जैसे-जैसे छुट्टियां नजदीक आ रही हैं, सांता को दुनिया भर के बच्चों को उपहार देने के लिए कुछ अतिरिक्त मदद की जरूरत है। आज, हम एक डेटा मॉडल विकसित करेंगे जो सांता और उनके कल्पित बौने को अधिक कुशलता से काम करने में मदद कर सकता है।
पृष्ठभूमि
सांता का काम अत्यंत महत्वपूर्ण है, इसलिए उसे समय पर सफलता सुनिश्चित करने के लिए वह सब कुछ करने की जरूरत है जो वह कर सकता है। एक टर्बो मैन फिगर को खोजने की कोशिश में हॉवर्ड को 'जिंगल ऑल द वे' में जिन सभी समस्याओं का सामना करना पड़ा, उन्हें याद रखें- हम सांता को फिर से फिसलने नहीं दे सकते, या उनकी प्रतिष्ठा बर्बाद हो जाएगी। इसलिए, सांता को संगठित रहने में मदद करने के लिए, हम उसकी गतिविधियों को तीन मुख्य चरणों में विभाजित करेंगे।
-
योजना बनाना
सबसे पहले, सांता को सब कुछ योजना बनाने की जरूरत है। आखिरकार, वह अपने कल्पित बौने को कारखाने के चारों ओर दौड़ते हुए और घबराते हुए नहीं रख सकता क्योंकि वे अरबों प्रसव का मतलब निकालने की कोशिश करते हैं! इस वर्ष के पत्रों को पढ़ने और यह निर्धारित करने के अलावा कि बच्चों को कौन से उपहार पसंद आएंगे, हमें कुछ सामान्य सामग्रियों को इकट्ठा करने या समय से पहले उपहार देने के लिए पिछले वर्षों के किसी भी रुझान का विश्लेषण करना चाहिए। यह कुछ बैकलॉग को कम करने में मदद करेगा क्योंकि हम उत्पादन पर काम करना शुरू करते हैं।
-
उत्पादन
योजना चरण के बाद, हम उपहारों का उत्पादन शुरू करने के लिए तैयार हैं। सांता के कल्पित बौने की मदद से, हम प्राप्त इच्छा सूची के अनुसार जल्दी से उपहारों का निर्माण और पैकेज कर सकते हैं। प्रक्रिया को और अधिक कुशल बनाने के लिए, हालांकि, हमें अपने पास मौजूद सभी सामग्रियों और सूचनाओं को व्यवस्थित करने की आवश्यकता है ताकि कल्पित बौने जितनी जल्दी हो सके अपनी ज़रूरत की चीज़ों को हड़प सकें।
-
वितरण
पल जल्दी आ रहा है! सांता के बारहसिंगे तैयार हैं, और वह आदमी खुद उत्सुकता से अपनी घड़ी की जाँच कर रहा है। सांता के सहायकों द्वारा उपहारों को जल्दी से बेपहियों की गाड़ी में लोड किया जा रहा है। इस बिंदु पर, सांता अपने शेड्यूल पर अंतिम नज़र डाल रहा है ताकि यह सुनिश्चित हो सके कि उसके पास सभी सही पते हैं, साथ ही साथ किसी भी नोट पर विचार करने की आवश्यकता होगी।
अब जबकि हमारे पास इस बारे में कुछ पृष्ठभूमि है कि हमें किस तरह की जानकारी के साथ काम करना होगा, हम अंततः सांता के डेटा मॉडल को डिजाइन करना शुरू कर सकते हैं।
डेटा मॉडल
इस डेटा मॉडल में तीन खंड होते हैं:
- आइटम
- व्यक्तियों और इच्छा सूची
- डिलीवरी
आइए इनमें से प्रत्येक पर करीब से नज़र डालें।
अनुभाग 1:आइटम
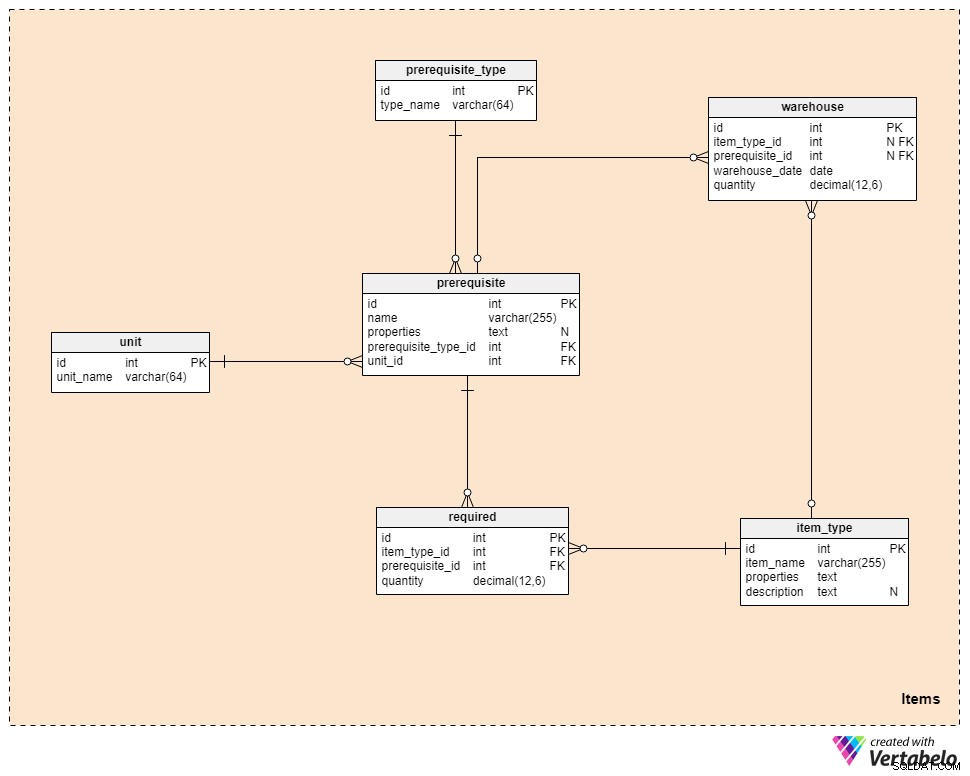
हमारा डेटा मॉडल आइटम सेक्शन से शुरू होता है, जिसमें कई टेबल होते हैं जो बाकी दो सेक्शन के बीच में होते हैं।
item_type तालिका यकीनन यहाँ सबसे महत्वपूर्ण है। इस तालिका में उन सभी वस्तुओं की एक सूची है, जिन्हें हमें सांता के कारखाने में उत्पादन करने की आवश्यकता होगी। प्रत्येक आइटम के लिए, हम निम्नलिखित जानकारी संग्रहीत करेंगे:
item_name— वस्तु का नाम।properties— टेक्स्ट की-वैल्यू पेयर जो उत्पादित वस्तु के आकार, आकार, रंग और अन्य गुणों को दर्शाते हैं, एक संरचित प्रारूप में संग्रहीत।description— वस्तु का एक असंरचित पाठ्य विवरण।
यदि हमारे पास कभी भी दो समान आइटम होते हैं जो केवल उनके कुछ गुणों में भिन्न होते हैं, जैसे कि रंग, तो हम आगे बढ़ेंगे और उन्हें तालिका में अलग-अलग रिकॉर्ड के रूप में संग्रहीत करेंगे।
हमारे डेटा मॉडल के प्रयोजनों के लिए, हम मान लेंगे कि सांता उपहार नहीं खरीदेगा, बल्कि अपने कल्पित बौने को घर में सब कुछ बनाने का आदेश देगा। प्रत्येक भिन्न प्रकार के आइटम के लिए, हमारे पास पूर्वापेक्षाओं की एक सूची होगी जिसे हमें पूरा करना होगा। ये श्रम या लकड़ी, प्लास्टिक, धातु और पेंट जैसी सामग्री हो सकती हैं। हमें सभी संभावित पूर्वापेक्षाओं की एक सूची संग्रहीत करने और उन्हें प्रत्येक आइटम से संबंधित करने की आवश्यकता होगी जिसे हमें उत्पादन करने की आवश्यकता है। इसे प्राप्त करने के लिए हम चार तालिकाओं का उपयोग करेंगे।
इन चार तालिकाओं में से पहली है prerequisite , जैसा कि नाम से पता चलता है, सभी संभावित पूर्वापेक्षाओं की एक सूची संग्रहीत करता है। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हम एक अद्वितीय पूर्वापेक्षा नाम, सभी अतिरिक्त properties संग्रहीत करेंगे (इस बार एक असंरचित प्रारूप में), और prerequisite_type . के संदर्भ में और इकाई शब्दकोश। prerequisite_type शब्दकोश का उपयोग सभी आवश्यक श्रेणियों, जैसे "श्रम" और "सामग्री" की सूची को संग्रहीत करने के लिए किया जाएगा। unit शब्दकोश का उपयोग उन सभी इकाइयों की सूची को संग्रहीत करने के लिए किया जाएगा जिनका उपयोग हम अपनी पूर्वापेक्षाएँ निर्धारित करने के लिए करेंगे। उदाहरण के लिए, हम श्रम को घंटों या मिनटों में और सामग्री को उत्पादन लागत (डॉलर), वजन (किलोग्राम), या मात्रा (लीटर) के रूप में मापने की उम्मीद कर सकते हैं।
इस खंड में अंतिम तालिका warehouse , जिसका उपयोग हम आइटम और सामग्री दोनों के लिए अपनी इन्वेंट्री की वर्तमान स्थिति को ट्रैक करने के लिए करेंगे (इसलिए item_type_id और prerequisite_id विदेशी कुंजी)। इन दो चाबियों में से केवल एक में किसी भी समय एक मूल्य होगा। इन चाबियों के अलावा, हम अंतिम quantity को भी स्टोर करेंगे जो एक विशेष warehouse_date . पर उपलब्ध था ।
अनुभाग 2:व्यक्ति और इच्छा सूचियां
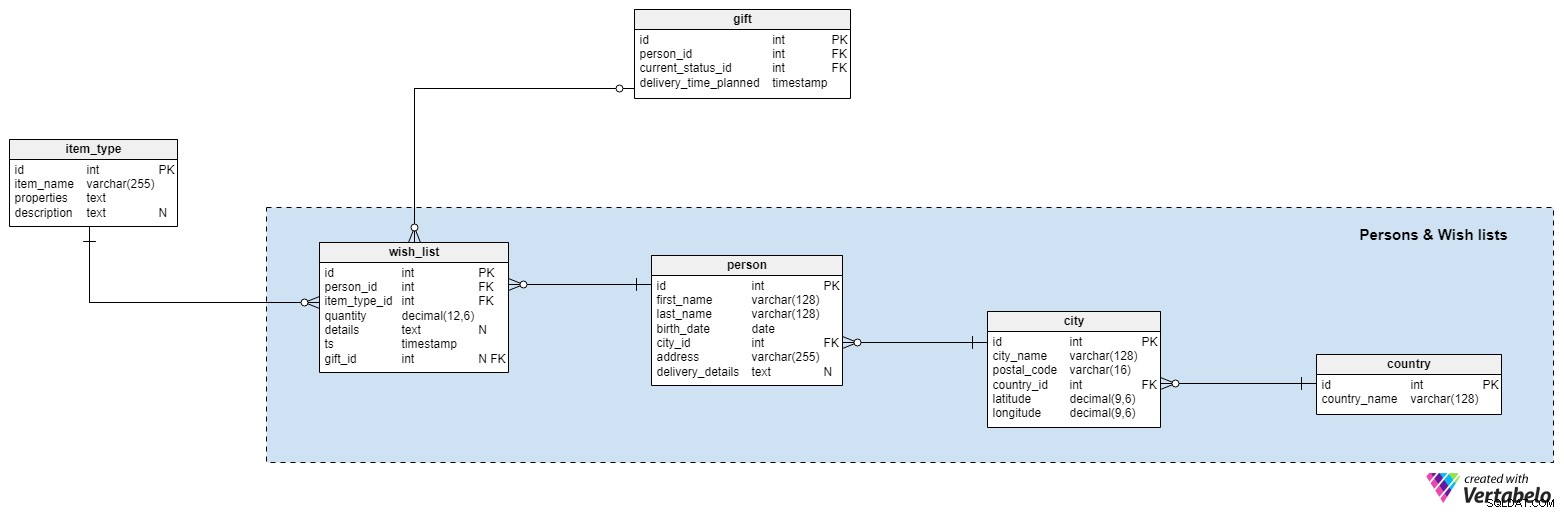
हमारे डेटा मॉडल का एक महत्वपूर्ण हिस्सा, यह खंड उन चीजों से संबंधित है जो बच्चे अपने क्रिसमस ट्री के नीचे खोजना चाहते हैं! हम दाएं से बाएं काम करेंगे।
सबसे दाईं ओर दो टेबल हैं country और city . सांता को एक इच्छा सूची भेजने वाले बच्चे के स्थान का संदर्भ देते समय हम इन दो तालिकाओं का उपयोग करेंगे। country तालिका में केवल अद्वितीय country_name शामिल है विशेषता और सभी मौजूदा countries . की सूची . अपने स्थानों के बारे में अधिक सटीक होने के लिए, हम city सभी शहरों को स्टोर करने के लिए टेबल सांता को जाना होगा। इस तालिका में प्रत्येक शहर के लिए, हम स्टोर करेंगे:
city_name— शहर का नाम, जो जरूरी नहीं कि अद्वितीय हो।postal_code— शहर का डाक कोड।country_id— उस देश की आईडी जिसमें शहर स्थित है। पिछली दो विशेषताओं के साथ, यह इस तालिका के लिए अद्वितीय कुंजी बनाता है।latitudeऔरlongitude— सांता को उसके नक्शे पर शहर खोजने में मदद करने के लिए या उसके द्वारा उपयोग किए जाने वाले नेविगेशन सिस्टम में उसके निर्देशांक दर्ज करने में मदद करता था।
बेशक, लोगों के बिना आपकी इच्छाएँ नहीं हो सकतीं! हम person टेबल। प्रत्येक व्यक्ति के लिए, हम एक first_name संग्रहित करेंगे , last_name , birth_date , और city . हम उस व्यक्ति के पते के साथ-साथ किसी भी अतिरिक्त delivery_details को भी स्टोर करेंगे। सांता को विचार करने की आवश्यकता हो सकती है (जैसे एक नोट जो दर्शाता है कि किसी व्यक्ति के पास चिमनी नहीं है)।
इस अनुभाग की अंतिम तालिका में संपूर्ण wish_list जो कभी भी बनाई गई सभी क्रिसमस इच्छाओं को संग्रहीत करता है। प्रत्येक इच्छा के लिए, हमें यह जानने की आवश्यकता है:
person_id— इच्छा करने वाले व्यक्ति का संदर्भ।item_type_id— व्यक्ति द्वारा अनुरोधित वस्तु (प्रकार) का संदर्भ।quantity- इच्छा में निर्दिष्ट वस्तु की वांछित मात्रा।description— सभी विवरण जो सांता की इच्छा पूरी करने में मदद कर सकते हैं।ts— उस क्षण को दर्शाता है जब इच्छा हमारे सिस्टम में संग्रहीत की गई थी, जो उस वर्ष को निर्धारित करने के लिए महत्वपूर्ण है जिसमें इच्छा की गई थी।gift_id— उपहार तालिका का एक संदर्भ जो इस इच्छा को पूरा करने के लिए दिया गया उपहार दर्शाता है।
अनुभाग 3:वितरण
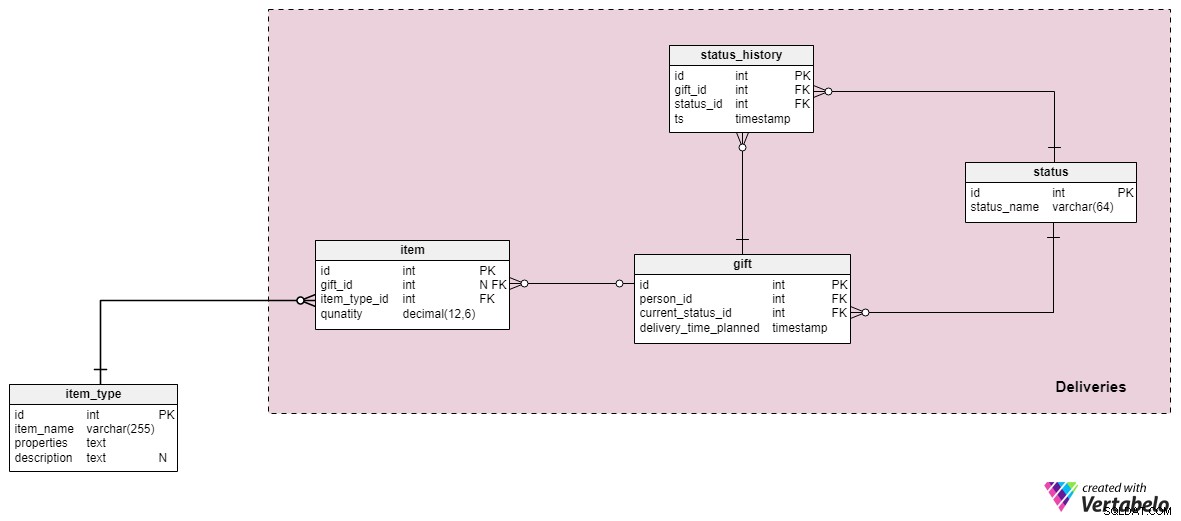
अब, हम आखिरकार अपने डेटा मॉडल के सबसे दिलचस्प हिस्से पर पहुंच गए हैं—उपहार और डिलीवरी!
किसी एक आइटम के बनने के बाद, हम उसका संबंधित रिकॉर्ड item टेबल। ध्यान दें कि जब कोई आइटम बनाया जाता है, तब भी उसे किसी उपहार को असाइन नहीं किया जाता है, इसलिए gift_id विशेषता में तब तक शून्य का मान होगा जब तक कि आइटम किसी विशेष उपहार से संबद्ध न हो। हमें उत्पादित किए गए आइटम के प्रकार को भी स्टोर करना होगा (item_type_id ), साथ ही साथ इसकी quantity . जबकि किसी आइटम की मात्रा अधिकतर 1 होगी, हम कुछ विशेष मामलों में अलग-अलग मात्राओं की अपेक्षा कर सकते हैं (उदाहरण के लिए, एक सेट में 1 से अधिक आइटम संयुक्त-यह बहुत ही असामान्य है लेकिन फिर भी संभव है)।
आगे बढ़ते हुए, हम gift . हम item.gift_id को अपडेट करेंगे एक बार जब हम अपनी चुनी हुई वस्तुओं को उस उपहार में पैक कर लेते हैं। प्रत्येक उपहार उसके संबंधित व्यक्ति को दिया जाएगा (person_id ) और उसकी ट्रैकिंग स्थिति होगी (current_status_id ), साथ ही उस समय का टाइमस्टैम्प जब सांता उपहार देने की योजना बना रहा है (delivery_time_planned ) हम wish_list.gift_id . का मान भी अपडेट करेंगे सफलतापूर्वक डिलीवर किए गए सभी आइटम के लिए विशेषता।
इस डेटा मॉडल की अंतिम दो तालिकाएं वितरण स्थितियों पर नज़र रखने से संबंधित हैं। सबसे पहले, status तालिका में एक अद्वितीय status_name है वह मान जिसका उपयोग हम gft (gift.current_status_id) की वर्तमान स्थिति का संदर्भ देते समय करेंगे ) इसके अतिरिक्त, status_history तालिका हमारे डेटाबेस में सभी उपहारों के लिए सभी स्थितियों की सूची, साथ ही सभी स्थिति अपडेट (टीएस) के टाइमस्टैम्प को संग्रहीत करेगी।
उम्मीद है, हमारा डेटा मॉडल सांता को प्रसव के एक और सफल वर्ष को पूरा करने में मदद करेगा ताकि हम सभी समय पर अपने उपहार प्राप्त कर सकें। यदि आप अधिक क्रिसमस-थीम वाले SQL के मूड में हैं, तो Vertabelo Academy ने एक विशेष 24-क्वेरी अवकाश चुनौती तैयार की है। आगे बढ़ो और इसे जांचें! वर्टाबेलो परिवार की ओर से, हम आशा करते हैं कि आपका क्रिसमस शानदार हो!