परिचय
इस ट्यूटोरियल में SQL (DDL, DML) के बारे में जानकारी शामिल है जो मैंने अपने पेशेवर जीवन के दौरान एकत्र की है। डेटाबेस के साथ काम करते समय आपको यह न्यूनतम जानने की आवश्यकता है। यदि जटिल एसक्यूएल निर्माणों का उपयोग करने की आवश्यकता है, तो आमतौर पर मैं एमएसडीएन पुस्तकालय सर्फ करता हूं, जो आसानी से इंटरनेट पर पाया जा सकता है। मेरे ख्याल से सब कुछ अपने दिमाग में रखना बहुत मुश्किल है और वैसे, इसकी कोई जरूरत नहीं है। मेरा सुझाव है कि आपको Oracle, MySQL और Firebird जैसे अधिकांश रिलेशनल डेटाबेस में उपयोग किए जाने वाले सभी मुख्य निर्माणों के बारे में पता होना चाहिए। फिर भी, वे डेटा प्रकारों में भिन्न हो सकते हैं। उदाहरण के लिए, वस्तुओं (तालिकाओं, बाधाओं, अनुक्रमित, आदि) को बनाने के लिए, आप डेटाबेस के साथ काम करने के लिए बस एकीकृत विकास वातावरण (आईडीई) का उपयोग कर सकते हैं और किसी विशेष डेटाबेस प्रकार (एमएस एसक्यूएल, ओरेकल) के लिए दृश्य उपकरणों का अध्ययन करने की कोई आवश्यकता नहीं है। , MySQL, फायरबर्ड, आदि)। यह सुविधाजनक है क्योंकि आप पूरे पाठ को देख सकते हैं, और आपको बनाने के लिए कई टैब देखने की आवश्यकता नहीं है, उदाहरण के लिए, एक सूचकांक या एक बाधा। यदि आप डेटाबेस के साथ लगातार काम कर रहे हैं, तो स्क्रिप्ट का उपयोग करके किसी ऑब्जेक्ट को बनाना, संशोधित करना और विशेष रूप से पुनर्निर्माण करना विज़ुअल मोड की तुलना में बहुत तेज़ है। इसके अलावा, मेरी राय में, स्क्रिप्ट मोड में (उचित सटीकता के साथ), वस्तुओं के नामकरण के लिए नियमों को निर्दिष्ट करना और नियंत्रित करना आसान है। इसके अलावा, स्क्रिप्ट का उपयोग करना सुविधाजनक होता है जब आपको डेटाबेस परिवर्तनों को परीक्षण डेटाबेस से उत्पादन डेटाबेस में स्थानांतरित करने की आवश्यकता होती है।
SQL को कई भागों में बांटा गया है। अपने लेख में, मैं सबसे महत्वपूर्ण लोगों की समीक्षा करूँगा:
डीडीएल - डेटा परिभाषा भाषा
डीएमएल - डेटा हेरफेर भाषा, जिसमें निम्नलिखित निर्माण शामिल हैं:
- चुनें - डेटा चयन
- INSERT - नया डेटा प्रविष्टि
- अपडेट करें - डेटा अपडेट
- हटाएं - डेटा हटाना
- MERGE - डेटा मर्जिंग
मैं अध्ययन के मामलों में सभी निर्माणों की व्याख्या करूंगा। इसके अलावा, मुझे लगता है कि बेहतर समझ के लिए एक प्रोग्रामिंग भाषा, विशेष रूप से एसक्यूएल का अभ्यास में अध्ययन किया जाना चाहिए।
यह एक चरण-दर-चरण ट्यूटोरियल है, जहाँ आपको इसे पढ़ते समय उदाहरण प्रस्तुत करने की आवश्यकता होती है। हालांकि, अगर आपको कमांड को विवरण में जानना है, तो इंटरनेट पर सर्फ करें, उदाहरण के लिए, एमएसडीएन।
इस ट्यूटोरियल को बनाते समय, मैंने स्क्रिप्ट निष्पादित करने के लिए MS SQL सर्वर डेटाबेस, संस्करण 2014 और MS SQL सर्वर प्रबंधन स्टूडियो (SSMS) का उपयोग किया है।
संक्षेप में इसके बारे में MS SQL सर्वर प्रबंधन स्टूडियो (SSMS)
SQL सर्वर प्रबंधन स्टूडियो (SSMS) डेटाबेस घटकों को कॉन्फ़िगर करने, प्रबंधित करने और प्रशासित करने के लिए Microsoft SQL सर्वर उपयोगिता है। इसमें एक स्क्रिप्ट संपादक और एक ग्राफिक्स प्रोग्राम शामिल है जो सर्वर ऑब्जेक्ट्स और सेटिंग्स के साथ काम करता है। SQL सर्वर प्रबंधन स्टूडियो का मुख्य उपकरण ऑब्जेक्ट एक्सप्लोरर है, जो उपयोगकर्ता को सर्वर ऑब्जेक्ट को देखने, पुनर्प्राप्त करने और प्रबंधित करने की अनुमति देता है। यह पाठ आंशिक रूप से विकिपीडिया से लिया गया है।
नया स्क्रिप्ट संपादक बनाने के लिए, नई क्वेरी बटन का उपयोग करें:
वर्तमान डेटाबेस से स्विच करने के लिए, आप ड्रॉप-डाउन मेनू का उपयोग कर सकते हैं:
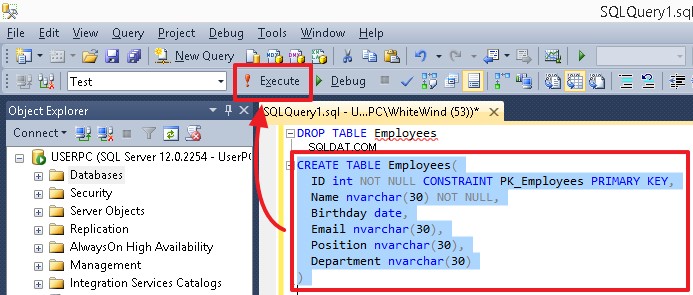
किसी विशेष कमांड या कमांड के सेट को निष्पादित करने के लिए, उसे हाइलाइट करें और एक्ज़िक्यूट बटन या F5 दबाएं। यदि संपादक में केवल एक कमांड है या आपको सभी कमांड निष्पादित करने की आवश्यकता है, तो कुछ भी हाइलाइट न करें।
ऑब्जेक्ट्स (टेबल, कॉलम, इंडेक्स) बनाने वाली स्क्रिप्ट निष्पादित करने के बाद, संबंधित ऑब्जेक्ट (उदाहरण के लिए, टेबल्स या कॉलम) का चयन करें और फिर परिवर्तन देखने के लिए शॉर्टकट मेनू पर रीफ्रेश करें क्लिक करें।
दरअसल, यहां दिए गए उदाहरणों को निष्पादित करने के लिए आपको बस इतना ही जानना होगा।
सिद्धांत
एक रिलेशनल डेटाबेस एक साथ जुड़े तालिकाओं का एक सेट है। सामान्य तौर पर, डेटाबेस एक फ़ाइल होती है जो संरचित डेटा को संग्रहीत करती है।
डेटाबेस प्रबंधन प्रणाली (DBMS) विशेष डेटाबेस प्रकारों (MS SQL, Oracle, MySQL, Firebird, आदि) के साथ काम करने के लिए उपकरणों का एक सेट है।
नोट: जैसा कि हमारे दैनिक जीवन में, हम कहते हैं "ओरेकल डीबी" या सिर्फ "ओरेकल" जिसका वास्तव में अर्थ है "ओरेकल डीबीएमएस", तो इस ट्यूटोरियल में, मैं "डेटाबेस" शब्द का उपयोग करूंगा।
एक तालिका स्तंभों का एक समूह है। बहुत बार, आप इन शब्दों की निम्नलिखित परिभाषाएँ सुन सकते हैं:फ़ील्ड, पंक्तियाँ और रिकॉर्ड, जिसका अर्थ एक ही होता है।
एक तालिका संबंधपरक डेटाबेस का मुख्य उद्देश्य है। सभी डेटा तालिका स्तंभों में पंक्ति दर पंक्ति संग्रहीत किया जाता है।
प्रत्येक तालिका के साथ-साथ उसके स्तंभों के लिए, आपको एक नाम निर्दिष्ट करना होगा, जिसके अनुसार आप एक आवश्यक वस्तु पा सकते हैं।
ऑब्जेक्ट के नाम, टेबल, कॉलम और इंडेक्स की लंबाई कम से कम 128 हो सकती है।
नोट: Oracle डेटाबेस में, ऑब्जेक्ट नाम की न्यूनतम लंबाई - 30 प्रतीक हो सकते हैं। इस प्रकार, किसी विशेष डेटाबेस में, ऑब्जेक्ट नामों के लिए कस्टम नियम बनाना आवश्यक है।
SQL एक ऐसी भाषा है जो DBMS के माध्यम से डेटाबेस में क्वेरी निष्पादित करने की अनुमति देती है। किसी विशेष DBMS में, SQL भाषा की अपनी बोली हो सकती है।
DDL और DML - SQL उपभाषा:
- डीडीएल भाषा डेटाबेस संरचना (तालिका और लिंक हटाना) बनाने और संशोधित करने के लिए कार्य करती है;
- DML भाषा तालिका डेटा, उसकी पंक्तियों में हेरफेर करने की अनुमति देती है। यह तालिकाओं से डेटा का चयन करने, नया डेटा जोड़ने के साथ-साथ वर्तमान डेटा को अपडेट करने और हटाने के लिए भी कार्य करता है।
SQL (सिंगल-लाइन और सीमांकित) में दो प्रकार की टिप्पणियों का उपयोग करना संभव है:
-- सिंगल लाइन कमेंट
और
/* सीमांकित टिप्पणी */
सिद्धांत के लिए बस इतना ही।
DDL - डेटा परिभाषा भाषा
आइए एक नमूना तालिका पर विचार करें जिसमें कर्मचारियों के बारे में डेटा एक ऐसे व्यक्ति से परिचित तरीके से दर्शाया गया है जो प्रोग्रामर नहीं है।
| कर्मचारी आईडी | पूरा नाम | जन्मदिन | ई-मेल | स्थिति | विभाग |
| 1000 | जॉन | 19.02.1955 | example@sqldat.com | सीईओ | प्रशासन |
| 1001 | डैनियल | 03.12.1983 | example@sqldat.com | प्रोग्रामर | आईटी |
| 1002 | माइक | 07.06.1976 | example@sqldat.com | लेखाकार | खाता विभाग |
| 1003 | जॉर्डन | 17.04.1982 | example@sqldat.com | वरिष्ठ प्रोग्रामर | आईटी |
इस मामले में, कॉलम में निम्नलिखित शीर्षक हैं:कर्मचारी आईडी, पूरा नाम, जन्मतिथि, ई-मेल, स्थिति और विभाग।
हम इस तालिका के प्रत्येक स्तंभ को उसके डेटा प्रकार द्वारा वर्णित कर सकते हैं:
- कर्मचारी आईडी - पूर्णांक
- पूरा नाम - स्ट्रिंग
- जन्मतिथि - तारीख
- ई-मेल - स्ट्रिंग
- स्थिति - स्ट्रिंग
- विभाग - स्ट्रिंग
स्तंभ प्रकार एक ऐसी संपत्ति है जो निर्दिष्ट करती है कि प्रत्येक स्तंभ किस प्रकार का डेटा संग्रहीत कर सकता है।
आरंभ करने के लिए, आपको MS SQL में उपयोग किए जाने वाले मुख्य डेटा प्रकारों को याद रखना होगा:
| परिभाषा | पदनाम में एमएस एसक्यूएल | विवरण |
| वेरिएबल-लेंथ स्ट्रिंग | varchar(N) and nvarchar(N) | N संख्या का उपयोग करके, हम किसी विशेष कॉलम के लिए अधिकतम संभव स्ट्रिंग लंबाई निर्दिष्ट कर सकते हैं। उदाहरण के लिए, यदि हम यह कहना चाहते हैं कि Full Name कॉलम के मान में 30 चिह्न (अधिकतम) हो सकते हैं, तो nvarchar(30) के प्रकार को निर्दिष्ट करना आवश्यक है। varchar और nvarchar के बीच का अंतर यह है कि varchar स्ट्रिंग को ASCII प्रारूप में संग्रहीत करने की अनुमति देता है, जबकि nvarchar स्ट्रिंग को यूनिकोड प्रारूप में संग्रहीत करता है, जहां प्रत्येक प्रतीक 2 बाइट्स लेता है। दिए गए क्षेत्र में यूनिकोड प्रतीकों को संग्रहीत करने की आवश्यकता नहीं होगी। उदाहरण के लिए, आप ईमेल संपर्कों को संग्रहीत करने के लिए वर्कर का उपयोग कर सकते हैं। |
| फिक्स्ड-लेंथ स्ट्रिंग | char(N) और nchar(N) | यह प्रकार निम्नलिखित में चर-लंबाई वाली स्ट्रिंग से भिन्न है:यदि स्ट्रिंग की लंबाई N प्रतीकों से कम है, तो रिक्त स्थान हमेशा दाईं ओर N लंबाई में जोड़े जाते हैं। इस प्रकार, एक डेटाबेस में, यह बिल्कुल N प्रतीकों को लेता है, जहाँ एक प्रतीक चार के लिए 1 बाइट और nchar के लिए 2 बाइट्स लेता है। मेरे अभ्यास में, इस प्रकार का अधिक उपयोग नहीं किया जाता है। फिर भी, यदि कोई इसका उपयोग करता है, तो आमतौर पर इस प्रकार का चार (1) प्रारूप होता है, अर्थात जब किसी क्षेत्र को 1 प्रतीक द्वारा परिभाषित किया जाता है। |
| पूर्णांक | int | यह प्रकार हमें एक कॉलम में केवल पूर्णांक (सकारात्मक और नकारात्मक दोनों) का उपयोग करने की अनुमति देता है। नोट:इस प्रकार के लिए एक संख्या श्रेणी इस प्रकार है:2 147 483 648 से 2 147 483 647 तक। आमतौर पर, यह पहचानकर्ताओं के लिए उपयोग किया जाने वाला मुख्य प्रकार है। |
| फ़्लोटिंग-पॉइंट नंबर | फ्लोट | दशमलव बिंदु वाली संख्याएं। |
| तारीख | तारीख | इसका उपयोग एक कॉलम में केवल एक तिथि (दिनांक, माह और वर्ष) को स्टोर करने के लिए किया जाता है। उदाहरण के लिए, 02/15/2014। इस प्रकार का उपयोग निम्नलिखित कॉलम के लिए किया जा सकता है:प्राप्ति तिथि, जन्मतिथि, आदि, जब आपको केवल एक तिथि निर्दिष्ट करने की आवश्यकता होती है या जब समय हमारे लिए महत्वपूर्ण नहीं होता है और हम इसे छोड़ सकते हैं। |
| समय | समय | यदि समय को स्टोर करना आवश्यक हो तो आप इस प्रकार का उपयोग कर सकते हैं:घंटे, मिनट, सेकंड और मिलीसेकंड। उदाहरण के लिए, आपके पास 17:38:31.3231603 है या आपको उड़ान के प्रस्थान का समय जोड़ना होगा। |
| दिनांक और समय | डेटाटाइम | इस प्रकार से उपयोगकर्ता दिनांक और समय दोनों स्टोर कर सकते हैं। उदाहरण के लिए, आपका ईवेंट 02/15/2014 17:38:31.323 पर है। |
| संकेतक | बिट | आप 'हां'/'नहीं' जैसे मानों को स्टोर करने के लिए इस प्रकार का उपयोग कर सकते हैं, जहां 'हां' 1 है और 'नहीं' 0 है। |
इसके अलावा, फ़ील्ड मान निर्दिष्ट करना आवश्यक नहीं है, जब तक कि यह निषिद्ध न हो। इस मामले में, आप NULL का उपयोग कर सकते हैं।
उदाहरणों को निष्पादित करने के लिए, हम 'टेस्ट' नामक एक परीक्षण डेटाबेस बनाएंगे।
बिना किसी अतिरिक्त गुण के एक साधारण डेटाबेस बनाने के लिए, निम्न कमांड चलाएँ:
डेटाबेस टेस्ट बनाएं
किसी डेटाबेस को हटाने के लिए, इस कमांड को निष्पादित करें:
ड्रॉप डेटाबेस टेस्ट
हमारे डेटाबेस पर स्विच करने के लिए, कमांड का उपयोग करें:
परीक्षण का उपयोग करें
वैकल्पिक रूप से, आप SSMS मेनू क्षेत्र में ड्रॉप-डाउन मेनू से परीक्षण डेटाबेस का चयन कर सकते हैं।
अब, हम विवरण, रिक्त स्थान और सिरिलिक प्रतीकों का उपयोग करके अपने डेटाबेस में एक तालिका बना सकते हैं:
टेबल बनाएं [कर्मचारी]( 30) )
इस मामले में, हमें नामों को वर्गाकार कोष्ठकों में लपेटना होगा […]।
फिर भी, सभी ऑब्जेक्ट नामों को लैटिन में निर्दिष्ट करना और नामों में रिक्त स्थान का उपयोग नहीं करना बेहतर है। इस मामले में, प्रत्येक शब्द एक बड़े अक्षर से शुरू होता है। उदाहरण के लिए, "कर्मचारी आईडी" फ़ील्ड के लिए, हम कार्मिक संख्या नाम निर्दिष्ट कर सकते हैं। आप नाम में नंबरों का भी उपयोग कर सकते हैं, उदाहरण के लिए, PhoneNumber1।
नोट: कुछ डीबीएमएस में, निम्नलिखित नाम प्रारूप «PHONE_NUMBER» का उपयोग करना अधिक सुविधाजनक है। उदाहरण के लिए, आप इस प्रारूप को ORACLE डेटाबेस में देख सकते हैं। इसके अलावा, फ़ील्ड का नाम DBMS में उपयोग किए गए कीवर्ड से मेल नहीं खाना चाहिए।
इस कारण से, आप वर्ग कोष्ठक सिंटैक्स के बारे में भूल सकते हैं और कर्मचारी तालिका को हटा सकते हैं:
ड्रॉप टेबल [कर्मचारी]
उदाहरण के लिए, आप कर्मचारियों वाली तालिका को "कर्मचारी" के रूप में नाम दे सकते हैं और उसके क्षेत्रों के लिए निम्नलिखित नाम सेट कर सकते हैं:
- आईडी
- नाम
- जन्मदिन
- ईमेल
- स्थिति
- विभाग
अक्सर, हम पहचानकर्ता फ़ील्ड के लिए 'आईडी' का उपयोग करते हैं।
अब, एक टेबल बनाते हैं:
टेबल कर्मचारी बनाएं (आईडी int, नाम nvarchar(30), जन्मदिन की तारीख, ईमेल nvarchar(30), स्थिति nvarchar(30), विभाग nvarchar(30))
अनिवार्य कॉलम सेट करने के लिए, आप NOT NULL विकल्प का उपयोग कर सकते हैं।
वर्तमान तालिका के लिए, आप निम्न आदेशों का उपयोग करके फ़ील्ड को फिर से परिभाषित कर सकते हैं:
-- आईडी फ़ील्ड अपडेट वैकल्पिक तालिका कर्मचारी वैकल्पिक कॉलम आईडी इंट न्यूल नहीं-- नाम फ़ील्ड अपडेट वैकल्पिक तालिका कर्मचारी वैकल्पिक कॉलम नाम nvarchar(30) न्यूल नहीं
नोट: अधिकांश डीबीएमएस के लिए एसक्यूएल भाषा की सामान्य अवधारणा वही है (मेरे अपने अनुभव से)। विभिन्न डीबीएमएस में डीडीएल के बीच अंतर मुख्य रूप से डेटा प्रकारों में होता है (वे न केवल उनके नाम से बल्कि उनके विशिष्ट कार्यान्वयन से भी भिन्न हो सकते हैं)। इसके अलावा, विशिष्ट SQL कार्यान्वयन (आदेश) समान हैं, लेकिन बोली में थोड़ा अंतर हो सकता है। SQL बेसिक्स जानने के बाद, आप आसानी से एक DBMS से दूसरे DBMS में स्विच कर सकते हैं। इस मामले में, आपको केवल नए DBMS में कमांड को लागू करने की बारीकियों को समझने की आवश्यकता होगी।
ORACLE DBMS में समान कमांड की तुलना करें:
- टेबल बनाएं टेबल कर्मचारी बनाएं (आईडी int, - ओरेकल में int प्रकार संख्या (38) नाम nvarchar2 (30) के लिए एक मान है, - ओरेकल में nvarchar2 एमएस एसक्यूएल जन्मदिन की तारीख में nvarchar के समान है, ईमेल nvarchar2(30), स्थिति nvarchar2(30), विभाग nvarchar2(30)); - आईडी और नाम फ़ील्ड अपडेट (यहां हम वैकल्पिक कॉलम टेबल कर्मचारियों के बजाय संशोधित (...) का उपयोग करते हैं (आईडी int न्यूल, नाम nvarchar2 (30) न्यूल नहीं); - पीके जोड़ें (इस मामले में निर्माण समान है जैसा कि MS SQL में है) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE varchar2 प्रकार को लागू करने में भिन्न है। इसका प्रारूप डीबी सेटिंग्स पर निर्भर करता है और आप टेक्स्ट को सहेज सकते हैं, उदाहरण के लिए, यूटीएफ -8 में। इसके अलावा, आप बाइट्स और प्रतीकों दोनों में फ़ील्ड की लंबाई निर्दिष्ट कर सकते हैं। ऐसा करने के लिए, आपको लंबाई फ़ील्ड के बाद BYTE और CHAR मानों का उपयोग करना होगा। उदाहरण के लिए:
NAME varchar2(30 BYTE) - फ़ील्ड क्षमता 30 बाइट्स NAME varchar2(30 CHAR) के बराबर होती है -- फ़ील्ड क्षमता 30 प्रतीकों के बराबर होती है
डिफ़ॉल्ट रूप से उपयोग किया जाने वाला मान (BYTE या CHAR) जब आप केवल ORACLE में varchar2(30) इंगित करते हैं, तो यह DB सेटिंग्स पर निर्भर करेगा। अक्सर, आप आसानी से भ्रमित हो सकते हैं। इस प्रकार, जब आप ORACLE में varchar2 प्रकार (उदाहरण के लिए, UTF-8 के साथ) का उपयोग करते हैं, तो मैं स्पष्ट रूप से CHAR निर्दिष्ट करने की अनुशंसा करता हूं (क्योंकि यह प्रतीकों में स्ट्रिंग लंबाई को पढ़ने के लिए अधिक सुविधाजनक है)।
हालांकि, इस मामले में, यदि तालिका में कोई डेटा है, तो कमांड को सफलतापूर्वक निष्पादित करने के लिए, सभी तालिका पंक्तियों में आईडी और नाम फ़ील्ड भरना आवश्यक है।
मैं इसे एक विशेष उदाहरण में दिखाऊंगा।
आइए निम्न स्क्रिप्ट का उपयोग करके आईडी, स्थिति और विभाग फ़ील्ड में डेटा डालें:
इंसर्ट कर्मचारी (आईडी, पद, विभाग) मान (1000, 'सीईओ, एन' प्रशासन'), (1001, एन'प्रोग्रामर', एन'आईटी'), (1002, एन'अकाउंटेंट', एन'अकाउंट्स Dept'), (1003,N'Senior Programmer',N'IT')
इस स्थिति में, INSERT कमांड भी एक त्रुटि देता है। ऐसा इसलिए होता है क्योंकि हमने अनिवार्य फ़ील्ड नाम के लिए मान निर्दिष्ट नहीं किया है।
यदि मूल तालिका में कुछ डेटा थे, तो "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" कमांड काम करेगी, जबकि "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" कमांड एक त्रुटि लौटाएगा जो नाम फ़ील्ड में है शून्य मान।
आइए नाम फ़ील्ड में मान जोड़ें:
INSERT कर्मचारी (आईडी, पद, विभाग, नाम) मान (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002, एन'एकाउंटेंट', एन'अकाउंट्स विभाग', एन'माइक'), (1003, एन'सीनियर प्रोग्रामर', एन'आईटी', एन'जॉर्डन')
इसके अलावा, CREATE TABLE स्टेटमेंट के साथ एक नई टेबल बनाते समय आप NOT NULL का उपयोग कर सकते हैं।
आइए सबसे पहले एक टेबल को डिलीट करें:
ड्रॉप टेबल कर्मचारी
अब, हम आईडी और नाम अनिवार्य फ़ील्ड के साथ एक टेबल बनाने जा रहे हैं:
टेबल कर्मचारी बनाएं (आईडी इंट न्यूल, नाम नवरचर (30) नॉट न्यूल, जन्मदिन की तारीख, ईमेल नवरचर (30), स्थिति नवरचर (30), विभाग नवरचर (30))
साथ ही, आप कॉलम नाम के बाद NULL निर्दिष्ट कर सकते हैं जिसका अर्थ है कि NULL मानों की अनुमति है। यह अनिवार्य नहीं है, क्योंकि यह विकल्प डिफ़ॉल्ट रूप से सेट होता है।
यदि आपको वर्तमान कॉलम को गैर-अनिवार्य बनाने की आवश्यकता है, तो निम्न सिंटैक्स का उपयोग करें:
ALTER TABLE एंप्लॉयीज ALTER COLUMN Name nvarchar(30) NULL
वैकल्पिक रूप से, आप इस कमांड का उपयोग कर सकते हैं:
ALTER TABLE एम्प्लॉईज ALTER COLUMN Name nvarchar(30)
इसके अलावा, इस आदेश के साथ, हम या तो फ़ील्ड प्रकार को किसी अन्य संगत में संशोधित कर सकते हैं या इसकी लंबाई बदल सकते हैं। उदाहरण के लिए, आइए नाम फ़ील्ड को 50 प्रतीकों तक बढ़ाएँ:
ALTER TABLE एंप्लॉयीज ALTER COLUMN Name nvarchar(50)
प्राथमिक कुंजी
तालिका बनाते समय, आपको प्रत्येक पंक्ति के लिए एक स्तंभ या स्तंभों का एक सेट निर्दिष्ट करना होगा। इस अद्वितीय मान का उपयोग करके, आप एक रिकॉर्ड की पहचान कर सकते हैं। इस मान को प्राथमिक कुंजी कहा जाता है। आईडी कॉलम (जिसमें «एक कर्मचारी का व्यक्तिगत नंबर» शामिल है - हमारे मामले में यह प्रत्येक कर्मचारी के लिए अद्वितीय मूल्य है और डुप्लिकेट नहीं किया जा सकता) हमारी कर्मचारी तालिका के लिए प्राथमिक कुंजी हो सकता है।
तालिका के लिए प्राथमिक कुंजी बनाने के लिए आप निम्न कमांड का उपयोग कर सकते हैं:
ALTER TABLE Employees Add CONSTRAINT PK_Employees PRIMARY KEY(ID)
'पीके_कर्मचारी' प्राथमिक कुंजी को परिभाषित करने वाला एक बाधा नाम है। आमतौर पर, प्राथमिक कुंजी के नाम में 'PK_' उपसर्ग और तालिका का नाम होता है।
यदि प्राथमिक कुंजी में कई फ़ील्ड हैं, तो आपको इन फ़ील्ड को अल्पविराम द्वारा अलग किए गए कोष्ठक में सूचीबद्ध करने की आवश्यकता है:
वैकल्पिक तालिका_नाम CONSTRAINT बाधा जोड़ें_नाम प्राथमिक कुंजी(फ़ील्ड1,फ़ील्ड2,…)
ध्यान रखें कि MS SQL में, प्राथमिक कुंजी के सभी क्षेत्र NOT NULL होने चाहिए।
इसके अलावा, आप तालिका बनाते समय प्राथमिक कुंजी को परिभाषित कर सकते हैं। आइए तालिका हटाएं:
ड्रॉप टेबल कर्मचारी
फिर, निम्न सिंटैक्स का उपयोग करके एक तालिका बनाएं:
टेबल कर्मचारी बनाएं (आईडी इंट न्यूल, नाम नवरचर (30) नॉट न्यूल, जन्मदिन की तारीख, ईमेल नवरचर (30), स्थिति नवरचर (30), विभाग नवरचर (30), कॉन्स्ट्रेंट पीके_कर्मचारी प्राथमिक कुंजी (आईडी) - वर्णन करें पीके सभी फाइलों के बाद एक बाधा के रूप में)
तालिका में डेटा जोड़ें:
INSERT कर्मचारी (आईडी, पद, विभाग, नाम) मान (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002, एन'एकाउंटेंट', एन'अकाउंट्स विभाग', एन'माइक'), (1003, एन'सीनियर प्रोग्रामर', एन'आईटी', एन'जॉर्डन')
असल में, आपको बाधा नाम निर्दिष्ट करने की आवश्यकता नहीं है। इस मामले में, सिस्टम नाम असाइन किया जाएगा। उदाहरण के लिए, «PK__कर्मचारी__3214EC278DA42077»:
टेबल कर्मचारी बनाएं (आईडी इंट न्यूल, नाम नवरचर (30) नॉट न्यूल, जन्मदिन की तारीख, ईमेल नवरचर (30), स्थिति नवरचर (30), विभाग नवरचर (30), प्राथमिक कुंजी (आईडी))
या
टेबल कर्मचारी बनाएं (आईडी इंट न्यूल प्राथमिक कुंजी, नाम नवरचर (30) शून्य नहीं, जन्मदिन की तारीख, ईमेल nvarchar (30), स्थिति nvarchar (30), विभाग nvarchar (30))
व्यक्तिगत रूप से, मैं स्थायी तालिकाओं के लिए बाधा नाम को स्पष्ट रूप से निर्दिष्ट करने की अनुशंसा करता हूं, क्योंकि भविष्य में स्पष्ट रूप से परिभाषित और स्पष्ट मूल्य के साथ काम करना या हटाना आसान है। उदाहरण के लिए:
वैकल्पिक तालिका कर्मचारी DROP CONSTRAINT PK_कर्मचारी
फिर भी, अस्थायी डेटाबेस तालिकाएँ बनाते समय बिना किसी बाधा के इस संक्षिप्त सिंटैक्स को लागू करना अधिक सुविधाजनक होता है (एक अस्थायी तालिका का नाम # या ## से शुरू होता है।
सारांश:
हम पहले ही निम्नलिखित कमांड का विश्लेषण कर चुके हैं:
- तालिका बनाएं table_name (फ़ील्ड और उनके प्रकार, साथ ही बाधाओं की सूची) - वर्तमान डेटाबेस में एक नई तालिका बनाने के लिए कार्य करता है;
- ड्रॉप टेबल table_name - वर्तमान डेटाबेस से तालिका को हटाने के लिए कार्य करता है;
- तालिका बदलें table_name ALTER COLUMN column_name… - कॉलम प्रकार को अपडेट करने या इसकी सेटिंग्स को संशोधित करने के लिए कार्य करता है (उदाहरण के लिए, जब आपको NULL या NOT NULL सेट करने की आवश्यकता होती है);
- तालिका बदलें table_name प्रतिबंध जोड़ें बाधा_नाम प्राथमिक कुंजी (फ़ील्ड1, फ़ील्ड2,…) - वर्तमान तालिका में प्राथमिक कुंजी जोड़ने के लिए उपयोग किया जाता है;
- तालिका बदलें table_name ड्रॉप बाधा बाधा_नाम - तालिका से एक बाधा को हटाने के लिए प्रयोग किया जाता है।
अस्थायी टेबल
एमएसडीएन से सार। MS SQL सर्वर में दो प्रकार की अस्थायी तालिकाएँ होती हैं:स्थानीय (#) और वैश्विक (##)। SQL सर्वर की आवृत्ति डिस्कनेक्ट होने से पहले स्थानीय अस्थायी तालिकाएँ केवल उनके रचनाकारों को दिखाई देती हैं। SQL सर्वर की आवृत्ति से उपयोगकर्ता के डिस्कनेक्ट होने के बाद वे स्वचालित रूप से हटा दिए जाते हैं। इन तालिकाओं को बनाने के बाद किसी भी कनेक्शन सत्र के दौरान सभी उपयोगकर्ताओं के लिए वैश्विक अस्थायी तालिकाएँ दिखाई देती हैं। एक बार जब उपयोगकर्ता SQL सर्वर की आवृत्ति से डिस्कनेक्ट हो जाते हैं तो ये तालिकाएँ हटा दी जाती हैं।
Tempdb सिस्टम डेटाबेस में अस्थायी तालिकाएँ बनाई जाती हैं, जिसका अर्थ है कि हम मुख्य डेटाबेस को बाढ़ नहीं करते हैं। इसके अतिरिक्त, आप उन्हें DROP TABLE कमांड का उपयोग करके हटा सकते हैं। बहुत बार, स्थानीय (#) अस्थायी तालिकाओं का उपयोग किया जाता है।
अस्थायी तालिका बनाने के लिए, आप तालिका बनाएँ कमांड का उपयोग कर सकते हैं:
तालिका बनाएं #Temp(ID int, Name nvarchar(30) )
आप अस्थायी तालिका को DROP TABLE कमांड से हटा सकते हैं:
ड्रॉप टेबल #Temp
इसके अलावा, आप एक अस्थायी तालिका बना सकते हैं और इसे SELECT… INTO सिंटैक्स का उपयोग करके डेटा से भर सकते हैं:
चयन आईडी, #कर्मचारियों से अस्थायी नाम
नोट: विभिन्न DBMS में, अस्थायी डेटाबेस का कार्यान्वयन भिन्न हो सकता है। उदाहरण के लिए, ORACLE और Firebird DBMS में, अस्थायी तालिकाओं की संरचना को CREATE GLOBAL TEMPORARY TABLE कमांड द्वारा पहले से परिभाषित किया जाना चाहिए। इसके अलावा, आपको डेटा संग्रहीत करने का तरीका निर्दिष्ट करने की आवश्यकता है। इसके बाद, उपयोगकर्ता इसे सामान्य तालिकाओं के बीच देखता है और इसके साथ पारंपरिक तालिका की तरह काम करता है।
डेटाबेस सामान्यीकरण:उप-सारणी (संदर्भ तालिका) में विभाजित करना और तालिका संबंधों को परिभाषित करना
हमारी वर्तमान कर्मचारी तालिका में एक खामी है:एक उपयोगकर्ता स्थिति और विभाग के क्षेत्रों में कोई भी पाठ टाइप कर सकता है, जो गलतियाँ लौटा सकता है, क्योंकि एक कर्मचारी के लिए वह एक विभाग के रूप में "आईटी" निर्दिष्ट कर सकता है, जबकि दूसरे कर्मचारी के लिए, वह "आईटी" निर्दिष्ट कर सकता है। विभाग"। नतीजतन, यह स्पष्ट नहीं होगा कि उपयोगकर्ता का क्या मतलब है, क्या ये कर्मचारी एक ही विभाग के लिए काम करते हैं या क्या कोई गलत वर्तनी है और 2 अलग-अलग विभाग हैं। इसके अलावा, इस मामले में, हम एक रिपोर्ट के लिए डेटा को सही ढंग से समूहित करने में सक्षम नहीं होंगे, जहां हमें प्रत्येक विभाग के लिए कर्मचारियों की संख्या दिखाने की आवश्यकता है।
एक और कमी है भंडारण की मात्रा और इसका दोहराव, यानी आपको प्रत्येक कर्मचारी के लिए विभाग का पूरा नाम निर्दिष्ट करने की आवश्यकता है, जिसके लिए विभाग के नाम के प्रत्येक प्रतीक को संग्रहीत करने के लिए डेटाबेस में स्थान की आवश्यकता होती है।
तीसरा नुकसान फील्ड डेटा को अपडेट करने की जटिलता है जब आपको किसी भी पद के नाम को संशोधित करने की आवश्यकता होती है - प्रोग्रामर से जूनियर प्रोग्रामर तक। इस मामले में, आपको प्रत्येक तालिका पंक्ति में नया डेटा जोड़ना होगा जहां स्थिति "प्रोग्रामर" है।
ऐसी स्थितियों से बचने के लिए, डेटाबेस सामान्यीकरण का उपयोग करने की सिफारिश की जाती है - उप-सारणी में विभाजित करना - संदर्भ तालिकाएँ।
आइए 2 संदर्भ तालिकाएं "स्थिति" और "विभाग" बनाएं:
टेबल पोजिशन बनाएं (आईडी इंट पहचान (1,1) न्यूल कॉन्स्ट्रेंट पीके_पोजिशन प्राथमिक कुंजी, नाम नवरचर (30) न्यूल नहीं) टेबल विभाग बनाएं (आईडी इंट पहचान (1,1) न्यूल कॉन्स्ट्रेंट पीके_डिपार्टमेंट प्राथमिक कुंजी, नाम nvarchar(30) NOT NULL )
ध्यान दें कि यहां हमने एक नई संपत्ति पहचान का उपयोग किया है। इसका मतलब है कि आईडी कॉलम में डेटा स्वचालित रूप से 1 से शुरू हो जाएगा। इस प्रकार, नए रिकॉर्ड जोड़ते समय, मान 1, 2, 3, आदि क्रमिक रूप से असाइन किए जाएंगे। आमतौर पर, इन क्षेत्रों को ऑटोइनक्रिकमेंट फ़ील्ड कहा जाता है। पहचान संपत्ति के साथ केवल एक फ़ील्ड को तालिका में प्राथमिक कुंजी के रूप में परिभाषित किया जा सकता है। आमतौर पर, लेकिन हमेशा नहीं, ऐसी फ़ील्ड तालिका की प्राथमिक कुंजी होती है।
नोट: विभिन्न डीबीएमएस में, एक वेतन वृद्धि वाले क्षेत्रों का कार्यान्वयन भिन्न हो सकता है। उदाहरण के लिए, MySQL में, ऐसे क्षेत्र को AUTO_INCREMENT प्रॉपर्टी द्वारा परिभाषित किया जाता है। ओरेकल और फ़ायरबर्ड में, आप अनुक्रमों (अनुक्रम) द्वारा इस कार्यक्षमता का अनुकरण कर सकते हैं। लेकिन जहां तक मुझे पता है, ORACLE में GENERATED AS IDENTITY संपत्ति जोड़ दी गई है।
कर्मचारी तालिका की स्थिति और विभाग फ़ील्ड में वर्तमान डेटा के आधार पर इन तालिकाओं को स्वचालित रूप से भरें:
-- कर्मचारी तालिका के स्थिति फ़ील्ड से अद्वितीय मानों के साथ स्थिति तालिका के नाम फ़ील्ड भरें। /पूर्व>आपको विभाग तालिका के लिए समान चरण करने होंगे:
INSERT विभाग (नाम) उन कर्मचारियों से अलग विभाग चुनें जहां विभाग खाली नहीं हैअब, यदि हम पदों और विभागों की तालिका खोलते हैं, तो हमें आईडी फ़ील्ड में मानों की एक क्रमांकित सूची दिखाई देगी:
चुनें* पदों से
| ID | नाम |
| 1 | लेखाकार |
| 2 | सीईओ |
| 3 | प्रोग्रामर |
| 4 | वरिष्ठ प्रोग्रामर |
विभागों से * चुनें
| ID | नाम |
| 1 | प्रशासन |
| 2 | खाता विभाग |
| 3 | आईटी |
ये तालिकाएँ पदों और विभागों को परिभाषित करने के लिए संदर्भ तालिकाएँ होंगी। अब, हम पदों और विभागों के पहचानकर्ताओं का उल्लेख करेंगे। सबसे पहले, आइए पहचानकर्ताओं को संग्रहीत करने के लिए कर्मचारी तालिका में नए फ़ील्ड बनाएं:
-- आईडी स्थिति के लिए एक फ़ील्ड जोड़ें वैकल्पिक तालिका कर्मचारी स्थिति जोड़ें int - आईडी विभाग के लिए एक फ़ील्ड जोड़ें वैकल्पिक तालिका कर्मचारी विभाग जोड़ें int
संदर्भ फ़ील्ड का प्रकार संदर्भ तालिकाओं के समान होना चाहिए, इस मामले में, यह int है।
इसके अलावा, आप अल्पविराम द्वारा अलग किए गए फ़ील्ड को सूचीबद्ध करके एक कमांड का उपयोग करके कई फ़ील्ड जोड़ सकते हैं:
ALTER TABLE एम्प्लॉइज ऐड पोजीशनआईडी इंट, डिपार्टमेंट आईडी इंट
अब, हम इन क्षेत्रों में संदर्भ बाधाओं (विदेशी कुंजी) को जोड़ देंगे, ताकि उपयोगकर्ता कोई भी मान नहीं जोड़ सके जो संदर्भ तालिका के आईडी मान नहीं हैं।
ALTER TABLE एम्प्लॉइज कॉन्स्ट्रेंट जोड़ें FK_Employees_PositionID FOREIGN KEY(PositionID) रेफरेंस पोजीशन (ID)
दूसरे क्षेत्र के लिए भी यही कदम उठाए जाने चाहिए:
ALTER TABLE एम्प्लॉइज कॉन्स्ट्रेन्ट जोड़ें FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) संदर्भ विभाग (ID)
अब, उपयोगकर्ता केवल इन क्षेत्रों में संबंधित संदर्भ तालिका से आईडी मान सम्मिलित कर सकते हैं। इस प्रकार, एक नए विभाग या स्थिति का उपयोग करने के लिए, उपयोगकर्ता को संबंधित संदर्भ तालिका में एक नया रिकॉर्ड जोड़ना होगा। चूंकि पदों और विभागों को एक प्रति में संदर्भ तालिकाओं में संग्रहीत किया जाता है, इसलिए उनका नाम बदलने के लिए, आपको इसे केवल संदर्भ तालिका में बदलना होगा।
एक संदर्भ बाधा का नाम आमतौर पर मिश्रित होता है। इसमें उपसर्ग «FK» होता है, जिसके बाद एक तालिका का नाम और एक फ़ील्ड नाम होता है जो संदर्भ तालिका पहचानकर्ता को संदर्भित करता है।
पहचानकर्ता (आईडी) आमतौर पर केवल लिंक के लिए उपयोग किया जाने वाला एक आंतरिक मान होता है। इससे कोई फर्क नहीं पड़ता कि इसका क्या मूल्य है। इस प्रकार, तालिका के साथ काम करते समय दिखाई देने वाले मानों के अनुक्रम में अंतराल से छुटकारा पाने का प्रयास न करें, उदाहरण के लिए, जब आप संदर्भ तालिका से रिकॉर्ड हटाते हैं।
कुछ मामलों में, कई क्षेत्रों से संदर्भ बनाना संभव है:
वैकल्पिक तालिका तालिका जोड़ें CONSTRAINT बाधा_नाम विदेशी कुंजी(फ़ील्ड1,फ़ील्ड2,…) संदर्भ संदर्भ तालिका(फ़ील्ड1,फ़ील्ड2,…)
इस मामले में, प्राथमिक कुंजी को "reference_table" तालिका में कई फ़ील्ड (फ़ील्ड1, फ़ील्ड2,…) के सेट द्वारा दर्शाया जाता है।
अब, संदर्भ तालिका के आईडी मानों के साथ स्थिति आईडी और विभाग आईडी फ़ील्ड को अपडेट करें।
ऐसा करने के लिए, हम UPDATE कमांड का उपयोग करेंगे:
अपडेट ई सेट पोजीशनआईडी=(उन पदों से आईडी चुनें जहां नाम =ई। पद), विभाग आईडी =(विभागों से चयन आईडी जहां नाम =ई। विभाग) कर्मचारियों से ई
निम्नलिखित क्वेरी चलाएँ:
कर्मचारियों से *चुनें
| ID | नाम | जन्मदिन | ईमेल | स्थिति | विभाग | स्थिति आईडी | विभाग आईडी |
| 1000 | जॉन | शून्य | शून्य | सीईओ | प्रशासन | 2 | 1 |
| 1001 | डैनियल | शून्य | शून्य | प्रोग्रामर | आईटी | 3 | 3 |
| 1002 | माइक | शून्य | शून्य | लेखाकार | खाता विभाग | 1 | 2 |
| 1003 | जॉर्डन | शून्य | शून्य | वरिष्ठ प्रोग्रामर | आईटी | 4 | 3 |
जैसा कि आप देख सकते हैं, स्थिति आईडी और विभाग आईडी फ़ील्ड पदों और विभागों से मेल खाते हैं। इस प्रकार, आप निम्न आदेश निष्पादित करके कर्मचारी तालिका में स्थिति और विभाग फ़ील्ड हटा सकते हैं:
ALTER TABLE Employees DROP COLUMN position, Department
अब, इस कथन को चलाएँ:
कर्मचारियों से *चुनें
| ID | नाम | जन्मदिन | ईमेल | स्थिति आईडी | विभाग आईडी |
| 1000 | जॉन | शून्य | शून्य | 2 | 1 |
| 1001 | डैनियल | शून्य | शून्य | 3 | 3 |
| 1002 | माइक | शून्य | शून्य | 1 | 2 |
| 1003 | जॉर्डन | शून्य | शून्य | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
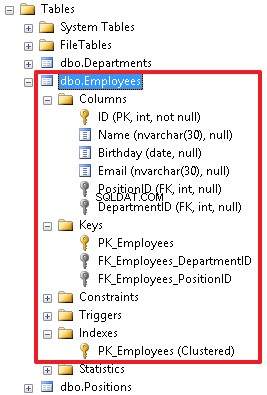
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
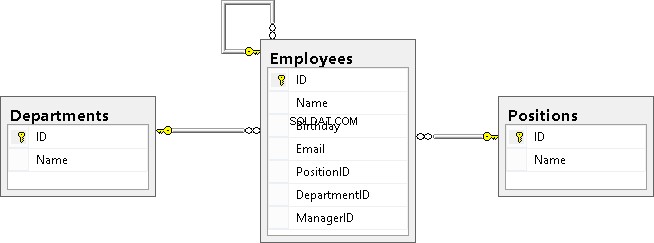
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
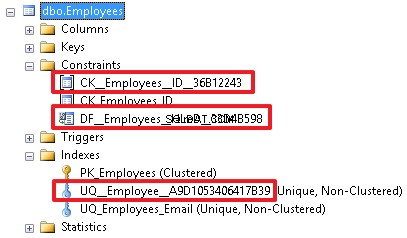
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
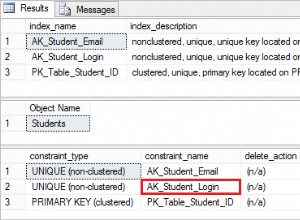
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
सारांश
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.