क्वेरी ट्यूनिंग का एक महत्वपूर्ण हिस्सा विभिन्न क्वेरी निर्माणों को संभालने के लिए ऑप्टिमाइज़र के लिए उपलब्ध एल्गोरिदम को समझ रहा है, जैसे, फ़िल्टरिंग, जॉइनिंग, ग्रुपिंग और एग्रीगेटिंग, और वे कैसे स्केल करते हैं। यह ज्ञान आपको अपने प्रश्नों के लिए एक इष्टतम भौतिक वातावरण तैयार करने में मदद करता है, जैसे कि सही अनुक्रमणिका बनाना। यह आपको सहज रूप से यह समझने में भी मदद करता है कि आपको किस एल्गोरिथम को एक निश्चित परिस्थितियों में योजना में देखने की उम्मीद करनी चाहिए, थ्रेसहोल्ड के साथ आपकी परिचितता के आधार पर जहां ऑप्टिमाइज़र को एक एल्गोरिदम से दूसरे में स्विच करना चाहिए। फिर, खराब प्रदर्शन करने वाली क्वेरी को ट्यून करते समय, आप क्वेरी प्लान में अधिक आसानी से उन क्षेत्रों का पता लगा सकते हैं जहां अनुकूलक ने गलत कार्डिनैलिटी अनुमानों के कारण उप-इष्टतम विकल्प बनाए होंगे, और उन्हें ठीक करने के लिए कार्रवाई कर सकते हैं।
क्वेरी ट्यूनिंग का एक अन्य महत्वपूर्ण हिस्सा लीक से हटकर सोच रहा है - स्पष्ट टूल का उपयोग करते समय ऑप्टिमाइज़र के लिए उपलब्ध एल्गोरिदम से परे। रचनात्मक बनो। मान लें कि आपके पास एक क्वेरी है जो खराब प्रदर्शन करती है, भले ही आपने इष्टतम भौतिक वातावरण की व्यवस्था की हो। आपके द्वारा उपयोग किए गए क्वेरी निर्माण के लिए, ऑप्टिमाइज़र के लिए उपलब्ध एल्गोरिदम x, y, और z हैं, और अनुकूलक ने परिस्थितियों में सबसे अच्छा चुना है। फिर भी, क्वेरी खराब प्रदर्शन करती है। क्या आप एक एल्गोरिदम के साथ एक सैद्धांतिक योजना की कल्पना कर सकते हैं जो एक बेहतर प्रदर्शन करने वाली क्वेरी उत्पन्न कर सकती है? यदि आप इसकी कल्पना कर सकते हैं, तो संभावना है कि आप इसे कुछ क्वेरी पुनर्लेखन के साथ प्राप्त करने में सक्षम होंगे, शायद कार्य के लिए कम स्पष्ट क्वेरी संरचनाओं के साथ।
लेखों की इस श्रृंखला में, मैं डेटा को समूहीकृत करने और एकत्र करने पर ध्यान केंद्रित करता हूं। मैं समूहबद्ध प्रश्नों का उपयोग करते समय ऑप्टिमाइज़र के लिए उपलब्ध एल्गोरिदम पर जाकर शुरू करूँगा। फिर मैं उन परिदृश्यों का वर्णन करूँगा जहाँ कोई भी मौजूदा एल्गोरिदम अच्छा नहीं करता है और क्वेरी पुनर्लेखन दिखाता है जिसके परिणामस्वरूप उत्कृष्ट प्रदर्शन और स्केलिंग होती है।
क्वेरी ऑप्टिमाइज़ेशन के बारे में मेरे सवालों के जवाब देने के लिए मैं क्रेग फ़्रीडमैन, वासिलिस पापाडिमोस, और जो सैक, ग्रह पर सबसे चतुर लोगों के समूह और SQL सर्वर डेवलपर्स के सेट के प्रतिच्छेदन के सदस्यों को धन्यवाद देना चाहता हूँ!
नमूना डेटा के लिए मैं PerformanceV3 नामक डेटाबेस का उपयोग करूंगा। आप यहां से डेटाबेस बनाने और पॉप्युलेट करने के लिए एक स्क्रिप्ट डाउनलोड कर सकते हैं। मैं dbo.Orders नामक एक तालिका का उपयोग करूँगा, जो 1,000,000 पंक्तियों से भरी हुई है। इस तालिका में कुछ इंडेक्स हैं जिनकी आवश्यकता नहीं है और मेरे उदाहरणों में हस्तक्षेप कर सकते हैं, इसलिए उन अनावश्यक इंडेक्स को छोड़ने के लिए निम्न कोड चलाएं:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
इस टेबल पर केवल दो इंडेक्स बचे हैं, ऑर्डरडेट कॉलम पर idx_cl_od नामक क्लस्टर इंडेक्स और ऑर्डरिड कॉलम पर PK_Orders नामक एक गैर-क्लस्टर अद्वितीय इंडेक्स है, जो प्राथमिक कुंजी बाधा को लागू करता है।
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
मौजूदा एल्गोरिदम
SQL सर्वर डेटा एकत्र करने के लिए दो मुख्य एल्गोरिदम का समर्थन करता है:स्ट्रीम एग्रीगेट और हैश एग्रीगेट। समूहीकृत प्रश्नों के साथ, स्ट्रीम एग्रीगेट एल्गोरिथम को डेटा को समूहीकृत स्तंभों द्वारा क्रमबद्ध करने की आवश्यकता होती है, इसलिए आपको दो मामलों के बीच अंतर करने की आवश्यकता होती है। एक पहले से ऑर्डर किया गया स्ट्रीम एग्रीगेट है, उदाहरण के लिए, जब डेटा किसी इंडेक्स से पहले से ऑर्डर किया जाता है। दूसरा एक गैर-आदेशित स्ट्रीम एग्रीगेट है, जहां इनपुट को स्पष्ट रूप से सॉर्ट करने के लिए एक अतिरिक्त चरण की आवश्यकता होती है। ये दो मामले बहुत अलग-अलग पैमाने पर हैं, इसलिए आप उन्हें दो अलग-अलग एल्गोरिदम के रूप में भी मान सकते हैं।
हैश एग्रीगेट एल्गोरिथ्म समूहों और उनके समुच्चय को हैश तालिका में व्यवस्थित करता है। इसे ऑर्डर करने के लिए इनपुट की आवश्यकता नहीं है।
पर्याप्त डेटा के साथ, ऑप्टिमाइज़र कार्य को समानांतर बनाने पर विचार करता है, जिसे स्थानीय-वैश्विक समुच्चय के रूप में जाना जाता है। ऐसे मामले में, इनपुट को कई थ्रेड्स में विभाजित किया जाता है, और प्रत्येक थ्रेड उपरोक्त एल्गोरिदम में से एक को स्थानीय रूप से पंक्तियों के सबसेट को एकत्रित करने के लिए लागू करता है। एक वैश्विक समुच्चय तब स्थानीय समुच्चय के परिणामों को एकत्रित करने के लिए उपरोक्त एल्गोरिदम में से एक का उपयोग करता है।
इस लेख में मैं पहले से ऑर्डर किए गए स्ट्रीम एग्रीगेट एल्गोरिथम और इसके स्केलिंग पर ध्यान केंद्रित करता हूं। इस श्रृंखला के भविष्य के हिस्सों में मैं अन्य एल्गोरिदम को कवर करूंगा और उन थ्रेसहोल्ड का वर्णन करूंगा जहां ऑप्टिमाइज़र एक से दूसरे में स्विच करता है, और जब आपको क्वेरी पुनर्लेखन पर विचार करना चाहिए।
पहले से ऑर्डर किया गया स्ट्रीम एग्रीगेट
एक गैर-रिक्त समूहीकरण सेट (अभिव्यक्तियों का समूह जिसे आप समूहबद्ध करते हैं) के साथ एक समूहीकृत क्वेरी को देखते हुए, स्ट्रीम एग्रीगेट एल्गोरिदम को समूहीकरण सेट बनाने वाले अभिव्यक्तियों द्वारा इनपुट पंक्तियों को क्रमबद्ध करने की आवश्यकता होती है। जब एल्गोरिथम समूह में पहली पंक्ति को संसाधित करता है, तो यह प्रासंगिक मान के साथ मध्यवर्ती कुल मान रखने वाले सदस्य को प्रारंभ करता है (उदाहरण के लिए, MAX कुल के लिए पहली पंक्ति का मान)। जब यह समूह में एक गैर-पहली पंक्ति को संसाधित करता है, तो यह उस सदस्य को एक गणना के परिणाम के साथ निर्दिष्ट करता है जिसमें मध्यवर्ती कुल मूल्य और नई पंक्ति का मान शामिल होता है (उदाहरण के लिए, मध्यवर्ती कुल मूल्य और नए मान के बीच अधिकतम)। जैसे ही ग्रुपिंग सेट का कोई भी सदस्य अपना मूल्य बदलता है, या इनपुट की खपत होती है, वर्तमान कुल मूल्य को अंतिम समूह के लिए अंतिम परिणाम माना जाता है।
स्ट्रीम एग्रीगेट एल्गोरिथम की तरह डेटा को ऑर्डर करने का एक तरीका यह है कि इसे किसी इंडेक्स से प्रीऑर्डर किया जाए। आपको इंडेक्स को ग्रुपिंग सेट के कॉलम के साथ चाबियों के रूप में परिभाषित करने की आवश्यकता है - उनमें से किसी भी क्रम में। आप यह भी चाहते हैं कि सूचकांक कवर हो। उदाहरण के लिए, निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 1 कहेंगे):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
इस क्वेरी का समर्थन करने के लिए एक इष्टतम रोस्टोर इंडेक्स को शिपरिड के साथ प्रमुख कुंजी कॉलम के रूप में परिभाषित किया जाएगा, और ऑर्डरडेट को शामिल कॉलम के रूप में, या दूसरे कुंजी कॉलम के रूप में परिभाषित किया जाएगा:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
इस इंडेक्स के साथ, आपको चित्र 1 (SentryOne Plan Explorer का उपयोग करके) में दिखाया गया अनुमानित प्लान मिलता है।

चित्र 1:प्रश्न 1 के लिए योजना
ध्यान दें कि इंडेक्स स्कैन ऑपरेटर के पास ऑर्डर किया गया है:सही संपत्ति यह दर्शाती है कि इंडेक्स कुंजी द्वारा ऑर्डर की गई पंक्तियों को वितरित करना आवश्यक है। स्ट्रीम एग्रीगेट ऑपरेटर तब ऑर्डर की गई पंक्तियों को अपनी आवश्यकता के अनुसार सम्मिलित करता है। ऑपरेटर की लागत की गणना कैसे की जाती है; इससे पहले कि हम उस पर पहुँचें, पहले एक त्वरित प्रस्तावना…
जैसा कि आप पहले से ही जानते हैं, जब SQL सर्वर एक क्वेरी को अनुकूलित करता है, तो यह कई उम्मीदवार योजनाओं का मूल्यांकन करता है, और अंततः सबसे कम अनुमानित लागत वाली योजना को चुनता है। अनुमानित योजना लागत सभी ऑपरेटरों की अनुमानित लागतों का योग है। बदले में, प्रत्येक ऑपरेटर की अनुमानित लागत अनुमानित I/O लागत और अनुमानित CPU लागत का योग है। लागत इकाई अपने आप में अर्थहीन है। इसकी प्रासंगिकता उस तुलना में है जो ऑप्टिमाइज़र उम्मीदवार योजनाओं के बीच बनाता है। यही है, लागत फ़ार्मुलों को इस लक्ष्य के साथ डिज़ाइन किया गया था कि, उम्मीदवार योजनाओं के बीच, सबसे कम लागत वाला (उम्मीद है) उस का प्रतिनिधित्व करेगा जो अधिक तेज़ी से समाप्त होगा। सटीक रूप से करने के लिए एक बहुत ही जटिल कार्य!
जितना अधिक लागत सूत्र पर्याप्त रूप से उन कारकों को ध्यान में रखते हैं जो वास्तव में एल्गोरिथम के प्रदर्शन और स्केलिंग को प्रभावित करते हैं, वे उतने ही सटीक होते हैं, और अधिक संभावना है कि सटीक कार्डिनैलिटी अनुमान दिए गए हैं, ऑप्टिमाइज़र इष्टतम योजना का चयन करेगा। किसी भी दर पर, यदि आप यह समझना चाहते हैं कि क्यों ऑप्टिमाइज़र एक एल्गोरिथम बनाम दूसरे को चुनता है, तो आपको दो मुख्य बातों को समझने की आवश्यकता है:एक यह है कि एल्गोरिदम कैसे काम करता है और स्केल करता है, और दूसरा SQL सर्वर का कॉस्टिंग मॉडल है।
तो चित्र 1 में योजना पर वापस जाएं; आइए कोशिश करें और समझें कि लागतों की गणना कैसे की जाती है। एक नीति के रूप में, Microsoft उनके द्वारा उपयोग किए जाने वाले आंतरिक लागत-निर्धारण फ़ार्मुलों को प्रकट नहीं करेगा। जब मैं बच्चा था तो मुझे चीजों को अलग करने का शौक था। घड़ियाँ, रेडियो, कैसेट टेप (हाँ, मैं वह बूढ़ा हूँ), आप इसे नाम दें। मैं जानना चाहता था कि चीजें कैसे बनती हैं। इसी तरह, मुझे रिवर्स इंजीनियरिंग में फॉर्मूले का मूल्य दिखाई देता है क्योंकि अगर मैं लागत का यथोचित सटीक अनुमान लगाने का प्रबंधन करता हूं, तो शायद इसका मतलब है कि मैं एल्गोरिथम को अच्छी तरह से समझता हूं। इस प्रक्रिया के दौरान आपको बहुत कुछ सीखने को मिलता है।
हमारी क्वेरी में 1,000,000 पंक्तियां शामिल हैं। इतनी पंक्तियों के साथ भी, CPU लागत की तुलना में I/O लागत नगण्य लगती है, इसलिए इसे अनदेखा करना शायद सुरक्षित है।
जहां तक सीपीयू की लागत का सवाल है, आप यह पता लगाने की कोशिश करना चाहते हैं कि कौन से कारक इसे प्रभावित करते हैं और किस तरह से। सैद्धांतिक रूप से कई कारक हो सकते हैं:इनपुट पंक्तियों की संख्या, समूहों की संख्या, समूहीकरण सेट की कार्डिनैलिटी, डेटा प्रकार और समूह के सदस्यों का आकार। इसलिए, इनमें से किसी भी कारक के प्रभाव को मापने और मापने के लिए, आप दो प्रश्नों की अनुमानित लागतों की तुलना करना चाहते हैं जो केवल उस कारक में भिन्न हैं जिसे आप मापना चाहते हैं। उदाहरण के लिए, लागत पर पंक्तियों की संख्या के प्रभाव को मापने के लिए, अलग-अलग इनपुट पंक्तियों के साथ दो प्रश्न पूछें, लेकिन अन्य सभी पहलुओं के साथ समान (समूहों की संख्या, समूहीकरण सेट की कार्डिनैलिटी आदि)। साथ ही, यह सत्यापित करना महत्वपूर्ण है कि अनुमानित संख्याएं—वास्तविक नहीं—वांछित हैं क्योंकि अनुकूलक लागतों की गणना के लिए अनुमानित संख्याओं पर निर्भर करता है।
ऐसी तुलना करते समय, ऐसी तकनीकों का होना अच्छा है जो आपको अनुमानित संख्याओं को पूरी तरह से नियंत्रित करने की अनुमति देती हैं। उदाहरण के लिए, इनपुट पंक्तियों की अनुमानित संख्या को नियंत्रित करने का एक आसान तरीका एक तालिका अभिव्यक्ति को क्वेरी करना है जो एक शीर्ष क्वेरी पर आधारित है और बाहरी क्वेरी में कुल फ़ंक्शन लागू करता है। यदि आप चिंतित हैं कि आपके द्वारा TOP ऑपरेटर के उपयोग के कारण ऑप्टिमाइज़र पंक्ति लक्ष्यों को लागू करेगा, और इसके परिणामस्वरूप मूल लागतों का समायोजन होगा, तो यह केवल उन ऑपरेटरों पर लागू होता है जो शीर्ष ऑपरेटर के नीचे योजना में दिखाई देते हैं। दाएँ), ऊपर नहीं (बाईं ओर)। स्ट्रीम एग्रीगेट ऑपरेटर स्वाभाविक रूप से योजना में शीर्ष ऑपरेटर के ऊपर दिखाई देता है क्योंकि यह फ़िल्टर की गई पंक्तियों को सम्मिलित करता है।
आउटपुट समूहों की अनुमानित संख्या को नियंत्रित करने के लिए, आप समूह अभिव्यक्ति
यह सुनिश्चित करने के लिए कि आपको स्ट्रीम एग्रीगेट एल्गोरिथम और एक सीरियल प्लान मिलता है, आप इसे क्वेरी संकेतों के साथ बाध्य कर सकते हैं:OPTION(ORDER GROUP, MAXDOP 1)।
आप यह भी पता लगाना चाहते हैं कि क्या ऑपरेटर के लिए कोई स्टार्टअप लागत है ताकि आप इसे अपने रिवर्स इंजीनियर फॉर्मूले में शामिल कर सकें।
आइए यह पता लगाना शुरू करें कि इनपुट पंक्तियों की संख्या ऑपरेटर की अनुमानित CPU लागत को कैसे प्रभावित करती है। स्पष्ट रूप से, यह कारक ऑपरेटर की लागत के लिए प्रासंगिक होना चाहिए। साथ ही, आप प्रति पंक्ति लागत स्थिर रहने की अपेक्षा करेंगे। तुलना के लिए यहां कुछ प्रश्न दिए गए हैं जो केवल इनपुट पंक्तियों की अनुमानित संख्या में भिन्न हैं (उन्हें क्रमशः क्वेरी 2 और क्वेरी 3 कहते हैं):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
चित्र 2 में इन प्रश्नों के लिए अनुमानित योजनाओं के प्रासंगिक भाग हैं:

चित्र 2:प्रश्न 2 और प्रश्न 3 के लिए योजनाएं
यह मानते हुए कि प्रति पंक्ति लागत स्थिर है, आप इसकी गणना ऑपरेटर की लागत के बीच अंतर को ऑपरेटर इनपुट कार्डिनैलिटी के बीच के अंतर से विभाजित करके कर सकते हैं:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
यह सत्यापित करने के लिए कि आपको जो संख्या मिली है वह वास्तव में स्थिर और सही है, आप अन्य इनपुट पंक्तियों के साथ प्रश्नों में अनुमानित लागतों की कोशिश कर सकते हैं और अनुमान लगा सकते हैं। उदाहरण के लिए, अनुमानित लागत 500,000 इनपुट पंक्तियों के साथ है:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
आपकी भविष्यवाणी सही है या नहीं यह जांचने के लिए निम्न क्वेरी का उपयोग करें (इसे क्वेरी 4 कहें):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
इस क्वेरी के लिए योजना का प्रासंगिक भाग चित्र 3 में दिखाया गया है।
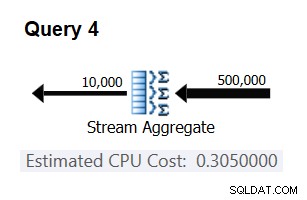
चित्र 3:क्वेरी 4 के लिए योजना
बिंगो। स्वाभाविक रूप से, कई अतिरिक्त इनपुट कार्डिनैलिटी की जांच करना एक अच्छा विचार है। उन सभी के साथ, जिनकी मैंने जाँच की, यह थीसिस कि प्रति इनपुट पंक्ति 0.0000006 की एक स्थिर लागत है, सही थी।
इसके बाद, आइए यह जानने की कोशिश करें कि समूहों की अनुमानित संख्या ऑपरेटर की सीपीयू लागत को कैसे प्रभावित करती है। आप उम्मीद करते हैं कि प्रत्येक समूह को संसाधित करने के लिए कुछ CPU कार्य की आवश्यकता होगी, और यह अपेक्षा करना भी उचित है कि यह प्रति समूह स्थिर हो। इस थीसिस का परीक्षण करने और प्रति समूह लागत की गणना करने के लिए, आप निम्नलिखित दो प्रश्नों का उपयोग कर सकते हैं, जो केवल परिणाम समूहों की संख्या में भिन्न होते हैं (उन्हें क्रमशः प्रश्न 5 और प्रश्न 6 कहते हैं):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
अनुमानित क्वेरी योजनाओं के प्रासंगिक भाग चित्र 4 में दिखाए गए हैं।
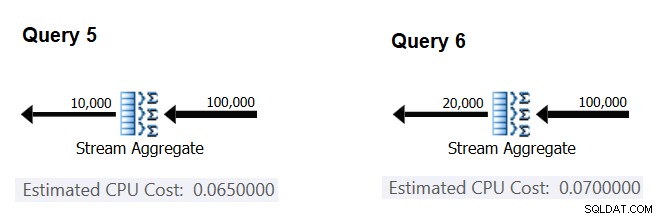
चित्र 4:प्रश्न 5 और प्रश्न 6 के लिए योजनाएं
जिस तरह से आपने प्रति इनपुट पंक्ति में निश्चित लागत की गणना की है, आप प्रति आउटपुट समूह की निश्चित लागत की गणना कर सकते हैं क्योंकि ऑपरेटर की लागत के बीच अंतर को ऑपरेटर आउटपुट कार्डिनैलिटी के बीच के अंतर से विभाजित किया जाता है:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
और जैसा कि मैंने पहले दिखाया था, आप अन्य आउटपुट समूहों के साथ लागतों का अनुमान लगाकर और अनुकूलक द्वारा उत्पादित अपनी अनुमानित संख्याओं की तुलना करके अपने निष्कर्षों को सत्यापित कर सकते हैं। जितने भी समूह मैंने आजमाए, उन सभी के साथ, अनुमानित लागतें सटीक थीं।
समान तकनीकों का उपयोग करके, आप जांच सकते हैं कि अन्य कारक ऑपरेटर की लागत को प्रभावित करते हैं या नहीं। मेरे परीक्षण से पता चलता है कि ग्रुपिंग सेट की कार्डिनैलिटी (आपके द्वारा समूहित अभिव्यक्तियों की संख्या), डेटा प्रकार और समूहीकृत अभिव्यक्तियों के आकार का अनुमानित लागत पर कोई प्रभाव नहीं पड़ता है।
क्या बचा है यह जांचने के लिए कि क्या ऑपरेटर के लिए कोई सार्थक स्टार्टअप लागत मान ली गई है। यदि एक है, तो ऑपरेटर की सीपीयू लागत की गणना करने का पूरा (उम्मीदवार) फॉर्मूला होना चाहिए:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
तो आप बाकी से स्टार्टअप लागत प्राप्त कर सकते हैं:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
आप इस उद्देश्य के लिए इस लेख से किसी भी प्रश्न योजना का उपयोग कर सकते हैं। उदाहरण के लिए, चित्र 4 में पहले दिखाए गए प्रश्न 5 के लिए योजना से संख्याओं का उपयोग करके, आप प्राप्त करते हैं:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
जैसा कि प्रतीत होता है, स्ट्रीम एग्रीगेट ऑपरेटर के पास कोई सीपीयू-संबंधित स्टार्टअप लागत नहीं है, या यह इतना कम है कि यह लागत माप की सटीकता के साथ नहीं दिखाया जाता है।
अंत में, स्ट्रीम एग्रीगेट ऑपरेटर लागत के लिए रिवर्स-इंजीनियर्ड फॉर्मूला है:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
चित्र 5 पंक्तियों की संख्या और समूहों की संख्या दोनों के संबंध में स्ट्रीम एग्रीगेट ऑपरेटर की लागत के स्केलिंग को दर्शाता है।
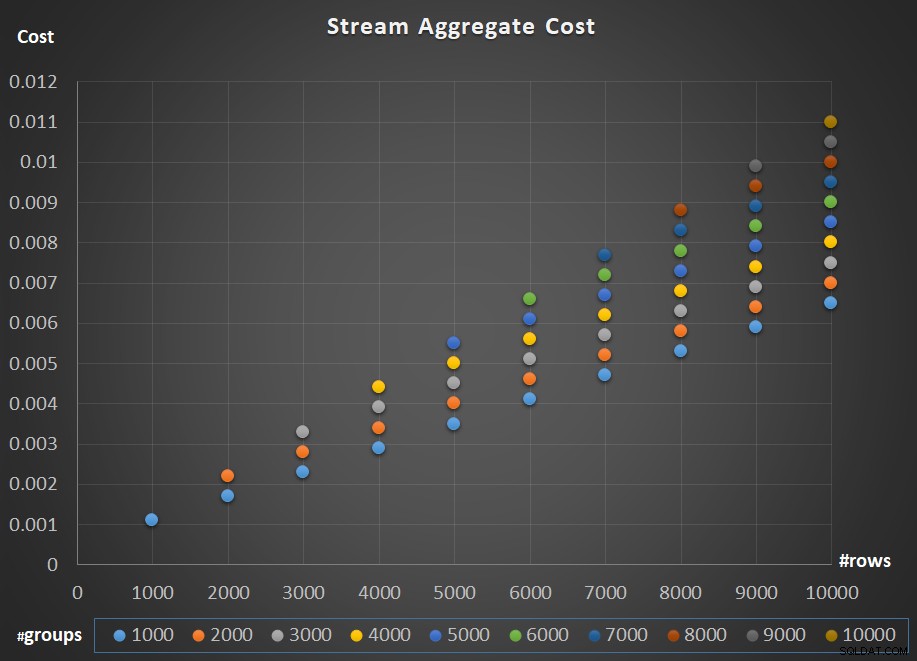
चित्र 5:स्ट्रीम एग्रीगेट एल्गोरिथम स्केलिंग चार्ट
ऑपरेटर के स्केलिंग के लिए; यह रैखिक है। ऐसे मामलों में जहां समूहों की संख्या पंक्तियों की संख्या के समानुपाती होती है, पूरे ऑपरेटर की लागत उसी कारक से बढ़ जाती है जिससे पंक्तियों और समूहों की संख्या दोनों में वृद्धि होती है। इसका मतलब है कि इनपुट पंक्तियों और इनपुट समूहों दोनों की संख्या को दोगुना करने से पूरे ऑपरेटर की लागत दोगुनी हो जाती है। यह देखने के लिए, मान लें कि हम ऑपरेटर की लागत को इस प्रकार दर्शाते हैं:
r * 0.0000006 + g * 0.0000005
यदि आप पंक्तियों की संख्या और समूहों की संख्या दोनों को समान कारक p से बढ़ाते हैं, तो आपको प्राप्त होता है:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
इसलिए, यदि दी गई पंक्तियों और समूहों की संख्या के लिए, स्ट्रीम एग्रीगेट ऑपरेटर की लागत C है, तो एक ही कारक p द्वारा पंक्तियों और समूहों की संख्या दोनों में वृद्धि करने से pC की ऑपरेटर लागत होती है। देखें कि क्या आप चित्र 5 में चार्ट में उदाहरणों की पहचान करके इसे सत्यापित कर सकते हैं।
ऐसे मामलों में जहां इनपुट पंक्तियों की संख्या बढ़ने पर भी समूहों की संख्या काफी स्थिर रहती है, फिर भी आपको रैखिक स्केलिंग मिलती है। आप केवल समूहों की संख्या से जुड़ी लागत को स्थिर मानते हैं। यही है, यदि दी गई पंक्तियों और समूहों के लिए ऑपरेटर की लागत C =G (समूहों की संख्या से जुड़ी लागत) प्लस R (पंक्तियों की संख्या से जुड़ी लागत) है, तो केवल एक कारक द्वारा पंक्तियों की संख्या में वृद्धि पी परिणाम जी + पीआर में। ऐसे में स्वाभाविक रूप से पूरे ऑपरेटर की लागत पीसी से कम होती है। यानी, पंक्तियों की संख्या को दोगुना करने से पूरे ऑपरेटर की लागत दोगुनी से भी कम हो जाती है।
व्यवहार में, कई मामलों में जब आप डेटा समूहित करते हैं, तो इनपुट पंक्तियों की संख्या आउटपुट समूहों की संख्या से काफी अधिक होती है। यह तथ्य, इस तथ्य के साथ संयुक्त है कि प्रति पंक्ति आवंटित लागत और प्रति समूह लागत लगभग समान है, ऑपरेटर की लागत का वह हिस्सा जो समूहों की संख्या के लिए जिम्मेदार है, नगण्य हो जाता है। उदाहरण के तौर पर, चित्र 1 में पहले दिखाए गए प्रश्न 1 के लिए योजना देखें। ऐसे मामलों में, ऑपरेटर की लागत को केवल इनपुट पंक्तियों की संख्या के संबंध में रैखिक रूप से स्केलिंग के रूप में सोचना सुरक्षित है।
विशेष मामले
ऐसे विशेष मामले हैं जहां स्ट्रीम एग्रीगेट ऑपरेटर को सॉर्ट किए गए डेटा की बिल्कुल भी आवश्यकता नहीं होती है। यदि आप इसके बारे में सोचते हैं, तो स्ट्रीम एग्रीगेट एल्गोरिथम में इनपुट से अधिक आराम से ऑर्डर करने की आवश्यकता होती है, जब आपको प्रस्तुति उद्देश्यों के लिए ऑर्डर किए गए डेटा की आवश्यकता होती है, उदाहरण के लिए, जब क्वेरी में बाहरी प्रस्तुति ORDER BY क्लॉज होती है। स्ट्रीम एग्रीगेट एल्गोरिदम को एक ही समूह से सभी पंक्तियों को एक साथ ऑर्डर करने की आवश्यकता होती है। इनपुट सेट {5, 1, 5, 2, 1, 2} लें। प्रेजेंटेशन ऑर्डरिंग उद्देश्यों के लिए, इस सेट को इस तरह से ऑर्डर करना होगा:1, 1, 2, 2, 5, 5। एकत्रीकरण उद्देश्यों के लिए, स्ट्रीम एग्रीगेट एल्गोरिथम अभी भी अच्छी तरह से काम करेगा यदि डेटा को निम्नलिखित क्रम में व्यवस्थित किया गया हो:5, 5, 1, 1, 2, 2. इसे ध्यान में रखते हुए, जब आप एक अदिश समुच्चय की गणना करते हैं (एक समग्र फ़ंक्शन वाली क्वेरी और कोई ग्रुप बाय क्लॉज नहीं), या डेटा को एक खाली समूह सेट द्वारा समूहित करते हैं, तो कभी भी एक से अधिक समूह नहीं होते हैं . इनपुट पंक्तियों के क्रम के बावजूद, स्ट्रीम एग्रीगेट एल्गोरिथम लागू किया जा सकता है। हैश एग्रीगेट एल्गोरिथम इनपुट के रूप में ग्रुपिंग सेट के एक्सप्रेशन के आधार पर डेटा को हैश करता है, और स्केलर एग्रीगेट के साथ और खाली ग्रुपिंग सेट के साथ, हैश बाय के लिए कोई इनपुट नहीं है। इसलिए, स्केलर एग्रीगेट्स के साथ और एक खाली ग्रुपिंग सेट पर लागू होने वाले एग्रीगेट्स के साथ, ऑप्टिमाइज़र हमेशा डेटा को प्रीऑर्डर किए बिना, स्ट्रीम एग्रीगेट एल्गोरिथम का उपयोग करता है। पंक्ति निष्पादन मोड में कम से कम यही स्थिति है, क्योंकि वर्तमान में (SQL सर्वर 2017 CU4 के अनुसार) बैच मोड केवल हैश एग्रीगेट एल्गोरिथम के साथ उपलब्ध है। मैं इसे प्रदर्शित करने के लिए निम्नलिखित दो प्रश्नों का उपयोग करूंगा (उन्हें प्रश्न 7 और प्रश्न 8 कहें):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
इन प्रश्नों की योजना चित्र 6 में दिखाई गई है।
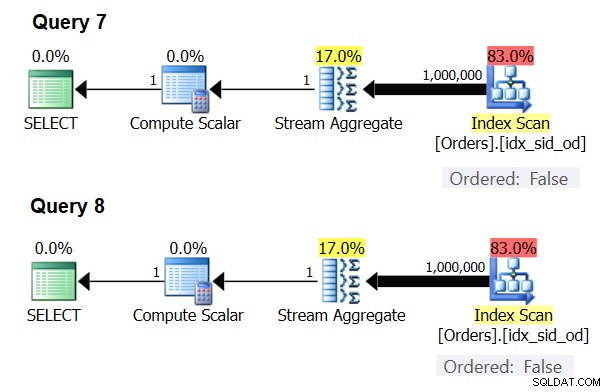
चित्र 6:प्रश्न 7 और प्रश्न 8 के लिए योजनाएं
दोनों ही मामलों में हैश एग्रीगेट एल्गोरिथम को बाध्य करने का प्रयास करें:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
अनुकूलक आपके अनुरोध को अनदेखा कर देता है और चित्र 6 में दर्शाए गए समान प्लान तैयार करता है।
त्वरित क्विज़:किसी खाली समूहीकरण सेट पर लागू किए गए स्केलर एग्रीगेट और एग्रीगेट में क्या अंतर है?
उत्तर:एक खाली इनपुट सेट के साथ, एक स्केलर एग्रीगेट एक पंक्ति के साथ एक परिणाम देता है, जबकि एक खाली ग्रुपिंग सेट वाली क्वेरी में एक एग्रीगेट एक खाली परिणाम सेट देता है। इसे आज़माएं:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
जब आप कर लें, तो सफाई के लिए निम्न कोड चलाएँ:
DROP INDEX idx_sid_od ON dbo.Orders;
सारांश और चुनौती
स्ट्रीम एग्रीगेट एल्गोरिथम के लिए कॉस्टिंग फॉर्मूला को रिवर्स-इंजीनियरिंग करना बच्चों का खेल है। मैं आपको बस इतना बता सकता था कि पहले से ऑर्डर किए गए स्ट्रीम एग्रीगेट एल्गोरिथम के लिए लागत सूत्र @numrows * 0.0000006 + @numgroups * 0.0000005 पूरे लेख के बजाय यह समझाने के लिए है कि आप इसे कैसे समझते हैं। बिंदु, हालांकि, अधिक जटिल एल्गोरिदम और थ्रेसहोल्ड पर जाने से पहले रिवर्स-इंजीनियरिंग की प्रक्रिया और सिद्धांतों का वर्णन करना था, जहां एक एल्गोरिदम दूसरों की तुलना में अधिक इष्टतम हो जाता है। आपको मछली की तरह की चीज़ देने के बजाय मछली पकड़ना सिखाना। मैंने बहुत कुछ सीखा है, और उन चीजों की खोज की है जिनके बारे में मैंने सोचा भी नहीं है, जबकि विभिन्न एल्गोरिदम के लिए लागत-सूत्रों को रिवर्स-इंजीनियर करने की कोशिश कर रहा हूं।
अपने कौशल का परीक्षण करने के लिए तैयार हैं? आपका मिशन, यदि आप इसे स्वीकार करना चुनते हैं, तो यह स्ट्रीम एग्रीगेट ऑपरेटर को रिवर्स-इंजीनियरिंग से कहीं अधिक कठिन है। रिवर्स-इंजीनियर एक सीरियल सॉर्ट ऑपरेटर का कॉस्टिंग फॉर्मूला। यह हमारे शोध के लिए महत्वपूर्ण है क्योंकि एक गैर-खाली ग्रुपिंग सेट वाली क्वेरी के लिए स्ट्रीम एग्रीगेट एल्गोरिदम लागू होता है, जहां इनपुट डेटा प्रीऑर्डर नहीं किया जाता है, इसके लिए स्पष्ट सॉर्टिंग की आवश्यकता होती है। ऐसे मामले में कुल संचालन की लागत और स्केलिंग, सॉर्ट और स्ट्रीम एग्रीगेट ऑपरेटरों की संयुक्त लागत और स्केलिंग पर निर्भर करती है।
यदि आप सॉर्ट ऑपरेटर की लागत की भविष्यवाणी के साथ शालीनता से करीब आने का प्रबंधन करते हैं, तो आप महसूस कर सकते हैं कि आपने अपने हस्ताक्षर "रिवर्स इंजीनियर" में जोड़ने का अधिकार अर्जित किया है। वहाँ कई सॉफ्टवेयर इंजीनियर हैं; लेकिन आप निश्चित रूप से कई रिवर्स इंजीनियर नहीं देखते हैं! बस अपने फॉर्मूले का परीक्षण छोटी संख्याओं और बड़ी संख्याओं के साथ करना सुनिश्चित करें; आप जो पाते हैं उससे आप आश्चर्यचकित हो सकते हैं।