प्रतिबद्ध पढ़ें दूसरा सबसे कमजोर . है SQL मानक द्वारा परिभाषित चार अलगाव स्तरों में से। फिर भी, यह SQL सर्वर सहित कई डेटाबेस इंजनों के लिए डिफ़ॉल्ट आइसोलेशन स्तर है। आइसोलेशन स्तर और लेन-देन के एसीआईडी गुणों के बारे में श्रृंखला में यह पोस्ट वास्तव में रीड कमिटेड आइसोलेशन द्वारा प्रदान की गई तार्किक और भौतिक गारंटी को देखता है।
तार्किक गारंटी
SQL मानक के लिए आवश्यक है कि रीड कमिटेड आइसोलेशन के तहत चलने वाला लेन-देन केवल प्रतिबद्ध पढ़ता है जानकारी। यह एक गंदे पढ़ने के रूप में ज्ञात समवर्ती घटना को मना कर इस आवश्यकता को व्यक्त करता है। एक गंदा पठन तब होता है जब एक लेन-देन उस डेटा को पढ़ता है जो किसी अन्य लेनदेन द्वारा लिखा गया है, इससे पहले कि दूसरा लेनदेन पूरा हो। इसे व्यक्त करने का एक और तरीका यह है कि जब कोई लेन-देन अप्रतिबद्ध डेटा पढ़ता है, तो एक गंदा पठन होता है।
मानक में यह भी उल्लेख किया गया है कि रीड कमिटेड आइसोलेशन पर चलने वाले लेन-देन को समवर्ती घटना का सामना करना पड़ सकता है जिसे नॉन-रिपीटेबल रीड्स के रूप में जाना जाता है। और प्रेत . हालांकि कई पुस्तकें इन घटनाओं की व्याख्या इस संदर्भ में करती हैं कि यदि डेटा को बाद में फिर से पढ़ा जाता है तो लेन-देन में बदलाव या नए डेटा आइटम देखने में सक्षम होते हैं, यह स्पष्टीकरण गलतफहमी को पुष्ट कर सकता है कि समवर्ती घटना केवल एक स्पष्ट लेनदेन के अंदर हो सकती है जिसमें कई कथन होते हैं। ऐसा नहीं है। एक एकल कथन स्पष्ट लेन-देन के बिना गैर-दोहराए जाने योग्य पढ़ने और प्रेत घटना के लिए उतना ही कमजोर है, जैसा कि हम जल्द ही देखेंगे।
पढ़ने के लिए प्रतिबद्ध अलगाव के विषय पर सभी मानकों को इतना ही कहना है। पहली नज़र में, केवल प्रतिबद्ध डेटा पढ़ना समझदार व्यवहार की एक बहुत अच्छी गारंटी की तरह लगता है, लेकिन हमेशा की तरह शैतान विस्तार में है। जैसे ही आप संभावित खामियों की तलाश शुरू करते हैं इस परिभाषा में, ऐसे उदाहरणों को खोजना बहुत आसान हो जाता है जहां हमारे पढ़े गए प्रतिबद्ध लेनदेन हमारे अपेक्षित परिणाम नहीं दे सकते हैं। फिर से, हम इन पर एक या दो क्षण में और अधिक विस्तार से चर्चा करेंगे।
विभिन्न भौतिक कार्यान्वयन
कम से कम दो चीजें हैं जिसका मतलब है कि अलग-अलग डेटाबेस इंजनों पर पढ़े गए अलगाव स्तर का देखा गया व्यवहार काफी भिन्न हो सकता है। सबसे पहले, केवल प्रतिबद्ध डेटा को पढ़ने के लिए SQL मानक आवश्यकता नहीं अनिवार्य रूप से इसका मतलब है कि लेन-देन द्वारा पढ़ा गया प्रतिबद्ध डेटा सबसे हाल का . होगा प्रतिबद्ध डेटा।
एक डेटाबेस इंजन को अतीत के किसी भी बिंदु . से एक पंक्ति के प्रतिबद्ध संस्करण को पढ़ने की अनुमति है , और अभी भी SQL मानक परिभाषा का अनुपालन करते हैं। कई लोकप्रिय डेटाबेस उत्पाद इस तरह से प्रतिबद्ध अलगाव को लागू करते हैं। रीड कमिटेड आइसोलेशन के इस कार्यान्वयन के तहत प्राप्त क्वेरी परिणाम मनमाने ढंग से पुराने हो सकते हैं , जब डेटाबेस की वर्तमान प्रतिबद्ध स्थिति के साथ तुलना की जाती है। हम इस विषय को कवर करेंगे क्योंकि यह श्रृंखला की अगली पोस्ट में SQL सर्वर पर लागू होता है।
दूसरी बात मैं आपका ध्यान आकर्षित करना चाहता हूं कि SQL मानक परिभाषा नहीं . है किसी विशेष कार्यान्वयन को गंदे पढ़ने को रोकने से परे अतिरिक्त समवर्ती-प्रभाव सुरक्षा प्रदान करने से रोकें . मानक केवल यह निर्दिष्ट करता है कि गंदे पढ़ने की अनुमति नहीं है, इसके लिए यह आवश्यक नहीं है कि अन्य समवर्ती घटनाओं को अनुमति होना चाहिए किसी दिए गए अलगाव स्तर पर।
इस दूसरे बिंदु के बारे में स्पष्ट होने के लिए, एक मानक-संगत डेटाबेस इंजन serializable का उपयोग करके सभी अलगाव स्तरों को लागू कर सकता है। व्यवहार अगर ऐसा चुना है। कुछ प्रमुख वाणिज्यिक डेटाबेस इंजिन भी पठन प्रतिबद्ध का कार्यान्वयन प्रदान करते हैं जो केवल गंदे पठन को रोकने से परे है (हालांकि ACID में पूर्ण अलगाव प्रदान करने तक कोई भी नहीं जाता है। शब्द का अर्थ)।
इसके अलावा, कई लोकप्रिय उत्पादों के लिए, प्रतिबद्ध पढ़ें अलगाव निम्नतम है अलगाव स्तर उपलब्ध; पढ़ने के उनके कार्यान्वयन अप्रतिबद्ध अलगाव बिल्कुल वैसा ही है जैसा पढ़ा गया है। मानक द्वारा इसकी अनुमति है, लेकिन इस प्रकार के अंतर कोड को एक प्लेटफॉर्म से दूसरे प्लेटफॉर्म पर माइग्रेट करने के पहले से ही कठिन कार्य में जटिलता जोड़ते हैं। अलगाव स्तर के व्यवहार के बारे में बात करते समय, आमतौर पर विशेष मंच को भी निर्दिष्ट करना महत्वपूर्ण होता है।
जहां तक मुझे पता है, SQL सर्वर प्रमुख वाणिज्यिक डेटाबेस इंजनों में से एक है जो दो . प्रदान करता है पढ़ने के लिए प्रतिबद्ध अलगाव स्तर के कार्यान्वयन, प्रत्येक बहुत अलग शारीरिक व्यवहार के साथ। इस पोस्ट में इनमें से पहला शामिल है, लॉकिंग प्रतिबद्ध पढ़ें।
SQL सर्वर लॉकिंग प्रतिबद्ध पढ़ें
यदि डेटाबेस विकल्प READ_COMMITTED_SNAPSHOT OFF है , SQL सर्वर एक लॉकिंग . का उपयोग करता है पढ़ने के लिए प्रतिबद्ध अलगाव स्तर का कार्यान्वयन, जहां समवर्ती लेनदेन को समवर्ती रूप से डेटा को संशोधित करने से रोकने के लिए साझा ताले लिए जाते हैं, क्योंकि संशोधन के लिए एक विशेष लॉक की आवश्यकता होगी, जो साझा लॉक के साथ संगत नहीं है।
SQL सर्वर लॉकिंग कमिटेड और लॉकिंग रिपीटेबल रीड (जो डेटा पढ़ते समय साझा लॉक भी लेता है) के बीच महत्वपूर्ण अंतर यह है कि रीड कमिटेड साझा लॉक को जल्द से जल्द रिलीज़ करता है , जबकि दोहराने योग्य रीड इन तालों को संलग्न लेनदेन के अंत तक रखता है।
जब रीड कमिटेड लॉकिंग पंक्ति ग्रैन्युलैरिटी पर लॉक प्राप्त करता है, तो एक पंक्ति पर लिया गया साझा लॉक रिलीज़ होता है जब कोई साझा लॉक अगली पंक्ति . पर लिया जाता है . पेज ग्रैन्युलैरिटी पर, जब अगले पेज पर पहली पंक्ति पढ़ी जाती है, तो साझा पेज लॉक जारी किया जाता है, और इसी तरह। जब तक क्वेरी के साथ लॉक-ग्रैन्युलैरिटी संकेत प्रदान नहीं किया जाता है, तब तक डेटाबेस इंजन यह तय करता है कि किस स्तर की ग्रैन्युलैरिटी शुरू करनी है। ध्यान दें कि ग्रैन्युलैरिटी संकेतों को केवल इंजन द्वारा सुझावों के रूप में माना जाता है, अनुरोध की तुलना में कम दानेदार लॉक अभी भी शुरू में लिया जा सकता है। सिस्टम कॉन्फ़िगरेशन के आधार पर पंक्ति या पृष्ठ स्तर से विभाजन या तालिका स्तर तक निष्पादन के दौरान ताले को भी बढ़ाया जा सकता है।
यहां महत्वपूर्ण बात यह है कि साझा ताले आमतौर पर केवल बहुत कम समय . के लिए आयोजित किए जाते हैं जबकि कथन निष्पादित हो रहा है। एक आम ग़लतफ़हमी को स्पष्ट रूप से दूर करने के लिए, प्रतिबद्ध पढ़ने को लॉक करना नहीं स्टेटमेंट के अंत तक शेयर्ड लॉक को होल्ड करें।
पढ़ने के लिए प्रतिबद्ध व्यवहारों को लॉक करना
SQL सर्वर लॉकिंग प्रतिबद्ध कार्यान्वयन द्वारा उपयोग किए जाने वाले अल्पकालिक साझा लॉक टी-एसक्यूएल प्रोग्रामर द्वारा आमतौर पर डेटाबेस लेनदेन की अपेक्षा की जाने वाली बहुत कम गारंटी प्रदान करते हैं। विशेष रूप से, लॉकिंग के तहत चल रहा एक बयान प्रतिबद्ध पढ़ें अलगाव:
- एक ही पंक्ति का कई बार सामना कर सकते हैं;
- कुछ पंक्तियों को पूरी तरह से याद कर सकते हैं; और
- क्या नहीं एक पॉइंट-इन-टाइम व्यू provide प्रदान करें डेटा का
वह सूची उन अजीब व्यवहारों के विवरण की तरह लग सकती है जिन्हें आप NOLOCK के उपयोग से जोड़ सकते हैं संकेत, लेकिन ये सभी चीजें वास्तव में हो सकती हैं, और लॉकिंग रीड कमिटेड आइसोलेशन का उपयोग करते समय होती हैं।
उदाहरण
स्पष्ट सिंगल-स्टेटमेंट क्वेरी का उपयोग करके, तालिका में पंक्तियों को गिनने के सरल कार्य पर विचार करें। पंक्ति-लॉकिंग ग्रैन्युलैरिटी के साथ प्रतिबद्ध अलगाव को लॉक करने के तहत, हमारी क्वेरी पहली पंक्ति पर एक साझा लॉक लेगी, इसे पढ़ेगी, साझा लॉक जारी करेगी, अगली पंक्ति पर आगे बढ़ेगी, और इसी तरह जब तक यह संरचना के अंत तक नहीं पहुंच जाती पढ़ रहा है। इस उदाहरण के लिए, मान लें कि हमारी क्वेरी आरोही कुंजी क्रम में एक इंडेक्स बी-ट्री पढ़ रही है (हालांकि यह अवरोही क्रम, या किसी अन्य रणनीति का भी उपयोग कर सकती है)।
चूंकि केवल एक पंक्ति किसी भी समय शेयर-लॉक किया गया है, समवर्ती लेनदेन के लिए यह स्पष्ट रूप से संभव है कि हमारी क्वेरी ट्रैवर्सिंग इंडेक्स में अनलॉक पंक्तियों को संशोधित करे। यदि ये समवर्ती संशोधन इंडेक्स कुंजी मानों को बदलते हैं, तो वे पंक्तियों को इंडेक्स संरचना के भीतर घूमने का कारण बनेंगे। उस संभावना को ध्यान में रखते हुए, नीचे दिया गया चित्र दो समस्याग्रस्त परिदृश्यों को दिखाता है जो हो सकते हैं:
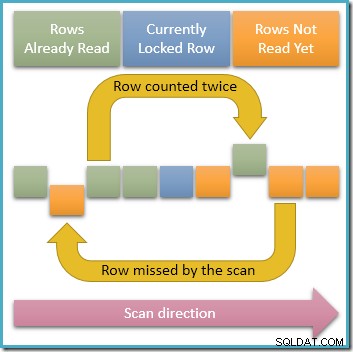
सबसे ऊपर वाला तीर एक पंक्ति दिखाता है जिसे हमने पहले ही गिन लिया है और इसकी अनुक्रमणिका कुंजी को समवर्ती रूप से संशोधित किया है ताकि पंक्ति अनुक्रमणिका में वर्तमान स्कैन स्थिति से आगे बढ़े, जिसका अर्थ है कि पंक्ति को दो बार गिना जाएगा . दूसरा तीर उस पंक्ति को दिखाता है जिसका सामना हमारे स्कैन ने अभी तक नहीं किया है, स्कैन स्थिति के पीछे चलती है, जिसका अर्थ है कि पंक्ति को गिना नहीं जाएगा बिल्कुल।
समय-समय पर दृश्य नहीं
पिछले खंड में दिखाया गया है कि कैसे लॉकिंग कमिटेड डेटा को पूरी तरह से याद कर सकता है, या एक ही आइटम को कई बार गिन सकता है (दो बार से अधिक, अगर हम बदकिस्मत हैं)। अनपेक्षित व्यवहारों की सूची में तीसरे बुलेट पॉइंट में कहा गया है कि लॉक किए गए पढ़ने से डेटा का पॉइंट-इन-टाइम व्यू भी नहीं मिलता है।
उस बयान के पीछे का तर्क अब देखना आसान होना चाहिए। उदाहरण के लिए, हमारी गणना क्वेरी, हमारी क्वेरी के निष्पादित होने के बाद समवर्ती लेनदेन द्वारा डाले गए डेटा को आसानी से पढ़ सकती है। समान रूप से, हमारी क्वेरी द्वारा देखे जाने वाले डेटा को हमारी क्वेरी शुरू होने के बाद और उसके पूरा होने से पहले समवर्ती गतिविधि द्वारा संशोधित किया जा सकता है। अंत में, हमारे द्वारा पढ़े और गिने गए डेटा को हमारी क्वेरी पूरी होने से पहले एक समवर्ती लेनदेन द्वारा हटाया जा सकता है।
स्पष्ट रूप से, किसी स्टेटमेंट या लेन-देन द्वारा देखे गए डेटा को लॉक किए गए प्रतिबद्ध अलगाव के तहत चल रहा है कोई एकल राज्य नहीं से मेल खाता है किसी विशेष समय पर . पर डेटाबेस का . हमें जो डेटा मिलता है वह समय के विभिन्न बिंदुओं से हो सकता है, एकमात्र सामान्य कारक यह है कि प्रत्येक आइटम उस डेटा के नवीनतम प्रतिबद्ध मूल्य का प्रतिनिधित्व करता है उस समय इसे पढ़ा गया था (हालाँकि यह शायद तब से बदल गया है या गायब हो गया है)।
ये समस्याएं कितनी गंभीर हैं?
यह सब मामलों की एक बहुत ही ऊनी स्थिति की तरह लग सकता है यदि आप अपने सिंगल-स्टेटमेंट प्रश्नों और स्पष्ट लेनदेन को तार्किक रूप से तत्काल निष्पादित करने के बारे में सोचने के लिए उपयोग किए जाते हैं, या डेटाबेस का उपयोग करते समय डेटाबेस की एकल प्रतिबद्ध बिंदु-समय-समय पर चल रहे हैं। डिफ़ॉल्ट SQL सर्वर अलगाव स्तर। यह निश्चित रूप से एसीआईडी अर्थ में अलगाव की अवधारणा के साथ अच्छी तरह से फिट नहीं है।
रीड कमिटेड आइसोलेशन को लॉक करके प्रदान की गई गारंटी की स्पष्ट कमजोरी को देखते हुए, आपको आश्चर्य हो सकता है कि कैसे कोई आपके उत्पादन के टी-एसक्यूएल कोड ने कभी ठीक से काम किया है! बेशक, हम यह स्वीकार कर सकते हैं कि सीरियल करने योग्य से नीचे के अलगाव स्तर का उपयोग करने का मतलब है कि हम अन्य संभावित लाभों के बदले में पूर्ण एसीआईडी लेनदेन अलगाव छोड़ देते हैं, लेकिन हम इन मुद्दों के व्यवहार में कितनी गंभीर उम्मीद कर सकते हैं?
अनुपलब्ध और दोहरी गणना वाली पंक्तियां
ये पहले दो मुद्दे अनिवार्य रूप से कुंजी changing को बदलने वाली समवर्ती गतिविधि पर निर्भर करते हैं एक इंडेक्स संरचना में जिसे हम वर्तमान में स्कैन कर रहे हैं। ध्यान दें कि स्कैन करना यहां इंडेक्स का आंशिक रेंज स्कैन भाग शामिल है तलाश , साथ ही परिचित अप्रतिबंधित अनुक्रमणिका या तालिका स्कैन।
यदि हम एक इंडेक्स संरचना को स्कैन कर रहे हैं (रेंज) जिसकी चाबियां आम तौर पर किसी समवर्ती गतिविधि द्वारा संशोधित नहीं की जाती हैं, तो इन पहले दो मुद्दों को व्यावहारिक समस्या नहीं होनी चाहिए। हालांकि इसके बारे में निश्चित होना मुश्किल है, क्योंकि क्वेरी प्लान एक अलग एक्सेस विधि का उपयोग करने के लिए बदल सकते हैं, और नए खोजे गए इंडेक्स में अस्थिर कुंजियां शामिल हो सकती हैं।
हमें यह भी ध्यान में रखना होगा कि कई उत्पादन प्रश्नों के लिए वास्तव में केवल अनुमानित . की आवश्यकता होती है या वैसे भी कुछ प्रकार के प्रश्नों का सर्वोत्तम प्रयास उत्तर। तथ्य यह है कि कुछ पंक्तियाँ गायब हैं या डबल-काउंटेड चीजों की व्यापक योजना में ज्यादा मायने नहीं रखती हैं। कई समवर्ती परिवर्तनों वाले सिस्टम पर, यह सुनिश्चित करना भी मुश्किल हो सकता है कि परिणाम था गलत है, यह देखते हुए कि डेटा इतनी बार बदलता है। उस तरह की स्थिति में, डेटा उपभोक्ता के उद्देश्यों के लिए मोटे तौर पर सही उत्तर काफी अच्छा हो सकता है।
कोई समय-समय पर दृश्य नहीं
तीसरा मुद्दा (तथाकथित 'सुसंगत' डेटा के समय-समय पर देखने का सवाल) भी उसी तरह के विचारों पर आता है। रिपोर्टिंग उद्देश्यों के लिए, जहां विसंगतियों के परिणामस्वरूप डेटा उपभोक्ताओं से अजीब प्रश्न होते हैं, एक स्नैपशॉट दृश्य अक्सर बेहतर होता है। अन्य मामलों में, डेटा के समय-समय पर दृश्य की कमी से उत्पन्न होने वाली विसंगतियों को अच्छी तरह से सहन किया जा सकता है।
समस्याग्रस्त परिदृश्य
ऐसे बहुत से मामले भी हैं जहां सूचीबद्ध चिंताएं होगी महत्वपूर्ण हो। उदाहरण के लिए, यदि आप कोड लिखते हैं जो व्यावसायिक नियमों . को लागू करता है टी-एसक्यूएल में, आपको शुद्धता की गारंटी के लिए अलगाव स्तर (या अन्य उपयुक्त कार्रवाई करने) का चयन करने के लिए सावधान रहना होगा। कई व्यावसायिक नियमों को विदेशी कुंजियों या बाधाओं का उपयोग करके लागू किया जा सकता है, जहां डेटाबेस इंजन द्वारा आपके लिए अलगाव स्तर चयन की पेचीदगियों को स्वचालित रूप से नियंत्रित किया जाता है। एक सामान्य नियम के रूप में, घोषणात्मक अखंडता . के अंतर्निर्मित सेट का उपयोग करना टी-एसक्यूएल में अपने स्वयं के नियम बनाने के लिए सुविधाएँ बेहतर हैं।
क्वेरी का एक और व्यापक वर्ग है जो प्रति से . एक व्यावसायिक नियम को पूरी तरह से लागू नहीं करता है , लेकिन फिर भी डिफ़ॉल्ट लॉकिंग रीड प्रतिबद्ध आइसोलेशन स्तर पर चलने पर इसके दुर्भाग्यपूर्ण परिणाम हो सकते हैं। ये परिदृश्य हमेशा उतने स्पष्ट नहीं होते जितने कि बैंक खातों के बीच धन के हस्तांतरण के अक्सर-उद्धृत उदाहरण, या यह सुनिश्चित करते हैं कि कई लिंक किए गए खातों में शेष राशि कभी भी शून्य से नीचे नहीं जाती है। उदाहरण के लिए, निम्नलिखित क्वेरी पर विचार करें जो अतिदेय चालानों को कुछ प्रक्रिया के इनपुट के रूप में पहचानती है जो कड़े शब्दों वाले अनुस्मारक पत्र भेजती है:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); स्पष्ट रूप से हम किसी ऐसे व्यक्ति को पत्र नहीं भेजना चाहेंगे जिसने किश्तों में अपने चालान का पूरा भुगतान किया था, केवल इसलिए कि हमारी क्वेरी के समय समवर्ती डेटाबेस गतिविधि का मतलब था कि हमने गलत राशि की गणना की थी प्राप्त भुगतानों का। वास्तविक उत्पादन प्रणालियों पर वास्तविक प्रश्न अक्सर ऊपर दिए गए सरल उदाहरण की तुलना में बहुत अधिक जटिल होते हैं।
आज के लिए समाप्त करने के लिए, निम्नलिखित प्रश्न पर एक नज़र डालें और देखें कि क्या आप देख सकते हैं कि अनपेक्षित रूप से कुछ होने के कितने अवसर हैं, यदि कई ऐसे प्रश्न एक साथ लॉकिंग रीड कमिटेड आइसोलेशन स्तर पर चल रहे हैं (शायद अन्य असंबंधित लेनदेन के दौरान) केस तालिका को भी संशोधित कर रहे हैं):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; एक बार जब आप उन सभी छोटे तरीकों की तलाश शुरू कर देते हैं जो इस अलगाव स्तर पर एक प्रश्न गलत हो सकते हैं, तो इसे रोकना मुश्किल हो सकता है। पूरी तरह से पृथक और समय-समय पर सटीक परिणामों की वास्तविक आवश्यकता के बारे में पहले बताई गई चेतावनियों को ध्यान में रखें। ऐसे प्रश्न पूछना पूरी तरह से ठीक है जो पर्याप्त अच्छे परिणाम देते हैं, जब तक आप उन ट्रेड-ऑफ के बारे में जानते हैं जो आप रीड कमिटेड का उपयोग करके कर रहे हैं।
अगली बार
इस श्रृंखला का अगला भाग SQL सर्वर में उपलब्ध रीड कमिटेड आइसोलेशन के दूसरे भौतिक कार्यान्वयन को देखता है, प्रतिबद्ध स्नैपशॉट आइसोलेशन पढ़ें।
[ पूरी श्रृंखला के लिए सूचकांक देखें ]