Moodle सबसे लोकप्रिय लर्निंग मैनेजमेंट सिस्टम (LMS) है जो शिक्षकों को पाठ्यक्रम या सामग्री के साथ अपनी वेबसाइट बनाने की अनुमति देता है जो सीखने का विस्तार करता है। इस प्रकार के प्लेटफ़ॉर्म अधिक से अधिक महत्वपूर्ण होते जा रहे हैं ताकि आप पारंपरिक शिक्षा प्रणाली उपलब्ध न होने पर या इसके पूरक के रूप में दूरस्थ रूप से सीखना जारी रख सकें, इसलिए ट्रैफ़िक या उपयोगकर्ताओं की वृद्धि को कम प्रतिक्रिया सुनिश्चित करने के लिए आपके वातावरण को स्केल करने की आवश्यकता होती है। समय।
स्केलेबिलिटी एक सिस्टम/डेटाबेस की संपत्ति है जो संसाधनों को जोड़कर मांगों की बढ़ती मात्रा को संभालती है। आपके डेटाबेस को स्केल करने के तरीके के आधार पर आपके डेटाबेस को स्केल करने के लिए अलग-अलग दृष्टिकोण उपलब्ध हैं, और, उत्पादन वातावरण में, शायद लंबे समय तक डाउनटाइम वांछित नहीं है, इसलिए आपको इसे भी ध्यान में रखना चाहिए।
इस ब्लॉग में, हम देखेंगे कि कौन-से पैमाने के विकल्प उपलब्ध हैं और आपके चल रहे सिस्टम को प्रभावित किए बिना अपने Moodle PostgreSQL डेटाबेस को आसान तरीके से कैसे बढ़ाया जाए।
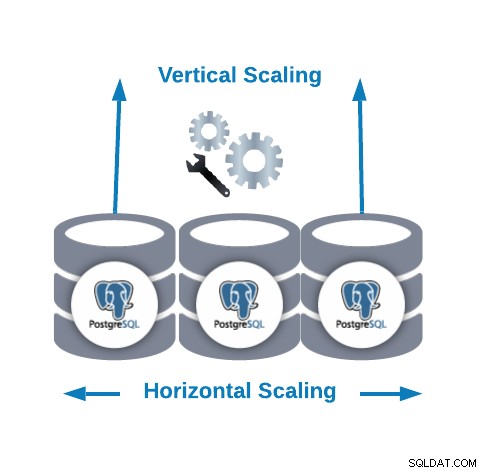
क्षैतिज स्केलिंग और लंबवत स्केलिंग
आपके डेटाबेस को मापने के दो मुख्य तरीके हैं:
- क्षैतिज स्केलिंग (स्केल-आउट):यह डेटाबेस क्लस्टर बनाने या बढ़ाने के लिए और अधिक डेटाबेस नोड्स जोड़कर किया जाता है।
- वर्टिकल स्केलिंग (स्केल-अप):यह मौजूदा डेटाबेस नोड में अधिक हार्डवेयर संसाधन (CPU, मेमोरी, डिस्क) जोड़कर किया जाता है।
क्षैतिज स्केलिंग के लिए , आप स्टैंडबाय नोड्स के रूप में अधिक डेटाबेस नोड्स जोड़ सकते हैं। यह नोड्स के बीच यातायात को संतुलित करने वाले पठन प्रदर्शन को बेहतर बनाने में आपकी मदद कर सकता है। इस मामले में, आपको नीति और नोड स्थिति के आधार पर ट्रैफ़िक को सही नोड पर वितरित करने के लिए लोड बैलेंसर जोड़ने की आवश्यकता होगी। आपको विफलता के एक बिंदु से बचने के लिए दो या अधिक लोड बैलेंसर नोड्स जोड़ने पर विचार करना चाहिए, और उपलब्धता सुनिश्चित करने के लिए "रख-रखाव" जैसे टूल का उपयोग करना चाहिए। Keepalived एक ऐसी सेवा है जो आपको सर्वर के एक सक्रिय/निष्क्रिय समूह के भीतर एक वर्चुअल IP पता कॉन्फ़िगर करने की अनुमति देती है। यह वर्चुअल आईपी एड्रेस एक सक्रिय सर्वर (सक्रिय लोड बैलेंसर) को सौंपा गया है। यदि यह सर्वर विफल हो जाता है, तो आईपी पता स्वचालित रूप से "माध्यमिक" निष्क्रिय सर्वर में माइग्रेट हो जाता है, जिससे यह सिस्टम के लिए पारदर्शी तरीके से उसी आईपी पते के साथ काम करना जारी रखता है।
ऊर्ध्वाधर स्केलिंग के लिए , PostgreSQL को एक नए या बेहतर हार्डवेयर संसाधन का उपयोग करने की अनुमति देने के लिए कुछ कॉन्फ़िगरेशन मापदंडों को बदलने की आवश्यकता हो सकती है। आइए PostgreSQL दस्तावेज़ीकरण से इनमें से कुछ पैरामीटर देखें।
- work_mem:अस्थायी डिस्क फ़ाइलों पर लिखने से पहले आंतरिक सॉर्ट संचालन और हैश टेबल द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को निर्दिष्ट करता है। कई रनिंग सेशन एक साथ ऐसे ऑपरेशन कर सकते हैं, इसलिए उपयोग की जाने वाली कुल मेमोरी वर्क_मेम के मान से कई गुना अधिक हो सकती है।
- maintenance_work_mem:रखरखाव कार्यों, जैसे VACUUM, CREATE INDEX, और ALTER TABLE ADD FOREIGN KEY द्वारा उपयोग की जाने वाली मेमोरी की अधिकतम मात्रा को निर्दिष्ट करता है। बड़ी सेटिंग्स वैक्यूमिंग और डेटाबेस डंप को पुनर्स्थापित करने के लिए प्रदर्शन में सुधार कर सकती हैं।
- autovacuum_work_mem:प्रत्येक autovacuum कार्यकर्ता प्रक्रिया द्वारा उपयोग की जाने वाली मेमोरी की अधिकतम मात्रा निर्दिष्ट करता है।
- autovacuum_max_workers:ऑटोवैक्यूम प्रक्रियाओं की अधिकतम संख्या निर्दिष्ट करता है जो किसी एक समय में चल सकती हैं।
- max_worker_processes:सिस्टम द्वारा समर्थित अधिकतम पृष्ठभूमि प्रक्रियाओं को सेट करता है। वैक्यूमिंग, चेकपॉइंट, और अधिक रखरखाव कार्य जैसी प्रक्रिया की सीमा निर्दिष्ट करें।
- max_parallel_workers:उन कर्मचारियों की अधिकतम संख्या सेट करता है जो सिस्टम समानांतर संचालन के लिए समर्थन कर सकता है। समानांतर श्रमिकों को पिछले पैरामीटर द्वारा स्थापित कार्यकर्ता प्रक्रियाओं के पूल से लिया जाता है।
- max_parallel_maintenance_workers:समानांतर वर्कर्स की अधिकतम संख्या सेट करता है जिसे सिंगल यूटिलिटी कमांड द्वारा शुरू किया जा सकता है। वर्तमान में, समानांतर श्रमिकों के उपयोग का समर्थन करने वाला एकमात्र समानांतर उपयोगिता कमांड क्रिएट इंडेक्स है, और केवल बी-ट्री इंडेक्स बनाते समय।
- प्रभावी_कैश_साइज:डिस्क कैश के प्रभावी आकार के बारे में योजनाकार की धारणा सेट करता है जो एकल क्वेरी के लिए उपलब्ध है। यह एक सूचकांक का उपयोग करने की लागत के अनुमानों में शामिल है; एक उच्च मान इसे और अधिक संभावना बनाता है कि इंडेक्स स्कैन का उपयोग किया जाएगा, एक कम मान यह अधिक संभावना बनाता है कि अनुक्रमिक स्कैन का उपयोग किया जाएगा।
- shared_buffers:साझा मेमोरी बफ़र्स के लिए डेटाबेस सर्वर द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को सेट करता है। आमतौर पर अच्छे प्रदर्शन के लिए न्यूनतम से काफी अधिक सेटिंग्स की आवश्यकता होती है।
- temp_buffers:प्रत्येक डेटाबेस सत्र द्वारा उपयोग किए जाने वाले अस्थायी बफ़र्स की अधिकतम संख्या सेट करता है। ये सत्र-स्थानीय बफ़र हैं जिनका उपयोग केवल अस्थायी तालिकाओं तक पहुँच के लिए किया जाता है।
- प्रभावी_io_concurrency:समवर्ती डिस्क I/O संचालन की संख्या सेट करता है जो PostgreSQL को एक साथ निष्पादित होने की उम्मीद है। इस मान को बढ़ाने से I/O संचालन की संख्या में वृद्धि होगी जिसे कोई भी व्यक्तिगत PostgreSQL सत्र समानांतर में आरंभ करने का प्रयास करता है। वर्तमान में, यह सेटिंग केवल बिटमैप हीप स्कैन को प्रभावित करती है।
- max_connections:डेटाबेस सर्वर से समवर्ती कनेक्शन की अधिकतम संख्या निर्धारित करता है। इस पैरामीटर को बढ़ाने से PostgreSQL एक साथ अधिक बैकएंड प्रक्रियाओं को चलाने की अनुमति देता है।
यहां चुनौती यह हो सकती है कि आप यह कैसे जान सकते हैं कि आपको अपने मूडल डेटाबेस को स्केल करने की आवश्यकता है और किस तरह से, और इसका उत्तर मॉनिटरिंग है।
Moodle के लिए PostgreSQL की निगरानी करना
डेटाबेस को स्केल करना एक जटिल प्रक्रिया है, इसलिए आपको इसे मापने के लिए सबसे अच्छी रणनीति निर्धारित करने में सक्षम होने के लिए कुछ मीट्रिक की जांच करनी चाहिए।
आप यह निर्धारित करने के लिए सीपीयू, मेमोरी और डिस्क उपयोग की निगरानी कर सकते हैं कि क्या कुछ कॉन्फ़िगरेशन समस्या है या वास्तव में आपको अपने डेटाबेस को स्केल करने की आवश्यकता है। उदाहरण के लिए, यदि आप एक उच्च सर्वर लोड देख रहे हैं लेकिन डेटाबेस गतिविधि कम है, तो शायद इसे स्केल करने की कोई आवश्यकता नहीं है, आपको केवल अपने हार्डवेयर संसाधनों से मिलान करने के लिए कॉन्फ़िगरेशन पैरामीटर की जांच करने की आवश्यकता है।
प्रति डेटाबेस PostgreSQL नोड द्वारा उपयोग किए जाने वाले डिस्क स्थान की जांच करने से आपको यह पुष्टि करने में मदद मिल सकती है कि आपको अधिक डिस्क या तालिका विभाजन की आवश्यकता है या नहीं। डेटाबेस/टेबल द्वारा उपयोग किए गए डिस्क स्थान की जांच करने के लिए आप कुछ PostgreSQL फ़ंक्शन जैसे pg_database_size या pg_table_size का उपयोग कर सकते हैं।
डेटाबेस की ओर से, आपको जांचना चाहिए:
- कनेक्शन की राशि
- चल रही क्वेरी
- सूचकांक उपयोग
- ब्लोट
- प्रतिकृति अंतराल
यह पुष्टि करने के लिए स्पष्ट मीट्रिक हो सकते हैं कि आपके डेटाबेस के स्केलिंग की आवश्यकता है या नहीं।
एक स्केलिंग और निगरानी प्रणाली के रूप में क्लस्टर नियंत्रण
ClusterControl आपको स्केलिंग के उन दोनों तरीकों से निपटने में मदद कर सकता है जिनका हमने पहले उल्लेख किया था और स्केलिंग आवश्यकता की पुष्टि करने के लिए सभी आवश्यक मेट्रिक्स की निगरानी करने में मदद कर सकता है।
यदि आप अभी तक ClusterControl का उपयोग नहीं कर रहे हैं, तो आप इसे स्थापित कर सकते हैं और "आयात" विकल्प का चयन करके अपने वर्तमान PostgreSQL डेटाबेस को तैनात या आयात कर सकते हैं और बैकअप जैसी सभी क्लस्टर नियंत्रण सुविधाओं का लाभ उठाने के लिए चरणों का पालन कर सकते हैं। स्वचालित विफलता, अलर्ट, निगरानी, और बहुत कुछ।
क्षैतिज स्केलिंग
क्षैतिज स्केलिंग के लिए, यदि आप क्लस्टर क्रियाओं पर जाते हैं और "प्रतिकृति दास जोड़ें" का चयन करते हैं, तो आप या तो खरोंच से एक नई प्रतिकृति बना सकते हैं या प्रतिकृति के रूप में मौजूदा PostgreSQL डेटाबेस जोड़ सकते हैं।
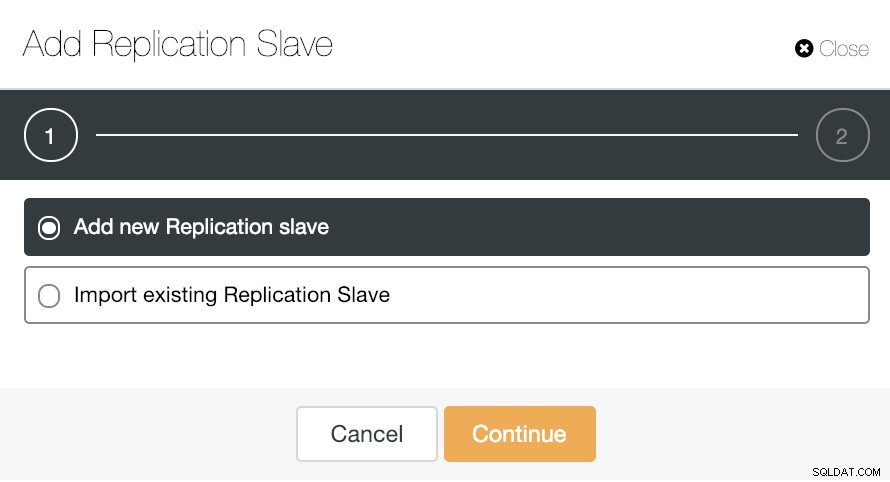
आइए देखते हैं कि कैसे एक नया प्रतिकृति स्लेव जोड़ना वास्तव में एक आसान काम हो सकता है।
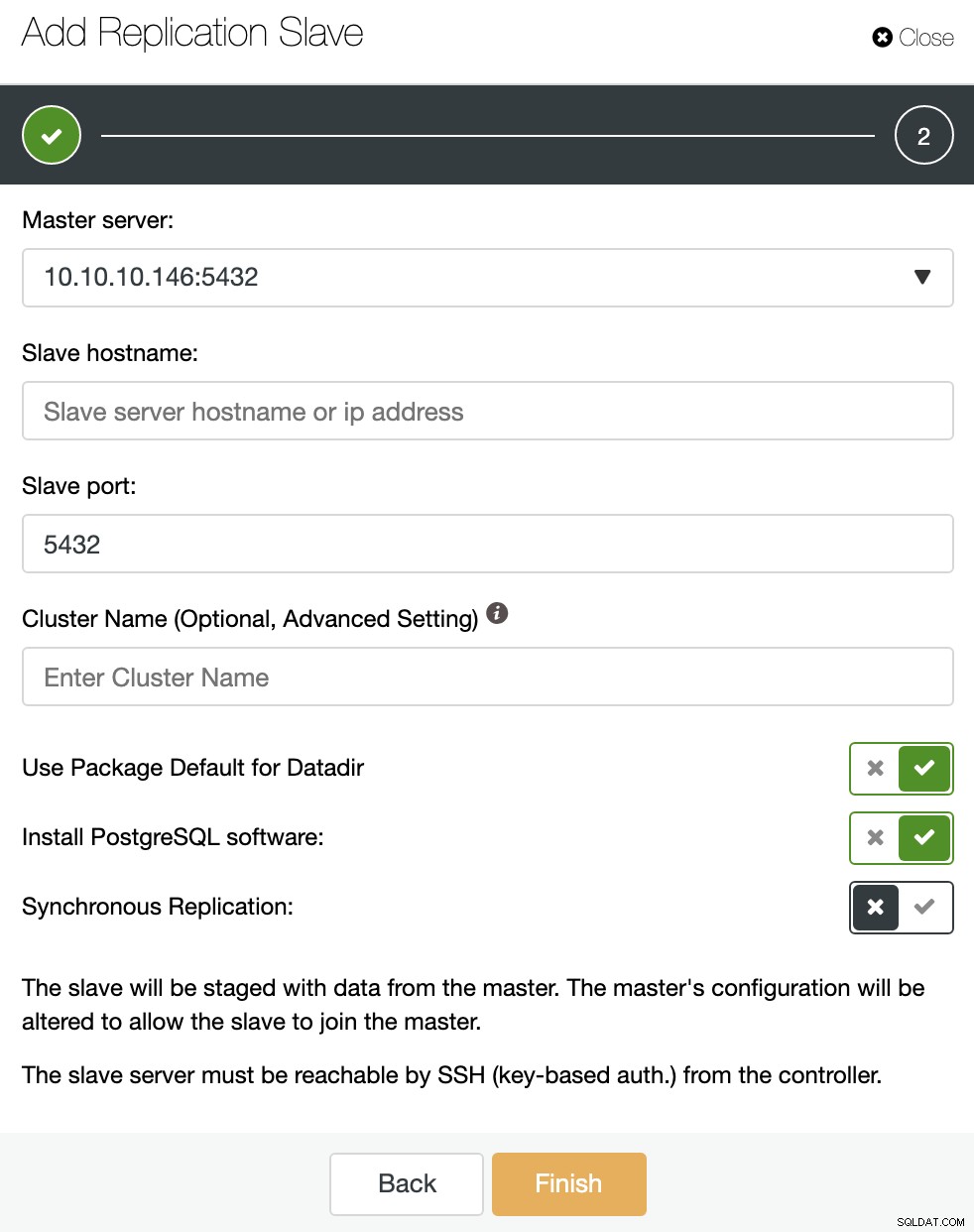
जैसा कि आप इमेज में देख सकते हैं, आपको केवल अपना मास्टर चुनने की आवश्यकता है सर्वर, अपने नए दास सर्वर और डेटाबेस पोर्ट के लिए आईपी पता दर्ज करें। फिर, आप चुन सकते हैं कि क्या आप चाहते हैं कि ClusterControl आपके लिए सॉफ़्टवेयर स्थापित करे और यदि प्रतिकृति स्लेव सिंक्रोनस या एसिंक्रोनस होना चाहिए।
इस तरह, आप जितनी चाहें उतनी प्रतिकृतियां जोड़ सकते हैं और लोड बैलेंसर का उपयोग करके उनके बीच पढ़ने वाले ट्रैफ़िक को फैला सकते हैं, जिसे आप ClusterControl के साथ भी लागू कर सकते हैं।
अब, यदि आप क्लस्टर क्रियाओं पर जाते हैं और "लोड बैलेंसर जोड़ें" का चयन करते हैं, तो आप एक नया HAProxy लोड बैलेंसर तैनात कर सकते हैं या एक मौजूदा जोड़ सकते हैं।
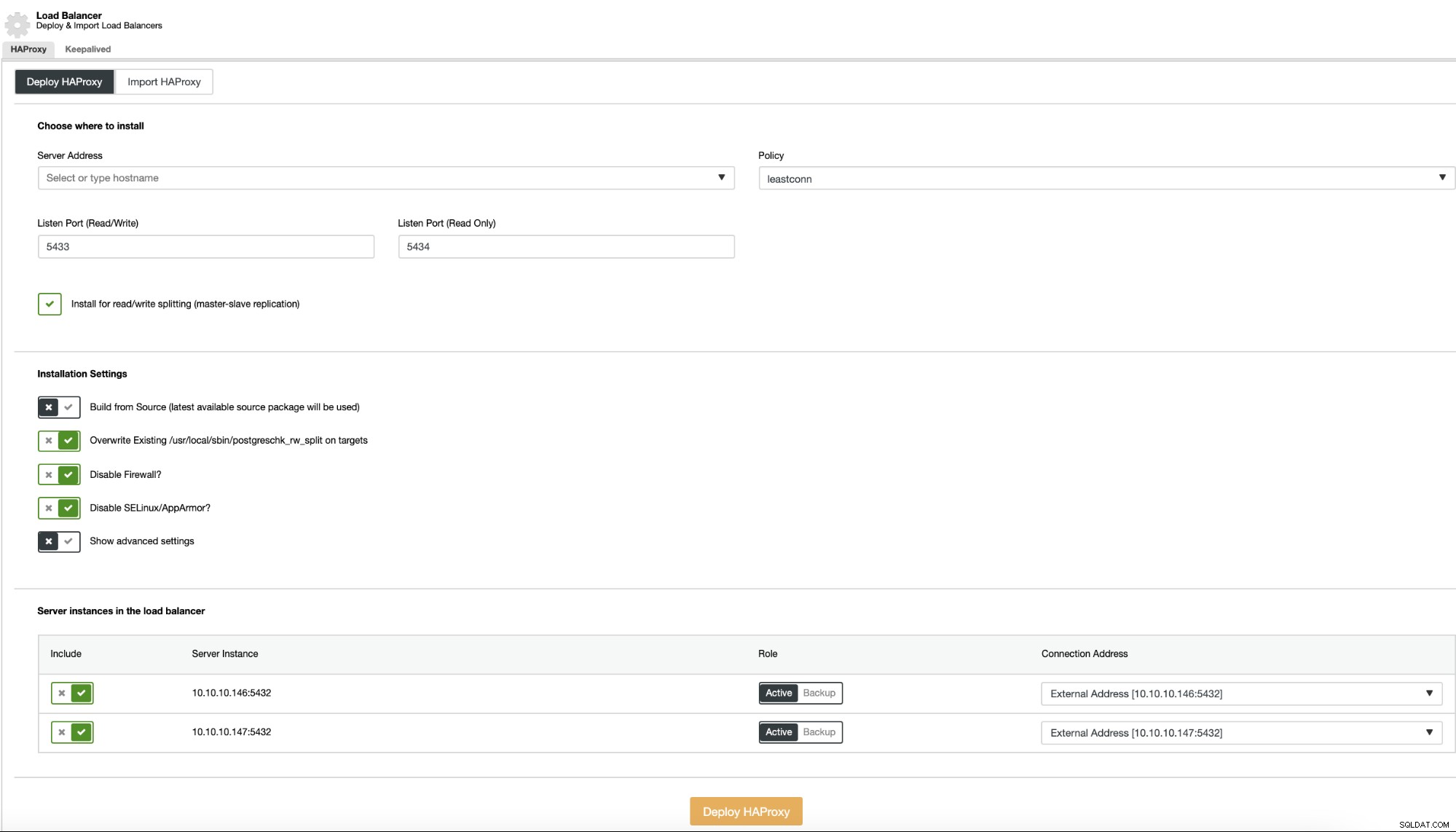
और फिर, उसी लोड बैलेंसर सेक्शन में, आप एक Keepalived जोड़ सकते हैं सेवा जो आपके उच्च उपलब्धता वातावरण को बेहतर बनाने के लिए लोड बैलेंसर नोड्स पर चल रही होगी।
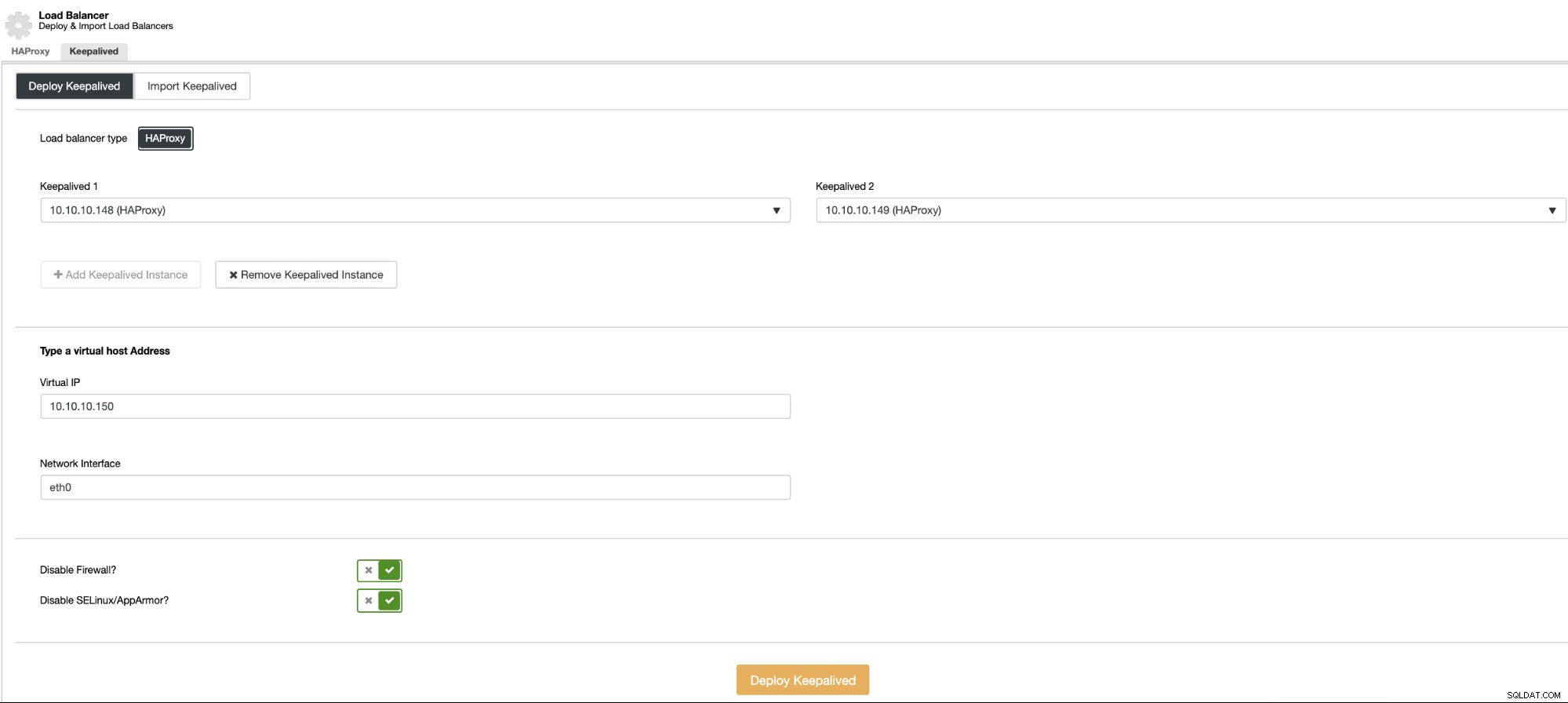
लोड बैलेंसर जोड़ने के बाद या वर्चुअल आईपी का उपयोग करने के बाद जिसमें कीपाइव्ड सर्विस हो नए डेटाबेस एंडपॉइंट का उपयोग करने के लिए आपको अपने मूडल कॉन्फ़िगरेशन को अपडेट करना होगा। इसके लिए, अपने मूडल रूट डायरेक्टरी में जाएं और नए आईपी पते के साथ config.php फाइल को संशोधित करें:
$CFG->dbhost = 'IP_ADDRESS';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'mdluser';
$CFG->dbpass = '********';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbpersist' => 0,
'dbport' => PORT,
'dbsocket' => '',
);सुनिश्चित करें कि आप लोड बैलेंसर या वर्चुअल आईपी पते के माध्यम से अपने डेटाबेस तक पहुंच सकते हैं, या यदि आपको इसे अनुमति देने के लिए अपनी pg_hba.conf PostgreSQL फ़ाइल को अपडेट करने की आवश्यकता है।
वर्टिकल स्केलिंग
लंबवत स्केलिंग के लिए, ClusterControl के साथ आप ऑपरेटिंग सिस्टम और डेटाबेस दोनों तरफ से अपने डेटाबेस नोड्स की निगरानी कर सकते हैं। आप कुछ मेट्रिक्स जैसे CPU उपयोग, मेमोरी, कनेक्शन, शीर्ष क्वेरी, रनिंग क्वेरी, और भी बहुत कुछ देख सकते हैं। आप डैशबोर्ड अनुभाग को भी सक्षम कर सकते हैं, जिससे आप मीट्रिक को अधिक विस्तृत और मित्रवत तरीके से देख सकते हैं।
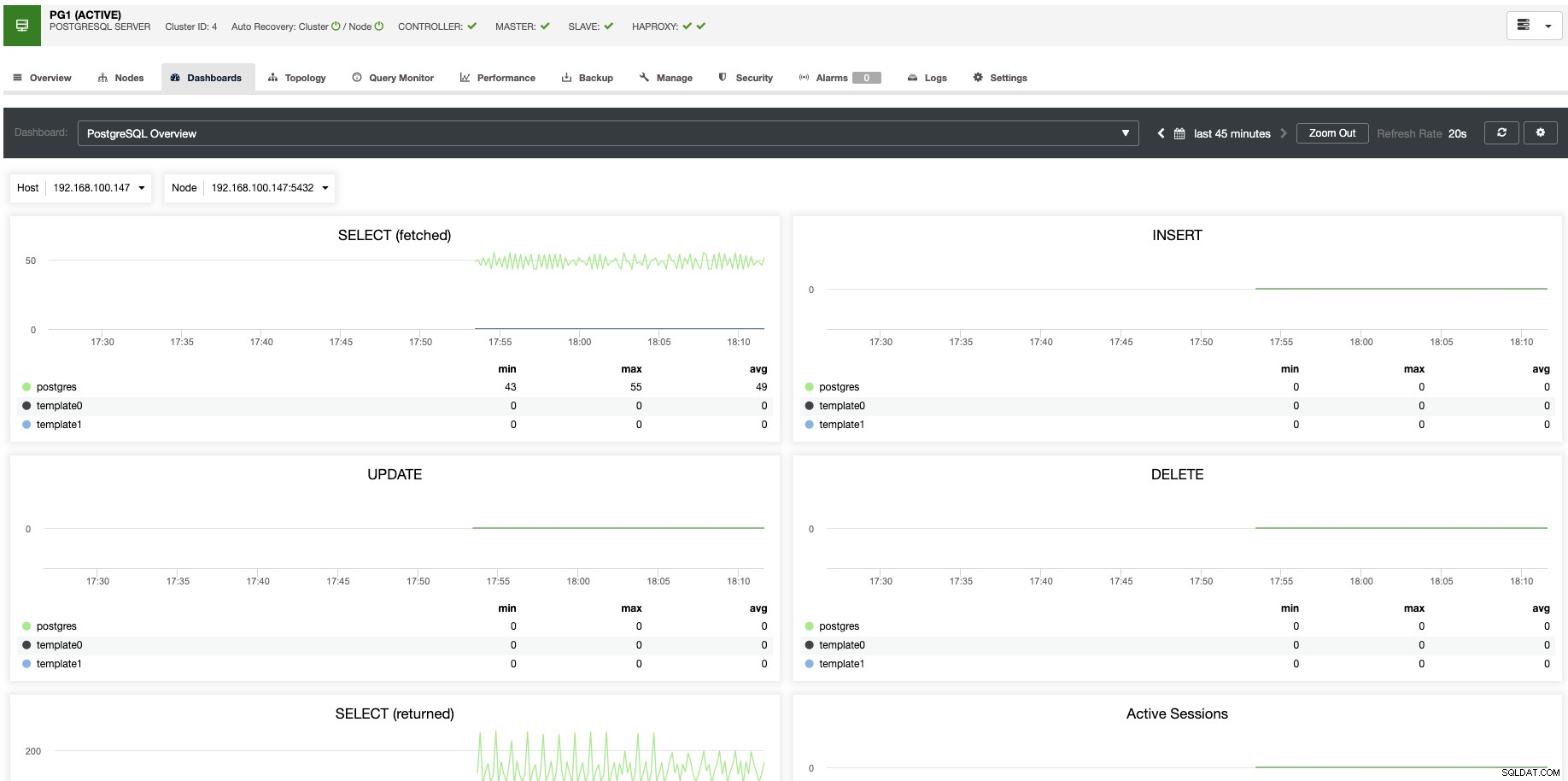
ClusterControl से, आप Reboot Host, Rebuild जैसे विभिन्न प्रबंधन कार्य भी कर सकते हैं एक क्लिक के साथ प्रतिकृति दास, या दास को बढ़ावा दें।
निष्कर्ष
अपने मूडल पोस्टग्रेएसक्यूएल डेटाबेस को स्केल करना एक कठिन काम हो सकता है क्योंकि आपको यह जानना होगा कि आपको सिस्टम को प्रभावित किए बिना कैसे स्केल करना है और इसे कैसे करना है। एक अच्छी निगरानी प्रणाली का होना यह जानने के लिए पहला कदम है कि आपको अपने मूडल डेटाबेस को कब और कैसे स्केल करने की आवश्यकता है। लोड बैलेंसर जोड़ने से आपको अनावश्यक डाउनटाइम से बचने में मदद मिलेगी और यह आपके एलएमएस वातावरण में उच्च उपलब्धता में भी सुधार करेगा।
इन सभी चीजों का हमने उल्लेख किया है जो ClusterControl का उपयोग करके किया जा सकता है जिससे काम आसान हो जाएगा। ClusterControl निगरानी, चेतावनी, स्वचालित फ़ेलओवर, बैकअप, पॉइंट-इन-टाइम पुनर्प्राप्ति, बैकअप सत्यापन, स्केलिंग, और बहुत कुछ जैसी सुविधाओं की एक पूरी श्रृंखला प्रदान करता है।