विभाजन एक SQL सर्वर सुविधा है जिसे अक्सर प्रबंधनीयता, रखरखाव कार्यों, या लॉकिंग और ब्लॉकिंग से संबंधित चुनौतियों को कम करने के लिए लागू किया जाता है। विभाजन के साथ बड़ी तालिकाओं का प्रशासन आसान हो सकता है, और यह मापनीयता और उपलब्धता में सुधार कर सकता है। इसके अलावा, विभाजन के उप-उत्पाद को क्वेरी प्रदर्शन में सुधार किया जा सकता है। यह कोई गारंटी या दिया हुआ नहीं है, और यह विभाजन को लागू करने का प्रेरक कारण नहीं है, लेकिन जब आप एक बड़ी तालिका का विभाजन करते हैं तो यह समीक्षा के लायक है।
पृष्ठभूमि
एक त्वरित समीक्षा के रूप में, SQL सर्वर विभाजन सुविधा केवल एंटरप्राइज़ और डेवलपर संस्करणों में उपलब्ध है। विभाजन को प्रारंभिक डेटाबेस डिज़ाइन के दौरान कार्यान्वित किया जा सकता है, या किसी तालिका में पहले से ही डेटा होने के बाद इसे लागू किया जा सकता है। समझें कि डेटा के साथ मौजूदा तालिका को विभाजित तालिका में बदलना हमेशा तेज़ और सरल नहीं होता है, लेकिन अच्छी योजना के साथ यह काफी व्यवहार्य है और लाभ जल्दी से महसूस किए जा सकते हैं।
एक विभाजित तालिका वह है जहां डेटा को एक विशिष्ट कॉलम के मूल्य के आधार पर छोटी भौतिक संरचनाओं में विभाजित किया जाता है (जिसे विभाजन कॉलम कहा जाता है, जिसे विभाजन फ़ंक्शन में परिभाषित किया जाता है)। यदि आप वर्ष के आधार पर डेटा को अलग करना चाहते हैं, तो आप विभाजन कॉलम के रूप में डेटसोल्ड नामक कॉलम का उपयोग कर सकते हैं, और 2013 के सभी डेटा एक संरचना में रहेंगे, 2012 के लिए सभी डेटा एक अलग संरचना में रहेंगे, आदि। डेटा के ये अलग सेट केंद्रित रखरखाव की अनुमति दें (आप संपूर्ण अनुक्रमणिका के बजाय किसी अनुक्रमणिका के केवल एक विभाजन का पुनर्निर्माण कर सकते हैं) और डेटा को शीघ्रता से जोड़ने और निकालने की अनुमति दें क्योंकि यह तालिका में वास्तव में जोड़े जाने या उससे हटाए जाने से पहले ही मंचित किया जा सकता है।
सेटअप
एक विभाजित बनाम एक गैर-विभाजित तालिका के लिए क्वेरी प्रदर्शन में अंतर की जांच करने के लिए, मैंने AdventureWorks2012 डेटाबेस से Sales.SalesOrderHeader तालिका की दो प्रतियां बनाईं। गैर-विभाजित तालिका केवल SalesOrderID पर एक संकुल अनुक्रमणिका के साथ बनाई गई थी, जो तालिका के लिए पारंपरिक प्राथमिक कुंजी है। दूसरी तालिका को ऑर्डरडेट पर विभाजित किया गया था, ऑर्डरडेट और सेल्सऑर्डरआईडी को क्लस्टरिंग कुंजी के रूप में, और कोई अतिरिक्त अनुक्रमणिका नहीं थी। ध्यान दें कि विभाजन के लिए किस कॉलम का उपयोग करना है, यह तय करते समय विचार करने के लिए कई कारक हैं। अक्सर विभाजन, लेकिन निश्चित रूप से हमेशा नहीं, विभाजन सीमाओं को परिभाषित करने के लिए दिनांक फ़ील्ड का उपयोग करता है। इस प्रकार, इस उदाहरण के लिए ऑर्डरडेट का चयन किया गया था, और नमूना क्वेरी का उपयोग SalesOrderHeader तालिका के विरुद्ध विशिष्ट गतिविधि को अनुकरण करने के लिए किया गया था। दोनों टेबल बनाने और भरने के लिए स्टेटमेंट यहां डाउनलोड किए जा सकते हैं।
टेबल बनाने और डेटा जोड़ने के बाद, मौजूदा इंडेक्स को सत्यापित किया गया और फिर फुलस्कैन के साथ आंकड़े अपडेट किए गए:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader';GOEXEC sp_helpindex 'Sales.Part_SalesOrderHeader';जाओ अद्यतन आँकड़े [बिक्री]। '।' + so.name AS [तालिका], ss.name AS [सांख्यिकी], sp.last_updated AS [आंकड़े अंतिम अद्यतन], sp.rows AS [पंक्तियाँ], sp.rows_sampled AS [पंक्तियाँ नमूना], sp.modification_counter AS [पंक्ति संशोधन] sys.stats AS ssINNER JOIN sys.objects as so ss.[object_id] =so.[object_id]INNER JOIN sys.schemas AS sch ON इसलिए। (so.[object_id], ss.stats_id) जहां भी ऐसा हो।>इसके अलावा, दोनों तालिकाओं में डेटा का सटीक समान वितरण और न्यूनतम विखंडन होता है।
एक साधारण क्वेरी के लिए प्रदर्शन
किसी भी अतिरिक्त अनुक्रमणिका को जोड़ने से पहले, दिसंबर 2012 में दिए गए आदेशों के लिए बिक्री व्यक्ति द्वारा अर्जित कुल योग की गणना करने के लिए दोनों तालिकाओं के विरुद्ध एक मूल क्वेरी निष्पादित की गई थी:
चुनें [SalesPersonID], SUM([TotalDue])FROM [Sales].[Big_SalesOrderHeader]कहां [आदेश दिनांक] '2012-12-01' और '2012-12-31' के बीच [SalesPersonID] समूह; चयन करें [सेल्सपर्सनआईडी], एसयूएम([टोटलड्यू])फ्रॉम [सेल्स]। सांख्यिकी आईओ आउटपुटटेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
टेबल 'बिग_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 2710440, फिजिकल रीड्स 2226, रीड-फॉरवर्ड रीड्स 2658769, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0.टेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
टेबल 'पार्ट_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 248128, फिजिकल रीड्स 3, रीड-फॉरवर्ड रीड्स 245030, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
दिसंबर के लिए बिक्री व्यक्ति द्वारा कुल - गैर-विभाजित तालिका
दिसंबर के लिए सेल्स पर्सन द्वारा कुल - विभाजित तालिकाजैसा कि अपेक्षित था, गैर-विभाजित तालिका के विरुद्ध क्वेरी को तालिका का पूर्ण स्कैन करना पड़ा क्योंकि इसका समर्थन करने के लिए कोई अनुक्रमणिका नहीं थी। इसके विपरीत, विभाजित तालिका के विरुद्ध क्वेरी केवल तालिका के एक विभाजन तक पहुँचने के लिए आवश्यक है।
निष्पक्ष होने के लिए, यदि यह अलग-अलग दिनांक सीमाओं के साथ बार-बार निष्पादित की गई क्वेरी थी, तो उपयुक्त गैर-संकुल सूचकांक मौजूद होगा। उदाहरण के लिए:
गैर-अनुक्रमित अनुक्रमणिका बनाएं [Big_SalesOrderHeader_SalesPersonID] [बिक्री] पर।[Big_SalesOrderHeader] ([OrderDate]) शामिल करें ([SalesPersonID], [TotalDue]);इस अनुक्रमणिका के निर्माण के साथ, जब क्वेरी को फिर से निष्पादित किया जाता है, तो I/O आँकड़े गिर जाते हैं और योजना गैर-संकुलित अनुक्रमणिका का उपयोग करने के लिए बदल जाती है:
सांख्यिकी आईओ आउटपुटटेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
टेबल 'बिग_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 42901, फिजिकल रीड्स 3, रीड-फॉरवर्ड रीड्स 42346, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
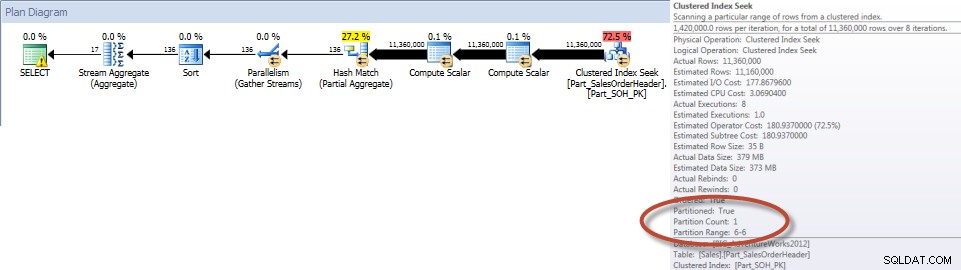
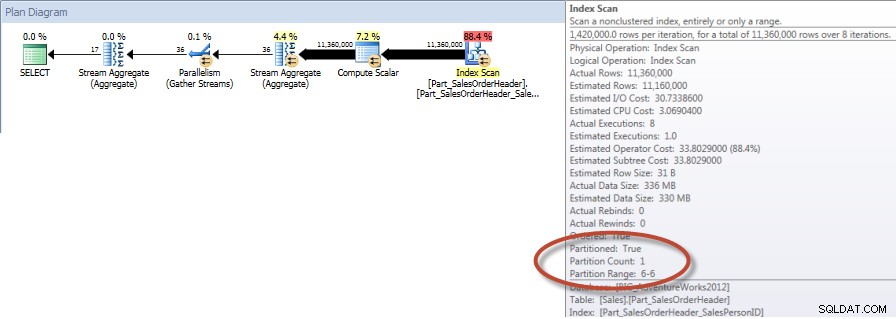
दिसंबर के लिए सेल्स पर्सन द्वारा कुल योग - गैर-विभाजित तालिका पर NCIसपोर्टिंग इंडेक्स के साथ, Sales.Big_SalesOrderHeader के खिलाफ क्वेरी को Sales.Part_SalesOrderHeader के खिलाफ क्लस्टर किए गए इंडेक्स स्कैन की तुलना में काफी कम रीड्स की आवश्यकता होती है, जो अप्रत्याशित नहीं है क्योंकि क्लस्टर्ड इंडेक्स बहुत व्यापक है। यदि हम Sales.Part_SalesOrderHeader के लिए एक तुलनीय गैर-संकुल अनुक्रमणिका बनाते हैं, तो हम समान I/O संख्याएँ देखते हैं:
गैर-अनुक्रमित अनुक्रमणिका बनाएं [Part_SalesOrderHeader_SalesPersonID] [बिक्री] पर।[Part_SalesOrderHeader]([SalesPersonID]) शामिल करें ([TotalDue]);सांख्यिकी आईओ आउटपुटतालिका 'Part_SalesOrderHeader'। स्कैन काउंट 9, लॉजिकल रीड्स 42894, फिजिकल रीड्स 1, रीड-फॉरवर्ड रीड्स 42378, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
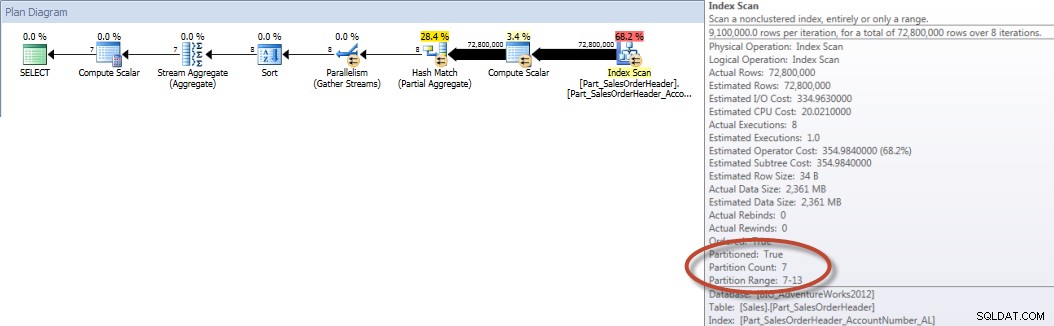
दिसंबर के लिए सेल्स पर्सन द्वारा कुल योग - एलिमिनेशन के साथ विभाजित टेबल पर NCIऔर अगर हम गैर-संकुल सूचकांक स्कैन के गुणों को देखें, तो हम यह सत्यापित कर सकते हैं कि इंजन ने केवल एक विभाजन (6) का उपयोग किया है।
जैसा कि मूल रूप से कहा गया है, विभाजन को आमतौर पर प्रदर्शन में सुधार के लिए लागू नहीं किया जाता है। ऊपर दिखाए गए उदाहरण में, जब तक उपयुक्त गैर-संकुल अनुक्रमणिका मौजूद है, तब तक विभाजित तालिका के विरुद्ध क्वेरी काफ़ी बेहतर प्रदर्शन नहीं करती है।
तदर्थ क्वेरी के लिए प्रदर्शन
विभाजित तालिका के विरुद्ध एक प्रश्न कर सकते हैं कुछ मामलों में गैर-विभाजित तालिका के विरुद्ध समान क्वेरी से बेहतर प्रदर्शन करें, उदाहरण के लिए जब क्वेरी को संकुल अनुक्रमणिका का उपयोग करना होता है। हालांकि गैर-संकुल अनुक्रमित द्वारा समर्थित अधिकांश प्रश्नों के लिए आदर्श है, कुछ सिस्टम उपयोगकर्ताओं से तदर्थ प्रश्नों की अनुमति देते हैं, और अन्य के पास ऐसे प्रश्न होते हैं जो इतनी बार चल सकते हैं कि वे सहायक अनुक्रमणिका की गारंटी नहीं देते हैं। SalesOrderHeader तालिका के विरुद्ध, एक उपयोगकर्ता दिसंबर 2012 से ऑर्डर खोजने के लिए निम्न क्वेरी चला सकता है, जिसे वर्ष के अंत तक शिप करने की आवश्यकता होती है, लेकिन ग्राहकों के एक विशेष समूह के लिए और $1000 से अधिक की TotalDue के साथ नहीं:
चुनें[सेल्सऑर्डरआईडी],[ऑर्डरडेट],[ड्यूडेट],[शिपडेट],[अकाउंट नंबर],[कस्टमरआईडी],[सेल्सपर्सनआईडी],[सबटोटल],[टोटलड्यू]फ्रॉम [सेल्स]।[बिग_सेल्सऑर्डरहैडर]जहां [टोटलड्यू ]> 1000और [ग्राहक आईडी] के बीच 10000 और 20000और [आदेश दिनांक] के बीच '2012-12-01' और '2012-12-31' और [नियत दिनांक] <'2012-12-31' और [शिपडेट]> '2012-12 -31';जाओ चुनें[सेल्सऑर्डरआईडी],[ऑर्डरडेट],[ड्यूडेट],[शिपडेट],[खाता नंबर],[ग्राहक आईडी],[सेल्सपर्सनआईडी],[सबटोटल],[टोटलड्यू]फ्रॉम [सेल्स]।[पार्ट_सेल्सऑर्डरहेडर]कहां [कुल देय]> 1000 और [ग्राहक आईडी] 10000 और 20000 और [आदेश दिनांक] के बीच '2012-12-01' और '2012-12-31' और [देय तिथि] <'2012-12-31' और [शिपडेट]> '2012 -12-31';जाओसांख्यिकी आईओ आउटपुटतालिका 'बिग_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 2711220, फिजिकल रीड्स 8386, रीड-फॉरवर्ड रीड्स 2662400, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
टेबल 'पार्ट_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 248128, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 243792, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
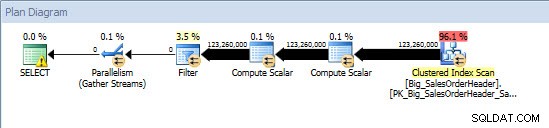
तदर्थ क्वेरी - गैर-विभाजित तालिका
तदर्थ क्वेरी - विभाजन तालिकागैर-विभाजित तालिका के खिलाफ क्वेरी को क्लस्टर इंडेक्स के खिलाफ एक पूर्ण स्कैन की आवश्यकता होती है, लेकिन विभाजित तालिका के खिलाफ, क्वेरी ने क्लस्टर इंडेक्स की एक इंडेक्स खोज की, क्योंकि इंजन ने विभाजन उन्मूलन का उपयोग किया और केवल उस डेटा को पढ़ा जिसकी बिल्कुल आवश्यकता थी। इस उदाहरण में, यह I/O के संदर्भ में एक महत्वपूर्ण अंतर है, और हार्डवेयर के आधार पर, निष्पादन समय में एक नाटकीय अंतर हो सकता है। उपयुक्त अनुक्रमणिका जोड़कर क्वेरी को अनुकूलित किया जा सकता है, लेकिन आमतौर पर प्रत्येक के लिए अनुक्रमणित करना संभव नहीं है एकल सवाल। विशेष रूप से, तदर्थ प्रश्नों की अनुमति देने वाले समाधानों के लिए, यह कहना उचित होगा कि आप कभी नहीं जानते कि उपयोगकर्ता क्या करने जा रहे हैं। एक क्वेरी एक बार चल सकती है और फिर कभी नहीं चल सकती है, और तथ्य के बाद एक इंडेक्स बनाना व्यर्थ है। इसलिए, गैर-विभाजित तालिका से विभाजित तालिका में बदलते समय, नियमित अनुक्रमणिका ट्यूनिंग के समान प्रयास और दृष्टिकोण को लागू करना महत्वपूर्ण है; आप सत्यापित करना चाहते हैं कि अधिकांश प्रश्नों का समर्थन करने के लिए उपयुक्त अनुक्रमणिका मौजूद हैं।
प्रदर्शन और अनुक्रमणिका संरेखण
विभाजित तालिका के लिए अनुक्रमणिका बनाते समय विचार करने के लिए एक अतिरिक्त कारक यह है कि अनुक्रमणिका को संरेखित करना है या नहीं। यदि आप विभाजन के अंदर और बाहर डेटा स्विच करने की योजना बना रहे हैं तो अनुक्रमणिका को तालिका के साथ संरेखित किया जाना चाहिए। विभाजित तालिका पर एक गैर-संकुल अनुक्रमणिका बनाना डिफ़ॉल्ट रूप से एक संरेखित अनुक्रमणिका बनाता है, जहां विभाजन स्तंभ को अनुक्रमणिका में शामिल स्तंभ के रूप में जोड़ा जाता है।
एक अलग विभाजन योजना या एक अलग फ़ाइल समूह को निर्दिष्ट करके एक गैर-संरेखित सूचकांक बनाया जाता है। विभाजन स्तंभ एक प्रमुख स्तंभ या सम्मिलित स्तंभ के रूप में अनुक्रमणिका का भाग हो सकता है, लेकिन यदि तालिका की विभाजन योजना का उपयोग नहीं किया जाता है, या किसी भिन्न फ़ाइल समूह का उपयोग किया जाता है, तो अनुक्रमणिका संरेखित नहीं होगी।
एक संरेखित सूचकांक को तालिका की तरह ही विभाजित किया जाता है - डेटा अलग-अलग संरचनाओं में मौजूद होगा - और इसलिए विभाजन उन्मूलन हो सकता है। एक असंरेखित सूचकांक एक भौतिक संरचना के रूप में मौजूद है, और विधेय के आधार पर एक क्वेरी के लिए अपेक्षित लाभ प्रदान नहीं कर सकता है। एक ऐसी क्वेरी पर विचार करें जो महीने के आधार पर समूहीकृत खाता संख्या के आधार पर बिक्री की गणना करती है:
चुनें DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) from [Sales].[Part_SalesOrderHeader]जहां [OrderDate] '2013-01-01' और '2013-07-31' ग्रुप बाय DATEPART (MONTH,[OrderDate]) DATEPART द्वारा ऑर्डर (MONTH,[OrderDate]);यदि आप विभाजन से परिचित नहीं हैं, तो आप क्वेरी का समर्थन करने के लिए इस तरह एक अनुक्रमणिका बना सकते हैं (ध्यान दें कि प्राथमिक फ़ाइल समूह निर्दिष्ट है):
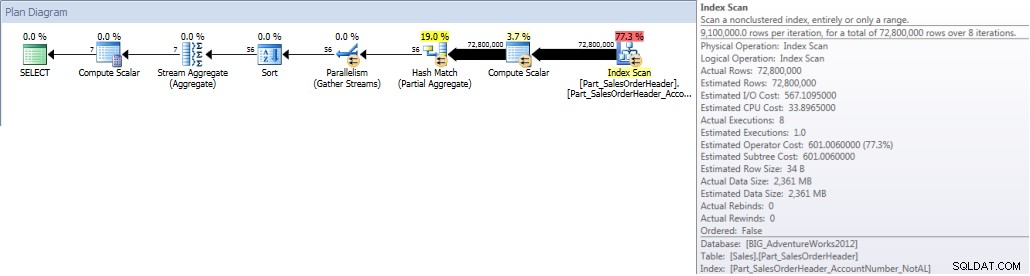
गैर-अनुक्रमित अनुक्रमणिका बनाएं [Part_SalesOrderHeader_AccountNumber_NotAL]ON [Sales].[Part_SalesOrderHeader]([AccountNumber])ON [PRIMARY];यह इंडेक्स संरेखित नहीं है, भले ही इसमें ऑर्डरडेट शामिल है क्योंकि यह प्राथमिक कुंजी का हिस्सा है। यदि हम एक संरेखित अनुक्रमणिका बनाते हैं तो कॉलम भी शामिल होते हैं, लेकिन सिंटैक्स में अंतर पर ध्यान दें:
गैर-अनुक्रमित अनुक्रमणिका बनाएं [Part_SalesOrderHeader_AccountNumber_AL]ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);किम्बर्ली ट्रिप के sp_helpindex का उपयोग करके हम यह सत्यापित कर सकते हैं कि अनुक्रमणिका में कौन से स्तंभ मौजूद हैं:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader';
sp_helpindex for Sales.Part_SalesOrderHeaderजब हम अपनी क्वेरी चलाते हैं और उसे गैर-संरेखित अनुक्रमणिका का उपयोग करने के लिए बाध्य करते हैं, तो संपूर्ण अनुक्रमणिका स्कैन की जाती है। भले ही ऑर्डरडेट इंडेक्स का हिस्सा है, यह अग्रणी कॉलम नहीं है, इसलिए इंजन को यह देखने के लिए प्रत्येक अकाउंट नंबर के लिए ऑर्डरडेट मान की जांच करनी होगी कि क्या यह 1 जनवरी 2013 और 31 जुलाई 2013 के बीच आता है:
चुनें DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL]))जहां [ऑर्डरडेट-01-01' के बीच ' 2013-07-31'डेटपार्ट द्वारा ग्रुप(महीना,[ऑर्डरडेट])डेटपार्ट द्वारा ऑर्डर(महीना,[ऑर्डरडेट]);सांख्यिकी आईओ आउटपुटटेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
टेबल 'पार्ट_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 786861, फिजिकल रीड्स 1, रीड-फॉरवर्ड रीड्स 770929, लोब लॉजिकल रीड्स 0, लॉब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0.
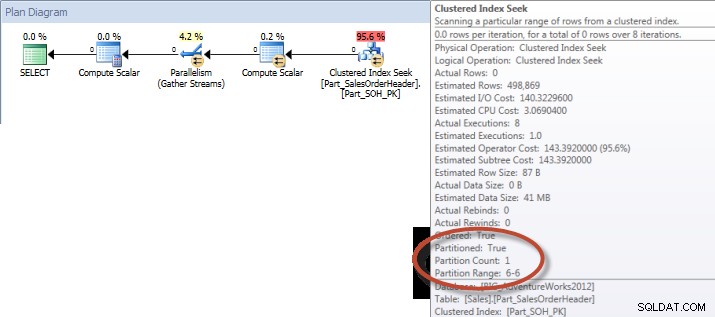
माह के हिसाब से खाता योग (जनवरी-जुलाई 2013) गैर- संरेखित NCI (मजबूर)इसके विपरीत, जब क्वेरी को संरेखित इंडेक्स का उपयोग करने के लिए मजबूर किया जाता है, तो विभाजन उन्मूलन का उपयोग किया जा सकता है, और कम I/Os की आवश्यकता होती है, भले ही ऑर्डरडेट इंडेक्स में अग्रणी कॉलम न हो।
चुनें DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])FROM [Sales]। 2013-07-31'डेटपार्ट द्वारा ग्रुप(महीना,[ऑर्डरडेट])डेटपार्ट द्वारा ऑर्डर(महीना,[ऑर्डरडेट]);सांख्यिकी आईओ आउटपुटटेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
टेबल 'पार्ट_सेल्सऑर्डरहेडर'। स्कैन काउंट 9, लॉजिकल रीड्स 456258, फिजिकल रीड्स 16, रीड-फॉरवर्ड रीड्स 453241, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
संरेखित NCI का उपयोग करते हुए माह (जनवरी-जुलाई 2013) के अनुसार खाता योग (मजबूर)सारांश
विभाजन को लागू करने का निर्णय वह है जिस पर उचित विचार और योजना की आवश्यकता होती है। प्रबंधन में आसानी, बेहतर मापनीयता और उपलब्धता, और अवरोधन में कमी, विभाजन तालिकाओं के सामान्य कारण हैं। क्वेरी प्रदर्शन में सुधार करना विभाजन को नियोजित करने का एक कारण नहीं है, हालांकि यह कुछ मामलों में एक लाभकारी दुष्प्रभाव हो सकता है। प्रदर्शन के संदर्भ में, यह सुनिश्चित करना महत्वपूर्ण है कि आपकी कार्यान्वयन योजना में क्वेरी प्रदर्शन की समीक्षा शामिल है। पुष्टि करें कि आपकी अनुक्रमणिका बाद . के बाद आपके प्रश्नों का उचित समर्थन करना जारी रखेगी तालिका को विभाजित किया गया है, और सत्यापित करें कि क्लस्टर और गैर-संकुल अनुक्रमणिका का उपयोग करने वाली क्वेरीज़ जहां लागू हो, विभाजन उन्मूलन से लाभान्वित होती हैं।