि सबसे तेज़ है"? इसलिए, हम अवधि को मापना चाहते हैं और ऐसा करने के लिए हमें प्रारंभ समय और समाप्ति समय को कैप्चर करने की आवश्यकता है। हम इसे उस पर छोड़ सकते हैं, लेकिन हम यह समझना चाहते हैं कि प्रत्येक विधि के लिए संसाधन उपयोग कैसा दिखता है, या शायद हम उच्चतम प्रतीक्षा, या लेनदेन की संख्या, या गतिरोध की संख्या जानना चाहते हैं। सबसे दिलचस्प और प्रासंगिक डेटा इस बात पर निर्भर करेगा कि आप किन प्रक्रियाओं की तुलना कर रहे हैं। हमारे डेटा लोड के लिए लेन-देन की संख्या को कैप्चर करना उतना दिलचस्प नहीं है; लेकिन एक कोड परिवर्तन के लिए यह हो सकता है। क्योंकि हम अनुक्रमणिका बना रहे हैं और उनका पुनर्निर्माण कर रहे हैं, मुझे इस बात में दिलचस्पी है कि प्रत्येक विधि कितना IO उत्पन्न करती है। जबकि समग्र अवधि शायद अंत में निर्णायक कारक है, IO को देखना न केवल यह समझने के लिए उपयोगी हो सकता है कि कौन सा विकल्प सबसे अधिक IO उत्पन्न करता है, बल्कि यह भी कि क्या डेटाबेस संग्रहण अपेक्षा के अनुरूप प्रदर्शन कर रहा है।
आपको आवश्यक डेटा कहां है?
एक बार जब आप यह निर्धारित कर लें कि आपको कौन सा डेटा चाहिए, तो तय करें कि इसे कहां से कैप्चर किया जाएगा। हम अवधि में रुचि रखते हैं, इसलिए हम उस समय को रिकॉर्ड करना चाहते हैं जब प्रत्येक डेटा लोड परीक्षण शुरू होता है, और जब यह समाप्त होता है। हम IO में भी रुचि रखते हैं, और हम इस डेटा को कई स्थानों से खींच सकते हैं - प्रदर्शन मॉनिटर काउंटर और sys.dm_io_virtual_file_stats DMV दिमाग में आते हैं।
समझें कि हम यह डेटा मैन्युअल रूप से प्राप्त कर सकते हैं। परीक्षण चलाने से पहले, हम sys.dm_io_virtual_file_stats के विरुद्ध चयन कर सकते हैं और वर्तमान मानों को एक फ़ाइल में सहेज सकते हैं। हम समय नोट कर सकते हैं, और फिर परीक्षण शुरू कर सकते हैं। जब यह समाप्त हो जाता है, तो हम फिर से समय नोट करते हैं, sys.dm_io_virtual_file_stats को फिर से क्वेरी करते हैं और IO को मापने के लिए मानों के बीच अंतर की गणना करते हैं।
इस पद्धति में कई खामियां हैं, अर्थात् यह त्रुटि के लिए महत्वपूर्ण जगह छोड़ती है; क्या होगा यदि आप प्रारंभ समय नोट करना भूल जाते हैं, या शुरू करने से पहले फ़ाइल आँकड़े कैप्चर करना भूल जाते हैं? एक बेहतर उपाय यह है कि न केवल स्क्रिप्ट के निष्पादन को स्वचालित किया जाए, बल्कि डेटा कैप्चर भी किया जाए। उदाहरण के लिए, हम एक तालिका बना सकते हैं जिसमें हमारी परीक्षण जानकारी होती है - परीक्षण क्या है, यह किस समय शुरू हुआ, और यह किस समय पूरा हुआ, इसका विवरण। हम उसी तालिका में फ़ाइल आँकड़े शामिल कर सकते हैं। यदि हम अन्य मीट्रिक एकत्रित कर रहे हैं, तो हम उन्हें तालिका में जोड़ सकते हैं। या, हमारे द्वारा कैप्चर किए गए डेटा के प्रत्येक सेट के लिए एक अलग तालिका बनाना आसान हो सकता है। उदाहरण के लिए, यदि हम फ़ाइल आँकड़े डेटा को एक अलग तालिका में संग्रहीत करते हैं, तो हमें प्रत्येक परीक्षण को एक विशिष्ट आईडी देने की आवश्यकता होती है, ताकि हम अपने परीक्षण को सही फ़ाइल आँकड़े डेटा के साथ मिला सकें। फ़ाइल आँकड़ों को कैप्चर करते समय, हमें शुरू करने से पहले, और फिर बाद में, और अंतर की गणना करने से पहले हमारे डेटाबेस के लिए मानों को कैप्चर करना होगा। फिर हम उस जानकारी को अद्वितीय परीक्षण आईडी के साथ उसकी अपनी तालिका में संग्रहीत कर सकते हैं।
एक नमूना अभ्यास
इस परीक्षण के लिए मैंने Sales.SalesOrderHeader तालिका की एक खाली प्रतिलिपि बनाई जिसका नाम Sales.Big_SalesOrderHeader है, और मैंने लगभग 25,000 पंक्तियों के बैचों में तालिका में डेटा लोड करने के लिए अपनी विभाजन पोस्ट में उपयोग की गई एक स्क्रिप्ट की विविधता का उपयोग किया। आप यहां डेटा लोड के लिए स्क्रिप्ट डाउनलोड कर सकते हैं। मैंने इसे प्रत्येक भिन्नता के लिए चार बार चलाया, और मैंने सम्मिलित पंक्तियों की कुल संख्या में भी बदलाव किया। परीक्षणों के पहले सेट के लिए मैंने 20 मिलियन पंक्तियां डालीं, और दूसरे सेट के लिए मैंने 60 मिलियन पंक्तियां डालीं। अवधि डेटा आश्चर्यजनक नहीं है:
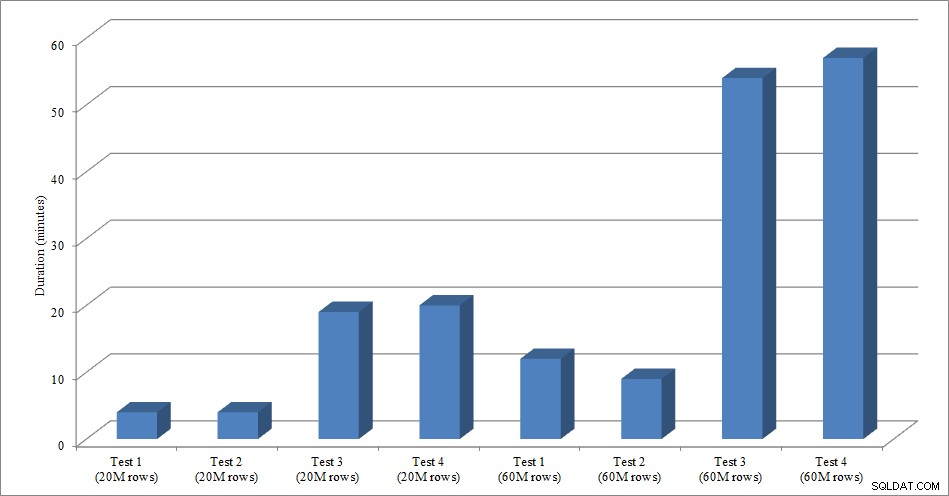
डेटा लोड अवधि
गैर-संकुल अनुक्रमणिका के बिना डेटा लोड करना, पहले से मौजूद गैर-संकुल अनुक्रमणिका के साथ लोड करने की तुलना में बहुत तेज़ है। मुझे जो दिलचस्प लगा वह यह है कि 20 मिलियन पंक्तियों के भार के लिए, टेस्ट 1 और टेस्ट 2 के बीच की कुल अवधि लगभग समान थी, लेकिन 60 मिलियन पंक्तियों को लोड करते समय टेस्ट 2 तेज था। हमारे परीक्षण में, हमारी क्लस्टरिंग कुंजी SalesOrderID थी, जो एक पहचान है और इसलिए हमारे लोड के लिए एक अच्छी क्लस्टरिंग कुंजी है क्योंकि यह आरोही है। अगर हमारे पास एक क्लस्टरिंग कुंजी थी जो इसके बजाय एक GUID थी, तो यादृच्छिक सम्मिलन और पृष्ठ विभाजन (एक और भिन्नता जिसे हम परीक्षण कर सकते थे) के कारण लोड समय अधिक हो सकता है।
क्या आईओ डेटा अवधि डेटा में प्रवृत्ति की नकल करता है? हां, इंडेक्स के पहले से मौजूद होने या न होने के अंतर के साथ, और भी अधिक अतिरंजित:
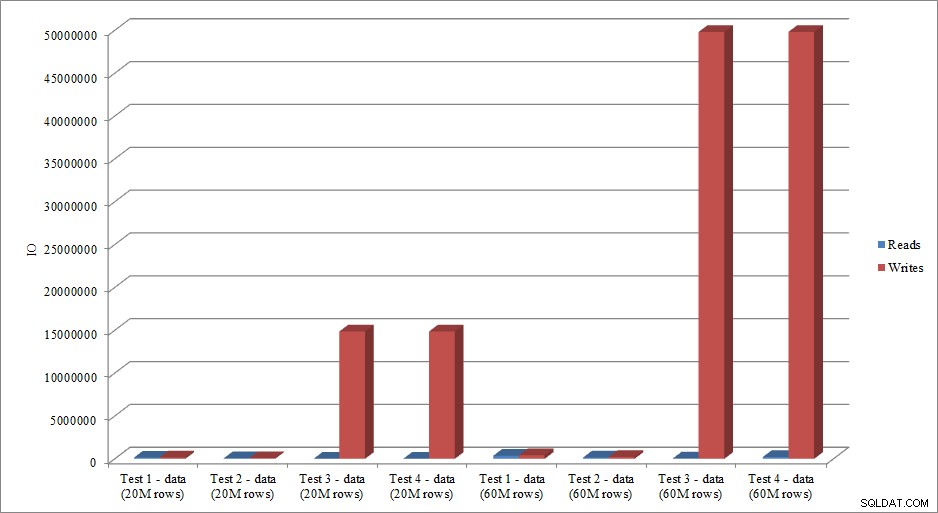
डेटा लोड पढ़ता और लिखता है
प्रदर्शन परीक्षण, या कोड, डिज़ाइन आदि में संशोधनों के आधार पर प्रदर्शन में परिवर्तन को मापने के लिए मैंने जो विधि प्रस्तुत की है, वह आधारभूत जानकारी को कैप्चर करने के लिए सिर्फ एक विकल्प है। कुछ परिदृश्यों में, यह अधिक हो सकता है। यदि आपके पास एक क्वेरी है जिसे आप ट्यून करने का प्रयास कर रहे हैं, तो डेटा कैप्चर करने के लिए इस प्रक्रिया को सेट करने से क्वेरी में बदलाव करने में अधिक समय लग सकता है! यदि आपने किसी भी मात्रा में क्वेरी ट्यूनिंग की है, तो संभवतः आप क्वेरी प्लान के साथ-साथ STATISTICS IO और STATISTICS TIME डेटा कैप्चर करने की आदत में हैं, और फिर जब आप परिवर्तन करते हैं तो आउटपुट की तुलना करते हैं। मैं इसे वर्षों से कर रहा हूं, लेकिन मैंने हाल ही में एक बेहतर तरीका खोजा है… SQL संतरी योजना एक्सप्लोरर प्रो। वास्तव में, जब मैंने ऊपर वर्णित सभी लोड परीक्षण को पूरा कर लिया, तो मैंने पीई के माध्यम से अपने परीक्षणों को फिर से चलाया और पाया, और पाया कि मैं अपने डेटा संग्रह तालिकाओं को सेट किए बिना अपनी इच्छित जानकारी को कैप्चर कर सकता हूं।
प्लान एक्सप्लोरर प्रो के भीतर आपके पास वास्तविक योजना प्राप्त करने का विकल्प है - पीई चयनित इंस्टेंस और डेटाबेस के खिलाफ क्वेरी चलाएगा, और योजना वापस कर देगा। और इसके साथ, आप अन्य सभी महान डेटा प्राप्त करते हैं जो पीई प्रदान करता है (समय के आंकड़े, पढ़ता है और लिखता है, तालिका द्वारा आईओ), साथ ही प्रतीक्षा आंकड़े, जो एक अच्छा लाभ है। हमारे उदाहरण का उपयोग करते हुए, मैंने पहले परीक्षण के साथ शुरुआत की - ढेर बनाना, डेटा लोड करना और फिर क्लस्टर इंडेक्स और गैर-क्लस्टर इंडेक्स जोड़ना - और फिर विकल्प वास्तविक योजना प्राप्त करें। जब यह पूरा हो गया तो मैंने अपनी स्क्रिप्ट टेस्ट 2 को संशोधित किया, फिर से वास्तविक योजना प्राप्त करें विकल्प चलाया। मैंने इसे तीसरे और चौथे परीक्षण के लिए दोहराया, और जब मैं समाप्त कर चुका, तो मेरे पास यह था:
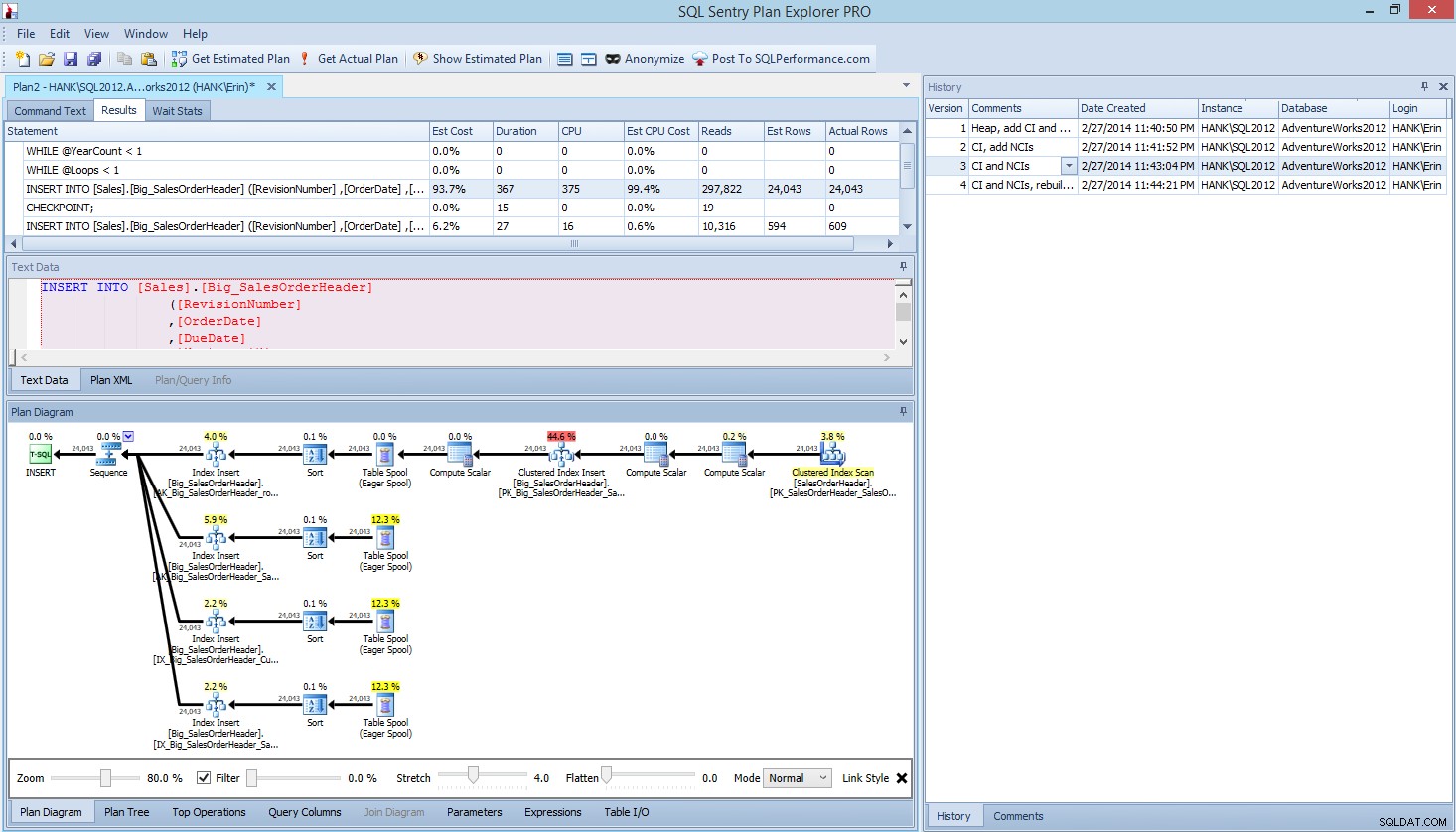
चार परीक्षण चलाने के बाद Explorer PRO व्यू की योजना बनाएं
दाहिनी ओर इतिहास फलक पर ध्यान दें? हर बार जब मैंने अपना कोड संशोधित किया और वास्तविक योजना को पुनः प्राप्त किया, तो इसने जानकारी का एक नया सेट सहेजा। मेरे पास इस डेटा को मेरी टीम के किसी अन्य सदस्य के साथ साझा करने के लिए एक .pession फ़ाइल के रूप में सहेजने की क्षमता है, या बाद में वापस जाकर विभिन्न परीक्षणों के माध्यम से स्क्रॉल करें, और आवश्यकतानुसार बैच के भीतर विभिन्न कथनों में ड्रिल करें, विभिन्न मैट्रिक्स को देखते हुए अवधि, सीपीयू और आईओ के रूप में। ऊपर दिए गए स्क्रीन शॉट में, मैंने टेस्ट 3 से INSERT को हाइलाइट किया है, और क्वेरी प्लान सभी चार गैर-संकुल इंडेक्स के अपडेट दिखाता है।
सारांश
SQL सर्वर में इतने सारे कार्यों की तरह, जब आप प्रदर्शन परीक्षण चला रहे हों या ट्यूनिंग कर रहे हों, तो डेटा को कैप्चर करने और उसकी समीक्षा करने के कई तरीके हैं। आपको जितना कम मैन्युअल प्रयास करना होगा, उतना ही बेहतर होगा, क्योंकि यह वास्तव में परिवर्तन करने, प्रभाव को समझने और फिर अपने अगले कार्य पर आगे बढ़ने के लिए अधिक समय छोड़ता है। चाहे आप डेटा कैप्चर करने के लिए किसी स्क्रिप्ट को कस्टमाइज़ करें, या किसी तृतीय पक्ष उपयोगिता को आपके लिए करने दें, मेरे द्वारा बताए गए चरण अभी भी मान्य हैं:
- परिभाषित करें कि आप क्या सुधारना चाहते हैं
- अपने परीक्षण का दायरा
- निर्धारित करें कि सुधार को मापने के लिए किस डेटा का उपयोग किया जा सकता है
- तय करें कि डेटा कैसे कैप्चर किया जाए
- जब भी संभव हो, परीक्षण और कैप्चर के लिए एक स्वचालित विधि सेट करें
- आवश्यकतानुसार परीक्षण करें, मूल्यांकन करें और दोहराएं
हैप्पी टेस्टिंग!