कुछ साल पहले (मैड्रिड में pgconf.eu 2014 में) मैंने "प्रदर्शन पुरातत्व" नामक एक वार्ता प्रस्तुत की, जिसमें दिखाया गया कि हाल ही में पोस्टग्रेएसक्यूएल रिलीज में प्रदर्शन कैसे बदल गया। मैंने वह बात की क्योंकि मुझे लगता है कि दीर्घकालिक दृष्टिकोण दिलचस्प है और हमें अंतर्दृष्टि प्रदान कर सकता है जो बहुत मूल्यवान हो सकता है। जो लोग वास्तव में मेरे जैसे PostgreSQL कोड पर काम करते हैं, उनके लिए यह भविष्य के विकास के लिए एक उपयोगी मार्गदर्शिका है, और PostgreSQL उपयोगकर्ताओं के लिए यह अपग्रेड का मूल्यांकन करने में मदद कर सकता है।
इसलिए मैंने इस अभ्यास को दोहराने का फैसला किया है, और कई पोस्टग्रेएसक्यूएल संस्करणों के प्रदर्शन का विश्लेषण करते हुए कुछ ब्लॉग पोस्ट लिखने का फैसला किया है। 2014 की बातचीत में मैंने PostgreSQL 7.4 के साथ शुरुआत की, जो उस समय लगभग 10 साल पुराना था (2003 में जारी)। इस बार मैं PostgreSQL 8.3 से शुरू करूंगा, जो लगभग 12 वर्ष पुराना है।
PostgreSQL 7.4 से फिर से शुरू क्यों नहीं? लगभग तीन मुख्य कारण हैं कि मैंने PostgreSQL 8.3 के साथ शुरुआत करने का निर्णय क्यों लिया। सबसे पहले, सामान्य आलस्य। संस्करण जितना पुराना होगा, वर्तमान कंपाइलर संस्करणों आदि का उपयोग करके इसे बनाना उतना ही कठिन हो सकता है। दूसरे, विशेष रूप से बड़ी मात्रा में डेटा के साथ उचित बेंचमार्क चलाने में समय लगता है, इसलिए एक एकल प्रमुख संस्करण जोड़ने से मशीन के समय में कुछ दिन आसानी से जुड़ सकते हैं। यह बस इसके लायक नहीं लग रहा था। और अंत में, 8.3 ने कई महत्वपूर्ण परिवर्तन पेश किए - ऑटोवैक्यूम सुधार (डिफ़ॉल्ट रूप से सक्षम, समवर्ती कार्यकर्ता प्रक्रियाएं, ...), कोर में एकीकृत पूर्ण-पाठ खोज, चौकियों का प्रसार, और इसी तरह। इसलिए मुझे लगता है कि PostgreSQL 8.3 से शुरू करना सही समझ में आता है। जो लगभग 12 साल पहले जारी किया गया था, इसलिए यह तुलना वास्तव में लंबी अवधि को कवर करेगी।
मैंने तीन बुनियादी कार्यभार प्रकारों को बेंचमार्क करने का निर्णय लिया है - OLTP, विश्लेषण और पूर्ण-पाठ खोज। मुझे लगता है कि ओएलटीपी और एनालिटिक्स काफी स्पष्ट विकल्प हैं, क्योंकि अधिकांश एप्लिकेशन उन दो बुनियादी प्रकारों के कुछ मिश्रण हैं। पूर्ण-पाठ खोज मुझे विशेष प्रकार के अनुक्रमितों में सुधार प्रदर्शित करने की अनुमति देता है, जिनका उपयोग लोकप्रिय डेटा प्रकारों जैसे JSONB, PostGIS द्वारा उपयोग किए जाने वाले प्रकार आदि को अनुक्रमित करने के लिए भी किया जाता है।
ऐसा क्यों करते हैं?
क्या यह वास्तव में प्रयास के लायक है? आखिरकार, हम यह दिखाने के लिए हर समय विकास के दौरान बेंचमार्क करते हैं कि एक पैच मदद करता है और/या यह प्रतिगमन का कारण नहीं बनता है, है ना? परेशानी यह है कि ये आमतौर पर केवल "आंशिक" बेंचमार्क होते हैं, दो विशेष प्रतिबद्धताओं की तुलना करते हैं, और आमतौर पर वर्कलोड के काफी सीमित चयन के साथ जो हमें लगता है कि प्रासंगिक हो सकता है। जो सही समझ में आता है - आप बस प्रत्येक प्रतिबद्धता के लिए कार्यभार की पूरी बैटरी नहीं चला सकते।
कभी-कभी (आमतौर पर एक नया पोस्टग्रेएसक्यूएल प्रमुख संस्करण जारी होने के तुरंत बाद) लोग नए संस्करण की तुलना पिछले वाले से करते हैं, जो अच्छा है और मैं आपको ऐसे बेंचमार्क चलाने के लिए प्रोत्साहित करता हूं (चाहे वह किसी प्रकार का मानक बेंचमार्क हो, या आपके आवेदन के लिए कुछ विशिष्ट)। लेकिन इन परिणामों को दीर्घकालिक दृष्टिकोण में संयोजित करना कठिन है, क्योंकि वे परीक्षण विभिन्न कॉन्फ़िगरेशन और हार्डवेयर का उपयोग करते हैं (आमतौर पर नए संस्करण के लिए हाल ही में एक), और इसी तरह। इसलिए सामान्य रूप से परिवर्तनों के बारे में स्पष्ट निर्णय लेना कठिन है।
वही एप्लिकेशन प्रदर्शन पर लागू होता है, जो निश्चित रूप से "अंतिम बेंचमार्क" है। लेकिन लोग हर बड़े संस्करण में अपग्रेड नहीं कर सकते हैं (कभी-कभी वे कुछ संस्करणों को छोड़ सकते हैं, जैसे 9.5 से 12 तक)। और जब वे अपग्रेड करते हैं, तो इसे अक्सर हार्डवेयर अपग्रेड आदि के साथ जोड़ दिया जाता है। यह उल्लेख नहीं करने के लिए कि एप्लिकेशन समय के साथ विकसित होते हैं (नई सुविधाएं, अतिरिक्त जटिलता), डेटा की मात्रा और समवर्ती उपयोगकर्ताओं की संख्या बढ़ती है, आदि।
यह ब्लॉग श्रृंखला यही दिखाने की कोशिश करती है - कुछ बुनियादी वर्कलोड के लिए पोस्टग्रेएसक्यूएल प्रदर्शन में दीर्घकालिक रुझान, ताकि हम - डेवलपर्स - वर्षों से अच्छे काम के बारे में कुछ गर्म और अस्पष्ट महसूस कर सकें। और उपयोगकर्ताओं को यह दिखाने के लिए कि भले ही इस समय PostgreSQL एक परिपक्व उत्पाद है, फिर भी हर नए प्रमुख संस्करण में महत्वपूर्ण सुधार हैं।
अन्य डेटाबेस उत्पादों के साथ तुलना के लिए इन बेंचमार्क का उपयोग करना, या किसी आधिकारिक रैंकिंग (जैसे टीपीसी-एच एक) को पूरा करने के लिए परिणाम तैयार करना मेरा लक्ष्य नहीं है। मेरा लक्ष्य बस खुद को एक PostgreSQL डेवलपर के रूप में शिक्षित करना है, शायद कुछ समस्याओं की पहचान करना और उनकी जांच करना, और दूसरों के साथ निष्कर्ष साझा करना है।
उचित तुलना?
मुझे नहीं लगता कि 12 वर्षों में जारी किए गए संस्करणों की ऐसी कोई तुलना पूरी तरह से उचित नहीं हो सकती है, क्योंकि कोई भी सॉफ़्टवेयर किसी विशेष संदर्भ में विकसित किया गया है - डेटाबेस सिस्टम के लिए हार्डवेयर एक अच्छा उदाहरण है। अगर आप 12 साल पहले इस्तेमाल की गई मशीनों को देखें तो उनमें कितने कोर थे, कितनी रैम? उन्होंने किस प्रकार के भंडारण का उपयोग किया?
2008 में एक विशिष्ट मिडरेंज सर्वर में शायद 8-12 कोर, 16GB RAM और कुछ SAS ड्राइव के साथ एक RAID था। एक सामान्य मिडरेंज सर्वर में आज कुछ दर्जन कोर, सैकड़ों जीबी रैम और एसएसडी स्टोरेज हो सकते हैं।
सॉफ़्टवेयर विकास प्राथमिकता के आधार पर आयोजित किया जाता है - आपके पास समय से अधिक संभावित कार्य होते हैं, इसलिए आपको अपने उपयोगकर्ताओं के लिए सर्वोत्तम लागत/लाभ अनुपात वाले कार्यों को चुनने की आवश्यकता होती है (विशेषकर वे परियोजना को प्रत्यक्ष या अप्रत्यक्ष रूप से वित्त पोषित करते हैं)। और 2008 में कुछ अनुकूलन शायद अभी तक प्रासंगिक नहीं थे - अधिकांश मशीनों में अत्यधिक मात्रा में RAM नहीं थी इसलिए बड़े साझा बफ़र्स के लिए अनुकूलन अभी तक इसके लायक नहीं था, उदाहरण के लिए। और सीपीयू की बहुत सी अड़चनें I/O से दूर हो गईं, क्योंकि अधिकांश मशीनों में "स्पिनिंग रस्ट" स्टोरेज थी।
ध्यान दें:बेशक, उस समय भी बहुत बड़ी मशीनों का उपयोग करने वाले ग्राहक थे। कुछ ने विभिन्न ट्वीक्स के साथ पोस्टग्रेज का इस्तेमाल किया, अन्य ने अतिरिक्त क्षमताओं के साथ विभिन्न पोस्टग्रेज फोर्क्स में से एक के साथ चलने का फैसला किया (जैसे बड़े पैमाने पर समानता, वितरित प्रश्न, एफपीजीए आदि का उपयोग करना)। और इसने निश्चित रूप से सामुदायिक विकास को भी प्रभावित किया।
जैसे-जैसे बड़ी मशीनें वर्षों में अधिक आम होती गईं, अधिक लोग बड़ी मात्रा में रैम और उच्च कोर काउंट वाली मशीनों को खरीद सकते थे, लागत / लाभ अनुपात को स्थानांतरित कर सकते थे। बाधाओं की जांच की गई और उन्हें संबोधित किया गया, जिससे नए संस्करण बेहतर प्रदर्शन कर सके।
इसका मतलब है कि इस तरह का एक बेंचमार्क हमेशा थोड़ा अनुचित होता है - यह सेटअप (हार्डवेयर, कॉन्फिग) के आधार पर पुराने या नए संस्करण का पक्ष लेगा। मैंने हार्डवेयर और कॉन्फ़िगरेशन पैरामीटर चुनने की कोशिश की है ताकि पुराने संस्करणों के लिए यह बहुत बुरा न हो।
मैं जो बिंदु बनाने की कोशिश कर रहा हूं वह यह है कि इसका मतलब यह नहीं है कि पुराने पोस्टग्रेएसक्यूएल संस्करण बकवास थे - इस तरह सॉफ्टवेयर विकास काम करता है। आप उन बाधाओं को दूर करते हैं जिनका आपके उपयोगकर्ताओं को सामना करना पड़ सकता है, न कि उन बाधाओं को जो वे 10 वर्षों में सामना कर सकते हैं।
हार्डवेयर
मैं भौतिक हार्डवेयर पर बेंचमार्क करना पसंद करता हूं, जिसकी मेरी सीधी पहुंच है, क्योंकि इससे मुझे सभी विवरणों को नियंत्रित करने की अनुमति मिलती है, मेरे पास सभी विवरणों तक पहुंच है, और इसी तरह। इसलिए मैंने अपने कार्यालय में मौजूद मशीन का उपयोग किया है - कुछ भी फैंसी नहीं है, लेकिन उम्मीद है कि इस उद्देश्य के लिए काफी अच्छा है।
- 2x E5-2620 v4 (16 कोर, 32 थ्रेड)
- 64GB रैम
- Intel Optane 900P 280GB NVMe SSD (डेटा)
- 3 x 7.2k SATA RAID0 (अस्थायी टेबलस्पेस)
- कर्नेल 5.6.15, ext4
- जीसीसी 9.2.0, बजना 9.0.1
मैंने एक दूसरी - बहुत छोटी - मशीन का भी उपयोग किया है, जिसमें केवल 4 कोर और 8GB RAM है, जो आम तौर पर समान सुधार / प्रतिगमन दिखाता है, बस कम स्पष्ट है।
पीजीबेंच
बेंचमार्किंग टूल के रूप में मैंने सभी संस्करणों का परीक्षण करने के लिए नवीनतम संस्करण (पोस्टग्रेएसक्यूएल 13 से) का उपयोग करके प्रसिद्ध पीजीबेंच का उपयोग किया है। यह समय के साथ pgbench में किए गए अनुकूलन के कारण संभावित पूर्वाग्रह को समाप्त करता है, जिससे परिणाम अधिक तुलनीय हो जाते हैं।
बेंचमार्क कई अलग-अलग मामलों का परीक्षण करता है, जिसमें कई पैरामीटर अलग-अलग होते हैं, अर्थात्:
पैमाना
- छोटा - डेटा साझा बफर में फिट बैठता है, लॉकिंग मुद्दों आदि को दिखाता है।
- माध्यम - साझा बफ़र्स से बड़ा डेटा लेकिन RAM में फ़िट हो जाता है, आमतौर पर CPU बाध्य (या संभवतः I/O रीड-राइट वर्कलोड के लिए)
- बड़ा - RAM से बड़ा डेटा, मुख्य रूप से I/O बाध्य
मोड
- केवल पढ़ने के लिए - pgbench -S
- पढ़ें-लिखें - pgbench -N
ग्राहकों की संख्या
- 1, 4, 8, 16, 32, 64, 128, 256
- pgbench थ्रेड्स (-j) की संख्या को तदनुसार बदल दिया जाता है
परिणाम
ठीक है, आइए परिणाम देखें। मैं पहले NVMe स्टोरेज से परिणाम प्रस्तुत करूंगा, फिर मैं SATA RAID स्टोरेज का उपयोग करके कुछ दिलचस्प परिणाम दिखाऊंगा।
NVMe SSD / केवल पढ़ने के लिए
छोटे डेटा सेट के लिए (जो पूरी तरह से साझा बफर में फिट बैठता है), केवल-पढ़ने के परिणाम इस तरह दिखते हैं:
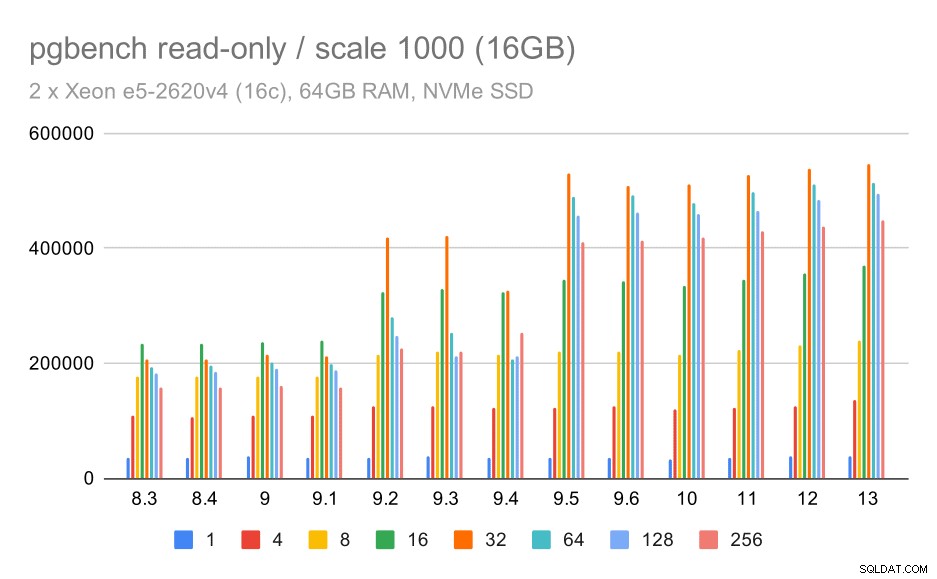
pgbench परिणाम / छोटे डेटा सेट पर केवल पढ़ने के लिए (स्केल 100, यानी 1.6GB)
स्पष्ट रूप से, 9.2 में थ्रूपुट में उल्लेखनीय वृद्धि हुई थी, जिसमें कई प्रदर्शन सुधार शामिल थे, उदाहरण के लिए लॉकिंग के लिए फास्ट-पाथ। एकल क्लाइंट के लिए थ्रूपुट वास्तव में थोड़ा कम हो जाता है - 47k tps से केवल 42k tps तक। लेकिन उच्च ग्राहक संख्या के लिए 9.2 में सुधार बहुत स्पष्ट है।
मध्यम डेटा सेट पर pgbench परिणाम / केवल-पढ़ने के लिए (स्केल 1000, यानी 16GB)
मध्यम डेटा सेट के लिए (जो साझा बफ़र्स से बड़ा है लेकिन फिर भी रैम में फिट बैठता है) 9.2 में भी कुछ सुधार प्रतीत होता है, हालांकि ऊपर के रूप में स्पष्ट नहीं है, इसके बाद 9.5 में बहुत स्पष्ट सुधार होने की संभावना है, लॉक स्केलेबिलिटी सुधार के लिए धन्यवाद ।
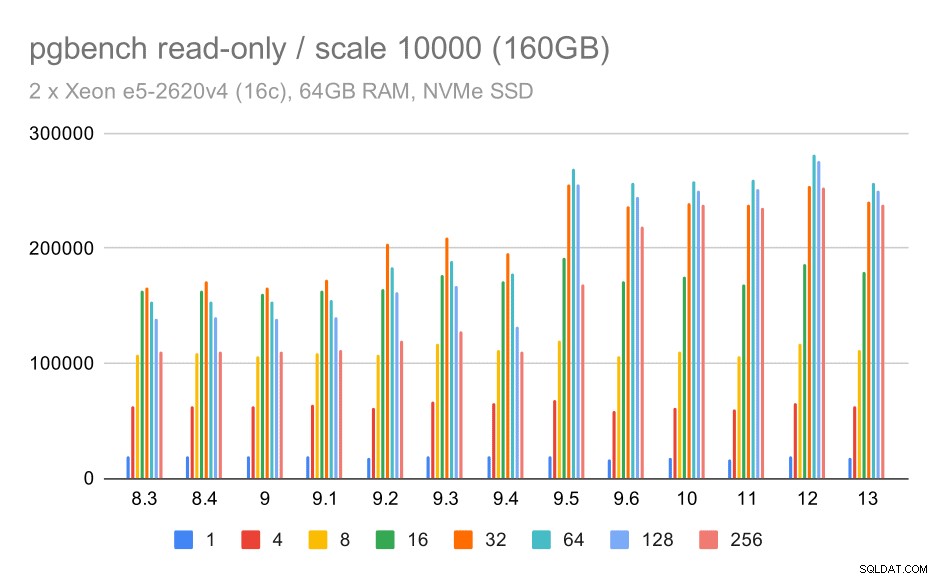
बड़े डेटा सेट (पैमाने पर 10000, यानी 160GB) पर pgbench परिणाम / केवल-पढ़ने के लिए
सबसे बड़े डेटा सेट पर, जो ज्यादातर भंडारण को कुशलता से उपयोग करने की क्षमता के बारे में है, कुछ गति भी है - संभवतः 9.5 सुधारों के लिए भी धन्यवाद।
NVMe SSD / रीड-राइट
पढ़ने-लिखने के परिणाम कुछ सुधार भी दिखाते हैं, हालांकि उतना स्पष्ट नहीं है। छोटे डेटा सेट पर, परिणाम इस तरह दिखते हैं:
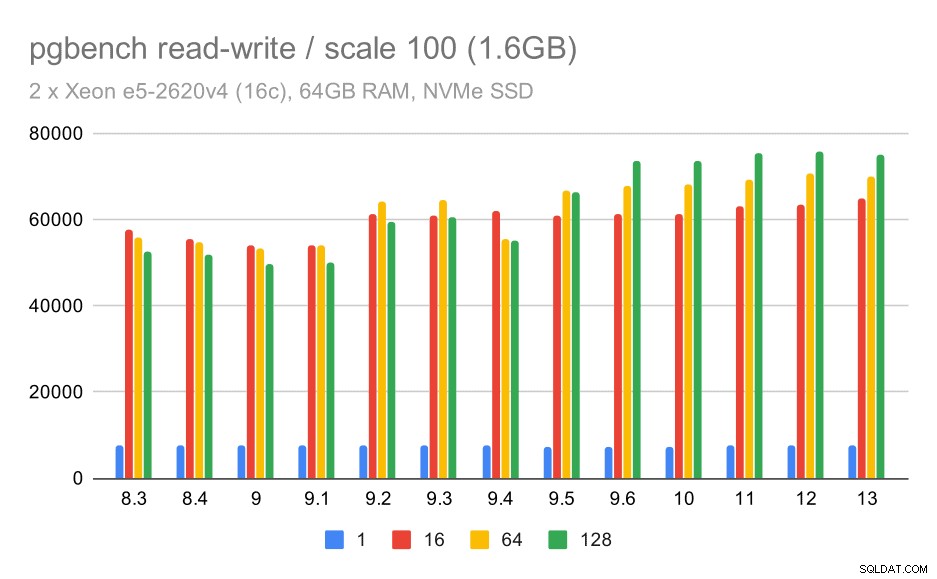
छोटे डेटा सेट पर pgbench परिणाम/पढ़ना-लिखना (स्केल 100, यानी 1.6GB)
इसलिए पर्याप्त संख्या में ग्राहकों के साथ लगभग 52k से 75k tps तक मामूली सुधार।
मध्यम डेटा सेट के लिए, सुधार बहुत स्पष्ट है - लगभग 27k से 63k tps तक, यानी थ्रूपुट दोगुने से अधिक।
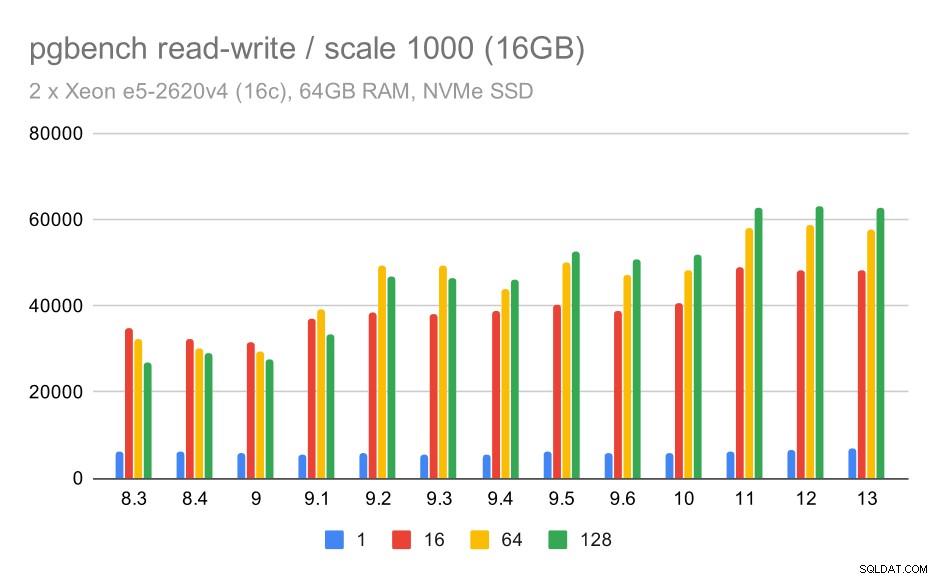
मध्यम डेटा सेट पर pgbench परिणाम/पढ़ना-लिखना (स्केल 1000, यानी 16GB)
सबसे बड़े डेटा सेट के लिए, हम एक समान समग्र सुधार देखते हैं, लेकिन 9.5 और 11 के बीच कुछ प्रतिगमन प्रतीत होता है।
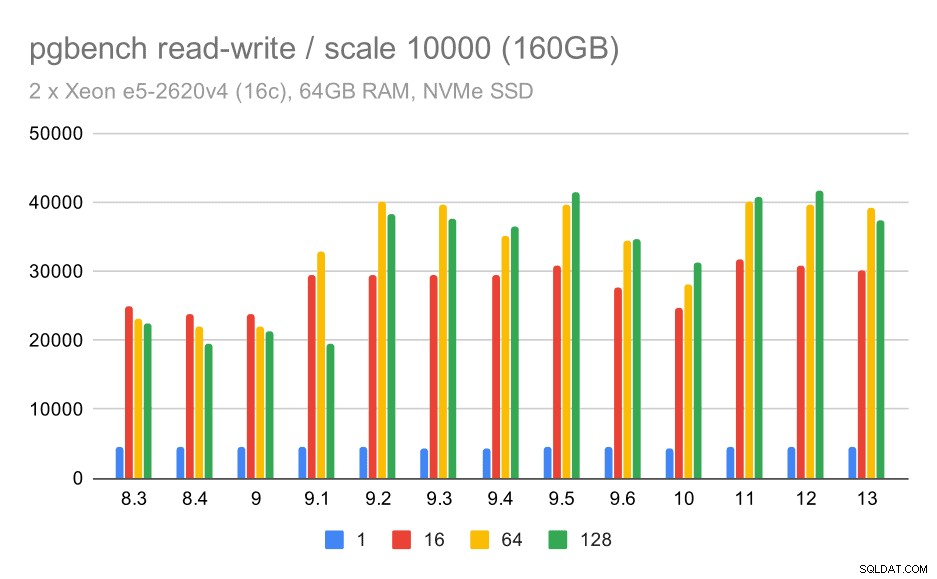
बड़े डेटा सेट पर pgbench परिणाम/पढ़ना-लिखना (पैमाना 10000, यानी 160GB)
SATA RAID / केवल पढ़ने के लिए
SATA RAID भंडारण के लिए, केवल-पढ़ने के परिणाम उतने अच्छे नहीं होते हैं। हम छोटे और मध्यम डेटा सेट को अनदेखा कर सकते हैं, जिसके लिए स्टोरेज सिस्टम अप्रासंगिक है। बड़े डेटा सेट के लिए, थ्रूपुट कुछ हद तक शोर है लेकिन यह वास्तव में समय के साथ कम हो जाता है - खासकर PostgreSQL 9.6 के बाद से। मुझे नहीं पता कि इसका क्या कारण है (9.6 जारी नोटों में कुछ भी स्पष्ट उम्मीदवार की तरह नहीं है), लेकिन यह किसी प्रकार का प्रतिगमन जैसा लगता है।
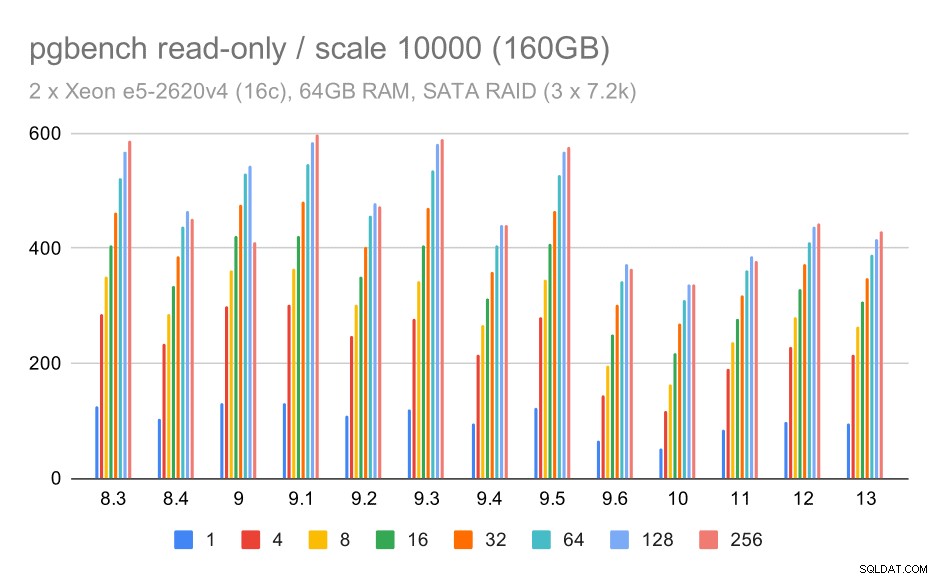
सैटा RAID पर pgbench परिणाम / बड़े डेटा सेट पर केवल पढ़ने के लिए (पैमाना 10000, यानी 160GB)
SATA RAID / पठन-लेखन
हालाँकि, पढ़ने-लिखने का व्यवहार बहुत अच्छा लगता है। छोटे डेटा सेट पर, थ्रूपुट लगभग 600 tps से बढ़कर 6000 tps से अधिक हो जाता है। मुझे यकीन है कि यह 9.1 और 9.2 में समूह प्रतिबद्धता में सुधार के लिए धन्यवाद है।
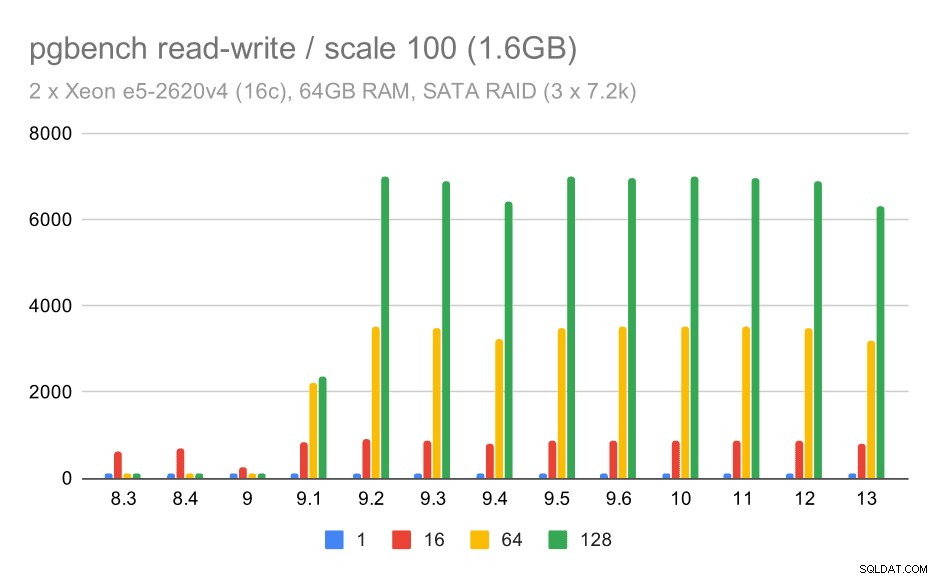
SATA RAID पर pgbench परिणाम / छोटे डेटा सेट पर रीड-राइट (स्केल 100, यानी 1.6GB)
मध्यम और बड़े पैमाने के लिए हम समान - लेकिन छोटे - सुधार देख सकते हैं, क्योंकि भंडारण को डेटा ब्लॉक को पढ़ने और लिखने के लिए I/O अनुरोधों को संभालने की भी आवश्यकता होती है। मध्यम पैमाने के लिए हमें केवल लिखने की आवश्यकता है (जैसा कि डेटा रैम में फिट बैठता है), बड़े पैमाने के लिए हमें भी पढ़ने की आवश्यकता होती है - इसलिए अधिकतम थ्रूपुट और भी कम होता है।
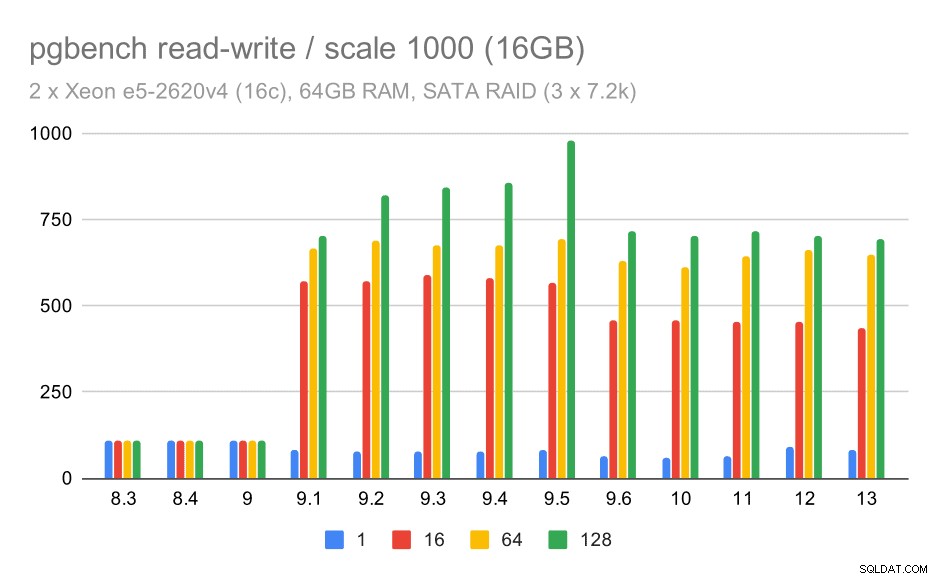
SATA RAID पर pgbench परिणाम / मध्यम डेटा सेट पर पढ़ना-लिखना (स्केल 1000, यानी 16GB)
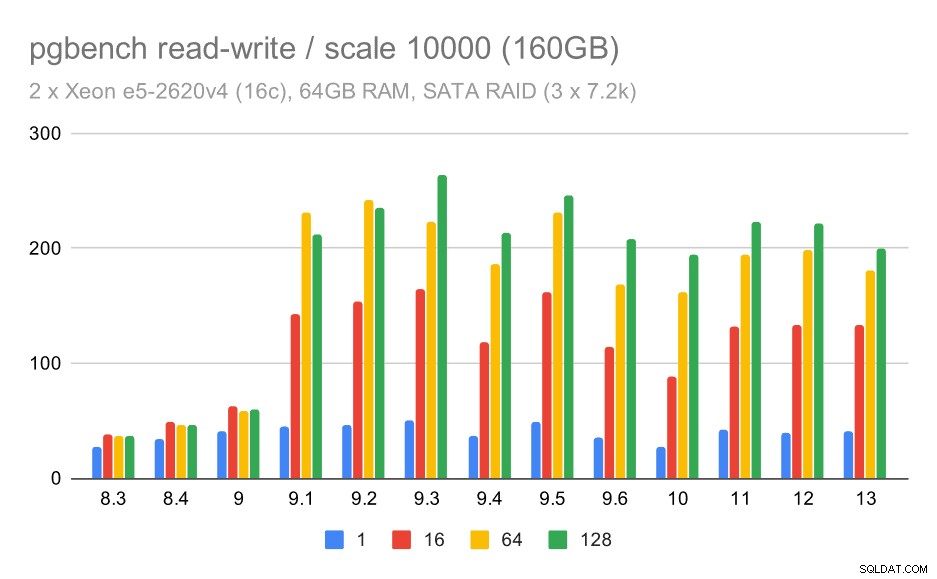
SATA RAID पर pgbench परिणाम / बड़े डेटा सेट पर पढ़ना-लिखना (पैमाना 10000, यानी 160GB)
सारांश और भविष्य
संक्षेप में, NVMe सेटअप के लिए निष्कर्ष काफी सकारात्मक प्रतीत होते हैं। रीड-ओनली वर्कलोड के लिए 9.2 में मध्यम गति और 9.5 में महत्वपूर्ण गति है, स्केलेबिलिटी ऑप्टिमाइज़ेशन के लिए धन्यवाद, जबकि रीड-राइट वर्कलोड के लिए कई संस्करणों / चरणों में समय के साथ प्रदर्शन में लगभग 2x सुधार हुआ है।
सैटा RAID सेटअप के साथ निष्कर्ष कुछ हद तक मिश्रित हैं, हालांकि। रीड-ओनली वर्कलोड के मामले में 9.6 में बहुत अधिक परिवर्तनशीलता / शोर और संभावित प्रतिगमन है। रीड-राइट वर्कलोड के लिए, 9.1 में भारी गति है जहां थ्रूपुट अचानक 100 टीपीएस से बढ़कर लगभग 600 टीपीएस हो गया।
भविष्य के PostgreSQL संस्करणों में सुधार के बारे में क्या? मेरे पास एक बहुत स्पष्ट विचार नहीं है कि अगला बड़ा सुधार क्या होगा - हालांकि मुझे यकीन है कि अन्य पोस्टग्रेएसक्यूएल हैकर शानदार विचारों के साथ आएंगे जो चीजों को और अधिक कुशल बनाते हैं या उपलब्ध हार्डवेयर संसाधनों का लाभ उठाने की अनुमति देते हैं। कई कनेक्शनों के साथ मापनीयता में सुधार के लिए पैच या गैर-वाष्पशील वाल बफ़र्स के लिए समर्थन जोड़ने के लिए पैच ऐसे सुधारों के उदाहरण हैं। हम पोस्टग्रेएसक्यूएल स्टोरेज में कुछ मौलिक सुधार देख सकते हैं (अधिक कुशल ऑन-डिस्क प्रारूप, प्रत्यक्ष I/O आदि का उपयोग करके), अनुक्रमण, आदि।