धारावाहिक अलगाव स्तर पूर्ण सुरक्षा प्रदान करता है समवर्ती प्रभावों से जो डेटा अखंडता को खतरा पैदा कर सकते हैं और गलत क्वेरी परिणाम दे सकते हैं। क्रमिक अलगाव का उपयोग करने का अर्थ है कि यदि कोई लेन-देन जिसे बिना समवर्ती गतिविधि के सही परिणाम देने के लिए दिखाया जा सकता है, तो समवर्ती लेनदेन के किसी भी संयोजन के साथ प्रतिस्पर्धा करते समय यह सही ढंग से प्रदर्शन करना जारी रखेगा।
यह एक बहुत ही शक्तिशाली गारंटी है , और एक जो संभवतः कई टी-एसक्यूएल प्रोग्रामर की सहज लेनदेन अलगाव अपेक्षाओं से मेल खाता है (हालांकि वास्तव में, इनमें से अपेक्षाकृत कुछ उत्पादन में नियमित रूप से क्रमिक अलगाव का उपयोग करेंगे)।
SQL मानक तीन अतिरिक्त आइसोलेशन स्तरों को परिभाषित करता है जो बहुत कमजोर ACID . प्रदान करते हैं क्रमिक रूप से उच्च संगामिति और कम संभावित साइड-इफेक्ट्स जैसे ब्लॉकिंग, डेडलॉकिंग और कमिट-टाइम एबॉर्ट्स के बदले में सीरियल करने योग्य की तुलना में अलगाव की गारंटी।
क्रमिक अलगाव के विपरीत, अन्य अलगाव स्तरों को पूरी तरह से कुछ समवर्ती घटनाओं के संदर्भ में परिभाषित किया जाता है जिन्हें देखा जा सकता है। क्रमबद्ध करने योग्य के बाद अगले सबसे मजबूत मानक अलगाव स्तरों का नाम दोहराए जाने योग्य पठनीय . है . SQL मानक निर्दिष्ट करता है कि इस स्तर पर लेन-देन एक एकल समवर्ती घटना की अनुमति देता है जिसे प्रेत के रूप में जाना जाता है ।
जिस तरह हमने पहले एसीआईडी लेनदेन गुणों और वास्तविकता के सामान्य सहज अर्थ के बीच महत्वपूर्ण अंतर देखा है, प्रेत घटना व्यवहार की एक विस्तृत श्रृंखला को शामिल करती है जिसे अक्सर सराहा जाता है।
श्रृंखला में यह पोस्ट दोहराए जाने योग्य पढ़ने . द्वारा प्रदान की गई वास्तविक गारंटी को देखता है अलगाव स्तर, और कुछ प्रेत-संबंधित व्यवहारों को दिखाता है जिनका सामना किया जा सकता है। कुछ बिंदुओं को स्पष्ट करने के लिए, हम निम्नलिखित सरल उदाहरण क्वेरी का उल्लेख करेंगे, जहां सरल कार्य तालिका में पंक्तियों की कुल संख्या की गणना करना है:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
दोहराने योग्य पढ़ें
दोहराने योग्य पढ़ने के अलगाव स्तर के बारे में एक अजीब बात यह है कि यह नहीं . करता है वास्तव में गारंटी है कि पढ़ना दोहराने योग्य . है , कम से कम एक सामान्य रूप से समझे जाने वाले अर्थ में। यह एक और उदाहरण है जहां केवल सहज ज्ञान युक्त अर्थ भ्रामक हो सकता है। एक ही बार-बार पढ़े जाने वाले लेन-देन में एक ही क्वेरी को दो बार निष्पादित करने से वास्तव में अलग-अलग परिणाम मिल सकते हैं।
इसके अलावा, दोहराए जाने योग्य रीड के SQL सर्वर कार्यान्वयन का अर्थ है कि डेटा के एक सेट का एकल रीड कुछ पंक्तियों को याद कर सकता है क्वेरी परिणाम में तार्किक रूप से विचार किया जाना चाहिए। निर्विवाद रूप से कार्यान्वयन-विशिष्ट होने पर, यह व्यवहार पूरी तरह से SQL मानक में निहित दोहराने योग्य पढ़ने की परिभाषा के अनुरूप है।
आखिरी बात जो मैं विवरण में जाने से पहले जल्दी से नोट करना चाहता हूं, वह यह है कि SQL सर्वर में दोहराए जाने योग्य रीड नहीं करता है डेटा का पॉइंट-इन-टाइम दृश्य प्रदान करें।
गैर-दोहराए जाने योग्य पठन
दोहराए जाने योग्य पठन अलगाव स्तर एक गारंटी प्रदान करता है कि डेटा नहीं बदलेगा लेन-देन के जीवन के लिए एक बार इसे पढ़ लेने के बाद पहली बार।
उस परिभाषा में कुछ सूक्ष्मताएँ निहित हैं। सबसे पहले, यह डेटा को बाद . बदलने की अनुमति देता है लेन-देन शुरू होता है लेकिन इससे पहले कि डेटा पहले हो पहुँचा। दूसरा, इस बात की कोई गारंटी नहीं है कि लेन-देन वास्तव में तार्किक रूप से योग्य सभी डेटा का सामना करेगा। हम जल्द ही इन दोनों के उदाहरण देखेंगे।
एक अन्य प्रारंभिक है जिसे हमें जल्दी से बाहर निकलने की आवश्यकता है, वह है उस उदाहरण क्वेरी से जिसका हम उपयोग करेंगे। निष्पक्षता में, इस प्रश्न के शब्दार्थ थोड़े अस्पष्ट हैं। थोड़ा दार्शनिक लगने के जोखिम पर, इसका क्या मतलब है मतलब तालिका में पंक्तियों की संख्या गिनने के लिए? क्या परिणाम तालिका की स्थिति को प्रतिबिंबित करना चाहिए जैसा कि यह किसी विशेष समय पर था? क्या यह समय लेन-देन की शुरुआत या अंत होना चाहिए, या कुछ और?
यह थोड़ा अटपटा लग सकता है, लेकिन यह सवाल किसी भी डेटाबेस में मान्य है जो समवर्ती डेटा को पढ़ने और संशोधनों का समर्थन करता है। हमारी उदाहरण क्वेरी को निष्पादित करने में मनमाने ढंग से लंबा समय लग सकता है (उदाहरण के लिए पर्याप्त बड़ी तालिका या संसाधन की कमी को देखते हुए) इसलिए समवर्ती परिवर्तन न केवल संभव हैं, वे अपरिहार्य हो सकते हैं ।
यहां मूलभूत मुद्दा समवर्ती घटना की संभावना है जिसे प्रेत . कहा जाता है एसक्यूएल मानक में। जब हम तालिका में पंक्तियों की गणना कर रहे हैं, एक अन्य समवर्ती लेनदेन नई पंक्तियाँ सम्मिलित कर सकता है उस स्थान पर जिसे हमने पहले ही चेक कर लिया है, या बदलें एक पंक्ति जिसे हमने अभी तक इस तरह से जांचा नहीं है कि वह उस स्थान पर चली जाती है जिसे हम पहले ही देख चुके हैं। लोग अक्सर प्रेत को पंक्तियों के रूप में सोचते हैं जो एक अलग कथन में दूसरी बार पढ़ने पर जादुई रूप से प्रकट हो सकते हैं, लेकिन प्रभाव उससे कहीं अधिक सूक्ष्म हो सकते हैं।
समवर्ती सम्मिलन उदाहरण
यह पहला उदाहरण दिखाता है कि कैसे समवर्ती सम्मिलन गैर-दोहराए जाने योग्य . उत्पन्न कर सकते हैं पढ़ें और/या परिणाम पंक्तियों को छोड़ दिया जा रहा है। कल्पना करें कि हमारी परीक्षण तालिका में प्रारंभ में पांच पंक्तियां हैं नीचे दिखाए गए मानों के साथ:

अब हम आइसोलेशन लेवल को रिपीटेबल रीड पर सेट करते हैं, ट्रांजैक्शन शुरू करते हैं और काउंटिंग क्वेरी चलाते हैं। जैसा कि आप उम्मीद करेंगे, परिणाम पांच . है . अब तक कोई बड़ा रहस्य नहीं है।
अभी भी उसी दोहराए जा सकने वाले रीड लेन-देन . के अंदर निष्पादित किया जा रहा है , हम फिर से गिनती क्वेरी चलाते हैं, लेकिन इस बार जब दूसरा समवर्ती लेनदेन उसी तालिका में नई पंक्तियों को सम्मिलित कर रहा है। नीचे दिया गया आरेख घटनाओं के क्रम को दिखाता है, दूसरे लेन-देन में 2 और 6 मान वाली पंक्तियों को जोड़ने के साथ (आपने देखा होगा कि ये मान उनकी अनुपस्थिति के ठीक ऊपर थे):
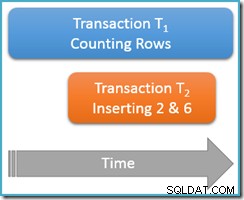
अगर हमारी गिनती क्वेरी serializable . पर चल रही थी अलगाव स्तर, यह या तो पांच count की गणना करने की गारंटी होगी या सात पंक्तियाँ (इस श्रृंखला में पिछला लेख देखें यदि आपको पुनश्चर्या की आवश्यकता है कि ऐसा क्यों है)। कम पृथक . पर दौड़ना कैसा होता है दोहराने योग्य पढ़ने का स्तर चीजों को प्रभावित करता है?
खैर, दोहराया जा सकता है आइसोलेशन गारंटी देता है कि काउंटिंग क्वेरी के दूसरे रन में पहले पढ़ी गई सभी पंक्तियाँ दिखाई देंगी, और वे पहले की तरह ही स्थिति में होंगी। पकड़ यह है कि बार-बार पढ़ने योग्य अलगाव कुछ नहीं says कहता है लेन-देन को नई पंक्तियों (प्रेत) के साथ कैसा व्यवहार करना चाहिए, इसके बारे में।
कल्पना कीजिए कि हमारा पंक्ति-गणना लेनदेन (T1 .) ) में एक भौतिक निष्पादन रणनीति है जहां पंक्तियों को आरोही अनुक्रमणिका क्रम में खोजा जाता है। यह एक सामान्य मामला है, उदाहरण के लिए जब निष्पादन इंजन द्वारा फॉरवर्ड-ऑर्डर किए गए बी-ट्री इंडेक्स स्कैन को नियोजित किया जाता है। अब, लेन-देन के ठीक बाद T1 पंक्तियों 1 और 3 को आरोही क्रम में गिनता है, लेन-देन T2 घुस सकता है, नई पंक्तियाँ 2 और 6 सम्मिलित कर सकता है, और फिर उसका लेन-देन कर सकता है।
हालांकि हम मुख्य रूप से इस बिंदु पर तार्किक व्यवहार के बारे में सोच रहे हैं, मुझे यह उल्लेख करना चाहिए कि SQL सर्वर लॉकिंग कार्यान्वयन में कुछ भी नहीं है जिसे दोहराने योग्य रोकें को पढ़ा जा सके। लेन-देन टी<उप>2 ऐसा करने से। लेन-देन T1 . द्वारा लिए गए साझा ताले पहले पढ़ी गई पंक्तियों पर उन पंक्तियों को बदलने से रोकते हैं, लेकिन वे नई पंक्तियों को नहीं रोकते हैं हमारी गिनती क्वेरी द्वारा परीक्षण किए गए मानों की श्रेणी में सम्मिलित होने से (क्रमिक अलगाव को लॉक करने में कुंजी-श्रेणी के ताले के विपरीत)।
वैसे भी, प्रतिबद्ध दो नई पंक्तियों के साथ, लेनदेन T1 अपनी आरोही-क्रम खोज जारी रखता है, अंततः 4, 5, 6, और 7 पंक्तियों का सामना करता है। ध्यान दें कि T1 इस परिदृश्य में नई पंक्ति 6 देखता है, लेकिन नहीं नई पंक्ति 2 (आदेशित खोज के कारण, और डालने पर उसकी स्थिति के कारण)।
नतीजा यह है कि दोहराने योग्य पढ़ा क्वेरी रिपोर्ट की गणना करना कि तालिका में छह पंक्तियाँ हैं (मान 1, 3, 4, 5, 6 और 7)। यह परिणाम पांच पंक्तियों . के पिछले परिणाम से असंगत है उसी लेन-देन . के अंदर प्राप्त किया गया . दूसरी पढ़ी गई फैंटम पंक्ति 6 की गणना की गई लेकिन प्रेत पंक्ति 2 को याद किया गया। दोहराने योग्य पढ़ने के सहज अर्थ के लिए बहुत कुछ!
समवर्ती अपडेट उदाहरण
समवर्ती अपडेट . के साथ भी ऐसी ही स्थिति उत्पन्न हो सकती है डालने के बजाय। कल्पना कीजिए कि हमारी परीक्षण तालिका पहले की तरह ही पांच पंक्तियों को समाहित करने के लिए रीसेट कर दी गई है:

इस बार, हम केवल अपनी गणना क्वेरी एक बार चलाएंगे दोहराए जाने योग्य पठन . पर अलगाव स्तर, जबकि दूसरा समवर्ती लेन-देन 2 के मान के लिए पंक्ति को 5 मान के साथ अद्यतन करता है:
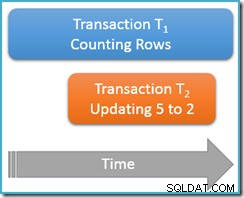
लेन-देन टी<उप>1 फिर से पंक्तियों की गिनती शुरू करता है, (आरोही क्रम में) पहले पंक्तियों 1 और 3 का सामना करता है। अब, लेन-देन T2 में फिसल जाता है, पंक्ति 5 से 2 का मान बदलता है और प्रतिबद्ध होता है:

मैंने परिवर्तन को स्पष्ट करने के लिए अद्यतन पंक्ति को उसी स्थिति में दिखाया है, लेकिन हम जिस बी-ट्री इंडेक्स को स्कैन कर रहे हैं वह डेटा को तार्किक क्रम में रखता है, इसलिए वास्तविक तस्वीर इसके करीब है:

बात यह है कि लेन-देन T1 आगे के क्रम में इसी संरचना को समवर्ती रूप से स्कैन कर रहा है, वर्तमान में केवल बाद . स्थित किया जा रहा है मान 3 के लिए प्रविष्टि। गिनती क्वेरी उस बिंदु से आगे स्कैन करना जारी रखती है, पंक्तियों 4 और 7 को ढूंढती है (लेकिन निश्चित रूप से पंक्ति 5 नहीं)।
संक्षेप में, गणना क्वेरी ने इस परिदृश्य में पंक्तियाँ 1, 3, 4 और 7 देखीं। यह चार पंक्तियों . की गिनती की रिपोर्ट करता है - जो अजीब है, क्योंकि ऐसा लगता है कि तालिका में पांच पंक्तियां हैं भर में!
एक ही दोहराने योग्य पठन लेन-देन के भीतर गिनती क्वेरी का दूसरा भाग पांच . की रिपोर्ट करेगा पंक्तियाँ, पहले की तरह ही कारणों से। अंतिम नोट के रूप में, यदि आप सोच रहे हैं, तो समवर्ती विलोपन दोहराए जाने योग्य पठन अलगाव के तहत एक प्रेत-आधारित विसंगति का अवसर प्रदान नहीं करते हैं।
अंतिम विचार
पिछले उदाहरण दोनों में एक इंडेक्स संरचना के आरोही क्रम स्कैन का इस्तेमाल किया गया था ताकि एक दोहराए जाने योग्य-पढ़ने योग्य पर प्रेत के प्रभावों का एक सरल दृश्य प्रस्तुत किया जा सके। सवाल। यह समझना महत्वपूर्ण है कि ये दृष्टांत किसी भी महत्वपूर्ण तरीके से स्कैन दिशा या इस तथ्य पर निर्भर नहीं करते हैं कि बी-ट्री इंडेक्स का उपयोग किया गया था। कृपया नहीं करें इस विचार का निर्माण करें कि आदेशित स्कैन किसी तरह जिम्मेदार हैं और इसलिए इससे बचा जाना चाहिए!
एक ही समवर्ती प्रभाव एक सूचकांक संरचना के अवरोही-क्रम स्कैन के साथ, या अन्य भौतिक डेटा एक्सेस परिदृश्यों की एक किस्म में देखा जा सकता है। व्यापक बिंदु यह है कि प्रेत घटना को विशेष रूप से एसक्यूएल मानक द्वारा अलगाव के दोहराने योग्य पढ़ने के स्तर पर लेनदेन के लिए अनुमति दी जाती है (हालांकि आवश्यक नहीं)।
सभी लेन-देन के लिए क्रमिक अलगाव द्वारा प्रदान की गई पूर्ण अलगाव गारंटी की आवश्यकता नहीं होती है, और यदि वे ऐसा करते हैं तो कई सिस्टम साइड इफेक्ट को सहन नहीं कर सकते हैं। फिर भी, यह अच्छी तरह से समझने के लिए भुगतान करता है कि विभिन्न अलगाव स्तरों की गारंटी कौन देता है।
अगली बार
इस श्रृंखला का अगला भाग SQL सर्वर के डिफ़ॉल्ट आइसोलेशन स्तर द्वारा प्रदान की जाने वाली और भी कमजोर आइसोलेशन गारंटियों को देखता है, प्रतिबद्ध पढ़ें ।
[ पूरी श्रृंखला के लिए सूचकांक देखें ]