JSON का मतलब जावास्क्रिप्ट ऑब्जेक्ट नोटेशन है। यह एक खुला मानक प्रारूप है जो डेटा को RFC 7159 में विस्तृत कुंजी / मान जोड़े और सरणियों में व्यवस्थित करता है। JSON वेब सेवाओं द्वारा डेटा का आदान-प्रदान करने, दस्तावेज़ों को संग्रहीत करने, असंरचित डेटा आदि के लिए उपयोग किया जाने वाला सबसे सामान्य प्रारूप है। इस पोस्ट में, हम जा रहे हैं PostgreSQL में JSON डेटा को प्रभावी ढंग से स्टोर और इंडेक्स करने के तरीके के बारे में सुझाव और तकनीक दिखाने के लिए।

आप इस विषय पर अधिक जानने के लिए PostgresConf के साथ साझेदारी में PostgreSQL बनाम MongoDB वेबिनार में JSON डेटा के साथ हमारे कार्य को भी देख सकते हैं, और हमारे स्लाइडशेयर पेज को देख सकते हैं। स्लाइड्स डाउनलोड करने के लिए।
JSON को PostgreSQL में क्यों स्टोर करें?
एक रिलेशनल डेटाबेस को असंरचित डेटा की भी परवाह क्यों करनी चाहिए? यह पता चला है कि कुछ परिदृश्य हैं जहां यह उपयोगी है।
-
स्कीमा लचीलापन
JSON प्रारूप का उपयोग करके डेटा संग्रहीत करने का एक मुख्य कारण स्कीमा लचीलापन है। JSON में अपना डेटा संग्रहीत करना तब उपयोगी होता है जब आपका स्कीमा तरल हो और बार-बार बदल रहा हो। यदि आप प्रत्येक कुंजी को कॉलम के रूप में संग्रहीत करते हैं, तो इसके परिणामस्वरूप बार-बार डीएमएल संचालन होगा - यह मुश्किल हो सकता है जब आपका डेटा सेट बड़ा हो - उदाहरण के लिए, ईवेंट ट्रैकिंग, एनालिटिक्स, टैग इत्यादि। नोट:यदि कोई विशेष कुंजी हमेशा मौजूद होती है आपके दस्तावेज़ में, इसे प्रथम श्रेणी के कॉलम के रूप में संग्रहीत करना समझ में आता है। हम नीचे "JSON पैटर्न और एंटीपैटर्न" खंड में इस दृष्टिकोण के बारे में अधिक चर्चा करते हैं।
-
नेस्टेड ऑब्जेक्ट
यदि आपके डेटा सेट में नेस्टेड ऑब्जेक्ट (एकल या बहु-स्तरीय) हैं, तो कुछ मामलों में, डेटा को कॉलम या एकाधिक तालिकाओं में विभाजित करने के बजाय JSON में उन्हें संभालना आसान होता है।
-
बाहरी डेटा स्रोतों के साथ समन्वयित करना
कई बार कोई बाहरी सिस्टम JSON के रूप में डेटा प्रदान कर रहा होता है, इसलिए सिस्टम के अन्य भागों में डेटा डालने से पहले यह एक अस्थायी स्टोर हो सकता है। उदाहरण के लिए, स्ट्राइप ट्रांजैक्शन।
PostgreSQL में JSON सपोर्ट की टाइमलाइन
PostgreSQL में JSON सपोर्ट 9.2 में पेश किया गया था और आगे हर रिलीज में इसमें लगातार सुधार हुआ है।
-
तरंग 1:PostgreSQL 9.2 (2012) ने JSON डेटा प्रकार के लिए समर्थन जोड़ा
9.2 में JSON डेटाबेस काफी सीमित था (और शायद उस बिंदु पर ओवरहाइप किया गया था) - मूल रूप से कुछ JSON सत्यापन के साथ एक महिमामंडित स्ट्रिंग। यह आने वाले JSON को मान्य करने और डेटाबेस में स्टोर करने के लिए उपयोगी है। अधिक विवरण नीचे दिए गए हैं।
-
वेव 2:PostgreSQL 9.4 (2014) ने JSONB डेटा प्रकार के लिए समर्थन जोड़ा
JSONB का अर्थ है "JSON बाइनरी" या "JSON बेहतर" जिसके आधार पर आप पूछते हैं। यह JSON को स्टोर करने के लिए एक विघटित बाइनरी प्रारूप है। JSONB JSON डेटा को अनुक्रमित करने का समर्थन करता है, और JSON डेटा को पार्स करने और क्वेरी करने में बहुत कुशल है। ज्यादातर मामलों में, जब आप PostgreSQL में JSON के साथ काम करते हैं, तो आपको JSONB का उपयोग करना चाहिए।
-
वेव 3:PostgreSQL 12 (2019) ने SQL/JSON मानक और JSONPATH क्वेरी के लिए समर्थन जोड़ा
JSONPath PostgreSQL में एक शक्तिशाली JSON क्वेरी इंजन लाता है।

आपको JSON बनाम JSONB का उपयोग कब करना चाहिए?
ज्यादातर मामलों में, JSONB वह है जिसका आपको उपयोग करना चाहिए। हालांकि, कुछ विशिष्ट मामले हैं जहां JSON बेहतर काम करता है:
- JSON मूल स्वरूपण (a.k.a व्हाइटस्पेस) और कुंजियों के क्रम को सुरक्षित रखता है।
- JSON डुप्लीकेट कुंजियों को सुरक्षित रखता है।
- JSON बनाम JSONB निगलना तेज़ है - हालांकि, यदि आप कोई और प्रक्रिया करते हैं, तो JSONB तेज़ हो जाएगा।
उदाहरण के लिए, यदि आप केवल JSON लॉग को अंतर्ग्रहण कर रहे हैं और उन्हें किसी भी तरह से क्वेरी नहीं कर रहे हैं, तो JSON आपके लिए एक बेहतर विकल्प हो सकता है। इस ब्लॉग के प्रयोजनों के लिए, जब हम PostgreSQL में JSON समर्थन का उल्लेख करते हैं, तो हम आगे जाकर JSONB का उल्लेख करेंगे।
PostgreSQL में JSONB का उपयोग करना:PostgreSQL में JSON डेटा को प्रभावी ढंग से कैसे स्टोर और इंडेक्स करें ट्वीट करने के लिए क्लिक करेंJSONB पैटर्न और एंटीपैटर्न
अगर PostgreSQL के पास JSONB के लिए बहुत अच्छा समर्थन है, तो हमें अब कॉलम की आवश्यकता क्यों है? क्यों न केवल JSONB ब्लॉब के साथ एक तालिका बनाएं और नीचे दिए गए स्कीमा जैसे सभी स्तंभों से छुटकारा पाएं:
CREATE TABLE test(id int, data JSONB, PRIMARY KEY (id));
दिन के अंत में, कॉलम अभी भी आपके डेटा के साथ काम करने की सबसे कुशल तकनीक हैं। JSONB स्टोरेज में पारंपरिक कॉलम बनाम कुछ कमियां हैं:
-
PostreSQL JSONB कॉलम के लिए कॉलम आँकड़े संग्रहीत नहीं करता है
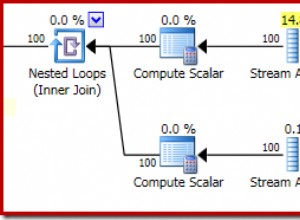
PostgreSQL तालिका के प्रत्येक स्तंभ में मानों के वितरण के बारे में आंकड़े रखता है - सबसे सामान्य मान (MCV), NULL प्रविष्टियाँ, वितरण का हिस्टोग्राम। इस डेटा के आधार पर, PostgreSQL क्वेरी प्लानर क्वेरी के लिए उपयोग करने की योजना पर स्मार्ट निर्णय लेता है। इस बिंदु पर, PostgreSQL JSONB कॉलम या कुंजियों के लिए कोई आँकड़े संग्रहीत नहीं करता है। यह कभी-कभी खराब विकल्पों में परिणत हो सकता है जैसे नेस्टेड लूप जॉइन बनाम हैश जॉइन आदि का उपयोग करना। इसका एक अधिक विस्तृत उदाहरण इस ब्लॉग पोस्ट में दिया गया है - जब एक पोस्टग्रेएसक्यूएल स्कीमा में JSONB से बचने के लिए।
-
JSONB स्टोरेज के परिणामस्वरूप एक बड़ा स्टोरेज फ़ुटप्रिंट होता है
JSONB संग्रहण JSON में प्रमुख नामों की प्रतिलिपि नहीं बनाता है। इसके परिणामस्वरूप WiredTiger या पारंपरिक कॉलम स्टोरेज पर MongoDB BSON की तुलना में काफी बड़ा स्टोरेज फुटप्रिंट हो सकता है। मैंने नीचे JSONB मॉडल के साथ डेटा की लगभग 10 मिलियन पंक्तियों को संग्रहीत करने के साथ एक सरल परीक्षण चलाया, और यहाँ परिणाम हैं - कुछ मायनों में यह MongoDB MMAPV1 स्टोरेज मॉडल के समान है जहाँ JSONB में कुंजियों को बिना किसी संपीड़न के संग्रहीत किया गया था। एक दीर्घकालिक सुधार कुंजी नामों को तालिका स्तर के शब्दकोश में स्थानांतरित करना और कुंजी नामों को बार-बार संग्रहीत करने के बजाय इस शब्दकोश को संदर्भित करना है। तब तक, अधिक वर्णनात्मक नामों के बजाय अधिक कॉम्पैक्ट नामों (यूनिक्स-शैली) का उपयोग करने के लिए समाधान हो सकता है। उदाहरण के लिए, यदि आप किसी विशेष कुंजी के लाखों इंस्टेंस संग्रहीत कर रहे हैं, तो बेहतर होगा कि इसे "publisherName" के बजाय "pb" नाम दिया जाए।
PostgreSQL में JSONB का लाभ उठाने का सबसे कारगर तरीका कॉलम और JSONB को मिलाना है। यदि आपके JSONB ब्लॉब्स में कोई कुंजी बहुत बार दिखाई देती है, तो संभवतः कॉलम के रूप में संग्रहीत किया जाना बेहतर है। अधिक स्थिर फ़ील्ड के लिए पारंपरिक स्तंभों का लाभ उठाते हुए अपने स्कीमा के परिवर्तनशील भागों को संभालने के लिए JSONB को "सभी को पकड़ें" के रूप में उपयोग करें।
JSONB डेटा संरचनाएं

JSONB और MongoDB BSON दोनों अनिवार्य रूप से पेड़ संरचनाएं हैं, पार्स किए गए JSONB डेटा को संग्रहीत करने के लिए बहु-स्तरीय नोड्स का उपयोग करते हैं। MongoDB BSON की संरचना बहुत समान है।
छवि स्रोत

JSONB और TOAST
स्टोरेज के लिए एक और महत्वपूर्ण विचार यह है कि JSONB TOAST (द ओवरसाइज एट्रीब्यूट स्टोरेज टेक्नीक) के साथ कैसे इंटरैक्ट करता है। आमतौर पर, जब आपके कॉलम का आकार TOAST_TUPLE_THRESHOLD (2kb डिफ़ॉल्ट) से अधिक हो जाता है, तो PostgreSQL डेटा को संपीड़ित करने और 2kb में फ़िट होने का प्रयास करेगा। यदि वह काम नहीं करता है, तो डेटा को आउट-ऑफ़-लाइन संग्रहण में ले जाया जाता है। इसे वे डेटा "TOASTing" कहते हैं। जब डेटा प्राप्त किया जाता है, तो रिवर्स प्रक्रिया "deTOASTting" होने की आवश्यकता होती है। आप TOAST संग्रहण कार्यनीति को भी नियंत्रित कर सकते हैं:
- विस्तारित - आउट-ऑफ़-लाइन संग्रहण और संपीड़न (pglz का उपयोग करके) की अनुमति देता है। यह डिफ़ॉल्ट विकल्प है।
- बाहरी - आउट-ऑफ़-लाइन संग्रहण की अनुमति देता है, लेकिन संपीड़न की नहीं।
यदि आपको TOAST संपीड़न या डीकंप्रेसन के कारण विलंब का सामना करना पड़ रहा है, तो एक विकल्प कॉलम संग्रहण को सक्रिय रूप से 'विस्तारित' पर सेट करना है। सभी विवरणों के लिए, कृपया यह पोस्टग्रेएसक्यूएल दस्तावेज़ देखें।
JSONB ऑपरेटर्स और फंक्शन्स
PostgreSQL JSONB पर काम करने के लिए कई तरह के ऑपरेटर प्रदान करता है। डॉक्स से:
| ऑपरेटर | <वें शैली="चौड़ाई:80%; पृष्ठभूमि-रंग:#def5fe; पैडिंग:10px;">विवरण|
|---|---|
| -> | JSON ऐरे एलीमेंट प्राप्त करें (शून्य से अनुक्रमित, अंत से नकारात्मक पूर्णांकों की गणना) |
| -> | कुंजी द्वारा JSON ऑब्जेक्ट फ़ील्ड प्राप्त करें |
| ->> | JSON ऐरे एलीमेंट को टेक्स्ट के रूप में प्राप्त करें |
| ->> | JSON ऑब्जेक्ट फ़ील्ड को टेक्स्ट के रूप में प्राप्त करें |
| #> | JSON ऑब्जेक्ट को निर्दिष्ट पथ पर प्राप्त करें |
| #>> | JSON ऑब्जेक्ट को टेक्स्ट के रूप में निर्दिष्ट पथ पर प्राप्त करें |
| @> | क्या बाएं JSON मान में शीर्ष स्तर पर सही JSON पथ/मान प्रविष्टियां हैं? |
| <@ | क्या लेफ्ट JSON पाथ/वैल्यू एंट्रीज टॉप लेवल पर राइट JSON वैल्यू के अंदर हैं? |
| ? | क्या स्ट्रिंग JSON मान के भीतर एक शीर्ष-स्तरीय कुंजी के रूप में मौजूद है? |
| ?| | इनमें से कोई भी ऐरे स्ट्रिंग्स करें शीर्ष-स्तरीय कुंजियों के रूप में मौजूद हैं? |
| ?& | इन सभी एरे को स्ट्रिंग्स करें शीर्ष-स्तरीय कुंजियों के रूप में मौजूद हैं? |
| || | दो jsonb मानों को एक नए jsonb मान में संयोजित करें |
| - | कुंजी/मान युग्म या स्ट्रिंग हटाएं बाएं ऑपरेंड से तत्व। कुंजी/मान युग्मों का मिलान उनके मुख्य मान के आधार पर किया जाता है। |
| - | एकाधिक कुंजी/मान जोड़े या स्ट्रिंग हटाएं बाएं ऑपरेंड से तत्व। कुंजी/मान युग्मों का मिलान उनके मुख्य मान के आधार पर किया जाता है। |
| - | ऐरे एलीमेंट को निर्दिष्ट इंडेक्स के साथ डिलीट करें (नकारात्मक पूर्णांकों की गिनती अंत से होती है)। यदि शीर्ष स्तर का कंटेनर एक सरणी नहीं है तो एक त्रुटि उत्पन्न करता है। |
| #- | निर्दिष्ट पथ के साथ फ़ील्ड या एलीमेंट हटाएं (JSON सरणियों के लिए, नकारात्मक पूर्णांकों की गणना अंत से होती है) |
| @? | क्या JSON पथ निर्दिष्ट JSON मान के लिए कोई आइटम लौटाता है? |
| @@ | निर्दिष्ट JSON मान के लिए JSON पाथ प्रेडिकेट चेक का परिणाम देता है। परिणाम के केवल पहले आइटम को ध्यान में रखा जाता है। यदि परिणाम बूलियन नहीं है, तो शून्य वापस आ जाता है। |
PostgreSQL JSONB डेटा के साथ काम करने के लिए कई तरह के क्रिएशन फंक्शन और प्रोसेसिंग फंक्शन भी प्रदान करता है।
JSONB अनुक्रमणिका
JSONB आपके JSON डेटा को अनुक्रमित करने के लिए विकल्पों की एक विस्तृत श्रृंखला प्रदान करता है। उच्च स्तर पर, हम 3 अलग-अलग प्रकार के इंडेक्स - GIN, BTREE और HASH में खुदाई करने जा रहे हैं। सभी इंडेक्स प्रकार सभी ऑपरेटर वर्गों का समर्थन नहीं करते हैं, इसलिए आपके द्वारा उपयोग किए जाने वाले ऑपरेटरों और प्रश्नों के प्रकार के आधार पर आपके इंडेक्स को डिजाइन करने के लिए योजना बनाने की आवश्यकता है।
GIN अनुक्रमणिका
GIN का अर्थ है "सामान्यीकृत इनवर्टेड इंडेक्स"। डॉक्स से:
“GIN को उन मामलों को संभालने के लिए डिज़ाइन किया गया है जहां अनुक्रमित किए जाने वाले आइटम समग्र मान हैं, और अनुक्रमणिका द्वारा नियंत्रित की जाने वाली क्वेरी को तत्व की खोज करने की आवश्यकता है मान जो मिश्रित वस्तुओं के भीतर दिखाई देते हैं। उदाहरण के लिए, आइटम दस्तावेज़ हो सकते हैं, और क्वेरी विशिष्ट शब्दों वाले दस्तावेज़ों की खोज हो सकती हैं।"

GIN दो ऑपरेटर वर्गों का समर्थन करता है:
- jsonb_ops (डिफ़ॉल्ट) -?,?|, ?&, @>, @@, @? [JSONB तत्व में प्रत्येक कुंजी और मान को अनुक्रमित करें]
- jsonb_pathops - @>, @@, @? [केवल JSONB तत्व में मानों को अनुक्रमित करें]
CREATE INDEX datagin ON books USING gin (data);
अस्तित्व संचालक (?, ?|, ?&)
इन ऑपरेटरों का उपयोग JSONB में शीर्ष-स्तरीय कुंजियों के अस्तित्व की जांच के लिए किया जा सकता है। आइए डेटा JSONB कॉलम पर एक GIN इंडेक्स बनाएं। उदाहरण के लिए, ब्रेल लिपि में उपलब्ध सभी पुस्तकें खोजें। JSON कुछ इस तरह दिखता है:
"{"tags": {"nk594127": {"ik71786": "iv678771"}}, "braille": false, "keywords": ["abc", "kef", "keh"], "hardcover": true, "publisher": "EfgdxUdvB0", "criticrating": 1}
demo=# select * from books where data ? 'braille';
id | author | isbn | rating | data
---------+-----------------+------------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
------------------
1000005 | XEI7xShT8bPu6H7 | 2kD5XJDZUF | 0 | {"tags": {"nk455671": {"ik937456": "iv506075"}}, "braille": true, "keywords": ["abc", "kef", "keh"], "hardcover": false, "publisher": "zSfZIAjGGs", "
criticrating": 4}
.....
demo=# explain analyze select * from books where data ? 'braille';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=12.75..1005.25 rows=1000 width=158) (actual time=0.033..0.039 rows=15 loops=1)
Recheck Cond: (data ? 'braille'::text)
Heap Blocks: exact=2
-> Bitmap Index Scan on datagin (cost=0.00..12.50 rows=1000 width=0) (actual time=0.022..0.022 rows=15 loops=1)
Index Cond: (data ? 'braille'::text)
Planning Time: 0.102 ms
Execution Time: 0.067 ms
(7 rows)
जैसा कि आप व्याख्या आउटपुट से देख सकते हैं, हमने जो GIN इंडेक्स बनाया है उसका उपयोग खोज के लिए किया जा रहा है। क्या होगा अगर हम ब्रेल या हार्डकवर में किताबें ढूंढना चाहते हैं?
demo=# explain analyze select * from books where data ?| array['braille','hardcover'];
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=16.75..1009.25 rows=1000 width=158) (actual time=0.029..0.035 rows=15 loops=1)
Recheck Cond: (data ?| '{braille,hardcover}'::text[])
Heap Blocks: exact=2
-> Bitmap Index Scan on datagin (cost=0.00..16.50 rows=1000 width=0) (actual time=0.023..0.023 rows=15 loops=1)
Index Cond: (data ?| '{braille,hardcover}'::text[])
Planning Time: 0.138 ms
Execution Time: 0.057 ms
(7 rows)
GIN इंडेक्स केवल "टॉप-लेवल" कीज़ पर "अस्तित्व" ऑपरेटरों का समर्थन करता है। यदि कुंजी शीर्ष स्तर पर नहीं है, तो सूचकांक का उपयोग नहीं किया जाएगा। इसके परिणामस्वरूप क्रमिक स्कैन होगा:
demo=# select * from books where data->'tags' ? 'nk455671';
id | author | isbn | rating | data
---------+-----------------+------------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
------------------
1000005 | XEI7xShT8bPu6H7 | 2kD5XJDZUF | 0 | {"tags": {"nk455671": {"ik937456": "iv506075"}}, "braille": true, "keywords": ["abc", "kef", "keh"], "hardcover": false, "publisher": "zSfZIAjGGs", "
criticrating": 4}
685122 | GWfuvKfQ1PCe1IL | jnyhYYcF66 | 3 | {"tags": {"nk455671": {"ik615925": "iv253423"}}, "publisher": "b2NwVg7VY3", "criticrating": 0}
(2 rows)
demo=# explain analyze select * from books where data->'tags' ? 'nk455671';
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Seq Scan on books (cost=0.00..38807.29 rows=1000 width=158) (actual time=0.018..270.641 rows=2 loops=1)
Filter: ((data -> 'tags'::text) ? 'nk455671'::text)
Rows Removed by Filter: 1000017
Planning Time: 0.078 ms
Execution Time: 270.728 ms
(5 rows)
नेस्टेड डॉक्स में अस्तित्व की जांच करने का तरीका "एक्सप्रेशन इंडेक्स" का उपयोग करना है। आइए data->tags पर एक इंडेक्स बनाएं:
CREATE INDEX datatagsgin ON books USING gin (data->'tags');
demo=# select * from books where data->'tags' ? 'nk455671';
id | author | isbn | rating | data
---------+-----------------+------------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
------------------
1000005 | XEI7xShT8bPu6H7 | 2kD5XJDZUF | 0 | {"tags": {"nk455671": {"ik937456": "iv506075"}}, "braille": true, "keywords": ["abc", "kef", "keh"], "hardcover": false, "publisher": "zSfZIAjGGs", "
criticrating": 4}
685122 | GWfuvKfQ1PCe1IL | jnyhYYcF66 | 3 | {"tags": {"nk455671": {"ik615925": "iv253423"}}, "publisher": "b2NwVg7VY3", "criticrating": 0}
(2 rows)
demo=# explain analyze select * from books where data->'tags' ? 'nk455671';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=12.75..1007.75 rows=1000 width=158) (actual time=0.031..0.035 rows=2 loops=1)
Recheck Cond: ((data ->'tags'::text) ? 'nk455671'::text)
Heap Blocks: exact=2
-> Bitmap Index Scan on datatagsgin (cost=0.00..12.50 rows=1000 width=0) (actual time=0.021..0.021 rows=2 loops=1)
Index Cond: ((data ->'tags'::text) ? 'nk455671'::text)
Planning Time: 0.098 ms
Execution Time: 0.061 ms
(7 rows)
ध्यान दें:यहां एक विकल्प @> ऑपरेटर का उपयोग करना है:
select * from books where data @> '{"tags":{"nk455671":{}}}'::jsonb;
हालाँकि, यह केवल तभी काम करता है जब मान कोई वस्तु हो। इसलिए, यदि आप सुनिश्चित नहीं हैं कि मान एक वस्तु है या एक आदिम मूल्य है, तो यह गलत परिणाम दे सकता है।
पाथ ऑपरेटर्स @>, <@
“path” ऑपरेटर का उपयोग आपके JSONB डेटा के बहु-स्तरीय प्रश्नों के लिए किया जा सकता है। आइए इसे के समान उपयोग करें? ऊपर ऑपरेटर:
select * from books where data @> '{"braille":true}'::jsonb;
demo=# explain analyze select * from books where data @> '{"braille":true}'::jsonb;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=16.75..1009.25 rows=1000 width=158) (actual time=0.040..0.048 rows=6 loops=1)
Recheck Cond: (data @> '{"braille": true}'::jsonb)
Rows Removed by Index Recheck: 9
Heap Blocks: exact=2
-> Bitmap Index Scan on datagin (cost=0.00..16.50 rows=1000 width=0) (actual time=0.030..0.030 rows=15 loops=1)
Index Cond: (data @> '{"braille": true}'::jsonb)
Planning Time: 0.100 ms
Execution Time: 0.076 ms
(8 rows)
पाथ ऑपरेटर नेस्टेड ऑब्जेक्ट्स या टॉप-लेवल ऑब्जेक्ट्स को क्वेरी करने का समर्थन करते हैं:
demo=# select * from books where data @> '{"publisher":"XlekfkLOtL"}'::jsonb;
id | author | isbn | rating | data
-----+-----------------+------------+--------+-------------------------------------------------------------------------------------
346 | uD3QOvHfJdxq2ez | KiAaIRu8QE | 1 | {"tags": {"nk88": {"ik37": "iv161"}}, "publisher": "XlekfkLOtL", "criticrating": 3}
(1 row)
demo=# explain analyze select * from books where data @> '{"publisher":"XlekfkLOtL"}'::jsonb;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=16.75..1009.25 rows=1000 width=158) (actual time=0.491..0.492 rows=1 loops=1)
Recheck Cond: (data @> '{"publisher": "XlekfkLOtL"}'::jsonb)
Heap Blocks: exact=1
-> Bitmap Index Scan on datagin (cost=0.00..16.50 rows=1000 width=0) (actual time=0.092..0.092 rows=1 loops=1)
Index Cond: (data @> '{"publisher": "XlekfkLOtL"}'::jsonb)
Planning Time: 0.090 ms
Execution Time: 0.523 ms
प्रश्न बहु-स्तरीय भी हो सकते हैं:
demo=# select * from books where data @> '{"tags":{"nk455671":{"ik937456":"iv506075"}}}'::jsonb;
id | author | isbn | rating | data
---------+-----------------+------------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
------------------
1000005 | XEI7xShT8bPu6H7 | 2kD5XJDZUF | 0 | {"tags": {"nk455671": {"ik937456": "iv506075"}}, "braille": true, "keywords": ["abc", "kef", "keh"], "hardcover": false, "publisher": "zSfZIAjGGs", "
criticrating": 4}
(1 row)
GIN Index "pathops" ऑपरेटर क्लास
GIN, GIN इंडेक्स के आकार को कम करने के लिए "पाथॉप्स" विकल्प का भी समर्थन करता है। जब आप पाथॉप्स विकल्प का उपयोग करते हैं, तो एकमात्र ऑपरेटर समर्थन "@>" होता है, इसलिए आपको अपने प्रश्नों से सावधान रहने की आवश्यकता है। डॉक्स से:
“jsonb_ops और jsonb_path_ops GIN इंडेक्स के बीच तकनीकी अंतर यह है कि पूर्व डेटा में प्रत्येक कुंजी और मान के लिए स्वतंत्र इंडेक्स आइटम बनाता है, जबकि बाद वाला केवल इंडेक्स आइटम बनाता है डेटा में प्रत्येक मान”
आप निम्न प्रकार से एक GIN पाथॉप्स इंडेक्स बना सकते हैं:
CREATE INDEX dataginpathops ON books USING gin (data jsonb_path_ops);
1 मिलियन पुस्तकों के मेरे छोटे डेटासेट पर, आप देख सकते हैं कि पाथॉप्स GIN इंडेक्स छोटा है - बचत को समझने के लिए आपको अपने डेटासेट के साथ परीक्षण करना चाहिए:
public | dataginpathops | index | sgpostgres | books | 67 MB | public | datatagsgin | index | sgpostgres | books | 84 MB |
आइए पाथॉप्स इंडेक्स के साथ अपनी क्वेरी को पहले से फिर से चलाएँ:
demo=# select * from books where data @> '{"tags":{"nk455671":{"ik937456":"iv506075"}}}'::jsonb;
id | author | isbn | rating | data
---------+-----------------+------------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
------------------
1000005 | XEI7xShT8bPu6H7 | 2kD5XJDZUF | 0 | {"tags": {"nk455671": {"ik937456": "iv506075"}}, "braille": true, "keywords": ["abc", "kef", "keh"], "hardcover": false, "publisher": "zSfZIAjGGs", "
criticrating": 4}
(1 row)
demo=# explain select * from books where data @> '{"tags":{"nk455671":{"ik937456":"iv506075"}}}'::jsonb;
QUERY PLAN
-----------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=12.75..1005.25 rows=1000 width=158)
Recheck Cond: (data @> '{"tags": {"nk455671": {"ik937456": "iv506075"}}}'::jsonb)
-> Bitmap Index Scan on dataginpathops (cost=0.00..12.50 rows=1000 width=0)
Index Cond: (data @> '{"tags": {"nk455671": {"ik937456": "iv506075"}}}'::jsonb)
(4 rows)
हालाँकि, जैसा कि ऊपर बताया गया है, "पाथॉप्स" विकल्प उन सभी परिदृश्यों का समर्थन नहीं करता है जो कि डिफ़ॉल्ट ऑपरेटर वर्ग समर्थन करता है। "पाथॉप्स" जीआईएन इंडेक्स के साथ, ये सभी प्रश्न जीआईएन इंडेक्स का लाभ उठाने में सक्षम नहीं हैं। संक्षेप में, आपके पास एक छोटा सूचकांक है लेकिन यह अधिक सीमित उपयोग के मामले का समर्थन करता है।
select * from books where data ? 'tags'; => Sequential scan
select * from books where data @> '{"tags" :{}}'; => Sequential scan
select * from books where data @> '{"tags" :{"k7888":{}}}' => Sequential scan
B-Tree indexes
बी-ट्री इंडेक्स रिलेशनल डेटाबेस में सबसे आम इंडेक्स प्रकार हैं। हालांकि, अगर आप एक बी-ट्री इंडेक्स के साथ एक संपूर्ण JSONB कॉलम को इंडेक्स करते हैं, तो केवल उपयोगी ऑपरेटर "=", <, <=,>,>=हैं। अनिवार्य रूप से, इसका उपयोग केवल संपूर्ण वस्तु तुलना के लिए किया जा सकता है, जिसका उपयोग बहुत सीमित है।
एक अधिक सामान्य परिदृश्य बी-ट्री "एक्सप्रेशन इंडेक्स" का उपयोग करना है। प्राइमर के लिए, यहां देखें - एक्सप्रेशन पर इंडेक्स। बी-ट्री एक्सप्रेशन इंडेक्स सामान्य तुलना ऑपरेटरों '=', '<', '>', '>=', '<=' का समर्थन कर सकते हैं। जैसा कि आपको याद होगा, GIN इंडेक्स इन ऑपरेटरों का समर्थन नहीं करते हैं। आइए उस मामले पर विचार करें जब हम डेटा के साथ सभी पुस्तकों को पुनः प्राप्त करना चाहते हैं-> आलोचनात्मक> 4. तो, आप कुछ इस तरह से एक प्रश्न बनाएंगे:
demo=# select * from books where data->'criticrating' > 4; ERROR: operator does not exist: jsonb >= integer LINE 1: select * from books where data->'criticrating' >= 4; ^ HINT: No operator matches the given name and argument types. You might need to add explicit type casts.
ठीक है, यह काम नहीं करता क्योंकि '->' ऑपरेटर एक JSONB प्रकार लौटाता है। इसलिए हमें कुछ इस तरह इस्तेमाल करने की ज़रूरत है:
demo=# select * from books where (data->'criticrating')::int4 > 4;
यदि आप PostgreSQL 11 से पहले के संस्करण का उपयोग कर रहे हैं, तो यह और भी बदसूरत हो जाता है। आपको पहले टेक्स्ट के रूप में क्वेरी करनी होगी और फिर इसे पूर्णांक में डालना होगा:
demo=# select * from books where (data->'criticrating')::int4 > 4;
एक्सप्रेशन इंडेक्स के लिए, इंडेक्स को क्वेरी एक्सप्रेशन के साथ सटीक मिलान होना चाहिए। तो, हमारी अनुक्रमणिका कुछ इस तरह दिखेगी:
demo=# CREATE INDEX criticrating ON books USING BTREE (((data->'criticrating')::int4)); CREATE INDEX demo=# explain analyze select * from books where (data->'criticrating')::int4 = 3; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------- Index Scan using criticrating on books (cost=0.42..4626.93 rows=5000 width=158) (actual time=0.069..70.221 rows=199883 loops=1) Index Cond: (((data -> 'criticrating'::text))::integer = 3) Planning Time: 0.103 ms Execution Time: 79.019 ms (4 rows) demo=# explain analyze select * from books where (data->'criticrating')::int4 = 3; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------- Index Scan using criticrating on books (cost=0.42..4626.93 rows=5000 width=158) (actual time=0.069..70.221 rows=199883 loops=1) Index Cond: (((data -> 'criticrating'::text))::integer = 3) Planning Time: 0.103 ms Execution Time: 79.019 ms (4 rows) 1 From above we can see that the BTREE index is being used as expected.
हैश इंडेक्स
यदि आप केवल "=" ऑपरेटर में रुचि रखते हैं, तो हैश इंडेक्स दिलचस्प हो जाते हैं। उदाहरण के लिए, उस मामले पर विचार करें जब हम किसी पुस्तक पर किसी विशेष टैग की तलाश कर रहे हों। अनुक्रमित किया जाने वाला तत्व शीर्ष स्तर का तत्व या गहराई से नेस्टेड हो सकता है।
उदा. टैग->प्रकाशक =XlekfkLOtL
CREATE INDEX publisherhash ON books USING HASH ((data->'publisher'));
हैश इंडेक्स भी आकार में बी-ट्री या जीआईएन इंडेक्स से छोटे होते हैं। बेशक, यह अंततः आपके डेटा सेट पर निर्भर करता है।
demo=# select * from books where data->'publisher' = 'XlekfkLOtL'
demo-# ;
id | author | isbn | rating | data
-----+-----------------+------------+--------+-------------------------------------------------------------------------------------
346 | uD3QOvHfJdxq2ez | KiAaIRu8QE | 1 | {"tags": {"nk88": {"ik37": "iv161"}}, "publisher": "XlekfkLOtL", "criticrating": 3}
(1 row)
demo=# explain analyze select * from books where data->'publisher' = 'XlekfkLOtL';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Index Scan using publisherhash on books (cost=0.00..2.02 rows=1 width=158) (actual time=0.016..0.017 rows=1 loops=1)
Index Cond: ((data -> 'publisher'::text) = 'XlekfkLOtL'::text)
Planning Time: 0.080 ms
Execution Time: 0.035 ms
(4 rows)
विशेष उल्लेख:GIN Trigram Indexes
PostgreSQL ट्रिग्राम इंडेक्स का उपयोग करके स्ट्रिंग मिलान का समर्थन करता है। Trigram indexes work by breaking up text into trigrams. Trigrams are basically words broken up into sequences of 3 letters. More information can be found in the documentation. GIN indexes support the “gin_trgm_ops” class that can be used to index the data in JSONB. You can choose to use expression indexes to build the trigram index on a particular column.
CREATE EXTENSION pg_trgm;
CREATE INDEX publisher ON books USING GIN ((data->'publisher') gin_trgm_ops);
demo=# select * from books where data->'publisher' LIKE '%I0UB%';
id | author | isbn | rating | data
----+-----------------+------------+--------+---------------------------------------------------------------------------------
4 | KiEk3xjqvTpmZeS | EYqXO9Nwmm | 0 | {"tags": {"nk3": {"ik1": "iv1"}}, "publisher": "MI0UBqZJDt", "criticrating": 1}
(1 row)
As you can see in the query above, we can search for any arbitrary string occurring at any potion. Unlike the B-tree indexes, we are not restricted to left anchored expressions.
demo=# explain analyze select * from books where data->'publisher' LIKE '%I0UB%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=9.78..111.28 rows=100 width=158) (actual time=0.033..0.033 rows=1 loops=1)
Recheck Cond: ((data -> 'publisher'::text) ~~ '%I0UB%'::text)
Heap Blocks: exact=1
-> Bitmap Index Scan on publisher (cost=0.00..9.75 rows=100 width=0) (actual time=0.025..0.025 rows=1 loops=1)
Index Cond: ((data -> 'publisher'::text) ~~ '%I0UB%'::text)
Planning Time: 0.213 ms
Execution Time: 0.058 ms
(7 rows)
Special Mention:GIN Array Indexes
JSONB has great built-in support for indexing arrays. Let's consider an example of indexing an array of strings using a GIN index in the case when our JSONB data contains a "keyword" element and we would like to find rows with particular keywords:
{"tags": {"nk780341": {"ik397357": "iv632731"}}, "keywords": ["abc", "kef", "keh"], "publisher": "fqaJuAdjP5", "criticrating": 2}
CREATE INDEX keywords ON books USING GIN ((data->'keywords') jsonb_path_ops);
demo=# select * from books where data->'keywords' @> '["abc", "keh"]'::jsonb;
id | author | isbn | rating | data
---------+-----------------+------------+--------+-----------------------------------------------------------------------------------------------------------------------------------
1000003 | zEG406sLKQ2IU8O | viPdlu3DZm | 4 | {"tags": {"nk263020": {"ik203820": "iv817928"}}, "keywords": ["abc", "kef", "keh"], "publisher": "7NClevxuTM", "criticrating": 2}
1000004 | GCe9NypHYKDH4rD | so6TQDYzZ3 | 4 | {"tags": {"nk780341": {"ik397357": "iv632731"}}, "keywords": ["abc", "kef", "keh"], "publisher": "fqaJuAdjP5", "criticrating": 2}
(2 rows)
demo=# explain analyze select * from books where data->'keywords' @> '["abc", "keh"]'::jsonb;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=54.75..1049.75 rows=1000 width=158) (actual time=0.026..0.028 rows=2 loops=1)
Recheck Cond: ((data -> 'keywords'::text) @> '["abc", "keh"]'::jsonb)
Heap Blocks: exact=1
-> Bitmap Index Scan on keywords (cost=0.00..54.50 rows=1000 width=0) (actual time=0.014..0.014 rows=2 loops=1)
Index Cond: ((data -> 'keywords'::text) @&amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; '["abc", "keh"]'::jsonb)
Planning Time: 0.131 ms
Execution Time: 0.063 ms
(7 rows)
The order of the items in the array on the right does not matter. For example, the following query would return the same result as the previous:
demo=# explain analyze select * from books where data->'keywords' @> '["keh","abc"]'::jsonb;
All elements in the right side array of the containment operator need to be present - basically like an "AND" operator. If you want "OR" behavior, you can construct it in the WHERE clause:
demo=# explain analyze select * from books where (data->'keywords' @> '["abc"]'::jsonb OR data->'keywords' @> '["keh"]'::jsonb);
More details on the behavior of the containment operators with arrays can be found in the documentation.
SQL/JSON &JSONPath
SQL standard added support for JSON in SQL - SQL/JSON Standard-2016. With the PostgreSQL 12/13 releases, PostgreSQL has one of the best implementations of the SQL/JSON standard. For more details refer to the PostgreSQL 12 announcement.
One of the core features of SQL/JSON is support for the JSONPath language to query JSONB data. JSONPath allows you to specify an expression (using a syntax similar to the property access notation in Javascript) to query your JSONB data. This makes it simple and intuitive, but is also very powerful to query your JSONB data. Think of JSONPath as the logical equivalent of XPath for XML.
| .key | Returns an object member with the specified key. |
| [*] | Wildcard array element accessor that returns all array elements. |
| .* | Wildcard member accessor that returns the values of all members located at the top level of the current object. |
| .** | Recursive wildcard member accessor that processes all levels of the JSON hierarchy of the current object and returns all the member values, regardless of their nesting level. |
Refer to JSONPath documentation for the full list of operators. JSONPath also supports a variety of filter expressions.
JSONPath Functions
PostgreSQL 12 provides several functions to use JSONPath to query your JSONB data. From the docs:
- jsonb_path_exists - Checks whether JSONB path returns any item for the specified JSON मूल्य।
- jsonb_path_match - Returns the result of JSONB path predicate check for the specified JSONB value. Only the first item of the result is taken into account. If the result is not Boolean, then null is returned.
- jsonb_path_query - Gets all JSONB items returned by JSONB path for the specified JSONB value. There are also a couple of other variants of this function that handle arrays of objects.
Let's start with a simple query - finding books by publisher:
demo=# select * from books where data @@ '$.publisher == "ktjKEZ1tvq"';
id | author | isbn | rating | data
---------+-----------------+------------+--------+----------------------------------------------------------------------------------------------------------------------------------
1000001 | 4RNsovI2haTgU7l | GwSoX67gLS | 2 | {"tags": {"nk542369": {"ik55240": "iv305393"}}, "keywords": ["abc", "def", "geh"], "publisher": "ktjKEZ1tvq", "criticrating": 0}
(1 row)
demo=# explain analyze select * from books where data @@ '$.publisher == "ktjKEZ1tvq"';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=21.75..1014.25 rows=1000 width=158) (actual time=0.123..0.124 rows=1 loops=1)
Recheck Cond: (data @@ '($."publisher" == "ktjKEZ1tvq")'::jsonpath)
Heap Blocks: exact=1
-> Bitmap Index Scan on datagin (cost=0.00..21.50 rows=1000 width=0) (actual time=0.110..0.110 rows=1 loops=1)
Index Cond: (data @@ '($."publisher" == "ktjKEZ1tvq")'::jsonpath)
Planning Time: 0.137 ms
Execution Time: 0.194 ms
(7 rows)
You can rewrite this expression as a JSONPath filter:
demo=# select * from books where jsonb_path_exists(data,'$.publisher ?(@ == "ktjKEZ1tvq")');
You can also use very complex query expressions. For example, let's select books where print style =hardcover and price =100:
select * from books where jsonb_path_exists(data, '$.prints[*] ?(@.style=="hc" &amp;amp;amp;amp;&amp;amp;amp;amp; @.price == 100)');
However, index support for JSONPath is very limited at this point - this makes it dangerous to use JSONPath in the where clause. JSONPath support for indexes will be improved in subsequent releases.
demo=# explain analyze select * from books where jsonb_path_exists(data,'$.publisher ?(@ == "ktjKEZ1tvq")');
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Seq Scan on books (cost=0.00..36307.24 rows=333340 width=158) (actual time=0.019..480.268 rows=1 loops=1)
Filter: jsonb_path_exists(data, '$."publisher"?(@ == "ktjKEZ1tvq")'::jsonpath, '{}'::jsonb, false)
Rows Removed by Filter: 1000028
Planning Time: 0.095 ms
Execution Time: 480.348 ms
(5 rows)
Projecting Partial JSON
Another great use case for JSONPath is projecting partial JSONB from the row that matches. Consider the following sample JSONB:
demo=# select jsonb_pretty(data) from books where id = 1000029;
jsonb_pretty
-----------------------------------
{
"tags": {
"nk678947": {
"ik159670": "iv32358
}
},
"prints": [
{
"price": 100,
"style": "hc"
},
{
"price": 50,
"style": "pb"
}
],
"braille": false,
"keywords": [
"abc",
"kef",
"keh"
],
"hardcover": true,
"publisher": "ppc3YXL8kK",
"criticrating": 3
}
Select only the publisher field:
demo=# select jsonb_path_query(data, '$.publisher') from books where id = 1000029; jsonb_path_query ------------------ "ppc3YXL8kK" (1 row)
Select the prints field (which is an array of objects):
demo=# select jsonb_path_query(data, '$.prints') from books where id = 1000029;
jsonb_path_query
---------------------------------------------------------------
[{"price": 100, "style": "hc"}, {"price": 50, "style": "pb"}]
(1 row)
Select the first element in the array prints:
demo=# select jsonb_path_query(data, '$.prints[0]') from books where id = 1000029;
jsonb_path_query
-------------------------------
{"price": 100, "style": "hc"}
(1 row)
Select the last element in the array prints:
demo=# select jsonb_path_query(data, '$.prints[$.size()]') from books where id = 1000029;
jsonb_path_query
------------------------------
{"price": 50, "style": "pb"}
(1 row)
Select only the hardcover prints from the array:
demo=# select jsonb_path_query(data, '$.prints[*] ?(@.style=="hc")') from books where id = 1000029;
jsonb_path_query
-------------------------------
{"price": 100, "style": "hc"}
(1 row)
We can also chain the filters:
demo=# select jsonb_path_query(data, '$.prints[*] ?(@.style=="hc") ?(@.price ==100)') from books where id = 1000029;
jsonb_path_query
-------------------------------
{"price": 100, "style": "hc"}
(1 row)
In summary, PostgreSQL provides a powerful and versatile platform to store and process JSON data. There are several gotcha's that you need to be aware of, but we are optimistic that it will be fixed in future releases.

|