इस ब्लॉग श्रृंखला के पहले भाग में, मैंने कुछ बेंचमार्क परिणाम प्रस्तुत किए हैं, जिसमें दिखाया गया है कि 2008 में जारी 8.3 के बाद से PostgreSQL OLTP का प्रदर्शन कैसे बदल गया। इस भाग में मैं वही काम करने की योजना बना रहा हूं, लेकिन विश्लेषणात्मक / बीआई प्रश्नों के लिए, बड़े प्रसंस्करण के लिए डेटा की मात्रा.
इस कार्यभार के परीक्षण के लिए कई उद्योग मानक हैं, लेकिन शायद सबसे अधिक इस्तेमाल किया जाने वाला एक टीपीसी-एच है, इसलिए मैं इस ब्लॉग पोस्ट के लिए इसका उपयोग करूंगा। टीपीसी-डीएस भी है, निर्णय समर्थन प्रणालियों के परीक्षण के लिए एक और टीपीसी बेंचमार्क, जिसे टीपीसी-एच के विकास या प्रतिस्थापन के रूप में देखा जा सकता है। मैंने कुछ कारणों से टीपीसी-एच से चिपके रहने का फैसला किया है।
सबसे पहले, टीपीसी-डीएस स्कीमा (अधिक टेबल) और प्रश्नों की संख्या (22 बनाम 99) दोनों के संदर्भ में बहुत अधिक जटिल है। इसे ठीक से ट्यून करना, विशेष रूप से कई PostgreSQL संस्करणों के साथ काम करते समय, बहुत कठिन होगा। दूसरे, कुछ टीपीसी-डीएस प्रश्न उन सुविधाओं का उपयोग करते हैं जो पुराने पोस्टग्रेएसक्यूएल संस्करणों (जैसे समूहीकरण सेट) द्वारा समर्थित नहीं हैं, जिससे कुछ संस्करणों के लिए उन प्रश्नों को अप्रासंगिक बना दिया जाता है। और अंत में, मैं कहूंगा कि लोग टीपीसी-डी की तुलना में टीपीसी-एच से अधिक परिचित हैं।
इसका लक्ष्य अन्य डेटाबेस उत्पादों की तुलना की अनुमति देना नहीं है, केवल PostgreSQL 8.3 के बाद से PostgreSQL प्रदर्शन कैसे विकसित हुआ, इस पर एक उचित दीर्घकालिक लक्षण वर्णन प्रदान करना है।
नोट :टीपीसी-एच बेंचमार्क के एक बहुत ही रोचक विश्लेषण के लिए, मैं बोन्ज़, न्यूमैन और एर्लिंग से "टीपीसी-एच विश्लेषण:छिपे हुए संदेश और एक प्रभावशाली बेंचमार्क से सीखे गए पाठ" पेपर की जोरदार अनुशंसा करता हूं।
हार्डवेयर
इस ब्लॉग पोस्ट के अधिकांश परिणाम हमारे कार्यालय में "बड़े बॉक्स" से आते हैं, जिसमें ये पैरामीटर हैं:
- 2x E5-2620 v4 (16 कोर, 32 थ्रेड)
- 64GB रैम
- Intel Optane 900P 280GB NVMe SSD (डेटा)
- 3 x 7.2k SATA RAID0 (अस्थायी टेबलस्पेस)
- कर्नेल 5.6.15, ext4 फ़ाइल सिस्टम
मुझे यकीन है कि आप काफी बीफियर मशीनें खरीद सकते हैं, लेकिन मेरा मानना है कि यह हमें प्रासंगिक डेटा देने के लिए पर्याप्त है। दो कॉन्फ़िगरेशन वेरिएंट थे - एक समानांतरवाद के साथ अक्षम, एक समानांतरवाद सक्षम के साथ। उपलब्ध हार्डवेयर संसाधनों (सीपीयू, रैम, स्टोरेज) के लिए ट्यून किए गए दोनों मामलों में अधिकांश पैरामीटर मान समान हैं। आप इस पोस्ट के अंत में कॉन्फ़िगरेशन के बारे में अधिक विस्तृत जानकारी प्राप्त कर सकते हैं।
बेंचमार्क
मैं यह स्पष्ट करना चाहता हूं कि एक वैध टीपीसी-एच बेंचमार्क लागू करना मेरा लक्ष्य नहीं है जो टीपीसी द्वारा आवश्यक सभी मानदंडों को पारित कर सके। मेरा लक्ष्य यह मूल्यांकन करना है कि समय के साथ विभिन्न विश्लेषणात्मक प्रश्नों का प्रदर्शन कैसे बदल गया, प्रति डॉलर प्रदर्शन के कुछ सार माप या ऐसा कुछ का पीछा नहीं करना।
इसलिए मैंने केवल टीपीसी-एच के सबसेट का उपयोग करने का निर्णय लिया है - अनिवार्य रूप से केवल डेटा लोड करें, और 22 प्रश्नों को चलाएं (सभी संस्करणों पर समान पैरामीटर)। कोई डेटा रीफ्रेश नहीं है, प्रारंभिक लोड के बाद डेटा सेट स्थिर है। मैंने कई पैमाने के कारक चुने हैं, 1, 10 और 75, ताकि हमारे पास फिट-इन-शेयर्ड-बफ़र्स (1), फ़िट-इन-मेमोरी (10) और अधिक-से-मेमोरी (75) के परिणाम हों। . मैं इसे "अच्छा अनुक्रम" बनाने के लिए 100 के लिए जाऊंगा, जो कुछ मामलों में 280GB स्टोरेज में फिट नहीं होगा (इंडेक्स, अस्थायी फ़ाइलों आदि के लिए धन्यवाद)। ध्यान दें कि स्केल फ़ैक्टर 75 को TPC-H द्वारा मान्य स्केल फ़ैक्टर के रूप में भी मान्यता नहीं दी गई है।
लेकिन क्या यह 1GB या 10GB डेटा सेट को बेंचमार्क करने का कोई मतलब है? लोग बहुत बड़े डेटाबेस पर ध्यान केंद्रित करते हैं, इसलिए उनका परीक्षण करने से परेशान होना थोड़ा मूर्खतापूर्ण लग सकता है। लेकिन मुझे नहीं लगता कि यह उपयोगी होगा - जंगली में डेटाबेस का विशाल बहुमत काफी छोटा है, मेरे अनुभव में और यहां तक कि जब पूरा डेटाबेस बड़ा होता है, तो लोग आमतौर पर इसके एक छोटे से सबसेट के साथ ही काम करते हैं - हालिया डेटा, अनसुलझे आदेश, आदि। इसलिए मेरा मानना है कि उन छोटे डेटा सेट के साथ भी परीक्षण करना समझ में आता है।
डेटा लोड
सबसे पहले, देखते हैं कि डेटाबेस में डेटा लोड करने में कितना समय लगता है - बिना और समानांतरवाद के। मैं केवल 75GB डेटा सेट से परिणाम दिखाऊंगा, क्योंकि छोटे मामलों के लिए समग्र व्यवहार लगभग समान है।
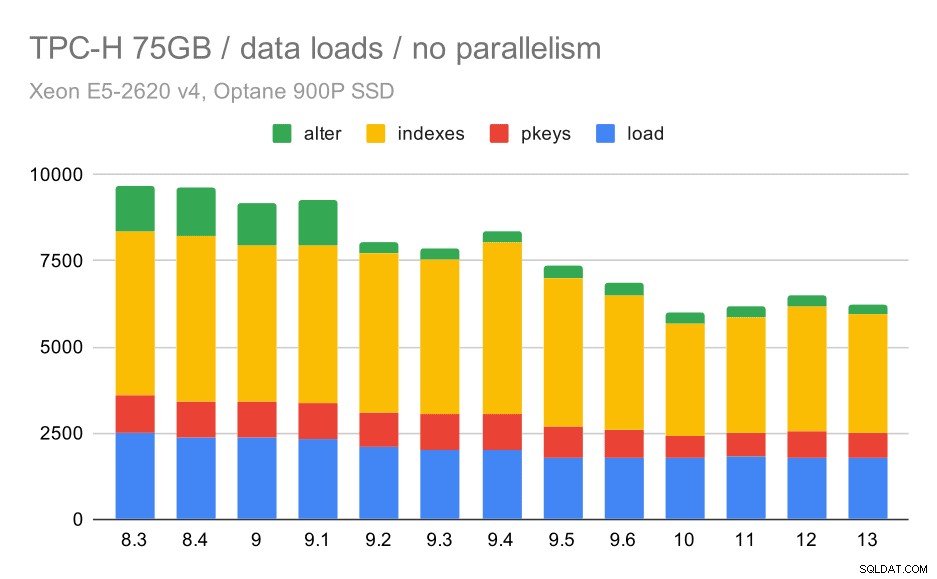
TPC-H डेटा लोड अवधि - पैमाना 75GB, कोई समानता नहीं
आप स्पष्ट रूप से देख सकते हैं कि सुधार की एक स्थिर प्रवृत्ति है, सभी चार चरणों में दक्षता में सुधार करके अवधि का लगभग 30% शेविंग करना, प्राथमिक कुंजी और अनुक्रमणिका बनाना, और (विशेष रूप से) विदेशी कुंजी सेट करना। 9.2 में "परिवर्तन" सुधार विशेष रूप से स्पष्ट है।
| कॉपी करें | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
अब, देखते हैं कि समांतरता को सक्षम करने से व्यवहार कैसे बदलता है। निम्न चार्ट समानांतरवाद सक्षम के साथ परिणामों की तुलना करता है - "(पी)" के साथ चिह्नित - समानांतरवाद अक्षम परिणामों के साथ।
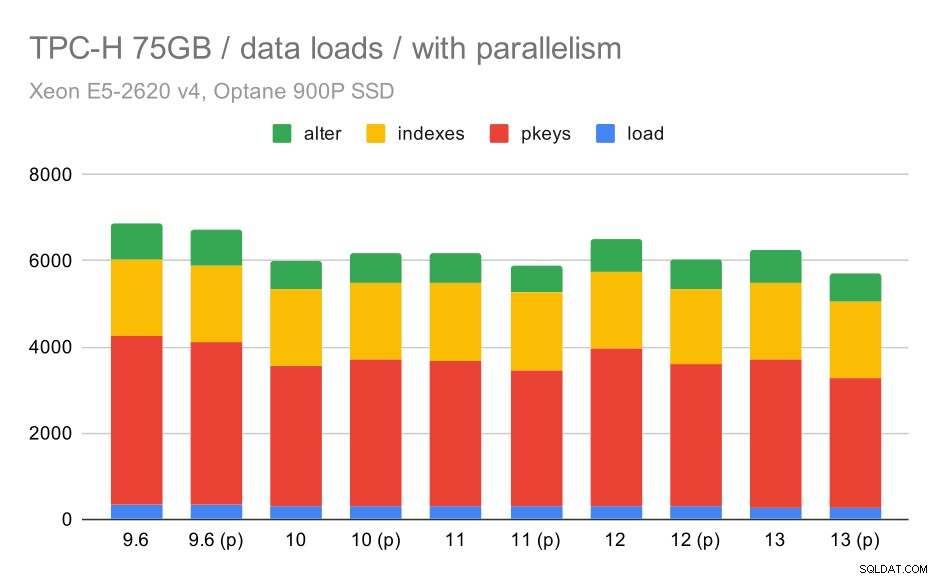
TPC-H डेटा लोड अवधि - स्केल 75GB, समांतरता सक्षम।
दुर्भाग्य से, ऐसा लगता है कि इस परीक्षण में समानता का प्रभाव बहुत सीमित है - यह थोड़ी मदद करता है, लेकिन अंतर काफी कम हैं। तो कुल मिलाकर सुधार लगभग 30% रहता है।
| कॉपी करें | PKEYS | INDEXES | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
प्रश्न
अब हम प्रश्नों पर एक नज़र डाल सकते हैं। टीपीसी-एच में 22 क्वेरी टेम्प्लेट हैं - मैंने वास्तविक प्रश्नों का एक सेट तैयार किया है, और उन्हें सभी संस्करणों पर दो बार चलाया है - पहले सभी कैश को छोड़ने और इंस्टेंस को पुनरारंभ करने के बाद, फिर वार्म-अप कैश के साथ। चार्ट में प्रस्तुत सभी नंबर इन दो रनों में से सर्वश्रेष्ठ हैं (ज्यादातर मामलों में यह दूसरा है, निश्चित रूप से)।
कोई समानता नहीं
समानता के बिना, सबसे छोटे डेटा सेट पर परिणाम बहुत स्पष्ट हैं - प्रत्येक बार 22 प्रश्नों में से प्रत्येक के लिए अलग-अलग रंगों के साथ कई भागों में विभाजित है। यह कहना मुश्किल है कि कौन सा भाग किस सटीक क्वेरी के लिए मैप करता है, लेकिन यह उन मामलों की पहचान करने के लिए पर्याप्त है जब एक क्वेरी में सुधार होता है या दो रनों के बीच बहुत खराब हो जाता है। उदाहरण के लिए पहले चार्ट में यह बहुत स्पष्ट है कि Q21 8.3 और 8.4 के बीच बहुत तेज हो गया।
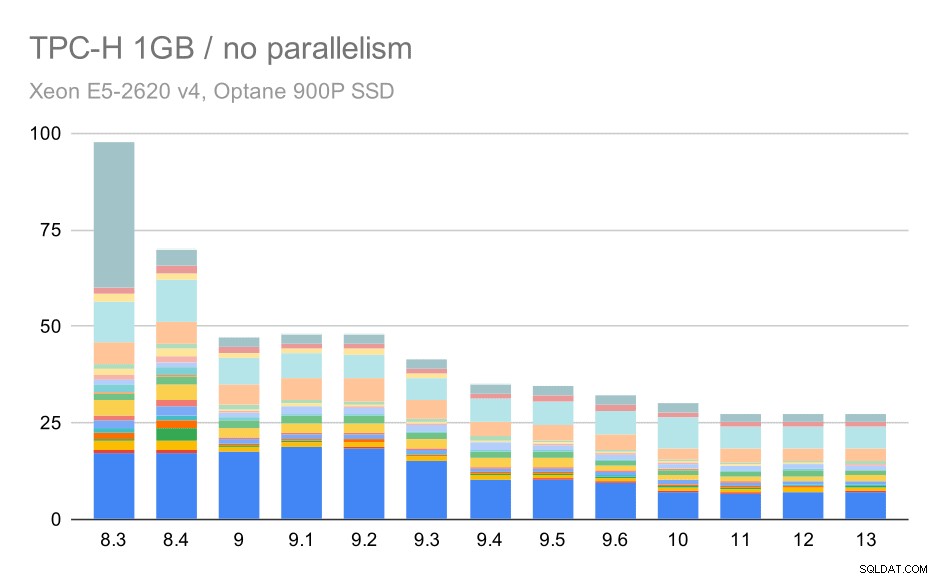
छोटे डेटा सेट (1GB) पर TPC-H क्वेरीज़ - समानांतरवाद अक्षम
10GB पैमाने के लिए, परिणामों की व्याख्या करना थोड़ा कठिन है, क्योंकि 8.3 पर एक क्वेरी (Q21) को निष्पादित करने में इतना समय लगता है कि यह बाकी सभी चीज़ों को बौना बना देता है।
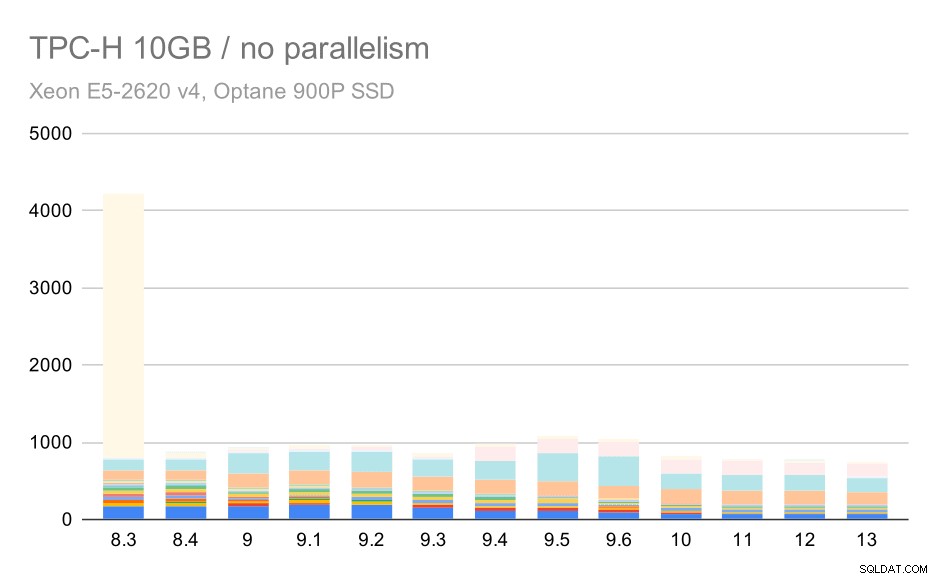
मध्यम डेटा सेट (10GB) पर TPC-H क्वेरीज़ - समानांतरवाद अक्षम
तो आइए देखें कि Q21 के बिना चार्ट कैसा दिखेगा:
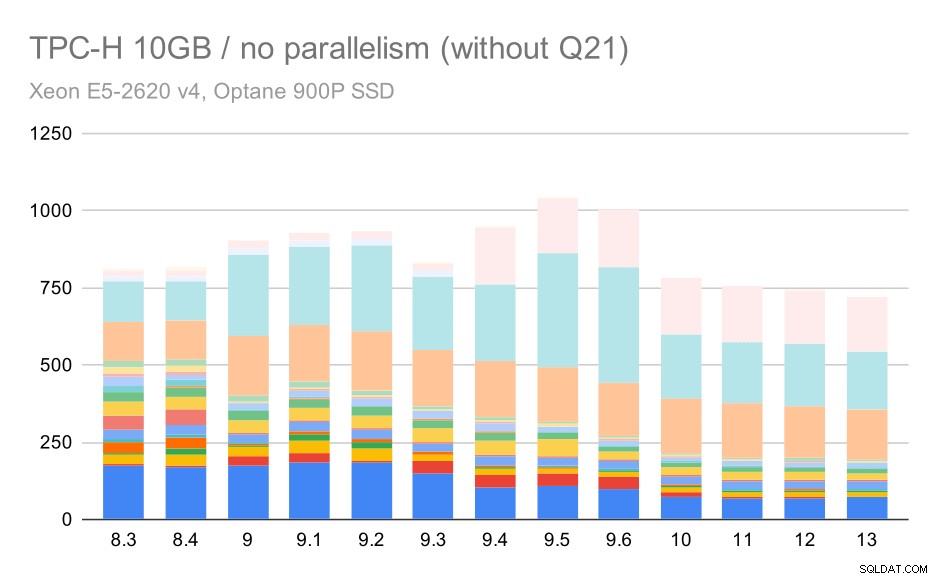
मध्यम डेटा सेट (10GB) पर TPC-H क्वेरीज़ - समांतरता अक्षम, समस्याग्रस्त Q2 के बिना
ठीक है, इसे पढ़ना आसान है। हम स्पष्ट रूप से देख सकते हैं कि अधिकांश प्रश्न (Q17 तक) तेज हो गए, लेकिन फिर दो प्रश्न (Q18 और Q20) कुछ धीमे हो गए। हम सबसे बड़े डेटा सेट पर एक समान समस्या देखेंगे, इसलिए मैं चर्चा करूंगा कि मूल कारण क्या हो सकता है।
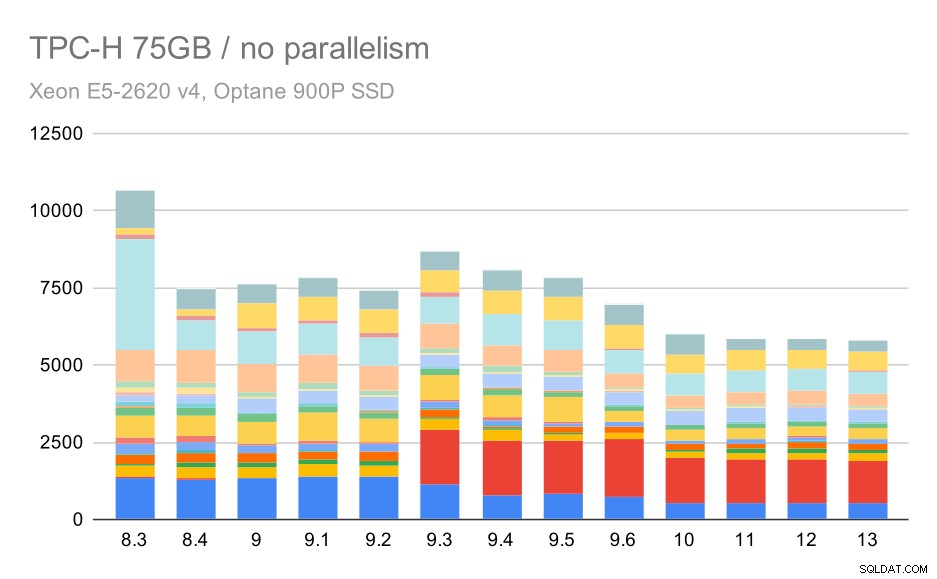
बड़े डेटा सेट (75GB) पर TPC-H क्वेरीज़ - समानांतरवाद अक्षम
फिर से, हम 9.3 में से किसी एक प्रश्न के लिए अचानक वृद्धि देखते हैं - इस बार यह Q2 है, जिसके बिना चार्ट इस तरह दिखता है:
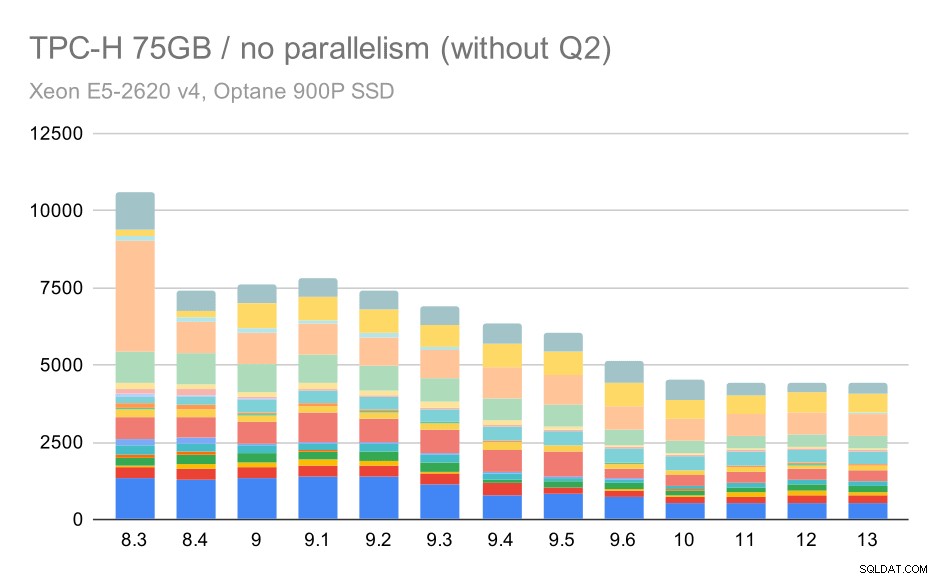
बड़े डेटा सेट (75GB) पर TPC-H क्वेरीज़ - समांतरता अक्षम, समस्याग्रस्त Q2 के बिना
यह सामान्य रूप से एक बहुत अच्छा सुधार है, पूरे निष्पादन को ~ 2.7 घंटे से केवल ~ 1.2h तक, केवल योजनाकार और अनुकूलक को स्मार्ट बनाकर, और निष्पादक को और अधिक कुशल बनाकर (याद रखें, इन रनों में समांतरता अक्षम थी) ।
तो, Q2 के साथ क्या समस्या हो सकती है, जिससे यह 9.3 में धीमा हो जाए? इसका सीधा सा जवाब है कि हर बार जब आप प्लानर और ऑप्टिमाइज़र को स्मार्ट बनाते हैं - या तो नए प्रकार के रास्तों / योजनाओं का निर्माण करके, या इसे कुछ आँकड़ों पर निर्भर बनाकर, इसका मतलब यह भी है कि आँकड़े या अनुमान गलत होने पर नई गलतियाँ हो सकती हैं। Q2 में, WHERE क्लॉज एक समग्र सबक्वेरी का संदर्भ देता है - क्वेरी का एक सरलीकृत संस्करण इस तरह दिख सकता है:
1from partsuppwhere का चयन करें ps_supplycost =(Partsupp, आपूर्तिकर्ता, राष्ट्र, क्षेत्र से Min (ps_supplycost) का चयन करें, जहां p_partkey =ps_partkey और s_suppkey =ps_suppkey और s_nationkey =n_nationkey और n_regionkey और r_namekey ='समस्या यह है कि हम नियोजन समय पर औसत मूल्य नहीं जानते हैं, जिससे WHERE स्थिति के लिए पर्याप्त रूप से अच्छे अनुमानों की गणना करना असंभव हो जाता है। वास्तविक Q2 में अतिरिक्त जोड़ होते हैं, और उनकी योजना बनाना मूल रूप से जुड़े हुए संबंधों के अच्छे अनुमानों पर निर्भर करता है। पुराने संस्करणों में ऐसा लगता है कि ऑप्टिमाइज़र सही काम कर रहा है, लेकिन फिर 9.3 में हमने इसे किसी तरह से स्मार्ट बना दिया, लेकिन खराब अनुमान के साथ यह सही निर्णय लेने में विफल रहता है। दूसरे शब्दों में, पुराने संस्करणों में अच्छी योजनाएँ केवल भाग्य थीं, योजनाकार सीमाओं के लिए धन्यवाद।
मैं शर्त लगाता हूं कि छोटे डेटा सेट पर Q18 और Q20 के प्रतिगमन भी कुछ इसी तरह के कारण होते हैं, हालांकि मैंने उनकी विस्तार से जांच नहीं की है।
मेरा मानना है कि उन अनुकूलक मुद्दों में से कुछ को लागत मापदंडों (जैसे random_page_cost आदि) को ट्यून करके ठीक किया जा सकता है, लेकिन मैंने समय की कमी के कारण ऐसा करने की कोशिश नहीं की है। हालांकि यह दिखाता है कि अपग्रेड स्वचालित रूप से सभी प्रश्नों में सुधार नहीं करता है - कभी-कभी एक अपग्रेड एक प्रतिगमन को ट्रिगर कर सकता है, इसलिए आपके आवेदन का उपयुक्त परीक्षण एक अच्छा विचार है।
समानांतरता
तो आइए देखें कि क्वेरी समांतरता परिणामों को कितना बदल देती है। फिर से, हम केवल 9.6 लेबलिंग परिणामों के बाद से रिलीज़ के परिणामों को "(p)" के साथ देखेंगे जहां समानांतर क्वेरी सक्षम है।
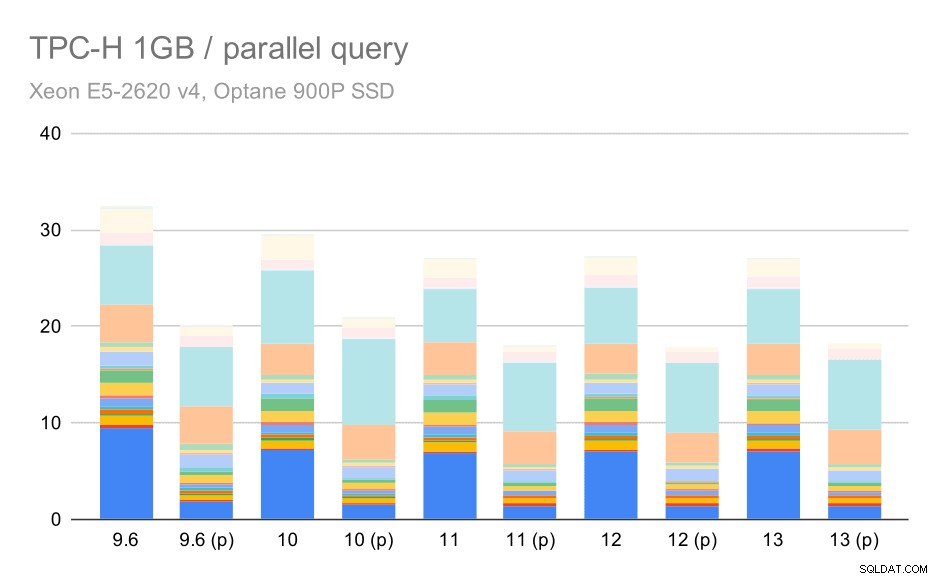
छोटे डेटा सेट (1GB) पर TPC-H क्वेरीज़ - समानांतरवाद सक्षम
स्पष्ट रूप से, समानांतरवाद काफी मदद करता है - यह इस छोटे से डेटा सेट पर भी लगभग 30% की बचत करता है। मध्यम डेटा सेट पर, नियमित और समानांतर रन के बीच बहुत अंतर नहीं है:
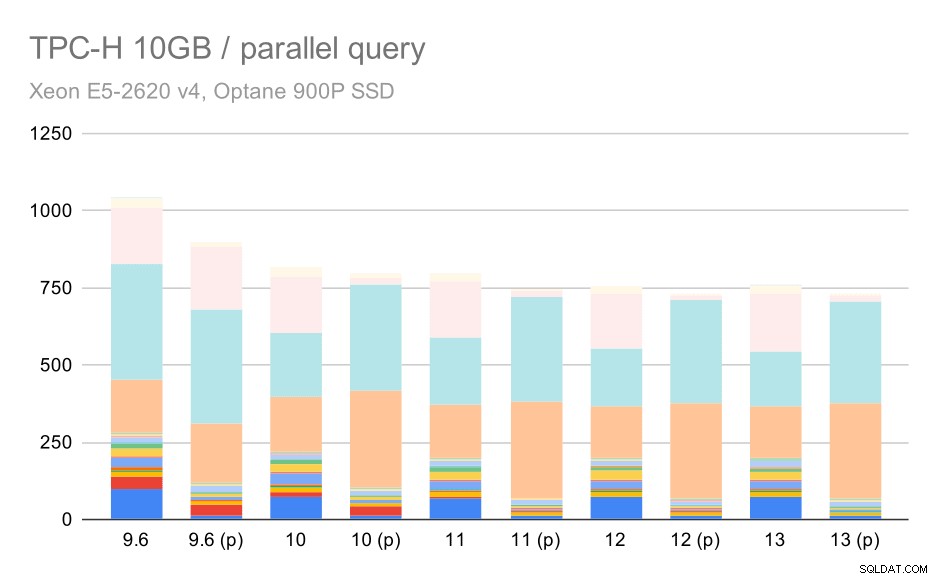
मध्यम डेटा सेट (10GB) पर TPC-H क्वेरीज़ - समानांतरवाद सक्षम
यह पहले से ही चर्चा किए गए मुद्दे का एक और प्रदर्शन है - समांतरता को सक्षम करने से अतिरिक्त क्वेरी योजनाओं पर विचार करने की अनुमति मिलती है, और स्पष्ट रूप से अनुमान या लागत वास्तविकता से मेल नहीं खाती है, जिसके परिणामस्वरूप खराब योजना विकल्प होते हैं।
और अंत में बड़ा डेटा सेट, जहां पूरे परिणाम इस तरह दिखते हैं:
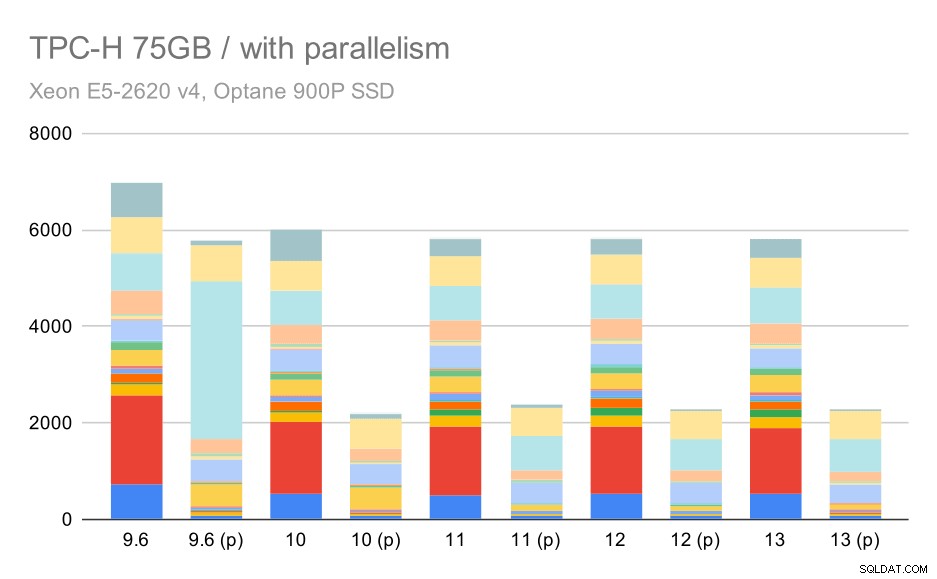
बड़े डेटा सेट (75GB) पर TPC-H क्वेरीज़ - समानांतरवाद सक्षम
यहां समांतरता को सक्षम करना हमारे लाभ में काम करता है - ऑप्टिमाइज़र Q2 के लिए एक सस्ता समानांतर योजना बनाने का प्रबंधन करता है, जो 9.3 में शुरू की गई खराब योजना पसंद को ओवरराइड करता है। लेकिन केवल पूर्णता के लिए, यहाँ Q2 के बिना परिणाम दिए गए हैं।
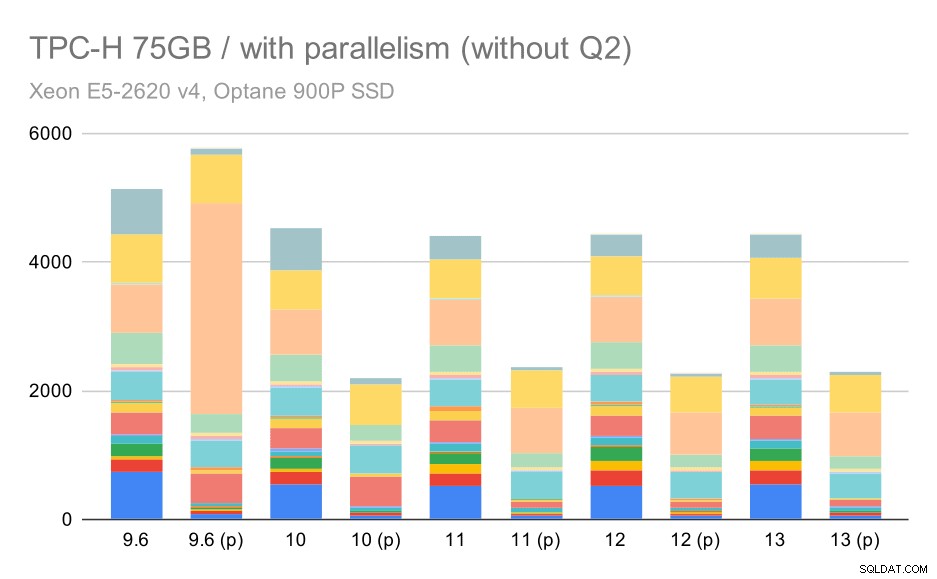
बड़े डेटा सेट (75GB) पर TPC-H क्वेरीज़ - समांतरता सक्षम, समस्याग्रस्त Q2 के बिना
यहां तक कि आप कुछ खराब समानांतर योजना विकल्पों को देख सकते हैं - उदाहरण के लिए Q9 के लिए समानांतर योजना 11 तक खराब है जहां यह तेज हो जाता है - संभवतः 11 अतिरिक्त समानांतर निष्पादक नोड्स का समर्थन करने के लिए धन्यवाद। दूसरी ओर, कुछ समानांतर क्वेरी (Q18, Q20) 11 पर धीमी हो जाती हैं, इसलिए यह केवल इंद्रधनुष और गेंडा नहीं है।
सारांश और भविष्य
मुझे लगता है कि ये परिणाम PostgreSQL 8.3 के बाद से लागू किए गए अनुकूलन को अच्छी तरह से प्रदर्शित करते हैं। समानांतरवाद के साथ परीक्षण दक्षता में सुधार (यानी समान मात्रा में संसाधनों के साथ अधिक करना) को दर्शाते हैं - डेटा लोड ~ 30% तेज हो गया और क्वेरी ~ 2x तेज हो गई। यह सच है कि मैंने अक्षम क्वेरी योजनाओं के साथ कुछ समस्याओं का सामना किया है, लेकिन क्वेरी प्लानर को स्मार्ट बनाते समय यह एक अंतर्निहित जोखिम है। हम परिणामों को अधिक विश्वसनीय बनाने के लिए लगातार काम कर रहे हैं, और मुझे यकीन है कि मैं कॉन्फ़िगरेशन को थोड़ा सा सुधार कर इनमें से अधिकांश समस्याओं को कम कर सकता हूं।
समांतरता सक्षम परिणाम दिखाते हैं कि हम अतिरिक्त संसाधनों का प्रभावी ढंग से उपयोग कर सकते हैं (विशेष रूप से सीपीयू कोर)। डेटा लोड से इसका बहुत अधिक लाभ नहीं होता है - कम से कम इस बेंचमार्क में नहीं, लेकिन क्वेरी निष्पादन पर प्रभाव महत्वपूर्ण है, जिसके परिणामस्वरूप ~ 2x स्पीडअप (हालांकि अलग-अलग क्वेरी अलग-अलग प्रभावित होती हैं, निश्चित रूप से)।
भविष्य के PostgreSQL संस्करणों में इसे सुधारने के कई अवसर हैं। उदाहरण के लिए, COPY के लिए समांतरता को लागू करने वाली एक पैच श्रृंखला है, जो डेटा लोड को तेज करती है। विश्लेषणात्मक प्रश्नों के निष्पादन में सुधार करने वाले विभिन्न पैच हैं - छोटे स्थानीय अनुकूलन से लेकर बड़ी परियोजनाओं जैसे स्तंभ भंडारण और निष्पादन, कुल पुश-डाउन, आदि। घोषणात्मक विभाजन का उपयोग करके भी बहुत कुछ प्राप्त किया जा सकता है - एक विशेषता जिसे मैंने ज्यादातर इस पर काम करते समय अनदेखा कर दिया। बेंचमार्क, सिर्फ इसलिए कि इससे दायरा बहुत ज्यादा बढ़ जाएगा। और मुझे यकीन है कि ऐसे कई अन्य अवसर हैं जिनकी मैं कल्पना भी नहीं कर सकता, लेकिन PostgreSQL समुदाय के होशियार लोग पहले से ही उन पर काम कर रहे हैं।
परिशिष्ट:PostgreSQL कॉन्फ़िगरेशन
समानांतरता अक्षम
साझा_बफ़र्स =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# लॉगिंगलॉग_चेकपॉइंट्स =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %24v_temp_%l 0# अनुकूलक डिफ़ॉल्ट_सांख्यिकी_लक्ष्य =1000random_पृष्ठ_लागत =60प्रभावी_कैश_आकार =32GB
समानांतरता सक्षम
साझा_बफ़र्स =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# लॉगिंगलॉग_चेकपॉइंट्स =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %24v_temp_files_workspergains =onlog_line_prefix='%t 16मैक्स_वर्कर_प्रोसेसेस =32मैक्स_पैरेलल_वर्कर्स =32# ऑप्टिमाइज़रडिफॉल्ट_स्टैटिस्टिक्स_टारगेट =1000 रैंडम_पेज_कॉस्ट =60 इफेक्टिव_कैश_साइज़ =32 जीबी