SQL सर्वर डेटाबेस इंजन द्वारा उपयोग की जाने वाली सामान्य रणनीति एक अनुक्रमित दृश्य को उसके आधार तालिकाओं के साथ सिंक्रनाइज़ करने के लिए उपयोग करती है - जिसे मैंने अपनी पिछली पोस्ट में अधिक विस्तार से वर्णित किया है - वृद्धिशील रखरखाव करना है। दृश्य में संदर्भित तालिकाओं में से किसी एक के विरुद्ध जब भी कोई डेटा-परिवर्तन कार्रवाई होती है। व्यापक शब्दों में, यह विचार है:
- आधार तालिका परिवर्तन के बारे में जानकारी एकत्र करें
- दृश्य में परिभाषित अनुमान, फ़िल्टर और जोड़ लागू करें
- प्रति अनुक्रमित दृश्य क्लस्टर किए गए परिवर्तनों को समेकित करें
- तय करें कि प्रत्येक परिवर्तन के परिणामस्वरूप दृश्य के विरुद्ध एक सम्मिलित, अद्यतन, या हटाना चाहिए
- दृश्य में बदलने, जोड़ने या हटाने के लिए मानों की गणना करें
- दृश्य परिवर्तन लागू करें
या, और भी अधिक संक्षेप में (यद्यपि सकल सरलीकरण के जोखिम पर):
- मूल डेटा संशोधनों के वृद्धिशील दृश्य प्रभावों की गणना करें;
- उन परिवर्तनों को दृश्य में लागू करें
यह आमतौर पर प्रत्येक अंतर्निहित डेटा परिवर्तन (सुरक्षित लेकिन धीमा विकल्प) के बाद पूरे दृश्य के पुनर्निर्माण की तुलना में बहुत अधिक कुशल रणनीति है, लेकिन यह प्रत्येक संभावित अनुक्रमित दृश्य परिभाषा के विरुद्ध, प्रत्येक बोधगम्य डेटा परिवर्तन के लिए वृद्धिशील अद्यतन तर्क के सही होने पर निर्भर करता है।
जैसा कि शीर्षक से पता चलता है, यह लेख एक दिलचस्प मामले से संबंधित है जहां वृद्धिशील-अद्यतन तर्क टूट जाता है, जिसके परिणामस्वरूप एक भ्रष्ट अनुक्रमित दृश्य होता है जो अब अंतर्निहित डेटा से मेल नहीं खाता है। इससे पहले कि हम स्वयं बग पर पहुंचें, हमें स्केलर और वेक्टर समुच्चय की तुरंत समीक्षा करने की आवश्यकता है।
स्केलर और वेक्टर समुच्चय
यदि आप इस शब्द से परिचित नहीं हैं, तो समुच्चय दो प्रकार के होते हैं। एक समूह जो ग्रुप बाय क्लॉज से जुड़ा होता है (भले ही सूची के अनुसार समूह खाली हो) को वेक्टर एग्रीगेट के रूप में जाना जाता है . ग्रुप बाय क्लॉज के बिना एक समुच्चय को स्केलर एग्रीगेट . के रूप में जाना जाता है ।
जबकि एक वेक्टर समुच्चय को डेटा सेट में मौजूद प्रत्येक समूह के लिए एक एकल आउटपुट पंक्ति का उत्पादन करने की गारंटी है, स्केलर समुच्चय थोड़ा अलग हैं। अदिश समुच्चय हमेशा इनपुट सेट खाली होने पर भी एकल आउटपुट पंक्ति उत्पन्न करें।
वेक्टर कुल उदाहरण
निम्नलिखित एडवेंचरवर्क्स उदाहरण एक खाली इनपुट सेट पर दो वेक्टर समुच्चय (एक योग और एक गिनती) की गणना करता है:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
ये प्रश्न निम्नलिखित आउटपुट उत्पन्न करते हैं (कोई पंक्तियाँ नहीं):

परिणाम वही है, यदि हम ग्रुप बाय क्लॉज को एक खाली सेट से बदलते हैं (SQL Server 2008 या बाद के संस्करण की आवश्यकता है):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
निष्पादन योजनाएँ दोनों मामलों में भी समान हैं। यह गणना क्वेरी के लिए निष्पादन योजना है:
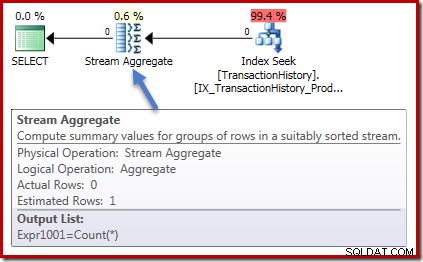
स्ट्रीम एग्रीगेट में शून्य पंक्तियाँ इनपुट होती हैं, और शून्य पंक्तियाँ बाहर होती हैं। योग निष्पादन योजना इस तरह दिखती है:

फिर से, कुल में शून्य पंक्तियाँ, और शून्य पंक्तियाँ बाहर। अब तक की सभी अच्छी साधारण चीजें।
स्केलर समुच्चय
अब देखें कि अगर हम ग्रुप बाय क्लॉज को पूरी तरह से क्वेरी से हटा दें तो क्या होगा:
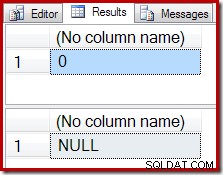
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
एक खाली परिणाम के बजाय, COUNT कुल एक शून्य उत्पन्न करता है, और SUM एक NULL देता है:
गणना निष्पादन योजना इस बात की पुष्टि करती है कि शून्य इनपुट पंक्तियाँ स्ट्रीम एग्रीगेट से आउटपुट की एकल पंक्ति उत्पन्न करती हैं:
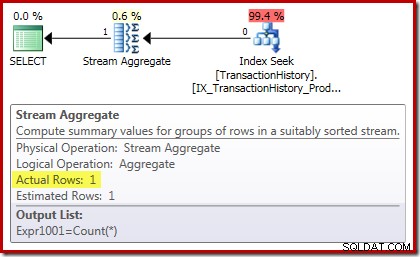
योग निष्पादन योजना और भी दिलचस्प है:
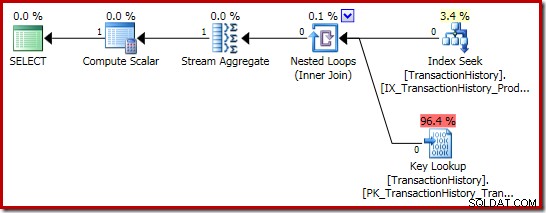
स्ट्रीम एग्रीगेट प्रॉपर्टी हमारे द्वारा मांगी गई राशि के अलावा गणना की जाने वाली कुल संख्या दिखाती है:
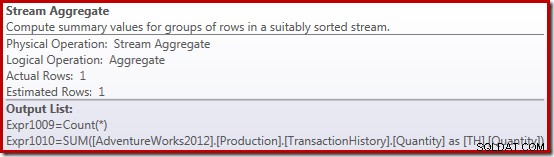
यदि स्ट्रीम एग्रीगेट द्वारा प्राप्त पंक्तियों की संख्या शून्य है, तो नए कंप्यूट स्केलर ऑपरेटर का उपयोग NULL को वापस करने के लिए किया जाता है, अन्यथा यह सामने आए डेटा का योग देता है:
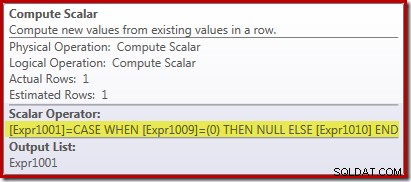
यह सब कुछ अजीब लग सकता है, लेकिन यह इस तरह काम करता है:
- शून्य पंक्तियों का एक वेक्टर समुच्चय शून्य पंक्तियों को लौटाता है;
- एक स्केलर समुच्चय हमेशा आउटपुट की एक पंक्ति उत्पन्न करता है, यहां तक कि एक खाली इनपुट के लिए भी;
- शून्य पंक्तियों की अदिश संख्या शून्य है; और
- शून्य पंक्तियों का अदिश योग शून्य (शून्य नहीं) होता है।
हमारे वर्तमान उद्देश्यों के लिए महत्वपूर्ण बिंदु यह है कि स्केलर समुच्चय हमेशा आउटपुट की एक पंक्ति का उत्पादन करते हैं, भले ही इसका मतलब कुछ भी नहीं से एक बनाना हो। साथ ही, शून्य पंक्तियों का अदिश योग शून्य है, शून्य नहीं।
वैसे ये सभी व्यवहार "सही" हैं। चीजें वैसे ही हैं क्योंकि एसक्यूएल मानक मूल रूप से स्केलर एग्रीगेट्स के व्यवहार को परिभाषित नहीं करता था, इसे कार्यान्वयन तक छोड़ देता था। SQL सर्वर पश्चगामी संगतता कारणों से अपने मूल कार्यान्वयन को सुरक्षित रखता है। वेक्टर समुच्चय में हमेशा अच्छी तरह से परिभाषित व्यवहार होते हैं।
अनुक्रमित दृश्य और वेक्टर एकत्रीकरण
अब एक साधारण अनुक्रमित दृश्य पर विचार करें जिसमें कुछ (वेक्टर) समुच्चय शामिल हैं:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); निम्न क्वेरीज़ आधार तालिका की सामग्री, अनुक्रमित दृश्य को क्वेरी करने का परिणाम और दृश्य के अंतर्गत तालिका पर दृश्य क्वेरी चलाने का परिणाम दिखाती हैं:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
परिणाम हैं:
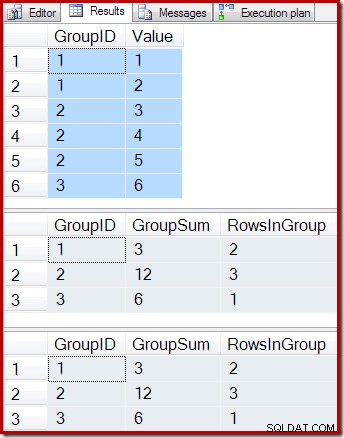
जैसा कि अपेक्षित था, अनुक्रमित दृश्य और अंतर्निहित क्वेरी बिल्कुल समान परिणाम लौटाते हैं। आधार तालिका T1 में किसी भी और सभी संभावित परिवर्तनों के बाद भी परिणाम समकालिक बने रहेंगे। खुद को यह याद दिलाने के लिए कि यह सब कैसे काम करता है, आधार तालिका में एक नई पंक्ति जोड़ने के साधारण मामले पर विचार करें:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); इस इंसर्ट की निष्पादन योजना में अनुक्रमित दृश्य को सिंक्रनाइज़ रखने के लिए आवश्यक सभी तर्क शामिल हैं:
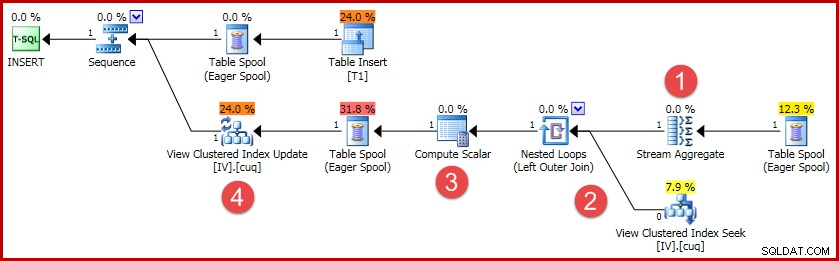
योजना में प्रमुख गतिविधियां हैं:
- स्ट्रीम एग्रीगेट प्रति अनुक्रमित दृश्य कुंजी में परिवर्तन की गणना करता है
- दृश्य में बाहरी जुड़ाव परिवर्तन सारांश को लक्ष्य दृश्य पंक्ति से जोड़ता है, यदि कोई हो
- कंप्यूट स्केलर यह तय करता है कि प्रत्येक परिवर्तन के लिए दृश्य के विरुद्ध एक सम्मिलित करना, अद्यतन करना या हटाना आवश्यक है या नहीं, और आवश्यक मानों की गणना करता है।
- व्यू अपडेट ऑपरेटर व्यू क्लस्टर इंडेक्स में प्रत्येक परिवर्तन को भौतिक रूप से करता है।
आधार तालिका (जैसे अद्यतन और विलोपन) के विरुद्ध विभिन्न परिवर्तन कार्यों के लिए कुछ योजना अंतर हैं, लेकिन दृश्य को सिंक्रनाइज़ रखने के पीछे व्यापक विचार एक ही रहता है:प्रति दृश्य कुंजी में परिवर्तन एकत्र करें, यदि यह मौजूद है तो दृश्य पंक्ति खोजें, फिर प्रदर्शन करें आवश्यकतानुसार व्यू इंडेक्स पर सम्मिलित करें, अपडेट करें और हटाएं संचालन का एक संयोजन।
कोई फर्क नहीं पड़ता कि आप इस उदाहरण में आधार तालिका में क्या परिवर्तन करते हैं, अनुक्रमित दृश्य सही ढंग से सिंक्रनाइज़ रहेगा - ऊपर दिए गए NOEXPAND और EXPAND VIEWS प्रश्न हमेशा एक ही परिणाम सेट लौटाएंगे। चीजों को हमेशा इसी तरह काम करना चाहिए।
अनुक्रमित दृश्य और स्केलर एकत्रीकरण
अब इस उदाहरण को आजमाएं, जहां अनुक्रमित दृश्य स्केलर एकत्रीकरण का उपयोग करता है (दृश्य में कोई ग्रुप बाय क्लॉज नहीं):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); यह पूरी तरह से कानूनी अनुक्रमित दृश्य है; इसे बनाते समय कोई त्रुटि नहीं आई है। एक सुराग है कि हम कुछ अजीब कर रहे हैं, हालांकि:जब आवश्यक अद्वितीय क्लस्टर इंडेक्स बनाकर दृश्य को अमल में लाने का समय आता है, तो कुंजी के रूप में चुनने के लिए कोई स्पष्ट कॉलम नहीं होता है। आम तौर पर, हम निश्चित रूप से व्यू के ग्रुप बाय क्लॉज से ग्रुपिंग कॉलम चुनेंगे।
ऊपर की स्क्रिप्ट मनमाने ढंग से NumRows कॉलम चुनती है। वह चुनाव महत्वपूर्ण नहीं है। अद्वितीय क्लस्टर इंडेक्स बनाने के लिए स्वतंत्र महसूस करें, चाहे आप किसी भी समय चुनें। दृश्य में हमेशा एक पंक्ति होगी अदिश समुच्चय के कारण, इसलिए अद्वितीय कुंजी उल्लंघन की कोई संभावना नहीं है। उस अर्थ में, अनुक्रमणिका कुंजी देखने का विकल्प बेमानी है, लेकिन फिर भी आवश्यक है।
पिछले उदाहरण के परीक्षण प्रश्नों का पुन:उपयोग करते हुए, हम देख सकते हैं कि अनुक्रमित दृश्य सही ढंग से काम करता है:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
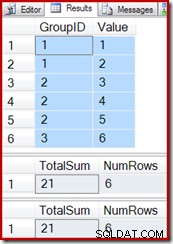
आधार तालिका में एक नई पंक्ति सम्मिलित करना (जैसा कि हमने वेक्टर समग्र अनुक्रमित दृश्य के साथ किया था) ठीक से काम करना जारी रखता है:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); निष्पादन योजना समान है, लेकिन बिल्कुल समान नहीं है:
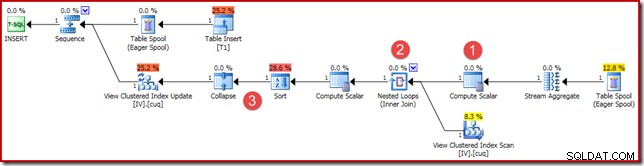
मुख्य अंतर हैं:
- यह नया कंप्यूट स्केलर उन्हीं कारणों से है, जब हमने पहले वेक्टर और स्केलर एग्रीगेशन परिणामों की तुलना की थी:यह सुनिश्चित करता है कि यदि एक खाली सेट पर एग्रीगेट संचालित होता है, तो एक NULL योग वापस आ जाता है (शून्य के बजाय)। पंक्तियों के अदिश योग के लिए यह आवश्यक व्यवहार है।
- पहले देखे गए आउटर जॉइन को इनर जॉइन से बदल दिया गया है। अनुक्रमित दृश्य में हमेशा एक पंक्ति होगी (स्केलर एकत्रीकरण के कारण) इसलिए यह देखने के लिए बाहरी जुड़ाव की आवश्यकता का कोई सवाल ही नहीं है कि कोई दृश्य पंक्ति मेल खाती है या नहीं। दृश्य में मौजूद एक पंक्ति हमेशा डेटा के पूरे सेट का प्रतिनिधित्व करती है। इस इनर जॉइन का कोई विधेय नहीं है, इसलिए यह तकनीकी रूप से एक क्रॉस जॉइन है (एक गारंटीकृत एकल पंक्ति वाली तालिका में)।
- अनुक्रमित दृश्य रखरखाव पर मेरे पिछले लेख में शामिल तकनीकी कारणों से क्रमबद्ध और संक्षिप्त करें ऑपरेटर मौजूद हैं। वे यहां अनुक्रमित दृश्य रखरखाव के सही संचालन को प्रभावित नहीं करते हैं।
वास्तव में, इस उदाहरण में बेस टेबल T1 के खिलाफ कई अलग-अलग प्रकार के डेटा-चेंजिंग ऑपरेशन सफलतापूर्वक किए जा सकते हैं; अनुक्रमित दृश्य में प्रभाव सही ढंग से दिखाई देंगे। अनुक्रमित दृश्य को सही रखते हुए आधार तालिका के विरुद्ध निम्नलिखित परिवर्तन कार्य किए जा सकते हैं:
- मौजूदा पंक्तियां हटाएं
- मौजूदा पंक्तियों को अपडेट करें
- नई पंक्तियाँ सम्मिलित करें
यह एक व्यापक सूची की तरह लग सकता है, लेकिन ऐसा नहीं है।
बग का खुलासा
मुद्दा बल्कि सूक्ष्म है, और वेक्टर और स्केलर समुच्चय के विभिन्न व्यवहारों से संबंधित है (जैसा कि आपको उम्मीद करनी चाहिए)। मुख्य बिंदु यह है कि एक अदिश समुच्चय हमेशा एक आउटपुट पंक्ति का उत्पादन करेगा, भले ही उसे इसके इनपुट पर कोई पंक्तियाँ प्राप्त न हों, और एक खाली सेट का अदिश योग शून्य है, शून्य नहीं।
<ब्लॉककोट>समस्या पैदा करने के लिए, हमें बस इतना करना है कि आधार तालिका में कोई पंक्तियाँ डालें या हटाएं।
यह कथन उतना पागल नहीं है जितना पहली नज़र में लग सकता है।
मुद्दा यह है कि एक सम्मिलित या हटाने वाली क्वेरी जो बिना आधार तालिका पंक्तियों को प्रभावित करती है अभी भी दृश्य को अपडेट करेगी, क्योंकि क्वेरी प्लान के अनुक्रमित दृश्य रखरखाव भाग में स्केलर स्ट्रीम एग्रीगेट बिना इनपुट के प्रस्तुत किए जाने पर भी आउटपुट पंक्ति उत्पन्न करेगा। कंप्यूट स्केलर जो स्ट्रीम एग्रीगेट का अनुसरण करता है, पंक्तियों की संख्या शून्य होने पर भी एक पूर्ण योग उत्पन्न करेगा।
निम्न स्क्रिप्ट कार्य में बग को प्रदर्शित करती है:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
उस स्क्रिप्ट का आउटपुट नीचे दिखाया गया है:
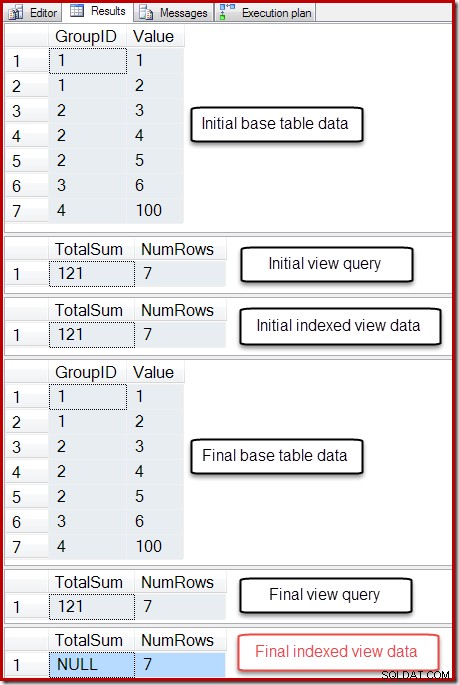
अनुक्रमित दृश्य के कुल योग स्तंभ की अंतिम स्थिति अंतर्निहित दृश्य क्वेरी या आधार तालिका डेटा से मेल नहीं खाती है। NULL योग ने दृश्य को दूषित कर दिया है, जिसकी पुष्टि DBCC CHECKTABLE (अनुक्रमित दृश्य पर) चलाकर की जा सकती है।
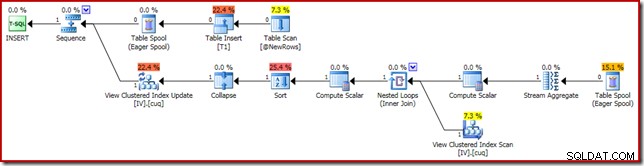
भ्रष्टाचार के लिए जिम्मेदार निष्पादन योजना नीचे दिखाई गई है:
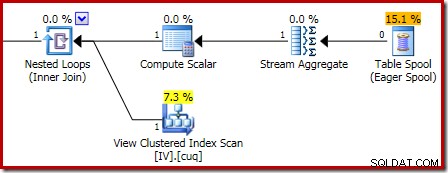
ज़ूम इन करना स्ट्रीम एग्रीगेट में शून्य-पंक्ति इनपुट और एक-पंक्ति आउटपुट दिखाता है:
अगर आप ऊपर दी गई भ्रष्टाचार स्क्रिप्ट को डालने के बजाय डिलीट के साथ आज़माना चाहते हैं, तो यहां एक उदाहरण दिया गया है:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
हटाना कोई आधार तालिका पंक्तियों को प्रभावित नहीं करता है, लेकिन फिर भी अनुक्रमित दृश्य के योग स्तंभ को NULL में बदल देता है।
बग को सामान्य बनाना
आप शायद किसी भी संख्या में डालने के साथ आ सकते हैं, और आधार तालिका प्रश्नों को हटा सकते हैं जो पंक्तियों को प्रभावित नहीं करते हैं, और इस अनुक्रमित दृश्य भ्रष्टाचार का कारण बनते हैं। हालांकि, एक ही मूल मुद्दा समस्या के एक व्यापक वर्ग पर लागू होता है, न कि केवल सम्मिलित और हटाता है जो आधार तालिका पंक्तियों को प्रभावित नहीं करता है।
उदाहरण के लिए, एक इंसर्ट का उपयोग करके वही भ्रष्टाचार उत्पन्न करना संभव है जो करता है आधार तालिका में पंक्तियाँ जोड़ें। आवश्यक घटक यह है कि कोई अतिरिक्त पंक्तियाँ दृश्य के योग्य नहीं होनी चाहिए . इसके परिणामस्वरूप स्ट्रीम एग्रीगेट में एक खाली इनपुट होगा, और निम्न कंप्यूट स्केलर से भ्रष्टाचार पैदा करने वाली NULL पंक्ति आउटपुट होगा।
इसे हासिल करने का एक तरीका है WHERE क्लॉज को उस व्यू में शामिल करना जो कुछ बेस टेबल रो को अस्वीकार करता है:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); दृश्य में शामिल समूह आईडी पर नए प्रतिबंध को देखते हुए, निम्न प्रविष्टि आधार तालिका में पंक्तियों को जोड़ देगी, लेकिन फिर भी दूषित अनुक्रमित दृश्य एक पूर्ण योग होगा:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; आउटपुट अब परिचित सूचकांक भ्रष्टाचार दिखाता है:
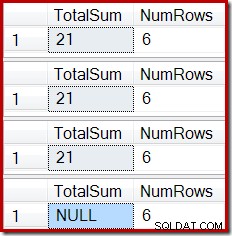
एक या अधिक आंतरिक जुड़ाव वाले दृश्य का उपयोग करके एक समान प्रभाव उत्पन्न किया जा सकता है। जब तक आधार तालिका में जोड़ी गई पंक्तियों को अस्वीकार कर दिया जाता है (उदाहरण के लिए शामिल होने में विफल होने पर), स्ट्रीम एग्रीगेट को कोई पंक्तियाँ प्राप्त नहीं होंगी, कंप्यूट स्केलर एक NULL योग उत्पन्न करेगा, और अनुक्रमित दृश्य दूषित होने की संभावना है।
अंतिम विचार
यह समस्या अद्यतन प्रश्नों के लिए नहीं होती है (कम से कम जहाँ तक मैं बता सकता हूँ) लेकिन यह डिज़ाइन की तुलना में दुर्घटना से अधिक प्रतीत होता है - समस्याग्रस्त स्ट्रीम एग्रीगेट अभी भी संभावित-कमजोर अद्यतन योजनाओं में मौजूद है, लेकिन कंप्यूट स्केलर जो उत्पन्न करता है NULL योग नहीं जोड़ा गया है (या शायद अनुकूलित किया गया है)। कृपया मुझे बताएं कि क्या आप अपडेट क्वेरी का उपयोग करके बग को पुन:उत्पन्न करने का प्रबंधन करते हैं।
जब तक इस बग को ठीक नहीं किया जाता है (या, शायद, अनुक्रमित दृश्यों में स्केलर समुच्चय अस्वीकृत हो जाते हैं) GROUP BY खंड के बिना अनुक्रमित दृश्य में समुच्चय का उपयोग करने के बारे में बहुत सावधान रहें।
इस लेख को व्लादिमीर मोल्दोवनेंको द्वारा प्रस्तुत एक कनेक्ट आइटम द्वारा प्रेरित किया गया था, जो मेरे एक पुराने ब्लॉग पोस्ट पर एक टिप्पणी छोड़ने के लिए पर्याप्त था (जो MERGE कथन के कारण एक अलग अनुक्रमित दृश्य भ्रष्टाचार से संबंधित है)। व्लादिमिर ध्वनि कारणों से अनुक्रमित दृश्य में अदिश समुच्चय का उपयोग कर रहा था, इसलिए इस बग को एक किनारे के मामले के रूप में आंकने में जल्दबाजी न करें जो आपको उत्पादन वातावरण में कभी नहीं मिलेगा! व्लादिमिर को मेरा धन्यवाद उसके कनेक्ट आइटम के बारे में मुझे सचेत करने के लिए।