अपनी पिछली पोस्ट में, मैंने दिखाया था कि छोटी मात्रा में, एक मेमोरी-अनुकूलित टीवीपी सामान्य क्वेरी पैटर्न के लिए पर्याप्त प्रदर्शन लाभ प्रदान कर सकता है।
थोड़े अधिक पैमाने पर परीक्षण करने के लिए, मैंने SalesOrderDetailEnlarged की एक प्रति बनाई तालिका, जिसे मैंने जोनाथन केहैयस (ब्लॉग | @SQLPoolBoy) की इस स्क्रिप्ट की बदौलत लगभग 5,000,000 पंक्तियों तक विस्तारित किया था।
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
मैंने इस तालिका के तीन इन-मेमोरी संस्करण भी बनाए, प्रत्येक में एक अलग बकेट काउंट ("स्वीट स्पॉट" के लिए फिशिंग) के साथ - 16,384, 131,072, और 1,048,576। (आप राउंडर नंबरों का उपयोग कर सकते हैं, लेकिन वे वैसे भी 2 की अगली घात तक पूर्णांकित हो जाते हैं।) उदाहरण:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
ध्यान दें कि मैंने पिछले उदाहरण (256) से बाल्टी का आकार बदल दिया है। टेबल बनाते समय, आप बकेट साइज के लिए "स्वीट स्पॉट" चुनना चाहते हैं - आप पॉइंट लुकअप के लिए हैश इंडेक्स को ऑप्टिमाइज़ करना चाहते हैं, जिसका अर्थ है कि आप प्रत्येक बकेट में यथासंभव कुछ पंक्तियों के साथ अधिक से अधिक बकेट चाहते हैं। बेशक यदि आप ~ 5 मिलियन बकेट बनाते हैं (चूंकि इस मामले में, शायद बहुत अच्छा उदाहरण नहीं है, तो मूल्यों के ~ 5 मिलियन अद्वितीय संयोजन हैं), आपके पास निपटने के लिए कुछ मेमोरी उपयोग और कचरा संग्रहण ट्रेड-ऑफ होंगे। हालाँकि यदि आप ~ 5 मिलियन अद्वितीय मानों को 256 बाल्टी में भरने का प्रयास करते हैं, तो आपको कुछ समस्याओं का भी अनुभव होगा। किसी भी मामले में, यह चर्चा इस पोस्ट के लिए मेरे परीक्षणों के दायरे से बहुत आगे निकल जाती है।
मानक तालिका के विरुद्ध परीक्षण करने के लिए, मैंने पिछले परीक्षणों की तरह ही संग्रहीत कार्यविधियाँ बनाईं:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO तो सबसे पहले, योजनाओं को देखने के लिए, कहें, तालिका चर में 1,000 पंक्तियों को सम्मिलित किया जा रहा है, और फिर प्रक्रियाओं को चलाना:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
इस बार, हम देखते हैं कि दोनों ही मामलों में, ऑप्टिमाइज़र ने आधार तालिका के विरुद्ध एक संकुल अनुक्रमणिका खोज को चुना है और एक नेस्टेड लूप TVP के विरुद्ध जुड़ता है। कुछ लागत मीट्रिक अलग हैं, लेकिन अन्यथा योजनाएं काफी समान हैं:
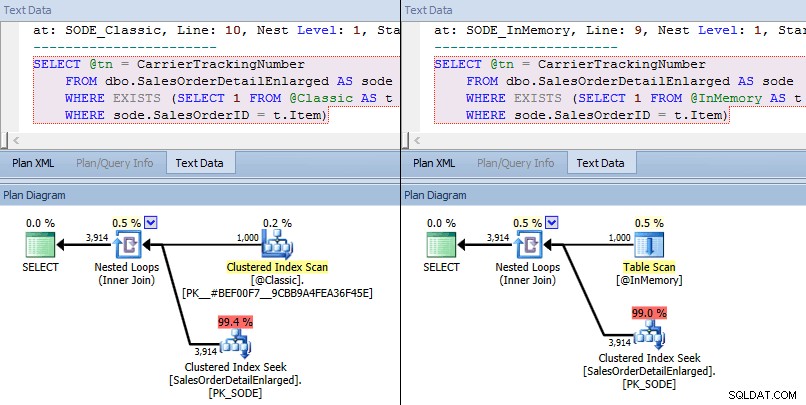 उच्च स्तर पर इन-मेमोरी टीवीपी बनाम क्लासिक टीवीपी के लिए समान योजनाएं
उच्च स्तर पर इन-मेमोरी टीवीपी बनाम क्लासिक टीवीपी के लिए समान योजनाएं
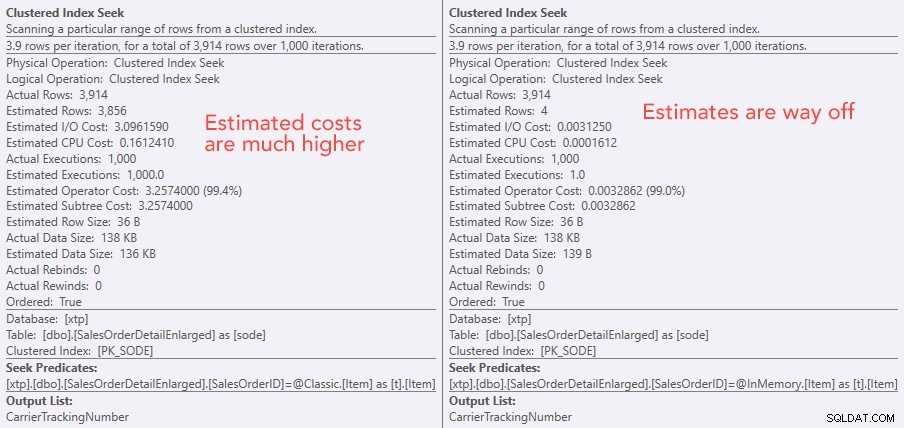 सीक ऑपरेटर लागतों की तुलना करना - बाईं ओर क्लासिक, दाईं ओर इन-मेमोरी
सीक ऑपरेटर लागतों की तुलना करना - बाईं ओर क्लासिक, दाईं ओर इन-मेमोरी
लागतों का पूर्ण मूल्य ऐसा लगता है कि क्लासिक टीवीपी इन-मेमोरी टीवीपी की तुलना में बहुत कम कुशल होगा। लेकिन मुझे आश्चर्य हुआ कि क्या यह व्यवहार में सच होगा (विशेषकर जब से अनुमानित संख्या में निष्पादन का आंकड़ा संदिग्ध लग रहा था), तो निश्चित रूप से, मैंने कुछ परीक्षण किए। मैंने प्रक्रिया में भेजे जाने वाले 100, 1,000, और 2,000 मानों के विरुद्ध जाँच करने का निर्णय लिया।
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
प्रदर्शन के परिणाम बताते हैं कि, बड़ी संख्या में पॉइंट लुकअप पर, इन-मेमोरी टीवीपी का उपयोग करने से रिटर्न थोड़ा कम होता है, हर बार थोड़ा धीमा होता है:
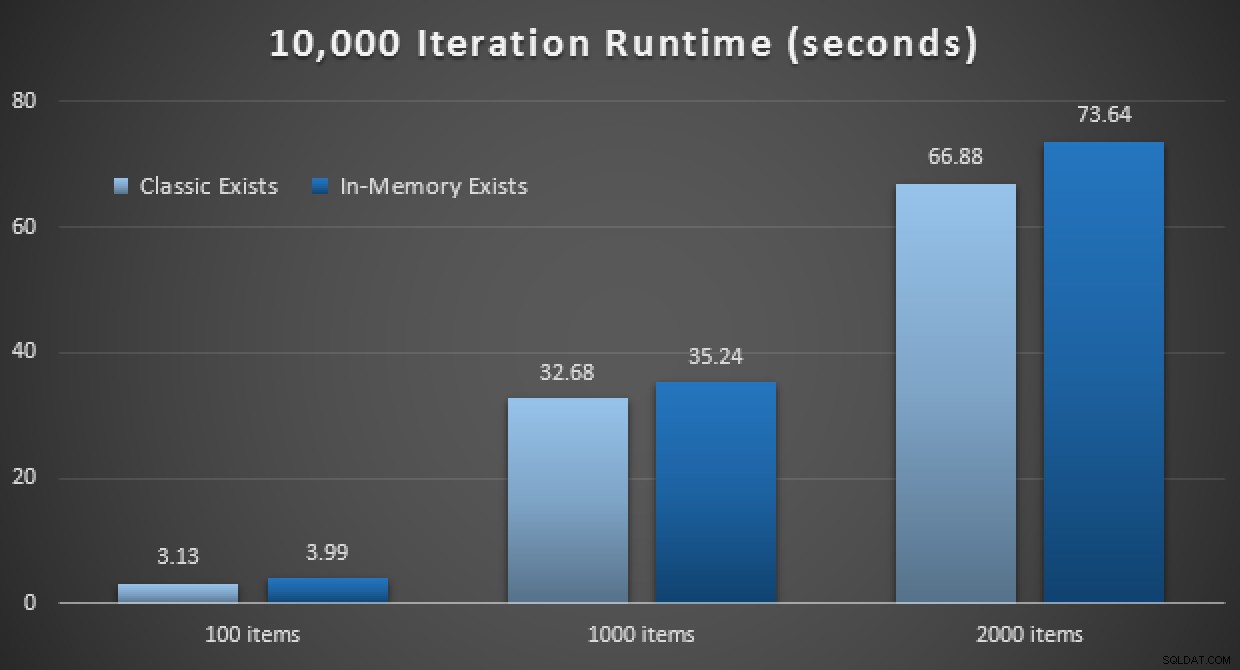
क्लासिक और इन-मेमोरी टीवीपी का उपयोग करके 10,000 निष्पादन के परिणाम
इसलिए, मेरी पिछली पोस्ट से आपने जो प्रभाव लिया होगा, उसके विपरीत, इन-मेमोरी टीवीपी का उपयोग करना सभी मामलों में जरूरी नहीं है।
इससे पहले मैंने इन-मेमोरी टीवीपी के संयोजन में, मूल रूप से संकलित संग्रहित प्रक्रियाओं और इन-मेमोरी टेबल को भी देखा था। क्या इससे यहां कोई फर्क पड़ सकता है? स्पोइलर:बिल्कुल नहीं। मैंने इस तरह से तीन प्रक्रियाएं बनाई हैं:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO एक और स्पॉइलर:मैं इन 9 परीक्षणों को 10,000 की पुनरावृत्ति संख्या के साथ चलाने में सक्षम नहीं था - इसमें बहुत लंबा समय लगा। इसके बजाय मैंने प्रत्येक प्रक्रिया को 10 बार लूप किया और चलाया, परीक्षणों के उस सेट को 10 बार चलाया, और औसत लिया। ये रहे परिणाम:
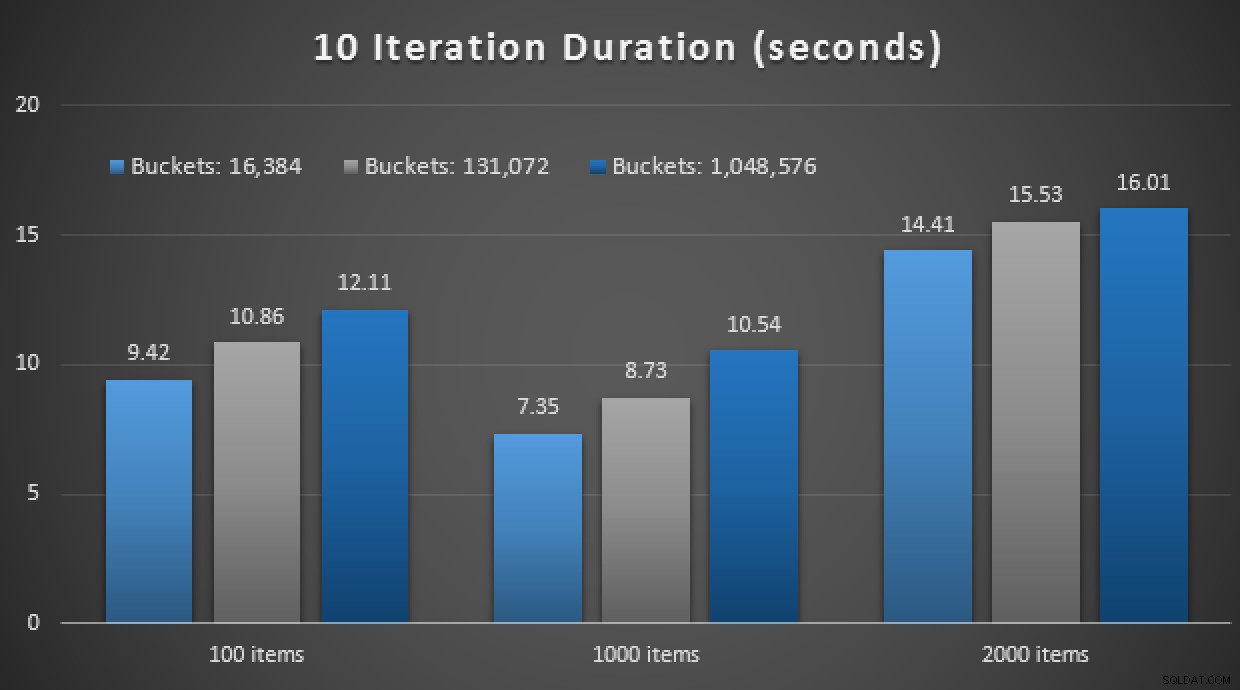
इन-मेमोरी टीवीपी का उपयोग करके 10 निष्पादन के परिणाम और मूल रूप से संकलित संग्रहीत प्रक्रियाएं
कुल मिलाकर यह प्रयोग काफी निराशाजनक रहा। ऑन-डिस्क टेबल के साथ अंतर के विशाल परिमाण को देखते हुए, औसत संग्रहित प्रक्रिया कॉल औसतन 0.0036 सेकंड में पूरी हो गई थी। हालाँकि, जब सब कुछ इन-मेमोरी तकनीकों का उपयोग कर रहा था, तो औसत संग्रहीत कार्यविधि कॉल 1.1662 सेकंड थी। आउच . यह अत्यधिक संभावना है कि मैंने समग्र रूप से डेमो करने के लिए खराब उपयोग के मामले को चुना है, लेकिन उस समय यह एक सहज ज्ञान युक्त "पहला प्रयास" था।
निष्कर्ष
इस परिदृश्य के आसपास परीक्षण करने के लिए और भी बहुत कुछ है, और मेरे पास अनुसरण करने के लिए और ब्लॉग पोस्ट हैं। मैंने अभी तक बड़े पैमाने पर इन-मेमोरी टीवीपी के लिए इष्टतम उपयोग के मामले की पहचान नहीं की है, लेकिन आशा है कि यह पोस्ट एक अनुस्मारक के रूप में कार्य करती है कि भले ही एक समाधान एक मामले में इष्टतम लगता है, यह मानना सुरक्षित नहीं है कि यह समान रूप से लागू है विभिन्न परिदृश्यों के लिए। इन-मेमोरी ओएलटीपी से ठीक इसी तरह संपर्क किया जाना चाहिए:उपयोग के मामलों के एक संकीर्ण सेट के साथ एक समाधान के रूप में जिसे उत्पादन में लागू करने से पहले पूरी तरह से मान्य किया जाना चाहिए।