माध्यिका की गणना करने का सबसे तेज़ तरीका SQL Server 2012 का उपयोग करता है OFFSET ORDER BY . का विस्तार खंड। एक करीबी सेकंड चल रहा है, अगला सबसे तेज़ समाधान एक (संभवतः नेस्टेड) डायनेमिक कर्सर का उपयोग करता है जो सभी संस्करणों पर काम करता है। यह लेख 2012 से पहले के एक सामान्य ROW_NUMBER . पर दिखता है माध्य गणना समस्या का समाधान यह देखने के लिए कि यह कम अच्छा प्रदर्शन क्यों करता है, और इसे तेजी से आगे बढ़ाने के लिए क्या किया जा सकता है।
एकल माध्य परीक्षण
इस परीक्षण के लिए नमूना डेटा में एक दस मिलियन पंक्ति तालिका शामिल है (हारून बर्ट्रेंड के मूल लेख से पुन:प्रस्तुत):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); पर अद्वितीय क्लस्टर इंडेक्स cx बनाएं ऑफसेट समाधान
बेंचमार्क सेट करने के लिए, पीटर लार्सन द्वारा बनाया गया SQL Server 2012 (या बाद का) OFFSET समाधान यहां दिया गया है:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); तालिका में पंक्तियों को गिनने के लिए क्वेरी पर टिप्पणी की जाती है और हार्ड-कोडित मान के साथ प्रतिस्थापित किया जाता है ताकि कोर कोड के प्रदर्शन पर ध्यान केंद्रित किया जा सके। वार्म कैशे और निष्पादन योजना संग्रह बंद होने के साथ, यह क्वेरी 910 ms . तक चलती है मेरी परीक्षण मशीन पर औसतन। निष्पादन योजना नीचे दिखाई गई है:

एक साइड नोट के रूप में, यह दिलचस्प है कि यह मामूली जटिल क्वेरी एक छोटी योजना के लिए योग्य है:
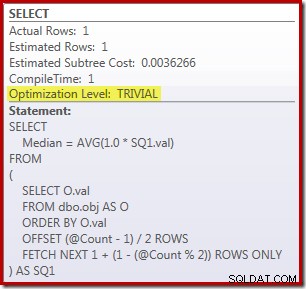
ROW_NUMBER समाधान
SQL Server 2008 R2 या इससे पहले के संस्करण चलाने वाले सिस्टम के लिए, परिवर्तनकारी समाधानों का सबसे अच्छा प्रदर्शन करने वाला एक गतिशील कर्सर का उपयोग करता है जैसा कि पहले उल्लेख किया गया है। यदि आप एक विकल्प के रूप में विचार करने में असमर्थ (या अनिच्छुक) हैं, तो 2012 OFFSET के अनुकरण के बारे में सोचना स्वाभाविक है। ROW_NUMBER . का उपयोग करके निष्पादन योजना ।
मूल विचार पंक्तियों को उचित क्रम में क्रमित करना है, फिर माध्यिका की गणना करने के लिए आवश्यक केवल एक या दो पंक्तियों के लिए फ़िल्टर करना है। Transact SQL में इसे लिखने के कई तरीके हैं; सभी प्रमुख तत्वों को कैप्चर करने वाला एक कॉम्पैक्ट संस्करण इस प्रकार है:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
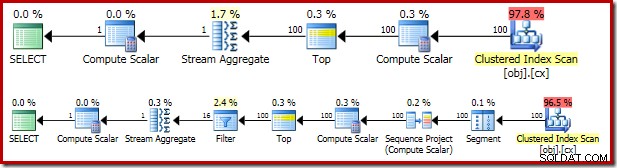
परिणामी निष्पादन योजना काफी हद तक OFFSET . के समान है संस्करण:

योजना ऑपरेटरों में से प्रत्येक को पूरी तरह से समझने के लिए बारी-बारी से देखने लायक है:
- इस योजना में सेगमेंट ऑपरेटर बेमानी है। यह आवश्यक होगा यदि
ROW_NUMBERरैंकिंग फ़ंक्शन मेंPARTITION BYथा खंड, लेकिन ऐसा नहीं है। फिर भी, यह अंतिम योजना में रहता है। - अनुक्रम प्रोजेक्ट पंक्तियों की धारा में परिकलित पंक्ति संख्या जोड़ता है।
- कंप्यूट स्केलर
valको परोक्ष रूप से रूपांतरित करने की आवश्यकता से जुड़े व्यंजक को परिभाषित करता है कॉलम से न्यूमेरिक ताकि इसे निरंतर शाब्दिक1.0. से गुणा किया जा सके क्वेरी में। इस गणना को तब तक के लिए स्थगित कर दिया जाता है जब तक कि बाद के ऑपरेटर (जो कि स्ट्रीम एग्रीगेट होता है) की आवश्यकता होती है। इस रनटाइम ऑप्टिमाइज़ेशन का अर्थ है कि निहित रूपांतरण केवल स्ट्रीम एग्रीगेट द्वारा संसाधित दो पंक्तियों के लिए किया जाता है, न कि कंप्यूट स्केलर के लिए इंगित 5,000,001 पंक्तियों के लिए। - शीर्ष ऑपरेटर को क्वेरी ऑप्टिमाइज़र द्वारा पेश किया जाता है। यह मानता है कि अधिक से अधिक, केवल पहला
(@Count + 2) / 2क्वेरी द्वारा पंक्तियों की आवश्यकता है। हम एकTOP ... ORDER BY. जोड़ सकते थे सबक्वायरी में इसे स्पष्ट करने के लिए, लेकिन यह अनुकूलन इसे काफी हद तक अनावश्यक बनाता है। - फ़िल्टर इस शर्त को
WHERE. में लागू करता है खंड, माध्यिका की गणना के लिए आवश्यक दो 'मध्य' पंक्तियों को छोड़कर सभी को फ़िल्टर करना (प्रस्तावित शीर्ष भी इसी स्थिति पर आधारित है)। - स्ट्रीम एग्रीगेट
SUM. की गणना करता है औरCOUNTदो मध्य पंक्तियों में से। - अंतिम कंप्यूट स्केलर योग और गणना से औसत की गणना करता है।
कच्चा प्रदर्शन
OFFSET की तुलना में योजना, हम उम्मीद कर सकते हैं कि अतिरिक्त खंड, अनुक्रम परियोजना और फ़िल्टर ऑपरेटरों के प्रदर्शन पर कुछ प्रतिकूल प्रभाव पड़ने वाला है। अनुमानित . की तुलना करने में कुछ समय लगता है दो योजनाओं की लागत:
OFFSET योजना की अनुमानित लागत 0.0036266 . है इकाइयाँ, जबकि ROW_NUMBER योजना का अनुमान 0.0036744 . है इकाइयां ये बहुत छोटी संख्याएं हैं, और दोनों में बहुत कम अंतर है।
तो, शायद यह आश्चर्यजनक है कि ROW_NUMBER क्वेरी वास्तव में 4000 ms . के लिए चलती है औसतन, 910 ms . की तुलना में OFFSET . के लिए औसत उपाय। इस वृद्धि में से कुछ निश्चित रूप से अतिरिक्त योजना ऑपरेटरों के ओवरहेड द्वारा समझाया जा सकता है, लेकिन चार का एक कारक अत्यधिक लगता है। इसमें और भी बहुत कुछ होना चाहिए।
आपने शायद यह भी देखा होगा कि उपरोक्त दोनों अनुमानित योजनाओं के लिए कार्डिनैलिटी अनुमान काफी निराशाजनक रूप से गलत हैं। यह शीर्ष ऑपरेटरों के प्रभाव के कारण है, जिनके पास एक चर को संदर्भित करने वाली अभिव्यक्ति है जो उनकी पंक्ति गणना सीमा के रूप में है। क्वेरी ऑप्टिमाइज़र संकलन समय पर चर की सामग्री को नहीं देख सकता है, इसलिए यह 100 पंक्तियों के अपने डिफ़ॉल्ट अनुमान का सहारा लेता है। दोनों योजनाएं वास्तव में रनटाइम पर 5,000,001 पंक्तियों का सामना करती हैं।
यह सब बहुत दिलचस्प है, लेकिन यह सीधे तौर पर स्पष्ट नहीं करता है कि ROW_NUMBER . क्यों क्वेरी OFFSET . से चार गुना धीमी है संस्करण। आखिरकार, 100 पंक्ति कार्डिनैलिटी का अनुमान दोनों ही मामलों में उतना ही गलत है।
ROW_NUMBER समाधान के प्रदर्शन में सुधार
अपने पिछले लेख में, हमने देखा कि समूहीकृत माध्यिका OFFSET . का प्रदर्शन कैसा रहा? केवल PAGLOCK . जोड़कर परीक्षण को लगभग दोगुना किया जा सकता है संकेत देना। यह संकेत भंडारण इंजन के सामान्य निर्णय को अधिग्रहित करने और पंक्ति ग्रैन्युलैरिटी (कम अपेक्षित कार्डिनैलिटी के कारण) पर साझा लॉक जारी करने के लिए ओवरराइड करता है।
एक और अनुस्मारक के रूप में, PAGLOCK एकल माध्यिका में संकेत अनावश्यक था OFFSET एक अलग आंतरिक अनुकूलन के कारण परीक्षण करें जो पंक्ति स्तर साझा लॉक को छोड़ सकता है, जिसके परिणामस्वरूप पृष्ठ स्तर पर केवल कुछ ही इंटेंट-साझा लॉक लिए जा रहे हैं।
हम उम्मीद कर सकते हैं ROW_NUMBER एक ही आंतरिक अनुकूलन से लाभ उठाने के लिए एकल माध्य समाधान, लेकिन ऐसा नहीं है। ROW_NUMBER . के दौरान लॉकिंग गतिविधि की निगरानी करना क्वेरी निष्पादित होती है, हम आधा मिलियन से अधिक व्यक्तिगत पंक्ति स्तर साझा ताले देखते हैं लिया और छोड़ा जा रहा है।
तो, अब हम जानते हैं कि समस्या क्या है, हम लॉकिंग प्रदर्शन को उसी तरह सुधार सकते हैं जैसे हमने पहले किया था:या तो PAGLOCK के साथ लॉक ग्रैन्युलैरिटी संकेत, या दस्तावेज ट्रेस फ्लैग 4138 का उपयोग करके कार्डिनैलिटी अनुमान को बढ़ाकर।
ट्रेस ध्वज का उपयोग करके "पंक्ति लक्ष्य" को अक्षम करना कई कारणों से कम संतोषजनक समाधान है। सबसे पहले, यह केवल SQL Server 2008 R2 या बाद के संस्करण में प्रभावी है। सबसे अधिक संभावना है कि हम OFFSET . को प्राथमिकता देंगे SQL सर्वर 2012 में समाधान, इसलिए यह प्रभावी रूप से केवल SQL Server 2008 R2 के लिए ट्रेस फ़्लैग फ़िक्स को सीमित करता है। दूसरा, ट्रेस ध्वज को लागू करने के लिए व्यवस्थापक-स्तर की अनुमति की आवश्यकता होती है, जब तक कि योजना मार्गदर्शिका के माध्यम से लागू नहीं किया जाता है। तीसरा कारण यह है कि पूरी क्वेरी के लिए पंक्ति लक्ष्यों को अक्षम करने से अन्य अवांछनीय प्रभाव हो सकते हैं, विशेष रूप से अधिक जटिल योजनाओं में।
इसके विपरीत, PAGLOCK संकेत प्रभावी है, बिना किसी विशेष अनुमति के SQL सर्वर के सभी संस्करणों में उपलब्ध है, और लॉकिंग ग्रैन्युलैरिटी से परे इसका कोई बड़ा दुष्प्रभाव नहीं है।
PAGLOCK को लागू करना ROW_NUMBER की ओर संकेत करें क्वेरी प्रदर्शन में नाटकीय रूप से वृद्धि करती है:4000 ms . से से 1500 एमएस:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 एमएस परिणाम अभी भी 910 ms . से काफी धीमा है OFFSET . के लिए समाधान, लेकिन कम से कम अब यह उसी बॉलपार्क में है। शेष प्रदर्शन अंतर केवल निष्पादन योजना में अतिरिक्त कार्य के कारण है:

OFFSET . में योजना, पांच मिलियन पंक्तियों को शीर्ष तक संसाधित किया जाता है (गणना स्केलर में परिभाषित अभिव्यक्तियों के साथ पहले चर्चा की गई)। ROW_NUMBER . में योजना, पंक्तियों की समान संख्या को खंड, अनुक्रम परियोजना, शीर्ष और फ़िल्टर द्वारा संसाधित किया जाना है।



