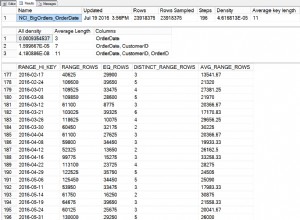
अधिक उत्पादन टी-एसक्यूएल कोड निहित धारणा के साथ लिखा गया है कि निष्पादन के दौरान अंतर्निहित डेटा नहीं बदलेगा। जैसा कि हमने इस श्रृंखला के पिछले लेख में देखा था, यह एक असुरक्षित धारणा है क्योंकि डेटा और इंडेक्स प्रविष्टियां हमारे नीचे घूम सकती हैं, यहां तक कि एक स्टेटमेंट के निष्पादन के दौरान भी।
जहां टी-एसक्यूएल प्रोग्रामर को अन्य प्रक्रियाओं द्वारा समवर्ती डेटा संशोधनों के कारण उत्पन्न होने वाली शुद्धता और डेटा अखंडता के मुद्दों के बारे में पता है, सबसे आम तौर पर पेश किया जाने वाला समाधान लेनदेन में कमजोर बयानों को लपेटना है। यह स्पष्ट नहीं है कि एक ही तरह के तर्क को एकल-कथन मामले पर कैसे लागू किया जाएगा, जो पहले से ही डिफ़ॉल्ट रूप से एक ऑटो-प्रतिबद्ध लेनदेन में लिपटा हुआ है।
एक सेकंड के लिए इसे छोड़कर, लेनदेन के साथ टी-एसक्यूएल कोड के एक महत्वपूर्ण क्षेत्र की रक्षा करने का विचार एसीआईडी लेनदेन गुणों द्वारा प्रदान की जाने वाली सुरक्षा की गलतफहमी पर आधारित है। वर्तमान चर्चा के लिए उस संक्षिप्त नाम का महत्वपूर्ण तत्व है अलगाव संपत्ति। विचार यह है कि लेन-देन का उपयोग स्वचालित रूप से अन्य समवर्ती गतिविधियों के प्रभावों से पूर्ण अलगाव प्रदान करता है।
इस मामले की सच्चाई यह है कि SERIALIZABLE . से नीचे के लेन-देन केवल डिग्री . प्रदान करें अलगाव, जो वर्तमान में प्रभावी लेनदेन अलगाव स्तर पर निर्भर करता है। यह समझने के लिए कि हमारे दैनिक T . के लिए इसका क्या अर्थ है SQL कोडिंग प्रथाओं, हम पहले क्रमबद्ध अलगाव स्तर पर एक विस्तृत नज़र डालेंगे।
धारावाहिक अलगाव
Serializable मानक लेनदेन अलगाव स्तरों में सबसे अलग है। यह डिफ़ॉल्ट . भी है एसक्यूएल मानक द्वारा निर्दिष्ट अलगाव स्तर, हालांकि एसक्यूएल सर्वर (अधिकांश वाणिज्यिक डेटाबेस सिस्टम की तरह) इस संबंध में मानक से अलग है। SQL सर्वर में डिफॉल्ट आइसोलेशन लेवल कमिटेड पढ़ा जाता है, एक निचला आइसोलेशन लेवल जिसे हम बाद में सीरीज में एक्सप्लोर करेंगे।
SQL-92 मानक में क्रमबद्ध अलगाव स्तर की परिभाषा में निम्नलिखित पाठ शामिल हैं (जोर मेरा):
<ब्लॉकक्वॉट>एक क्रमिक निष्पादन को समवर्ती रूप से निष्पादित SQL-लेन-देन के संचालन के निष्पादन के रूप में परिभाषित किया जाता है जो कुछ सीरियल निष्पादन के समान प्रभाव उत्पन्न करता है उन्हीं SQL-लेनदेनों में से। एक सीरियल निष्पादन वह है जिसमें प्रत्येक SQL-लेन-देन अगले SQL-लेन-देन शुरू होने से पहले पूरा होने के लिए निष्पादित होता है।
वास्तव में धारावाहिक . के बीच यहां एक महत्वपूर्ण अंतर करना है निष्पादन (जहां प्रत्येक लेनदेन वास्तव में अगले एक शुरू होने से पहले पूरा होने के लिए विशेष रूप से चलता है) और धारावाहिक अलगाव, जहां लेनदेन के लिए केवल वही प्रभाव होना आवश्यक है जैसे कि उन्हें क्रमिक रूप से (कुछ अनिर्दिष्ट क्रम में) निष्पादित किया गया था।
इसे दूसरे तरीके से रखने के लिए, वास्तविक डेटाबेस सिस्टम को भौतिक रूप से ओवरलैप . करने की अनुमति है समय पर क्रमबद्ध लेनदेन का निष्पादन (जिससे संगामिति बढ़ रही है) जब तक उन लेनदेन के प्रभाव अभी भी धारावाहिक निष्पादन के कुछ संभावित क्रम के अनुरूप हैं। दूसरे शब्दों में, क्रमानुसार लेन-देन संभावित क्रमानुसार हैं वास्तव में क्रमबद्ध . होने के बजाय ।
तार्किक रूप से क्रमानुसार लेन-देन
एक पल के लिए सभी भौतिक विचारों (जैसे लॉक करना) को छोड़ दें, और केवल दो समवर्ती क्रमिक लेनदेन के तार्किक प्रसंस्करण के बारे में सोचें।
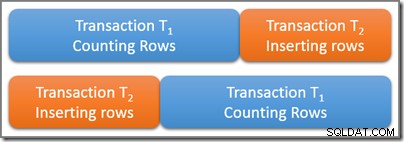
एक तालिका पर विचार करें जिसमें बड़ी संख्या में पंक्तियाँ हैं, जिनमें से पाँच कुछ दिलचस्प क्वेरी विधेय को संतुष्ट करने के लिए होती हैं। क्रमानुसार लेन-देन T1 इस विधेय से मेल खाने वाली तालिका में पंक्तियों की संख्या गिनना शुरू कर देता है। T1 . के कुछ समय बाद शुरू होता है, लेकिन इसके शुरू होने से पहले, दूसरा क्रमिक लेन-देन T2 शुरू होता है। लेन-देन टी<उप>2 चार नई पंक्तियाँ जोड़ता है जो तालिका के लिए विधेय क्वेरी को भी संतुष्ट करता है, और कमिट करता है। नीचे दिया गया चित्र घटनाओं का समय क्रम दिखाता है:

सवाल यह है, श्रृंखला लेनदेन T1 . में क्वेरी कितनी पंक्तियों में होनी चाहिए गिनती? याद रखें कि हम यहां पूरी तरह से तार्किक आवश्यकताओं के बारे में सोच रहे हैं, इसलिए यह सोचने से बचें कि कौन से ताले लिए जा सकते हैं और इसी तरह।
दो लेन-देन भौतिक रूप से समय पर ओवरलैप होते हैं, जो ठीक है। सीरियल करने योग्य अलगाव के लिए केवल यह आवश्यक है कि इन दो लेनदेन के परिणाम कुछ संभावित सीरियल निष्पादन के अनुरूप हों। लेन-देन के तार्किक सीरियल शेड्यूल के लिए स्पष्ट रूप से दो संभावनाएं हैं T1 और टी<उप>2 :
पहले संभावित सीरियल शेड्यूल का उपयोग करना (T1 फिर टी<उप>2 ) टी<उप>1 काउंटिंग क्वेरी में पांच पंक्तियाँ दिखाई देंगी , क्योंकि दूसरा लेनदेन तब तक शुरू नहीं होता जब तक कि पहला पूरा नहीं हो जाता। दूसरे संभावित तार्किक शेड्यूल का उपयोग करते हुए, T1 क्वेरी नौ पंक्तियों की गणना करेगी , क्योंकि चार-पंक्ति सम्मिलन गिनती लेनदेन शुरू होने से पहले तार्किक रूप से पूरा हो गया था।
क्रमबद्ध अलगाव के तहत दोनों उत्तर तार्किक रूप से सही हैं। इसके अलावा, कोई अन्य उत्तर संभव नहीं है (इसलिए लेनदेन टी1 उदाहरण के लिए, सात पंक्तियों की गिनती नहीं कर सका)। वास्तव में देखे जाने वाले दो संभावित परिणामों में से कौन सा सटीक समय और उपयोग में डेटाबेस इंजन के लिए विशिष्ट कार्यान्वयन विवरण पर निर्भर करता है।
ध्यान दें कि हम यह निष्कर्ष नहीं निकाल रहे हैं कि लेन-देन वास्तव में किसी तरह समय पर पुन:व्यवस्थित किए गए हैं। भौतिक निष्पादन ओवरलैप करने के लिए स्वतंत्र है जैसा कि पहले आरेख में दिखाया गया है, जब तक कि डेटाबेस इंजन यह सुनिश्चित करता है कि परिणाम दो संभावित धारावाहिक अनुक्रमों में से एक में निष्पादित होने पर क्या होता।
धारावाहिक और समवर्ती घटना
तार्किक क्रमांकन के अलावा, SQL मानक में यह भी उल्लेख किया गया है कि क्रमिक अलगाव स्तर पर चल रहे लेनदेन को कुछ समवर्ती घटनाओं का अनुभव नहीं करना चाहिए। इसे अप्रतिबद्ध डेटा नहीं पढ़ना चाहिए (कोई गंदा पढ़ा नहीं ); और एक बार डेटा पढ़ लेने के बाद, उसी ऑपरेशन को दोहराने से ठीक उसी डेटा का सेट वापस आना चाहिए (दोहराए जाने योग्य रीड बिना किसी प्रेत . के )।
मानक यह कहने का एक बिंदु बनाता है कि उन समवर्ती घटनाओं को क्रमिक अलगाव स्तर पर प्रत्यक्ष परिणाम के रूप में बाहर रखा गया है लेन-देन को तार्किक रूप से क्रमबद्ध करने की आवश्यकता है। दूसरे शब्दों में, क्रमबद्धता की आवश्यकता अपने आप में पर्याप्त . है गंदे पढ़ने, गैर-दोहराने योग्य पढ़ने, और प्रेत समवर्ती घटना से बचने के लिए। इसके विपरीत, केवल तीन समवर्ती घटनाओं से बचना पर्याप्त नहीं . है क्रमबद्धता की गारंटी के लिए, जैसा कि हम जल्द ही देखेंगे।
सहज रूप से, क्रमबद्ध लेनदेन सभी समवर्ती-संबंधित घटनाओं से बचते हैं क्योंकि उन्हें कार्य करने की आवश्यकता होती है जैसे कि उन्होंने पूर्ण अलगाव में निष्पादित किया था। इस मायने में, सीरियल करने योग्य लेन-देन अलगाव स्तर टी-एसक्यूएल प्रोग्रामर की सामान्य अपेक्षाओं से काफी निकटता से मेल खाता है।
सीरियल करने योग्य कार्यान्वयन
SQL सर्वर क्रमिक अलगाव स्तर के लॉकिंग कार्यान्वयन का उपयोग करने के लिए होता है, जहां भौतिक ताले प्राप्त किए जाते हैं और आयोजित लेन-देन के अंत तक (इसलिए पदावनत तालिका संकेत HOLDLOCK SERIALIZABLE . के पर्यायवाची के रूप में )।
यह रणनीति पूर्ण क्रमिकता की तकनीकी गारंटी प्रदान करने के लिए पर्याप्त नहीं है, क्योंकि लेन-देन द्वारा पहले संसाधित की गई पंक्तियों की एक श्रृंखला में नया या परिवर्तित डेटा दिखाई दे सकता है। इस समवर्ती घटना को एक प्रेत के रूप में जाना जाता है, और इसके परिणामस्वरूप ऐसे प्रभाव हो सकते हैं जो किसी भी सीरियल शेड्यूल में नहीं हो सकते थे।
प्रेत समवर्ती घटना से सुरक्षा सुनिश्चित करने के लिए, SQL सर्वर द्वारा क्रमिक अलगाव स्तर पर लिए गए लॉक में की-रेंज लॉकिंग भी शामिल हो सकता है। नई या बदली हुई पंक्तियों को पहले से जांचे गए इंडेक्स कुंजी मानों के बीच प्रदर्शित होने से रोकने के लिए। रेंज लॉक हमेशा नहीं होते हैं क्रमिक अलगाव स्तर के तहत अधिग्रहित; हम सामान्य रूप से केवल इतना कह सकते हैं कि SQL सर्वर हमेशा क्रमिक अलगाव स्तर की तार्किक आवश्यकताओं को पूरा करने के लिए पर्याप्त ताले प्राप्त करता है। वास्तव में, लॉकिंग कार्यान्वयन अक्सर अधिक प्राप्त करते हैं, और सख्त, ताले वास्तव में क्रमिकता की गारंटी के लिए आवश्यक होते हैं, लेकिन मैं पीछे हट जाता हूं।
लॉकिंग धारावाहिक अलगाव स्तर के संभावित भौतिक कार्यान्वयन में से एक है। हमें SQL सर्वर लॉकिंग कार्यान्वयन के विशिष्ट व्यवहारों को क्रमबद्ध करने योग्य की तार्किक परिभाषा से मानसिक रूप से अलग करने के लिए सावधान रहना चाहिए।
एक वैकल्पिक भौतिक रणनीति के उदाहरण के रूप में, सीरियल करने योग्य स्नैपशॉट अलगाव के PostgreSQL कार्यान्वयन को देखें, हालांकि यह सिर्फ एक विकल्प है। प्रत्येक अलग-अलग भौतिक कार्यान्वयन की अपनी ताकत और कमजोरियां होती हैं। एक तरफ, ध्यान दें कि ओरेकल अभी भी धारावाहिक अलगाव स्तर का पूरी तरह से अनुपालन कार्यान्वयन प्रदान नहीं करता है। इसका एक आइसोलेशन स्तर नाम . है सीरियल करने योग्य, लेकिन यह वास्तव में गारंटी नहीं देता है कि लेनदेन कुछ संभावित सीरियल शेड्यूल के अनुसार निष्पादित होंगे। इसके बजाय Oracle स्नैपशॉट आइसोलेशन प्रदान करता है जब क्रमबद्ध करने योग्य अनुरोध किया जाता है, ठीक उसी तरह जैसे PostgreSQL ने धारावाहिक स्नैपशॉट अलगाव से पहले किया था (SSI ) लागू किया गया था।
स्नैपशॉट अलगाव समवर्ती विसंगतियों को रोकता नहीं है जैसे कि तिरछा लिखना, जो वास्तव में क्रमिक अलगाव के तहत संभव नहीं है। यदि आप रुचि रखते हैं, तो आप ऊपर SSI लिंक पर स्नैपशॉट अलगाव द्वारा अनुमत लेखन तिरछा और अन्य समवर्ती प्रभावों के उदाहरण पा सकते हैं। हम बाद में श्रृंखला में स्नैपशॉट अलगाव स्तर के SQL सर्वर कार्यान्वयन पर भी चर्चा करेंगे।
एक समय-समय पर दृश्य?
तार्किक क्रमिकता और शारीरिक रूप से क्रमबद्ध निष्पादन के बीच अंतर के बारे में बात करने में मैंने समय बिताया है, यह गारंटी देना आसान है जो वास्तव में मौजूद नहीं हो सकता है। उदाहरण के लिए, यदि आप क्रमानुसार लेन-देन को वास्तव में . मानते हैं एक के बाद एक को क्रियान्वित करते हुए, आप अनुमान लगा सकते हैं कि क्रमानुसार लेन-देन आवश्यक रूप से डेटाबेस को उसी रूप में देखेगा, जैसा कि वह लेन-देन की शुरुआत में मौजूद था, एक बिंदु-समय दृश्य प्रदान करता है।
वास्तव में, यह एक कार्यान्वयन-विशिष्ट विवरण है। पिछले उदाहरण को याद करें, जहां क्रमिक लेनदेन T1 वैध रूप से पाँच या नौ पंक्तियों की गिनती कर सकता है। यदि नौ की गिनती लौटा दी जाती है, तो पहला लेन-देन स्पष्ट रूप से उन पंक्तियों को देखता है जो लेन-देन शुरू होने के समय मौजूद नहीं थीं। यह परिणाम SQL सर्वर में संभव है लेकिन PostgreSQL SSI में नहीं, हालांकि दोनों कार्यान्वयन क्रमिक अलगाव स्तर के लिए निर्दिष्ट तार्किक व्यवहारों का अनुपालन करते हैं।
SQL सर्वर में, सीरियल करने योग्य लेन-देन आवश्यक रूप से डेटा को नहीं देखते हैं क्योंकि यह लेनदेन की शुरुआत में मौजूद था। इसके बजाय, SQL सर्वर कार्यान्वयन के विवरण का अर्थ है कि एक क्रमबद्ध लेनदेन नवीनतम प्रतिबद्ध डेटा देखता है, जिस क्षण डेटा को पहले एक्सेस के लिए लॉक किया गया था। इसके अलावा, अंतिम रूप से पढ़े गए नवीनतम-प्रतिबद्ध डेटा के सेट की गारंटी है कि लेन-देन समाप्त होने से पहले इसकी सदस्यता नहीं बदलेगी।
अगली बार
इस श्रृंखला का अगला भाग पुनरावर्तनीय पठन आइसोलेशन स्तर की जांच करता है, जो सीरियल करने योग्य की तुलना में कमजोर लेनदेन अलगाव गारंटी प्रदान करता है।
[ पूरी श्रृंखला के लिए सूचकांक देखें ]