उच्च उपलब्धता के प्रमुख पहलुओं में से एक विफलताओं पर तुरंत प्रतिक्रिया करने की क्षमता है। डेटाबेस को मैन्युअल रूप से प्रबंधित करना असामान्य नहीं है, और मॉनिटरिंग सॉफ़्टवेयर डेटाबेस स्वास्थ्य पर नज़र रखता है। विफलता के मामले में, निगरानी सॉफ्टवेयर ऑन-कॉल स्टाफ को अलर्ट भेजता है। इसका मतलब है कि किसी को संभावित रूप से जागने, कंप्यूटर पर जाने और सिस्टम में लॉग इन करने और लॉग देखने की आवश्यकता हो सकती है - यानी, उपचार शुरू होने से पहले काफी समय लगता है। आदर्श रूप से, पूरी प्रक्रिया स्वचालित होनी चाहिए।
इस ब्लॉग में, हम देखेंगे कि एक पूरी तरह से स्वचालित प्रणाली को कैसे परिनियोजित किया जाए जो प्राथमिक डेटाबेस के विफल होने का पता लगाती है, और द्वितीयक डेटाबेस को बढ़ावा देकर विफलता प्रक्रिया शुरू करती है। हम मूडल पोस्टग्रेएसक्यूएल डेटाबेस की स्वचालित विफलता करने के लिए क्लस्टर कंट्रोल का उपयोग करेंगे।
स्वचालित विफलता का लाभ
- डेटाबेस सेवा को पुनर्प्राप्त करने के लिए कम समय
- उच्च सिस्टम अपटाइम
- डेटाबेस के लिए उच्च उपलब्धता सेट करने वाले DBA या व्यवस्थापक पर कम निर्भरता
आर्किटेक्चर
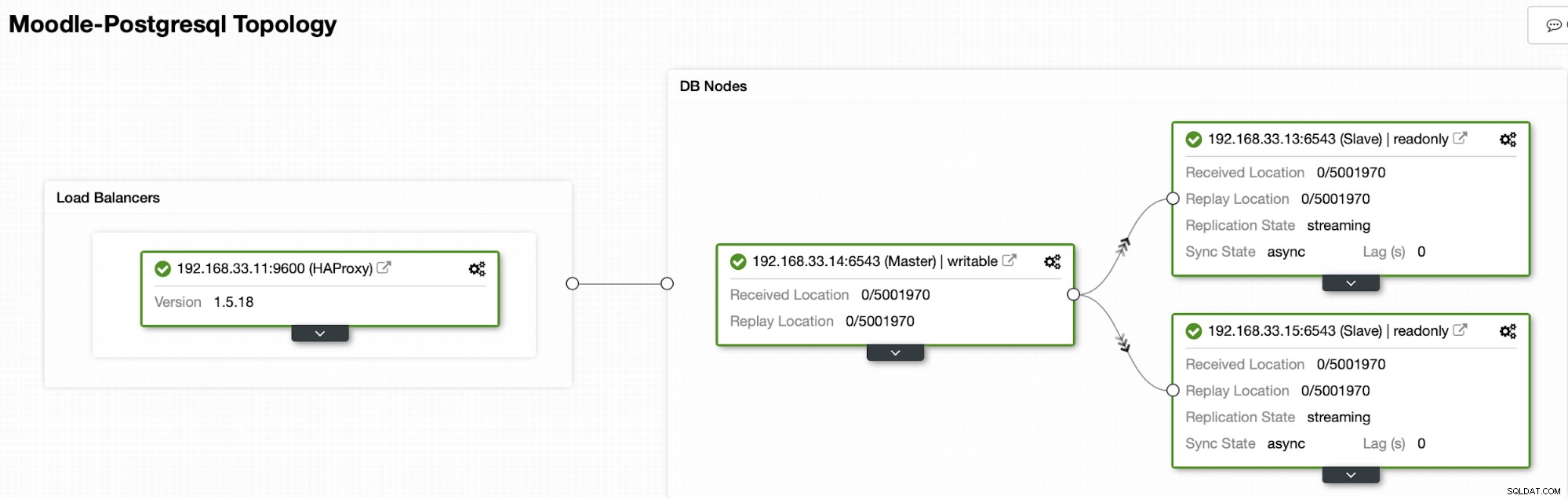
वर्तमान में हमारे पास HAProxy लोड बैलेंसर के तहत एक पोस्टग्रेज प्राइमरी सर्वर और दो सेकेंडरी सर्वर हैं। जो मूडल ट्रैफिक को प्राइमरी पोस्टग्रेएसक्यूएल नोड को भेजता है। ClusterControl में क्लस्टर पुनर्प्राप्ति और नोड स्वतः पुनर्प्राप्ति स्वचालित फ़ेलओवर प्रक्रिया को निष्पादित करने के लिए महत्वपूर्ण सेटिंग्स हैं।

विफल होने वाले सर्वर को नियंत्रित करना
ClusterControl उन सर्वरों के एक सेट की श्वेतसूची और ब्लैकलिस्टिंग की पेशकश करता है जिन्हें आप फ़ेलओवर में भाग लेना चाहते हैं, या एक उम्मीदवार के रूप में बाहर करना चाहते हैं।
सीमोन कॉन्फ़िगरेशन में आप दो चर सेट कर सकते हैं,
- replication_failover_whitelist :इसमें द्वितीयक सर्वरों के IP या होस्टनामों की सूची होती है, जिन्हें संभावित प्राथमिक उम्मीदवारों के रूप में उपयोग किया जाना चाहिए। अगर यह वेरिएबल सेट है, तो केवल उन्हीं होस्ट्स पर विचार किया जाएगा।
- replication_failover_blacklist :इसमें मेजबानों की एक सूची होती है जिसे कभी भी प्राथमिक उम्मीदवार के रूप में नहीं माना जाएगा। आप इसका उपयोग द्वितीयक सर्वरों को सूचीबद्ध करने के लिए कर सकते हैं जो बैकअप या विश्लेषणात्मक प्रश्नों के लिए उपयोग किए जाते हैं। यदि हार्डवेयर द्वितीयक सर्वरों के बीच भिन्न होता है, तो आप यहां सर्वरों को रखना चाहेंगे जो धीमे हार्डवेयर का उपयोग करते हैं।
ऑटो फ़ेलओवर प्रक्रिया
चरण 1
हमने sysbench टूल का उपयोग करके प्राथमिक सर्वर (192.168.33.14) पर डेटा लोड करना शुरू कर दिया है।
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
चरण 2
हम पोस्टग्रेज प्राइमरी सर्वर (192.168.33.14) को बंद करने जा रहे हैं। ClusterControl में, (enable_cluster_autorecovery) पैरामीटर सक्षम है, इसलिए यह अगले उपयुक्त प्राथमिक को बढ़ावा देगा।
# service postgresql-12 stopचरण 3
ClusterControl प्राथमिक में विफलताओं का पता लगाता है और एक नए प्राथमिक के रूप में सबसे वर्तमान डेटा के साथ एक माध्यमिक को बढ़ावा देता है। यह बाकी सेकेंडरी सर्वर पर भी काम करता है ताकि उन्हें नए प्राइमरी सर्वर से दोहराया जा सके।

हमारे मामले में (192.168.33.13) एक नया प्राथमिक सर्वर है और द्वितीयक सर्वर अब इस नए प्राथमिक सर्वर से दोहराते हैं। अब HAProxy डेटाबेस ट्रैफ़िक को मूडल सर्वर से नवीनतम प्राथमिक सर्वर पर रूट करता है।
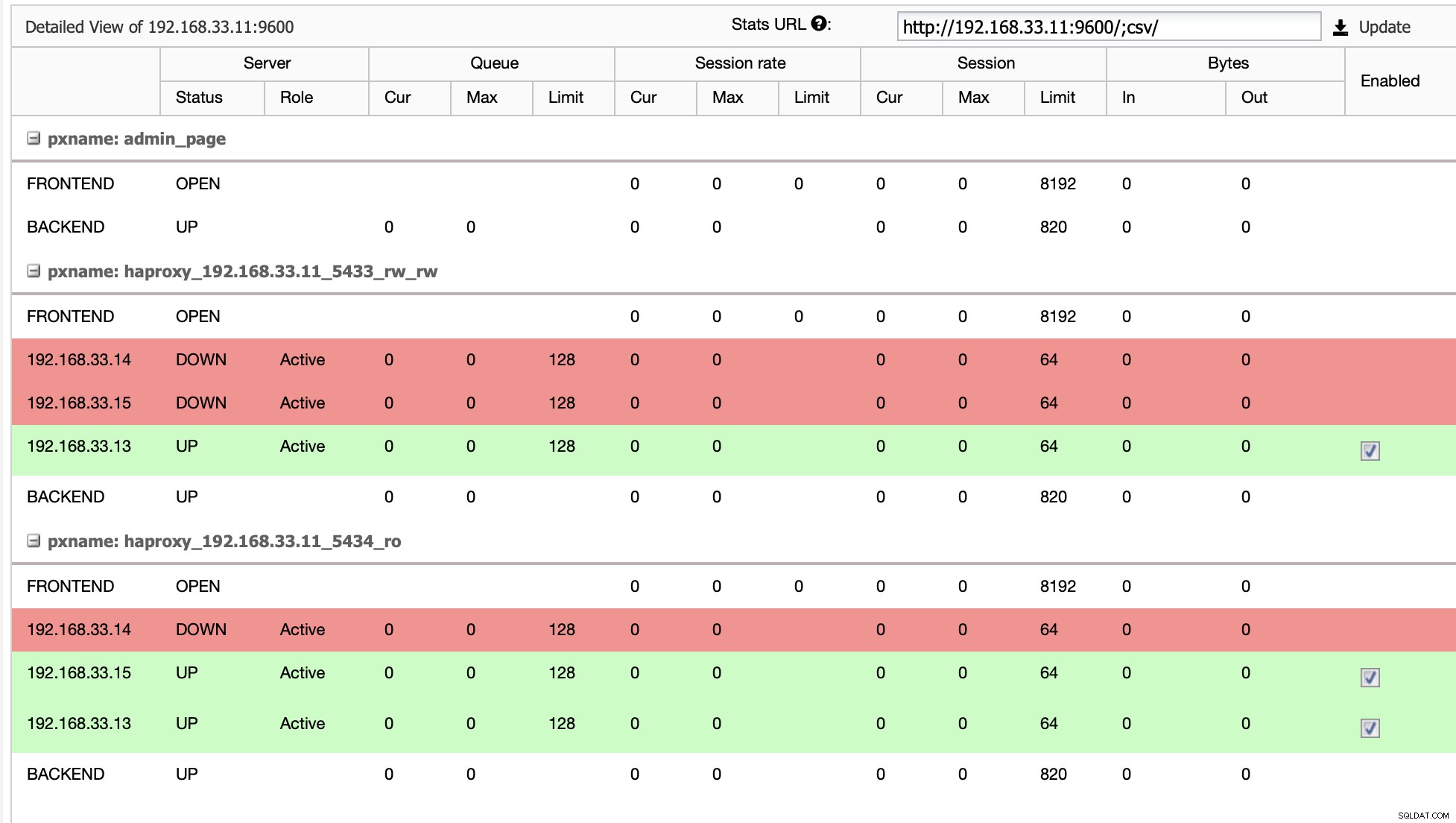
से (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)से (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
वर्तमान टोपोलॉजी
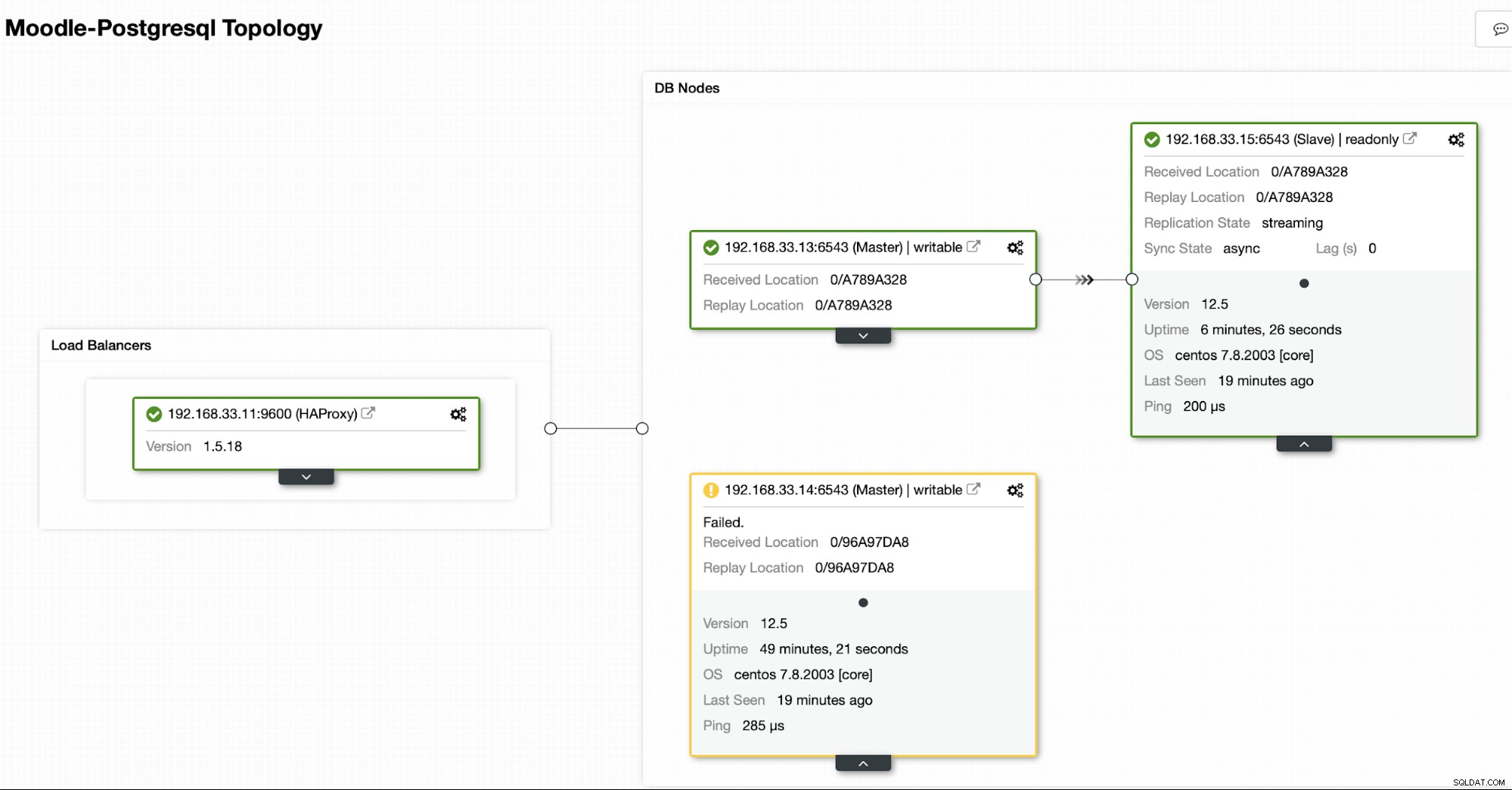
जब HAProxy को पता चलता है कि हमारा एक नोड, या तो प्राथमिक या प्रतिकृति, है पहुंच योग्य नहीं है, यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित करता है। HAProxy उस पर मूडल एप्लिकेशन से कोई ट्रैफ़िक नहीं भेजेगा। यह जांच स्वास्थ्य जांच स्क्रिप्ट द्वारा की जाती है जिसे परिनियोजन के समय क्लस्टरकंट्रोल द्वारा कॉन्फ़िगर किया जाता है।
एक बार जब ClusterControl एक प्रतिकृति सर्वर को प्राथमिक में बढ़ावा देता है, तो हमारा HAProxy पुराने प्राथमिक को ऑफ़लाइन के रूप में चिह्नित करता है और प्रचारित नोड को ऑनलाइन रखता है।
एक बार पुराना प्राथमिक वापस ऑनलाइन हो जाने पर, यह स्वचालित रूप से नए प्राथमिक सर्वर से समन्वयित नहीं होगा। हमें इसे टोपोलॉजी में वापस आने देना है, और इसे ClusterControl इंटरफ़ेस के माध्यम से किया जा सकता है। यह डेटा हानि या असंगति की संभावना से बच जाएगा, अगर हम जांच करना चाहते हैं कि वह सर्वर पहली जगह में विफल क्यों हुआ।
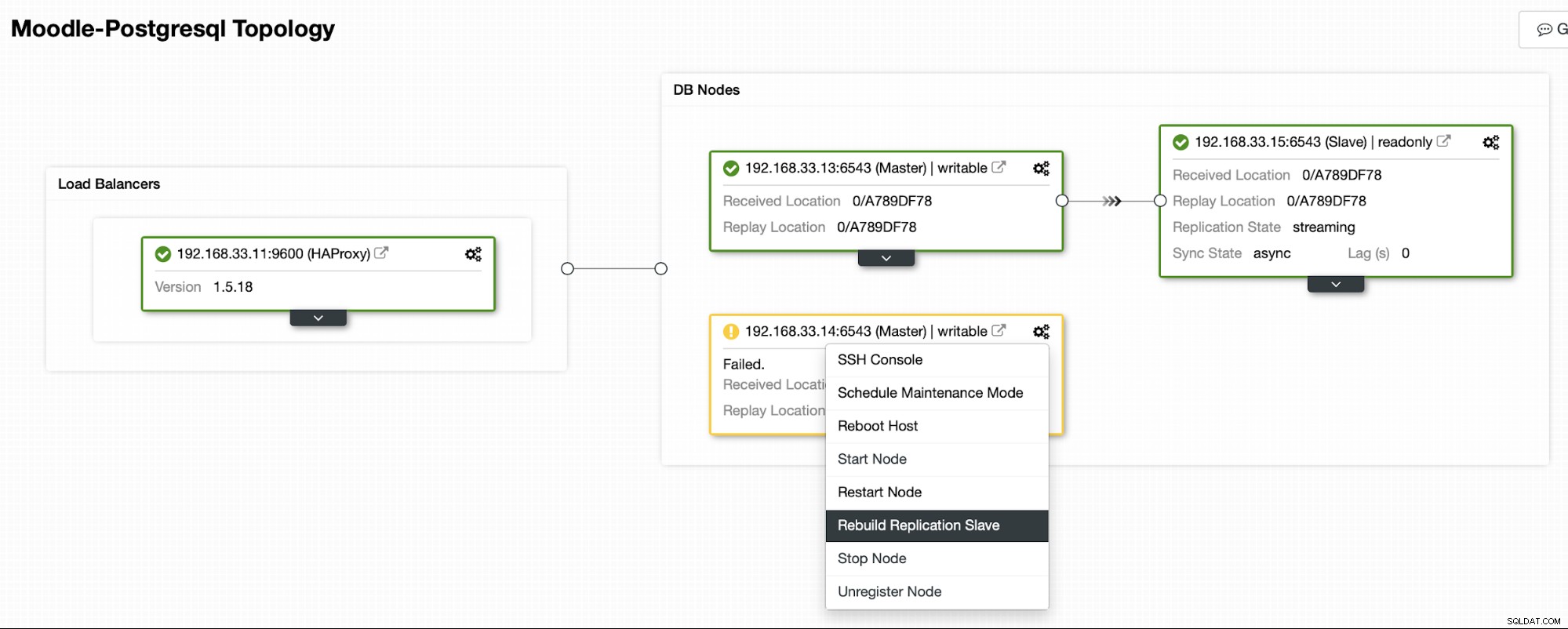
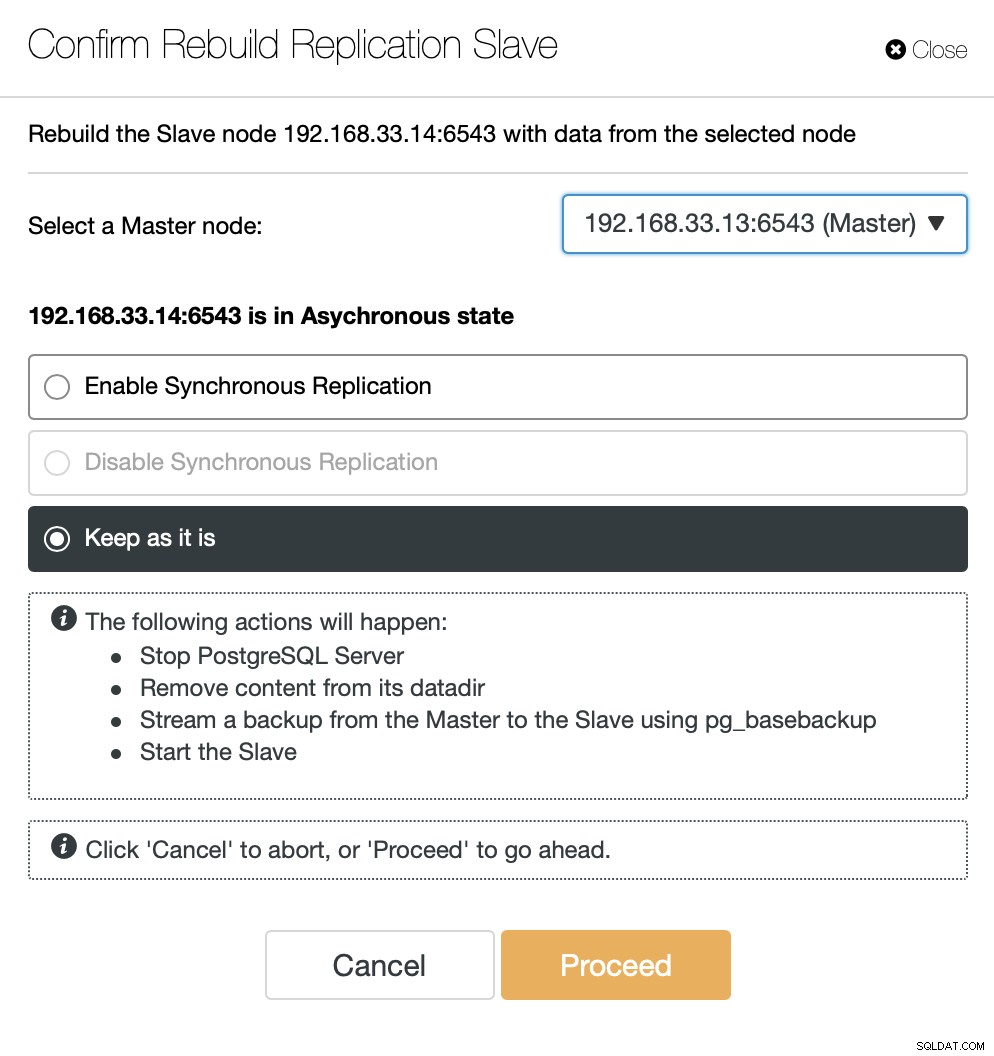
ClusterControl नए प्राथमिक सर्वर से बैकअप स्ट्रीम करेगा और प्रतिकृति को कॉन्फ़िगर करेगा।
निष्कर्ष
ऑटो फेलओवर किसी भी मूडल प्रोडक्शन डेटाबेस का एक महत्वपूर्ण हिस्सा है। सर्वर डाउन होने पर यह डाउनटाइम को कम कर सकता है, लेकिन सामान्य रखरखाव कार्य या माइग्रेशन करते समय भी। इसे ठीक करना महत्वपूर्ण है, क्योंकि फ़ेलओवर सॉफ़्टवेयर के लिए सही निर्णय लेना महत्वपूर्ण है।