क्वेरी निष्पादन के दौरान प्राप्त किए गए और जारी किए गए ताले के प्रकार और संख्या का प्रदर्शन पर आश्चर्यजनक प्रभाव पड़ सकता है (जब लॉकिंग आइसोलेशन स्तर का उपयोग किया जाता है जैसे कि डिफ़ॉल्ट रूप से पढ़ा जाता है) तब भी जहां कोई प्रतीक्षा या अवरोध नहीं होता है। निष्पादन के दौरान लॉकिंग गतिविधि की मात्रा को इंगित करने के लिए निष्पादन योजनाओं में कोई जानकारी नहीं है, जिससे यह पता लगाना कठिन हो जाता है कि अत्यधिक लॉकिंग के कारण प्रदर्शन समस्या हो रही है।
SQL सर्वर में कुछ कम प्रसिद्ध लॉकिंग व्यवहारों का पता लगाने के लिए, मैं माध्यिका की गणना पर अपने पिछले पोस्ट से प्रश्नों और नमूना डेटा का पुन:उपयोग करूंगा। उस पोस्ट में, मैंने उल्लेख किया था कि OFFSET समूहीकृत माध्यिका समाधान के लिए एक स्पष्ट PAGLOCK की आवश्यकता होती है नेस्टेड कर्सर . को बुरी तरह से खोने से बचने के लिए लॉकिंग संकेत समाधान, तो आइए इसके कारणों पर विस्तार से एक नज़र डालते हुए शुरू करते हैं।
ऑफ़सेट समूहीकृत माध्यिका समाधान
समूहीकृत माध्य परीक्षण ने हारून बर्ट्रेंड के पहले के लेख से नमूना डेटा का पुन:उपयोग किया। नीचे दी गई स्क्रिप्ट इस मिलियन-पंक्ति सेटअप को फिर से बनाती है, जिसमें सौ काल्पनिक बिक्री लोगों में से प्रत्येक के लिए दस हजार रिकॉर्ड शामिल हैं:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL सर्वर 2012 (और बाद में) OFFSET पीटर लार्सन द्वारा बनाया गया समाधान इस प्रकार है (बिना किसी लॉकिंग संकेत के):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); निष्पादन के बाद की योजना के महत्वपूर्ण भाग नीचे दिखाए गए हैं:

मेमोरी में सभी आवश्यक डेटा के साथ, यह क्वेरी 580 ms . में निष्पादित होती है मेरे लैपटॉप पर औसतन (SQL Server 2014 सर्विस पैक 1 चल रहा है)। इस क्वेरी के प्रदर्शन को 320 ms . तक सुधारा जा सकता है बस लागू सबक्वेरी में सेल्स टेबल में पेज ग्रैन्युलैरिटी लॉकिंग हिंट जोड़कर:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); निष्पादन योजना अपरिवर्तित है (ठीक है, शोप्लान एक्सएमएल में लॉकिंग हिंट टेक्स्ट के अलावा):
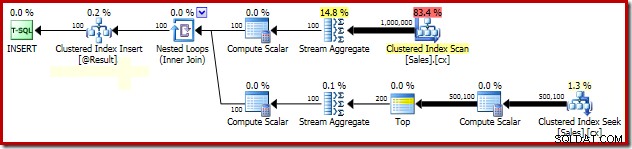
ग्रुप्ड मेडियन लॉकिंग एनालिसिस
PAGLOCK . के कारण प्रदर्शन में नाटकीय सुधार के लिए स्पष्टीकरण कम से कम शुरुआत में संकेत काफी सरल है।
यदि हम इस क्वेरी के निष्पादित होने के दौरान मैन्युअल रूप से लॉकिंग गतिविधि की निगरानी करते हैं, तो हम देखते हैं कि पेज लॉकिंग ग्रैन्युलैरिटी संकेत के बिना, SQL सर्वर आधा मिलियन से अधिक पंक्ति स्तर लॉक प्राप्त करता है और जारी करता है। क्लस्टर्ड इंडेक्स की मांग करते समय। दोष देने के लिए कोई अवरोध नहीं है; बस इसे प्राप्त करने और जारी करने से कई ताले इस क्वेरी के निष्पादन के लिए पर्याप्त ओवरहेड जोड़ते हैं। पेज लेवल लॉक का अनुरोध करने से लॉकिंग गतिविधि बहुत कम हो जाती है, जिसके परिणामस्वरूप प्रदर्शन में काफी सुधार होता है।
इस विशेष योजना का लॉकिंग प्रदर्शन मुद्दा उपरोक्त योजना में क्लस्टर्ड इंडेक्स की तलाश तक ही सीमित है। संकुल सूचकांक का पूरा स्कैन (प्रत्येक बिक्री व्यक्ति के लिए मौजूद पंक्तियों की संख्या की गणना करने के लिए प्रयुक्त) पृष्ठ स्तर के ताले का स्वचालित रूप से उपयोग करता है। यह एक दिलचस्प बिंदु है। SQL सर्वर इंजन के विस्तृत लॉकिंग व्यवहार को किसी भी हद तक पुस्तकें ऑनलाइन में प्रलेखित नहीं किया गया है, लेकिन SQL सर्वर टीम के विभिन्न सदस्यों ने वर्षों में कुछ सामान्य टिप्पणियां की हैं, जिसमें तथ्य यह है कि अप्रतिबंधित स्कैन पृष्ठ लेना शुरू कर देते हैं ताले, जबकि छोटे संचालन पंक्ति ताले से शुरू होते हैं।
क्वेरी ऑप्टिमाइज़र स्टोरेज इंजन को कुछ जानकारी उपलब्ध कराता है, जिसमें कार्डिनैलिटी अनुमान, आइसोलेशन स्तर के लिए आंतरिक संकेत और लॉकिंग ग्रैन्युलैरिटी शामिल है, जिसे आंतरिक अनुकूलन सुरक्षित रूप से लागू किया जा सकता है और इसी तरह। फिर से, इन विवरणों को Books Online में प्रलेखित नहीं किया गया है। अंत में, स्टोरेज इंजन विभिन्न प्रकार की सूचनाओं का उपयोग यह तय करने के लिए करता है कि रन टाइम पर कौन से ताले की आवश्यकता है, और उन्हें किस ग्रैन्युलैरिटी पर लिया जाना चाहिए।
एक साइड नोट के रूप में, और यह याद रखना कि हम डिफ़ॉल्ट लॉकिंग रीड कमिटेड ट्रांजैक्शन आइसोलेशन स्तर के तहत निष्पादित एक क्वेरी के बारे में बात कर रहे हैं, ध्यान दें कि ग्रैन्युलैरिटी संकेत के बिना लिए गए पंक्ति लॉक इस मामले में टेबल लॉक तक नहीं बढ़ेंगे। ऐसा इसलिए है क्योंकि रीड कमिटेड के तहत सामान्य व्यवहार अगले लॉक को प्राप्त करने से ठीक पहले पिछले लॉक को जारी करना है, जिसका अर्थ है कि किसी विशेष क्षण में केवल एक साझा पंक्ति लॉक (इसके संबद्ध उच्च-स्तरीय इंटेंट-शेयर्ड लॉक के साथ) आयोजित किया जाएगा। चूंकि समवर्ती रूप से आयोजित पंक्ति ताले की संख्या सीमा तक कभी नहीं पहुंचती है, इसलिए कोई लॉक वृद्धि का प्रयास नहीं किया जाता है।
ऑफ़सेट सिंगल मेडियन सॉल्यूशन
एकल माध्य गणना के लिए प्रदर्शन परीक्षण नमूना डेटा के एक अलग सेट का उपयोग करता है, फिर से हारून के पहले के लेख से पुन:प्रस्तुत किया गया। नीचे दी गई स्क्रिप्ट छद्म-यादृच्छिक डेटा की दस मिलियन पंक्तियों के साथ एक तालिका बनाती है:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); पर अद्वितीय क्लस्टर इंडेक्स cx बनाएं
OFFSET समाधान है:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); निष्पादन के बाद की योजना है:

यह क्वेरी 910 ms . में निष्पादित होती है मेरी परीक्षण मशीन पर औसतन। यदि PAGLOCK . है तो प्रदर्शन अपरिवर्तित रहता है संकेत जोड़ा जाता है, लेकिन इसका कारण वह नहीं है जो आप सोच रहे होंगे…
सिंगल मेडियन लॉकिंग एनालिसिस
क्लस्टर इंडेक्स स्कैन के कारण, आप शायद स्टोरेज इंजन से पेज-लेवल शेयर्ड लॉक चुनने की उम्मीद कर रहे होंगे, यह समझाते हुए कि क्यों एक PAGLOCK संकेत का कोई प्रभाव नहीं है। वास्तव में, इस क्वेरी को निष्पादित करते समय लिए गए ताले की निगरानी से पता चलता है कि कोई साझा लॉक (एस) बिल्कुल नहीं लिया जाता है, किसी भी ग्रैन्युलैरिटी पर . केवल ऑब्जेक्ट और पेज स्तर पर इंटेंट-शेयर्ड (IS) लॉक किए गए हैं।
इस व्यवहार के लिए स्पष्टीकरण दो भागों में आता है। ध्यान देने वाली पहली बात यह है कि निष्पादन योजना में क्लस्टर्ड इंडेक्स स्कैन एक शीर्ष ऑपरेटर से नीचे है। इसका कार्डिनैलिटी अनुमानों पर एक महत्वपूर्ण प्रभाव पड़ता है, जैसा कि पूर्व-निष्पादन (अनुमानित) योजना में दिखाया गया है:

OFFSET और FETCH क्वेरी में क्लॉज़ एक एक्सप्रेशन और एक वेरिएबल को संदर्भित करता है, इसलिए क्वेरी ऑप्टिमाइज़र अनुमान लगाता है कि रनटाइम पर कितनी पंक्तियों की आवश्यकता होगी। शीर्ष के लिए मानक अनुमान एक सौ पंक्तियाँ हैं। यह निश्चित रूप से एक भयानक अनुमान है, लेकिन यह स्टोरेज इंजन को पेज स्तर के बजाय पंक्ति ग्रैन्युलैरिटी पर लॉक करने के लिए मनाने के लिए पर्याप्त है।
यदि हम प्रलेखित ट्रेस फ्लैग 4138 का उपयोग करके शीर्ष ऑपरेटर के "पंक्ति लक्ष्य" प्रभाव को अक्षम करते हैं, तो स्कैन पर पंक्तियों की अनुमानित संख्या दस मिलियन में बदल जाती है (जो अभी भी गलत है, लेकिन दूसरी दिशा में)। यह स्टोरेज इंजन के लॉकिंग ग्रैन्युलैरिटी निर्णय को बदलने के लिए पर्याप्त है, ताकि पेज-लेवल शेयर्ड लॉक (नोट, इंटेंट-शेयर्ड लॉक नहीं) लिए जा सकें:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); ट्रेस फ्लैग 4138 के तहत निर्मित अनुमानित निष्पादन योजना है:

मुख्य उदाहरण पर लौटने पर, अनुमानित पंक्ति लक्ष्य के कारण सौ-पंक्ति अनुमान का अर्थ है कि भंडारण इंजन पंक्ति स्तर पर लॉक करने का चुनाव करता है। हालाँकि, हम केवल टेबल और पेज स्तर पर इंटेंट-शेयर्ड (IS) लॉक देखते हैं। यदि हम पंक्ति-स्तर साझा (एस) ताले देखते हैं तो ये उच्च-स्तरीय ताले काफी सामान्य होंगे, तो वे कहां गए?
इसका उत्तर यह है कि स्टोरेज इंजन में एक और अनुकूलन होता है जो कुछ परिस्थितियों में पंक्ति-स्तरीय साझा तालों को छोड़ सकता है। जब यह अनुकूलन लागू किया जाता है, तब भी उच्च-स्तरीय इंटेंट-शेयर्ड लॉक प्राप्त होते हैं।
संक्षेप में, एकल-माध्यम क्वेरी के लिए:
- वेरिएबल और एक्सप्रेशन का उपयोग
OFFSET. में क्लॉज का मतलब है कि ऑप्टिमाइज़र कार्डिनैलिटी का अनुमान लगाता है। - कम अनुमान का मतलब है कि स्टोरेज इंजन एक पंक्ति-स्तरीय लॉकिंग रणनीति पर निर्णय लेता है।
- आंतरिक अनुकूलन का अर्थ है कि पंक्ति-स्तरीय S लॉक को रनटाइम पर छोड़ दिया जाता है, जिससे पृष्ठ और ऑब्जेक्ट स्तर पर केवल IS लॉक रह जाते हैं।
एकल माध्य क्वेरी में समूहित माध्यिका (क्वेरी ऑप्टिमाइज़र के गलत अनुमान के कारण) के समान पंक्ति-लॉकिंग प्रदर्शन समस्या होती, लेकिन इसे एक अलग स्टोरेज इंजन ऑप्टिमाइज़ेशन द्वारा सहेजा गया, जिसके परिणामस्वरूप केवल इंटेंट-शेयर्ड पेज और टेबल लॉक लिया जा रहा था। रनटाइम पर।
समूहीकृत माध्यिका परीक्षण पर दोबारा गौर किया गया
आप सोच रहे होंगे कि समूहीकृत माध्यिका परीक्षण में क्लस्टर्ड इंडेक्स सीक ने पंक्ति-स्तरीय साझा लॉक को छोड़ने के लिए समान स्टोरेज इंजन ऑप्टिमाइज़ेशन का लाभ क्यों नहीं उठाया। PAGLOCK . बनाने के लिए इतने सारे साझा पंक्ति लॉक का उपयोग क्यों किया गया? संकेत आवश्यक है?
संक्षिप्त उत्तर यह है कि यह अनुकूलन INSERT...SELECT . के लिए उपलब्ध नहीं है प्रश्न। अगर हम SELECT चलाते हैं अपने आप (अर्थात तालिका में परिणाम लिखे बिना), और बिना PAGLOCK के संकेत, रो लॉक स्किपिंग ऑप्टिमाइज़ेशन है लागू किया गया:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
केवल टेबल- और पेज-लेवल इंटेंट-शेयर्ड (IS) लॉक का उपयोग किया जाता है, और प्रदर्शन उसी स्तर तक बढ़ जाता है जब हम PAGLOCK का उपयोग करते हैं। संकेत देना। आपको यह व्यवहार पाठ्यक्रम के दस्तावेज़ीकरण में नहीं मिलेगा, और यह किसी भी समय बदल सकता है। फिर भी, इसके बारे में जानकारी होना अच्छा है।
इसके अलावा, यदि आप सोच रहे थे, ट्रेस फ्लैग 4138 का इस मामले में स्टोरेज इंजन की लॉकिंग ग्रैन्युलैरिटी पसंद पर कोई प्रभाव नहीं पड़ता है क्योंकि पंक्ति लक्ष्य अक्षम होने पर भी सीक पर पंक्तियों की अनुमानित संख्या बहुत कम (प्रति लागू पुनरावृत्ति) है।
किसी क्वेरी के प्रदर्शन के बारे में निष्कर्ष निकालने से पहले, निष्पादन के दौरान संख्या और लॉक के प्रकार की जांच करना सुनिश्चित करें। हालांकि SQL सर्वर आमतौर पर 'सही' ग्रैन्युलैरिटी को चुनता है, लेकिन कई बार यह गलत हो सकता है, कभी-कभी प्रदर्शन पर नाटकीय प्रभाव पड़ता है।