इस ब्लॉग श्रृंखला के तीसरे और अंतिम भाग में आपका स्वागत है, यह पता लगाने के लिए कि वर्षों में PostgreSQL का प्रदर्शन कैसे विकसित हुआ। पहले भाग में OLTP वर्कलोड को देखा गया, जिसे pgbench परीक्षणों द्वारा दर्शाया गया है। दूसरे भाग में पारंपरिक टीपीसी-एच बेंचमार्क (अनिवार्य रूप से शक्ति परीक्षण का एक हिस्सा) के सबसेट का उपयोग करते हुए विश्लेषणात्मक / बीआई प्रश्नों को देखा गया।
और यह अंतिम भाग पूर्ण-पाठ खोज को देखता है, अर्थात बड़ी मात्रा में पाठ डेटा को अनुक्रमित करने और खोजने की क्षमता। वही बुनियादी ढांचा (विशेषकर इंडेक्स) अर्ध-संरचित डेटा जैसे JSONB दस्तावेज़ आदि को अनुक्रमित करने के लिए उपयोगी हो सकता है, लेकिन यह बेंचमार्क पर केंद्रित नहीं है।
लेकिन पहले, आइए PostgreSQL में पूर्ण-पाठ खोज के इतिहास को देखें, जो RDBMS में जोड़ने के लिए एक अजीब विशेषता की तरह लग सकता है, पारंपरिक रूप से संरचित डेटा को पंक्तियों और स्तंभों में संग्रहीत करने के लिए।
पूर्ण-पाठ खोज का इतिहास
जब 1996 में Postgres को ओपन-सोर्स किया गया था, तो उसके पास कुछ भी नहीं था जिसे हम पूर्ण-पाठ खोज कह सकते हैं। लेकिन जिन लोगों ने Postgres का उपयोग करना शुरू किया, वे टेक्स्ट दस्तावेज़ों में बुद्धिमानी से खोज करना चाहते थे, और LIKE क्वेरीज़ पर्याप्त नहीं थीं। वे शब्दकोशों का उपयोग करते हुए शब्दों को लिपिबद्ध करने में सक्षम होना चाहते थे, स्टॉप शब्दों को अनदेखा करना, प्रासंगिकता के आधार पर मिलान करने वाले दस्तावेज़ों को क्रमबद्ध करना, उन प्रश्नों को निष्पादित करने के लिए अनुक्रमणिका का उपयोग करना, और कई अन्य चीजें करना चाहते थे। वे चीज़ें जो आप पारंपरिक SQL ऑपरेटरों के साथ उचित रूप से नहीं कर सकते हैं।
सौभाग्य से, उनमें से कुछ लोग भी डेवलपर थे इसलिए उन्होंने इस पर काम करना शुरू कर दिया - और वे पूरी दुनिया में ओपन-सोर्स के रूप में पोस्टग्रेएसक्यूएल उपलब्ध होने के लिए धन्यवाद कर सकते थे। पिछले कुछ वर्षों में पूर्ण-पाठ खोज में कई योगदानकर्ता रहे हैं, लेकिन शुरुआत में इस प्रयास का नेतृत्व ओलेग बार्टुनोव और टीओडोर सिगाएव ने किया था, जिसे निम्नलिखित तस्वीर में दिखाया गया है। दोनों अभी भी प्रमुख PostgreSQL योगदानकर्ता हैं, जो पूर्ण-पाठ खोज, अनुक्रमण, JSON समर्थन और कई अन्य सुविधाओं पर काम कर रहे हैं।

तेओडोर सिगेव और ओलेग बारटुनोव
प्रारंभ में, कार्यक्षमता को एक बाहरी "contrib" मॉड्यूल के रूप में विकसित किया गया था (आजकल हम कहेंगे कि यह एक एक्सटेंशन है) जिसे "tsearch" कहा जाता है, जिसे 2002 में जारी किया गया था। बाद में इसे tsearch2 द्वारा अप्रचलित कर दिया गया था, और कई मायनों में इस सुविधा में काफी सुधार हुआ था, और PostgreSQL में 8.3 (2008 में जारी) यह पूरी तरह से पोस्टग्रेएसक्यूएल कोर में एकीकृत था (यानी किसी भी एक्सटेंशन को स्थापित करने की आवश्यकता के बिना, हालांकि एक्सटेंशन अभी भी पश्चगामी संगतता के लिए प्रदान किए गए थे)।
तब से कई सुधार हुए हैं (और काम जारी है, उदाहरण के लिए JSONB जैसे डेटा प्रकारों का समर्थन करने के लिए, jsonpath आदि का उपयोग करके क्वेरी करना)। लेकिन इन प्लगइन्स ने अब हमारे पास PostgreSQL में मौजूद अधिकांश पूर्ण-पाठ कार्यक्षमता को पेश किया है - शब्दकोश, पूर्ण-पाठ अनुक्रमण और क्वेरी करने की क्षमता, आदि।
बेंचमार्क
ओएलटीपी / टीपीसी-एच बेंचमार्क के विपरीत, मुझे किसी भी पूर्ण-पाठ बेंचमार्क के बारे में पता नहीं है जिसे "उद्योग मानक" माना जा सकता है या कई डेटाबेस सिस्टम के लिए डिज़ाइन किया जा सकता है। मुझे पता है कि अधिकांश बेंचमार्क एक ही डेटाबेस / उत्पाद के साथ उपयोग किए जाने के लिए हैं, और उन्हें सार्थक रूप से पोर्ट करना कठिन है, इसलिए मुझे एक अलग मार्ग लेना पड़ा और अपना पूर्ण-पाठ बेंचमार्क लिखना पड़ा।
वर्षों पहले मैंने आर्ची लिखा था - कुछ पायथन स्क्रिप्ट जो पोस्टग्रेएसक्यूएल मेलिंग सूची अभिलेखागार को डाउनलोड करने की अनुमति देती हैं, और पार्स किए गए संदेशों को पोस्टग्रेएसक्यूएल डेटाबेस में लोड करती हैं जिन्हें तब अनुक्रमित और खोजा जा सकता है। सभी संग्रहों के वर्तमान स्नैपशॉट में ~1M पंक्तियाँ हैं, और इसे डेटाबेस में लोड करने के बाद तालिका लगभग 9.5GB (सूचकांकों की गिनती नहीं) है।
प्रश्नों के लिए, मैं शायद कुछ यादृच्छिक उत्पन्न कर सकता हूं, लेकिन मुझे यकीन नहीं है कि यह कितना यथार्थवादी होगा। सौभाग्य से, कुछ साल पहले मैंने PostgreSQL वेबसाइट से 33k वास्तविक खोजों का एक नमूना प्राप्त किया था (यानी वे चीजें जो लोगों ने वास्तव में सामुदायिक अभिलेखागार में खोजी थीं)। यह संभावना नहीं है कि मुझे कुछ और यथार्थवादी / प्रतिनिधि मिल सकता है।
उन दो भागों (डेटा सेट + क्वेरीज़) का संयोजन एक अच्छा बेंचमार्क जैसा लगता है। हम केवल डेटा लोड कर सकते हैं, और विभिन्न प्रकार के इंडेक्स के साथ विभिन्न प्रकार के पूर्ण-पाठ प्रश्नों के साथ खोजों को चला सकते हैं।
प्रश्न
पूर्ण-पाठ प्रश्नों के विभिन्न आकार हैं - क्वेरी बस सभी मिलान पंक्तियों का चयन कर सकती है, यह परिणामों को रैंक कर सकती है (उन्हें प्रासंगिकता के अनुसार क्रमबद्ध करें), केवल एक छोटी संख्या या सबसे प्रासंगिक परिणाम लौटाएं, आदि। मैंने विभिन्न के साथ बेंचमार्क चलाया प्रश्नों के प्रकार, लेकिन इस पोस्ट में मैं दो सरल प्रश्नों के परिणाम प्रस्तुत करूंगा जो मुझे लगता है कि समग्र व्यवहार को काफी अच्छी तरह से दर्शाते हैं।
- चयन आईडी, संदेशों से विषय जहां body_tsvector @@ $1
- चयन आईडी, संदेशों से विषय जहां body_tsvector @@ $1
ts_rank(body_tsvector, $1) DESC LIMIT 100
द्वारा आदेश
पहली क्वेरी बस सभी मिलान करने वाली पंक्तियों को लौटाती है, जबकि दूसरी 100 सबसे प्रासंगिक परिणाम लौटाती है (यह कुछ ऐसा है जिसे आप शायद उपयोगकर्ता खोजों के लिए उपयोग करेंगे)।
मैंने कई अन्य प्रकार के प्रश्नों के साथ प्रयोग किया है, लेकिन उन सभी ने अंततः इन दो क्वेरी प्रकारों में से एक के समान व्यवहार किया।
सूचकांक
प्रत्येक संदेश के दो मुख्य भाग होते हैं जिन्हें हम खोज सकते हैं - विषय और मुख्य भाग। उनमें से प्रत्येक के पास एक अलग tsvector कॉलम है, और अलग से अनुक्रमित किया गया है। संदेश के विषय बॉडी से बहुत छोटे होते हैं, इसलिए इंडेक्स स्वाभाविक रूप से छोटे होते हैं।
PostgreSQL में पूर्ण-पाठ खोज के लिए दो प्रकार के अनुक्रमणिका उपयोगी हैं - GIN और GiST। मुख्य अंतरों को डॉक्स में समझाया गया है, लेकिन संक्षेप में:
- खोजों के लिए GIN अनुक्रमणिका तेज़ होती हैं
- GiST अनुक्रमणिका हानिपूर्ण हैं, यानी खोज के दौरान पुन:जांच की आवश्यकता होती है (और इसलिए धीमी होती हैं)
हम दावा करते थे कि जीआईएसटी इंडेक्स अपडेट करने के लिए सस्ता है (विशेषकर कई समवर्ती सत्रों के साथ), लेकिन कुछ समय पहले इंडेक्सिंग कोड में सुधार के कारण इसे दस्तावेज़ीकरण से हटा दिया गया था।
यह बेंचमार्क अपडेट के साथ व्यवहार का परीक्षण नहीं करता है - यह केवल पूर्ण-पाठ अनुक्रमणिका के बिना तालिका को लोड करता है, उन्हें एक बार में बनाता है, और फिर डेटा पर 33k प्रश्नों को निष्पादित करता है। इसका मतलब है कि मैं इस बारे में कोई बयान नहीं दे सकता कि वे इंडेक्स प्रकार इस बेंचमार्क के आधार पर समवर्ती अपडेट कैसे संभालते हैं, लेकिन मेरा मानना है कि दस्तावेज़ीकरण परिवर्तन हाल के विभिन्न जीआईएन सुधारों को दर्शाते हैं।
यह मेलिंग सूची संग्रह उपयोग के मामले से भी अच्छी तरह से मेल खाना चाहिए, जहां हम केवल एक बार में नए ईमेल जोड़ते हैं (कुछ अपडेट, लगभग कोई लेखन संगामिति नहीं)। लेकिन अगर आपका एप्लिकेशन बहुत सारे समवर्ती अपडेट करता है, तो आपको इसे स्वयं बेंचमार्क करना होगा।
हार्डवेयर
मैंने पहले की तरह ही दो मशीनों पर बेंचमार्क किया था, लेकिन परिणाम/निष्कर्ष लगभग समान हैं, इसलिए मैं केवल छोटी मशीन से ही संख्याएं प्रस्तुत करूंगा, यानी
- सीपीयू i5-2500K (4 कोर/थ्रेड्स)
- 8GB रैम
- 6 x 100GB SSD RAID0
- कर्नेल 5.6.15, ext4 फ़ाइल सिस्टम
मैंने पहले उल्लेख किया है कि लोड होने पर डेटा सेट में लगभग 10GB है, इसलिए यह RAM से बड़ा है। लेकिन इंडेक्स अभी भी RAM से छोटे हैं, जो बेंचमार्क के लिए मायने रखता है।
परिणाम
ठीक है, कुछ नंबरों और चार्ट के लिए समय। मैं डेटा लोड और क्वेरी, दोनों के लिए पहले GIN और फिर GiST इंडेक्स के साथ नतीजे पेश करूंगा।
GIN / डेटा लोड
लोड विशेष रूप से दिलचस्प नहीं है, मुझे लगता है। सबसे पहले, इसमें से अधिकांश (नीला भाग) का पूर्ण-पाठ से कोई लेना-देना नहीं है, क्योंकि यह दो अनुक्रमणिका बनने से पहले होता है। इस समय का अधिकांश समय संदेशों को पार्स करने, मेल थ्रेड्स को फिर से बनाने, उत्तरों की सूची बनाए रखने आदि में व्यतीत होता है। इनमें से कुछ कोड पीएल/पीजीएसक्यूएल ट्रिगर्स में कार्यान्वित किए जाते हैं, इनमें से कुछ डेटाबेस के बाहर कार्यान्वित किए जाते हैं। पूर्ण-पाठ के लिए संभावित रूप से प्रासंगिक एक हिस्सा tsvectors का निर्माण कर रहा है, लेकिन उस पर खर्च किए गए समय को अलग करना असंभव है।
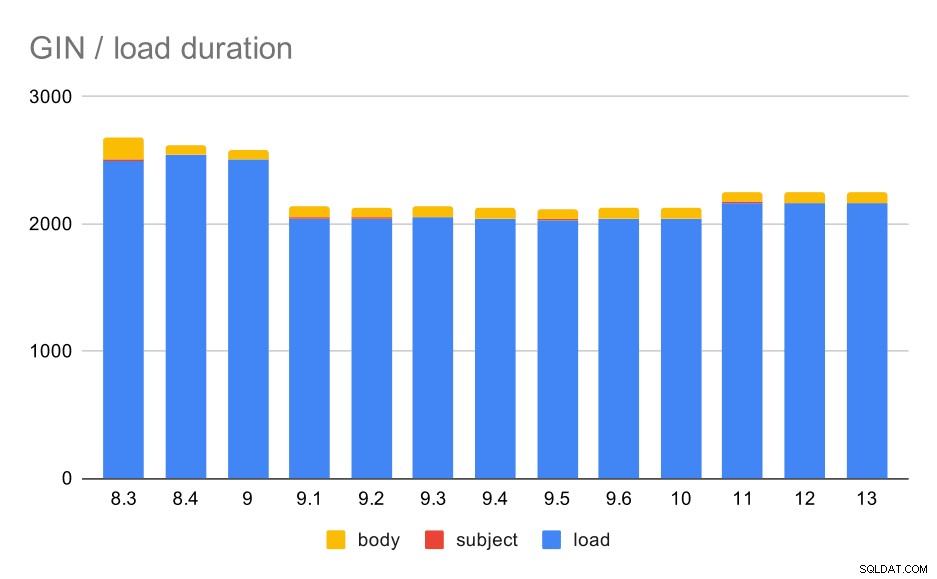
तालिका और GIN अनुक्रमणिका के साथ डेटा लोड संचालन।
निम्न तालिका इस चार्ट के लिए स्रोत डेटा दिखाती है - मान सेकंड में अवधि हैं। LOAD में mbox आर्काइव्स (पायथन स्क्रिप्ट से) को पार्स करना, एक टेबल में सम्मिलित करना और विभिन्न अतिरिक्त कार्य (ई-मेल थ्रेड्स का पुनर्निर्माण, आदि) शामिल हैं। SUBJECT/BODY INDEX डेटा लोड होने के बाद विषय/बॉडी कॉलम पर पूर्ण-पाठ GIN इंडेक्स के निर्माण को संदर्भित करता है।
| लोड करें | SUBJECT INDEX | बॉडी इंडेक्स | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
जाहिर है, प्रदर्शन काफी स्थिर है - 9.0 और 9.1 के बीच काफी महत्वपूर्ण सुधार (लगभग 20%) हुआ है। मुझे पूरा यकीन नहीं है कि इस सुधार के लिए कौन सा परिवर्तन जिम्मेदार हो सकता है - 9.1 जारी नोटों में कुछ भी स्पष्ट रूप से प्रासंगिक नहीं लगता है। 8.4 में GIN इंडेक्स के निर्माण में भी स्पष्ट सुधार हुआ है, जो समय को लगभग आधा कर देता है। जो अच्छा है, बिल्कुल। दिलचस्प बात यह है कि मुझे इसके लिए कोई स्पष्ट रूप से संबंधित रिलीज़ नोट आइटम भी नहीं दिख रहा है।
हालांकि, GIN इंडेक्स के आकार के बारे में क्या? बहुत अधिक परिवर्तनशीलता है, कम से कम 9.4 तक, जिस बिंदु पर इंडेक्स का आकार ~1GB से गिरकर केवल 670MB (लगभग 30%) हो जाता है।
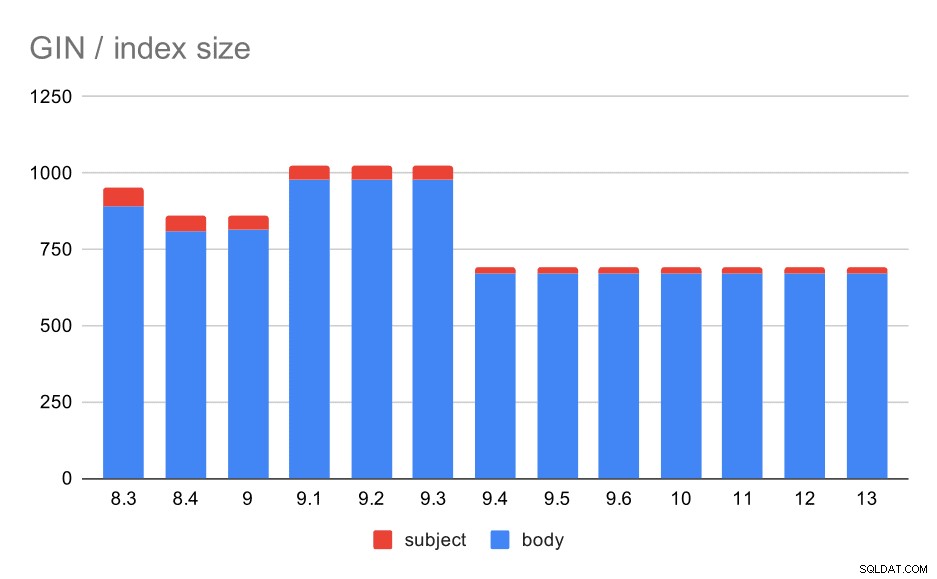
संदेश विषय/शरीर पर GIN अनुक्रमणिका का आकार। मान मेगाबाइट हैं।
निम्न तालिका संदेश के मुख्य भाग और विषय पर GIN अनुक्रमणिका के आकार को दर्शाती है। मान मेगाबाइट में हैं।
| बॉडी | विषय | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
इस मामले में, मुझे लगता है कि हम सुरक्षित रूप से यह मान सकते हैं कि यह गति 9.4 रिलीज़ नोटों में इस आइटम से संबंधित है:
- GIN इंडेक्स का आकार कम करें (सिकंदर कोरोटकोव, हिक्की लिन्नाकांगस)
8.3 और 9.1 के बीच आकार परिवर्तनशीलता लेमेटाइजेशन में परिवर्तन (शब्दों को "मूल" रूप में कैसे परिवर्तित किया जाता है) के कारण प्रतीत होता है। आकार के अंतरों के अलावा, उन संस्करणों की क्वेरीज़, उदाहरण के लिए, परिणामों की थोड़ी भिन्न संख्याएँ लौटाती हैं।
GIN / क्वेरीज़
अब, इस बेंचमार्क का मुख्य भाग - क्वेरी प्रदर्शन। यहां प्रस्तुत सभी नंबर एक ही क्लाइंट के लिए हैं - हमने पहले ही OLTP प्रदर्शन से संबंधित भाग में क्लाइंट स्केलेबिलिटी पर चर्चा की है, निष्कर्ष इन प्रश्नों पर भी लागू होते हैं। (इसके अलावा, इस विशेष मशीन में केवल 4 कोर हैं, इसलिए हम वैसे भी मापनीयता परीक्षण के मामले में बहुत दूर नहीं होंगे।)
चयन आईडी, संदेशों से विषय जहां tsvector @@ $1
सबसे पहले, सभी मेल खाने वाले दस्तावेज़ों की खोज करने वाली क्वेरी। "विषय" कॉलम में खोजों के लिए हम प्रति सेकंड लगभग 800 प्रश्न कर सकते हैं (और यह वास्तव में 9.1 में थोड़ा कम हो जाता है), लेकिन 9.4 में यह अचानक प्रति सेकंड 3000 प्रश्नों तक शूट करता है। "बॉडी" कॉलम के लिए यह मूल रूप से एक ही कहानी है - शुरू में 160 क्वेरीज़, 9.1 में ~90 क्वेरीज़ तक गिरती हैं, और फिर 9.4 में 300 तक बढ़ जाती हैं।
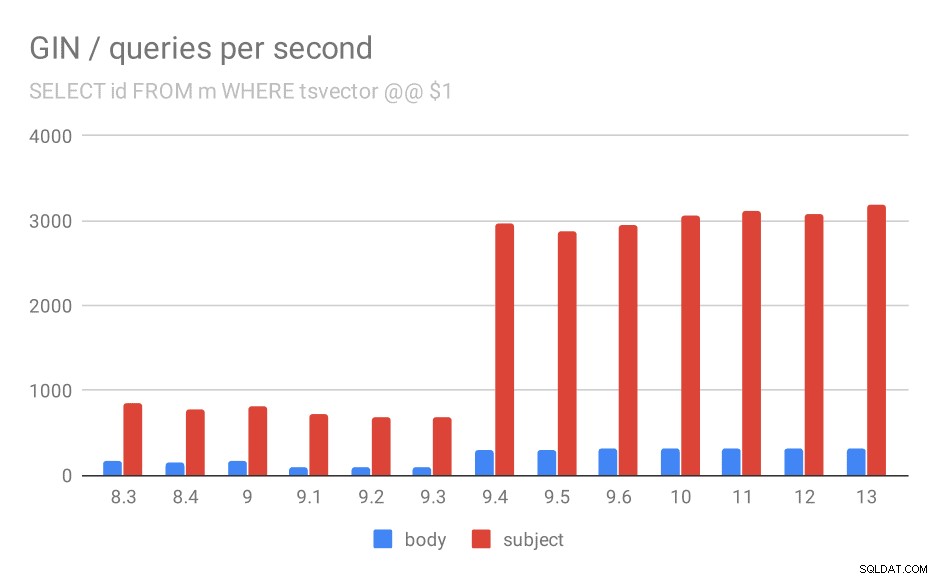
पहली क्वेरी के लिए प्रति सेकंड प्रश्नों की संख्या (सभी मिलान पंक्तियों को ला रही है)।
और फिर से, स्रोत डेटा - संख्याएँ थ्रूपुट (क्वेरी प्रति सेकंड) हैं।
| बॉडी | विषय | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
मुझे लगता है कि हम सुरक्षित रूप से मान सकते हैं कि 9.4 में सुधार इस मद से संबंधित रिलीज नोट्स में है:
- बहु-कुंजी GIN लुकअप की गति में सुधार करें (सिकंदर कोरोटकोव, हिक्की लिन्नाकांगस)
इसलिए, उन्हीं दो डेवलपर्स से GIN में एक और 9.4 सुधार - स्पष्ट रूप से, सिकंदर और हिक्की ने 9.4 रिलीज़ में GIN इंडेक्स पर बहुत अच्छा काम किया 😉
चयन आईडी, संदेशों से विषय जहां tsvector @@ $1
ts_rank(tsvector, $2) द्वारा आदेश DESC LIMIT 100
ts_rank और LIMIT का उपयोग करते हुए प्रासंगिकता के आधार पर परिणामों की रैंकिंग करने वाली क्वेरी के लिए, समग्र व्यवहार लगभग समान है, मुझे लगता है कि चार्ट का विस्तार से वर्णन करने की कोई आवश्यकता नहीं है।
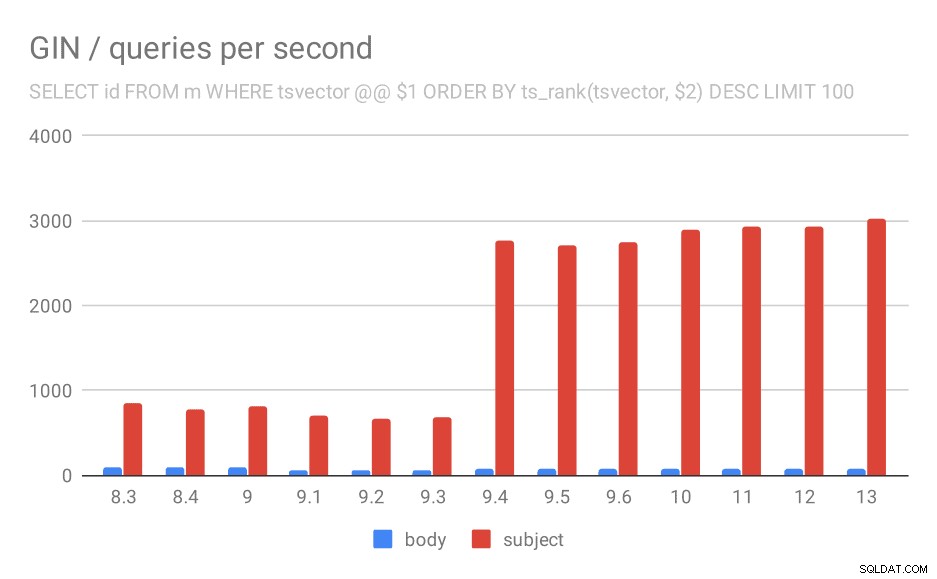
दूसरी क्वेरी के लिए प्रति सेकंड प्रश्नों की संख्या (सबसे प्रासंगिक पंक्तियों को लाना)।
| बॉडी | विषय | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
हालांकि, एक सवाल है - 9.0 और 9.1 के बीच प्रदर्शन में गिरावट क्यों आई? ऐसा लगता है कि थ्रूपुट में काफी महत्वपूर्ण गिरावट आई है - शरीर की खोजों के लिए लगभग 50% और संदेश विषयों में खोजों के लिए 20% तक। मेरे पास स्पष्ट स्पष्टीकरण नहीं है कि क्या हुआ, लेकिन मेरे पास दो अवलोकन हैं …
सबसे पहले, सूचकांक का आकार बदल गया - यदि आप पहले चार्ट "GIN / अनुक्रमणिका आकार" और तालिका को देखते हैं, तो आप देखेंगे कि संदेश निकायों पर सूचकांक 813MB से बढ़कर लगभग 977MB हो गया है। यह एक महत्वपूर्ण वृद्धि है, और यह कुछ मंदी की व्याख्या कर सकता है। हालाँकि समस्या यह है कि विषयों पर सूचकांक बिल्कुल नहीं बढ़ा, फिर भी प्रश्न धीमे हो गए।
दूसरे, हम देख सकते हैं कि कितने परिणाम लौटे प्रश्न। अनुक्रमित डेटा सेट बिल्कुल समान है, इसलिए सभी PostgreSQL संस्करणों में समान परिणामों की अपेक्षा करना उचित लगता है, है ना? खैर, व्यवहार में ऐसा दिखता है:
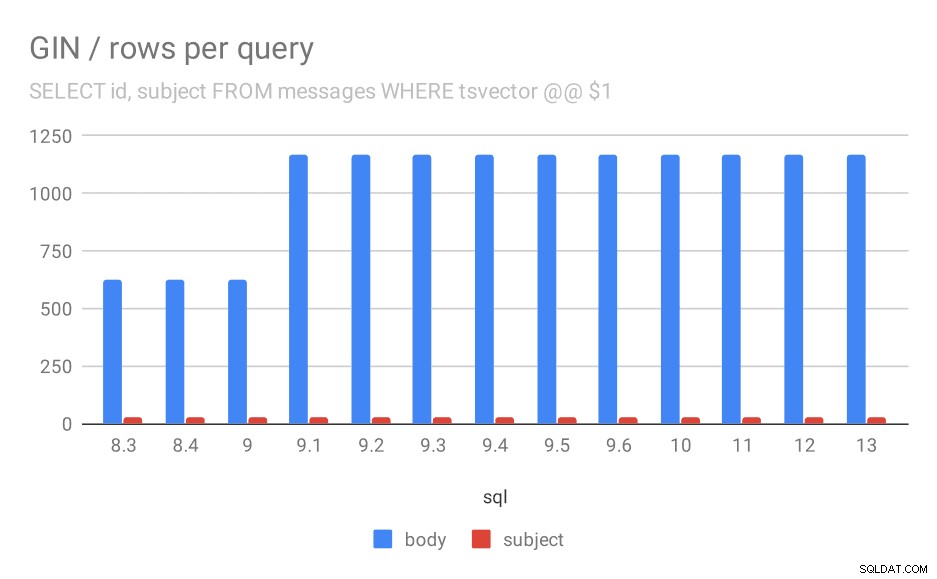
किसी क्वेरी के लिए औसतन लौटाई गई पंक्तियों की संख्या.
| बॉडी | विषय | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
स्पष्ट रूप से, 9.1 में संदेश निकायों में खोजों के परिणामों की औसत संख्या अचानक दोगुनी हो जाती है, जो मंदी के लगभग पूरी तरह से आनुपातिक है। हालांकि विषय खोजों के लिए परिणामों की संख्या वही रहती है। मेरे पास इसके लिए बहुत अच्छी व्याख्या नहीं है, सिवाय इसके कि अनुक्रमण इस तरह से बदल गया है जो अधिक संदेशों के मिलान की अनुमति देता है, लेकिन इसे थोड़ा धीमा कर देता है। अगर आपके पास बेहतर स्पष्टीकरण हैं, तो मैं उन्हें सुनना चाहूंगा!
GiST / डेटा लोड
अब, अन्य प्रकार के पूर्ण-पाठ अनुक्रमणिका - जीआईएसटी। ये अनुक्रमणिका हानिपूर्ण हैं, यानी तालिका से मानों का उपयोग करके परिणामों की पुन:जांच की आवश्यकता है। इसलिए हम GIN इंडेक्स की तुलना में कम थ्रूपुट की उम्मीद कर सकते हैं, लेकिन अन्यथा मोटे तौर पर उसी पैटर्न की अपेक्षा करना उचित है।
लोड समय वास्तव में GIN से लगभग पूरी तरह मेल खाता है - सूचकांक निर्माण समय अलग है, लेकिन समग्र पैटर्न समान है। 9.1 में स्पीडअप, 11 में छोटी मंदी।
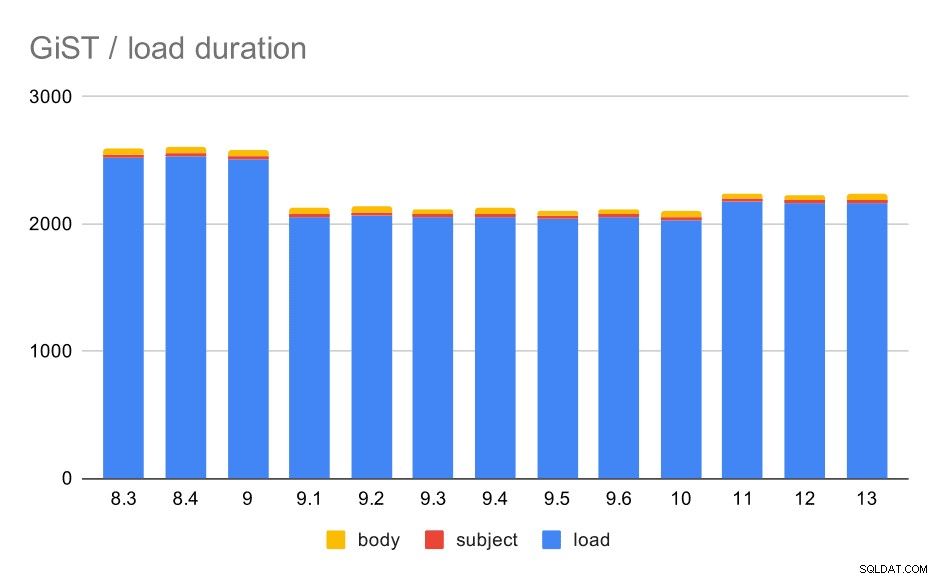
एक टेबल और जिस्ट इंडेक्स के साथ डेटा लोड ऑपरेशन।
| लोड करें | विषय | बॉडी | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
हालांकि सूचकांक का आकार लगभग स्थिर रहा - 9.4 में जीआईएन के समान कोई जीआईएसटी सुधार नहीं हुआ, जिससे आकार में ~ 30% की कमी आई। 9.1 की वृद्धि हुई है, जो एक और संकेत है कि पूर्ण-पाठ अनुक्रमणिका उस संस्करण में अधिक शब्दों को अनुक्रमित करने के लिए बदल गई है।
यह जीआईएसटी के साथ परिणामों की औसत संख्या द्वारा समर्थित है, जीआईएन के समान ही (9.1 की वृद्धि के साथ)।
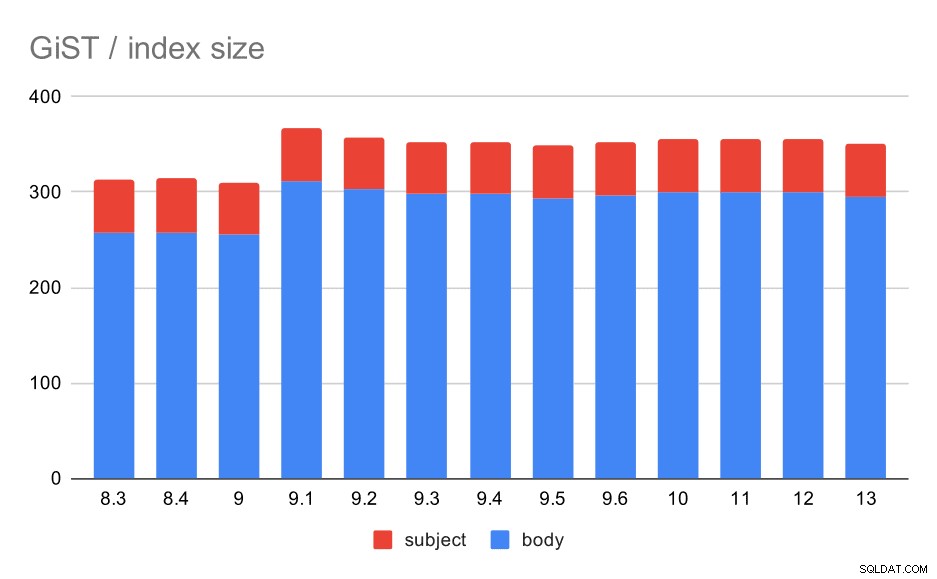
संदेश विषय/बॉडी पर जीआईएसटी इंडेक्स का आकार। मान मेगाबाइट हैं।
| बॉडी | विषय | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
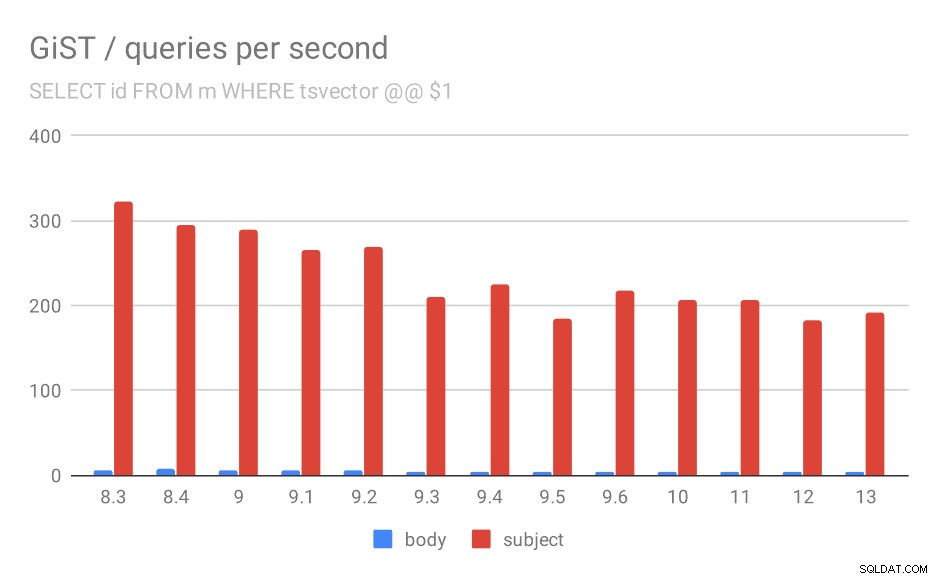
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
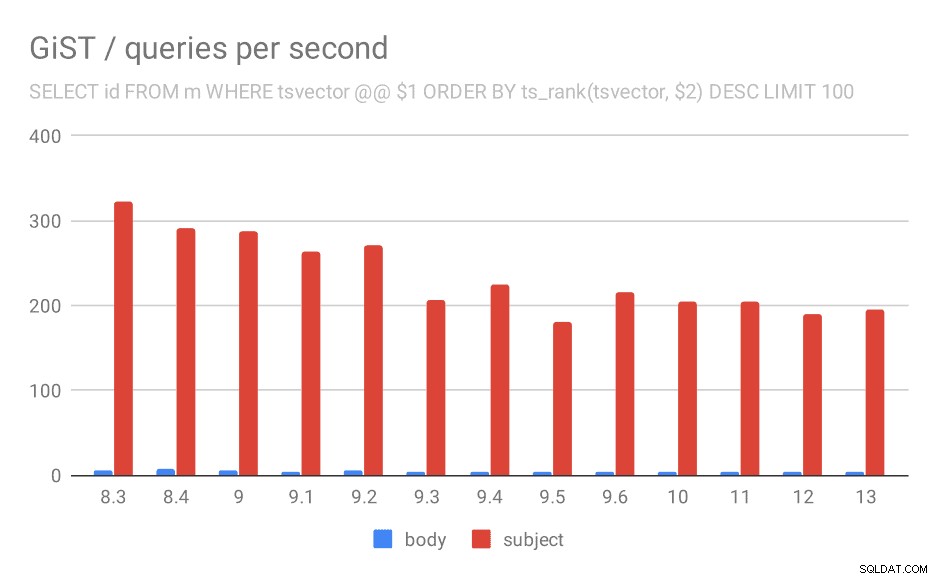
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).