इस श्रृंखला में मेरी पिछली पोस्ट में, मैंने दिखाया था कि सभी क्वेरी परिदृश्य इन-मेमोरी ओएलटीपी प्रौद्योगिकियों से लाभ नहीं उठा सकते हैं। वास्तव में, कुछ उपयोग के मामलों में हेकाटन का उपयोग वास्तव में प्रदर्शन पर हानिकारक प्रभाव डाल सकता है (विस्तार करने के लिए क्लिक करें):

संग्रहीत कार्यविधि निष्पादन के दौरान प्रदर्शन मॉनीटर प्रोफ़ाइल
हालांकि, मैंने उस परिदृश्य में हेकाटन के खिलाफ डेक को दो तरीकों से ढेर कर दिया होगा:
- मेमोरी-ऑप्टिमाइज़्ड टेबल टाइप जो मैंने बनाया था उसकी बकेट काउंट 256 थी, लेकिन मैं तुलना करने के लिए 2,000 तक वैल्यू पास कर रहा था। SQL सर्वर टीम के एक और हालिया ब्लॉग पोस्ट में, उन्होंने समझाया कि बकेट काउंट को ओवर-साइज़ करना इसे अंडर-साइज़ करने से बेहतर है - ऐसा कुछ जिसे मैं सामान्य रूप से जानता था, लेकिन यह नहीं पता था कि टेबल वेरिएबल्स पर भी महत्वपूर्ण प्रभाव पड़ता है:रखें ध्यान रखें कि हैश इंडेक्स के लिए बकेट_काउंट अपेक्षित अद्वितीय इंडेक्स कुंजियों की संख्या लगभग 1-2X होनी चाहिए। ओवर-साइज़िंग आमतौर पर अंडर-साइज़िंग से बेहतर होता है:यदि कभी-कभी आप वेरिएबल्स में केवल 2 मान सम्मिलित करते हैं, लेकिन कभी-कभी 1000 मान तक सम्मिलित करते हैं, तो आमतौर पर
BUCKET_COUNT=1000निर्दिष्ट करना बेहतर होता है। .वे इसके वास्तविक कारण पर स्पष्ट रूप से चर्चा नहीं करते हैं, और मुझे यकीन है कि बहुत सारे तकनीकी विवरण हैं जिन पर हम ध्यान दे सकते हैं, लेकिन निर्देशात्मक मार्गदर्शन अधिक आकार का प्रतीत होता है।
- प्राथमिक कुंजी दो स्तंभों पर एक हैश अनुक्रमणिका थी, जबकि तालिका-मूल्यवान पैरामीटर केवल उन स्तंभों में से एक में मानों से मिलान करने का प्रयास कर रहा था। काफी सरलता से, इसका मतलब है कि हैश इंडेक्स का उपयोग नहीं किया जा सकता है। टोनी रोजर्सन ने हाल के ब्लॉग पोस्ट में इसे थोड़ा और विस्तार से समझाया:हैश इंडेक्स में निहित सभी कॉलम में उत्पन्न होता है, आपको हैश इंडेक्स में सभी कॉलम को अपनी समानता जांच अभिव्यक्ति पर भी निर्दिष्ट करना होगा अन्यथा इंडेक्स का उपयोग नहीं किया जा सकता है .
मैंने इसे पहले नहीं दिखाया था, लेकिन ध्यान दें कि दो-स्तंभ हैश इंडेक्स के साथ मेमोरी-ऑप्टिमाइज़्ड टेबल के खिलाफ योजना वास्तव में इंडेक्स की बजाय एक टेबल स्कैन करती है जिसे आप गैर-क्लस्टर हैश इंडेक्स के खिलाफ उम्मीद कर सकते हैं (अग्रणी के बाद से) कॉलम था
SalesOrderID):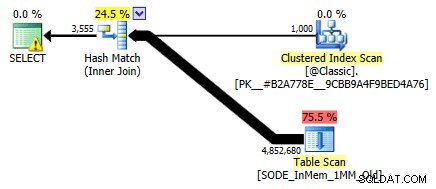
दो कॉलम वाली इन-मेमोरी टेबल वाली क्वेरी प्लान हैश इंडेक्सअधिक विशिष्ट होने के लिए, हैश इंडेक्स में, प्रमुख कॉलम का मतलब अपने आप में सेम की पहाड़ी नहीं है; हैश अभी भी सभी स्तंभों से मेल खाता है, इसलिए यह पारंपरिक बी-ट्री इंडेक्स की तरह बिल्कुल भी काम नहीं करता है (पारंपरिक इंडेक्स के साथ, केवल प्रमुख कॉलम को शामिल करने वाला एक विधेय अभी भी पंक्तियों को खत्म करने में बहुत उपयोगी हो सकता है)।
क्या करें?
ठीक है, सबसे पहले, मैंने केवल SalesOrderID . पर एक द्वितीयक हैश इंडेक्स बनाया है कॉलम। एक ऐसी तालिका का एक उदाहरण, जिसमें एक लाख बाल्टियाँ हैं:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); याद रखें कि हमारे टेबल प्रकार इस तरह से सेट किए गए हैं:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
एक बार जब मैंने डेटा के साथ नई तालिकाओं को पॉप्युलेट कर दिया, और नई तालिकाओं को संदर्भित करने के लिए एक नई संग्रहीत प्रक्रिया बनाई, तो हमें जो योजना मिलती है वह सिंगल-कॉलम हैश इंडेक्स के खिलाफ एक इंडेक्स खोजती है:

सिंगल-कॉलम हैश इंडेक्स का उपयोग करके बेहतर योजना
लेकिन वास्तव में प्रदर्शन के लिए इसका क्या अर्थ होगा? मैंने फिर से परीक्षणों का एक ही सेट चलाया - इस तालिका के खिलाफ 16K, 131K, और 1MM की बकेट काउंट के साथ क्वेरी; 100, 1,000 और 2,000 मान वाले क्लासिक और इन-मेमोरी टीवीपी दोनों का उपयोग करना; और इन-मेमोरी टीवीपी मामले में, पारंपरिक संग्रहीत कार्यविधि और मूल रूप से संकलित संग्रहीत कार्यविधि दोनों का उपयोग करते हुए। यहां बताया गया है कि प्रति संयोजन 10,000 पुनरावृत्तियों के लिए प्रदर्शन कैसा रहा:

एक-स्तंभ हैश इंडेक्स के मुकाबले 10,000 पुनरावृत्तियों के लिए प्रदर्शन प्रोफ़ाइल, 256-बकेट वाले टीवीपी का उपयोग करना
आप सोच सकते हैं, हे, वह प्रदर्शन प्रोफ़ाइल उतनी अच्छी नहीं लगती; इसके विपरीत, यह पिछले महीने मेरे पिछले परीक्षण से काफी बेहतर है। यह सिर्फ यह दर्शाता है कि तालिका के लिए बकेट काउंट का SQL सर्वर की हैश इंडेक्स का प्रभावी ढंग से उपयोग करने की क्षमता पर भारी प्रभाव पड़ सकता है। इस मामले में, 16K की बकेट काउंट का उपयोग स्पष्ट रूप से इनमें से किसी भी मामले के लिए इष्टतम नहीं है, और यह तेजी से खराब हो जाता है क्योंकि TVP में मानों की संख्या बढ़ जाती है।
अब, याद रखें, TVP की बकेट काउंट 256 थी। तो Microsoft के मार्गदर्शन के अनुसार, यदि मैं इसे बढ़ा दूं तो क्या होगा? मैंने अधिक उपयुक्त बकेट आकार के साथ दूसरा टेबल प्रकार बनाया। चूँकि मैं 100, 1,000 और 2,000 मानों का परीक्षण कर रहा था, मैंने बकेट काउंट (2,048) के लिए 2 की अगली शक्ति का उपयोग किया:
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
मैंने इसके लिए सहायक प्रक्रियाएं बनाईं, और परीक्षणों की वही बैटरी फिर से चलाई। यहां प्रदर्शन प्रोफ़ाइल साथ-साथ दी गई हैं:

प्रदर्शन प्रोफ़ाइल की तुलना 256- और 2,048-बकेट टीवीपी के साथ की जाती है। उन्हें>
तालिका प्रकार के लिए बकेट काउंट में परिवर्तन का वह प्रभाव नहीं पड़ा जिसकी मुझे उम्मीद थी, आकार देने पर माइक्रोसॉफ्ट के बयान को देखते हुए। इसका वास्तव में बहुत अधिक सकारात्मक प्रभाव नहीं पड़ा; वास्तव में कुछ परिदृश्यों के लिए यह थोड़ा खराब था। लेकिन कुल मिलाकर प्रदर्शन प्रोफ़ाइल सभी उद्देश्यों और उद्देश्यों के लिए समान हैं।
हालांकि, इसका बहुत बड़ा प्रभाव क्वेरी पैटर्न का समर्थन करने के लिए *दाएं* हैश इंडेक्स बनाना था। मैं आभारी था कि मैं यह प्रदर्शित करने में सक्षम था - मेरे पिछले परीक्षणों के बावजूद जो अन्यथा संकेत देते थे - एक इन-मेमोरी टेबल और इन-मेमोरी टीवीपी एक ही चीज़ को पूरा करने के लिए पुराने स्कूल के तरीके को हरा सकता है। आइए मेरे पिछले उदाहरण से सबसे चरम मामला लें, जब तालिका में केवल दो-स्तंभ हैश इंडेक्स था:

दो-स्तंभ वाले हैश इंडेक्स के खिलाफ 10 पुनरावृत्तियों के लिए प्रदर्शन प्रोफ़ाइल
सबसे दाहिना बार एक अनुपयुक्त हैश इंडेक्स से मेल खाने वाली मूल संग्रहीत प्रक्रिया के केवल 10 पुनरावृत्तियों की अवधि दिखाता है - क्वेरी समय 735 से 1,601 मिलीसेकंड तक। अब, हालांकि, सही हैश इंडेक्स के साथ, वही क्वेरी बहुत छोटी रेंज में निष्पादित हो रही हैं - 0.076 मिलीसेकंड से 51.55 मिलीसेकंड तक। यदि हम सबसे खराब स्थिति (16K बकेट काउंट) को छोड़ दें, तो विसंगति और भी अधिक स्पष्ट है। सभी मामलों में, यह किसी भी विधि के रूप में कम से कम दो बार कुशल (कम से कम अवधि के संदर्भ में) है, एक ही स्मृति-अनुकूलित तालिका के विरुद्ध, बिना किसी संकलित संग्रहीत प्रक्रिया के; और एकमात्र, दो-स्तंभ हैश इंडेक्स के साथ हमारी पुरानी मेमोरी-अनुकूलित तालिका के विरुद्ध किसी भी दृष्टिकोण से सैकड़ों गुना बेहतर है।
निष्कर्ष
मुझे आशा है कि मैंने प्रदर्शित किया है कि किसी भी प्रकार की मेमोरी-अनुकूलित तालिकाओं को लागू करते समय बहुत सावधानी बरतनी चाहिए, और कई मामलों में, स्मृति-अनुकूलित टीवीपी का उपयोग करने से सबसे बड़ा प्रदर्शन लाभ नहीं मिल सकता है। आप अपने हिरन के लिए सबसे धमाकेदार पाने के लिए मूल रूप से संकलित संग्रहीत प्रक्रियाओं का उपयोग करने पर विचार करना चाहेंगे, और सर्वोत्तम पैमाने पर, आप वास्तव में अपनी मेमोरी-अनुकूलित तालिकाओं में हैश इंडेक्स के लिए बकेट काउंट पर ध्यान देना चाहेंगे (लेकिन शायद नहीं आपकी स्मृति-अनुकूलित तालिका प्रकारों पर इतना ध्यान)।
इन-मेमोरी ओएलटीपी तकनीक पर सामान्य रूप से अतिरिक्त पढ़ने के लिए, आप इन संसाधनों को देखना चाहेंगे:
- एसक्यूएल सर्वर टीम ब्लॉग (टैग:हेकाटन और टैग:इन-मेमोरी ओएलटीपी - क्या कोड नाम मजेदार नहीं हैं?)
- बॉब ब्यूचेमिन का ब्लॉग
- क्लॉस एसचेनब्रेनर का ब्लॉग