फरवरी में मैंने SQL सर्वर में स्वचालित योजना सुधार के बारे में एक ब्लॉग पोस्ट लिखा था, और इस पोस्ट में मैं स्वचालित अनुक्रमण सुविधा के दूसरे घटक स्वचालित अनुक्रमणिका प्रबंधन के बारे में बात करना चाहता हूं। स्वचालित अनुक्रमणिका प्रबंधन केवल Azure SQL डेटाबेस में उपलब्ध है, और यह वर्तमान में SQL सर्वर ऑन-प्रिमाइसेस की अगली रिलीज़ में उपलब्ध होने के रोडमैप पर नहीं है। यह विकल्प स्वचालित योजना सुधार से स्वतंत्र रूप से सक्षम है, और जैसा कि नाम से पता चलता है, यह आपके डेटाबेस में अनुक्रमणिका का प्रबंधन करेगा। विशेष रूप से, यह उन अनुक्रमणिकाओं को बना सकता है जो गायब हैं, और यह उन अनुक्रमणिकाओं को हटा सकता है जिनका उपयोग नहीं किया गया है, और जो डुप्लीकेट हैं। आइए देखें कि यह कैसे होता है।
अंडर द कवर्स
स्वचालित अनुक्रमणिका प्रबंधन अपना निर्णय लेने के लिए डेटा पर निर्भर करता है। संभावित सूचकांक निर्माण के लिए, यह लापता सूचकांक DMV की जानकारी का उपयोग करता है और समय के साथ इसे ट्रैक करता है और सूचकांक के लाभ को निर्धारित करने के लिए उस डेटा को एक आंतरिक मॉडल के साथ जोड़ता है। यह यह निर्धारित करने के लिए क्वेरी स्टोर का भी उपयोग करता है कि क्या सूचकांक लाभ प्रदान करता है, इसलिए इसे डेटाबेस के लिए सक्षम किया जाना चाहिए, जैसे कि स्वचालित योजना सुधार के साथ। अनुक्रमणिका छोड़ने के संबंध में, अनुक्रमणिका उपयोग DMV (sys.dm_db_index_usage_stats) के साथ-साथ अनुक्रमणिका मेटाडेटा (उदा. स्तंभों की संख्या, स्तंभ डेटा प्रकार) के डेटा का उपयोग किया जाता है।
स्वचालित अनुक्रमणिका प्रबंधन सक्षम करना
जैसा कि बताया गया है, डेटाबेस के लिए क्वेरी स्टोर सक्षम होना चाहिए। यह SSMS में, T-SQL के साथ, और Azure SQL डेटाबेस के लिए REST API के साथ किया जा सकता है। ध्यान दें कि क्वेरी स्टोर Azure में डेटाबेस के लिए डिफ़ॉल्ट रूप से सक्षम है, और 2016 की चौथी तिमाही से है।
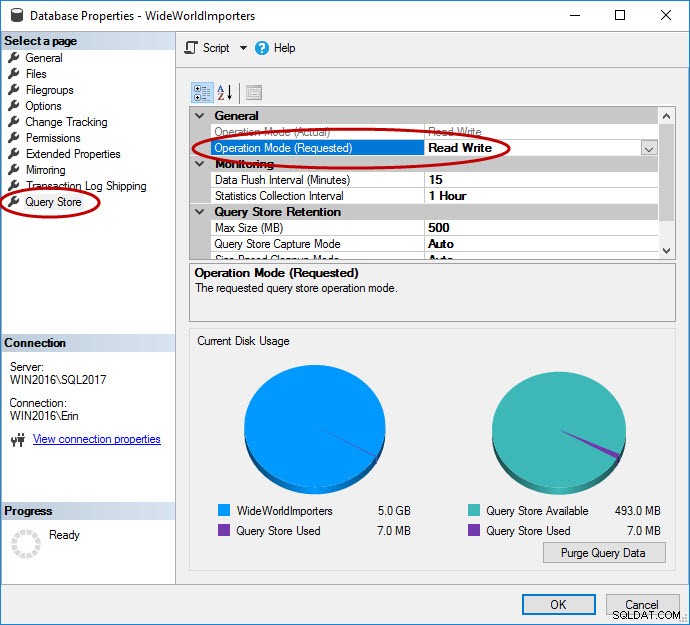
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
एक बार क्वेरी स्टोर सक्षम हो जाने पर, आप Azure SQL डेटाबेस में स्वचालित अनुक्रमणिका प्रबंधन को सक्षम करने के लिए Azure पोर्टल, T-SQL, या EST API का उपयोग कर सकते हैं (C# और PowerShell काम कर रहे हैं)।
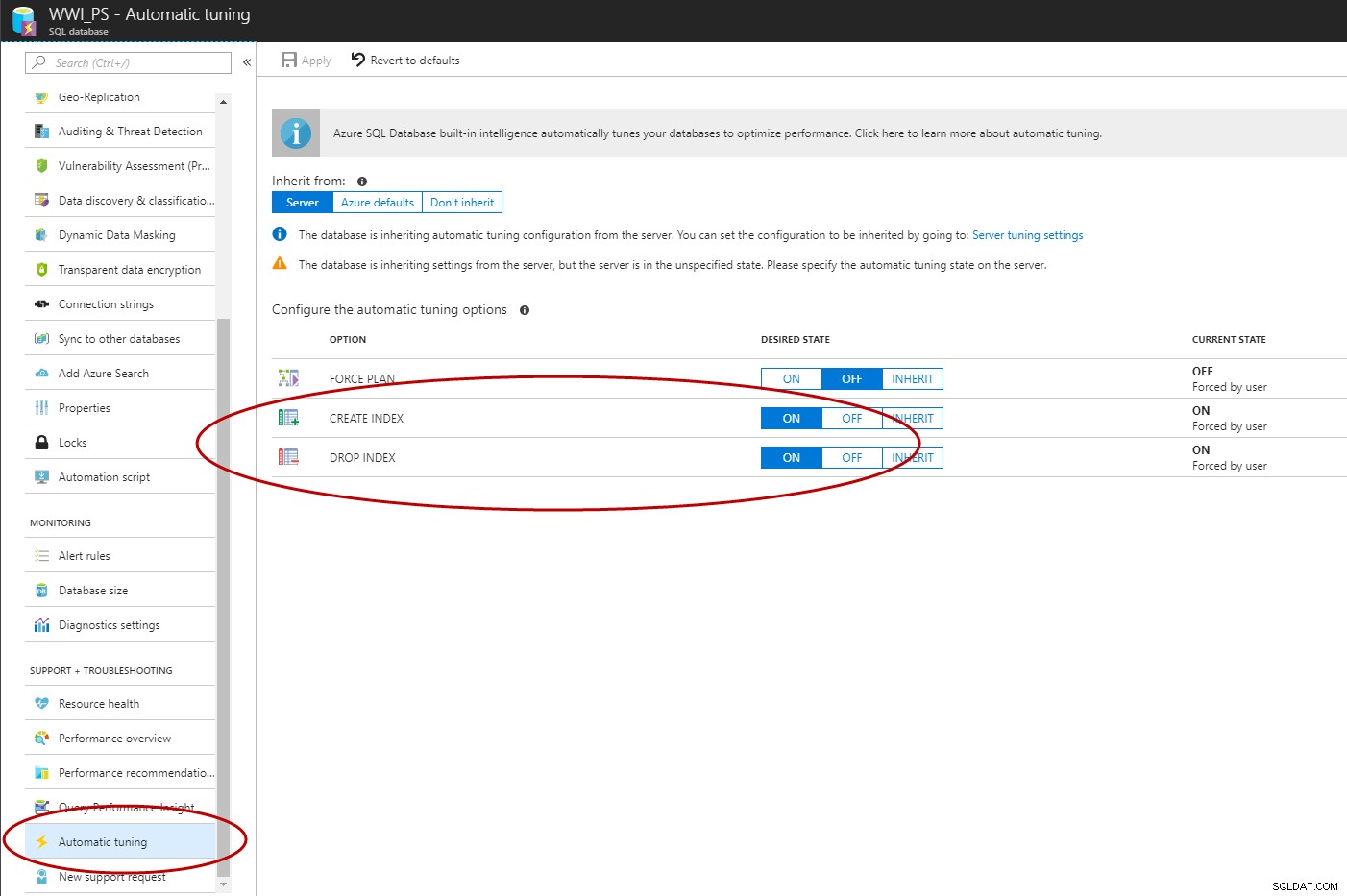
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
निकट भविष्य में Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) में नए डेटाबेस के लिए डिफ़ॉल्ट रूप से स्वचालित अनुक्रमणिका प्रबंधन सक्षम किया जाएगा। 2018 के जनवरी से शुरू होकर, Microsoft ने Azure SQL डेटाबेस के लिए स्वचालित ट्यूनिंग को सक्षम करने के लिए रोल-आउट शुरू किया, जिसमें पहले से ही इसे सक्षम नहीं किया गया था, प्रशासकों को सूचनाएं भेजी गईं ताकि विकल्प को वांछित होने पर अक्षम किया जा सके। इस प्रक्रिया में कई महीने लगते हैं, इसलिए यदि आपको अभी तक कोई सूचना नहीं मिली है, तो घबराएं नहीं!
यह कैसे काम करता है
इंडेक्स बनाने के लिए, वर्तमान में, सात (7) दिनों* की एक रोलिंग विंडो है, जिसमें डेटा ट्रैक किया जाता है, और एक इंडेक्स की सिफारिश करने के लिए मॉडल को कम से कम नौ (9) घंटे* डेटा की आवश्यकता होती है, साथ ही क्वेरी स्टोर में 12 घंटे* के डेटा के साथ, जिसका उपयोग आधार रेखा के रूप में किया जाएगा। यदि यह निर्धारित किया जाता है कि कोई अनुक्रमणिका महत्वपूर्ण लाभ प्रदान करेगी, तो SQL सर्वर अनुक्रमणिका बनाएगा।
*भविष्य में मॉडल के विकसित होने पर ये मान बदल सकते हैं।
नोट:वर्तमान में मॉडल अनुशंसाओं को मर्ज करता है। यही है, यदि एक तालिका के लिए एकाधिक अनुक्रमणिका की अनुशंसा की जाती है, लेकिन सभी विकल्पों को कवर करने के लिए एक अनुक्रमणिका बनाई जा सकती है, तो यह वर्तमान में एक अनुक्रमणिका बना सकती है। हालांकि, मॉडल वर्तमान में एक अनुशंसित इंडेक्स को पहले से मौजूद इंडेक्स के साथ मर्ज करने के लिए पर्याप्त बुद्धिमान नहीं है।
एक बार एक इंडेक्स बन जाने के बाद, SQL सर्वर सत्यापित करता है कि यह क्वेरी स्टोर का उपयोग करके लाभ प्रदान करता है (इस प्रकार डेटाबेस के लिए सक्षम होना चाहिए)। यह किसी भी क्वेरी के प्रदर्शन पर नज़र रखता है जो नई अनुक्रमणिका का उपयोग करता है और अनुक्रमणिका को जोड़ने से पहले और अनुक्रमणिका का उपयोग करते समय क्वेरी के CPU की तुलना करता है। यदि अनुक्रमणिका के परिणामस्वरूप क्वेरी प्रदर्शन में कोई प्रतिगमन होता है, तो यह अनुक्रमणिका को वापस (छोड़) देगा। SQL सर्वर तीन (3) दिनों तक या प्रासंगिक कार्यभार के 100% का विश्लेषण किए जाने तक क्वेरी प्रदर्शन की निगरानी करता है। उस समयावधि के बाद, यदि सूचकांक प्रतिगमन के कोई संकेत नहीं दिखाता है, तो यह इसके लिए फिर से प्रदर्शन की समीक्षा नहीं करेगा।
समझें कि यदि स्वचालित सूचकांक प्रबंधन एक सूचकांक बनाता है, और फिर दो महीने बाद आपका कार्यभार बदल जाता है और यह उसी सूचकांक से लाभान्वित होगा जो पहले से स्वचालित रूप से बनाया गया था लेकिन एक अतिरिक्त कॉलम के साथ, तो SQL सर्वर वर्तमान में एक नया सूचकांक बनाएगा। वर्तमान में किसी मौजूदा स्वतः-निर्मित अनुक्रमणिका को बदलने का कोई तर्क नहीं है, लेकिन वह कार्यक्षमता सुविधा के रोडमैप पर है।
इंडेक्स छोड़ने के संबंध में, यदि किसी इंडेक्स में 90 दिनों के लिए कोई खोज या स्कैन नहीं है, लेकिन इसकी रखरखाव लागत है (मतलब इसमें सम्मिलित, अपडेट या हटाए गए हैं) तो इसे छोड़ दिया जाएगा। डुप्लिकेट इंडेक्स भी हटा दिए जाएंगे, यह मानते हुए कि वे एक सटीक डुप्लिकेट हैं (और स्कीमा का उपयोग यह निर्धारित करने के लिए किया जाता है कि क्या इंडेक्स बिल्कुल समान हैं)। यदि कुंजी कॉलम और शामिल कॉलम (यदि प्रासंगिक हो) के संदर्भ में डुप्लिकेट इंडेक्स हैं, लेकिन उनमें से एक या अधिक में फ़िल्टर है, तो वे वास्तव में डुप्लिकेट नहीं हैं और कोई इंडेक्स नहीं छोड़ा जाएगा।
संदर्भ के लिए, Azure SQL डेटाबेस में DROP INDEX अनुशंसाओं की तुलना में दो गुना अधिक हैं, क्योंकि CREATE INDEX अनुशंसाएँ हैं।
जब आप DROP INDEX विकल्प को सक्षम करते हैं तो SQL सर्वर उपयोगकर्ता द्वारा बनाए गए इंडेक्स को छोड़ देगा। जब आप क्रिएट इंडेक्स विकल्प को सक्षम करते हैं, तो SQL सर्वर में स्वचालित रूप से इंडेक्स बनाने की क्षमता होती है और उन इंडेक्स को भी छोड़ सकता है (लेकिन उपयोगकर्ता द्वारा बनाए गए इंडेक्स को नहीं छोड़ेगा)। अंत में, डीटीयू द्वारा निर्धारित गैर-पीक वर्कलोड के दौरान इंडेक्स बनाए और गिराए जाते हैं। यदि कार्यभार 80% DTU से ऊपर है, तो SQL सर्वर सिस्टम लोड कम होने तक इंडेक्स बनाने या छोड़ने की प्रतीक्षा करेगा।
क्या मैं वाकई SQL सर्वर को नियंत्रण करने दूंगा?
शायद। इस सुविधा पर मेरी अनुशंसा, प्रारंभ में, "विश्वास लेकिन सत्यापित करें" दृष्टिकोण की आवश्यकता है।
स्वचालित योजना सुधार के साथ, स्वचालित सूचकांक प्रबंधन को लगभग दो मिलियन Azure SQL डेटाबेस से कैप्चर की गई पर्याप्त मात्रा में डेटा के साथ विकसित किया गया है। इंडेक्स एडवाइजर के हिस्से के रूप में, ऑटोमैटिक इंडेक्स मैनेजमेंट फीचर 2016 की पहली तिमाही से Azure SQL डेटाबेस में उपलब्ध है।
सुविधा द्वारा उपयोग किए जाने वाले एल्गोरिदम विकसित हुए हैं और समय के साथ विकसित होते रहते हैं, क्योंकि अधिक डेटाबेस इसका उपयोग करते हैं और अधिक डेटा कैप्चर और विश्लेषण किया जाता है। हालाँकि, वर्तमान में कुछ सीमाएँ हैं।
- सूचकांक अनुशंसाओं का मूल्यांकन मौजूदा अनुक्रमणिकाओं के विरुद्ध नहीं किया जाता है, इस प्रकार नए और मौजूदा अनुक्रमितों के बीच अनुक्रमणिका समेकन वर्तमान में उपलब्ध नहीं है।
- यदि कोई अनुक्रमणिका किसी SELECT के लिए लाभ प्रदान करेगी, तो INSERTs, UPDATEs, और DELETEs के कारण होने वाले संशोधनों का ऊपरी भाग निर्माण से पहले ज्ञात नहीं होता है। अनुक्रमणिका लागू होने के बाद, सत्यापन प्रक्रिया के दौरान SQL सर्वर इस ओवरहेड की निगरानी करता है।
स्वचालित अनुक्रमणिका प्रबंधन के ऐसे लाभ हैं जो बताने योग्य हैं:
- किसी ऐसे व्यक्ति के लिए जिसे SQL सर्वर डेटाबेस का प्रबंधन करना है, लेकिन DBA नहीं है, अनुक्रमणिका अनुशंसाएँ अत्यंत सहायक हो सकती हैं।
- सूचकांक अनुशंसाएँ sys.dm_db_tuning_recommendations DMV में कैप्चर की जाती हैं, भले ही CREATE और DROP अनुक्रमणिका विकल्प सक्षम न हों। इसलिए, यदि आप SQL सर्वर द्वारा किए जा सकने वाले परिवर्तनों के बारे में अनिश्चित हैं, तो आप समीक्षा कर सकते हैं कि DMV में क्या कैप्चर किया गया है और फिर अनुशंसा को मैन्युअल रूप से लागू करने का निर्णय लें।
नोट:यदि आप अनुशंसा को मैन्युअल रूप से लागू करते हैं, तो SQL सर्वर कोई सत्यापन नहीं करता है। यदि आप पोर्टल (लागू करें बटन का उपयोग करके) या आरईएसटी एपीआई के माध्यम से सिफारिश को लागू करते हैं, तो इसे निष्पादित किया जाएगा जैसे कि यह एक स्वचालित कार्रवाई थी, और सत्यापन किया जाएगा (और यदि कोई प्रतिगमन है तो सूचकांक स्वचालित रूप से वापस किया जा सकता है)।
- सुविधा में सुधार जारी है। जैसा कि मैंने पहले कहा है, माइक्रोसॉफ्ट डीबीए या डेवलपर्स को नौकरी से बाहर करने की कोशिश नहीं कर रहा है, यह कम लटके हुए फल को संबोधित करने की कोशिश कर रहा है ताकि आपके पास उन कार्यों और परियोजनाओं के लिए अधिक समय हो, जिन्हें बुद्धिमानी से स्वचालित नहीं किया जा सकता है।
सारांश
यदि आप अनुक्रमणिका प्रबंधन की बागडोर सौंपने के लिए तैयार नहीं हैं, तो मैं समझ गया। लेकिन यदि आपके पास कम से कम एक Azure SQL डेटाबेस है, तो आपको नियमित रूप से sys.dm_db_tuning_recommendations DMV की जाँच करनी चाहिए ताकि यह देखा जा सके कि SQL सर्वर क्या अनुशंसा कर रहा है, और इसकी तुलना उस डेटा से करें जो आप या आपका तृतीय-पक्ष निगरानी उपकरण अनुक्रमणिका उपयोग के बारे में कैप्चर कर रहे हैं। आखिरकार, आपने पिछली बार कब अपने इंडेक्स की पूरी और गहन समीक्षा की थी ताकि यह समझ सकें कि क्या गुम है, वास्तव में क्या उपयोग किया जा रहा है, और डेटाबेस में केवल ओवरहेड क्या उत्पन्न कर रहा है?